任务简介:
学习一个简单的BERT意图分类项目,了解BERT进行NLP任务时的流程。
任务说明(本节):
-
标签类别收集
-
训练样本读取
-
样本转化为符合BERT模型的特征
一、数据形式
使用的atis数据集已经将训练集、验证集和测试集区分好(
点击下载数据集
,提取码:
r2t0
)
- label文件保存了意图识别的标签
- seq.in文件每行保存了一句输入样本
- seq.out文件每行保存了样本的NER标签序列,以空格隔开(ner任务,不在本文内)


二、标签集:统计所有出现的意图标签
输入:
import argparse
import os
import copy
import json
import logging
import torch
from torch.utils.data import TensorDataset, RandomSampler, DataLoader
from transformers import BertConfig, BertPreTrainedModel, BertTokenizer
logger = logging.getLogger(__name__)
def vocab_process(data_dir):
'''
args:
data_dir: 数据集所在的路径;
return:
None
results:
intent的label类型(写入一个txt文件);
'''
# 标签集合输出到如下文件中
intent_label_vocab = 'intent_label.txt'
train_dir = os.path.join(data_dir, 'train')
# 收集intent标签
with open(os.path.join(train_dir, 'label'), 'r', encoding='utf-8') as f_r, open(os.path.join(data_dir, intent_label_vocab), 'w',
encoding='utf-8') as f_w:
# 提取所有出现的intent的label类型
intent_vocab = set()
for line in f_r:
line = line.strip()
intent_vocab.add(line)
# 因为训练集已经分好了,所以可能出现验证集中有而训练集中没有的label,以“UNK”来表示这种label;
# 后面读取dev集,就需要将未见过的intent标签归类为"UNK"
additional_tokens = ["UNK"]
for token in additional_tokens:
f_w.write(token + '\n')
# 将vocab以字典序排列
intent_vocab = sorted(list(intent_vocab))
for intent in intent_vocab:
f_w.write(intent + '\n')
atis_dir = "./bert_finetune_cls/data/atis/"
vocab_process(atis_dir)
输出:
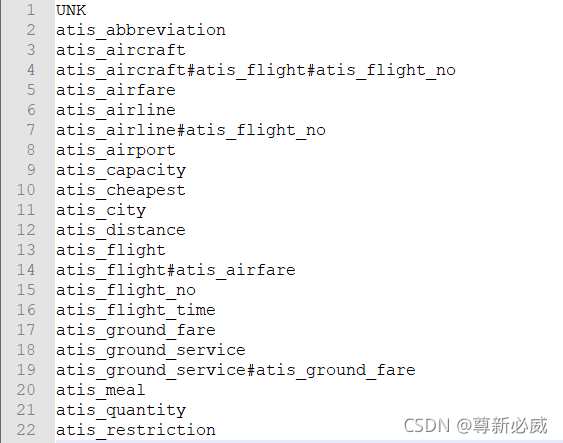
三、读取样本为样本实例
输入:
# 后面标签就分别通过简单的读取函数就可以读取出来了
def get_intent_labels(args):
return [label.strip() for label in open(os.path.join(args.data_dir, args.task, args.intent_label_file), 'r', encoding='utf-8')]
class InputExample(object):
"""
A single training/test example for simple sequence classification.
一个单独的序列分类样本实例
一个样本完全可以用一个dict来表示,但是使用 InputExample 类,作为一个python类,具有一些方便之处
Args:
guid: Unique id for the example.
words: list. The words of the sequence.
intent_label: (Optional) string. The intent label of the example.
"""
def __init__(self, guid, words, intent_label=None):
self.guid = guid # 每个样本的独特的序号
self.words = words # 样本的输入序列
self.intent_label = intent_label #样本的intent标签
def __repr__(self):
# 默认为: “类名+object at+内存地址”这样的信息表示这个实例;
# 这里重写成了想要输出的信息;
# print(input_example) 时候显示;
return str(self.to_json_string())
def to_dict(self):
"""
Serializes this instance to a Python dictionary.
实例序列化为dict
"""
# __dict__:
# 类 的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类__dict__里的
# 对象实例的__dict__中存储了一些self.xxx的一些东西
# 参见 https://www.cnblogs.com/starrysky77/p/9102344.html
output = copy.deepcopy(self.__dict__)
print('-------')
print(output)
print('-------')
return output
def to_json_string(self):
"""
Serializes this instance to a JSON string.
实例序列化为JSON字符串
"""
# 类的性质等信息dump进入json string
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
class ClsProcessor(object):
"""
Processor for the BERT classfication data set
BERT分类任务的数据集处理器
"""
def __init__(self, args):
self.args = args
# 读出我们已经整理好的意图标签;
self.intent_labels = get_intent_labels(args) # list
# 每个数据集的文件夹里面,数据格式是一致的,文件名也一致
self.input_text_file = 'seq.in'
self.intent_label_file = 'label'
# 按行读取文件
@classmethod # classmethod修饰符对应的函数不需要实例化,不需要self参数,但第一个参数需要是表示自身类的cls参数,可以来调用类的属性,类的方法,实例化对象等。
def _read_file(cls, input_file):
"""
Reads a tab separated value file.
读一个文件,以行为单位,先把每行读出来,读字段是后续的事情
"""
with open(input_file, "r", encoding="utf-8") as f:
lines = []
for line in f:
lines.append(line.strip())
return lines # list
def _create_examples(self, texts, intents, set_type):
"""
Creates examples for the training and dev sets.
创建训练集和验证集
Args:
texts: list. Sequence of unsplitted texts. 需要处理的文本组成的列表
intents: list. Sequence of intent labels. 意图label组成的列表
set_type: str. train, dev, test. 数据集类型:训练集/验证集/测试集
"""
examples = []
for i, (text, intent) in enumerate(zip(texts, intents)):
guid = "{}-{}".format(set_type, i) # 给每个样本一个编号
# 1. input_text
words = text.split() # 分词(中文不适用),后面还会再分一次,我感觉多此一举
# 2. intent
# 如果不在已知的意图类别中,则归为"UNK",intent_label为数字
intent_label = self.intent_labels.index(intent) if intent in self.intent_labels else self.intent_labels.index("UNK")
examples.append(InputExample(guid=guid, words=words, intent_label=intent_label, )) # list
return examples # list
def get_examples(self, mode):
"""
Args:
mode: train, dev, test; 区分训练/验证/测试集
"""
data_path = os.path.join(self.args.data_dir, self.args.task, mode)
print("LOOKING AT {}".format(data_path))
return self._create_examples(texts=self._read_file(os.path.join(data_path, self.input_text_file)),
intents=self._read_file(os.path.join(data_path, self.intent_label_file)),
set_type=mode) # list
# 先构建参数
# 实际使用应该是命令行传入的参数,不过我这里直接赋值传入
# parser = argparse.ArgumentParser()
# parser.add_argument("--task", default=None, required=True, type=str, help="The name of the task to train")
# parser.add_argument("--data_dir", default="./data", type=str, help="The input data dir")
# parser.add_argument("--intent_label_file", default="intent_label.txt", type=str, help="Intent Label file")
# args = parser.parse_args()
class Args():
task = None
data_dir = None
intent_label_file = None
args = Args()
args.task = "atis"
args.data_dir = "./bert_finetune_cls/data/"
args.intent_label_file = "intent_label.txt"
# 实例化
processor = ClsProcessor(args)
# 看一下processor的属性
print(processor.intent_labels)
输出:
['UNK', 'atis_abbreviation', 'atis_aircraft', 'atis_aircraft#atis_flight#atis_flight_no', 'atis_airfare', 'atis_airline', 'atis_airline#atis_flight_no', 'atis_airport', 'atis_capacity', 'atis_cheapest', 'atis_city', 'atis_distance', 'atis_flight', 'atis_flight#atis_airfare', 'atis_flight_no', 'atis_flight_time', 'atis_ground_fare', 'atis_ground_service', 'atis_ground_service#atis_ground_fare', 'atis_meal', 'atis_quantity', 'atis_restriction']
输入:
# 读取train样本
train_examples = processor.get_examples("train")
print(len(train_examples))
print(train_examples[0]) # InputExample __repr__
输出:
LOOKING AT ./bert_finetune_cls/data/atis\train
4478
-------
InputExample.to_dict()的输出:
{'guid': 'train-0', 'words': ['i', 'want', 'to', 'fly', 'from', 'baltimore', 'to', 'dallas', 'round', 'trip'], 'intent_label': 12}
-------
{
"guid": "train-0",
"intent_label": 12,
"words": [
"i",
"want",
"to",
"fly",
"from",
"baltimore",
"to",
"dallas",
"round",
"trip"
]
}
四、将数据处理成可以喂给模型的特征
输入:
# 如果有多个数据集,则数据集的processor可以通过映射得到
processors = {
"atis": ClsProcessor,
}
class InputFeatures(object):
"""
A single set of features of data.
输入数据特征→JSON字符串
"""
def __init__(self, input_ids, attention_mask, token_type_ids, intent_label_id):
self.input_ids = input_ids # 输入样本序列在bert词表里的索引,可以直接喂给nn.embedding
self.attention_mask = attention_mask # 注意力mask,padding的部分为0,其他为1
self.token_type_ids = token_type_ids # 表示每个token属于句子1还是句子2(值为0或1),单句分类任务值都是0
self.intent_label_id = intent_label_id # 意图标签序号
def __repr__(self):
return str(self.to_json_string())
def to_dict(self):
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
def convert_examples_to_features(examples,
max_seq_len,
tokenizer,
pad_token_label_id=-100,
cls_token_segment_id=0,
pad_token_segment_id=0,
sequence_a_segment_id=0,
mask_padding_with_zero=True):
"""
将之前读取的数据进行添加[CLS],[SEP]标记,padding等操作
args:
examples: 样本实例列表
pad_token_label_id: Use cross entropy ignore index as padding label id so that only real label ids contribute to the loss later
cls_token_segment_id: 取0
sequence_a_segment_id: 取0
pad_token_segment_id: 取0
mask_padding_with_zero: attention mask;
"""
# Setting based on the current model type 这里以BERT tokenizer为例
cls_token = tokenizer.cls_token # [CLS]
sep_token = tokenizer.sep_token # [SEP]
unk_token = tokenizer.unk_token # [UNK]
pad_token_id = tokenizer.pad_token_id # [PAD]编号为0
features = []
for (ex_index, example) in enumerate(examples):
if ex_index % 1000 == 0:
print("Writing example %d of %d" % (ex_index, len(examples)))
# Tokenize words 分词
tokens = []
for w in example.words:
toks = tokenizer.tokenize(w) # 分词,中文会按字分
tokens.extend(toks)
# Account for [CLS] and [SEP]
# 记录[CLS]和[SEP]
special_tokens_count = 2
# 如果句子长了就截断
if len(tokens) > max_seq_len - special_tokens_count:
tokens = tokens[:(max_seq_len - special_tokens_count)]
# Add [SEP] token
tokens += [sep_token]
token_type_ids = [sequence_a_segment_id] * len(tokens)
# Add [CLS] token
tokens = [cls_token] + tokens
token_type_ids = [cls_token_segment_id] + token_type_ids
# 把token转化为id
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_len - len(input_ids)
input_ids = input_ids + ([pad_token_id] * padding_length)
attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
# check长度是否符合
assert len(input_ids) == max_seq_len, "Error with input length {} vs {}".format(len(input_ids), max_seq_len)
assert len(attention_mask) == max_seq_len, "Error with attention mask length {} vs {}".format(len(attention_mask), max_seq_len)
assert len(token_type_ids) == max_seq_len, "Error with token type length {} vs {}".format(len(token_type_ids), max_seq_len)
intent_label_id = int(example.intent_label)
if ex_index < 5:
print("*** Example ***")
print("guid: %s" % example.guid)
print("tokens: %s" % " ".join([str(x) for x in tokens]))
print("input_ids: %s" % " ".join([str(x) for x in input_ids]))
print("attention_mask: %s" % " ".join([str(x) for x in attention_mask]))
print("token_type_ids: %s" % " ".join([str(x) for x in token_type_ids]))
print("intent_label: %s (id = %d)" % (example.intent_label, intent_label_id))
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
intent_label_id=intent_label_id,
))
return features # list
def load_and_cache_examples(args, tokenizer, mode):
processor = processors[args.task](args) # 即:ClsProcessor(args)
# Load data features from cache or dataset file
cached_features_file = os.path.join(
args.data_dir,
'cached_{}_{}_{}_{}'.format(
mode,
args.task,
list(filter(None, args.model_name_or_path.split("/"))).pop(),
args.max_seq_len
)
)
print(cached_features_file)
if os.path.exists(cached_features_file):
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
# Load data features from dataset file
logger.info("Creating features from dataset file at %s", args.data_dir)
if mode == "train":
examples = processor.get_examples("train")
elif mode == "dev":
examples = processor.get_examples("dev")
elif mode == "test":
examples = processor.get_examples("test")
else:
raise Exception("For mode, Only train, dev, test is available")
# 添加[CLS],[SEP]标记、input_id、padding等操作
features = convert_examples_to_features(examples,
args.max_seq_len,
tokenizer,)
print("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file) # 保存特征数据
# Convert to Tensors and build dataset 将特征转化为tensor
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_intent_label_ids = torch.tensor([f.intent_label_id for f in features], dtype=torch.long)
print('all input ids:',all_input_ids)
print('all input ids\' size:',all_input_ids.size())
# 将各种tensor打包,类似zip,要求各 tensor 第一维相等(样本数量)
dataset = TensorDataset(
all_input_ids,
all_attention_mask,
all_token_type_ids,
all_intent_label_ids,
)
return dataset
# 这一步涉及到不同模型的tokenizer
class ClsBERT(BertPreTrainedModel):
def __init__(self, config, args, intent_label_lst):
super(ClsBERT, self).__init__(config)
self.args = args
self.num_intent_labels = len(intent_label_lst)
self.bert = BertModel(config=config) # Load pretrained bert
self.intent_classifier = IntentClassifier(config.hidden_size, self.num_intent_labels, args.dropout_rate)
MODEL_CLASSES = {
'bert': (BertConfig, ClsBERT, BertTokenizer),
}
MODEL_PATH_MAP = {
'bert': './bert_finetune_cls/resources/uncased_L-2_H-128_A-2',
}
def load_tokenizer(args):
return MODEL_CLASSES[args.model_type][2].from_pretrained(args.model_name_or_path)
# 先构建参数
class Args():
task = None
data_dir = None
intent_label_file = None
args = Args()
args.task = "atis"
args.data_dir = "./bert_finetune_cls/data"
args.intent_label_file = "intent_label.txt"
args.max_seq_len = 50
args.model_type = "bert"
args.model_dir = "bert_finetune_cls/experiments/outputs/clsbert_0"
args.model_name_or_path = MODEL_PATH_MAP[args.model_type]
args.train_batch_size = 4
tokenizer = load_tokenizer(args) # Bert分词器
dataset = load_and_cache_examples(args, tokenizer, mode="train")
输出:
./bert_finetune_cls/data\cached_train_atis_uncased_L-2_H-128_A-2_50
LOOKING AT ./bert_finetune_cls/data\atis\train
Writing example 0 of 4478
*** Example ***
guid: train-0
tokens: [CLS] i want to fly from baltimore to dallas round trip [SEP]
input_ids: 101 1045 2215 2000 4875 2013 6222 2000 5759 2461 4440 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
attention_mask: 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
intent_label: 12 (id = 12)
*** Example ***
guid: train-1
tokens: [CLS] round trip fares from baltimore to philadelphia less than 1000 dollars round trip fares from denver to philadelphia less than 1000 dollars round trip fares from pittsburgh to philadelphia less than 1000 dollars [SEP]
input_ids: 101 2461 4440 27092 2013 6222 2000 4407 2625 2084 6694 6363 2461 4440 27092 2013 7573 2000 4407 2625 2084 6694 6363 2461 4440 27092 2013 6278 2000 4407 2625 2084 6694 6363 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
attention_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
intent_label: 4 (id = 4)
*** Example ***
guid: train-2
tokens: [CLS] show me the flights arriving on baltimore on june fourteenth [SEP]
input_ids: 101 2265 2033 1996 7599 7194 2006 6222 2006 2238 15276 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
attention_mask: 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
intent_label: 12 (id = 12)
*** Example ***
guid: train-3
tokens: [CLS] what are the flights which depart from san francisco fly to washington via indianapolis and arrive by 9 pm [SEP]
input_ids: 101 2054 2024 1996 7599 2029 18280 2013 2624 3799 4875 2000 2899 3081 9506 1998 7180 2011 1023 7610 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
attention_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
intent_label: 12 (id = 12)
*** Example ***
guid: train-4
tokens: [CLS] which airlines fly from boston to washington dc via other cities [SEP]
input_ids: 101 2029 7608 4875 2013 3731 2000 2899 5887 3081 2060 3655 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
attention_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
intent_label: 5 (id = 5)
Writing example 1000 of 4478
Writing example 2000 of 4478
Writing example 3000 of 4478
Writing example 4000 of 4478
Saving features into cached file %s ./bert_finetune_cls/data\cached_train_atis_uncased_L-2_H-128_A-2_50
all input ids: tensor([[ 101, 1045, 2215, ..., 0, 0, 0],
[ 101, 2461, 4440, ..., 0, 0, 0],
[ 101, 2265, 2033, ..., 0, 0, 0],
...,
[ 101, 2425, 2033, ..., 0, 0, 0],
[ 101, 1045, 1005, ..., 0, 0, 0],
[ 101, 2003, 2045, ..., 0, 0, 0]])
all input ids' size: torch.Size([4478, 50])
五、PyTorch数据加载函数DataLoader
这里是pytorch dataload的pipeline固定写法,需要了解清楚执行流程。
输入:
tokenizer = load_tokenizer(args)
# # 1. 定义dataset(torch)
train_dataset = load_and_cache_examples(args, tokenizer, mode="train") # 训练集
# dev_dataset = load_and_cache_examples(args, tokenizer, mode="dev")
# test_dataset = load_and_cache_examples(args, tokenizer, mode="test")
# torch自带的sampler类,功能是每次返回一个随机的样本索引
train_sampler = RandomSampler(train_dataset)
# # 2. 定义dataloader
# 使用dataloader输出batch
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
# # 3. 设置cpu或者gpu模式,按batch读取特征数据
device = "cpu"
for step, batch in enumerate(train_dataloader):
batch = tuple(t.to(device) for t in batch) # device设置为'gpu'则将batch上传到显卡
inputs = {"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"intent_label_ids": batch[3],}
if step == 0:
print(inputs["input_ids"], inputs["input_ids"].shape)
print(inputs["attention_mask"], inputs["attention_mask"].shape)
print(inputs["token_type_ids"], inputs["token_type_ids"].shape)
print(inputs["intent_label_ids"], inputs["intent_label_ids"].shape)
输出:
./bert_finetune_cls/data\cached_train_atis_uncased_L-2_H-128_A-2_50
all input ids: tensor([[ 101, 1045, 2215, ..., 0, 0, 0],
[ 101, 2461, 4440, ..., 0, 0, 0],
[ 101, 2265, 2033, ..., 0, 0, 0],
...,
[ 101, 2425, 2033, ..., 0, 0, 0],
[ 101, 1045, 1005, ..., 0, 0, 0],
[ 101, 2003, 2045, ..., 0, 0, 0]])
all input ids' size: torch.Size([4478, 50])
tensor([[ 101, 2054, 2003, 13258, 3642, 1049, 102, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 2054, 2024, 1996, 2598, 5193, 2578, 1999, 4407, 102,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 2265, 2033, 7599, 2013, 9184, 2000, 10108, 2006, 9432,
2851, 102, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 2054, 7599, 2024, 2045, 2013, 9774, 2000, 5869, 7136,
102, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) torch.Size([4, 50])
tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]]) torch.Size([4, 50])
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]]) torch.Size([4, 50])
tensor([ 1, 17, 12, 12]) torch.Size([4])
版权声明:本文为weixin_40633696原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。