一,如何爬取网站中的文本
1.如下载某网站中的三国演义:“
https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md
”
(1)第一种爬取方式,直接输出在控制台上
# 引用requests库
import requests
# 下载《三国演义》第一回,我们得到一个对象,它被命名为res
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
# 把Response对象的内容以字符串的形式返回
novel=res.text
# 现在,可以打印小说了,但考虑到整章太长,只输出800字看看就好。
print(novel[:800])
(2)第二种爬取方式,以文本的方式保存下来。“如果没有指定保存路径则会保存在项目文件的根目录下”
# 引入requests库
import requests
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
res = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md’)
# 把Response对象的内容以字符串的形式返回
novel = res.text
# 创建一个名为《三国演义》的txt文档,指针放在文件末尾,追加内容
k = open(‘《三国演义》.txt’,’a+’)
# 写进文件中
k.write(novel)
# 关闭文档
k.close()
二,爬取网站中的图片。
以某网站中的图片为例:“
https://res.pandateacher.com/2019-01-12-15-29-33.png
”
{kind=link}
爬取方法如下:
#导入 requests 模块
import requests
#发送请求,并将结果赋值给res
res=requests.get("https://res.pandateacher.com/2019-01-12-15-29-33.png")
#把response对象的内容以二进制数据的形式返回
pic=res.content
#新建一个文件风景.jpg,这里的文件没加路径,他会被保存在程序运行的当前目录下
#图片内容需要以二进制的wb读写“具体什么文件需要什么方式读写还请大家参考open()函数”
photo=open("风景.jpg","wb")
#获取pic的二进制内容
photo.write(pic)
#关闭文件
photo.close()
三,爬取网站中的音频
以某音乐网站为例:”
https://static.pandateacher.com/Over%20The%20Rainbow.mp3
”
#代码如下
import requests
res=requests.get("https://static.pandateacher.com/Over%20The%20Rainbow.mp3")
pic=res.content
photo=open("音乐.MP3","wb")
photo.write(pic)
photo.close()
四,乱码问题
以上述小说为例
# 引用requests库
import requests
# 下载《三国演义》第一回,我们得到一个对象,它被命名为res
res = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md’)
# 定义Response对象的编码为gbk
res.encoding=’gbk’
# 把Response对象的内容以字符串的形式返回
novel=res.text
# 打印小说的前800个字
print(novel[:800])

为什么会乱码呢?
事情是这样的:首先,目标数据本身有它的数据类型,这个小说中的URL中的数据是“’utf-8”
“因为这个网页是某人写的所以某人知道”。获取目标数据后要知道相应的编码类型才能正确解码。
如果我们把第七行的代码gbk换成utf-8则运行正常了

这只是个示范,是为了让大家理解
res.encoding
的意义,也就是它能定义
Response
对象的编码类型。肯定有人会疑问为什么最上面的爬取方式中没有定义对象的编码类型也能正常爬取呢,这是因为目标数据本身的编码方式是未知的。用
requests.get()
发送请求后,我们会取得一个
Response
对象,其中,
requests
库会对数据的编码类型做出自己的判断。但是!这个判断有可能准确,也可能不准确。比如你发给我一张“法语”字条,我看不出来是什么语言,猜测可能是“俄语”,“德语”等。
如果它判断准确的话,我们打印出来的
response.text
的内容就是正常的、没有乱码的,那就用不到
res.encoding
;如果判断不准确,就会出现一堆乱码,那我们就可以去查看目标数据的编码,然后再用
res.encoding
把编码定义成和目标数据一致的类型即可。
总的来说,就是遇上文本的乱码问题,才考虑用
res.encoding
如果用一张图来总结,那就是这样的:
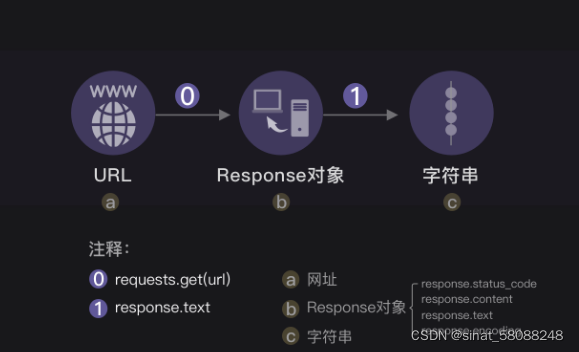
接下来为大家准备一些小干货:
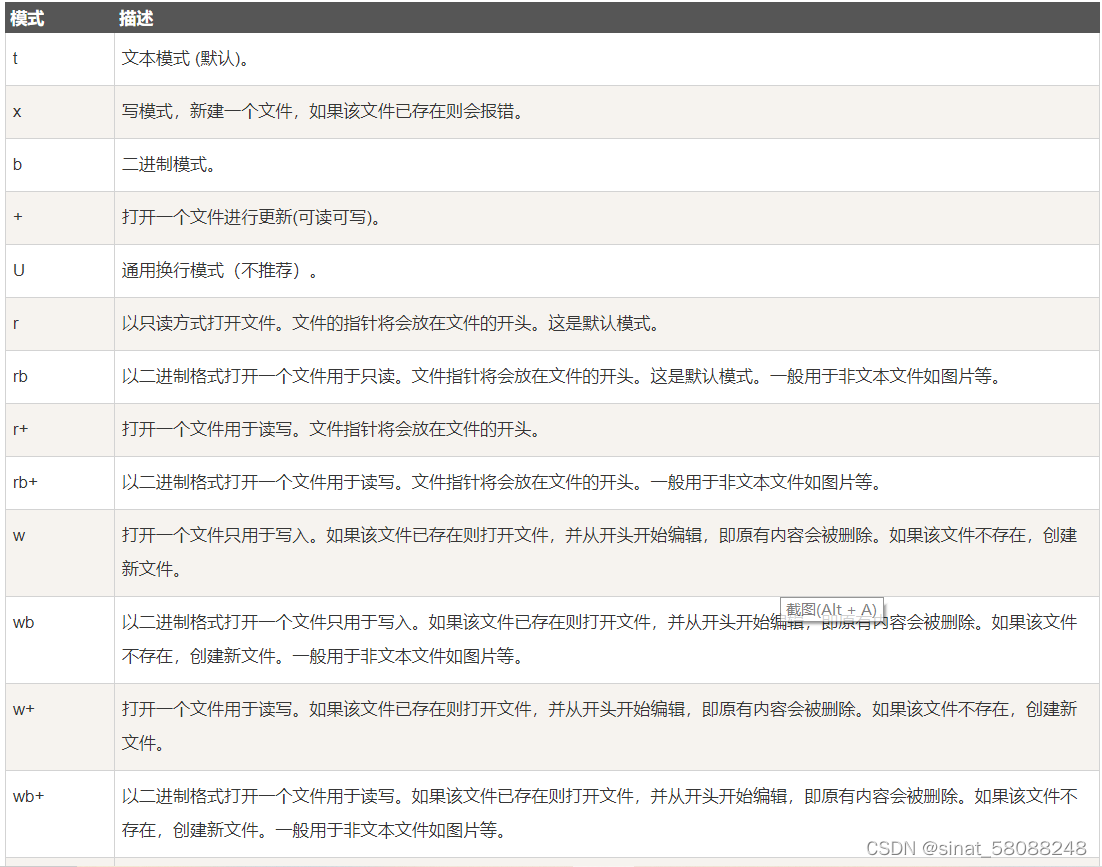
1.不同模式打开文件的完全列表:
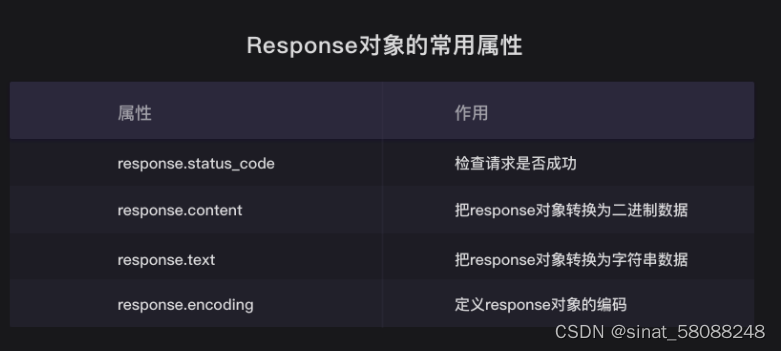
2.response对象的常用属性
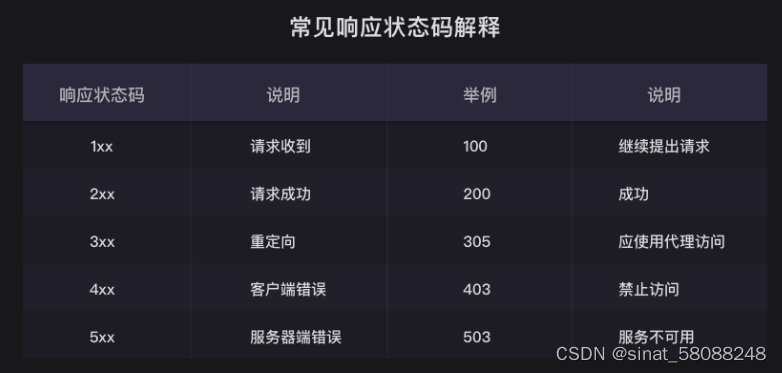
3.
常见响应状态码解释
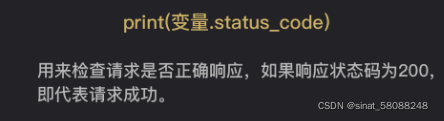
3.检查请求是否响应
4.目前常用的编码方式:gbk,gb2312,utf-8 “在乱码时可以逐个尝试下”