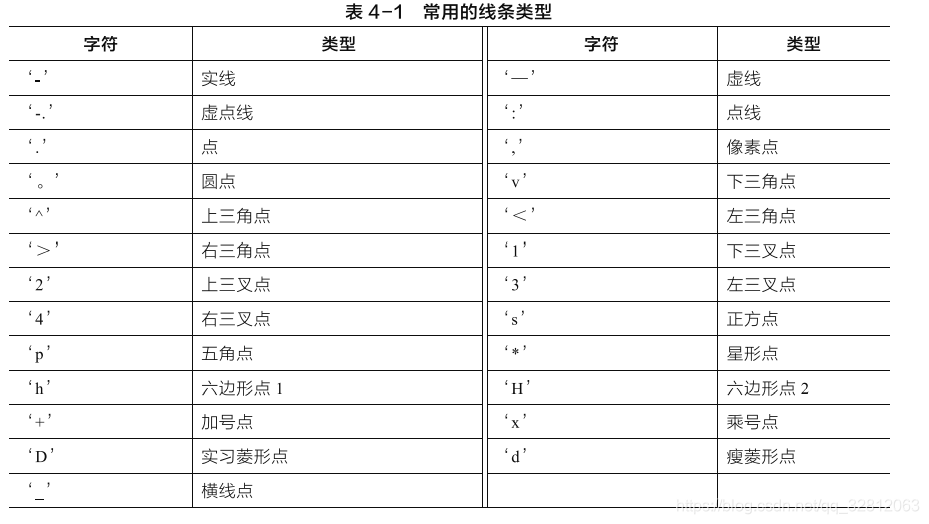
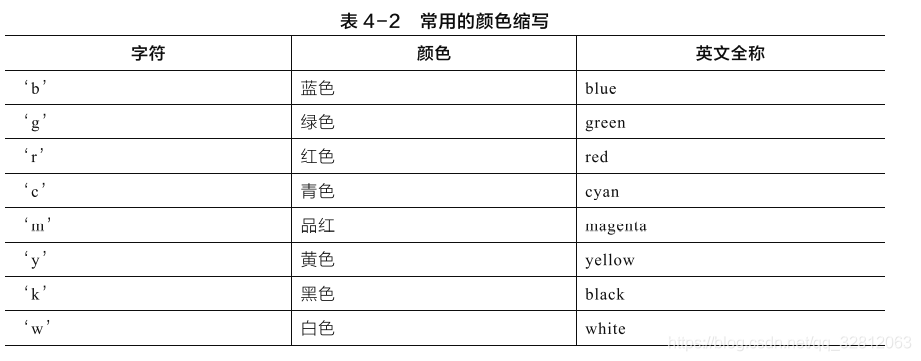
笔记终是笔记,记录使用频率高的函数
法宝:
import numpy as np
print(help(np.array))
numpy
import numpy as np
arr1 = np.array([1, 2, 3, 4]) #创建一维数组
print(' 创建的数组为: ',arr1)
# 创建二维数组
arr2 = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, 10]])
print('创建的数组为:\n',arr2)
print('数组类型为:',arr2.dtype) #查看数组类型
print('数组元素个数为:',arr2.size) #查看数组元素个数
print('数组每个元素大小为:',arr2.itemsize) #查看数组每个元素大小
arr2.shape = 4,3 #重新设置shape
print('重新设置shape 后的arr2 为:',arr2)
# 类型字段名可以用于存取实际的 age 列
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a['age'])
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
print('使用arange函数创建的数组为:\n',np.arange(0,1,0.1))
print('使用linspace函数创建的数组为:\n',np.linspace(0, 1, 12))#等差数列
print('使用logspace函数创建的数组为:\n',np.logspace(0, 2, 20))#等比数列
print('使用zeros函数创建的数组为:\n',np.zeros((2,3)))
print('使用eye函数创建的数组为:\n',np.eye(3))
print('使用ones函数的数组为:\n',np.ones((5,3)))
#冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
# 一维数组的索引
arr = np.arange(10)
print('数据为:',arr)
#用整数作为下标可以获取数组中的某个元素
print('索引结果为:',arr[5])
#用范围作为下标获取数组的一个切片,包括arr[3]不包括arr[5]
print('索引结果为:',arr[3:5])
#省略开始下标,表示从arr[0]开始
print('索引结果为:',arr[:5])
#下标可以使用负数,-1表示从数组后往前数的第一个元素
print('索引结果为:',arr[-1])
#下标还可以用来修改元素的值
arr[2:4] = 100,101
print('索引结果为:',arr)
#范围中的第三个参数表示步长,2表示隔一个元素取一个元素
print('索引结果为:',arr[1:-1:2])
#步长为负数时,开始下标必须大于结束下标
print('索引结果为:',arr[5:1:-2])
# 二维数组的索引
arr = np.array([[1, 2, 3, 4, 5],[4, 5, 6, 7, 8], [7, 8, 9, 10, 11]])
print('创建的二维数组为:\n',arr)
#索引第0行中第3和第4列的元素
print('索引结果为:\n',arr[0,3:5])
#索引第2和第3行中第3列、第4列和第5列的元素
print('索引结果为:\n',arr[1:,2:])
#索引第2列的元素
print('索引结果为:\n',arr[:,2])
# 二维数组的排序
arr = np.random.randint(1,10,size = (3,3)) #生成3行3列的随机数
print('创建的数组为:\n',arr)
arr.sort(axis = 1) #沿着横轴排序
print('排序后数组为:\n',arr)
arr.sort(axis = 0) #沿着纵轴排序
print('排序后数组为:\n',arr)
arr = np.array([2,3,6,8,0,7])
print('创建的数组为:',arr)
print('排序后数组为:',arr.argsort()) #返回值为重新排序值的下标
arr = np.arange(20).reshape(4,5)
print('创建的数组为:\n',arr)
print('数组的和为:',np.sum(arr)) #计算数组的和
print('数组横轴的和为:',arr.sum(axis = 0)) #沿着横轴计算求和
print('数组纵轴的和为:',arr.sum(axis = 1)) #沿着纵轴计算求和
print('数组的均值为:',np.mean(arr)) #计算数组均值
print('数组横轴的均值为:',arr.mean(axis = 0)) #沿着横轴计算数组均值
print('数组纵轴的均值为:',arr.mean(axis = 1)) #沿着纵轴计算数组均值
print('数组的标准差为:',np.std(arr)) #计算数组标准差
print('数组的方差为:',np.var(arr)) #计算数组方差
print('数组的最小值为:',np.min(arr)) #计算数组最小值
print('数组的最大值为:',np.max(arr)) #计算数组最大值
print('数组的最小元素为:',np.argmin(arr)) #返回数组最小元素的索引
print('数组的最大元素为:',np.argmax(arr)) #返回数组最大元素的索引
a = np.arange(9, dtype = np.float_).reshape(3,3)
print ('第一个数组:')
print (a)
print ('\n')
print ('第二个数组:')
b = np.array([10,10,10])
print (b)
print ('\n')
print ('两个数组相加:')
print (np.add(a,b))
print ('\n')
print ('两个数组相减:')
print (np.subtract(a,b))
print ('\n')
print ('两个数组相乘:')
print (np.multiply(a,b))
print ('\n')
print ('两个数组相除:')
print (np.divide(a,b))
a = np.array([[3,7],[9,1]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 sort() 函数:')
print (np.sort(a))
print ('\n')
print ('按列排序:')
print (np.sort(a, axis = 0))
print ('\n')
# 在 sort 函数中排序字段
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
print ('我们的数组是:')
print (a)
print ('\n')
print ('按 name 排序:')
print (np.sort(a, order = 'name'))
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
c = a[1:3,[1,2]]
d = a[...,1:]
print(b)
print(c)
print(d)
x=np.arange(32).reshape((8,4))
print (x)
print (x[[4,2,1,7]])
a = np.arange(6).reshape(2,3)
print ('原始数组是:')
print (a)
print ('\n')
print ('迭代输出元素:')
for x in np.nditer(a):
print (x, end=", " )
print ('\n')
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('原始数组的转置是:')
b = a.T
print (b)
print ('\n')
print ('以 C 风格顺序排序:')
c = b.copy(order='C')
print (c)
for x in np.nditer(c):
print (x, end=", " )
print ('\n')
print ('以 F 风格顺序排序:')
c = b.copy(order='F')
print (c)
for x in np.nditer(c):
print (x, end=", " )
#通过指定不同的axis,numpy会沿着不同的方向进行操作,如果不设置,则表示对所有的元素进行操作,如果axis=0,则沿着纵轴进行操作,若axis=1则沿着横轴进行操作。但是这只是仅仅对于二维数组而言。但是可以总结为一句话:设axis=i ,则numpy沿着第i个下标变化的方向进行操作
arr=np.arange(16).reshape(2,4,2)
print (arr)
print (arr.sum(axis=0))
'''
axis=0,首先来看一下,arr的0轴在哪里,arr的shape为(2,4,2),arr的shape下标为(0,1,2),则axis=0对应于数组shape下标的的第一个位置。那么第一个位置的变化方向有几个呢,就要看shape下标对应的数值了,为2,那我们列举这两个变化的方向
000->100 , 001->101
010->110 , 011->111
020->120 , 021->121
030->130 , 031->131
000->010->020->030 # axis=1的变化方向
001->011->021->031
100->110->120->130
101->111->121->131
'''
print (arr.sum(axis=1))
pandas
'''
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
Series的创建
pd.Series(list,index=[ ]),第二个参数是Series中数据的索引,可以省略。
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
DataFrame的创建
pd.DataFrame(data,columns = [ ],index = [ ]):columns和index为指定的列、行索引,并按照顺序排列。
创建DataFrame最常用的是直接传入一个由等长列表或NumPy数组组成的字典,会自动加上行索引,字典的键会被当做列索引:
'''
import numpy as np, pandas as pd
arr1 = np.arange(10)
s1 = pd.Series(arr1)
print(s1) #由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引
#三种创建DataFrame方式
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
df= pd.DataFrame(data)
print(df)
df2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],index=['one', 'two', 'three', 'four', 'five', 'six'])
print(df2)
pop = {'Nevada': {2001: 2.4, 2002: 2.9},'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
df3 = pd.DataFrame(pop)
print(df3)
################
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
df2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
print(df2.columns)
#通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series。
print(df2['state']) #或者df2.state
#列可以通过赋值的方式进行修改。例如,我们可以给那个空的"debt"列赋上一个标量值或一组值
df2['debt'] = 16.5
print(df2)
#将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
df2['debt'] = val
print(df2)
#为不存在的列赋值,会创建出一个新列
df2['eastern'] = df2.state == 'Ohio'
print(df2)
#关键字del用于删除列
del df2['eastern']
print(df2.columns)
数据索引:Series和DataFrame的索引是Index类型,Index对象是不可修改,可通过索引值或索引标签获取目标数据,也可通过索引使序列或数据框的计算、操作实现自动化对齐。索引类型index的常用方法:
.append(idx):连接另一个Index对象,产生新的Index对象
.diff(idx):计算差集,产生新的Index对象
.intersection(idx):计算交集
.union(idx):计算并集
.delete(loc):删除loc位置处的元素
.insert(loc,e):在loc位置增加一个元素
重新索引:能够改变、重排Series和DataFrame索引,会创建一个新对象,如果某个索引值当前不存在,就引入缺失值。
df.reindex(index, columns ,fill_value, method, limit, copy ):index/columns为新的行列自定义索引;fill_value为用于填充缺失位置的值;method为填充方法,ffill当前值向前填充,bfill向后填充;limit为最大填充量;copy 默认True,生成新的对象,False时,新旧相等不复制
删除指定索引:默认返回的是一个新对象。
.drop():能够删除Series和DataFrame指定行或列索引。
删除一行或者一列时,用单引号指定索引,删除多行时用列表指定索引。
如果删除的是列索引,需要增加axis=1或axis=’columns’作为参数。
增加inplace=True作为参数,可以就地修改对象,不会返回新的对象。
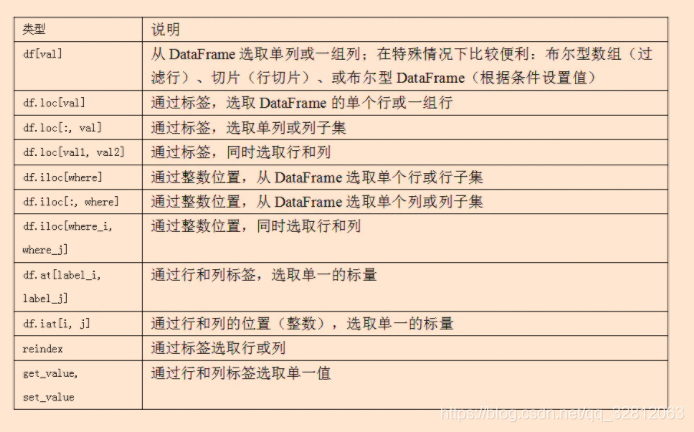
索引、选取和过滤
df.loc[行标签,列标签]:通过标签查询指定的数据,第一个值为行标签,第二值为列标签。当第二个参数为空时,查询的是单个或多个行的所有列。如果查询多个行、列的话,则两个参数用列表表示。
df.iloc[行位置,列位置]:通过默认生成的数字索引查询指定的数据。
适用于Series和DataFrame的基本统计分析函数:传入axis=’columns’或axis=1将会按行进行运算。
.describe():针对各列的多个统计汇总,用统计学指标快速描述数据的概要。
.sum():计算各列数据的和
.count():非NaN值的数量
.mean( )/.median():计算数据的算术平均值、算术中位数
.var()/.std():计算数据的方差、标准差
.corr()/.cov():计算相关系数矩阵、协方差矩阵,是通过参数对计算出来的。Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵。
.corrwith():利用DataFrame的corrwith方法,可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算),传入一个DataFrame则会计算按列名配对的相关系数。
.min()/.max():计算数据的最小值、最大值
.diff():计算一阶差分,对时间序列很有效
.mode():计算众数,返回频数最高的那(几)个
.mean():计算均值
.quantile():计算分位数(0到1)
.isin():用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集
适用于Series的基本统计分析函数,DataFrame[列名]返回的是一个Series类型。
.unique():返回一个Series中的唯一值组成的数组。
.value_counts():计算一个Series中各值出现的频率。
.argmin()/.argmax():计算数据最大值、最小值所在位置的索引位置(自动索引)
.idxmin()/.idxmax():计算数据最大值、最小值所在位置的索引(自定义索引)
*在许多数据分析工作中,缺失数据是经常发生的。对于数值数据,pandas使用浮点值NaN(np.nan)表示缺失数据,也可将缺失值表示为NA(Python内置的None值)。
.info():查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型。
.isnull():返回一个同样长度的值为布尔型的对象(Series或DataFrame),表示哪些值是缺失的,.notnull()为其否定形式。
.dropna():删除缺失数据。对于Series对象,dropna返回一个仅含非空数据和索引值的Series。对于DataFrame对象,dropna默认删除含有缺失值的行;如果想删除含有缺失值的列,需传入axis = 1作为参数;如果想删除全部为缺失值的行或者列,需传入how=’all’作为参数;如果想留下一部分缺失数据,需传入thresh = n作为参数,表示每行至少n个非NA值。
.fillna(value,method,limit,inplace):填充缺失值。value为用于填充的值(比如0、’a’等)或者是字典(比如{‘列’:1,‘列’:8,……}为指定列的缺失数据填充值);method默认值为ffill,向前填充,bfill为向后填充;limit为向前或者向后填充的最大填充量。inplace默认会返回新对象,修改为inplace=True可以对现有对象进行就地修改。
数据转换
替换值
.replace(old, new):用新的数据替换老的数据,如果希望一次性替换多个值,old和new可以是列表。默认会返回一个新的对象,传入inplace=True可以对现有对象进行就地修改。
删除重复数据
.duplicated():判断各行是否是重复行(前面出现过的行),返回一个布尔型Series。
.drop_duplicates():删除重复行,返回删除后的DataFrame对象。默认保留的是第一个出现的行,传入keep=’last’作为参数后,则保留最后一个出现的行。
两者都默认会对全部列做判断,在传入列索引组成的列表[ ‘列1’ , ‘列2’ , ……]作为参数后,可以只对这些列进行重复项判断。
利用函数或字典进行数据转换
Series.map():接受一个函数或字典作为参数。使用map方法是一种实现元素级转换以及其他数据清理工作的便捷方式。*
DataFrame常见函数
df.head():查询数据的前五行
df.tail():查询数据的末尾5行
pandas.cut()
pandas.qcut() 基于分位数的离散化函数。基于秩或基于样本分位数将变量离散化为等大小桶。
pandas.date_range() 返回一个时间索引
df.apply() 沿相应轴应用函数
Series.value_counts() 返回不同数据的计数值
df.aggregate()
df.reset_index() 重新设置index,参数drop = True时会丢弃原来的索引,设置新的从0开始的索引。常与groupby()一起用

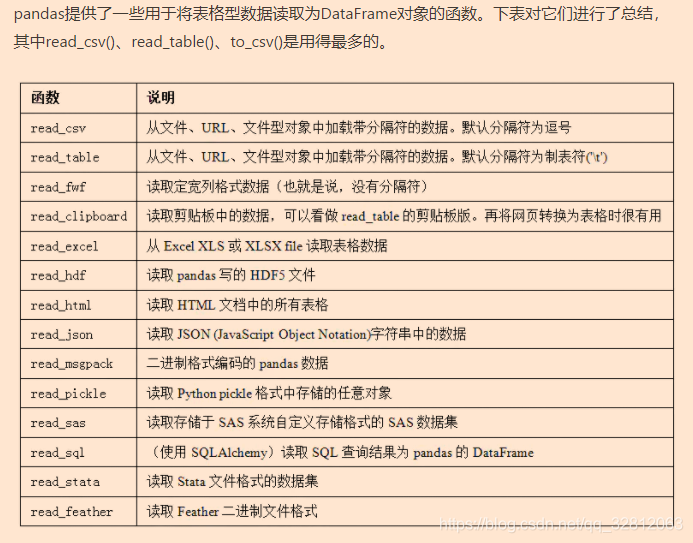
matplotlib
import matplotlib.pyplot as plt
import numpy as np
'''
设置刻度范围
plt.xlim(), plt.ylim()
ax.set_xlim(), ax.set_ylim()
设置显示的刻度
plt.xticks(), plt.yticks()
ax.set_xticks(), ax.set_yticks()
设置刻度标签
ax.set_xticklabels(), ax.set_yticklabels()
设置坐标轴标签
ax.set_xlabel(), ax.set_ylabel()
设置标题
ax.set_title()
图例
ax.plot(label=‘legend’)
ax.legend(), plt.legend()
通过loc指定图例的位置,默认右上角
loc=‘best’:自动选择放置图例最佳位置
'''
# 计算正弦和余弦曲线上的点的 x 和 y 坐标
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# 建立 subplot 网格,高为 2,宽为 1
# 激活第一个 subplot
plt.subplot(2, 1, 1)
# 绘制第一个图像
plt.plot(x, y_sin)
plt.title('Sine')
# 将第二个 subplot 激活,并绘制第二个图像
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# 展示图像
plt.show()
x = np.arange(1,11)
y = 2 * x + 5
plt.title("Matplotlib demo")
plt.xlabel("x axis caption")
plt.ylabel("y axis caption")
plt.plot(x,y,"ob")
plt.show()
#折线图
x = np.arange(24)
y = [np.random.uniform(0,60) for i in x]
plt.figure(figsize=(5,3),dpi=100)
## figure指的是画的图
## 通过实例化一个figure并且传递参数,能够在后台自动使用该figure实例
## 在图像模糊的时候可以传入dpi参数,让图片更清晰
plt.plot(x,y)
plt.show()
#柱状图
x = [5,8,10]
y = [12,16,6]
x2 = [6,9,11]
y2 = [6,15,7]
plt.bar(x, y, align = 'center')
plt.bar(x2, y2, color = 'g', align = 'center')
plt.title('Bar graph')
plt.ylabel('Y axis')
plt.xlabel('X axis')
plt.show()
#散点图
np.random.seed(19)
x = np.arange(0.0, 50.0, 2.0)
y = x ** 1.3 + np.random.rand(*x.shape) * 30.0
s = np.random.rand(*x.shape) * 400 + 100
plt.scatter(x, y, s, c="g", alpha=0.5, marker=r'$\clubsuit$',label="Luck")
plt.xlabel("Leprechauns")
plt.ylabel("Gold")
plt.legend(loc='upper left')
plt.show()
中文显示问题
from matplotlib import pyplot as plt
import random
from matplotlib import font_manager
# 设置中文显示,fname表示字体的路径。
# 在需要显示中文的地方加上fontproperties = my_font
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")
y = [random.randint(20,35) for i in range(120)]
x = range(0, 120)
fig = plt.figure(figsize=(20,8),dpi=80)
_x = list(x)
_xtick_labels = ["10点{}分".format(i) for i in range(60) ]
_xtick_labels += ["11点{}分".format(i) for i in range(60)]
# 让列表x中的数据和_xtick_labels上的数据都传入,最终会在x轴上一一对应显示
# 两组数据的长度必须一样,否则不能完全覆盖整个轴
# [::5]使用列表切片,每隔5个选一个数据进行展示
# rotation=45表示旋转45°,这样字符串之间不会覆盖 ,fontproperties = my_font
plt.xticks(_x[::5], _xtick_labels[::5],rotation = 45 ,fontproperties = my_font)
plt.xlabel("时间" ,fontproperties = my_font)
plt.ylabel("温度(ºC)" ,fontproperties = my_font)
plt.title("10点到12点每分钟温度的变化情况" ,fontproperties = my_font)
plt.plot(x,y)
plt.show()