QNX Neutrino 微内核
微内核实现了POSIX特性,连同基本的QNX中微子消息传递服务,用于嵌入式realtime 操作系统。
在procnto微内核中(file and device I/O, for example)没有被实现的POSIX特性,是由可选进程和共享库提供的。
Note:要确定系统上内核的发布版本,请使用uname -a命令
从QNX软件系统的后续微内核已经看到了实现给定内核调用所需的代码的减少。内核代码中最低层的对象定义已经变得更加具体,从而允许更大程度的代码重用(例如将各种形式的POSIX信号、实时信号和QNX中微子脉冲折叠成通用的数据结构和操纵这些结构的代码)。在底层,微内核包含一些基本对象和高度调优的例程来操作它们。操作系统就是在这个基础上构建的。
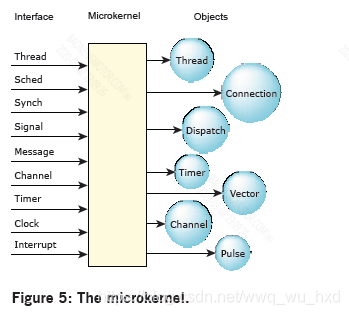
一些开发人员认为,由于大小或性能的原因,我们的微内核完全是用汇编代码实现的。事实上,我们的实现主要是用C语言编写的;大小和性能目标是通过不断改进的算法和数据结构实现的,而不是通过汇编级代码优化实现的。从历史上看,QNX软件系统操作系统的应用压力来自计算范围的两端,从内存有限的嵌入式系统一直到拥有千兆物理内存的高端SMP(对称多处理)机器。因此,QNX中微子的设计目标同时满足了这两种看似排他的功能。追求这些目标的目的是将系统的范围扩展到远远超出其他操作系统实现所能解决的范围。
The implementation of the QNX Neutrino RTOS
从历史上看,QNX软件系统操作系统的“应用压力”来自计算频谱的两端——从内存有限的嵌入式系统一直到拥有千兆物理内存的高端SMP(对称多处理)机器。而QNX中微子的设计目标同时满足了这两种看似排他的功能。追求这些目标的目的是将系统的范围扩展到远远超出其他操作系统实现所能解决的范围。
POSIX realtime and thread extensions
由于QNX中微子RTOS直接在微内核中实现了大部分的实时和线程服务,所以即使没有额外的OS模块,这些服务也是可用的。
此外,POSIX定义的一些配置文件表明,这些服务的出现并不一定需要流程模型。为了适应这一点,OS提供了对线程的直接支持,但是依赖于进程管理器来将这一功能扩展到包含多个线程的进程。
注意,许多实时执行程序和内核只提供不受内存保护的线程模型,根本不提供进程模型和/或受保护的内存模型。没有进程模型,就没有完整遵从POSIX。
System services
微内核由内核调用来支持以下内容:
* threads
* message-passing
* signals
* clocks
* timers
* interrupt handlers
* semaphores
* mutual exclusion locks(mutexes)
* condition variables(condvars)
* barriers
整个操作系统都是建立在这些调用之上的。操作系统是完全可抢占的,甚至在进程之间传递消息时也可以被抢占; 被抢占之后,消息传递从它被停止的地方恢复。微内核的最小复杂性有助于在通过内核的最长的不可抢占代码路径上设置一个上限,而较小的代码大小使得解决复杂的多处理器问题成为一个可处理的问题。服务是选择性包含到微内核中,这是基于服务具有较短的执行路径。需要大量工作的操作(例如,进程加载)被分配给外部进程/线程,与线程内部为服务请求所做的工作相比,进入该线程上下文的工作是微不足道的。严格应用这一规则来划分内核和外部进程之间的功能,打破了微内核操作系统必须比单内核操作系统产生更高的运行时开销的神话。给定上下文切换之间所做的工作(隐含在消息传递中),以及简化内核所导致的非常快的上下文切换时间,执行上下文切换所花费的时间变成了为服务请求所做的工作的“噪音”,这些请求是由组成操作系统的进程之间通过消息传递进行通信的。
下图显示了非smp内核(x86实现)的抢占细节。
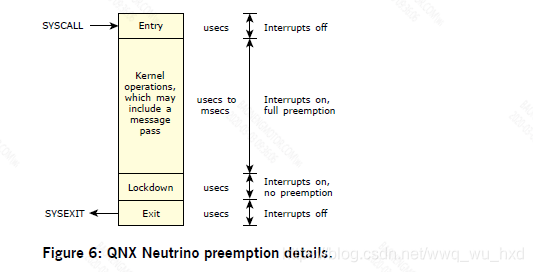
中断被禁用,或者抢占被延迟,时间间隔非常短(通常为几百纳秒)。
Threads and processes
在构建应用程序(实时、嵌入式、图形化或其他)时,开发人员可能希望应用程序中有多个算法并发执行。这种并发性是通过使用POSIX线程模型实现的,该模型将一个进程定义为包含一个或多个执行线程。
可以将线程视为最小的“执行单元”,即微内核中的调度和执行单元。另一方面,可以将进程看作线程的“容器”,定义线程将在其中执行的“地址空间”。一个进程总是至少包含一个线程。
根据应用程序的性质,线程可能独立执行,不需要在算法之间通信(不太可能),或者它们可能需要紧密耦合,使用高带宽通信和紧密同步。为了协助这种通信和同步,QNX中微子RTOS提供了丰富的IPC和同步服务。
下面的pthread_* (POSIX线程)库调用不涉及任何微内核线程调用:
* pthread_attr_destroy()
* pthread_attr_getdetachstate()
* pthread_attr_getinheritsched()
* pthread_attr_getschedparam()
* pthread_attr_getschedpolicy()
* pthread_attr_getscope()
* pthread_attr_getstackaddr()
* pthread_attr_getstacksize()
* pthread_attr_init()
* pthread_attr_setdetachstate()
* pthread_attr_setinheritsched()
* pthread_attr_setschedparam()
* pthread_attr_setschedpolicy()
* pthread_attr_setscope()
* pthread_attr_setstackaddr()
* pthread_attr_setstacksize()
* pthread_cleanup_pop()
* pthread_cleanup_push()
* pthread_equal()
* pthread_getspecific()
* pthread_setspecific()
* pthread_key_create()
* pthread_key_delete()
* pthread_self()
下表列出了相应微内核线程调用的POSIX线程调用,允许您选择其中一个接口:
| POSIX call | Microkernel call | Desciption |
|--|--|--|
|pthread_create()|ThreadCreate()|创建一个新的执行线程|
|pthread_exit()|ThreadDestroy()|Destroy a thread|
|pthread_detach()|ThreadDetach()|分离一个线程,这样它就不需join|
|pthread_join()|ThreadJoin()|加入一个线程,等待它的退出状态|
|N/A|ThreadCtl()|更改线程的QNX特定于中微子的线程特征|
| pthread_mutex_init() | SyncTypeCreate() | Create a mutex |
| pthread_mutex_destroy() | SyncDestroy() | Destroy a mutex |
| pthread_mutex_lock() | SyncMutexLock() | Lock a mutex |
| pthread_mutex_trylock() | SyncMutexLock() | 有条件地锁定一个互斥锁|
| pthread_mutex_unlock() | SyncMutexUnlock() | Unlock a mutex |
| pthread_cond_init() | SyncTypeCreate() | 创建一个条件变量 |
| pthread_cond_destroy() | SyncDestroy() | 销毁一个条件变量 |
| pthread_cond_wait() | SyncCondvarWait() | 等待条件变量 |
| pthread_cond_signal() | SyncCondvarSignal() | 给条件变量发信号 |
| pthread_cond_broadcast() | SyncCondvarSignal() | 广播一个条件变量 |
| pthread_getschedparam() | SchedGet() | get调度参数和策略|
| pthread_setschedparam() | SchedSet() | Set调度参数和策略|
| pthread_sigmask() | SignalProcmask() | 检查或设置线程的信号掩码|
| pthread_kill() | SignalKill() | 向特定线程发送一个信号|
操作系统可以配置为提供线程和进程的混合(由POSIX定义的)。每个进程都是受mmu保护的,并且每个进程可能包含一个或多个共享进程地址空间的线程。您选择的环境不仅影响应用程序的并发功能,而且还影响应用程序可能使用的IPC和同步服务。
Note:尽管公共术语“IPC”指的是通信的进程,但是我们在这里使用它来描述线程之间的通信,不管它们是在同一个进程中还是在不同的进程中。
Thread attributes
虽然进程中的线程共享进程地址空间中的所有内容,但是每个线程仍然有一些“私有”数据。在某些情况下,这个私有数据在内核中受到保护(例如tid或线程ID),而其他私有数据不受保护地驻留在进程的地址空间中(例如,每个线程都有自己使用的堆栈)。一些更值得关注的线程私有资源包括:
* tid 每个线程由一个整数线程ID标识,从1开始。tid在线程的进程中是唯一的.
* Priority 每个线程都有一个优先级,这有助于确定它何时运行。线程从父线程继承其初始优先级,但根据调度策略、线程所做的显式更改或发送给
线程的消息,优先级可以更改。Note:
进程没有优先级,线程由优先级
* Name 从QNX中微子核心OS 6.3.2开始,可以为线程分配一个名称;参见QNX中微子C库参考中的pthread_getname_np()和pthread_setname_np()条目。
诸如dumper和pidin之类的实用程序支持线程名。线程名是一个QNX中微子扩展。
* Register set 每个线程都有自己的指令指针(IP)、堆栈指针(SP)和其他特定于处理器的寄存器上下文。
* Stack 每个线程在自己的堆栈上执行,存储在其进程的地址空间中。
* Signal mask 每个线程都有自己的信号掩码
* Thread local storage 线程有一个系统定义的数据区域,称为“线程本地存储”(TLS)。TLS用于存储“每个线程”的信息(如tid、pid、stack
base、errno和特定于线程的键/数据绑定)。TLS不需要由用户应用程序直接访问。线程可以将用户定义的数据与特定于线程的数据键关联。
* Cancellation handlers 当线程终止时执行的回调函数。
特定于线程的数据在pthread库中实现并存储在TLS中,它提供了一种机制,用于将进程全局整数key与每个线程唯一的数据值相关联。要使用特定于线程的数据,您首先创建一个新key,然后将一个惟一的数据值绑定到该key(每个线程)。例如,数据值可以是一个整数,也可以是一个指向动态分配的数据结构的指针。随后,该key可以返回每个线程的绑定数据值。
您可以使用以下函数来创建和操作这些数据:
| Function | Description |
|:---------|:-------------|
|pthread_key_create() | creat key |
|pthread_key_delete() | Destroy a data key |
|pthread_setspecific() | 将数据值绑定到数据键|
|pthread_getspecific() | 返回绑定到数据键的数据值 |
Thread life cycle
一个进程中的线程数量可以有很大的变化,可以动态地创建和销毁线程。线程创建(pthread_create())涉及在进程的地址空间(例如,线程堆栈)中分配和初始化必要的资源,并在地址空间中的某个函数处启动线程的执行。
线程终止(pthread_exit(), pthread_cancel())涉及停止线程和回收线程的资源。当一个线程执行时,它的状态通常可以被描述为“就绪”或“阻塞”。更具体地说,它可以是下列之一:
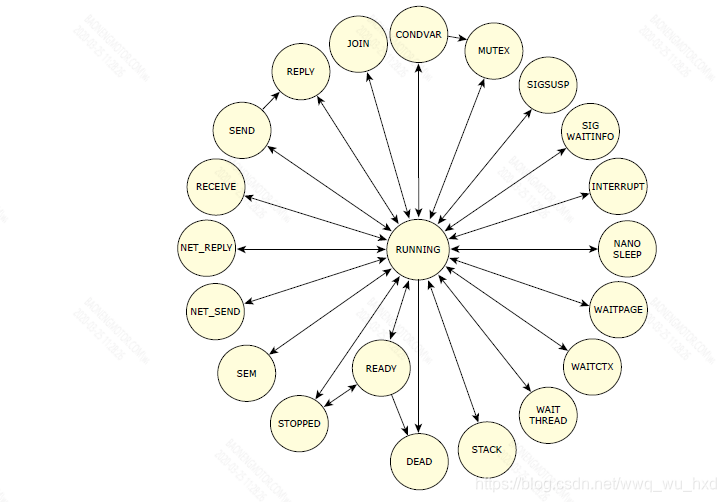
- CONDVAR :线程在一个条件变量上被阻塞(例如,它被称为pthread_cond_wait())。
- DEAD :该线程已经终止,正在等待另一个线程的join
- INTERRUPT : 线程被阻塞,等待一个中断。,它调用了InterruptWait()。
- JOIN: 线程被阻塞,等待加入另一个线程(例如,它被称为pthread_join())。
- MUTEX: 线程在互斥锁上被阻塞(例如,它被称为pthread_mutex_lock())。
- NANOSLEEP: 线程睡眠的时间间隔很短(例如,它被称为nanosleep())
- NET_REPLY: 线程正在等待通过网络传递的回复(即,它调用MsgReply*())。
- NET_SEND: 线程正在等待一个脉冲或信号通过网络传递 (即。,它被称为MsgSendPulse()、MsgDeliverEvent()或SignalKill()。
- READY: 当处理器执行另一个具有相同或更高优先级的线程时,该线程正在等待被执行.
- RECEIVE: 线程在接收消息时阻塞(例如,它调用MsgReceive())。
- REPLY: 线程在一个消息回复上被阻塞。,它调用MsgSend(),服务器接收到消息)。
- RUNNING: 线程由处理器执行。内核使用一个数组(系统中每个处理器有一个条目)来跟踪正在运行的线程。
- SEM: 线程正在等待一个信号量被发布。,它叫SyncSemWait ())。
- SEND: 线程在发送消息时被阻塞(例如,它被称为MsgSend(),但是服务器还没有收到消息)。
- SIGSUSPEND: 线程被阻塞,等待一个信号。,它被称为sigsuspend()。
- SIGWAITINFO: 线程被阻塞,等待一个信号。,它被称为sigwaitinfo()。
- STACK: 线程正在等待为线程的堆栈分配虚拟地址空间(父线程将调用ThreadCreate())。
- STOPPED: 在等待SIGCONT信号时,线程被阻塞。
- WAITCTX: 线程正在等待一个非整数(例如,浮点数)上下文可用。
- WAITPAGE: 线程正在等待为虚拟地址分配物理内存
- WAITTHREAD: 线程正在等待一个子线程完成自己的创建(即。,它叫ThreadCreate ())。
Thread scheduling
内核的部分工作是确定哪个线程在何时运行。
首先,让我们看看内核何时做出调度决策。当微内核由于内核调用、异常或硬件中断而被输入时,正在运行的线程的执行将被暂时暂停。每当任何线程的执行状态发生变化时,就会做出调度决策—不管这些线程可能驻留在哪个进程中。线程是跨所有进程全局调度的。
正常情况下,挂起线程的执行将恢复,但线程调度程序将执行上下文切换从一个线程到另一个运行线程:
- is blocked
- is preempted
-
yield
-
什么时候线程被阻塞?
正在运行的线程在等待某个事件发生时被阻塞(响应IPC请求,等待互斥锁,等等)。阻塞的线程将从正在运行的数组中移除,然后最高优先级的
就绪线程运行。当被阻塞的线程随后被解除阻塞时,它将被放置在就绪队列的末端,以达到该优先级。 -
什么时候线程被抢占?
当高优先级线程放在就绪队列上时,正在运行的线程将被抢占(由于它的condition被resolved,它将成为就绪线程)。被抢占的线程被放在该优
先级的就绪队列的开头,高优先级的线程运行。 -
什么时候线程yield?
正在运行的线程自动yields处理器(sched_yield()),并将其放置在就绪队列的末端,以获得该优先级。然后最高优先级的线程运行(可能仍然是
刚刚yielded的线程)。
-
什么时候线程被阻塞?
Scheduling priority 调度优先级
每个线程都有一个优先级。线程调度程序通过查看分配给每个准备好的线程的优先级来选择下一个要运行的线程。选择具有最高优先级的线程运行。
下图显示了五个就绪线程(B-F)的就绪队列。线程A当前正在运行。所有其他线程(G-Z)都被阻塞。线程A、B和C是最高优先级,因此它们将基于正在运行的线程的调度策略共享处理器。
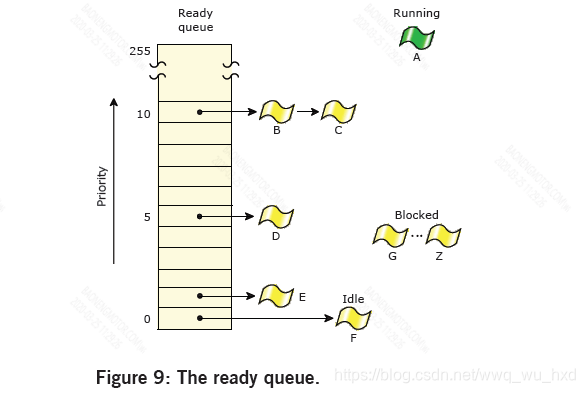
操作系统总共支持256个调度优先级。非特权线程可以将其优先级设置为1到63(最高优先级),这与调度策略无关。只有root线程(即有效uid为0的那些)或启用PROCMGR_AID_PRIORITY能力的那些(请参阅procmgr_ability())可以将优先级设置为63以上。特殊的空闲线程(在进程管理器中)具有优先级0 并且总是准备好运行。默认情况下,线程继承父线程的优先级。
可以使用procnto更改非特权进程的允许优先级范围:procnto -P priority
在QNX中微子6.6或更高版本中,如果希望超出范围的优先级请求在默认情况下达到最大允许值,而不是导致错误,则可以在此选项后附加s或S。当你设置一个优先级,你可以把它封装在一个(非posix)宏来指定如何处理超出范围的优先级请求:
* SCHED_PRIO_LIMIT_ERROR(priority) — indicate an error
* SCHED_PRIO_LIMIT_SATURATE(priority) — 设置成可用的最高优先级
注意,为了防止优先级反转,内核可能会临时提高线程的优先级。有关更多信息,请参阅本章后面的“优先级继承和互斥)”,以及“进程间通信”的“优先级继承和消息”章节。内核线程的初始优先级是255,但是它们要做的第一件事是在MsgReceive()中阻塞,所以在那之后,它们按照向它们发送消息的线程的优先级进行操作。
就绪队列上的线程按优先级排序。就绪队列实际实现为256个单独的队列,每个优先级一个。选择运行高优先级队列中的第一个线程。大多数情况下,线程在其优先级队列中按FIFO顺序排队,但也有一些例外:
-
一个来自接收端阻塞状态的服务器线程(带有来自客户机的消息)被插入到队列的最前面——也就是说,顺序是后进先出,而不是FIFO。
-
如果线程发送的消息具有“nc”(不可取消点)变量MsgSend*(),然后当服务器响应时,线程被放置在就绪队列的前面,而不是末尾。如果调度策略是循环的,则不补充线程的时间片;例如,如果线程在发送之前已经使用了一半的时间片,那么它在符合抢占条件之前仍然只剩下一半的时间片。
Scheduling policies
为了满足各种应用的需要,QNX中微子RTOS提供了这些调度算法:
* FIFO scheduling
* round-robin scheduling 循环调度策略
* sporadic scheduling 偶发调度策略
系统中的每个线程可以使用任何方法运行。这些方法在每个线程的基础上有效,而不是在一个节点上的所有线程和进程的全局基础上有效。
请记住,FIFO和循环调度策略仅在两个或多个具有相同优先级的线程准备好(即,线程之间是直接竞争的)。但是,偶发策略使用“预算”调度执行。在所有情况下,如果高优先级线程准备就绪,它会立即抢占所有低优先级线程。
在下面的图中,三个具有同等优先级的线程已经就绪。如果线程A阻塞,线程B将运行。
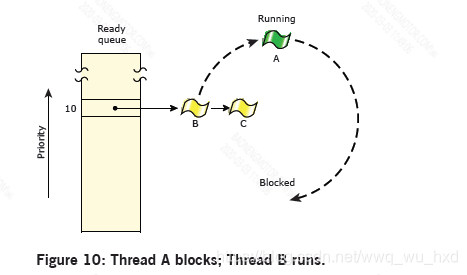
虽然线程从父进程继承调度策略,但是线程可以请求更改内核应用的算法。
FIFO scheduling
在FIFO调度中,选择运行的线程将持续执行,直到:
* 自动放弃控制权(例如,它阻塞)
* 被高优先级线程抢占

Round-robin scheduling 循环调度
在循环调度中,选择运行的线程将持续执行,直到:
- 自愿放弃控制权
- 被高优先级线程抢占
-
耗尽它的时间片
如下图所示,线程A一直运行到耗尽它的时间片;下一个准备线程(线程B)现在运行:
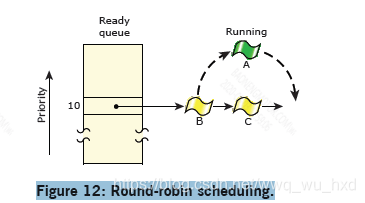
时间片是分配给每个进程的时间单位。一旦它消耗了它的时间片,一个线程就会被抢占,下一个处于相同优先级的就绪线程就会得到控制权。一个时间片是4×时钟周期。(有关更多信息,请参见条目时钟周期()在QNX中微子C库参考。)
Note:除了时间切片之外,循环调度与FIFO调度是相同的。
Sporadic scheduling 偶发调度
偶发调度策略通常用于有时间上限限制的线程。当在一个服务于周期性和非周期性事件的系统上执行速率单调分析(RMA)时,这种行为是必不可少的。
本质上,该算法允许线程为非周期事件提供服务,而不会影响系统中其他线程或进程的最后期限。与FIFO调度一样,使用偶发调度的线程将持续执行,直到阻塞或被高优先级的线程抢占。与自适应调度一样,使用偶发调度的线程的优先级会下降,但是使用偶发调度,您可以更精确地控制线程的行为。
在偶发调度下,线程的优先级可以在前台或普通优先级与后台或低优先级之间动态振荡。使用以下参数,您可以控制这种偶发移位的条件。
- Initial budget ©:允许一个线程以其正常优先级(N)执行的时间量,然后将其降低到其低优先级(L)。
- Low priority (L):线程将下降到的优先级。线程在后台以低优先级(L)执行,在前台以正常优先级(N)运行。
- Replenishment period (T):允许一个线程消耗其执行预算的时间。为了安排补货操作,POSIX实现还使用这个值作为线程准备就绪时的偏移量。
-
Max number of pending replenishments:这个值限制了可以进行的补充操作的数量,从而限制了由零星调度策略消耗的系统开销的数量。
Note:在一个配置很差的系统中,线程的执行预算可能会因为太多的阻塞而被削弱——也就是说,线程的执行预算可能会因为太多的阻塞而被削弱,它将得不到足够的补充。
正如下图所示,零星的调度策略建立一个线程的初始执行预算©,然后线程运行期间消耗和定期补充(T)。当一个线程阻塞时,执行预算被耗尽了,那它再次运行的补充被安排在,第一次运行时间点的后面一段时间(如40毫秒)。
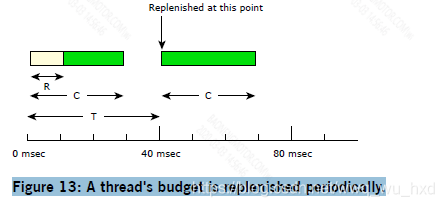
在正常优先级N时,一个线程将执行其初始执行预算c所定义的时间量。一旦该时间耗尽,线程的优先级将下降到其低优先级L,直到进行补货操作。
例如,假设一个线程从未阻塞或从未被抢占的系统:

在这里,线程将下降到它的低优先级(后台)级别,根据系统中其他线程的优先级,它可能有机会运行,也可能没有机会运行。
一旦补货发生,线程的优先级就提高到原来的水平。这保证了在一个正确配置的系统中,线程将在每个周期T中有机会运行最长的执行时间C。这保证了一个优先级为N的线程将只消耗系统资源的C/T。
当一个线程阻塞多次时,可能会启动多个补货操作,并在不同的时间进行补货。这可能意味着线程的执行预算将在一个时间段T内总计为C;但是,在此期间执行预算可能不是连续的。
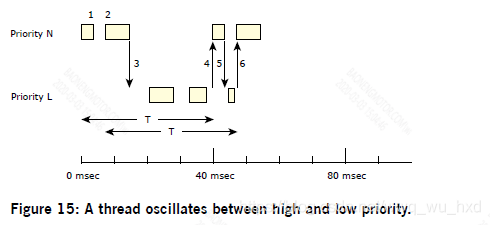
在上面的图中,线程的预算©为10 msec,在每个40 msec补货周期(T)内消耗。
//todo
Manipulating priority and scheduling policies 手动操作优先级和调度策略
IPC issues
Thread complexity issues
Synchronization services
QNX中微子RTOS提供了posix标准的线程级同步原语,其中一些原语甚至在不同进程的线程之间也很有用。同步服务至少包括以下内容:
|同步服务| 支持进程间| 支持QNX 跨局域网|
|:–|:–|:–|
| Mutexes | Yes | NO |
| Condvars | Yes | NO |
| Barriers | NO | NO |
| Sleepon locks | NO | NO |
| Reader/writer locks | Yes | NO |
| Semaphores | Yes | Yes (named only)|
| FIFO scheduling | Yes | NO |
| Send/Receive/Reply | Yes | Yes |
| Atomic operations | Yes | NO |
以上同步原语由内核直接实现,除了:
* barriers, sleepon locks, and reader/writer locks(这些建立在mutexes 和condvars之上)
* atomic operations (有些是由处理器直接实现的,有些是在内核中模拟的)
Note:应该在正常的内存映射中,分配互斥对象、控制器、屏障、读/写锁和信号量,以及计划对其进行原子操作的对象。在某些处理器上,
原子操作和调用(如pthread_mutex_lock())如果在非缓存内存中分配对象,则会导致错误。
Mutexes: mutual exclusion locks 互斥锁
互斥锁(互斥锁)是最简单的同步服务。互斥锁用于确保对线程间共享的数据的独占访问。互斥锁通常被获取(pthread_mutex_lock()或pthread_mutex_timedlock()),然后在访问共享数据的代码(通常是临界区)周围释放(pthread_mutex_unlock()。在任何给定的时间内,只有一
个线程可以锁定互斥锁。试图锁定已锁定互斥锁的线程将阻塞,直到拥有互斥锁的线程解锁它。当线程解锁互斥锁时,等待锁定互斥锁的高优先级线程将解锁并成为互斥锁的新所有者。通过这种方式,线程将按优先级顺序通过一个关键区域。在大多数处理器上,获得一个互斥锁不需要进入内核获得一个自由的互斥锁。允许这样做的是在x86处理器上使用比较和交换操作码,在大多数RISC处理器上使用加载/存储条件操作码。只有当互斥锁已经被持有,以便线程可以进入一个被阻塞的列表时,内核的入口才会在获取的时候完成;如果其他线程在互斥锁上等待被解除阻塞,则退出时完成内核条目。这使得获取和释放无争用临界区或资源变得非常快,导致操作系统的工作只是为了解决争用。非阻塞锁函数(pthread_mutex_trylock())可用于测试互斥锁当前是否处于锁定状态。为了获得最佳性能,临界段的执行时间应该很小,并且持续时间有限。如果线程可能在临界区阻塞,则应该使用condvar。
Priority inheritance and mutexes 优先级继承和互斥
默认情况下,如果一个线程的优先级高于互斥锁的所有者试图锁定一个互斥锁,那么当前所有者的有效优先级将增加到等待互斥锁的高优先级阻塞线程的有效优先级。当前所有者的有效优先级在解锁互斥锁时再次调整;它的新优先级是它自己的优先级的最大值,并且它仍然直接或间接地阻塞那些线程的优先级。该方案不仅保证了高优先级线程在等待互斥锁时被阻塞的时间尽可能短,而且解决了经典的优先级反转问题。pthread_mutexattr_init()函数将协议设置为PTHREAD_PRIO_INHERIT以允许这种行为;您可以调用pthread_mutexattr_setprotocol()来覆盖这个设置。pthr
ead_mutex_trylock()函数不会改变线程的优先级,因为它不会阻塞。
您还可以修改互斥对象的属性(使用pthread_mutexattr_settype())来允许同一个线程递归地锁定一个互斥对象。这对于允许一个线程调用一个可能试图锁定一个线程已经锁定的互斥锁的例程是很有用的。
Condvars: condition variables 条件变量
条件变量(condvar)用于阻塞临界区内的线程,直到满足某个条件为止。条件可以是任意复杂的,并且与控制无关。但是,为了实现监视器,
condvar必须始终与互斥锁一起使用。
A condvar supports three operations:
condvar支持三种操作:
* wait (pthread_cond_wait())
* signal (pthread_cond_signal())
* broadcast (pthread_cond_broadcast())
Note: condvar信号和POSIX信号之间没有关系。
以下是一个如何使用condvar的典型例子:
pthread_mutex_lock( &m );
. . .
while (!arbitrary_condition) {
pthread_cond_wait( &cv, &m );
}
. . .
pthread_mutex_unlock( &m );
在这个代码示例中,在测试条件之前获取互斥锁。这确保只有这个线程可以访问正在检查的任意条件。当条件为真时,代码样本将阻塞等待调用,直到其他线程执行一个信号或在condvar上广播。需要while循环有两个原因。首先,POSIX不能保证不会发生错误的唤醒(例如,多处理器系统)。其次,当另一个线程对条件进行了修改时,我们需要重新测试以确保修改符合我们的标准。当等待的线程被阻塞以允许另一个线程进入临界区时,pthread_cond_wait()会自动解锁关联的互斥锁。执行信号的线程将解除对condvar上排队的高优先级线程的阻塞,而广播将解除对condvar上排队的所有线程的阻塞。关联的互斥被最高优先级的未阻塞线程原子性地锁定;然后,线程必须在通过临界区之后解锁互斥锁。
condvar等待操作的一个版本允许指定超时(pthread_cond_timedwait ())。当超时过期时,等待的线程可以被解除阻塞。
Note:应用程序不应该使用带有条件变量的PTHREAD_MUTEX_RECURSIVE互斥对象,因为为pthread_cond_wait()或pthread_cond_timedwait()执行的隐
式解锁可能不会实际释放互斥对象(如果它被锁定了多次)。如果发生这种情况,则没有其他线程可以满足谓词的条件。
Barriers
barrier是一种同步机制,它允许您“捕获”几个协作的线程(例如,在一个矩阵计算中),迫使它们在一个特定的点上等待,直到所有线程都完成后,
任何一个线程才能继续。
与pthread_join()函数不同,在pthread_join()函数中,您将等待线程终止,而在出现barrier的情况下,您将等待线程在某一点会合。当指定数量
的线程到达barriers时,我们解除所有线程的阻塞,以便它们可以继续运行。
首先用pthread_barrier_init()创建一个屏障:
#include <pthread.h>
int
pthread_barrier_init (pthread_barrier_t *barrier,
const pthread_barrierattr_t *attr,
unsigned int count);
这将在传递的地址处创建一个barrier对象(指向barrier对象的指针位于barrier中),其属性由attr指定。count成员包含必须调用pthread_barrier_wait()的线程数。一旦创建了barriers,每个线程将调用pthread_barrier_wait()来表示它已经完成:
#include <pthread.h>
int pthread_barrier_wait (pthread_barrier_t *barrier);
当一个线程调用pthread_barrier_wait()时,它会阻塞,直到pthread_barrier_init()函数中最初指定的线程数调用了pthread_barrier_wait()(并且阻塞了)。当调用pthread_barrier_wait()的线程数目正确时,所有这些线程将同时解除阻塞。这里有一个例子:
/*
* barrier1.c
*/
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <time.h>
#include <pthread.h>
#include <sys/neutrino.h>
pthread_barrier_t barrier; // barrier synchronization object
void *
thread1 (void *not_used)
{
time_t now;
time (&now);
printf ("thread1 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (20);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread1() done at %s", ctime (&now));
}
void *
thread2 (void *not_used)
{
time_t now;
time (&now);
printf ("thread2 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (40);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread2() done at %s", ctime (&now));
}
int main () // ignore arguments
{
time_t now;
// create a barrier object with a count of 3
pthread_barrier_init (&barrier, NULL, 3);
// start up two threads, thread1 and thread2
pthread_create (NULL, NULL, thread1, NULL);
pthread_create (NULL, NULL, thread2, NULL);
// at this point, thread1 and thread2 are running
// now wait for completion
time (&now);
printf ("main() waiting for barrier at %s", ctime (&now));
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in main() done at %s", ctime (&now));
pthread_exit( NULL );
return (EXIT_SUCCESS);
}
主线程创建了barrier对象,并使用线程总数对其进行初始化,这些线程必须在线程继续运行之前与barrier同步。在上面的例子中,我们使用了3个计数:一个用于main()线程,一个用于thread1(),一个用于thread2()。然后启动thread1()和thread2()。为了简化这个例子,我们让线程睡眠以造成延迟,就好像计算正在发生一样。要进行同步,主线程只需在barrier上阻塞自己,因为它知道barrier只有在两个工作线程也加入之后才会解除阻塞。在这个版本中,包括了以下屏障功能:
| Function | Description |
|– |– |
| pthread_barrierattr_getpshared() | 获取barrier的进程共享属性的值|
| pthread_barrierattr_destroy() | 销毁屏障的属性对象|
| pthread_barrierattr_init() | 初始化屏障的属性对象|
| pthread_barrierattr_setpshared() | 设置barrier的进程共享属性的值|
| pthread_barrier_destroy() | Destroy a barrier|
| pthread_barrier_init() | Initialize a barrier|
| pthread_barrier_wait() | 在屏障上同步参与线程|
Sleepon locks 睡眠锁
睡眠锁与condvars非常相似,只是有一些细微的区别。与condvars一样,sleepon locks (pthread_sleepon_lock())可用于阻塞,直到条件变为true(如内存位置更改值)。但是,与必须为每个要检查的条件分配的condvar不同,sleepon locks将它们的功能多路复用到一个互斥锁上,并动态分配condvar,而不管要检查的条件的数量。condvar的最大数量最终等于阻塞线程的最大数量。这些锁是按照UNIX内核中常用的sleepon锁的模式设计的。
Reader/writer locks 读写锁
更正式的说法是“多读、单写锁”,当数据结构的访问模式由多个读数据的线程和(最多)一个写数据的线程组成时,就会使用这些锁。这些锁比互斥锁更昂贵,但是对于这种数据访问模式很有用。
这个锁允许所有请求读访问锁的线程工作(pthread_rwlock_rdlock())来成功地处理它们的请求。但是,当一个希望写的线程请求锁(pthread_rwlock_wrlock())时,该请求将被拒绝,直到所有当前读线程释放它们的读锁(pthread_rwlock_unlock())。
多个写线程可以(按优先级顺序)排队等待机会来写受保护的数据结构,所有被阻塞的写线程将在被允许再次访问读线程之前运行。不考虑读取线程的优先级。
还有一些调用(pthread_rwlock_tryrdlock()和pthread_rwlock_trywrlock())允许线程在不阻塞的情况下测试获得请求锁的尝试。这些调用返回一个成功的锁或一个状态,表明不能立即授予锁。
读写锁不是直接在内核中实现的,而是由内核提供的互斥锁和condvar服务构建的。
Semaphores 信号量
信号量是另一种常见的同步形式,它允许线程发布和等待一个信号量来控制线程何时唤醒或休眠post(sem_post())操作增加信号量;wait(sem_wait())操作使其减少。如果等待的信号量为正,则不会阻塞。等待非正信号量将阻塞,直到其他线程执行post。在等待之前发布一次或多次是有效的。这种用法将允许一个或多个线程在不阻塞的情况下执行等待。信号量和其他同步原语之间的一个重要区别是信号量是异步安全的,可以由信号处理程序操作。如果期望的效果是让信号处理程序唤醒线程,则信号量是正确的选择。
Note:
注意,通常互斥锁比信号量要快得多,信号量总是需要内核条目。信号量不会影响线程的有效优先级;如果需要优先级继承,请使用互斥锁。有关更多信息,请参阅本章前面的“互斥锁:互斥锁”。
信号量的另一个有用的特性是,它们被定义为在进程之间进行操作。虽然我们的互斥锁在进程之间工作,但是POSIX线程标准认为这是一个可选的功能,因此不能跨系统移植。对于单个进程中线程之间的同步,互斥锁将比信号量更有效。
作为一个有用的变体,还提供了一个命名信号量服务。它允许您在由网络连接的不同机器上的进程之间使用信号量。Note:注意,已命名的信号量比未命名的信号量要慢。
由于信号量,像条件变量,可以合法地返回一个非零值,导致一个错误的唤醒,所以正确的使用需要一个循环:
‘’‘C++
while (sem_wait(&s) && (errno == EINTR)) { do_nothing(); }
do_critical_region(); /* Semaphore was decremented */
‘’’
Synchronization via scheduling policy 通过调度策略的同步
通过选择POSIX FIFO调度策略,我们可以保证在非smp系统上不会有两个具有相同优先级的线程同时执行临界区。FIFO调度策略规定,系统中具有相同优先级的所有FIFO调度的线程在调度时都将运行,直到它们主动将处理器释放给另一个线程为止。当线程阻塞作为请求另一个进程的服务的一部
分时,或者当信号出现时,也可能发生此释放。因此,关键区域必须仔细编码并形成文档,以便以后的代码维护不会违反此条件。此外,该进程(或任何其他进程)中的高优先级线程仍然可以抢占这些fifo调度的线程。因此,在临界区内可能发生冲突的所有线程都必须以相同的优先级进行fifo调度。执行了这个条件之后,线程就可以随意地访问这个共享内存,而不必首先进行显式的同步调用。
Note:
这种排他性访问关系不适用于多处理器系统,因为每个CPU可以同时运行一个线程,而这个线程可以在单处理器机器上串行调度。
Synchronization via message passing 通过消息传递的同步
我们的发送/接收/应答消息传递IPC服务(稍后将介绍)通过其阻塞特性实现隐式同步。在许多情况下,这些IPC服务会使其他同步服务变得不必要。
它们也是惟一可以跨网络使用的同步和IPC原语(除了基于消息传递的命名信号量之外)。
Synchronization via atomic operations 通过原子操作的同步
在某些情况下,您可能希望执行一个简短的操作(例如增加一个变量),同时保证该操作将自动执行—即操作不会被另一个线程或ISR(中断服务例程)抢占。QNX中微子RTOS提供以下原子操作:
* adding a value
* subtracting a value
* clearing bits
* setting bits
* toggling (complementing) bits
通过包含C头文件<atom .h>,可以使用这些原子操作。虽然你可以在任何地方使用这些原子操作,但你会发现它们在这两种情况下特别有用:
* between an ISR and a thread
* between two threads (SMP or single-processor)
由于ISR可以在任何给定点抢占线程,因此线程能够保护自己的惟一方法是禁用中断。由于您应该避免在实时系统中禁用中断,所以我们建议您使用QNX中微子提供的原子操作。
在SMP系统上,多个线程可以并发运行。同样,我们会遇到与中断相同的情况——您应该在适当的地方使用原子操作来消除禁用和重新启用中断的需要。
Synchronization services implementation 同步服务的实现
下表列出了各种微内核调用和由它们构造的高级POSIX调用:
|Microkernel call | POSIX call | Description |
|:---- |:---- |:----- |
| SyncTypeCreate() | pthread_mutex_init(), pthread_cond_init(),sem_init() | Create object for mutex, condvars, and semphore
| SyncDestroy() | pthread_mutex_destroy(), pthread_cond_destroy(),sem_destroy() | Destroy synchronization object
| SyncCondvarWait() | pthread_cond_wait(), pthread_cond_timedwait() | Block on a condvar
| SyncCondvarSignal() | pthread_cond_broadcast(), pthread_cond_signal() | Wake up condvar-blocked threads
| SyncMutexLock() | pthread_mutex_lock(), pthread_mutex_trylock() | Lock a mutex
| SyncMutexUnlock() | pthread_mutex_unlock() | Unlock a mutex
| SyncSemPost() | sem_post() | Post a semaphore
| SyncSemWait() | sem_wait(), sem_trywait() | Wait on a semaphore
Clock and timer services
时钟服务用于维护一天的时间,而内核计时器调用又使用时钟服务来实现间隔计时器。
Note: QNX中微子系统的有效日期从1970年1月到至少是2038. time_t数据类型是一个无符号32位数字,它将许多应用程序的这个范围扩展到2106。内核本身使用无符号从1970年1月开始,64位数字可以计算纳秒,因此可以处理2554的日期。如果您的系统必须在2554之后运行,并且无法在现场对
系统进行升级或修改,那么您必须特别注意系统日期(请与我们联系以获得帮助)。
ClockTime()内核调用允许您获取或设置系统时钟指定一个ID (CLOCK_REALTIME),维护系统时间。一旦设置,系统时间增加一些数量的纳秒基于系统时钟的resolution。这项resolution可以查询或更改使用ClockPeriod()调用。在系统页面内,一个内存中的数据结构,有一个64位的字段(nsec),记有系统启动以来的纳秒数。nsec字段总是单调递增,通过ClockTime()或ClockAdjust()设置当前时间,不会影响到这个数值。
ClockCycles()函数返回一个自由运行的64位循环计数器的当前值。这是在每个处理器上作为短时间间隔定时的高性能机制实现的。例如,在Intelx86处理器上,使用一个操作码来读取处理器的时间戳计数器。在奔腾处理器上,这个计数器在每个时钟周期上递增。100兆赫奔腾的周期时间是
1/100,000,000秒(10纳秒)。其他CPU架构也有类似的指令。在没有在硬件中实现这样的指令的处理器上,内核将模拟这样的指令。这将提供比提供指令时更低的时间分辨率(在IBM pc兼容系统上是838.095345纳秒)
在所有情况下,SYSPAGE_ENTRY(qtime)->cycles_per_sec字段给出一秒内增加的时钟周期数()。ClockPeriod()函数允许线程将系统计时器设置为若干纳秒;操作系统内核将尽其所能,利用可用的硬件来满足请求的精度。
所选的间隔总是四舍五入到基础硬件计时器精度的整数。当然,将它设置为一个非常低的值会导致大量CPU性能被消耗在计时器中断上。
| Microkernel call | POSIX call | Description |
|---|---|---|
| ClockTime() | clock_gettime(), clock_settime() | Get or set the time of day (using a 64-bit value in nanoseconds ranging from 1970 to 2554). |
| ClockAdjust() | N/A | Apply small time adjustments to synchronize clocks. |
| ClockCycles() | N/A | Read a 64-bit free-running high-precision counter. |
| ClockPeriod() | clock_getres() | Get or set the period of the clock. |
| ClockId() | clock_getcpuclockid(),pthread_getcpuclockid() | Return an integer that’s passed to ClockTime() as a clockid_t. |
为了减少功耗,内核可以以无标记模式运行,但这有点名不副实。系统仍然有时钟滴答声,一切正常运行,除非系统是空闲的。只有当系统完全空闲时,内核才会关闭时钟滴答,而实际上,它所做的就是减慢时钟,以便下一个滴答中断刚好在下一个活动计时器触发之后发生,以便计时器立即触发。要
启用无标记操作,请为启动*代码指定- z选项。
Time correction 时间校正
为了方便应用时间校正,同时又不会让系统经历时间上的突然“步骤”(甚至让时间向后跳转),ClockAdjust()调用提供了一个选项来指定要应用时间校正的间隔。这将在指定的时间间隔内加速或延迟时间,直到系统同步到指定的当前时间为止。此服务可用于实现网络上多个节点之间的网络协调
时间平均。
Timers 定时器
QNX中微子RTOS直接提供了完整的POSIX定时器功能。由于这些计时器创建和操作起来很快,所以它们是内核中一种廉价的资源。POSIX定时器模型非常丰富,提供了一下类型定时器:
* an absolute date :绝对日期
* a relative data : 相对日期
* cyclical :循环
循环模式非常重要,因为计时器最常见的用途是作为事件的定期源,将线程“踢”入生命中进行一些处理,然后返回休眠状态,直到下一个事件发生。如果线程必须为每个事件重新编写计时器,那么就会有定时滑漏的危险,除非线程正在编写一个绝对日期。更糟糕的是,如果线程没有在计时器事件上运行,因为一个高优先级的线程正在运行,那么下一个被编程到计时器中的日期可能已经过去了!
循环模式通过要求线程设置定时器一次,然后简单地响应产生的周期性事件源来绕过这些问题。因为计时器是操作系统中事件的另一个来源,所以它们也使用它的事件传递系统。因此,当出现超时时,应用程序可以请求将任何QNX中微子支持的事件交付给应用程序。OS提供的一个经常需要的超时服务是能够指定应用程序准备等待任何给定内核调用或请求完成的最长时间。在一个抢占调度的实时操作系统中使用通用系统的定时器服务的问题在于在规定超时和服务请求之间的时间间隔内,一个高优先级的进程可能已经被安排运行并被抢占了足够长的时间,以至于在服务被请求之前,指定的超时就已经过期了。然后,应用程序将以一个已经失效的超时结束对服务的请求。这个定时窗口会导致挂起进程、数据传输协议中无法解释的延迟和其他问题。
‘’’
alarm(…);
…
… Alarm fires here
…
blocking_call();
‘’’
我们的解决方案是超时请以求原子性的形式给到服务本身。一种可行的方法是为每个可用的服务请求提供一个可选的超时参数,但这将使带有传递参数的服务请求变得过于复杂,而该参数通常不会被使用。
QNX中微子提供了一个TimerTimeout()内核调用,它允许应用程序指定一个阻塞状态列表,以便启动指定的超时。稍后,当应用程序向内核发出请求时,如果应用程序将在指定的某个状态上阻塞,内核将自动启用前面配置的超时。
由于操作系统的阻塞状态非常少,所以这种机制的工作方式非常简洁。在服务请求或超时结束时,计时器将被禁用,并将控制权交还给应用程序。
‘’’
TimerTimeout(…);
…
…
…
blocking_call();
… Timer atomically armed within kernel
‘’’
| Microkernel call | POSIX call | Description |
|---|---|---|
| TimerAlarm() | alarm() | Set a process alarm |
| TimerCreate() | timer_create() | Create an interval timer |
| TimerDestroy() | timer_delete() | Destroy an interval timer |
| TimerInfo() | timer_gettime() | Get the time remaining on an interval timer |
| TimerInfo() | timer_getoverrun() | Get the number of overruns on an interval timer |
| TimerSettime() | timer_settime() | Start an interval timer |
| TimerTimeout() | sleep(), nanosleep(), sigtimedwait(),pthread_cond_timedwait(),pthread_cond_timedwait(), | Arm a kernel timeout for any blocking state |
Interrupt handling 中断处理
无论我们多么希望它是这样,计算机并不是无限快的。在实时系统中,避免不必要地消耗CPU周期是非常重要的。最小化外部事件发生时间点到负责响应该事件的线程中代码的实际执行时间点之间的时间也是至关重要的。这一时间称为时延。
我们最关心的两种延迟是中断延迟和调度延迟。
Interrupt latency 中断时延
中断延迟是从硬件中断断言到执行设备驱动程序的中断处理程序的第一条指令的时间。操作系统几乎总是完全启用中断,因此中断延迟通常是无关紧要的。但是代码的某些关键部分确实需要暂时禁用中断。这种禁用时间的最大值通常定义了最坏情况下的中断延迟——在QNX中微子中这是非常小的
下面的图演示了一个硬件中断由一个中断处理程序处理的情况。中断处理程序要么简单地返回,要么返回并导致一个事件被交付。
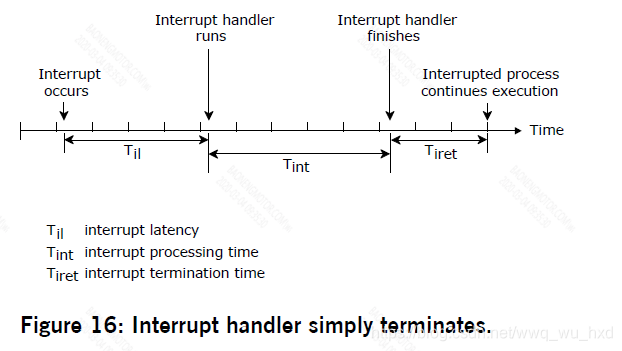
上图中的中断延迟(Til)表示最小延迟——当中断发生时,中断被完全激活时发生的延迟。最坏情况下的中断延迟将是这个时间加上操作系统(或正在运行的系统进程)禁用CPU中断的最长时间。
Scheduling latency 调度时延
在某些情况下,低级硬件中断处理程序必须调度高级线程才能运行。在此场景中,中断处理程序将返回并指示一个event需要交付,这引入了第二种形式
的延迟–调度延迟,这个也是我们必须考虑的。
调度延迟是指从用户的中断处理程序的最后一条指令到驱动线程的第一条指令执行之间的时间。这通常意味着保存当前执行线程的上下文和恢复所需驱动
线程的上下文所花费的时间。虽然比中断延迟大,但在QNX中微子系统中,这个时间也很小。
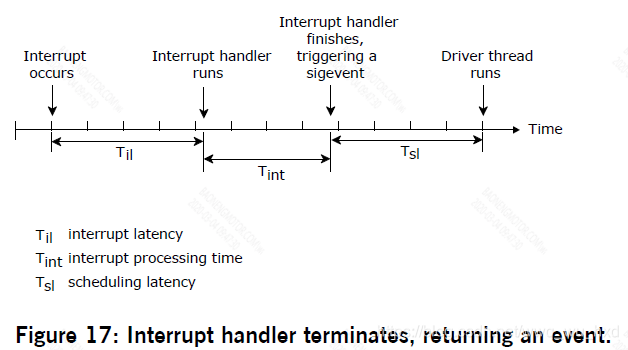
需要注意的是,大多数中断终止时,都是没有event需要被交付的。在很多情况下,中断处理程序可以处理所有与硬件相关的问题。只有在重大事件发生
时,才会交付event来唤醒更高级别的驱动程序线程。例如,串行设备驱动程序的中断处理程序将在每次接收到传输中断时向硬件提供一个字节的数据,并且仅在输出缓冲区几乎为空时才触发驱动程序(devc-ser*)内的高级线程。
Nested interrupts 嵌套中断
QNX中微子RTOS完全支持嵌套中断。前面的场景描述了最简单和最常见的情况,即只发生一个中断。对于未屏蔽中断的最坏情况下的时间考虑,必须考虑到当前正在处理的所有中断的时间,因为更高优先级的未屏蔽中断将抢占现有中断。
在下面的关系图中,线程A正在运行。中断IRQx导致中断处理程序它被IRQy和它的处理程序Inty抢占。Inty返回导致线程B运行的事件;Intx返回一个导致线程C运行的事件。
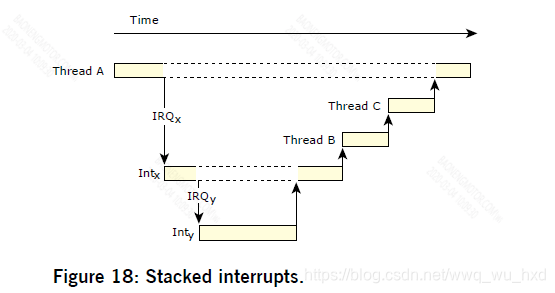
Interrupt calls 中断调用
中断处理API包括以下内核调用:
-
InterruptAttach():附加一个本地函数(一个中断)服务程序或ISR)到中断向量。
- InterruptAttachEvent():在一个中断上生成一个事件,它将准备一个线程。没有用户中断处理程序运行。它将优先调用。
- InterruptDetach():detach中断 用从上述两个调用中返回的ID做参数
- InterruptWait():等待一个中断。
- InterruptEnable():启用硬件中断。
- InterruptDisable():禁用硬件中断。
- InterruptMask():屏蔽硬件中断。
- InterruptUnmask():解除硬件中断的掩码
-
InterruptLock():保护中断处理程序和线程之间的关键代码区域。自旋锁的使用使这断代码SMP-safe,这个函数是InterruptDisable()的超集,应该
用它来代替它。 -
InterruptUnlock():在关键代码区域,去掉SMP-safe lock
使用这个API,一个具有适当特权的用户级线程可以调用InterruptAttach()或InterruptAttachEvent(),传递一个硬件中断号和在中断发生时要调用
的线程地址空间中的一个函数的地址。QNX中微子允许将多个isr附加到每个硬件中断号上——在运行中断处理程序的执行过程中,可以为未屏蔽中断提供
服务。
Note
1. 启动代码负责确保在系统初始化期间屏蔽所有中断源。当对中断向量第一次调用InterruptAttach()或InterruptAttachEvent(),
内核将解除它的掩码。类似地,当为一个中断向量执行最后一个InterruptDetach()时,内核会重新屏蔽该级别的中断。
2. 有关InterruptLock()和InterruptUnlock()的更多信息,请参阅关于多核处理的一章中的“临界区域”。
3. 在中断服务例程中使用浮点运算是不安全的。
下面的代码示例展示了如何将ISR(中断服务程序)附加到PC上的硬件计时器中断(操作系统也将其用于系统时钟)。由于内核的定时器ISR已经在处理清除中断源,这个ISR可以简单地在线程的数据空间中增加一个计数器变量,然后返回到内核:
‘’’
#include <stdio.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
struct sigevent event;
volatile unsigned counter;
const struct sigevent *handler( void *area, int id ) {
// Wake up the thread every 100th interrupt
if ( ++counter == 100 ) {
counter = 0;
return( &event );
}
else
return( NULL );
}
int main() {
int i;
int id;
// Request I/O privileges
ThreadCtl( _NTO_TCTL_IO, 0 );
// Initialize event structure
event.sigev_notify = SIGEV_INTR;
// Attach ISR vector
id=InterruptAttach( SYSPAGE_ENTRY(qtime)->intr, &handler,
NULL, 0, 0 );
for( i = 0; i < 10; ++i ) {
// Wait for ISR to wake us up
InterruptWait( 0, NULL );
printf( “100 events\n” );
}
// Disconnect the ISR handler
InterruptDetach(id);
return 0;
}
‘’’
使用此方法,可以动态附加具有适当特权的用户级线程(和分离)运行时硬件中断向量的中断处理程序。可以使用常规的源代码级调试工具对这些线程进行调试;可以在线程级调用ISR并在源代码级逐步执行它,或者使用InterruptAttachEvent()调用来调试ISR本身。
当硬件中断发生时,处理器将进入内核中的中断重定向,这段代码将保存当前线程的上下文的寄存器到适当的线程数据表中,并设置处理器上下文,以便ISR能够访问包含ISR的线程的一部分的代码和数据。这允许ISR使用缓冲区和代码在用户级线程解决中断,如果需要更高级别的工作线程,释放一个event到包含ISR的线程, 这样,它可以工作在ISR 放到线程私有的数据缓冲区的数据上。
因为它是在包含它的线程的内存映射中运行的,所以ISR可以直接操作映射到线程地址空间的设备,或者直接执行I/O指令。因此,操作硬件的设备驱动程序不需要链接到内核中。
微内核中的中断重定向代码将调用附加到该硬件中断的每个ISR。如果返回的值指示将传递某个进程某种事件,则内核将对该事件进行排队。当最后一次ISR调用该向量时,内核中断处理程序将完成对中断控制硬件的操作,然后“从中断返回”。
这个中断不一定在被中断的线程的上下文中返回。如果入队列event导致高优先级线程准备就绪,那么微内核将中断并返回到现在准备好的线程的上下文中。
这种方法提供了一个良好的边界间隔,从发生的中断到用户级别ISR的第一个指令级的执行(中断延迟),和ISR的最后一个指令到已经准备就绪的线程的第一个指令(如线程或进程调度延迟)。
最坏情况下的中断延迟是有界的,因为操作系统只对几个临界区域的几个操作码禁用中断。当中断被禁用时,这些间隔具有确定性的运行时间,因为它们不依赖于数据。
微内核的中断重定向器在调用用户的ISR之前只执行几条指令。因此,对于硬件中断或内核调用的进程抢占同样快速,并且基本上执行相同的代码路径
当ISR执行时,它有完全的硬件访问(因为它是特权线程的一部分),但是不能发出其他内核调用。ISR旨在应对硬件中断在尽可能少的微秒时间,做最少的工作来满足中断(从UART读取字节等),如果有必要,导致一个线程被安排在一些指定的优先级做进一步的工作。对于给定的硬件优先级,最坏情况下的中断延迟可以从内核强加的中断延迟直接计算出来,每个中断的最大运行时间要高于所讨论的ISR。由于可以重新分配硬件中断优先级,所以可以将系统中最重要的中断设置为最高优先级。还请注意,通过使用InterruptAttachEvent()调用,不会运行任何用户ISR。相反,在每个中断上都会生成一个用户指定的事件;该事件通常会导致调度一个等待线程来运行和执行工作。当事件生成时,中断被自动屏蔽,然后在适当的时间处理由设备的线程显式地解除屏蔽。
因此,由硬件中断生成的工作的优先级可以被执行在os调度的优先级,而不是硬件定义的优先级。由于中断源在得到服务之前不会重新中断,因此可以控制中断在临界区域执行时间硬期限的影响。
除了硬件中断之外,用户进程和线程还可以“钩住”微内核中的各种“事件”。当其中一个事件发生时,内核可以向上调用用户线程中指定的函数,从而对该事件执行一些特定的处理。例如,每当系统中的空闲线程被调用时,用户线程就可以将内核向上调用加入到线程中,这样就可以很容易地实现特定于硬件的低功耗模式。
* InterruptHookIdle():当内核没有要调度的活动线程时,它将运行空闲线程可以向上调用用户处理程序。此处理程序可以执行特定于
硬件的电源管理操作。
* InterruptHookTrace():此函数附加一个伪中断处理程序,该处理程序可以从仪器化的内核接收跟踪事件。