etcd简介
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用
raft
协议作为一致性算法,etcd基于Go语言实现。
etcd作为服务发现系统,有以下的特点:
- 简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
- 安全:支持SSL证书验证
- 快速:根据官方提供的benchmark数据,单实例支持每秒2k+读操作
- 可靠:采用raft算法,实现分布式系统数据的可用性和一致性
etcd项目地址:
https://github.com/coreos/etcd/
etcd应用场景
etcd比较多的应用场景是用于服务发现,服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。
从本质上说,服务发现就是要了解集群中是否有进程在监听upd或者tcp端口,并且通过名字就可以进行查找和链接。
要解决服务发现的问题,需要下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。
基于Ralf算法的etcd天生就是这样一个强一致性、高可用的服务存储目录。
- 一种注册服务和健康服务健康状况的机制。
用户可以在etcd中注册服务,并且对注册的服务配置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。
通过在etcd指定的主题下注册的服务业能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个proxy模式的etcd,这样就可以确保访问etcd集群的服务都能够互相连接。
etcd安装
etcd在生产环境中一般推荐集群方式部署。本文定位为入门,主要讲讲单节点安装和基本使用。
etcd目前默认使用2379端口提供HTTP API服务,2380端口和peer通信(这两个端口已经被IANA官方预留给etcd);在之前的版本中可能会分别使用4001和7001,在使用的过程中需要注意这个区别。
因为etcd是go语言编写的,安装只需要下载对应的二进制文件,并放到合适的路径就行。
下载软件包
wget https://github.com/coreos/etcd/releases/download/v3.1.5/etcd-v3.1.5-linux-amd64.tar.gz
tar zxvf etcd-v3.1.5-linux-amd64.tar.gz
sudo mv etcd-v3.1.5-linux-amd64 /opt/etcd
cd etcdctl
解压后是一些文档和两个二进制文件etcd和etcdctl。etcd是server端,etcdctl是客户端。
如果在测试环境,启动一个单节点的etcd服务,只需要运行etcd命令就行。
$ ./etcd
2017-04-10 11:46:44.772465 I | etcdmain: etcd Version: 3.1.5
2017-04-10 11:46:44.772512 I | etcdmain: Git SHA: 20490ca
2017-04-10 11:46:44.772607 I | etcdmain: Go Version: go1.7.5
2017-04-10 11:46:44.772756 I | etcdmain: Go OS/Arch: linux/amd64
2017-04-10 11:46:44.772817 I | etcdmain: setting maximum number of CPUs to 2, total number of available CPUs is 2
2017-04-10 11:46:44.772851 W | etcdmain: no data-dir provided, using default data-dir ./default.etcd
2017-04-10 11:46:44.773298 I | embed: listening for peers on http://localhost:2380
2017-04-10 11:46:44.773583 I | embed: listening for client requests on localhost:2379
2017-04-10 11:46:44.775967 I | etcdserver: name = default
2017-04-10 11:46:44.775993 I | etcdserver: data dir = default.etcd
2017-04-10 11:46:44.776167 I | etcdserver: member dir = default.etcd/member
2017-04-10 11:46:44.776253 I | etcdserver: heartbeat = 100ms
2017-04-10 11:46:44.776264 I | etcdserver: election = 1000ms
2017-04-10 11:46:44.776270 I | etcdserver: snapshot count = 10000
2017-04-10 11:46:44.776285 I | etcdserver: advertise client URLs = http://localhost:2379
2017-04-10 11:46:44.776293 I | etcdserver: initial advertise peer URLs = http://localhost:2380
2017-04-10 11:46:44.776306 I | etcdserver: initial cluster = default=http://localhost:2380
2017-04-10 11:46:44.781171 I | etcdserver: starting member 8e9e05c52164694d in cluster cdf818194e3a8c32
2017-04-10 11:46:44.781323 I | raft: 8e9e05c52164694d became follower at term 0
2017-04-10 11:46:44.781351 I | raft: newRaft 8e9e05c52164694d [peers: [], term: 0, commit: 0, applied: 0, lastindex: 0, lastterm: 0]
2017-04-10 11:46:44.781883 I | raft: 8e9e05c52164694d became follower at term 1
2017-04-10 11:46:44.795542 I | etcdserver: starting server... [version: 3.1.5, cluster version: to_be_decided]
2017-04-10 11:46:44.796453 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
2017-04-10 11:46:45.083350 I | raft: 8e9e05c52164694d is starting a new election at term 1
2017-04-10 11:46:45.083494 I | raft: 8e9e05c52164694d became candidate at term 2
2017-04-10 11:46:45.083520 I | raft: 8e9e05c52164694d received MsgVoteResp from 8e9e05c52164694d at term 2
2017-04-10 11:46:45.083598 I | raft: 8e9e05c52164694d became leader at term 2
2017-04-10 11:46:45.083654 I | raft: raft.node: 8e9e05c52164694d elected leader 8e9e05c52164694d at term 2
2017-04-10 11:46:45.084544 I | etcdserver: published {Name:default ClientURLs:[http://localhost:2379]} to cluster cdf818194e3a8c32
2017-04-10 11:46:45.084638 I | etcdserver: setting up the initial cluster version to 3.1
2017-04-10 11:46:45.084857 I | embed: ready to serve client requests
2017-04-10 11:46:45.085918 E | etcdmain: forgot to set Type=notify in systemd service file?
2017-04-10 11:46:45.086668 N | embed: serving insecure client requests on 127.0.0.1:2379, this is strongly discouraged!
2017-04-10 11:46:45.087004 N | etcdserver/membership: set the initial cluster version to 3.1
2017-04-10 11:46:45.087195 I | etcdserver/api: enabled capabilities for version 3.1
从上面的输出中,我们可以看到很多信息。以下是几个比较重要的信息:
- name表示节点名称,默认为default。
- data-dir 保存日志和快照的目录,默认为当前工作目录default.etcd/目录下。
-
在
http://localhost:2380
和集群中其他节点通信。 -
在
http://localhost:2379
提供HTTP API服务,供客户端交互。 - heartbeat为100ms,该参数的作用是leader多久发送一次心跳到followers,默认值是100ms。
- election为1000ms,该参数的作用是重新投票的超时时间,如果follow在该+ 时间间隔没有收到心跳包,会触发重新投票,默认为1000ms。
- snapshot count为10000,该参数的作用是指定有多少事务被提交时,触发+ 截取快照保存到磁盘。
- 集群和每个节点都会生成一个uuid。
- 启动的时候会运行raft,选举出leader。
- 上面的方法只是简单的启动一个etcd服务,但要长期运行的话,还是做成一个服务好一些。下面将以systemd为例,介绍如何建立一个etcd服务。
创建systemd服务
- 设定etcd配置文件
建立相关目录
$ mkdir -p /var/lib/etcd/
$ mkdir -p /opt/etcd/config/
- 创建etcd配置文件
$ cat <<EOF | sudo tee /opt/etcd/config/etcd.conf
#节点名称
ETCD_NAME=$(hostname -s)
#数据存放位置
ETCD_DATA_DIR=/var/lib/etcd
EOF
- 创建systemd配置文件
$ cat <<EOF | sudo tee /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
Documentation=https://github.com/coreos/etcd
After=network.target
[Service]
User=root
Type=notify
EnvironmentFile=-/opt/etcd/config/etcd.conf
ExecStart=/opt/etcd/etcd
Restart=on-failure
RestartSec=10s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
EOF
- 启动etcd
$ systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
etcd基本使用
etcdctl是一个命令行客户端,它能提供一些简洁的命令,供用户直接跟etcd服务打交道,而无需基于 HTTP API方式。可以方便我们在对服务进行测试或者手动修改数据库内容。建议刚刚接触etcd时通过etdctl来熟悉相关操作。这些操作跟HTTP API基本上是对应的。
etcd项目二进制发行包中已经包含了etcdctl工具,etcdctl支持的命令大体上分为数据库操作和非数据库操作两类。
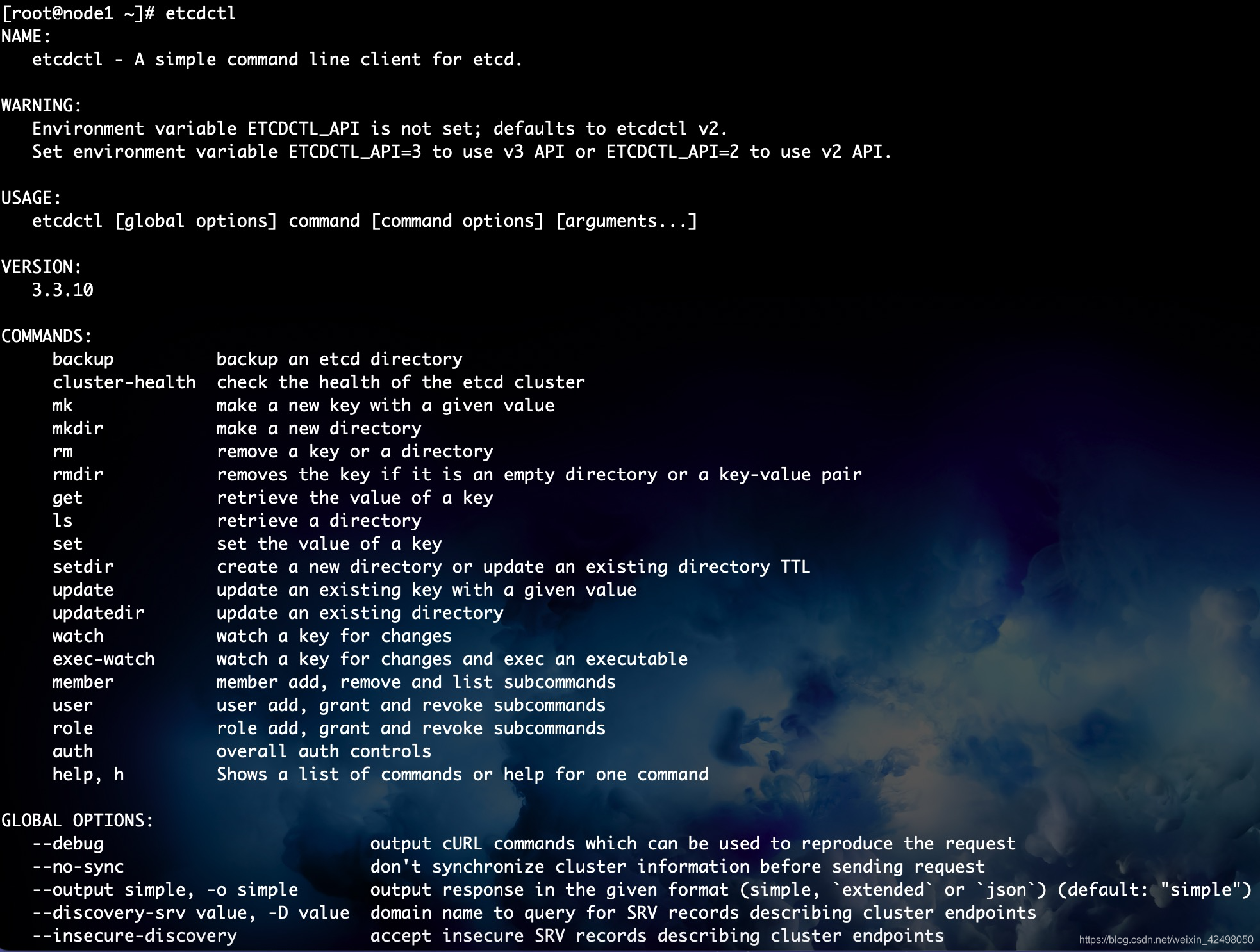
ectdctl 查看信息
集群就是 一个服务 有很多机器在跑,可以是同个机房,也可以是很多机房,同类服务的多个机器的集合
IaaS, PaaS和SaaS是云计算的三种服务模式。
1. SaaS:Software-as-a-Service(软件即服务)提供给客户的服务是运营商运行在云计算基础设施上的应用程序,用户可以在各种设备上通过客户端界面访问,如浏览器。消费者不需要管理或控制任何云计算基础设施,包括网络、服务器、操作系统、存储等等;
2. PaaS:Platform-as-a-Service(平台即服务)提供给消费者的服务是把客户采用提供的开发语言和工具(例如Java,python, .Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去。
客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置;
3. IaaS: Infrastructure-as-a-Service(基础设施即服务)提供给消费者的服务是对所有计算基础设施的利用,包括处理CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。
物理CPU,物理CPU内核,逻辑CPU概念详解
1.说明
CPU(Central Processing Unit)是中央处理单元,
本文介绍物理CPU,物理CPU内核,逻辑CPU,
以及他们三者之间的关系,
一个物理CPU可以有1个或者多个物理内核,
一个物理内核可以作为1个或者2个逻辑CPU。
2.物理CPU
物理CPU就是计算机上实际安装的CPU,
物理CPU数就是主板上实际插入的CPU数量。
在Linux上查看/proc/cpuinfo,
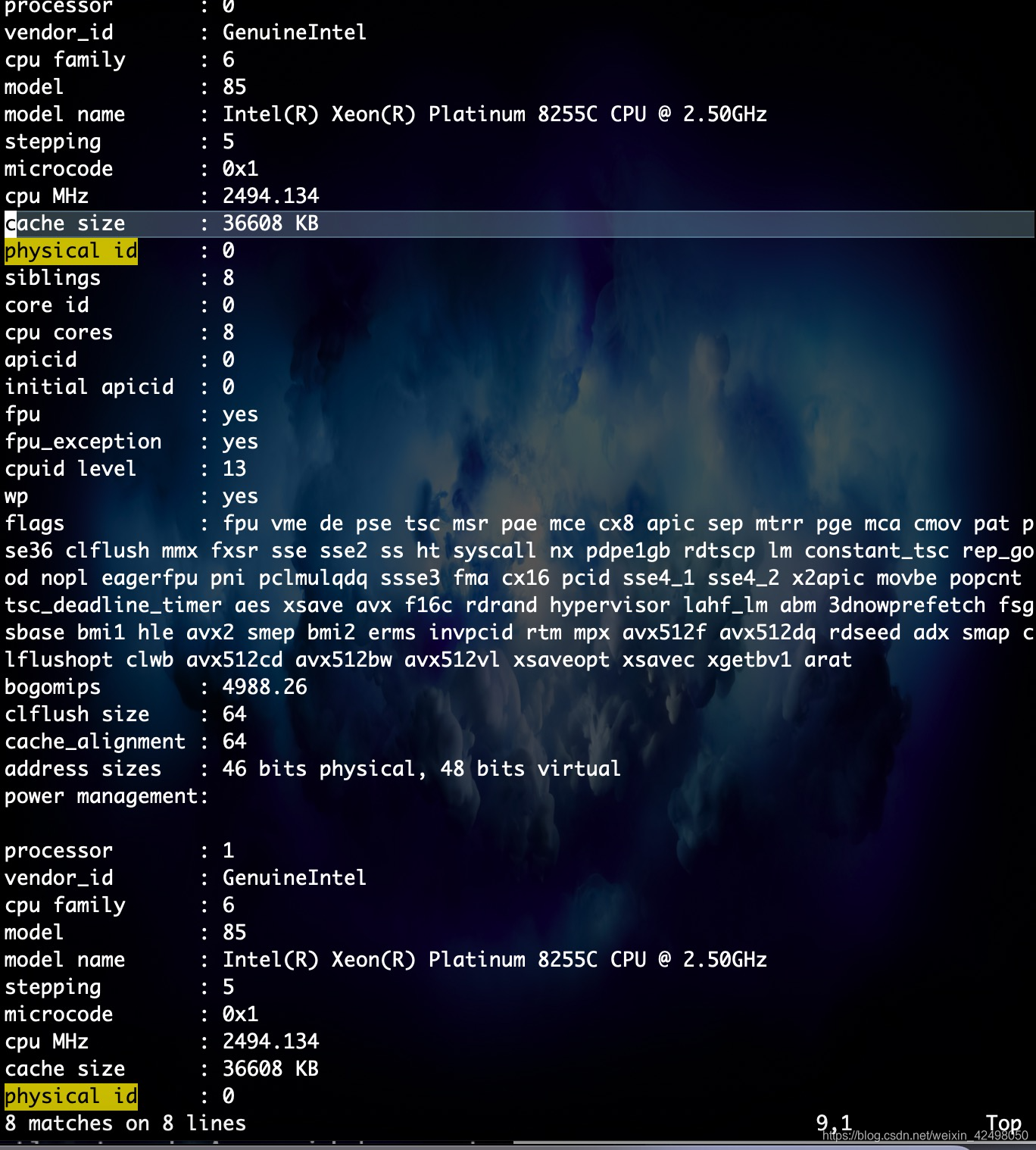
其中的physical id就是每个物理CPU的id,
有几个不同的physical id就有几个物理CPU。
3.物理CPU内核
每颗物理CPU可以有1个或者多个物理内核,
通常每颗物理CPU的内核数都是固定的,
单核CPU就是有1个物理内核,
双核CPU就是有2个物理内核。
在Linux上查看/proc/cpuinfo,
其中的core id就是每颗物理CPU的物理内核id,
有几个不同的core id就有几个物理内核。
总的CPU物理内核数 = 物理CPU数 * 每颗物理CPU的内核数
4.逻辑CPU
操作系统可以使用逻辑CPU来模拟真实CPU。
在没有多核处理器的时候,
一个物理CPU只能有一个物理内核,
而现在有了多核技术,
一个物理CPU可以有多个物理内核,
可以把一个CPU当作多个CPU使用,
为了与物理CPU区分开来,称其为逻辑CPU。
没有开启超线程时,逻辑CPU的个数就是总的CPU物理内核数。
然而开启超线程后,逻辑CPU的个数就是总的CPU物理内核数的两倍。
在Linux上查看/proc/cpuinfo,
其中的processor就是逻辑CPU,
有几个processor就有几个逻辑CPU。
总的逻辑CPU数 = 物理CPU个数 * 每颗物理CPU的核数 * 超线程数
总的逻辑CPU数 = 总的CPU物理内核数 * 超线程数
5.几核几线程
基于上面的基本概念,
理解一下常说的几核几线程。
如果计算机有一个物理CPU,
是双核的,支持超线程。
那么这台计算机就是双核四线程。
实际上几核几线程中的线程数就是逻辑CPU数。
对于两路四核超线程计算机,
两路指计算机有2个物理CPU,
每颗CPU中有4个物理内核,
CPU支持超线程,
就有2*4*2=16个逻辑CPU,
这就是通常所谓的16核计算机。
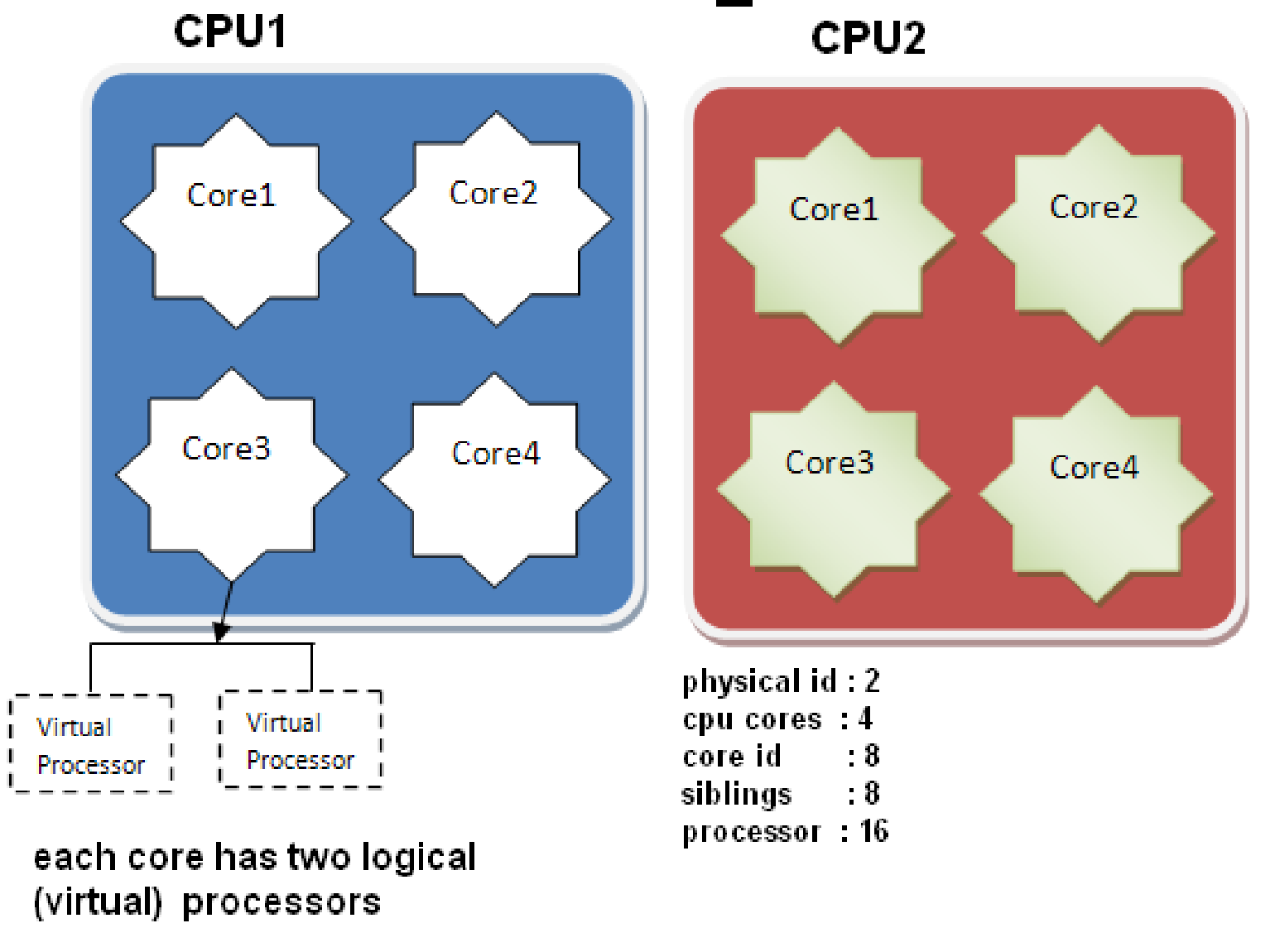
6.两路四核超线程
实际能看到的2个物理CPU:

实现16个逻辑CPU的原理图:
# cat /proc/cpuinfo 查看物理cpu
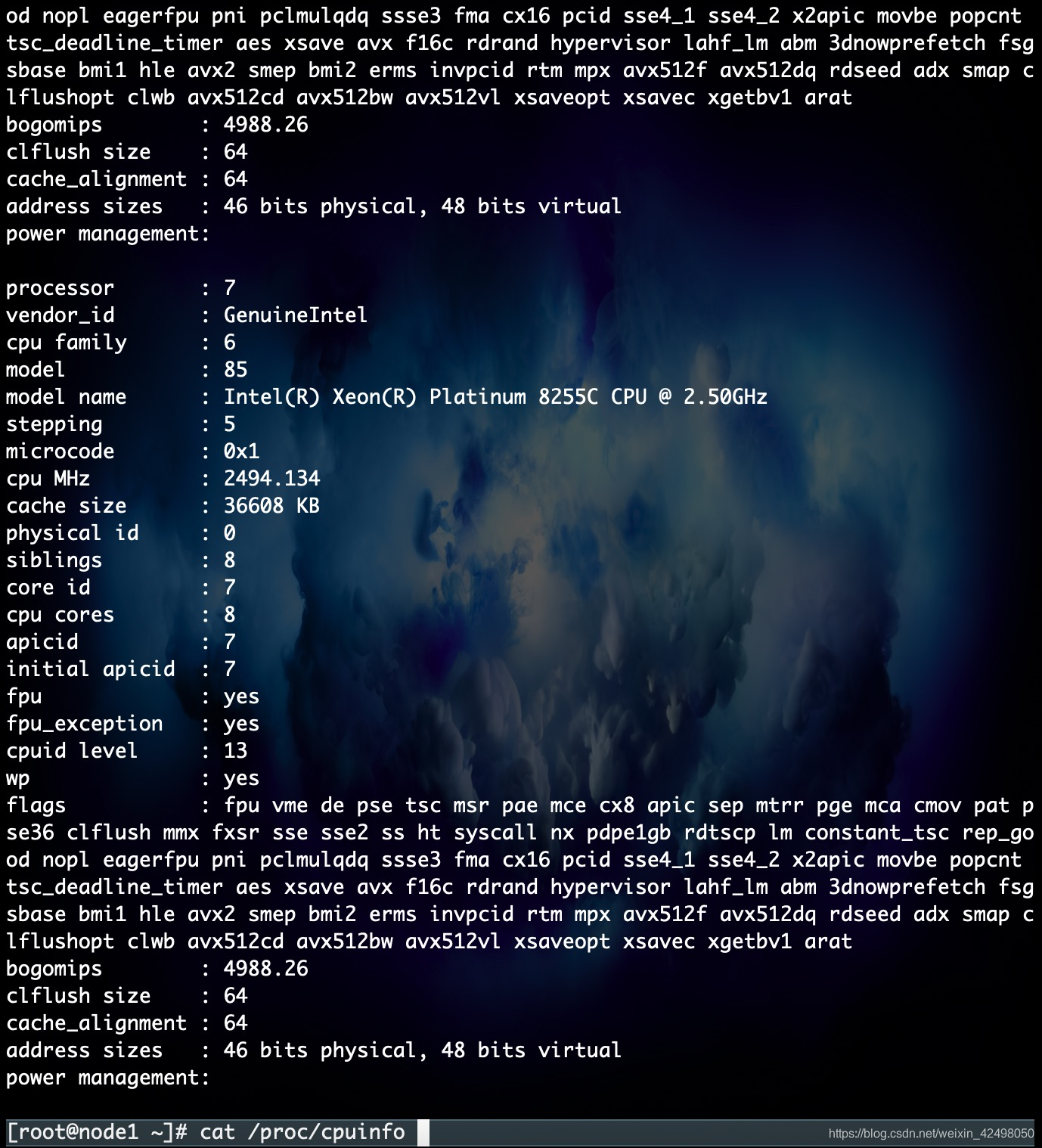
有多少physical id 就有多少个cpu,我们的服务器是8个
有多少个core id就有多少核 –8个物理内核
总的CPU物理内核数 = 物理CPU数 * 每颗物理CPU的内核数 8*8=64
边缘云计算是基于云计算技术的核心和边缘计算的能力,构筑在边缘基础设施之上的云计算平台。形成边缘位置的计算、网络、存储、安全等能力全面的弹性云平台,并与中心云和物联网 终端形成“云边端三体协同” 的端到端的技术架构,通过将网络转发、存储、 计算,智能化数据分析等工作放在边缘处理,降低响应时延、减轻云端压力、降低带宽成本,并提供全网调度、算力分发等云服务
iperf3的tcp测试需要注意
需要测试同一个node下绑定不同pod的网络带宽
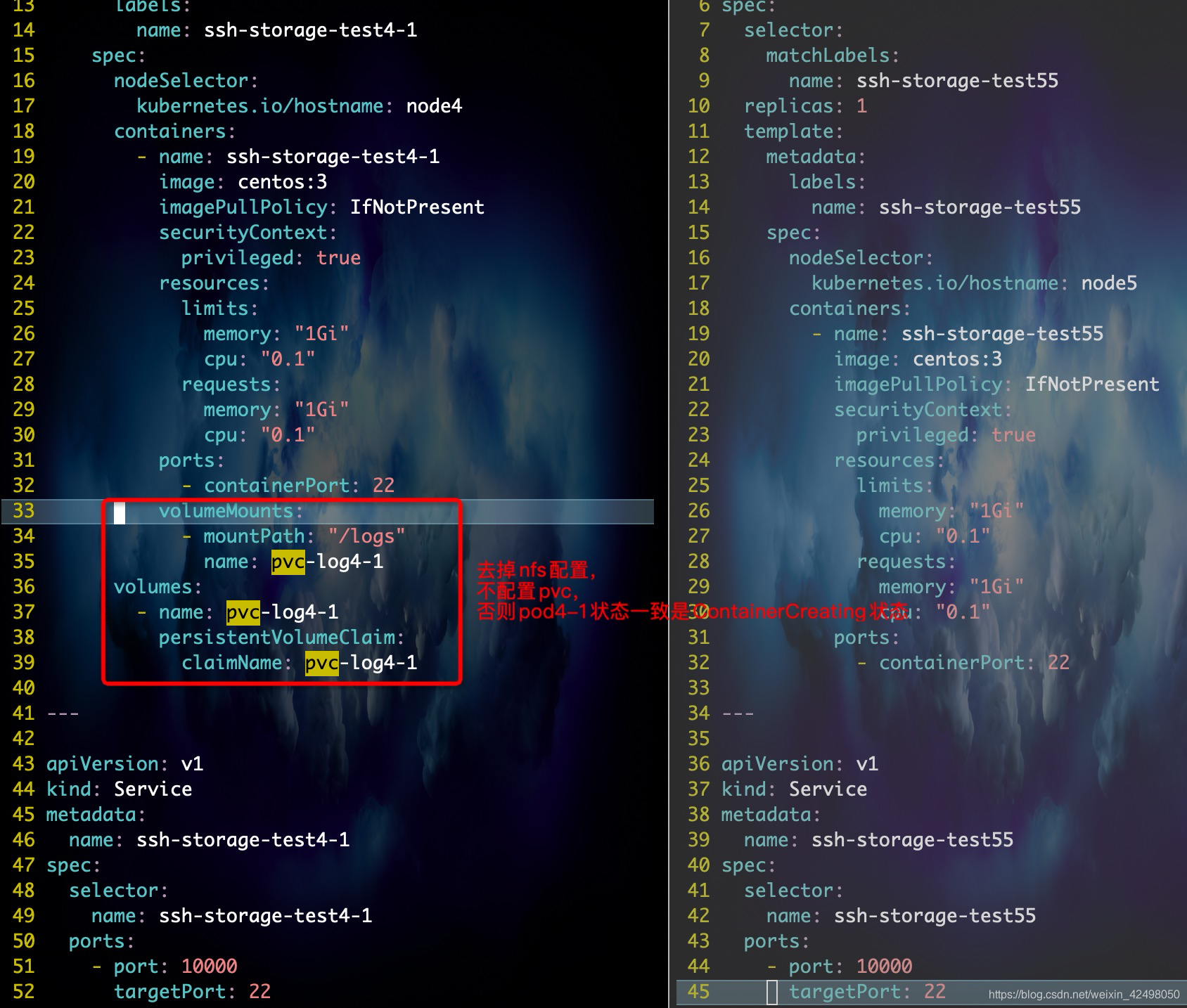
1. pod3 <-> pod4
2. 在node4上再建一个pod (e.g. pod4-1), pod4 <->pod4-1
cp pvc4文件 修改log4-1
cp deployment4.yml ,node还是node4 name改成ssh-storage-test-4-1 log4 改为log4-1
node4上有pod4和pod4-1
这套系统存储是基于nfs的。
nfs server在node6上
每建立一个pv /pvc 都会在这个节点上创建一个目录 。 目前看应该是创建不成功了
mount.nfs: mounting ipnode6:/nfsdata/kube-system-pvc-log55-pvc-03fad51a-c1ee-4dd4-ab77-5480b4ea048e failed, reason given by server: No such file or directory
请运维修下node6就好。目前测试不需要nfs,把nfs的配置去掉了。 目前可用
新创建的pod启动失败,比如创建node4绑定pod4,但是发现pod4启动状态一直为ContainerCreating

通过报错日志分析,不知道为什报错在ipnode6服务器(node6)绑定的是node4
Output: Running scope as unit run-3387123.scope.
mount.nfs: mounting ipnode6:/nfsdata/kube-system-pvc-log4-1-pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d failed, reason given by server: No such file or directory
Warning FailedMount 10m kubelet, node4 MountVolume.SetUp failed for volume “pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d” : mount failed: exit status 32
Mounting command: systemd-run
Mounting arguments: –description=Kubernetes transient mount for /var/lib/kubelet/pods/eea42b40-10bd-40a7-a8df-4375a0ad85e7/volumes/kubernetes.io~nfs/pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d –scope — mount -t nfs ipnode6:/nfsdata/kube-system-pvc-log4-1-pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d /var/lib/kubelet/pods/eea42b40-10bd-40a7-a8df-4375a0ad85e7/volumes/kubernetes.io~nfs/pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d
Output: Running scope as unit run-3387177.scope.
mount.nfs: mounting ipnode6:/nfsdata/kube-system-pvc-log4-1-pvc-cf27c7c5-bdd0-42b9-87e4-c5fb4dd0196d failed, reason given by server: No such file or directory
解决办法
删除
kubectl delete -f <pvc.yaml>
kubectl delete -f <deployment.yaml>
创建
kubectl create -f <pvc.yaml>
kubectl create -f <deployment.yaml>
时实际操作
kubectl get pod -A -o wide|grep storage-test4- 查看pod状态
kubectl delete -f pvc-test4-1.yml 删除pvc
kubectl delete -f deployment4-1.yml 删除pod
kubectl create -f pvc-test4-1.yml 创建盘
kubectl create -f deployment4-1.yml 创建pod
kubectl get pod -A -o wide|grep storage-test4- 再次查看pod状态