本文章是作者学习极客时间 分布式缓存 的笔记,不喜勿扰!
一个比较经典的数据库和缓存使用的模式
读数据时,先读缓存,缓存没有的话,在读数据库,然后取出数据后放入缓存,同时返回响应。
更新的时候,先删除缓存,在更新数据库。

数据库缓存一致的四个方案:
方案一:
通过redis的过期时间来更新缓存,mysql 数据库更新不会触发redis 更新,只有当redis的key过期后才会重新加载
这种方案的缺点:
1、数据不一致的时间较长,会造成一定的脏数据
2、完全依赖过去时间,过期时间太短缓存更新太频繁,过长容易有太长时间更新延迟。
方案二:
在方案一的基础上扩展,让key 的过期时间做兜底,在更新mysql 的同时也会更新redis,
这种方案的缺点:
如果更新mysql 成功,更新redis 失败,又会成为方案一。
方案三:
在方案二的基础上,对redis 的更新操作进行优化,增加消息队列,转为异步更新redis 数据, 将redis 的更新操作交给MQ ,队列来保证可靠性,异步更新redis.
这种方案的缺点:
1、解决不了时序的问题,如果有多个业务实例对同一条数据进行更新,数据更新的先后顺序可能会乱。
2、引入mq ,增加的系统复杂性,增加mq的维护成本。
方案四:
将mysql和redis更新放在一个事务中操作,这样能保证达到强一致性。
这种方案的缺点:
1、mysql或者redis任何一个环节出问题,都会造成数据回滚或者撤销。
2.如果网络出现超时,不仅可能会造成数据回滚或者撤销,还会有并发问题。
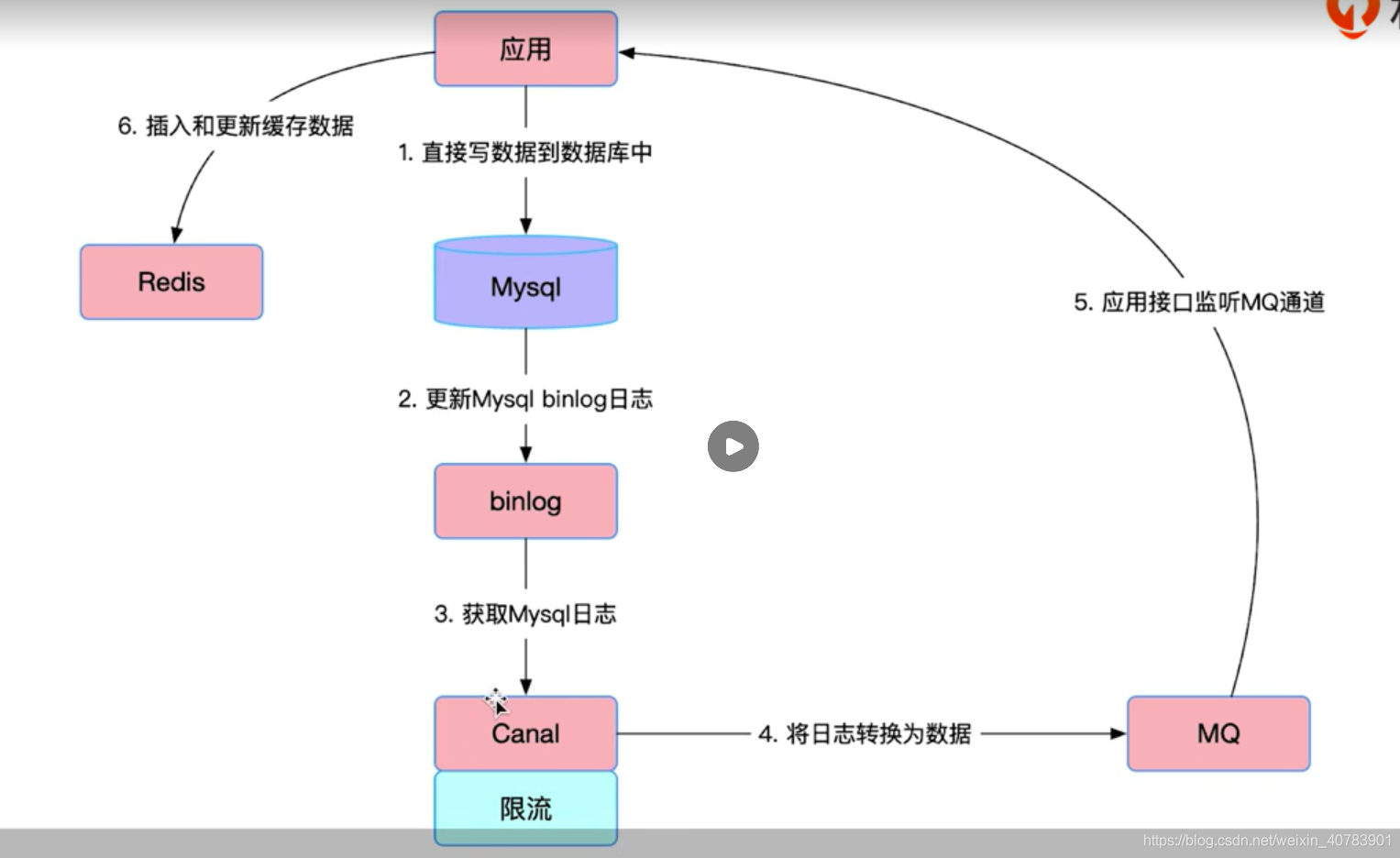
方案五:
通过订阅mysql的Binlog 日志来更新redis, 把我们搭建的mq消费服务,作为mysql的一个salve ,订阅Binlog ,解析出更新的内容,再更新redis.
这种方案的缺点:
要单独搭建一个同步服务,并且来引入BinLog同步机制,成本较大。