一、字符编码初探
字符编码其实就是将人类能识别的字符与计算机能识别的数字对应起来。ASCII(American Standard Code for Information Interchange)美国信息交换标准代码,是最早最通用的单字节编码标准。
ASCII单字节编码表示范围有限,是不能满足表示中文的,于是基于ASCII扩展,制定了GB2312标准(GB是国标的意思)。现在最常用的中文编码标准GBK又是GB2312的升级,能表示更多的字符。
计算机的发展和普及在各个国家和地区各有不同,各国也是制定了自己的编码标准,这些基于ASCII扩展而来,使用多字节表示字符的延伸编码方式称为 ANSI 编码。在简体中文Windows系统中,ANSI编码代表GBK,而韩文系统中ANSI编码代表EUC-KR。
由于不同国家和地区编码标准不一致,也导致了它们之间存在复杂的编码转换,于是诞生了unicode编码方式,以提供统一的编码标准,所以unicode也叫万国码,其标准称呼应该是Universal Multiple-Octet Coded Character Set,简称UCS。而unicode又存在多种编码方式的实现,其中UTF-8是最常用的一种UTF(UCS Transfer Format)标准。
二、python2/python3的默认编码
python2的默认编码是ascii,python3则是utf-8。可以通过如下方式获取:
python2 -c "import sys;print(sys.getdefaultencoding())"python3 -c "import sys;print(sys.getdefaultencoding())"可以在python文件开头设置默认编码,python3默认就使用了utf-8,所以不需要该编码声明。
# -*- coding: UTF-8 -*-# coding=utf-8python2虽然指定了编码,但还是不能很好地处理中文,在终端输出、文件读写、json处理等都难免遇到问题。要解决各种编码问题,需要明确当前编码是什么,python编码的相关特性,数据来源是什么编码,数据输出又是什么编码。
三、起点-python2打印输出中文
我们在python2文件开头设置了编码方式为utf-8,如果cmd终端字符编码不是utf-8,要正常打印输出中文,还
需要将字符串先解码,再编码成终端的编码格式输出
。
比如,中文windows系统的cmd终端默认是gbk中文编码,chcp查看活动代码页编号是936,也就是gbk编码,要正常输出中文,字符串需要先解码,再编码成终端的gbk格式打印,如下。
# -*- coding: UTF-8 -*-#python2import sysprint("中文".decode('utf-8').encode(sys.stdout.encoding)) #文件开头已经指定默认编码为utf-8,但是终端是gbk,所以需要先decode('utf-8') 再 encode(sys.stdout.encoding)
四、特性初识-python2/python3的unicode类型
python2与python3在定义unicode类型时是通用的。
#定义unicode类型u = u'中文'u = u"中文"u = u'''中文'''u = u"""中文"""我们知道unicode是通用的,所以无论使用python2还是python3执行如下代码时均不会出现乱码。
print(u"中文")print(u'中文')#均输出中文
所以前面python2
打印输出
的问题其实可以简写。
print("中文".decode('utf-8')) #"中文".decode('utf-8')是unicode类
五、区别-python2/python3的str、bytes类型
python2与python3在定义str、bytes类型时是通用的。
#定义str类型s = 'test's = "test"s = '''test'''s = """test"""#定义bytes类型b = b'test'b = b"test"b = b'''test'''b = b"""test"""首先, bytes类型是字节序列,一个事实上的bytes类型每个元素就是一个字节 。
打开一个gbk编码的文本,可以看到其对应十六进制字符码。
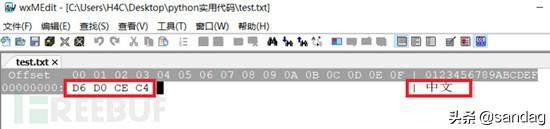
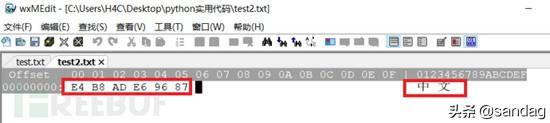
utf-8编码的文本,字符码则不同。可以看到,
能表示更多字符的编码标准,需要更多的字节来表示字符
。
首先查看如下python2代码运行情况。
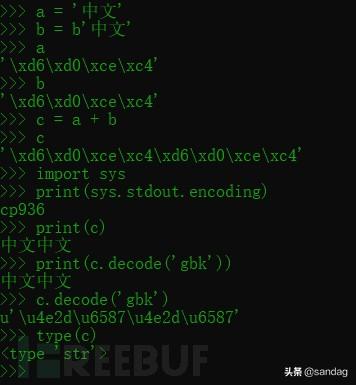
可以看到,python2处理str和bytes时是混用的,可以进行+运算,但它们都是字节序列。 python2没有将str和bytes型数据做明显的区分,是一种隐式的混用,并且python2处理str类型时优先将其视为bytes 。事实上str.decode是bytes.decode,从而转换成unicode。 str/bytes/unicode三者关系:str(bytes)—decode—>unicode—encode—>str(bytes) 。
不同于python2, python3对str和bytes型数据作了明显区分,str表示文本,默认就是原生unicode的utf-8编码格式,bytes型数据就表示二进制数据 ,用下标取bytes类型的单个元素返回的是int类型,而在python2中用下标取bytes类型的单个元素返回的还是bytes。 bytes/str/unicode三者关系:bytes—decode—>str(unicode)—encode—>bytes ,不能像python2那样string.decode。
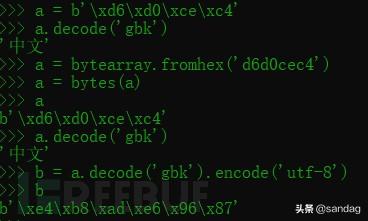
s = '中文'b = bytes(s,encoding='utf-8') # s.encode('utf-8')s = str(b,encoding='utf-8') # b.decode('utf-8')上面python2的实验,标准输出编码是gbk,将xd6xd0xcexc4复制到python3验证编码区别,如下python3的运行情况,可以看到gbk可以正常解码,再进行encode(‘utf-8′)得到bytes字节序列是不是与前面utf-8文本中”中文”的十六进制数据相同。
六、文件路径/文件名/文件读写
1.文件路径的困惑
存在如下一段代码,遍历目录里面的文件。
# -*- coding: UTF-8 -*-import osall_files = []for filepath, dirnames, filenames in os.walk(directory):for filename in filenames:tmppath = os.path.join(filepath, filename)all_files.append(tmppath)print(all_files)python2/python3结果对比。python3将str视为unicode处理的,所以正常显示。可以看到python2是以gbk编码来识别目录的。

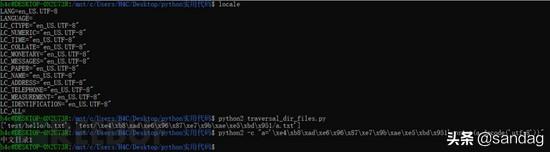
当前活动代码页是gbk,那python2识别目录是否会受到当前cmd终端编码方式影响?改变当前活动代码页为utf-8后,目录还是以gbk编码识别,encode成utf-8才能正常打印出目录名。

文章开头了解到ANSI编码的特点,是否可以推测python2是以当前系统ANSI编码获取目录名的呢?linux shell验证确实如此。
2.python2的文件名乱码
python2运行如下代码,文件名出现了乱码。
# -*- coding: UTF-8 -*-# python2/python3with open('中文2.txt','w+') as f:f.write("中文")
前面推测python2是以当前系统ANSI编码获取目录名,所以创建文件是否也是这样,由于声明了编码方式是utf-8,而文件名”中文2.txt”字符串是以bytes、utf-8格式存储的,与gbk不一致,所以导致乱码。尝试将代码改成如下,文件名正常。
# -*- coding: UTF-8 -*-# python2with open('中文2.txt'.decode('utf-8').encode('gbk'),'w+') as f: #当前编码是utf-8 所以先decode,再encode为系统的gbk编码f.write("中文")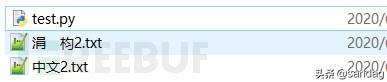
那么找文件读又会是怎样?
# -*- coding: UTF-8 -*-# python2with open('中文2.txt','r') as f:print(f.read().decode('utf-8'))python2执行报错No such file or directory,没有文件或目录。

修改文件名为 ‘中文2.txt’.decode(‘utf-8′).encode(‘gbk’) 后才正常找到了文件,由此可见, python2在识别目录、open创建、读取文件时均以系统ANSI编码识别的 ,处理中文名称时, 需要将目录/文件名字符串先解码,再编码成系统的ANSI编码格式 。
3.写入是否正常
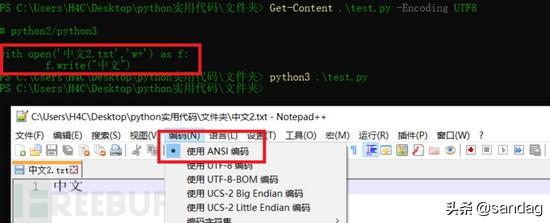
打开前面python2生成的两个文件,都是utf-8格式,内容中文显示正常!体会到python2的诡异编码了吗?至于这一点,忘了吧…
python3就没那么奇葩了,写入文本后,中文windows系统是ANSI编码,而linux是utf-8编码。
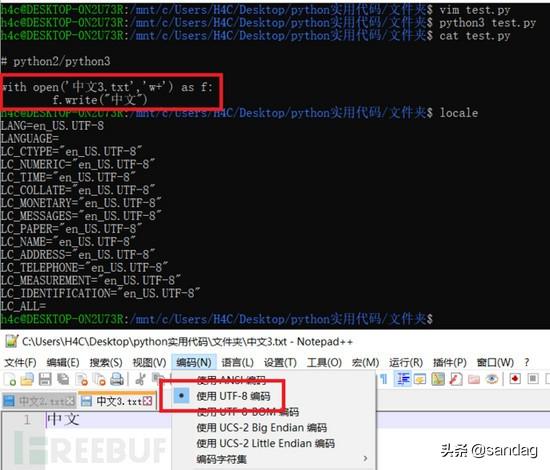
python3 open文件操作若不指定编码,则默认以系统ANSI编码写入、读取文本。 建议如果不是以二进制读取和写入,open文件时可指定文本的编码方式。
f = open("中文1.txt",'a+',encoding='utf-8')
4.读取小结
不管python2还是python3,解决编码问题的核心都是要解决编码统一。通过”python2/python3的默认编码”小节,我们认识到python2与python3默认编码的区别,实际上 python文件开头的编码声明声明的是当前脚本内字符串的编码 ,所以才有了python2打印输出中文时需要先decode(‘utf-8′),再encode(‘gbk’)为cmd终端编码格式,以及中文文件名的编码转换,至于python3,统一了编码,str就是原生unicode,具有普适性,就没有那么多编码转换。总之,读取文件时,需要明确文件的编码,当前python脚本文件的编码声明,输出的编码。如果一个utf-8格式文本文件内包含”xd6xd0xcexc4″、”中文″等字符串,读取后又如何处理呢?
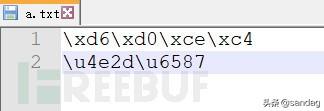
python2 可以以string-escape和unicode-escape方式解码。
# -*- coding: UTF-8 -*-# python2with open('a.txt','r') as f:lines = f.readlines()print(lines) #读取后会加上转义 ['xd6xd0xcexc4', '中文']for line in lines:if 'x' in line:print(line.decode('string-escape'))if 'u' in line:print(line.decode('unicode-escape'))python3 可以参考如下方式处理。
# -*- coding: UTF-8 -*-import codecswith open('a.txt','r',encoding='utf-8') as f:lines = f.readlines()print(lines)for line in lines:if 'x' in line:bline = bytes(bytearray.fromhex(line.strip().replace('x','')))print(bline.decode('gbk')) #xd6xd0xcexc4 是"中文"gbk格式的字符码if 'u' in line:print(codecs.decode(line,'unicode_escape'))
七、python2 json的问题
存在如下代码。
# -*- coding: UTF-8 -*-# python2import jsona = {'a':'test','语言':'中文'}with open('a.txt','a+') as f:f.write(json.dumps(a))运行之后,json.dumps会将中文以unicode的字符码形式dump,并不是真正的中文,需要指定ensure_ascii=False参数来dump真正的中文。
json.dumps(a,ensure_ascii=False)如下,dumps后文件为utf-8格式,如果读取进行json.loads,得到的字典”键”和”值”就都会是unicode类型的。
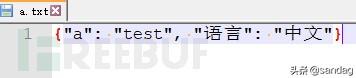
# -*- coding: UTF-8 -*-import jsonwith open('a.txt','r+') as f:print(json.loads(f.read()))结果如下。

需要对获取到的字典”键”和”值”进行解码的话,这里可以参考一段代码处理。
def unicode_convert(input):if isinstance(input, dict):return {unicode_convert(key): unicode_convert(value) for key, value in input.items()}elif isinstance(input, unicode):return input.encode('utf-8')else:return input
八、总结
4月20日,Python2的最后一个版本发布:2.7.18。可以说python2已是过去式,python3才是未来。可为什么文章大部分内容却还是python2的呢?一是确实python2的字符编码问题多,解决这些问题能更好的理解python编码机制;二是即便python2不再有,但编码问题一定一直会存在,不管是python自己生成处理的数据还是其它源数据。从解决python2的编码问题到了解python2与python3的差异,总结出以下解决编码问题的关键点,如有不当,还望指正。
1.python2的默认编码是ascii,python3则是utf-8。
2.python文件开头的编码声明声明的是当前脚本内字符串的编码,要避免编码错误,需要统一数据源,声明的编码类型,数据输出三者的编码。
3.python2没有将str和bytes型数据做明显的区分,是一种隐式的混用,并且python2处理str类型时优先将其视为bytes。str/bytes/unicode三者关系:str(bytes)—decode—>unicode—encode—>str(bytes)。
4.python3对str和bytes型数据作了明显区分,str表示文本,默认就是原生unicode的utf-8编码格式,bytes型数据就表示二进制数据。bytes/str/unicode三者关系:bytes—decode—>str(unicode)—encode—>bytes。
5.python2在识别目录、open创建、读取文件时均以系统ANSI编码识别的。
6.python3 open文件操作若不指定编码,则默认以系统ANSI编码写入、读取文本。