丨
目录:
· 概述
· 业界方案
· 本文方法
· 实验部分
· 总结
· 参考文献
1. 概述
在以淘宝搜索广告为代表的经典搜推广场景中,转化率(CVR)预估作为面向GMV优化的重要基础能力发挥着不可替代的重要作用。特别地,在广告场景中,CVR预估同时作为排序机制与CPC、oCPX等多种出价策略的基础模块,承担着平台效率与广告主ROI兼顾、保持电商广告平台健康发展的重要职能。
本文将从以下几个方面分享关于CVR延迟反馈建模与在线学习在直通车主场景的实践:
-
CVR&延迟反馈建模的问题定义与意义
-
我们对业界延迟反馈建模主流方案的理解
-
直通车CVR延迟反馈建模(DEFUSE/Bi-DEFUSE)算法思路
-
DEFUSE/Bi-DEFUSE与业界方法比较与直通车落地效果
文中相关工作已发表在 TheWebConf 2022,欢迎感兴趣同学阅读交流。
论文
:Asymptotically Unbiased Estimation for Delayed Feedback Modeling via Label Correction
下载
:https://arxiv.org/abs/2202.06472
1.1 背景
在CTR建模中,基于实时样本流的在线学习已经在搜索直通车等多个主流场景上取得显著效果。对样本和模型时效性的极致追求在CTR、CVR建模的Topic中已经成为与特征体系建设、模型结构优化并列的重要探索方向。然而,由于用户购买决策的成本天然远大于近乎零成本的点击决策,导致CVR建模中普遍存在常态化、显著的反馈延迟,即<user,item>的成交时间与<user,item>点击时间之间存在明显的延迟(delay)。从下表中可以看到,淘宝搜索直通车场景只有约60%的成交发生在点击item后的30分钟内,在Criteo数据上,这一比例更是低至42%。

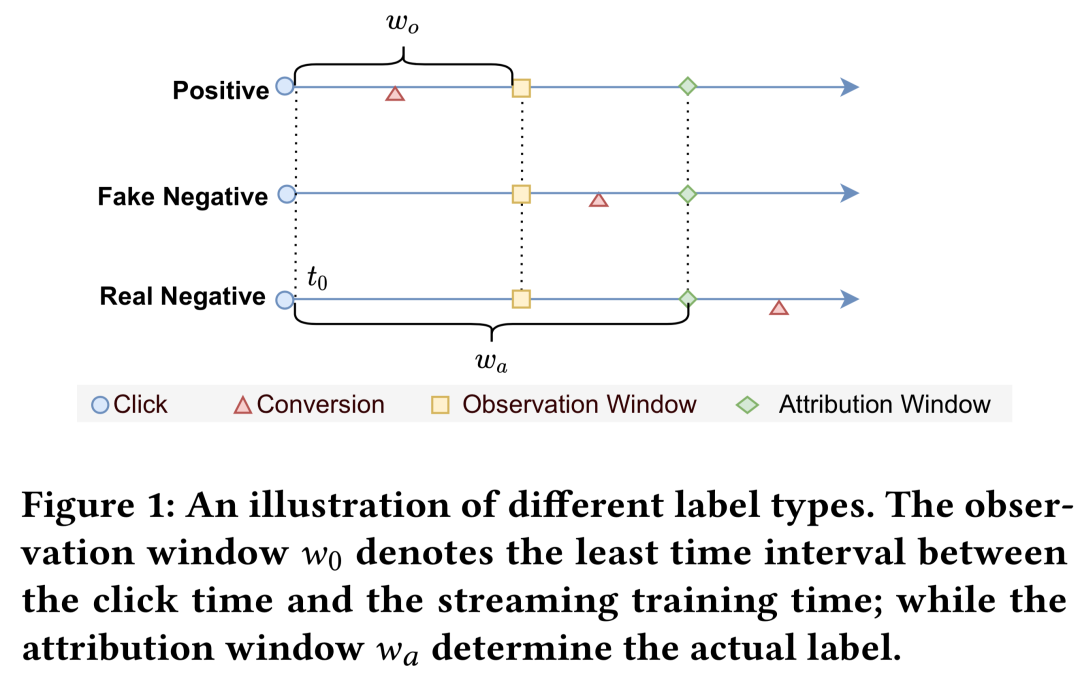
一般而言,在CVR预估中,对于发生于时刻的点击,以表示成交延迟(成交时间-点击时间),则只有其成交发生在(即)时,才被定义为CVR正样本。这种普遍存在的反馈延迟,一方面限制绝大多数场景无法设定较小的,另一方面也直接导致在CVR预估中只有等待足够长的时间(>=)才能观测到准确的样本label,两者的共同作用使得实时样本构建与在线学习成为CVR建模的巨大挑战。为了解决这一问题,目前业界主流方案通过引入远小于归因周期的观测窗口(由或表示,一般为15min/30min)这一概念实现样本时效性与label准确性的trade-off。如图1所示,即允许点击以截止时刻的观测成交状态作为(观测)label进入训练,通过延迟反馈建模来修正观测分布与真实分布间的偏差。
2 业界方案
2.1 传统CVR建模
在传统CVR建模中,我们定义输入为,其中以表示样本特征,表示真实转化label,表示真实分布,以表示CVR预估模型,并通过二分类cross entropy loss优化来建模:
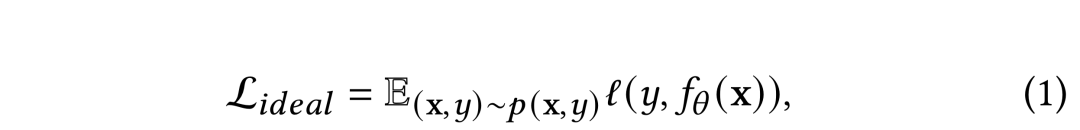
在实际应用中,(1)式则由以下经验表达式来拟合。

2.2 CVR延迟建模主流思路
如前所述,在传统CVR建模的基础上,主要通过引入观测窗口和成交延迟可以在不改变归因周期的情况下实现一定程度上的样本时效性与label准确性的trade-off。因此,根据图1中成交延迟与观测窗口的关系,CVR样本可以被划分成以下四类:
-
窗口内成交(Immediate Positive/IP):即的窗口内成交正样本
-
真负样本(Real Negative/RN):即无成交或的点击样本
-
假负样本(Fake Negative/FN):即的窗口外成交正样本,也即截止观测窗口结束时观测到的假负样本
-
延迟正样本(Delay Positive/DP):在FN成交发生时刻,被重新识别为正样本的延迟样本,与FN只有label及样本产出时间上的差异
根据以上trade-off实现方式的不同,不考虑CVR建模中不常使用的bandit类方法,则目前业界基于延迟反馈的CVR建模主要可以分成以下两种思路:
-
基于观测分布的延迟反馈&CVR联合建模
该思路的代表作主要以早期的经典方法为主[1, 2],该类方法在建模中通过显示建模一个成交是否可能发生在观测窗口外的概率来实现基于观测分布的label纠偏,即:
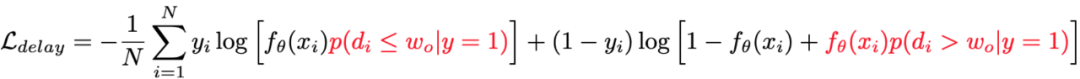
该类方法虽然理论上可以实现无偏建模,但由于对于延迟成交()样本只能通过联合建模来推断而无法在成交时作为确定性的正反馈,效果提升有限,实际应用较少。
-
基于样本回补的延迟反馈&CVR联合建模
为了充分利用稀疏且珍贵的正反馈,特别是延迟反馈,目前主流方案采用设计不同的样本回补机制并通过重要性采样(Importance Sampling/IS)进行样本分布纠偏。
样本回补机制
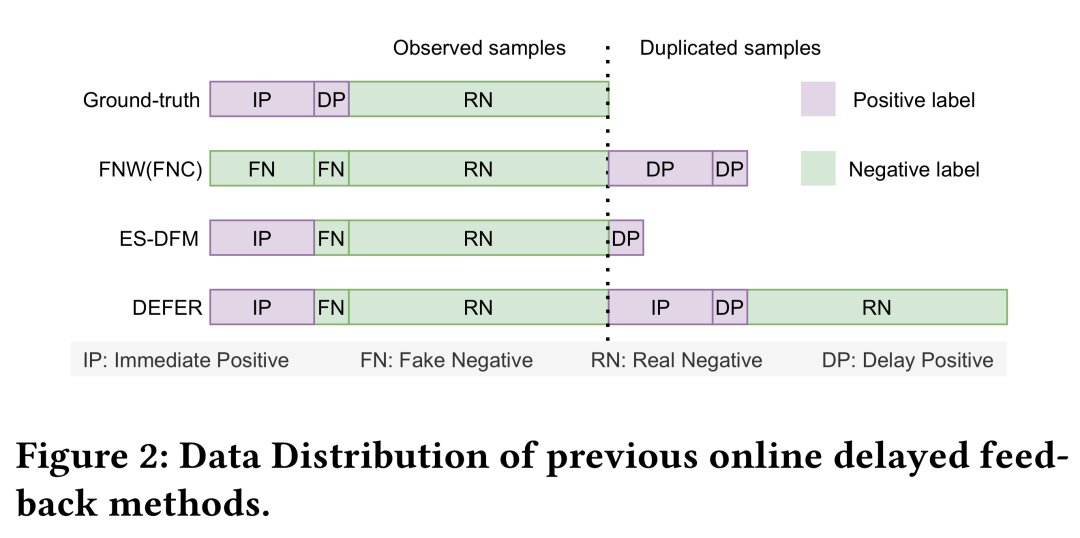
如图2所示,通过与真实分布的比较,以其代表作为例,目前业界主要有三种不同的样本回补机制:
-
FNC/FNW[3]
FNC/FNW所采用的的回补机制,最大的特点为,将所有点击样本在点击发生时刻首先作为观测负样本进入模型训练,所有的正样本在成交发生时刻作为重复样本以回补方式再次进入样本流中。
-
ES-DFM[5]
ES-DFM采用经典的窗口式样本回补,即所有点击样本在等待观测窗口(>0)结束后,在时刻根据观测到的成交状态确定观测label后构建实时样本,对于窗口内没有成交的观测负样本,在成交发生时作为延迟正样本再次下发。
-
DEFER[4]
DEFER对于窗口内样本的处理与ES-DFM一致,两者的区别在于ES-DFM只重新下发延迟成样本,而DEFER在完整归因周期结束后,将所有样本以真实label重新下发,以确保样本在特征空间上与真实分布保持一致。
重要性采样(IS)
以和分别表示基于完整归因周期的真实(ground-truth)分布和基于观测窗口与引入样本回补的观测(observed)分布,则可以将(1)式中的CVR loss函数改写为:

其中,为重要性采样(IS)所引入的真实分布与观测分布的似然比。在IS的具体应用中,目前业界所有方法均使用以下形式[3]:
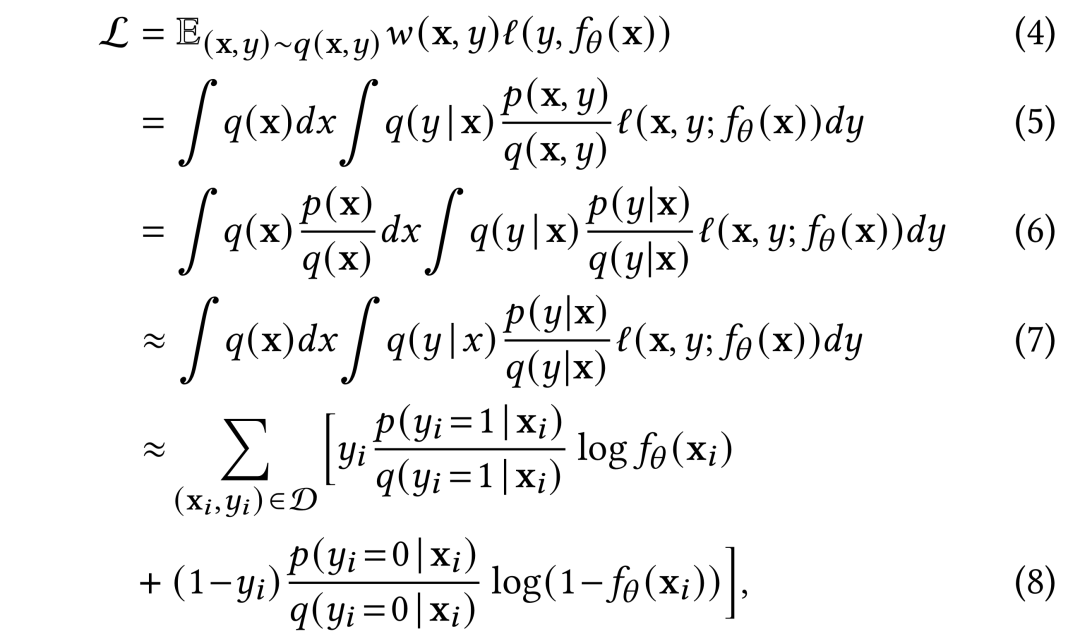
其中,(6)式到(7)式的近似,主要通过精心设计的样本回补机制或者直接假设实现;(7)式到(8)式的近似则表示通过数据对分布的拟合;而业界方法在实现和效果上的差异,主要集中在以下两部分:
-
延迟建模形式上的差异:是对成交延迟单独建模还是对成交及延迟整体建模
-
样本回补机制的设计:如何定义回补样本以及观测窗口的选取,从而决定重要性权重(importance weight)的推导结果 如前所述,目前业界基于回补的方法,在IS的应用上,均采用上述(4)式至(8)式的推导思路,其区别主要在于回补机制设计上的差异,进而衍生出的重要性权重表达式上的差异:

2.3 主流延迟建模方法的问题
虽然业界方法通过上述方案使用IS进行观测分布向真实分布的纠偏都取得了不同程度的收益,但上述(4)式至(8)式的推导过程中仍然有部分问题导致已有建模思路无法实现面向真实分布的无偏估计。
具体而言,IS的应用中隐含了一个假设条件,即在真实分布与观测分布的转化中,只存在概率空间上每一个点<x,y>在概率密度上的变化而不存在取值空间或<x,y>元素取值上的变化。然而,在CVR预估中,所有的样本回补机制中,FN到DP的变化与回补过程中必然涉及label的更新。严格来讲,如果以表示真实label,以表示观测label,则两者的关系应该表示为:

因此,目前业界方法在(8)式中,都错误地将理应表示为的假负样本(FN)等同于真负样本(RN)处理。
3 本文方法
为了解决2.3中所指出的问题,我们提出了一种更为严谨的IS应用方式,并以此为基础提出原创算法DEFUSE(DElayed Feedback modeling with UnbiaSed Estimation),同时提供了基于公开数据集Criteo及直通车搜索广告真实场景数据集的详细比较。
3.1 DEFUSE
为了实现基于IS的CVR无偏估计,我们首先需要对样本按图2进行更为细致的划分,同时使用2.3中的来更为严谨的刻画真实label 与观测label 之间的差异,并将(5)式中的loss函数重新改写为下述(13)式:
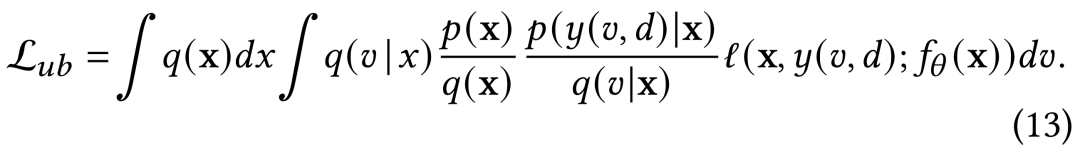
可以看出,(13)式与传统基于IS建模方法的差别主要体现在:
1)不通过的假设简化问题
2)
-
importance weight of DEFUSE
与以往基于IS的方法主要侧重样本回补机制的设计不同,我们的DEFUSE力求改进IS应用中loss函数各部分importance weight 的推导,以实现基于回补策略的CVR无偏估计。从图2可见,由于均为离散变量,在将样本划分为四部分后,(13)式可以改写为:
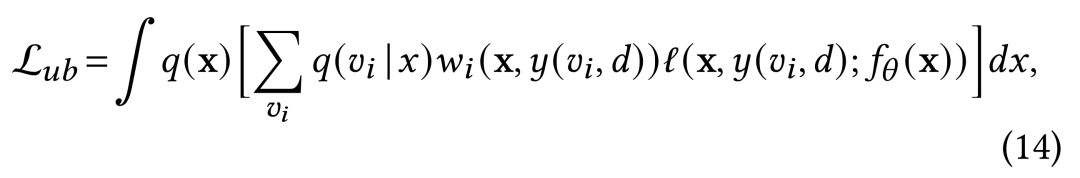
其中,,表示不同类型的四种样本,且,。根据CVR样本回补机制的特点,四类样本中,IP、DP均可直接观测到,并根据与的关系可相互区分,只有RN与FN无法通过观测数据直接区分。为了解决这一问题从而求解(14)式,我们引入潜变量来刻画一个观测到的负样本是否为假负样本FN,从而区分RN与FN,因此通过推导可知,(14)式等价于:
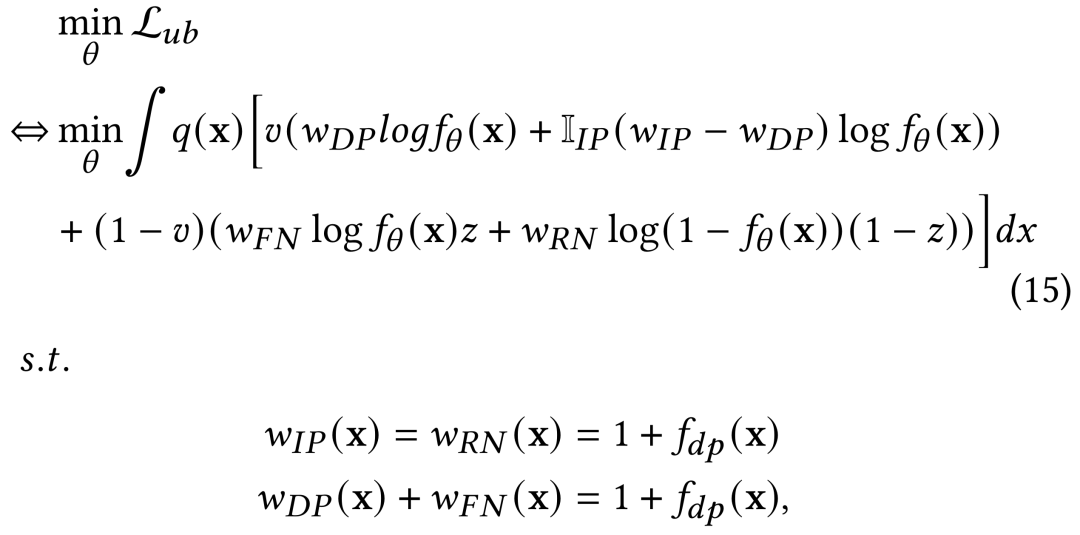
其中,, , , 即四类样本对应的importance weight,为样本是否为观测窗口内成交的正样本(IP)的示性函数。考虑到DP可观测,我们将(15)式关于和的约束简化为与,同时引入辅助模型通过建模一个点击最终为窗口外延迟成交的概率来刻画。
-
optimization of DEFUSE
在确定了各部分IS权重后,便确定了loss函数的形式,loss的求解(15)式中只需要设法估计即可。为此,我们额外引入一个辅助模型来预估从而区分RN与FN,即:
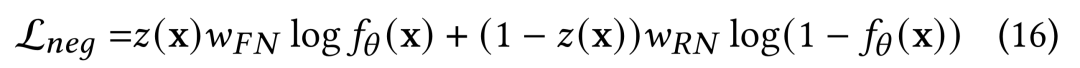
与需要单独建模的不同,根据的定义,我们可知:
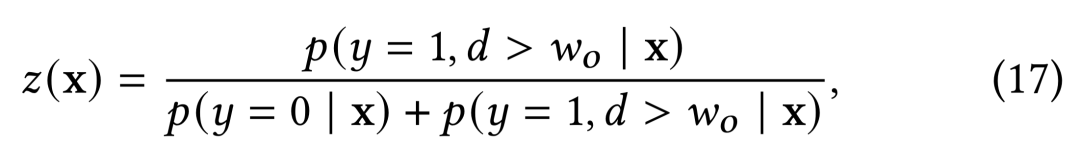
因此从实现上,可以通过两种方式求解而无需直接建模:
1)通过从观测负样本中识别RN二分类模型来刻画,形式简单,实际使用效果往往优于
2)
402 Payment Required
这一形式最大的好处在于完全通过CVR模型
与dp模型
表示
,无需引入额外的模型,但由于形式复杂,预估稳定性较差
3.2 Bi-DEFUSE
虽然DEFUSE已经实现了CVR的无偏估计,但在实际应用中,由于特别是与项仍然可能造成较大的方差,使得训练收敛速度变慢或导致次优解。为了探索进一步优化的空间,同时考虑到CVR场景中,仍然有一半左右的成交会在较短时间(30min)内完成(表1),我们提出一种基于窗口内外成交单独建模的Bi-DEFUSE方法,将CVR建模分拆为两个子任务,通过多任务学习框架实现联合训练[6,7,8,9],具体见图3(a),其中子任务的定义如下:
1)面向窗口内成交的建模: 其观测分布与真实分布一致,采用传统的二分类cross-entropy即可,具体形式为
2)窗口外成交建模: 通过DEFUSE进行分布修正,从而将引入产生的方差限定在窗口外建模的范围内,最大程度上保证了训练的稳定性

最终CVR建模可以表示为:
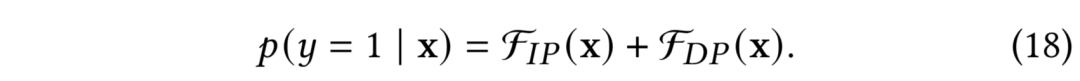
其中,如图3(b)所示,直接面向真实分布建模,不受IS及辅助模型表现的影响,的观测分布从形式上与FNW的回补机制一致,与基于ES-DFM回补方式的(15)式推导类似,基于FNW的DEFUSE及其IS权重(importance weight)的推导结果如下:
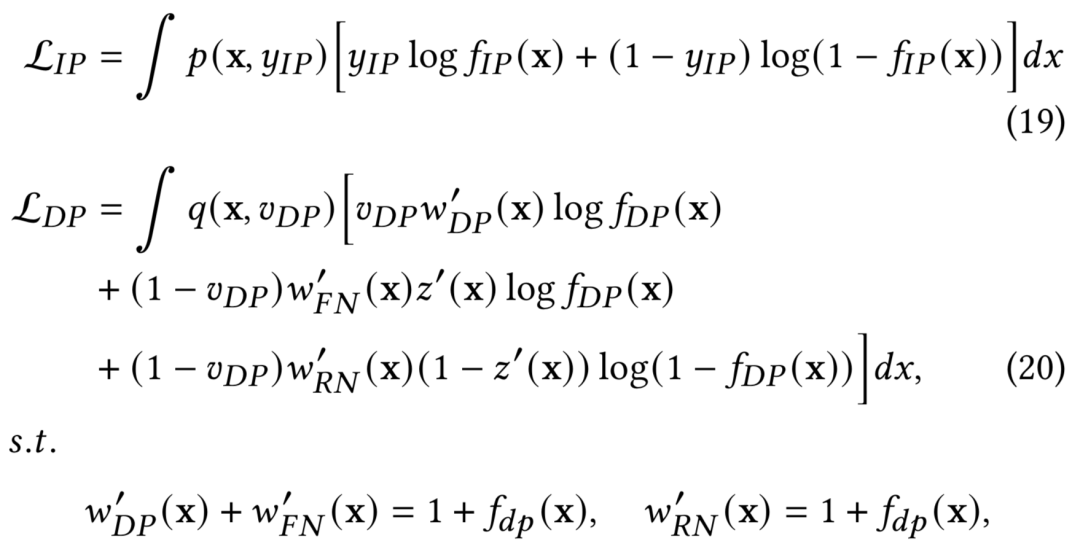
值得注意的是,这里, 分别表示窗口内建模、窗口外建模各自的观测分布,两者不仅实际用于训练的样本集合不同,所使用的的label也存在差异(见图3(b))。Bi-DEFUSE最终loss函数。
4 实验部分
本部分中,我们主要进行了DEFUSE/Bi-DEFUSE与业界主流方法在公开数据集与直通车场景下的效果表现,并回答以下问题:
-
RQ1:在流式样本训练方式下,DEFUSE与业界方法的比较
-
RQ2:DEFUSE在不同回补机制下的表现
-
RQ3:DEFFUSE/Bi-DEFUSE中不同组成部分的效果拆解
4.1 实验数据
我们的实验主要基于两份数据,数据中所涉及的样本、特征规模等见表4:
-
Criteo公开数据集:基于该数据集进行了30天归因与1天归因的效果比较
-
淘宝直通车(搜索广告)工业数据集:进行1天归因的效果比较

为了与业界方法可比,同时为了通过离线数据尽量复现在线学习环境下的表现,我们复用了ES-DFM的数据处理方式,根据点击时间戳将流数据集划分为多个数据集,每个数据集包含一个小时的数据,同时模型遵循工业系统在线训练的方式,先对t小时数据进行训练,然后对t+1小时数据进行测试,然后对t+1小时数据进行训练,再对t+2小时数据进行测试,依此类推。为了模拟在线场景,训练数据基于观测分布使用假负例,而评估数据使用服务无回补真实分布的样本,取不同时间评估数据集的均值,来比较不同方法在流式数据上的整体表现。
4.2 对比Baselines
我们主要与以下方法进行比较:
-
Pre-trained:基于预训练数据的预训练模型,直接用于流式数据的评估,也是后续所有方法用于流式数据finetune的pretrain模型
-
Oracle:理想化的CVR模型,在点击发生时候就“知道”未来真实的label,作为延迟建模的参考理论上限
-
Vanilla:将传统cross-entropy用于流式数据的窗口内成交建模且不使用延迟回补机制(即Bi-DEFUSE中的IP模型)
-
Vanilla-Win:会将窗口外成交的延迟样本再次下发,即使用ES-DFM回补机制但仍然采用cross-entropy以传统CVR建模方式训练
-
FNW:基于Pre-trained模型的FNW,具体实现见[3]
-
FNC:基于Pre-trained模型的FNC,具体实现见[3]
-
ES-DFM:具体实现见[5]
-
DEFER:具体实现见[4]
4.3 效果比较(RQ1)

从表5中可以看出:
-
DEFUSE/Bi-DEFUSE在几乎所有的数据上都取得了top1/2的表现,同时,在归因周期较短从而IP占主导的数据中,Bi-DEFUSE的表现优于DEFUSE
-
ES-DFM与DEFER的表现整体有FNC/FNW,考虑到这些方法所采用的IS思路相同,一定程度上说明了引入合理的观测窗口()的整体效果优于FNC/FNW的回补方式()
4.4 DEFUSE在不同回补机制下的表现(RQ2)
如前所述,我们的DEFUSE中对IS的优化适用于所有回补机制,为了验证DEFUSE是否在所有回补机制上都能相对已有方法的正向效果,我们在Criteo数据集与FNW、ES-DFM、DEFER进行了比较,结果充分证明了DEFUSE针对IS优化的有效性,具体结果见表6。
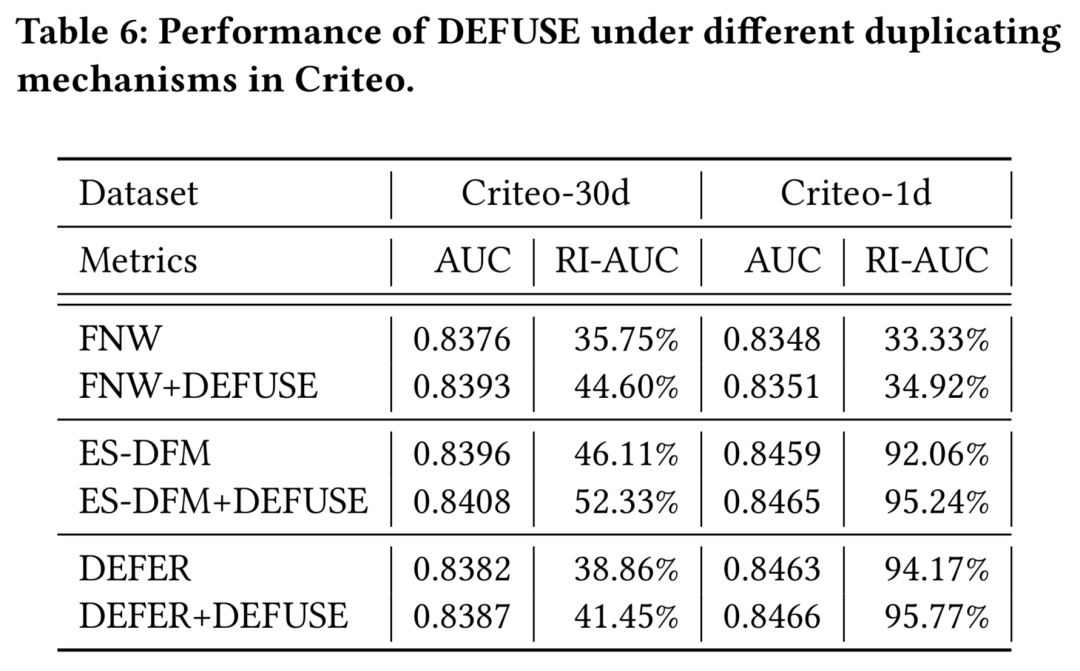
4.5 DEFUSE/Bi-DEFUSE拆解实验(RQ3)
基于DEFUSE/Bi-DEFUSE的特点,我们主要进行了以下探索:1)潜变量及其建模方式对效果的影响 2)Bi-DEFUSE网络结构的效果拆解 3)DEFUSE/Bi-DEFUSE在不同归因周期下的表现
-
z(x)的影响
如3.1中所属,根据的定义,可以使用两种不同的建模方式,在比较使用与效果的同时,我们也引入了(即告知模型区分FN与RN的真实label)作为评价参考,从表7中可以发现:
-
DEFUSE+总是优于DEFUSE+,我们这主要是由于形式更为简单从而不会因为复杂度引入额外的方差
-
DEFUSE虽然总是一致最优,但在归因周期较小时,DEFUSE+与其表现非常接近,部分程度上说明归因周期越长,延迟建模的难度越大,效果也会相应衰减

-
Bi-DEFUSE结构拆解
为了进一步了解Bi-DEFUSE各部分贡献,我们进行了如下拆解与对比实验:1)标准版Bi-DEFUSE:如图3(a)所示 2)简化版Bi-DEFUSE:使用MLP替换MMoE,表示为3)完全版Bi-DEFUSE:使用完全独立无共享的两个模型训练子任务,标记为,由于存储&计算资源限制,该方案不会作为实际上线版本,仅作为效果参考上限
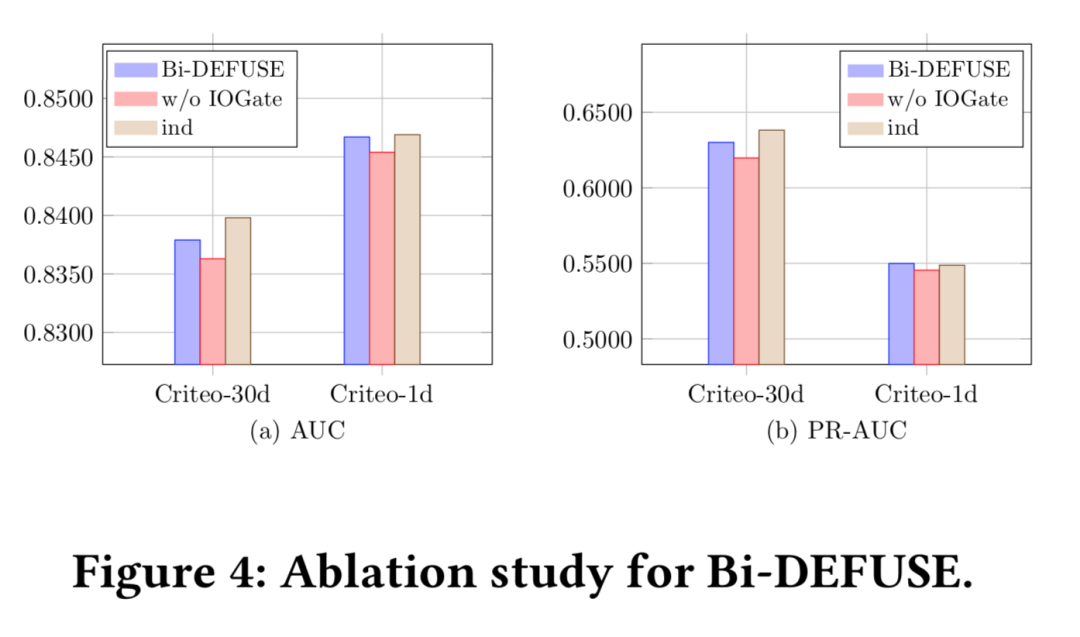
从图4中可以得出:
-
Bi-DEFUSE总是优于,验证了MMoE结构相对MLP的有效性
-
在Criteo-1d上,Bi-DEFUSE仍然取得了接近效果上限的表现,可见较小的归因周期一方面让IP样本的占比相对更高,更容易发挥Bi-DEFUSE的优势,另一方面也限制了IP与DP样本的差异程度,更有利于使用网络共享的MMoE结构进行联合训练
-
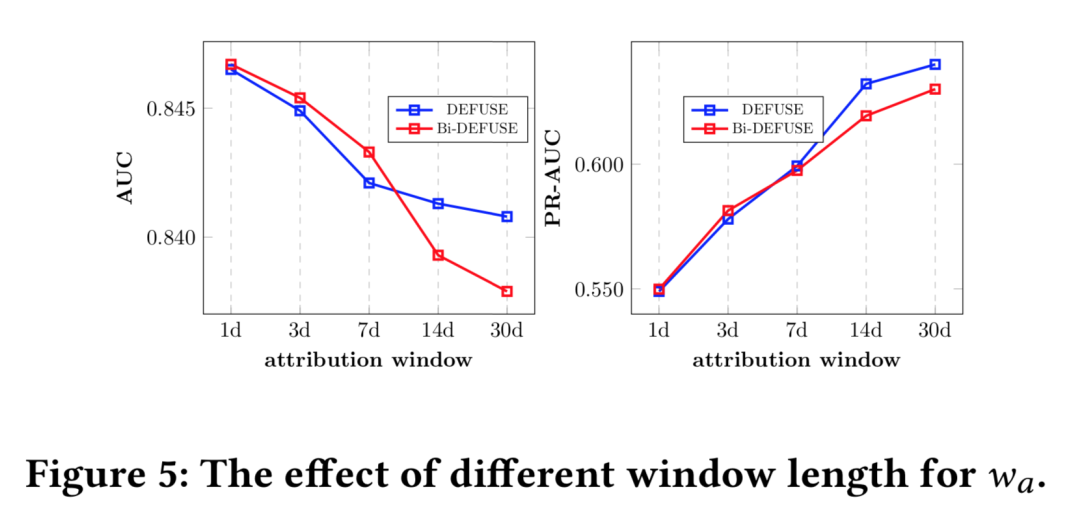
DEFUSE/Bi-DEFUSE在不同下的表现
鉴于表5中DEFUSE与Bi-DEFUSE在不同归因周期上的表现差异,我们基于Criteo数据,取,进行了更详细的DEFUSE.v.Bi-DEFUSE归因周期实验。图5结果显示,使用更小的归因周期()时,Bi-DEFUSE在AUC、PR-AUC表现上稳定优于DEFUSE,再一次验证了归因周期较小时,IP样本的重要性与Bi-DEFUSE设计思路的合理性。
4.6 Bi-DEFUSE在线效果
考虑到直通车目前使用的归因周期,我们选用Bi-DEFUSE方案作为上线版本,于2021双11前上线,取得了cvr+2%、roi+0.8%、rpm微正的显著效果。
5 总结
本文中我们提出了一种基于实时&回补样本流的CVR无偏估计建模方法DEFUSE,通过对样本的分类以及重要性采样推导和应用的优化,同时基于DEFUSE思路及CVR场景特点,针对归因周期较小的场景提出了进一步优化的Bi-DEFUSE方案。详尽的离线实验充分验证了DEFUSE、Bi-DEFUSE设计思路的合理性,取得了相对业界主流方案的稳定收益,并在阿里妈妈搜索广告主场景取得了显著的在线效果。
6 参考文献
[1]Olivier Chapelle. 2014. Modeling delayed feedback in display advertising
[2]Yuya Yoshikawa and Yusaku Imai. 2018. A Nonparametric Delayed Feed-back Model for Conversion Rate Prediction
[3]Sofia Ira Ktena, Alykhan Tejani, Lucas Theis, Pranay Kumar Myana, DeepakDilipkumar, Ferenc Huszár, Steven Yoo, and Wenzhe Shi. 2019. Addressing delayed feedback for continuous training with neural networks in CTR prediction
[4]Siyu Gu, Xiang-Rong Sheng, Ying Fan, Guorui Zhou, and Xiaoqiang Zhu. 2021.Real Negatives Matter: Continuous Training with Real Negatives for DelayedFeedback Modeling
[5]Jia-Qi Yang, Xiang Li, Shuguang Han, Tao Zhuang, De-Chuan Zhan, Xiaoyi Zeng,and Bin Tong. 2021. Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling
[6]Kuang-chih Lee, Burkay Orten, Ali Dasdan, and Wentong Li. 2012. Estimating conversion rate in display advertising from past erformance data
[7]Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018.Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
[8]Junwei Pan, Yizhi Mao, Alfonso Lobos Ruiz, Yu Sun, and Aaron Flores. 2019.Predicting Different Types of Conversions with Multi-Task Learning in OnlineAdvertising
[9]Zhuojian Xiao, Yunjiang Jiang, Guoyu Tang, Lin Liu, Sulong Xu, Yun Xiao, andWeipeng Yan. 2021. Adversarial Mixture Of Experts with Category Hierarchy Soft Constraint
END

也许你还想看
丨
CIKM 2021 | AutoHERI: 基于层次表示自动聚合的 CVR 预估模型
丨
KDD 2021 | 一种使用真负样本的在线延迟反馈建模
疯狂暗示↓↓↓↓↓↓↓