此系列为博雅数智举办的线上培训课程——python数据科学实践,为期两个月,本系列记录我在此课程中所学所思。
本节课总览:

本节课所用到的知识点:正则表达式、apply方法、lambda表达式、str.split、str.replace
实践
数据集:
某图书网站数据清洗 (idatascience.cn)
1、拿到数据第一件事:数据诊断
预览数据前、后、随机10行,了解数据字段含义及数据格式,为后续清洗做准备。

以【出版信息】列为例,可查看总共计数有600条出版社数据,有420个不重复的出版社, 出现次数最多的是机械工业出版社,13次。
还使用dada.describe()查看全部数值型字段的数据分布情况(计数、均值、标准值、最大最小值、分布概率),此数据中仅【当前价格】列符合要求。 后续将出一个文本型数据描述性分析的文章。

2、接下来进行:数据清洗
注意 :re模块中的findall函数返回的是一个列表,因此我们下面用了
result[0]
指定元素
2.1 提取价格数值

2.2 提取评论数值

2.3 转换图书星级数值

2.4 提取作者、出版时间和出版社
2.4.1 提取作者

2.4.2 提取出版时间

2.4.3 提取出版社

注意这里倒着取索引,因为有些出版信息中只有出版社名字,没有作者名字及出版日期。
2.5 提取书名和简介
2.5.1 提取书名

2.5.2 提取简介
2.6 删除不需要的列

整体代码
import pandas as pd
import re
data = pd.read_excel(r"C:\Users\HP\Desktop\某图书网站数据清洗.xlsx")
data.head(5)
data['出版信息'].describe()
data['出版信息'].value_counts()
data.describe()
#2.1提取价格
def funcPrice(data):
result = re.findall(r'\d+\.?\d*',data)
return float(result[0])
data['当前价格_match'] = data['当前价格'].apply(funcPrice)
data.head(3)
#2.2提取评论
def funcComment(data):
result = re.findall(r'\d+',data)
return int(result[0])
# 利用apply方法,将每一条数据进行处理
data['评论数_match'] = data['评论数'].apply(funcComment)
data.head(3)
#2.3提取星级
data['星级_match'] = data['星级'].apply(funcComment)
data.head(3)
#将星级除以20,取值范围转换到[0,5]的区间内
data['星级_match_cal'] = data['星级_match'].apply(lambda x:x/20)
data.head(3)
# 2.4将出版信息分割成三列,分别提取出作者、出版日期和出版社
# 2.4.1提取出作者
data['作者'] = data['出版信息'].apply(lambda x:x.split('/')[0])
data.head(3)
# 2.4.2用正则表达式提取日期,并将日期字符串转换成日期格式
from datetime import datetime
def func_2(data):
result = re.findall(r'\d{4}-\d{2}-\d{2}',data)
if len(result)<1:
return None
else:
return datetime.strptime(result[0],'%Y-%m-%d') #返回日期类型
# 提取日期,并添加为新的一列
#data['出版日期'] = data['出版信息'].apply(func_2)
data.head(3)
# 2.4.3提取出版社一列,并添加为新的一列
data['出版社'] = data['出版信息'].apply(lambda x:x.split('/')[-1])
# 查看结果
data.head(3)
#2.5提取书名和简介
#2.5.1将'【】'和'[]'以及之间的内容,用空格来代替
def func_3(data):
data = data.strip()#先去除头和尾的空格
data = re.sub("【.*?】"," ",data)
data = re.sub("\[.*?\]"," ",data)
return data.split(" ")
data['书名_split'] = data['书名'].apply(func_3)
data['书名_split'][:5]
# 提取书名
data['书名_split_1'] = data['书名_split'].apply(lambda x:x[0])
data['书名_split_1'][:5]
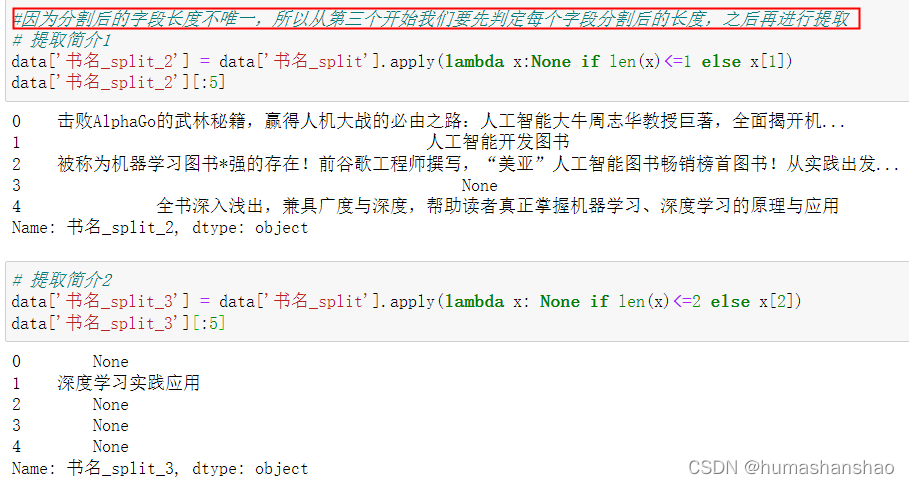
#因为分割后的字段长度不唯一,所以从第三个开始我们要先判定每个字段分割后的长度,之后再进行提取
# 2.5.2提取简介1
data['书名_split_2'] = data['书名_split'].apply(lambda x:None if len(x)<=1 else x[1])
data['书名_split_2'][:5]
# 提取简介2
data['书名_split_3'] = data['书名_split'].apply(lambda x: None if len(x)<=2 else x[2])
data['书名_split_3'][:5]
# 2.6删除不需要的列
data.drop(['书名','出版信息','当前价格','星级','评论数','星级_match','书名_split'],axis=1,inplace=True)
data.head(3)
版权声明:本文为sinat_38075329原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。