完全背包问题
1.
问题描述
在上一篇里,有关01背包问题,我们在状态转移函数、是否需要放满、利用一维数组优化空间复杂度几个方面做了阐述。本篇要解决的是完全背包问题,描述如下:
有N种物品和一个容量为V 的背包,每种物品都有无限件可用。放入第i种物品的费用是Ci,价值是Wi。求解:将哪些物品装入背包,可使这些物品的耗费的费用总和不超过背包容量,且价值总和最大。
2.
贪心策略预处理
完全背包问题与01背包问题的不同点在于:
“每种物品有无限件”
,从这一点出发,对于两件物品i和j,如果Ci >= Cj,Wi < Wj,那么以直接去掉物品i,因为显然物品j更加物美价廉。
具体可以采用计数排序实现:设置大小为1到V的V个桶,将每个物品的容量放入对应的桶内。
- 如果同一个桶内有重复的数据,那么仅取较大的。
- 所有物品都装入桶之后,读取每个桶中的Wi的值,如果有减小的,则直接删去。
具体代码如下:
/**
* 预处理方法,去除肯定不可能被添加进背包的物品
* @param c[] 每件物品的容量
* @param w[] 每件物品的价值
* @param v 背包容量
* @return 被选中的物品的c-w对
*/
public HashMap<Integer,Integer> PreProcess(int[] c,int[] w,int v){
if(c.length != w.length){return null;}
else{
//tong[0]弃用,其余位置存放容量为1到v的v个桶
int[] tong = new int[v+1];
//第一个循环,完成桶的填充,在同一个桶中有多个元素时,选取较大的w[i]。
for(int i=0;i<c.length;i++){
tong[c[i]] = tong[c[i]]>w[i]?tong[c[i]]:w[i];
}
//第二个循环,按照桶的容量大小遍历,如果有下面的桶w小于上面的桶的,直接删去(置零)。
int temp = 0;
HashMap<Integer,Integer> hm = new HashMap<Integer,Integer>();
for(int j=1;j<tong.length;j++){
if(tong[j]==0)continue;
else if(tong[j]>temp){
temp = tong[j];
hm.put(j, tong[j]);
}
else tong[j] = 0;
}
//输出key-value对
Set<Integer> set = hm.keySet();
for(Integer g:set){
System.out.println(g+","+hm.get(g));
}
return hm;
}
}测试数据:
| 角标 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| c | 3 | 4 | 5 | 3 | 6 |
| w | 4 | 5 | 6 | 3 | 5 |
测试结果:
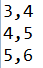
3.
方法一:常规思路
3.1
第一个状态转移函数
F[ i, v ]代表将前i种物品放入容量为v的背包中所能得到的最大价值。根据第i件物品放入的数量,可以得到如下的
状态转移函数
:
F
[
i
,
v
]
=
m
a
x
{
F
[
i
−
1
,
V
−
k
C
i
]
+
k
W
i
|
0
≤
k
C
i
≤
v
}
每个物品可以放的上限为
⌊
v
/
C
i
⌋
,为了得到F[ i,v ]需要遍历所有的 k ∈ (1…n) ,找出所有k值下F[ i , v ]的最大值。
伪代码如下:
F [0..V ] ←0
for i ← 1 to N
for v ← Ci to V
for k ← 0 to V/Ci
F [i, v] ← max(F [i-1,v-kCi] + kWi)
空间复杂度
O
(
V
N
)
、时间复杂度为
O
(
V
N
∑
N
i
=
1
V
/
C
i
)
实现代码如下:
public int[][] package_one(int[] c,int[] w,int v){
//预处理,得到处理过的数据c1[],c2[]。
HashMap<Integer,Integer> hm = PreProcess(c,w);
Set<Integer> set = hm.keySet();
int n = set.size();
int[] c1 = new int[n];
int[] w1 = new int[n];
Object[] c2 = set.toArray();
for(int i=0;i<c2.length;i++){
c1[i] = ((Integer)c2[i]).intValue();
w1[i] = hm.get(c1[i]);
}
//求解所有子问题
int[][] f = new int[n+1][v+1];
for(int i=1;i<n+1;i++){
for(int j=c1[i-1];j<v+1;j++){
for(int k=0;k<v/c1[i-1];k++){
if(j>=k*c1[i-1])
f[i][j] = f[i-1][j-k*c1[i-1]]+k*w1[i-1]>f[i][j]?f[i-1][j-k*c1[i-1]]+k*w1[i-1]:f[i][j];
}
}
}
return f;
}
测试代码:
public static void main(String[] args){
int c[]={3,4,5,3,6};
int w[]={4,5,6,3,5};
Package02 pack = new Package02();
int[][] f = pack.package_one(c, w,10);
for(int i=0;i<f.length;i++){
for(int j=0;j<f[0].length;j++){
System.out.print(f[i][j]+" ");
}
System.out.println();
}
}
测试数据共5件物品,根据前面的预处理方法,最终筛选出三件物品:
| 角标 | 1 | 2 | 3 |
|---|---|---|---|
| c | 3 | 4 | 5 |
| w | 4 | 5 | 6 |
最终所有子问题的集合
f
[
]
[
]
为:
|
f [ i ] [ v ] |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 4 | 4 | 4 | 8 | 8 | 8 | 8 | 8 |
| 2 | 0 | 0 | 0 | 0 | 5 | 5 | 8 | 9 | 9 | 9 | 13 |
| 3 | 0 | 0 | 0 | 0 | 0 | 6 | 8 | 9 | 9 | 11 | 13 |
3.2
物品选取路径的获取
与
“01背包问题”
不同,根据
状态转移函数
,需要计算出每一个物品用了多少个,即求出所有的k值。
举例如下:
根据上表,
f
[
3
]
[
10
]
=
m
a
x
{
f
[
2
]
[
10
]
,
f
[
2
]
[
5
]
+
6
,
f
[
2
]
[
0
]
+
12
}
得到
k
3
=
0
,即选取了0个物品3,继续处理子问题
f
[
2
]
[
10
]
。
f
[
2
]
[
10
]
=
m
a
x
{
f
[
1
]
[
10
]
,
f
[
1
]
[
6
]
+
5
,
f
[
1
]
[
2
]
+
10
}
得到
k
2
=
1
,即选取了1个物品2,继续处理子问题
f
[
1
]
[
6
]
。
f
[
1
]
[
6
]
=
m
a
x
{
f
[
0
]
[
6
]
,
f
[
0
]
[
3
]
+
4
,
f
[
0
]
[
0
]
+
8
}
得到
k
1
=
2
,即选取了2个物品1。
综上,选取了2个物品1和1个物品2。
伪代码如下:
v_0 = V
for i ← N to 1
for k ← 0 to V/ci
if(f[i][v_0] = f[i-1][v_0-k*ci]+k*wi){
print("选取了k个物品i")
v_0 = v_0 - k*ci;
break;
}
4.
方法二:转化为01背包
4.1
方法2.1
01背包问题是最基本的背包问题,我们可以考虑把完全背包问题转化为01背包问题来解。
最简单的想法是,考虑到第i种物品最多选⌊V /Ci⌋件,于是可以把第i种物品转化为⌊V /Ci⌋件费用及价值均不变的物品,然后求解这个01背包问题。这样的做法完全没有改进时间复杂度,但这种方法也指明了将完全背包问题转化为01背包问题的思路:将一种物品拆成多件只能选0件或1件的01背包中的物品。
考虑到存在将每个物品拆分为
V
/
C
i
的过程,拆分花费
O
(
N
∑
N
i
=
1
V
/
C
i
)
,一共拆分出
∑
N
i
=
1
V
/
C
i
个物品,而
“01背包问题”
花费
O
(
V
∑
N
i
=
1
V
/
C
i
)
,所以总的时间复杂度为:
O
(
(
V
+
N
)
∑
i
=
1
N
V
/
C
i
)
另外,方法2.1最大的缺点就在于,空间复杂度很大。
实现代码如下:
public int[] package_two(int[] c,int[] w,int v){
//预处理,得到处理过的数据c1[],w1[]。
HashMap<Integer,Integer> hm = PreProcess(c,w);
Set<Integer> set = hm.keySet();
int n = set.size();
int[] c1 = new int[n];
int[] w1 = new int[n];
Object[] c2 = set.toArray();
for(int i=0;i<c2.length;i++){
c1[i] = ((Integer)c2[i]).intValue();
w1[i] = hm.get(c1[i]);
}
// 第一步:生成新的数组,存放所有可能的背包
ArrayList<Integer> arr_1 = new ArrayList<Integer>();
ArrayList<Integer> arr_2 = new ArrayList<Integer>();
for(int i=1;i<n;i++){
for(int j=0;j<=v/c1[i-1];j++){
arr_1.add(c1[i-1]);
arr_2.add(w1[i-1]);
}
}
// 第二步:根据新的数组,利用01背包问题求解
int[] f = new int[v+1];
System.out.println("新的数组长度:"+arr_1.size());
for(int i=1;i<=arr_1.size();i++){
for(int j=v;j>=arr_1.get(i-1);j--){
f[j] = max(f[j],f[j-arr_1.get(i-1)]+arr_2.get(i-1));
}
}
return f;
}测试代码:
int[] f = pack.package_two(c,w,10);
for(int g:f){
System.out.println(g);
}输出结果:
| 角标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f[] | 0 | 0 | 0 | 4 | 5 | 5 | 8 | 9 | 10 | 12 | 13 |
4.2
方法2.2
为了节省空间,更高效的转化方法是:把第i种物品拆成费用为
C
i
2
k
、价值为
W
i
2
k
的
若干件
物品,其中k取遍满足
C
i
2
k
≤
V
的非负整数。
这是二进制的思想。因为,不管最优策略选几件第i种物品,其件数写成二进制后,总可以表示成若干个
2
k
件物品的和。这样一来就把每种物品拆成O(log ⌊V /Ci⌋)件物品,是一个很大的改进。
相较于方法2.1,利用二进制的思想,在物品的拆分过程中,我们无需开辟大容量的一维数组,仅需存放几个k值。而具体的实现过程可以建立一个ArrayList数组。代码如下:
public int[] package_three(int[] c,int[] w,int v){
// 预处理,得到处理过的数据c1[],w1[]。
HashMap<Integer,Integer> hm = PreProcess(c,w);
Set<Integer> set = hm.keySet();
int n = set.size();
int[] c1 = new int[n];
int[] w1 = new int[n];
Object[] c2 = set.toArray();
for(int i=0;i<c2.length;i++){
c1[i] = ((Integer)c2[i]).intValue();
w1[i] = hm.get(c1[i]);
}
// 第一步:存储所有的k值
ArrayList<ArrayList<Integer>> arr = new ArrayList<ArrayList<Integer>>();
for(int i=0;i<n;i++){
int temp = v/c1[i];
int k = -1;
while(temp>0){
arr.add(new ArrayList<Integer>());
k = (int) Math.floor(Math.log(temp)/Math.log(2));
arr.get(i).add(k);
//System.out.println("i= "+i+" k= "+k);
temp -= Math.pow(2, k);
}
}
//第二步:根据k值采用01背包策略
//array 存放每个物品的数量
//第一层循环:代表每一种物品;第二层循环:代表每一种物品的数量;第三层循环,代表每一次添加对应的所有背包容量。
int[] array = new int[n];
for(int i=0;i<n;i++){
for(int g:arr.get(i)){
array[i] += Math.pow(2, g);
}
//System.out.println(array[i]);
}
int[] f = new int[v+1];
for(int i=1;i<=n;i++){
for(int j=0;j<array[i-1];j++){
for(int k=c1[i-1];k<=v;k++){
f[k] = max(f[k-c1[i-1]]+w1[i-1],f[k]);
}
}
}
return f;
}
注意到拆分出k值的过程是在
O
(
N
)
的时间复杂度实现的,较之方法2.1中的
O
(
N
∑
N
i
=
1
V
/
C
i
)
有很大改进。
测试代码:
int[] f = pack.package_three(c, w, 10);
for(int g:f){
System.out.println(g);
}
输出结果:
| 角标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f[] | 0 | 0 | 0 | 4 | 5 | 6 | 8 | 9 | 10 | 12 | 13 |
5.
方法三:进一步优化
转换一下思路,再来看一下第一个状态转移函数:
F
[
i
,
v
]
=
m
a
x
{
F
[
i
−
1
,
V
−
k
C
i
]
+
k
W
i
|
0
≤
k
C
i
≤
v
}
仔细观察,在求解
F
[
i
,
v
]
的过程中,用到了若干个
F
[
i
−
1
,
0…
V
]
。这个方程的核心在于:若要求解当前
F
[
i
,
v
]
,我们遍历所有的第
i
−
1
层中需要的部分
F
[
i
−
1
,
V
−
k
C
i
]
,找出在该子问题的基础上,我们k取何值时所得到的
F
[
i
,
v
]
最大。
这个算法核心的缺陷就是:
对于
F
[
i
]
[
v
]
的求解,我们仅仅利用了第
i
−
1
层的数据
F
[
i
−
1
,
V
−
k
C
i
]
,而忽略了本层的数据
F
[
i
]
[
0…
v
−
1
]
。
在多层循环的过程中,可以保证前面的
F
[
]
[
]
一定是正确的,不管它使用了几个物品。所以同样的,
F
[
i
]
[
v
]
之前的子问题,包括
F
[
i
−
1
,
V
−
k
C
i
]
和
F
[
i
]
[
0…
v
−
1
]
都是正确的结果,都要用到我们的状态转移函数中去。
如何利用本层的数据?
F
[
i
]
[
0…
v
−
1
]
与
F
[
i
]
[
v
]
的共同点在于,它们都有可能包含有物品i,所以考虑将问题转化为“每次添加一个物品i的状态转移函数”
- 如果
F
[
i
]
[
v
]
包含物品i,那么
F
[
i
]
[
v
−
C
i
]
中物品i的数量一定比
F
[
i
]
[
v
]
少1。此时
F
[
i
,
v
]
=
F
[
i
]
[
v
−
C
i
]
+
W
i
。- 如果
F
[
i
]
[
v
]
不包含物品i,那么
F
[
i
,
v
]
=
F
[
i
−
1
,
v
]
当然,子问题
F
[
i
]
[
v
−
C
i
]
也可能包含有物品i,但是这个问题在前面的循环中已经被解决了,这里我们只需考虑在从
F
[
i
]
[
v
−
C
i
]
到
F
[
i
]
[
v
]
的过程中,物品i是否被再一次添加。
新的状态转移函数:
F
[
i
,
v
]
=
m
a
x
{
F
[
i
−
1
,
v
]
,
F
[
i
]
[
v
−
C
i
]
+
W
i
}
注意到该函数与
“01背包问题”
好像,但是需要注意:
对于二维数组实现的01背包问题,第二层循环(遍历背包容量)可以正序,也可以逆序。
一维数组的01背包问题,第二层循环必须逆序。
对于完全背包问题,无论二维还是一维数组实现,都必须正序。
具体留给大家思考。顺便写出一维情况下的状态转移函数:
F
[
v
]
=
m
a
x
{
F
[
v
]
,
F
[
v
−
C
i
]
+
W
i
}
实现代码:
public int[] package_four(int[] c,int[] w, int v){
// 预处理,得到处理过的数据c1[],w1[]。
HashMap<Integer,Integer> hm = PreProcess(c,w);
Set<Integer> set = hm.keySet();
int n = set.size();
int[] c1 = new int[n];
int[] w1 = new int[n];
Object[] c2 = set.toArray();
for(int i=0;i<c2.length;i++){
c1[i] = ((Integer)c2[i]).intValue();
w1[i] = hm.get(c1[i]);
}
int[] f = new int[v+1];
for(int i=1;i<=n;i++){
for(int j=c1[i-1];j<=v;j++){
f[j] = max(f[j],f[j-c1[i-1]]+w1[i-1]);
}
}
return f;
}
就是这么简单 =。=
测试代码:
int[] f = pack.package_four(c, w, 10);
for(int g:f){
System.out.println(g);
}
测试结果:
| 角标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f[] | 0 | 0 | 0 | 4 | 5 | 6 | 8 | 9 | 10 | 12 | 13 |
6.
总结
自己动手给出了三种算法的具体java实现过程,着实感受到了算法的改进对于工作量减少的重要性。完整的代码见:
http://download.csdn.net/detail/siyu1993/9660245
本文内容部分转载自
“背包问题九讲”