问题导入
在介绍什么是前缀和前,我们先来看这样一个问题,这里有一个
n
长度的数组,每个索引对应的的值是随机的,我们需要对这个数组做
m
次查询,每次查询会给出一个
起点
和
终点
,我们需要返回对应闭区间内的值的和。

如上图,若第一次的询问为
[0,2]
则结果为13;
若第二次的询问为
[2,5]
则结果为47;
如果我们按照最简单的想法,那么我们处理这个查询的方式则为直接加法求和,从起点开始依次加到终点即可。
而对于这样的一个方法,我们假设最坏的情况,每次查询的长度均为n次,那么完成这种m次的查询所需要的时间大概为
n*m
,我们也可以自然推测出这个算法的时间复杂度为
O(mn)
。
如果数量级合适,那自然是够用的,但如果
n=20000,m=20000
的情况下,显然我们这样的算法是超时的,无法满足这种情况的需要,那么,有没有一种方法可以让我们能够不需要在每次查询时都进行遍历求和呢?
试想一下,倘若我们知道前5项的和
A
与前10项的和
B
,那要求第6-10项的和可以怎么求呢?自然就是
B-A
,此时我们便不需要再去多次进行加法,而仅需要做简单的运算,很好地提高了求解的速度。
算法简介
而能够用来计算计算数组前若干项的
和(包括不同规则的加法)
的一种
预处理
的方法,我们将其称为
前缀和算法
,例如在上面这个例子中,我们如果用数组a来计算前缀和,
a[i]
表示前
i+1
项的和,那么我们的前缀和数组可以得到:

而此时,不管对于多大的区间的结果查询,我们都只需要做一次减法即可得到结果,在此算法中,我们需要
O(n)
的线性遍历来处理前缀和,
O(m)
的线性处理各种请求,所以我们的时间复杂度一下子降低到了
O(m+n)
能很好地解决这个问题。
常见应用
在问题引入中,我们使用的其实是最简单的
一维
的前缀和,既然有一维,自然也有
二维
,或是多维(但很少见且有独立的算和的规则),例如,如果是对下面的区域进行区域查询求和。
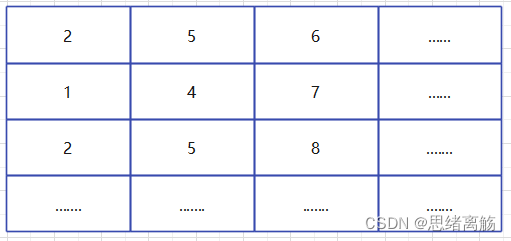
那么,我们的二维的前缀和数组的结果则为以改坐标为右下角顶点的矩形的和。
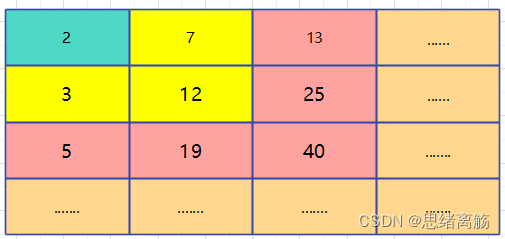
而根据此,我们可以很方便地求取不同区域范围内的值的和。
由此
我们也算初步了解了前缀和算法。
常见变体
在简介里面,我们说前缀和是一种
预处理
的方法,但实际上,前缀和在一些问题中也是可以作为
求解部分使用
的算法,但相对应的,也需要搭配上一定的预处理方法。
例如
求若干条线段间重合部分的最大重合次数
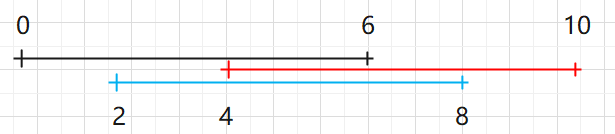
例如对于图中所给的这三条线段
(线段并不一定统一长度)
来说,最大的重合部分为[2,4],重合次数为3
对于这类问题,我们假设线段数量为
N
,起点和终点都在
[0,m]
间。
通俗的暴力解法:
我们直接开一个长度为
m+k
(k为常数预防可能的溢出)的数组,对于每条线段,从起点到终点每个索引下的值
+1
,到时候只需要求得最大的值即为所求。
在图中这个例子里,我们来进行
第一条线段处理后:

第二条线段处理后:

第三条线段处理后:

在这个方法中,如果我们设所有线段的平均长度为L,我们可以发现,大约需要的时间复杂度为
O(n*L)
,需要的空间复杂度为
O(m)
,如果n,L均大于10000,则面临超时的危险,这也是不可行的。
相对优化方法一:
那么在这个问题中,我们如何来用前缀和方法进行求解呢?
我们进行如下操作: 处理每条线段时,对应
起点坐标下的值+1
,对应
终点坐标下的值-1
那么,图中例子则被处理为如下图:

然后我们再对其进行前缀和求解,得到的
前缀和数组
为:

也能得到所求结果,这里用到的思想就是,用1代表线段开始,-1代表线段结束,而他们的和就代表当前
未结束的线段数量
也就是重合度,所以可以用前缀和方法进行求解。
而在这个方法中,线段的平均长度并不会影响时间复杂度,我们可以发现,大约需要的时间复杂度为
O(n)
很好地降低了需要的时间,而需要的空间复杂度为
O(m)
,如果m足够大,似乎会浪费很多的空间。
你知道如何处理来减少空间浪费吗
?
相对优化方法二:
这一部分的提示是:
链表
希望大家可以自己探索更多解法 hhhh