搜索与图论
第三章 搜索与图论
深搜与广搜
深搜:不断往前走,不撞南墙不回头
广搜:优先扩散
| – | 数据结构 | 空间 | – |
|---|---|---|---|
| DFS | stack |
O ( h ) O(h) O ( h ) |
– |
| BFS | queue |
O ( 2 h ) O(2^h) O ( 2 h ) |
具备最短路径 |
深搜
-
从解空间的搜索树进行理解,最重要的就是考虑一个能够
全遍历的合理顺序
-
需要注意
回溯
,要完全恢复现场 -
很多时候都是递归的形式

本题突出一个
剪枝
,就是判断有一条路肯定是走不通了,那就果断放弃
第一种做法:按行进行深搜,这是因为我们事先知道每一行只能放一个:
O
(
N
!
)
O(N!)
O
(
N
!)
#include <bits/stdc++.h>
using namespace std;
const int N = 2*10;
int n;
char g[N][N];
bool col[N],dg[N],udg[N];//用于标记是否能走的布尔数组,分别是列,对角线,副对角线
void dfs(int u){//参数里需要放一个表示“当前搜索进行到了哪一步”的标度,比如这里是“枚举第u行”
if(u == n){
for(int i = 0;i<n;i++) puts(g[i]);
puts("");
return ;
}
for(int i = 0;i<n;i++){//枚举第u行的每一列
if(!col[i] && !dg[u+i] && !udg[n-u+i]){//剪枝
//如果选择在这个点放皇后呢
g[u][i] = 'Q';
col[i] = dg[u+i] = udg[n-u+i] = true;//标明哪些列和对角线已经被占用了
dfs(u+1);//继续向前走
col[i] = dg[u+i] = udg[n-u+i] = false;//回溯
g[u][i] = '.';
}
}
}
int main(){
cin >> n;
for(int i = 0;i<n;i++){
for(int j = 0;j < n;j++){
g[i][j] = '.';
}
}
dfs(0);
return 0;
}
更原始的枚举顺序:一个格子一个格子进行枚举:
O
(
2
n
2
)
O(2^{n^2})
O
(
2
n
2
)
#include <bits/stdc++.h>
using namespace std;
const int N = 2*10;
int n;
char g[N][N];
bool col[N],dg[N],udg[N],row[N];//用于标记是否能走的布尔数组,分别是列,对角线,副对角线,行
void dfs(int x,int y,int s){//这里的标度就很复杂了,分别代表我们位于哪一行哪一列,共放了几个皇后
if(y == n) y = 0,x++;//表示已经到了行的最后一位
if(x == n){//表示搜索已结束
if(s == n){//如果皇后放够了,表示找到了一个解
for(int i = 0;i < n;i++) puts(g[i]);
puts("");
}
return ;
}
//不放皇后
dfs(x,y+1,s);//直接走
//放皇后
if(!row[x] && !col[y] && !dg[x+y] && !udg[x-y+n]){
g[x][y] = 'Q';
row[x] = col[y] = dg[x+y] = udg[x-y+n] = true;
dfs(x,y+1,s+1);
//回溯
row[x] = col[y] = dg[x+y] = udg[x-y+n] = false;
g[x][y] = '.';
}
}
int main(){
cin >> n;
for(int i = 0;i<n;i++){
for(int j = 0;j < n;j++){
g[i][j] = '.';
}
}
dfs(0,0,0);
return 0;
}
宽搜
-
一层一层搜,所以可以找所谓的最短路径
-
通常需要用到队列
模板:
//记录当前到达层数的宽搜
level = 0
初始值入队
while queue 不空:
size = queue.size()
while (size --) {
cur = queue.pop()
for 节点 in cur的所有相邻节点:
if 该节点有效且未被访问过:
queue.push(该节点)
}
level ++;
//给出的更一般的宽搜模板
初始值入队
while queue 不空{
t = 队头
“拓展”t //比如寻找相邻节点啥的
}
例题:

#include <cstdio>
#include <cstring>
#include <queue>
#include <utility>
using namespace std;
const int N = 1010;
typedef pair<int, int> PII;
int g[N][N];
bool flag[N][N]; //不回头条件,需要开一布尔数组来存哪些点已经到过了
int dx[4] = {0, 0, -1, 1}, dy[4] = {1, -1, 0, 0}; //用向量来表示向上下左右给
int n, m, k;
PII st, ed;
int bfs() {
st.first -= 1;
st.second -= 1;
ed.first -= 1;
ed.second -= 1;
//队列内储存坐标
queue<PII> q;
q.push(st); //起点进队
flag[st.first][st.second] = true;
int sec = 0; //记录层数
while (q.size()) { //当队列非空
int sz = q.size();
for (int i = 0; i < sz; i++) { //对当前这一层的每一个节点进行扩充
auto cur = q.front(); //取出要处理的节点
q.pop();
for (int o = 0; o < 4; o++) { //遍历上下左右四个方向
for (int t = 1; t <= k; t++) { //遍历所有步数
int x = cur.first + t * dx[o], y = cur.second + t * dy[o];
if (x < 0 || y < 0 || x >= m || y >= n || g[x][y]) {
break;
}
if (flag[x][y]) {
continue;
}
flag[x][y] = true;
PII ne = make_pair(x,y);
if(ne==ed){ //如果到达了终点
return ++sec;
}
q.push(ne);
}
}
}
sec++; //“层数”加一
}
return -1;
}
int main() {
scanf("%d %d %d", &n, &m, &k);
getchar();
memset(g, 0, sizeof(g));
memset(flag, 0, sizeof(flag));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
switch (getchar()) {
case '.':
g[j][i] = 0;
break;
case '#':
g[j][i] = 1;
break;
}
}
getchar();
}
scanf("%d %d %d %d", &(st.second), &(st.first), &(ed.second), &(ed.first));
printf("%d\n", bfs());
}
如果需要记录一下路径,就开一个数组,专门记录当前点是由哪个点拓展来,增加后代码
int g[N][N];
bool flag[N][N]; //不回头条件,需要开一布尔数组来存哪些点已经到过了
int dx[4] = {0, 0, -1, 1}, dy[4] = {1, -1, 0, 0}; //用向量来表示向上下左右给
int n, m, k;
PII st, ed,pre[N][N];//pre数组记录从哪来的
int bfs() {
st.first -= 1;
st.second -= 1;
ed.first -= 1;
ed.second -= 1;
//队列内储存坐标
queue<PII> q;
q.push(st); //起点进队
flag[st.first][st.second] = true;
int sec = 0; //记录层数
while (q.size()) { //当队列非空
int sz = q.size();
for (int i = 0; i < sz; i++) { //对当前这一层的每一个节点进行扩充
auto cur = q.front(); //取出要处理的节点
q.pop();
for (int o = 0; o < 4; o++) { //遍历上下左右四个方向
for (int t = 1; t <= k; t++) { //遍历所有步数
int x = cur.first + t * dx[o], y = cur.second + t * dy[o];
if (x < 0 || y < 0 || x >= m || y >= n || g[x][y]) {
break;
}
if (flag[x][y]) {
continue;
}
flag[x][y] = true;
pre[x][y] = cur;//表cur走到了(x,y)处
PII ne = make_pair(x,y);
if(ne==ed){ //如果到达了终点
return ++sec;
}
q.push(ne);
}
}
}
sec++; //“层数”加一
}
return -1;
}
树和图的存储
- 无向图就存储为双向边的有向图
-
邻接矩阵:用二维数组
g[
a
]
[
b
]
g[a][b]
g
[
a
]
[
b
]
存储
a到
b
a到b
a
到
b
这条边的信息,适合存储稠密的图 - 邻接表:类似拉链法的哈希表,每个节点拉出一个单链表,用于存储当前这个节点的所有邻居
下面都在讨论邻接表
代码实现,ACWING讲的是用数组模拟,也可以用stl的vector数组
vector<int> h[N]
进行模拟,甚至用
unordered_map<int,vector<int> > h
进行模拟
基本操作代码模板
const int N = 100010,M = N*2;
// 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点
int h[N], e[M], ne[M], idx;
// 添加一条边a->b
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
// 初始化
idx = 0;
memset(h, -1, sizeof h);
补充:带权重的邻接表:
int n,m;
int h[N],e[N],ne[N],w[N],idx;//邻接表,多开一个w[]数组来存储边的权重
void add(int a,int b,int c){//带权重的add算法
e[idx] = b,w[idx] = c,ne[idx] = h[a],h[a] = idx++;
}
树和图的dfs
bool st[N];//记录已经遍历过的点
void dfs(int u){//从编号为u的点开始深搜
//对u进行一些处理
st[u] = true;//标记,已到达
for(int i = h[u];i != -1;i = ne[i]){
int j = e[j];
if(!st[j]) dfs(j);
}
}
例题
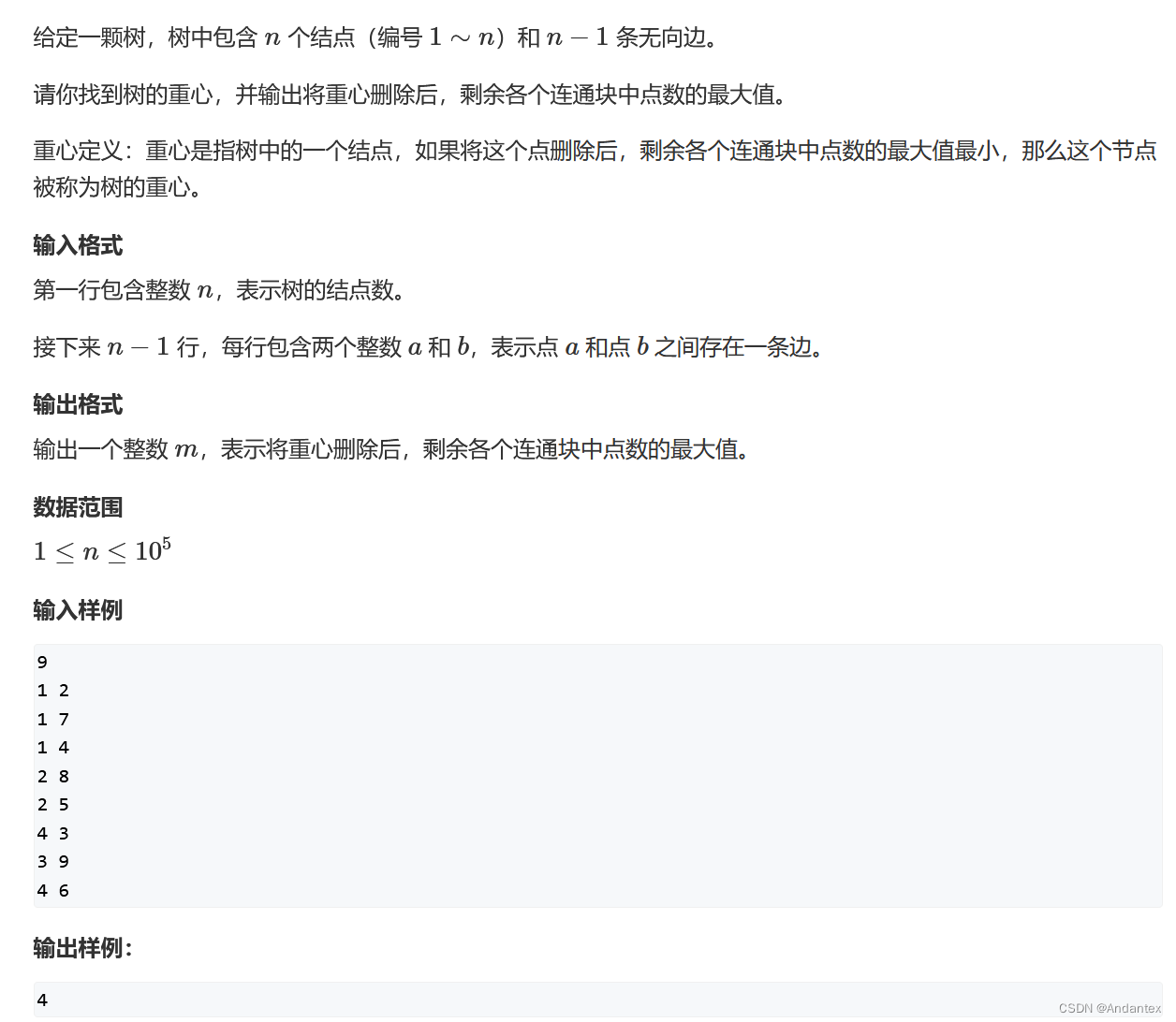
-
先分析一下“把每个点删除后连通块的最大值”:其实就是要求子树的大小
- 更换具体说,每个节点的子树大小可以由dfs自然求得
-
但是除了该节点的所有子树,还有一个连通块,就是拔掉以当前节点为根的树后,剩下的部分。这部分大小是
n−
Σ
s
o
n
i
n- \Sigma son_i
n
−
Σ
so
n
i
-
基本思路是对于每一个节点,都储存一下他的“最大模块数”。这样的话就需要用深搜来遍历整棵树
#include <bits/stdc++.h>
using namespace std;
const int N = 100010,M = N*2;
int n;
int h[N],e[M],ne[M],idx;
bool st[N];
int ans = N;//存储全局答案
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int dfs(int u){//从编号为u的点开始深搜,返回以u为根的子树大小
st[u] = true;//标记,已到达
int sum = 1,res = 0;//res是连通块最大数,sum是记数
for(int i = h[u];i != -1;i = ne[i]){
int j = e[j];
if(!st[j]){
int s = dfs(j);
res = max(res,s);
sum += s;//sum记录子树大小
}
}
res = max(res,n-sum);
ans = min(ans,res);
return sum;
}
int main(){
cin >>n;
memset(h,-1,sizeof(h));
for(int i = 0;i<n;i++){
int a,b;
cin >> a>> b;
add(a,b),add(b,a);//存储无向图
}
dfs(1);
cout << ans << endl;
}
树和图的bfs
套用模板
#include <bits/stdc++.h>
using namespace std;
int level = 0;
queue<int> q;
int bfs(){
level = 0;
q.push(1);
while(q.size()){
int size = q.size();
while (size --) {
int cur = q.front();
q.pop();
for(int i = h[cur];i!=-1;i=ne[i]){
int j = e[i];
//进行一些处理
if(!st[j]){
if(check(j)){
//满足终止条件,返回当前层数
return ++level;
}
st[j] = true;
q.push(j);//入队
}
}
}
level ++;
}
return -1;
}
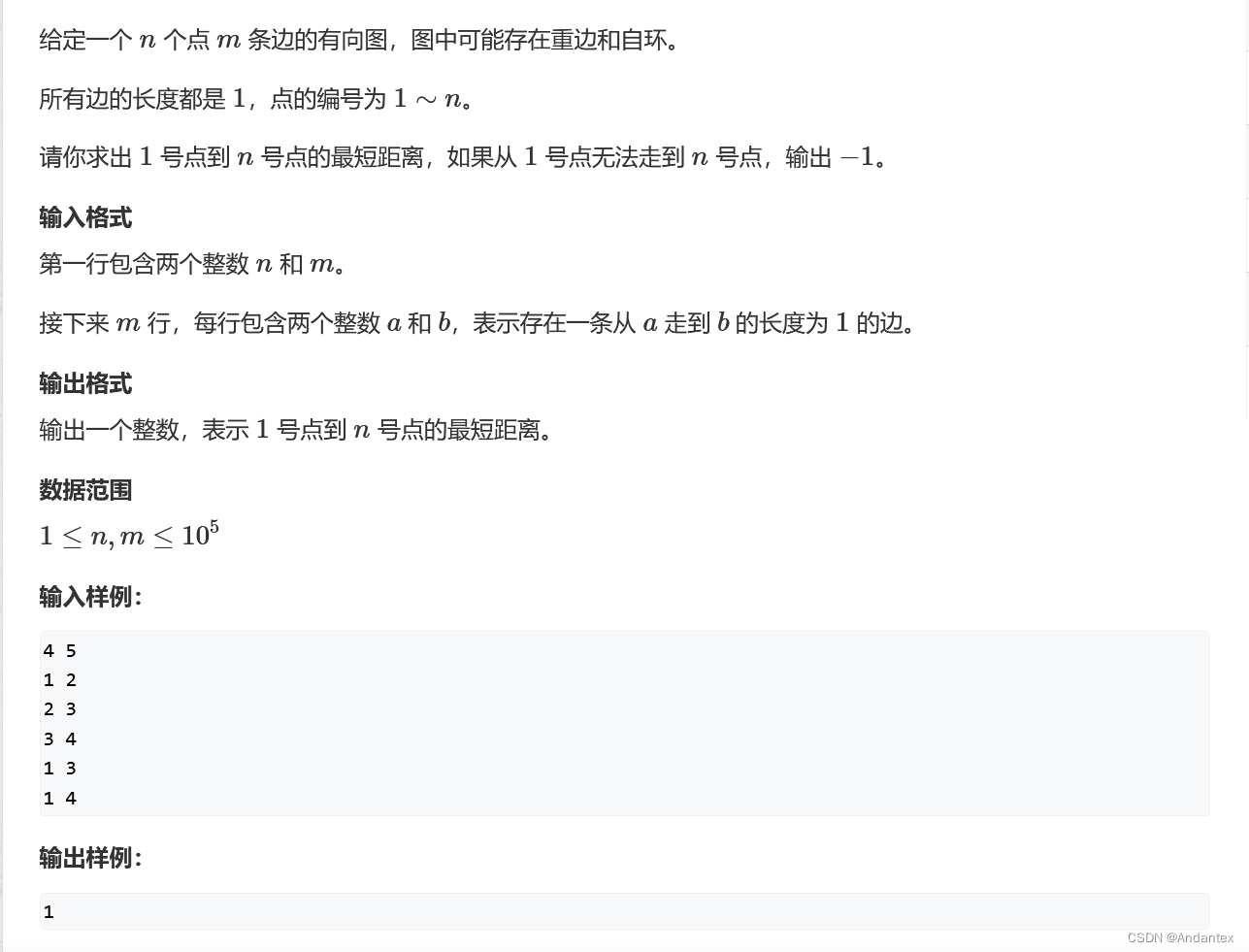
例题
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int n, m;
int h[N], e[N], ne[N], idx;
int d[N];
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
int bfs() {
memset(d, -1, sizeof d);//d用来存距离
queue<int> q;
d[1] = 0;
q.push(1);
while (q.size()) {
int t = q.front();
q.pop();
for (int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if (d[j] == -1) {
d[j] = d[t] + 1;
q.push(j);
}
}
}
return d[n];
}
int main() {
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
for (int i = 0; i < m; i ++ ) {
int a, b;
scanf("%d%d", &a, &b);
add(a, b);
}
cout << bfs() << endl;
return 0;
}
bfs应用:拓扑序
- 只有无环图有拓扑序
-
拓扑序列是这样的序列:在序列中
不
存在这样的对子
(a
,
b
)
s
.
t
.
在某条包含
a
,
b
的路径里,
b
位于起点而
a
位于终点
(a,b) \ s.t. \ 在某条包含a,b的路径里,b位于起点而a位于终点
(
a
,
b
)
s
.
t
.
在某条包含
a
,
b
的路径里,
b
位于起点而
a
位于终点
几个基本概念
- 某个点的度数:就是该点的边数
- 入度:箭头指向该点的边数
- 出度:箭头指出概念的边数
大致步骤
-
首先找到入度为0的点,入队
-
只要队不空,排出队头t,加入到拓扑序内
-
枚举t的所有出边t—>j
-
删除该边,并更新节点j的入度
-
如果j的入度已经是0了
- j入队
-
-
可以证明,如果图中有环,则环中不可能有入度为0的点,所以如果用以上操作后,图中有节点剩余,则不可能有拓扑序列
代码
int d[N];//d数组存放入度
queue<int> top;//该队列存储拓扑序的输出
bool topsort() {
queue<int> q;
for(int i = 1;i <= n;i++){
if(!d[i]) q.push(i);
}
while (q.size()) {
int t = q.front();
q.pop();
top.push(t);
for (int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
d[j]--;
if(!d[j]) q.push(j);
}
}
return (q.size() == n-1);
}
最短路问题
分类
-
单源最短路:一个起点
-
无负权边
-
朴素Dijkstra算法
O(
n
2
)
O(n^2)
O
(
n
2
)
适合稠密图 -
堆优化Dijkstra算法
O(
m
l
o
g
n
)
O(mlogn)
O
(
m
l
o
g
n
)
适合稀疏图
-
朴素Dijkstra算法
-
有负权边
-
Bellman-Ford
O(
n
m
)
O(nm)
O
(
nm
)
-
SPFA
一般O
(
m
)
,最坏
O
(
n
m
)
一般O(m),最坏O(nm)
一般
O
(
m
)
,最坏
O
(
nm
)
-
Bellman-Ford
-
无负权边
-
多源汇最短路:Floyd
O(
n
3
)
O(n^3)
O
(
n
3
)
难点:
建图
朴素Dijkstra算法
大致步骤
-
初始化距离 :以起点为一号点,初始化:
ds
t
[
1
]
=
0
;
d
i
s
t
[
.
.
.
]
=
+
∞
dst[1] = 0 \ ;dist[…] = + \infty
d
s
t
[
1
]
=
0
;
d
i
s
t
[
…
]
=
+
∞
-
初始化集合
ss
s
:s是所有当前已经确定最短距离的点 -
循环:
fo
r
i
i
n
r
a
n
g
e
(
1…
n
)
for \ i \ in \ range \ (1…n)
f
or
i
in
r
an
g
e
(
1…
n
)
就是循环n次-
拿出
tt
t
:不在集合
ss
s
中的
ds
t
[
t
]
dst[t]
d
s
t
[
t
]
值最小的点 -
把
tt
t
加入到
ss
s
之中 -
用
tt
t
更新别的点的距离-
对于所有
tt
t
的出边连接的节点
xx
x
-
if
d
s
t
[
x
]
>
d
i
s
t
[
t
]
+
w
if \ dst[x]>dist[t]+w
i
f
d
s
t
[
x
]
>
d
i
s
t
[
t
]
+
w
;其中
ww
w
是
t−
>
x
t->x
t
−
>
x
边的权重: -
更新
di
s
t
[
x
]
dist[x]
d
i
s
t
[
x
]
为更小值
-
-
对于所有
-
拿出
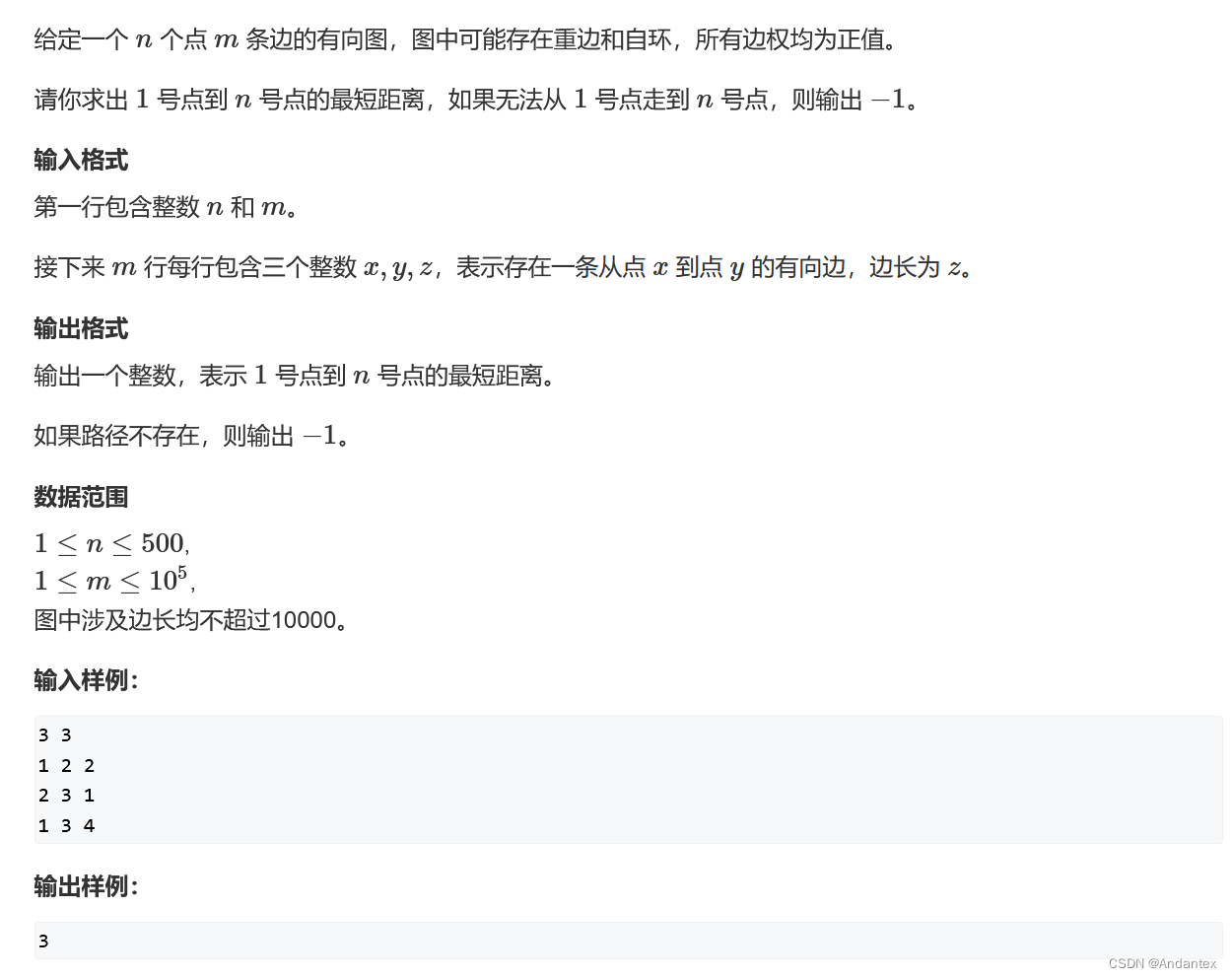
数据结构:由于适合稠密图,所以一般用邻接矩阵来存储
代码
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
int n,m;
int g[N][N];//邻接矩阵
int dist[N];//记录距离
bool st[N];//表示哪些点还未计算过最短路
int dijkstra(){
//初始化距离
memset(dist,0x3f,sizeof(dist));
dist[1] = 0;
for(int i = 0;i<n;i++){//迭代n次,以确保遍历所有的点
int t = -1;
for(int j = 1;j <= n;j++){
if(!st[j] && (t == -1 || dist[t] > dist[j])){//如果还没有最短距离
t = j;
}
}
st[t] = true;//入集合
for(int j = 1;j <= n;j++){
dist[j] = min(dist[j],dist[j] + g[t][j]);
}
}
if(dist[n] == 0x3f3f3f3f) return -1;//距离仍是正无穷,说明不连通
return dist[n];
}
int main(){
scanf("%d%d",&n,&m);
memset(g,0x3f,sizeof(g));//初始化邻接矩阵全为正无穷,为什么初始化成正无穷,则与算法的实现有关
while(m--){//读入图
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
g[a][b] = min(g[a][b],c);//面对重边 和 自环 的处理方式:每两点只保留最短的边
}
int t = dijkstra();
printf("%d\n",t);
return 0;
}
堆优化的Dijkstra算法
大致步骤
-
初始化距离 :以起点为一号点,初始化:
ds
t
[
1
]
=
0
;
d
i
s
t
[
.
.
.
]
=
+
∞
dst[1] = 0 \ ;dist[…] = + \infty
d
s
t
[
1
]
=
0
;
d
i
s
t
[
…
]
=
+
∞
-
初始化集合
ss
s
:s是所有当前已经确定最短距离的点 -
循环:
fo
r
i
i
n
r
a
n
g
e
(
1…
n
)
for \ i \ in \ range \ (1…n)
f
or
i
in
r
an
g
e
(
1…
n
)
-
拿出
tt
t
:不在集合
ss
s
中的
ds
t
[
t
]
dst[t]
d
s
t
[
t
]
值最小的点
在这里用小根堆优化,则减少了时间
-
把
tt
t
加入到
ss
s
之中 -
用
tt
t
更新别的点的距离-
对于所有
tt
t
的出边连接的节点
xx
x
-
if
d
s
t
[
x
]
>
d
i
s
t
[
t
]
+
w
if \ dst[x]>dist[t]+w
i
f
d
s
t
[
x
]
>
d
i
s
t
[
t
]
+
w
;其中
ww
w
是
t−
>
x
t->x
t
−
>
x
边的权重: -
更新
di
s
t
[
x
]
dist[x]
d
i
s
t
[
x
]
为更小值
-
-
对于所有
-
拿出
数据结构
- 稀疏矩阵:邻接表
-
堆:用STL里的优先队列
- 由于优先队列不存在修改的操作,所以修改时就是往堆里插入一个新元素,但是这就可能造成冗余
-
冗余的处理方式就是去查询
bo
o
l
s
t
[
]
bool \ st[]
b
oo
l
s
t
[
]
来判断是不是已经得到最小值了
代码
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
typedef pair<int ,int> PII;//由于既需要存距离,又需要存编号,所以搞一个有序对
//由于有序对的比大小函数是先比第一个再比第二个,所以第一个放距离
const int N = 10010;
int n,m;
int h[N],e[N],ne[N],w[N],idx;//邻接表,多开一个w[]数组来存储边的权重
int dist[N];//记录距离
bool st[N];//表示哪些点还未计算过最短路
void add(int a,int b,int c){//带权重的add算法
e[idx] = b,w[idx] = c,ne[idx] = h[a],h[a] = idx++;
}
int dijkstra(){
//初始化距离
memset(dist,0x3f,sizeof(dist));
dist[1] = 0;
priority_queue<PII, vector<PII>,greater<PII> > heap;//用优先队列,但是优先队列是大根堆,先调整一下
heap.push({0,1});//放入起点
while(heap.size()){
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if(st[ver]) continue;//发现冗余,跳过
st[ver] = true;//进入集合
for(int i = h[ver];i != -1;i = ne[i]){
int j = e[i];
if(dist[j] > distance + w[i]){//更新距离
dist[j] = distance + w[i];
heap.push({dist[j],j});
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;//距离仍是正无穷,说明不连通
return dist[n];
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof(h));//初始化邻接表
while(m--){//读入图
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
int t = dijkstra();
printf("%d\n",t);
return 0;
}
Bellman-Ford 算法
大体步骤:
-
循环 n 次
-
fo
r
所有边
(
a
,
b
,
w
)
for \ 所有边 (a,b,w)
f
or
所有边
(
a
,
b
,
w
)
(意思是从a走向b权重为w)-
更新距离
di
s
t
[
b
]
=
m
i
n
(
d
i
s
t
(
n
o
w
)
[
b
]
,
d
i
s
t
(
p
r
e
v
i
o
u
s
)
[
a
]
+
w
)
dist[b] = min(dist^{(now)}[b],dist^{(previous)}[a]+w)
d
i
s
t
[
b
]
=
min
(
d
i
s
t
(
n
o
w
)
[
b
]
,
d
i
s
t
(
p
re
v
i
o
u
s
)
[
a
]
+
w
)
思路上其实差不多
-
更新距离
-
注:
-
可以想到,如果图中存在
负权环
,则最短距离不存在(因为可以一直绕着负权环走) - 循环第k次的意义:从起点开始,经过不超过k条边的时候,最短距离是多少
-
注意:
更新距离的时候用的是上一次迭代的结果,而非当前
- 这是为了保持”循环k次“的意义,防止边之间”串联 “
进一步解释:比如给出这样的图
第一次迭代后,如果是一边遍历一边更新,则效果是
d
i
s
t
[
1
]
=
0
,
d
i
s
t
[
2
]
=
1
,
d
i
s
t
[
3
]
=
2
dist[1] = 0,dist[2] = 1,dist[3] = 2
d
i
s
t
[
1
]
=
0
,
d
i
s
t
[
2
]
=
1
,
d
i
s
t
[
3
]
=
2
但是这不是我们期望的结果,当改成用上一次的迭代结果,则效果是
d
i
s
t
[
1
]
=
0
,
d
i
s
t
[
2
]
=
1
,
d
i
s
t
[
3
]
=
3
dist[1] = 0,dist[2] = 1,dist[3] = 3
d
i
s
t
[
1
]
=
0
,
d
i
s
t
[
2
]
=
1
,
d
i
s
t
[
3
]
=
3
数据结构
-
直接开个结构,三元组,存
(a
,
b
,
w
)
(a,b,w)
(
a
,
b
,
w
)
- 然后开个数组,把边存下来就可
代码

本题是限制边数的,正好与算法中的循环次数k相对应
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510,M = 10010;
int n,m,k;//点数,边数,路径长度限制
int dist[N],backup[N];//距离,备份数组
struct Edge{
int a,b,w;
}edges[M];
int bellman_ford(){
memset(dist,0x3f,sizeof dist);
dist[1] = 0;
memset(backup,0x3f,sizeof backup);
backup[1] = 0;
for(int i = 0;i<k;i++){
memcpy(backup,dist,sizeof dist);
for(int j = 0;j<m;j++){
int a = edges[j].a,b = edges[j].b,w = edges[j].w;
dist[b] = min(dist[b],backup[a]+w);//只用上次迭代的结果进行备份
}
}
if(dist[n] > 0x3f3f3f3f/2) return -1;//判断大于一个比较大的数,这是因为负权边的存在,会导致无穷大被更新
return dist[n];
}
int main(){
scanf("%d%d%d",&n,&m,&k);
for(int i = 0;i<m;i++){
int a,b,w;
scanf("%d%d%d",&a,&b,&w);
edges[i] = {a,b,w};
}
int t = bellman_ford();
if(t == -1) puts("impossible");
else printf("%d\n",t);
}
SPFA算法
用队列对Bellman-Ford算法优化
-
观察我们用于更新的式子
di
s
t
[
b
]
=
m
i
n
(
d
i
s
t
(
n
o
w
)
[
b
]
,
d
i
s
t
(
p
r
e
v
i
o
u
s
)
[
a
]
+
w
)
dist[b] = min(dist^{(now)}[b],dist^{(previous)}[a]+w)
d
i
s
t
[
b
]
=
min
(
d
i
s
t
(
n
o
w
)
[
b
]
,
d
i
s
t
(
p
re
v
i
o
u
s
)
[
a
]
+
w
)
-
我们发现,事实上,在k,k+1次迭代之间(而非第k次迭代内),
di
s
t
k
+
1
[
b
]
dist^{k+1}[b]
d
i
s
t
k
+
1
[
b
]
变小的唯一可行能性是
di
s
t
i
[
a
]
dist^{i}[a]
d
i
s
t
i
[
a
]
变小了 - 这样追溯下去,实际上只需要自己变小的节点去更新其他节点
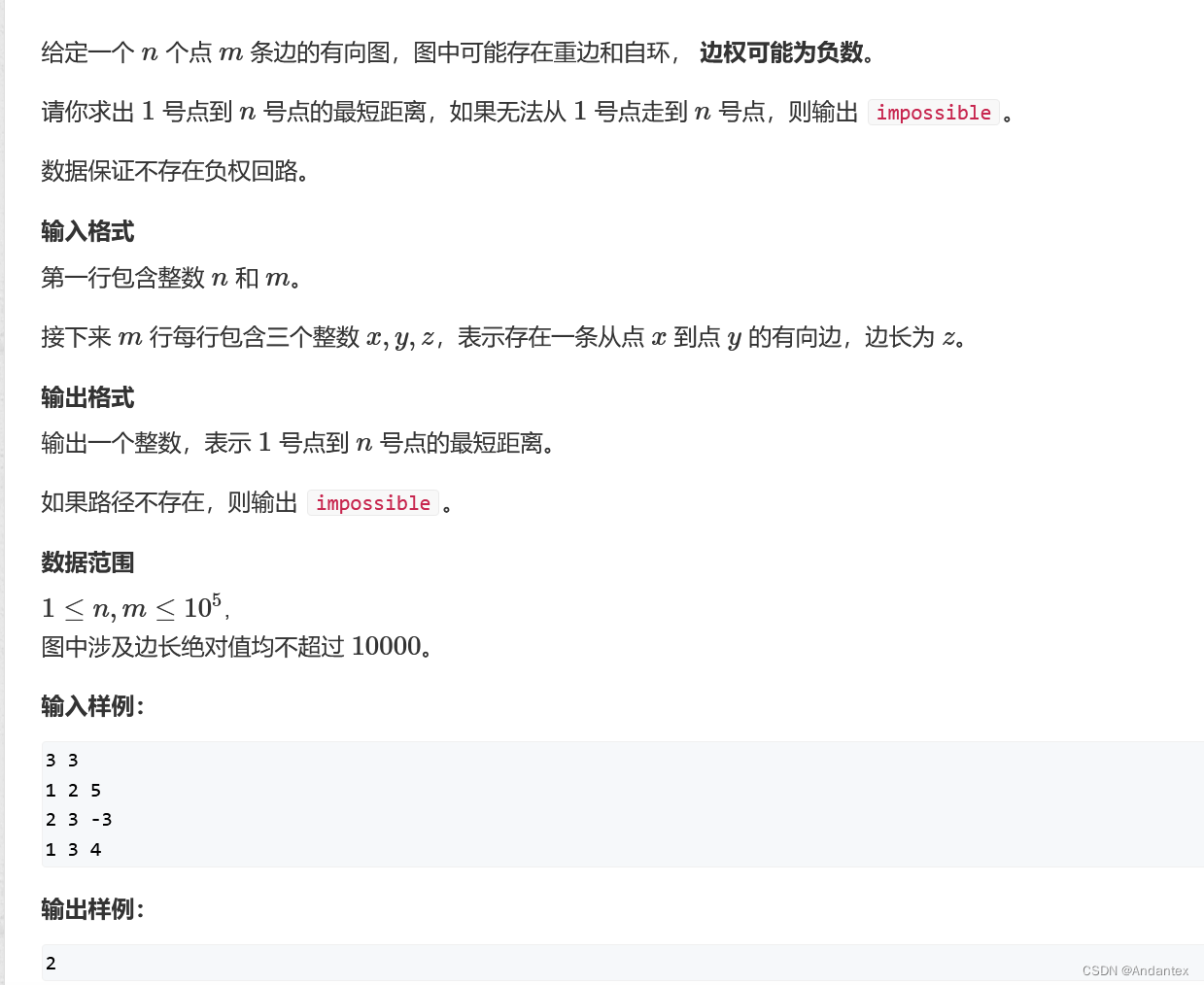
大致思路:
- 先把起点入队
-
循环:直到队列为空
- 取出队头
-
用队头更新所有队头的出边
- 如果更新成功,则把更新成功的节点加入队列
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
typedef pair<int,int> PII;
const int N = 100010;
int n,m;
int h[N],w[N],e[N],ne[N],idx;//邻接表
int dist[N];
bool st[N];//防止有重复的边放入
void add(int a,int b,int ww){
e[idx] = b,ne[idx] = h[a],w[idx] = ww,h[a] = idx++;
}
int spfa(){
memset(dist,0x3f,sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true;
while(q.size()){
int t = q.front();
q.pop();
st[t] = false;
for(int i = h[i];i!=-1;i = ne[i]){
int j = e[i];
if(dist[j]>dist[t]+w[i]){
dist[j] = dist[t]+w[i];
if(!st[j]){//防止重复放入
q.push(j);
st[j] = true;
}
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof h);
while(m--){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
int t = spfa();
if(t == -1) puts("impossible");
else printf("%d\n",t);
}
spfa判断负环:
- 维护一个cnt数组,表示从起点到当前点走了几条边
- cnt数组和dist数组同步更新
- 为了寻找起点可能在任意处的负环,需要在一开始把所有点都放入队列
int cnt[N];
bool spfa(){
queue<int> q;
for(int i = 0;i<n;i++){
q.push(i);
st[i] = true;
}
while(q.size()){
int t = q.front();
q.pop();
st[t] = false;
for(int i = h[i];i!=-1;i = ne[i]){
int j = e[i];
if(dist[j]>dist[t]+w[i]){
dist[j] = dist[t]+w[i];
cnt[j] = cnt[t]+1;//同步更新cnt数组
if(cnt[j] >= n) return true;//抽屉原理
if(!st[j]){//防止重复放入
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
Floyd算法
数据结构
- 邻接矩阵
大体思路:
-
fo
r
k
i
n
r
a
n
g
e
(
1…
n
)
for \ k \ in \ range(1…n)
f
or
k
in
r
an
g
e
(
1…
n
)
-
fo
r
i
i
n
r
a
n
g
e
(
1…
n
)
for \ i \ in \ range(1…n)
f
or
i
in
r
an
g
e
(
1…
n
)
-
fo
r
j
i
n
r
a
n
g
e
(
1…
n
)
for \ j \ in \ range(1…n)
f
or
j
in
r
an
g
e
(
1…
n
)
-
d[
i
,
j
]
=
m
i
n
(
d
[
i
,
j
]
,
d
[
i
,
k
]
+
d
[
k
,
j
]
)
d[i,j] = min(d[i,j],d[i,k]+d[k,j])
d
[
i
,
j
]
=
min
(
d
[
i
,
j
]
,
d
[
i
,
k
]
+
d
[
k
,
j
])
-
-
-
原理:动态规划
-
dp
(
i
,
j
,
k
)
dp(i,j,k)
d
p
(
i
,
j
,
k
)
表示从
ii
i
开始,只经过
1..k
1..k
1..
k
这些点,到达
jj
j
的最短路径

#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 210,INF = 1e9;
int n,m,Q;
int d[N][N];//邻接矩阵
void floyd(){
for(int k = 1;k <= n;k++){
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
d[i][j] = min(d[i][j],d[i][k]+d[k][j]);
}
}
}
}
int main(){
scanf("%d%d%d",&n,&m,&Q);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(i == j) d[i][j] = 0;
else d[i][j] = INF;
}
}
while(m--){
int a,b,w;
scanf("%d%d%d",&a,&b,&w);
d[a][b] = min(d[a][b],w);//别忘记处理重边
}
floyd();
while(Q--){
int a,b;
scanf("%d%d",&a,&b);
if(d[a][b] > INF/2) printf("%d\n",d[a][b]);
else puts("impossible");
}
return 0;
}
小总结:关于一些细节的判定
- 用邻接矩阵注意处理重边
- 遇到负权的图,最判断是否有路径是判断一个较大的数,不是直接与正无穷比较
最小生成树
最主要是无向图
-
Prim算法:与Dijkstra算法很像
-
朴素版Prim算法:
O(
n
2
)
O(n^2)
O
(
n
2
)
:稠密图 -
堆优化版Prim算法:
O(
m
l
o
g
n
)
O(mlogn)
O
(
m
l
o
g
n
)
:稀疏图(不常用)
-
朴素版Prim算法:
-
Kruskal算法:
O(
m
l
o
g
m
)
O(mlogm)
O
(
m
l
o
g
m
)
:稀疏图(常用)
朴素版Prim算法
一个贪心算法
- 把所有点到集合的距离初始化为正无穷,初始化一个集合,表示当前在连通块内的点
-
n次迭代
- 找到集合 外 距离最近的点t
- 把t加入到集合之中,并把最短距离对应的边,加入到生成树
-
用t更新其他点到
集合
的距离
基本上和Dijkstra一样
到集合距离的定义:
-
就是某点 到 集合内 所有边中,长度最小的边,的长度

#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510;
int n,m;
int g[N][N];
int dist[N];
bool st[N];
int prim(){
memset(dist,0x3f,sizeof dist);
int res = 0;
for(int i = 0;i < n;i++){
int t = -1;
for(int j = 1;j<=n;j++){
if(!st[i] && (t == -1 || dist[t] > dist[j])){
t = j;
}
}//选点
st[t] = true;//入集合
//在这里判断第是否是第一个点,其实意思是默认第一个点一开始就在集合中
if(i && dist[t] == 0x3f3f3f3f) return 0x3f3f3f3f;
if(i) res += dist[t];//先累加
for(int j = 1;j <= n;j++) dist[j] = min(dist[j],g[t][j]);//再更新,这是防止负权自环的扰乱
}
}
int main(){
scanf("%d%d",&n,&m);
memset(g,0x3f,sizeof g);
while(m--){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
g[a][b] = g[b][a] = min(g[a][b],c);
}
int t = prim();
if(t == 0x3f3f3f3f) puts("impossible");
else printf("%d\n",t);
return 0;
}
堆优化版的Prim算法(见堆优化的Dijkstra算法)
Kruskal算法
大致步骤
- 将所有边按权重从小到大排序
-
枚举所有边
(a
,
b
,
c
)
(a,b,c)
(
a
,
b
,
c
)
-
如果a,b不在同一个连通块内
-
将这条边加入集合

-
将这条边加入集合
-
如果a,b不在同一个连通块内
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n,m;
int p[N];//并查集
struct Edge{
int a,b,w;
bool operator< (const Edge &W)const {//重载运算符:按照边值大小排序
return w<W.w;
}
}edges[2*N];
int find(int x){//并查集功能:实现祖宗追溯
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal(){
//事先准备:排序边,构建并查集
sort(edges,edges+m);
for(int i = 1;i <= n;i++) p[i] = i;//全部孤立点
int res = 0,cnt = 0;//分别是最小生成树的权值和,以及树中节点个数
for(int i = 0;i < m;i++){
int a = edges[i].a,b = edges[i].b,w = edges[i].w;
a = find(a),b = find(b);//寻找祖宗
if(a!=b){//ab尚未在一个连通块内
p[a] = b;//加入同一个连通块
res += w;
cnt++;
}
}
if(cnt < n-1) return -1;
else return res;
}
int main(){
scanf("%d%d",&n,&m);
for(int i = 0;i < m;i++){
int a,b,w;
scanf("%d%d%d",&a,&b,&w);
edges[i] = {a,b,w};
}
int t = kruskal();
if(t == -1) puts("impossible");
else printf("%d\n",t);
}
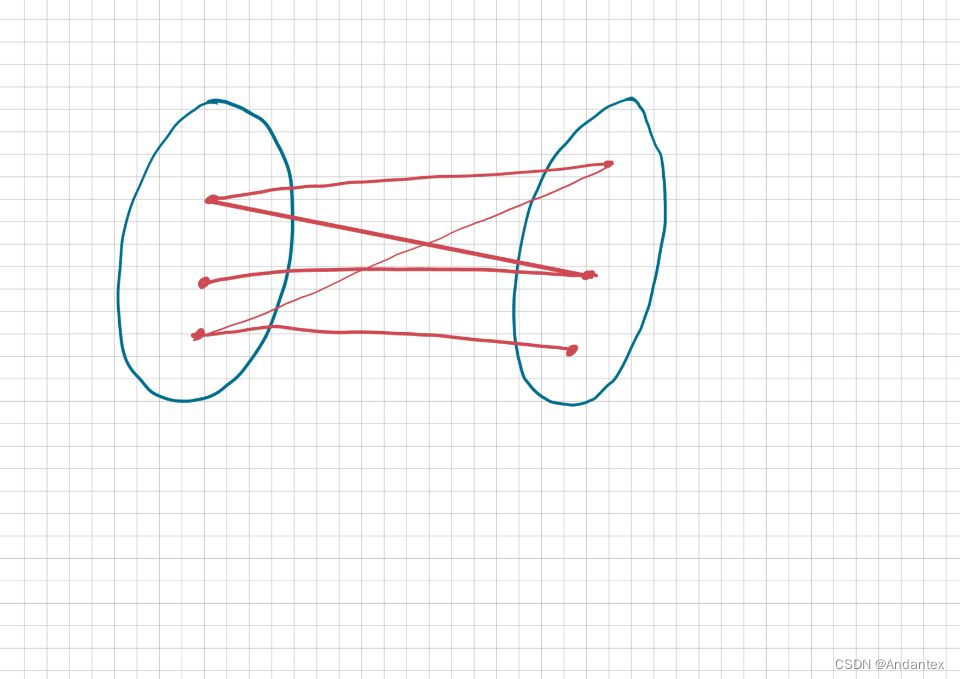
二分图
什么叫二分图?如下图,把节点划分为两个集合,且所有边都在集合之间
-
染色法:dfs
O(
m
+
n
)
O(m+n)
O
(
m
+
n
)
-
匈牙利算法:最坏
O(
m
n
)
O(mn)
O
(
mn
)
,实际运行时间远小于理论最坏
染色法
-
一个图是 二分图:当且仅当图中不含有奇数环
- 必要性:在奇数环中,任意选取一点作为起点,让其属于集合1.由于二分的要求,则其后继一定属于集合2。一直走下去,由于走过了奇数个点,得到起点必须属于集合2。矛盾。
-
充分性:进行一个构造,就是
染色
,给点染色,保证
一条边两侧的颜色不同
。具体步骤就是,对点进行遍历,如果遇到没有被染色的点,将其染成白色,再将其所有的邻居染成黑色。这就变成了,证明:只要图中不含有奇数环,则染色过程不会出现矛盾- 反证:结论的否命题引入:染色过程中出现了矛盾。这是因为,矛盾如果发生,则必须发生在一个点将要去染色一个已染色的邻居,这说明该点和即将下一个染色的点,一定处于一个环之中(易证)。这个环是奇数环是显然的,与前提矛盾。证毕
- 由以上论证,有 一个图是二分图,当且仅当其能被二染色
大致步骤:
-
遍历所有点
ii
i
-
if
ii
i
没有染色- 递归调用染色(dfs)
-
if
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010,M = 200020;
int n,m;
int h[N],e[M],ne[M],idx;
int color[N];//存储染色
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool dfs(int u,int c){//对一整个连通块染色
color[u] = c;//记录当前点颜色
for(int i = h[u];i!=-1;i = ne[i]){//遍历所有邻居
int j = e[i];
if(!color[j]){//如果没被染色
if(!dfs(j,3-c)) return false;//递归调用,颜色1变2,2变1
}
else if(color[j] == c) return false;//如果被染色,且矛盾
}
return true;
}
bool dye(){//对一整个图进行染色
for(int i = 1;i <= n;i++){
if(!color[i]){
if(!dfs(i,1)) return false;
}
}
return true;
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof h);
while(m--){
int a,b;
scanf("%d%d",&a,&b);
add(a,b),add(b,a);
}
bool flag = dye();
if(flag) puts("Yes");
else puts("No");
}
匈牙利算法
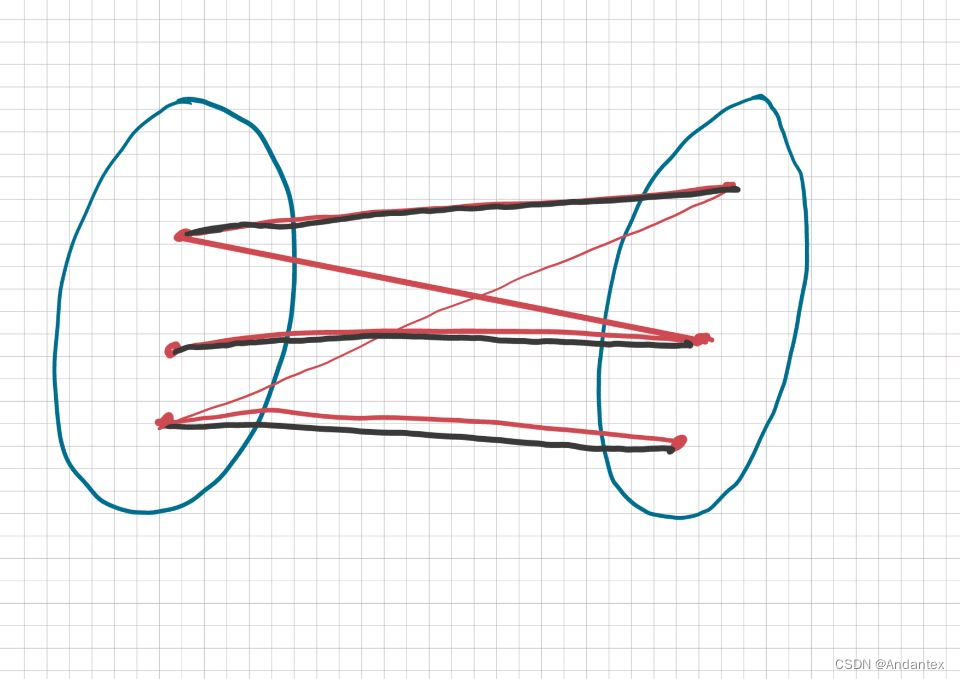
给定一个二分图,去找其最大匹配
匹配数量:选到边的数量
成功匹配:没有共用同一个点的边(不许搞三角关系)如下图,选择三条黑色的边,就是成功匹配
大体思路:贪心
-
从左1开始匹配
- 依次遍历出边,如果“出边”的点未被占用,则直接匹配,寻匹配左侧下一个节点
-
如果遍历该点所有出边,都被占用了,则进行协调:
- 找到第一个出边对应的点,该点被占用,则去找占用该点的左点去“协商”,看他能不能换一个
- 换不了?进行递归协商
-
如果都达到不了,放弃了

#include <bits/stdc++.h>
using namespace std;
const int N = 510,M = 1e5+10;
int n1,n2,m;//左点,右点,边数
int h[N],e[N],ne[N],idx;//邻接表
int match[N];//记录右侧点匹配了谁,即match[j] = i 表示右侧j匹配了i
bool st[N];//记录右侧点是否被占用
void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
//匈牙利算法部分,包括一个单点匹配函数和一个总体循环
bool find(int x){
for(int i = h[x];i!=-1;i=ne[i]){
int j = e[i];
if(!st[j]){//未被占用
st[j] = true;
if(match[j] == 0 || find(match[j])){//如果右侧点尚未匹配 或者 右侧匹配上的可以换人
match[j] = x;//直接匹配喵
return true;
}
}
}
return false;
}
int Xmacth(){
int res = 0;
for(int i = 1;i<=n1;i++){//遍历所有男生
memset(st,0,sizeof st);//初始化
if(find(i)) res++;
}
return res;
}
int main(){
scanf("%d%d%d",&n1,&n2,&m);
memset(h,-1,sizeof h);
while(m--){
int a,b;
scanf("%d%d",&a,&b);
add(a,b);
}
int t = Xmacth();
printf("%d\n",t);
}
证明见《算法导论》