sql进阶教程
第一章、神奇的sql
1.1 CASE 表达式
CASE 表达式概述
语法:
-- 简单CASE 表达式
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
-- 搜索CASE 表达式
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
简单 CASE 表达式能写的条件,搜索 CASE 表达式也能写,所以一般采用搜索CASE表达式的写法。
在发现为真的 WHEN 子句时, CASE 表达式的真假值判断就会中止, 而剩余的 WHEN 子句会被忽略。
注意事项
- 统一各分支返回的数据类型,一定要注意 CASE 表达式里各个分支返回的数据类型是否一致。
- 不要忘了写 END,忘记了会有语法错误。
-
养成写 ELSE 子句的习惯与 END 不同, ELSE 子句是可选的, 不写也不会出错。 不写 ELSE 子
句时, CASE 表达式的执行结果是 NULL 。
将已有编号方式转换为新的方式并统计

-- 把县编号转换成地区编号(1)
SELECT CASE pref_name
WHEN '德岛' THEN '四国'
WHEN '香川' THEN '四国'
WHEN '爱媛' THEN '四国'
WHEN '高知' THEN '四国'
WHEN '福冈' THEN '九州'
WHEN '佐贺' THEN '九州'
WHEN '长崎' THEN '九州'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
GROUP BY CASE pref_name
WHEN '德岛' THEN '四国'
WHEN '香川' THEN '四国'
WHEN '爱媛' THEN '四国'
WHEN '高知' THEN '四国'
WHEN '福冈' THEN '九州'
WHEN '佐贺' THEN '九州'
WHEN '长崎' THEN '九州'
ELSE '其他' END;
用一条 SQL 语句进行不同条件的统计
进行不同条件的统计是 CASE 表达式的著名用法之一。
往存储各县人口数量的表 PopTbl 里添加上“性别”列, 然后求按性别、 县名汇总的人数。
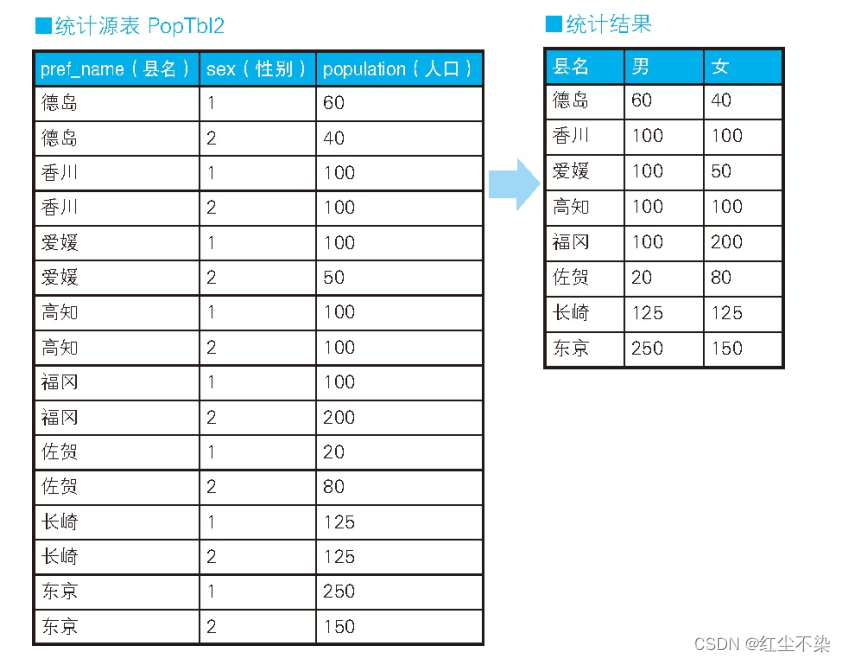
-- 男性人口
SELECT pref_name,
SUM(population)
FROM PopTbl2
WHERE sex = '1'
GROUP BY pref_name;
-- 女性人口
SELECT pref_name,
SUM(population)
FROM PopTbl2
WHERE sex = '2'
GROUP BY pref_name;
SELECT pref_name,
-- 男性人口
SUM( CASE WHEN sex = '1' THEN population ELSE 0 END) AS cnt_m,
-- 女性人口
SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) AS cnt_f
FROM PopTbl2
GROUP BY pref_name;
上面这段代码所做的是, 分别统计每个县的“男性”(即 ‘1’ ) 人数和“女性”(即 ‘2’ ) 人数。 也就是说, 这里是将“行结构”的数据转换成了“列结构”的数据。 除了 SUM , COUNT 、 AVG 等聚合函数也都可以用于将行结构的数据转换成列结构的数据。
新手用 WHERE 子句进行条件分支, 高手用 SELECT 子句进行条件分支。
用 CHECK 约束定义多个列的条件关系
CASE 表达式和 CHECK 约束是很般配的一对组合。
假设某公司规定“女性员工的工资必须在 20 万日元以下”, 而在这个公司的人事表中, 这条无理的规定是使用 CHECK 约束来描述的, 代码如下所示。
CONSTRAINT check_salary CHECK (
CASE WHEN sex = '2'
THEN
CASE WHEN salary <= 200000 THEN 1
ELSE 0
END
ELSE 1
END = 1
)
CASE 表达式被嵌入到 CHECK 约束里, 描述了“如果是女性员工, 则工资是 20 万日元以下”这个命题。 在命题逻辑中, 该命题是叫作蕴含式(conditional) 的逻辑表达式, 记作 P → Q
蕴含式和逻辑与的区别。逻辑与也是一个逻辑表达式,意思是P且Q, 记作 P ∧ Q。 用逻辑与改写的CHECK 约束如下所示。
CONSTRAINT check_salary CHECK( sex = '2' AND salary <= 200000 )
要想让逻辑与 P ∧ Q 为真, 需要命题 P 和命题 Q 均为真, 或者一个为真且另一个无法判定真假。
要想让蕴含式 P → Q 为真, 需要命题 P 和命题 Q 均为真, 或者 P 为假, 或者 P 无法判定真假。
蕴含式在员工性别不是女性(或者无法确定性别) 的时候为真, 可以说相比逻辑与约束更加宽松。
在 UPDATE 语句里进行条件分支
例子1:
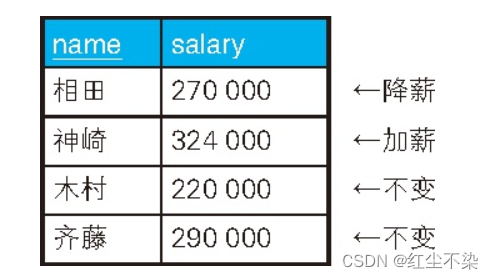
假设现在需要根据以下条件对该表的数据进行更新。
- 对当前工资为 30 万日元以上的员工, 降薪 10%。
- 对当前工资为 25 万日元以上且不满 28 万日元的员工, 加薪20%。
按照这些要求更新完的数据应该如下表所示。
-- 用CASE 表达式写正确的更新操作
UPDATE Salaries
SET salary = CASE WHEN salary >= 300000
THEN salary * 0.9
WHEN salary >= 250000 AND salary < 280000
THEN salary * 1.2
ELSE salary
END;
SQL 语句最后一行的 ELSE salary 非常重要, 必须写上。 因为如果没有它, 条件 1 和条件 2 都不满足的员工的工资就会被更新成 NULL 。 如果 CASE 表达式里没有明确指定 ELSE 子句, 执行结果会被默认地处理成 ELSE NULL 。
例子2:
通常, 当我们想调换主键值 a 和 b 时, 需要将主键值临时转换成某个中间值。 使用这种方法时需要执行 3 次 UPDATE 操作, 但是如果使用 CASE 表达式, 1 次就可以做到。
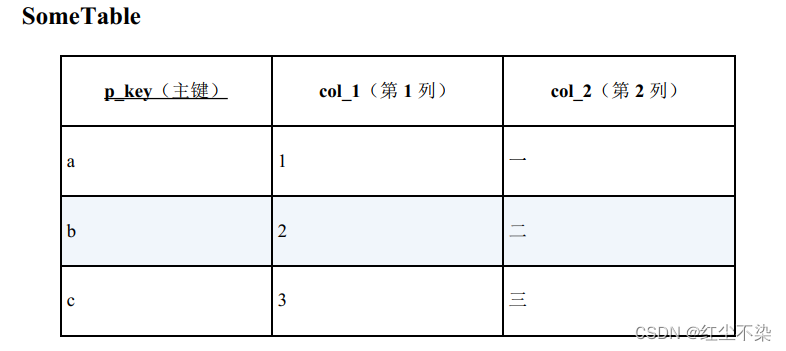
-- 用CASE 表达式调换主键值
UPDATE SomeTable
SET p_key = CASE WHEN p_key = 'a' THEN 'b'
WHEN p_key = 'b' THEN 'a'
ELSE p_key
END
WHERE p_key IN ('a', 'b');
表之间的数据匹配
与 DECODE 函数等相比, CASE 表达式的一大优势在于能够判断表达式。 在 CASE 表达式里,可以使用 BETWEEN 、 LIKE和 < 、 > 等便利的谓词组合, 以及能嵌套子查询的 IN 和 EXISTS 谓词。
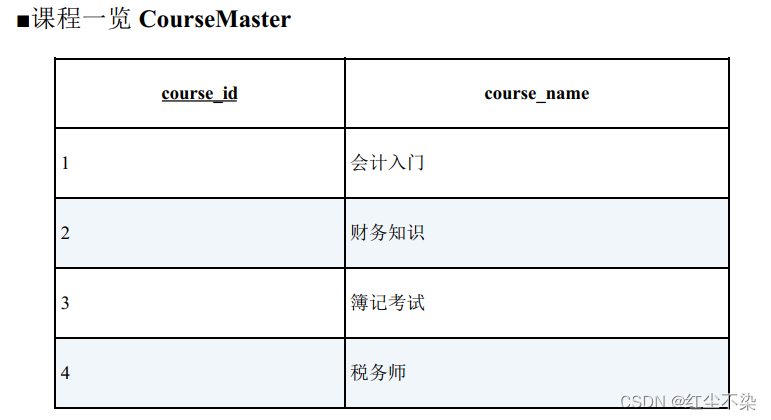
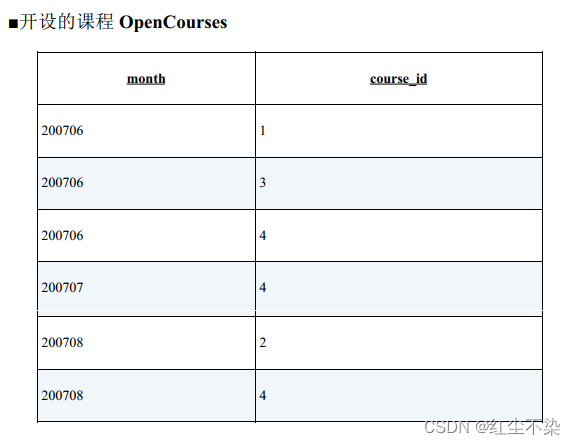
用这两张表来生成下面这样的交叉表, 以便于一目了然地知道每个月开设的课程。
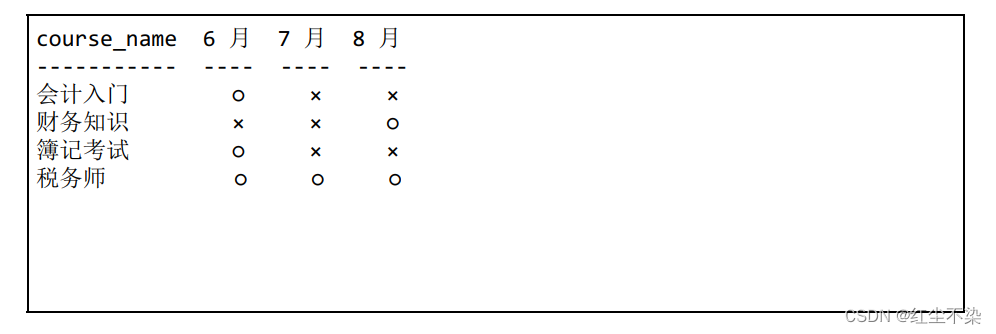
-- 表的匹配:使用IN 谓词
SELECT course_name,CASE
WHEN course_id IN (SELECT course_id
FROM OpenCourses
WHERE month = 200706)
THEN '○'
ELSE '×'
END AS "6 月",
CASE
WHEN course_id IN (SELECT course_id
FROM OpenCourses
WHERE month = 200707)
THEN '○'
ELSE '×'
END AS "7 月",
CASE
WHEN course_id IN (SELECT course_id
FROM OpenCourses
WHERE month = 200708)
THEN '○'
ELSE '×'
END AS "8 月"
FROM CourseMaster;
-- 表的匹配: 使用EXISTS 谓词
SELECT CM.course_name,CASE
WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200706
AND OC.course_id = CM.course_id)
THEN '○'
ELSE '×'
END AS "6 月",
CASE
WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200707
AND OC.course_id = CM.course_id)
THEN '○'
ELSE '×'
END AS "7 月",
CASE
WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200708
AND OC.course_id = CM.course_id)
THEN '○'
ELSE '×'
END AS "8 月"
FROM CourseMaster CM;
无论使用 IN 还是 EXISTS , 得到的结果是一样的, 但从性能方面来说, EXISTS 更好。 通过 EXISTS 进行的子查询能够用到“month,course_id ”这样的主键索引。
在 CASE 表达式中使用聚合函数
例子:
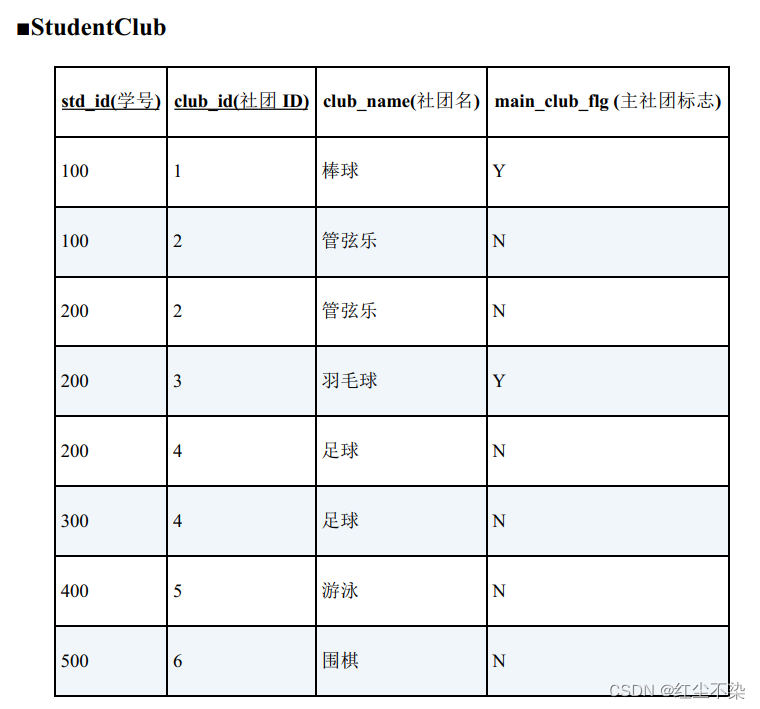
- 获取只加入了一个社团的学生的社团 ID。
- 获取加入了多个社团的学生的主社团 ID。
-- 条件1 : 选择只加入了一个社团的学生
SELECT std_id, MAX(club_id) AS main_club
FROM StudentClub
GROUP BY std_id
HAVING COUNT(*) = 1;
-- 条件2 : 选择加入了多个社团的学生
SELECT std_id, club_id AS main_club
FROM StudentClub
WHERE main_club_flg = 'Y' ;
CASE 表达式写法
SELECT std_id,
CASE
-- 只加入了一个社团的学生
WHEN COUNT(*) = 1
THEN MAX(club_id)
ELSE MAX(CASE
WHEN main_club_flg = 'Y'
THEN club_id
ELSE NULL
END)
END AS main_club
FROM StudentClub
GROUP BY std_id;
执行结果

这条 SQL 语句在 CASE 表达式里使用了聚合函数, 又在聚合函数里使用了 CASE 表达式。
CASE 表达式用在 SELECT 子句里时,既可以写在聚合函数内部, 也可以写在聚合函数外部。
新手用 HAVING 子句进行条件分支, 高手用 SELECT 子句进行条件分支。
本节要点
作为表达式, CASE 表达式在执行时会被判定为一个固定值, 因此它可以写在聚合函数内部; 也正因为它是表达式, 所以还可以写在SELECE 子句、 GROUP BY 子句、 WHERE 子句、 ORDER BY 子句里。 简单点说, 在能写列名和常量的地方, 通常都可以写 CASE 表达式。
- 在 GROUP BY 子句里使用 CASE 表达式, 可以灵活地选择作为聚合的单位的编号或等级。 这一点在进行非定制化统计时能发挥巨大的威力。
- 在聚合函数中使用 CASE 表达式, 可以轻松地将行结构的数据转换成列结构的数据。
- 相反, 聚合函数也可以嵌套进 CASE 表达式里使用。
- 相比依赖于具体数据库的函数, CASE 表达式有更强大的表达能力和更好的可移植性。
- 正因为 CASE 表达式是一种表达式而不是语句, 才有了这诸多优点。
1.2 自连接的用法
面向集合语言SQL
SQL通常在不同的表或者视图间进行连接运算, 但是也可以对相同的表进行“自连接”运算。
SQL 的连接运算根据其特征的不同, 有着不同的名称, 如内连接、外连接、 交叉连接等。 一般来说, 这些连接大都是以不同的表或视图为对象进行的, 但针对相同的表或相同的视图的连接也并没有被禁止。 针对相同的表进行的连接被称为“自连接”(self join) 。
可重排列、 排列、 组合
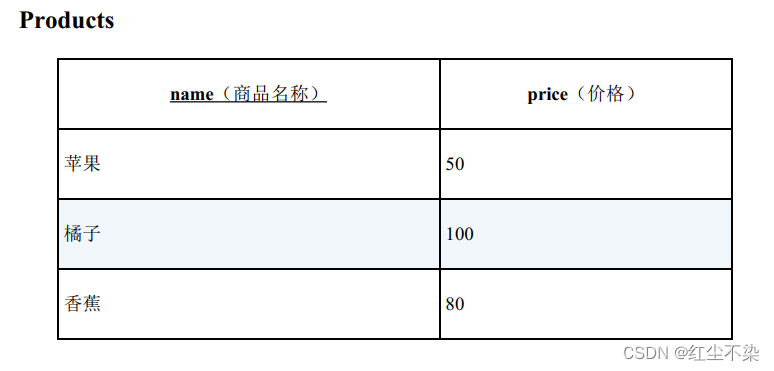
获取这些商品的组合,组合其实分为两种类型。 一种是有顺序的有序对(ordered pair) , 另一种是无顺序的无序对(unordered pair)。
有序对用尖括号括起来,如 <1, 2>; 无序对用花括号括起来, 如 {1, 2}。 在有序对里, 如果元素顺序相反, 那就是不同的对, 因此 <1, 2> ≠ <2, 1> ; 而无序对与顺序无关, 因此 {1, 2} = {2, 1}。
这两类分别对应着“排列”和“组合”。
-- 用于获取可重排列的SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;
执行结果
name_1 name_2
------ ------
苹果 苹果
苹果 橘子
苹果 香蕉
橘子 苹果
橘子 橘子
橘子 香蕉
香蕉 苹果
香蕉 橘子
香蕉 香蕉
排除掉由相同元素构成的对。
-- 用于获取排列的SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name;
执行结果
name_1 name_2
------ ------
苹果 橘子
苹果 香蕉
橘子 苹果
橘子 香蕉
香蕉 苹果
香蕉 橘子
P1 和 P2 ,来自一张实体表,只是在sql中的名称不一样。相同的表也可以看着两个不同的集合,按条件进行集合连接。 相同的表的自连接和不同表间的普通连接并没有什么区别。
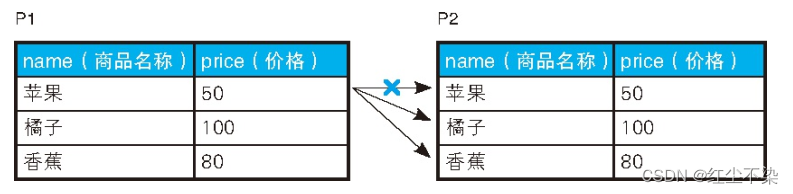
-- 用于获取组合的SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name > P2.name;
执行结果
name_1 name_2
------ ------
苹果 橘子
香蕉 橘子
香蕉 苹果
P1 和 P2进行连接,按字符顺序排列各商品, 只与“字符顺序比自己靠前”的商品进行配对, 结果行数为组合。
使用等号“=”以外的比较运算符, 如“<、 >、 <>”进行的连接称为“非等值连接”。 这里将非等值连接与自连接结合使用了, 因此称为“非等值自连接”。
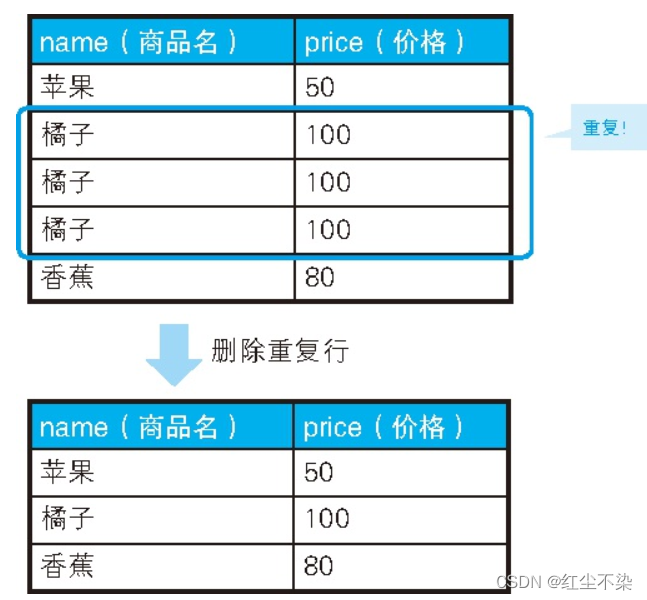
删除重复行
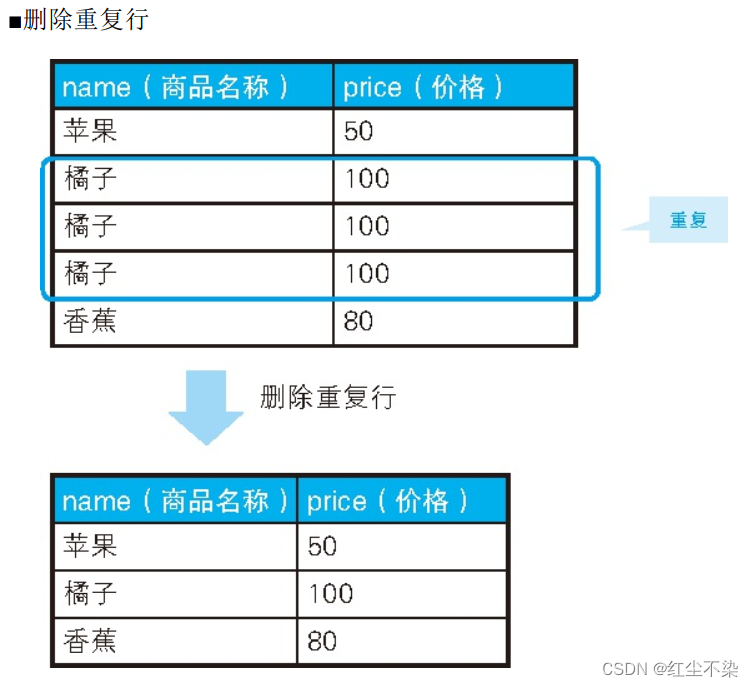
通常, 如果重复的列里不包含主键, 就可以用主键来处理, 但像这道例题一样所有的列都重复的情况, 则需要使用由数据库独自实现的行 ID。
-- 用于删除重复行的SQL 语句(1) : 使用极值函数
DELETE FROM Products P1
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE P1.name = P2. name
AND P1.price = P2.price ) ;
子查询会比较两个集合 P1 和 P2, 然后返回商品名称和价格都相同的行里最大的rowid 所在的行。然后会删除重复行中行id小的重复行,保留行id最大的重复行。
-- 用于删除重复行的SQL 语句(2) : 使用非等值连接
DELETE FROM Products P1
WHERE EXISTS ( SELECT *
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price
AND P1.rowid < P2.rowid );
查找局部不一致的列
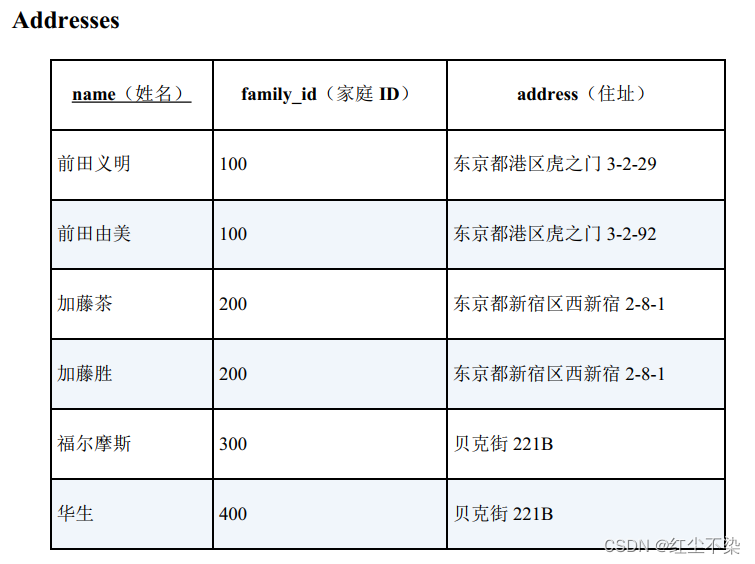
是同一家人但住址却不同的记录(家庭ID相同,住址不同)
-- 用于查找是同一家人但住址却不同的记录的SQL 语句
SELECT DISTINCT A1.name, A1.address
FROM Addresses A1, Addresses A2
WHERE A1.family_id = A2.family_id
56AND A1.address <> A2.address ;
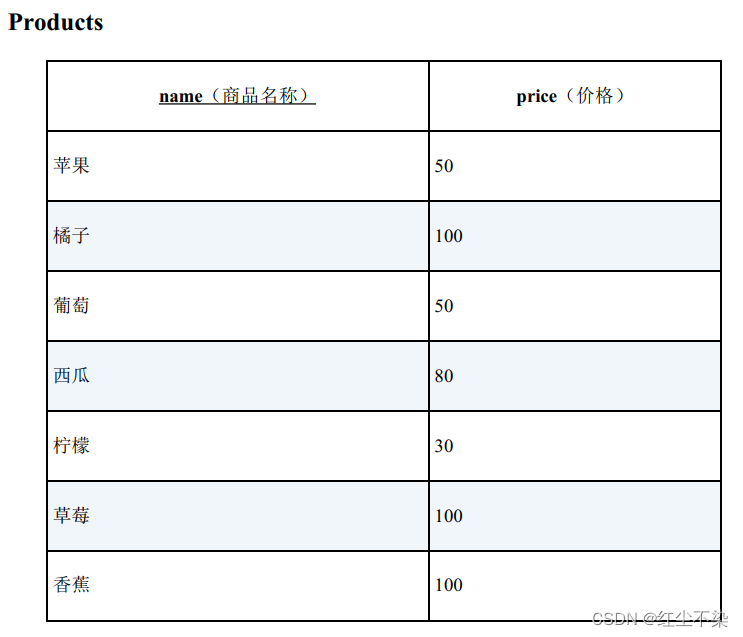
查找价格相同的商品组合。
-- 用于查找价格相等但商品名称不同的记录的SQL 语句
SELECT DISTINCT P1.name, P1.price
FROM Products P1, Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name;
-- 用于查找价格相等但商品名称不同的记录的SQL 语句
SELECT P1.name, P1.price
FROM Products P1, Products P2
WHERE EXISTS ( SELECT *
FROM Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name
);
排序
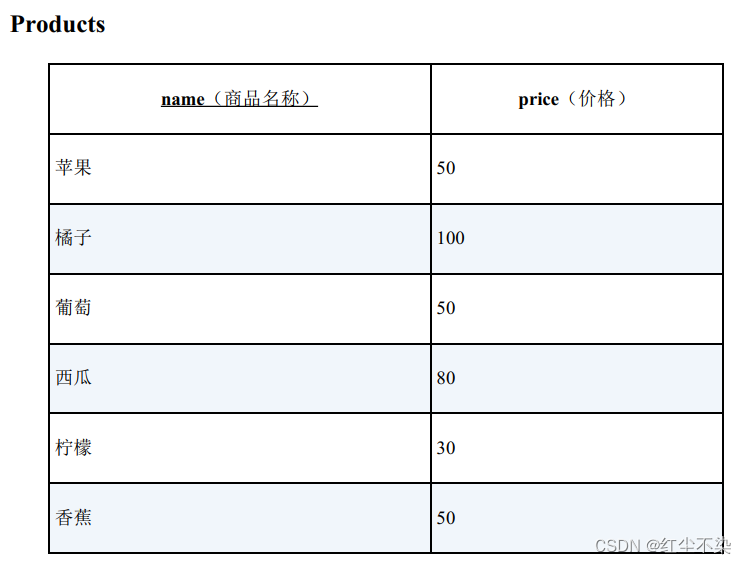
按照价格从高到低的顺序, 对这张表里的商品进行排序。 让价格相同的商品位次也一样, 而紧接着它们的商品则有两种排序方法, 一种是跳过之后的位次, 另一种是不跳过之后的位次。
-- 排序: 使用窗口函数
SELECT name,price,
RANK() OVER (ORDER BY price DESC) AS rank_1,
DENSE_RANK() OVER (ORDER BY price DESC) AS rank_2
FROM Products;
执行结果
name price rank_1 rank_2
------- ------ ------- -------
橘子 100 1 1
西瓜 80 2 2
苹果 50 3 3
香蕉 50 3 3
葡萄 50 3 3
柠檬 30 6 4
使用自连接排序
-- 排序从1 开始。 如果已出现相同位次, 则跳过之后的位次
SELECT P1.name,P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
如果修改成 COUNT(DISTINCT P2.price) , 那么存在相同位次的记录时, 就可以不跳过之后的位次, 而是连续输出(相当于 DENSE_RANK 函数)。
这条 SQL 语句可以根据不同的需求灵活地进行扩展, 实现不同的排序方式。
子查询所做的, 是计算出价格比自己高的记录的条数并将其作为自己的位次。
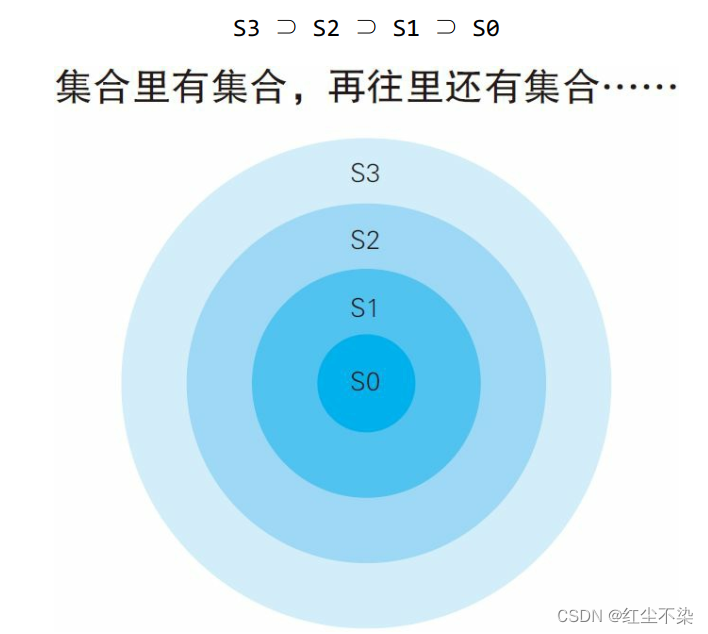
考虑对去重之后的 4 个价格“{ 100, 80, 50, 30 } ”进行排序的情况。
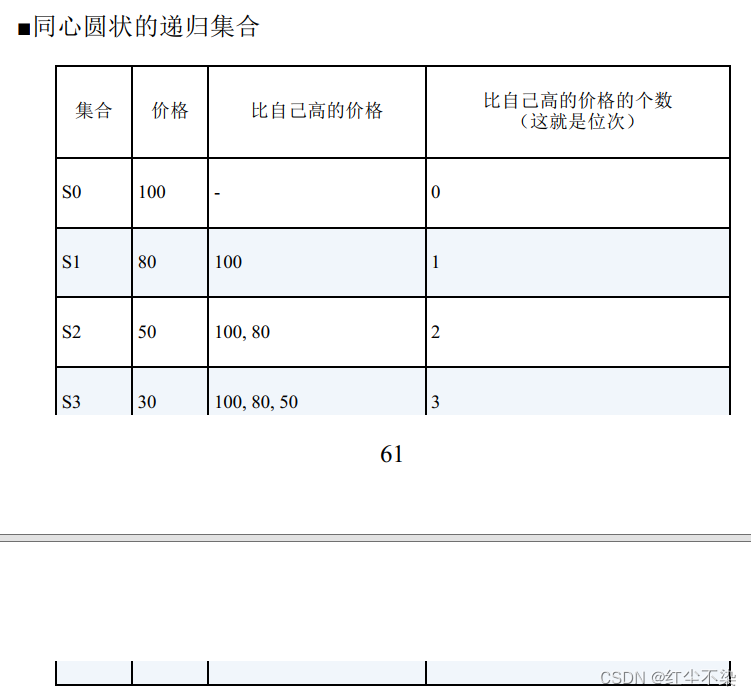
这条 SQL 语句会生成这样几个“同心圆状的” 递归集合,然后数这些集合的元素个数。
-- 排序: 使用自连接
SELECT P1.name,
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name
ORDER BY rank_1;
去掉这条 SQL 语句里的聚合并展开成下面这样, 就可以更清楚地看出同心圆状的包含关系。
-- 不聚合, 查看集合的包含关系
SELECT P1.name, P2.name
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price;
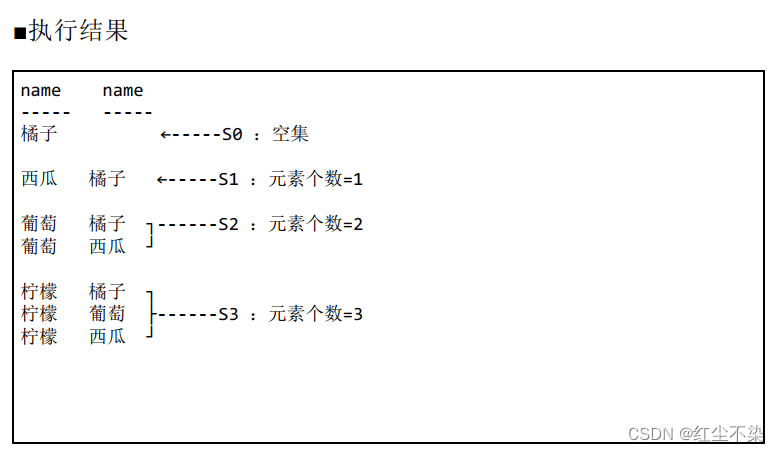
从执行结果可以看出,集合每增大1个,元素也增多1个, 通过数集合里元素的个数就可以算出位次。
本节小结
与多表之间进行的普通连接相比, 自连接的性能开销更大(特别是与非等值连接结合使用的时候),因此用于自连接的列推荐使用主键或者在相关列上建立索引。
- 自连接经常和非等值连接结合起来使用。
- 自连接和 GROUP BY 结合使用可以生成递归集合。
- 将自连接看作不同表之间的连接更容易理解。
- 应把表看作行的集合, 用面向集合的方法来思考。
- 自连接的性能开销更大, 应尽量给用于连接的列建立索引。
1.3 三值逻辑和NULL
大多数编程语言都是基于二值逻辑的, 即逻辑真值只有真和假两个。 而 SQL 语言则采用一种特别的逻辑体系——三值逻辑,即逻辑真值除了真和假, 还有第三个值 NULL。
普通语言里的布尔型只有 true 和 false 两个值,这种逻辑体系被称为二值逻辑。 而 SQL 语言里, 除此之外还有第三个值 unknown , 因此这种逻辑体系被称为三值逻辑(three-valued logic)。
为什么关系数据库中采用三值逻辑?
因为关系数据库里引进了 NULL , 所以不得不同时引进第三个值。
在讨论NULL时,我们一般都会将它分成两种类型来思考。
两种 NULL 分别指的是未知(unknown)和不适用(not applicable,inapplicable)
不适用这种情况下的NULL,在语义上更接近于“无意义”,如“圆的体积”“男性的分娩次数”一样,都是没有意义的。
未知指的是“虽然现在不知道, 但加上某些条件后就可以知道”; 而不适用指的是“无论怎么努力都无法知道”。
现在所有的 DBMS 都将两种类型的 NULL 归为了一类并采用了三值逻辑。
为什么必须写成“IS NULL”, 而不是“= NULL”
-- 查询 NULL 时出错的SQL 语句
SELECT * FROM tbl_A
WHERE col_1 = NULL;
对 NULL 使用比较谓词后得到的结果总是 unknown 。而查询结果只会包含 WHERE 子句里的判断结果为 true的行,会包含判断结果为 false 和 unknown 的行。不只是等号,对 NULL 使用其他比较谓词, 结果也都是一样的。
-- 以下的式子都会被判为 unknown
1 = NULL
2 > NULL
3 < NULL
4 <> NULL
NULL = NULL
为什么对 NULL 使用比较谓词后得到的结果永远不可能为真呢?
这是因为, NULL 既不是值也不是变量。 NULL 只是一个表示 “没有值” 的标记, 而比较谓词只适用于值。因此,对并非值的 NULL 使用比较谓词本来就是没有意义的 。
列的值为 NULL ,NULL 值这样的说法本身就是错误的。因为 NULL不是值, 所以不在定义域中。
unknown、 第三个真值
因为关系数据库采用了 NULL 而被引入的第三个真值 (unknown) 。
真值 unknown 和作为 NULL 的一种的UNKNOWN (未知) 是不同的东西。 前者是明确的布尔型的真值, 后者既不是值也不是变量。 为了便于区分, 前者采用粗体的小写字母unknown,后者用普通的大写字母 UNKNOWN 来表示。
-- 这个是明确的真值的比较
unknown = unknown → true
-- 这个相当于NULL = NULL
UNKNOWN = UNKNOWN → unknown
SQL遵循的三值逻辑的真值表
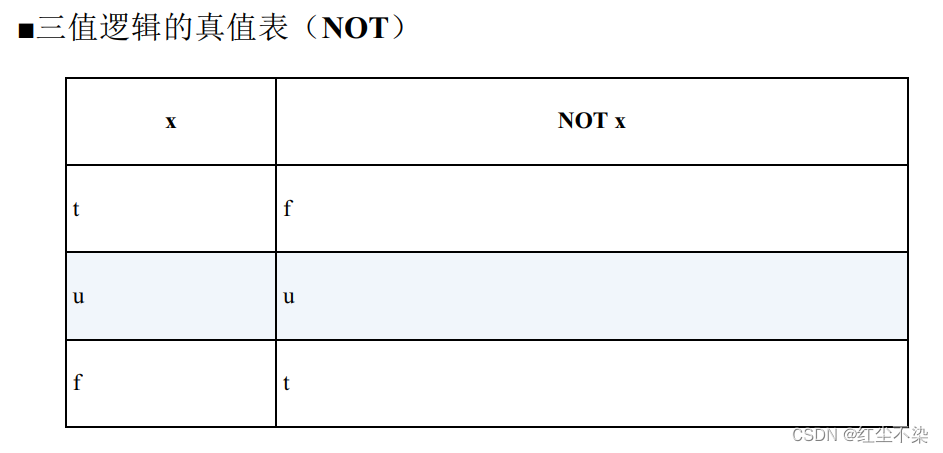
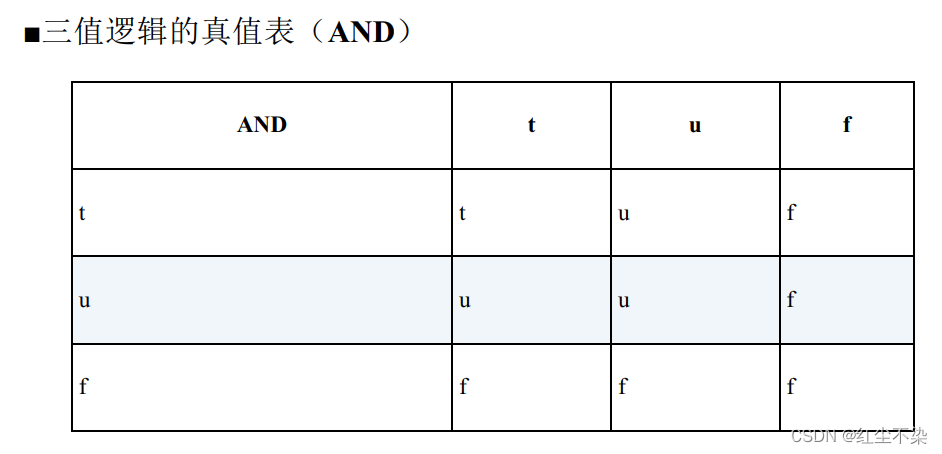
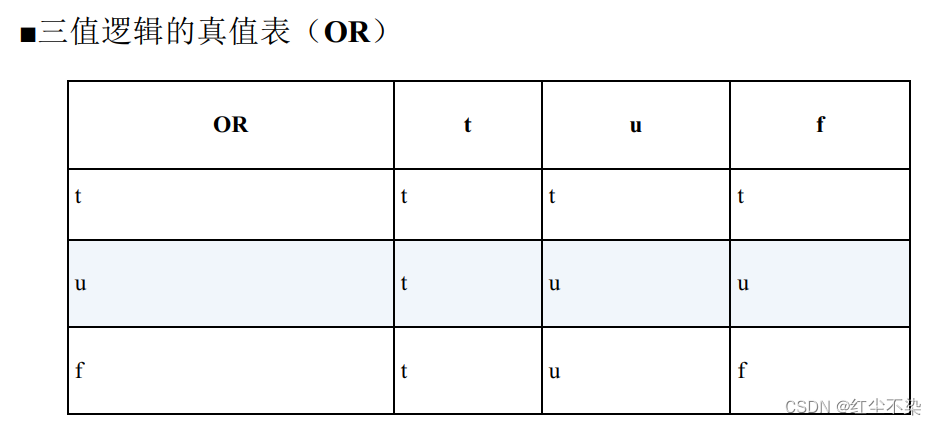
三个真值之间有下面这样的优先级顺序:
- AND 的情况: false > unknown > true
- OR 的情况: true > unknown > false
练习题:
问题: 假设 a = 2, b = 5, c = NULL , 此时下面这些式子的真值 是什么?
1. a < b AND b > c
2. a > b OR b < c
3. a < b OR b < c
4. NOT (b <> c)
答案:
1. unknown ; 2. unknown ; 3. true ; 4. unknown
比较谓词和 NULL: 排中律不成立
命题:
约翰是 20 岁, 或者不是 20 岁, 二者必居其一。 ——P
在采用二元逻辑的世界,上面的命题是真命题,但是在关系数据库中,还有NULL的存在。
如果排中律成立,则下面的语句能够查询到所有行。遗憾的是, 在 SQL 的世界里, 排中律是不成立的。 因为NULL的存在。
-- 查询年龄是20 岁或者不是20 岁的学生
SELECT *
FROM Students
WHERE age = 20
OR age <> 20;
假设表 Students里的数据如下所示:
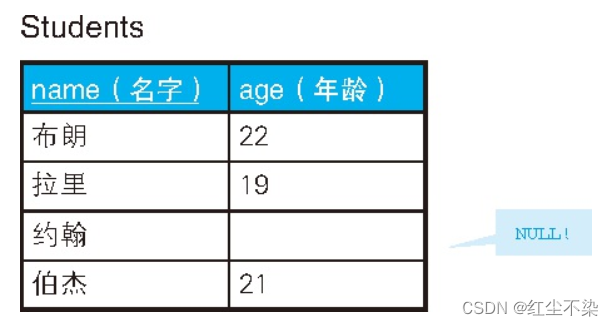
上面的SQL将无法查询差距约翰的年龄。
SQL 语句的查询结果里只有判断结果为 true 的行。 要想让约翰出现在结果里, 需要添加下面这样的“第 3 个条件”。
-- 添加第3 个条件: 年龄是20 岁, 或者不是20 岁, 或者年龄未知
SELECT * FROM Students
WHERE age = 20 OR age <> 20 OR age IS NULL;
比较谓词和 NULL:CASE 表达式和 NULL
下面我们来看一下在 CASE 表达式里将 NULL 作为条件使用时经常会出现的错误。 首先请看下面的简单 CASE 表达式。
-- col_1 为1 时返回○、 为NULL 时返回× 的CASE 表达式?
CASE col_1
WHEN 1 THEN '○'
WHEN NULL THEN '×'
END
这个 CASE 表达式一定不会返回×。 这是因为, 第二个 WHEN 子句是 col_1 = NULL 的缩写形式。这个式子的真值永远是unknown 。 而且 CASE 表达式的判断方法与 WHERE 子句一样, 只认可
真值为 true 的条件。
正确的写法是像下面这样使用搜索 CASE 表达式。
CASE WHEN col_1 = 1 THEN '○'
WHEN col_1 IS NULL THEN '×'
END
NULL 并不是值
NOT IN 和 NOT EXISTS 不是等价的
在对 SQL 语句进行性能优化时, 经常用到的一个技巧是将 IN 改写成EXISTS 。 这是等价改写, 并没有什么问题。 问题在于, 将 NOT IN 改写成 NOT EXISTS 时, 结果未必一样。
示例:
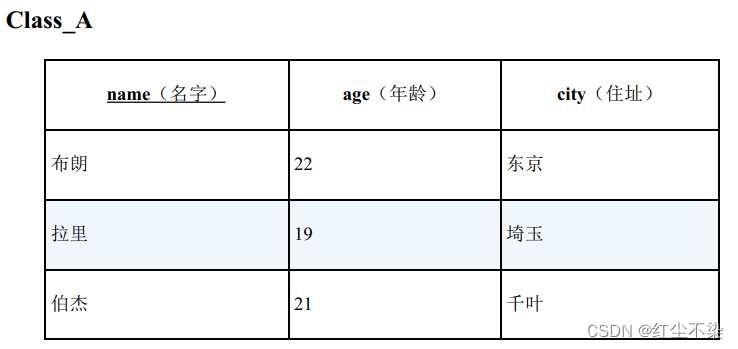
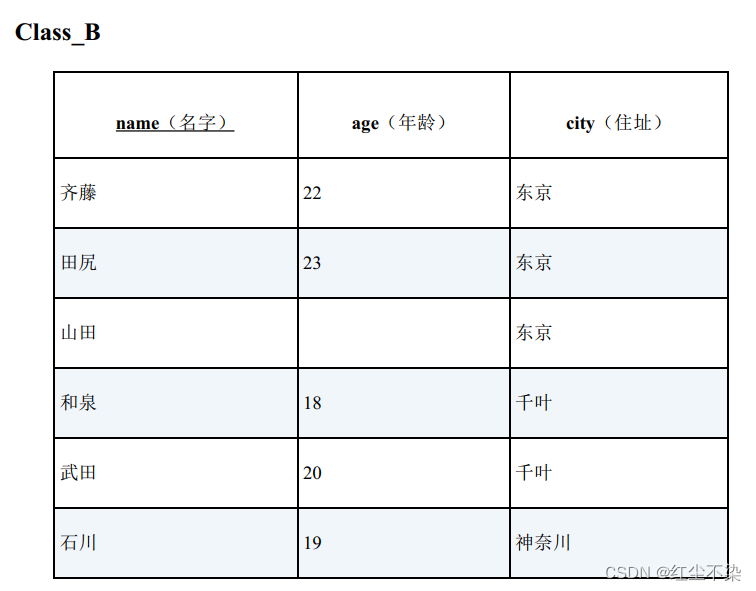
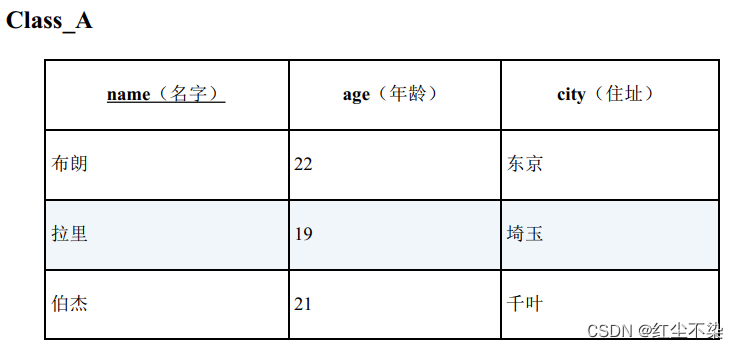
查询与B 班住在东京的学生年龄不同的A 班学生的SQL 语句?
SELECT * FROM Class_A
WHERE age NOT IN ( SELECT age FROM Class_B WHERE city = '东京' );
因为山田的年龄为 NULL,所以这条 sql 并不能查询出任何结果。
下面来看一下具体的SQL执行步骤
--1. 执行子查询, 获取年龄列表
SELECT * FROM Class_A
WHERE age NOT IN (22, 23, NULL);
--2. 用NOT 和IN 等价改写NOT IN
SELECT * FROM Class_A
WHERE NOT age IN (22, 23, NULL);
--3. 用OR 等价改写谓词IN
SELECT * FROM Class_A
WHERE NOT ( (age = 22) OR (age = 23) OR (age = NULL) );
--4. 使用德· 摩根定律等价改写
SELECT * FROM Class_A
WHERE NOT (age = 22) AND NOT(age = 23) AND NOT (age = NULL);
--5. 用<> 等价改写 NOT 和 =
SELECT * FROM Class_A
WHERE (age <> 22) AND (age <> 23) AND (age <> NULL);
--6. 对NULL 使用<> 后, 结果为unknown
SELECT * FROM Class_A
WHERE (age <> 22) AND (age <> 23) AND unknown;
--7. 如果AND 运算里包含unknown, 则结果不为true,查询不到任何结果
SELECT * FROM Class_A
WHERE false 或unknown;
可以看出, 这里对 A 班的所有行都进行了如此繁琐的判断, 然而没有一行在 WHERE 子句里被判断为 true 。 也就是说,
如果 NOT IN 子查询中用到的表里被选择的列中存在NULL,则 SQL 语句整体的查询结果永远是空。
为了得到正确的结果, 我们需要使用 EXISTS 谓词。
-- 正确的SQL 语句: 拉里和伯杰将被查询到
SELECT * FROM Class_A A
WHERE NOT EXISTS( SELECT * FROM Class_B B WHERE A.age = B.age AND B.city = '东京');
-- 查询结果
name age city
----- ---- ----
拉里 19 埼玉
伯杰 21 千叶
具体的SQL执行步骤
分析SQL 是如何处理年龄为 NULL的行
-- 1. 在子查询里和NULL 进行比较运算
SELECT * FROM Class_A A
WHERE NOT EXISTS ( SELECT * FROM Class_B B WHERE A.age = NULL AND B.city = '东京' );
--2. 对NULL 使用“=”后, 结果为 unknown
SELECT * FROM Class_A A
WHERE NOT EXISTS ( SELECT * FROM Class_B B WHERE unknown AND B.city = '东京' );
--3. 如果AND 运算里包含unknown, 结果不会是true
SELECT * FROM Class_A A
WHERE NOT EXISTS ( SELECT * FROM Class_B BWHERE false 或 unknown);
--4. 子查询没有返回结果, 因此相反地, NOT EXISTS 为true
SELECT * FROM Class_A A WHERE true;
产生这样的结果, 是因为 EXISTS 谓词永远不会返回 unknown 。
EXISTS 只会返回 true 或者
false
。 因此就有了 IN 和 EXISTS 可以互相替换使用, 而 NOT IN 和 NOT EXISTS 却不可以互相替换的混乱现象。
限定谓词和 NULL
SQL 里有 ALL 和 ANY 两个限定谓词。 因为 ANY 与 IN 是等价的, 所以我们不经常使用 ANY。 在这里, 我们主要看一下更常用的 ALL 的一些注意事项。
ALL 可以和比较谓词一起使用, 用来表达“与所有的××都相等”,或“比所有的××都大”的意思。
示例:
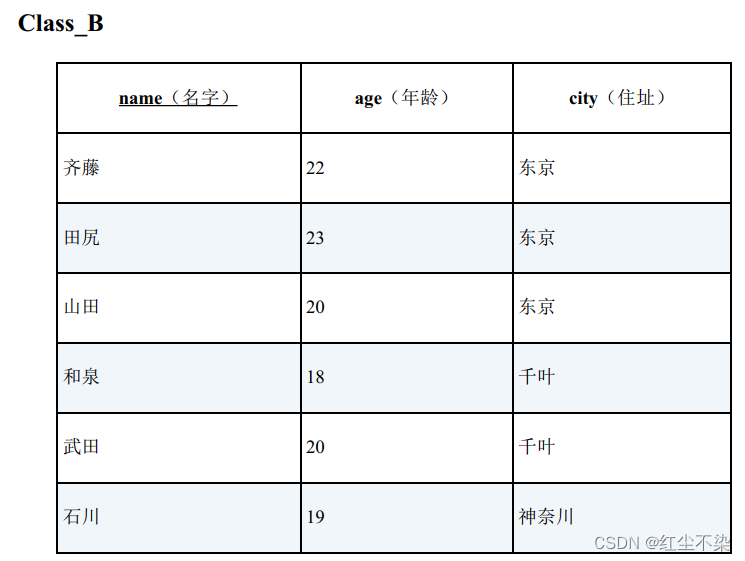
查询比B 班住在东京的所有学生年龄都小的A 班学生
SELECT * FROM Class_A
WHERE age < ALL ( SELECT age FROM Class_B WHERE city = '东京' );
-- 查询结果
name age city
----- ---- ----
拉里 19 埼玉
如果B班山田的年龄为空。分析sql的执行步骤。
--1. 执行子查询获取年龄列表
SELECT * FROM Class_A
WHERE age < ALL ( 22, 23, NULL );
--2. 将ALL 谓词等价改写为AND
SELECT * FROM Class_A
WHERE (age < 22) AND (age < 23) AND (age < NULL);
--3. 对NULL 使用“<”后, 结果变为 unknown
SELECT * FROM Class_A
WHERE (age < 22) AND (age < 23) AND unknown;
--4. 如果AND 运算里包含unknown, 则结果不为true
SELECT * FROM Class_A
WHERE false 或 unknown;
当存在NULL的数据,将不会查询到任何的数据。
限定谓词和极值函数不是等价的
使用极值函数代替 ALL 谓词的人应该不少吧。 如果用极值函数重写刚才的 SQL, 应该是下面这样。
-- 查询比B 班住在东京的年龄最小的学生还要小的A 班学生
SELECT * FROM Class_A
WHERE age < ( SELECT MIN(age) FROM Class_B WHERE city = '东京' );
-- 查询结果
name age city
----- ---- ----
拉里 19 埼玉
伯杰 21 千叶
极值函数在统计时会把为 NULL 的数据排除掉。
使用极值函数能使 Class_B 这张表里看起来就像不存在 NULL 一样。但是
极值函数和ALL谓词并不能等价使用!
ALL 谓词和极值函数表达的命题含义分别如下所示。
ALL 谓词: 他的年龄比在东京住的所有学生都小 —— Q1
极值函数: 他的年龄比在东京住的年龄最小的学生还要小 ——Q2
谓词(或者函数) 的输入为空集的情况。极值函数和ALL谓词不等价。
如 Class_B 没有住在东京的学生!使用 ALL 谓词的SQL 语句会查询到 A 班的所有学生。使用极值函数将不会查询到任何数据。
极值函数在输入为空表(空集) 时会返回 NULL 。
--1. 极值函数返回NULL
SELECT * FROM Class_A
WHERE age < NULL;
--2. 对NULL 使用“<”后结果为 unknown
SELECT * FROM Class_A
WHERE unknown;
聚合函数和 NULL
实际上, 当输入为空表时返回 NULL 的不只是极值函数, COUNT 以外的聚合函数也是如此。所以下面这条看似普通的 SQL 语句也会带来意想不到的结果。
-- 查询比住在东京的学生的平均年龄还要小的A 班学生的SQL 语句?
SELECT * FROM Class_A
WHERE age < ( SELECT AVG(age) FROM Class_B WHERE city = '东京' );
没有住在东京的学生时, AVG 函数返回 NULL 。 因此, 外侧的 WHERE子句永远是 unknown , 也就查询不到行。 使用 SUM 也是一样。
这种情况的解决方法只有两种: 要么把 NULL 改写成具体值, 要么闭上眼睛接受 NULL 。 但是如果某列有 NOT NULL 约束, 而我们需要往其中插入平均值或汇总值, 那么就只能选择将 NULL 改写成具体值了。
聚合函数和极值函数的这个陷阱是由函数自身带来的, 所以仅靠为具体列加上 NOT NULL 约束是无法从根本上消除的。 因此我们在编写SQL 代码的时候需要特别注意。
本节小结
本节要点。
- NULL 不是值。
- 因为 NULL 不是值, 所以不能对其使用谓词。
- 对 NULL 使用谓词后的结果是 unknown 。
- unknown 参与到逻辑运算时, SQL 的运行会和预想的不一样。
- 按步骤追踪 SQL 的执行过程能有效应对 4 种的情况。
要想解决 NULL 带来的各种问题, 最佳方法应该是往表里添加 NOT NULL 约束来尽力排除 NULL 。 这样就可以回到美妙的二值逻辑世界
1.4 HAVING 子句的力量
本节, 我们将学习 HAVING 子句的用法, 进而理解面向集合语言的第二个特性——
以集合为单位进行操作。
SQL 是一种基于面向集合思想设计的语言。
寻找缺失的编号
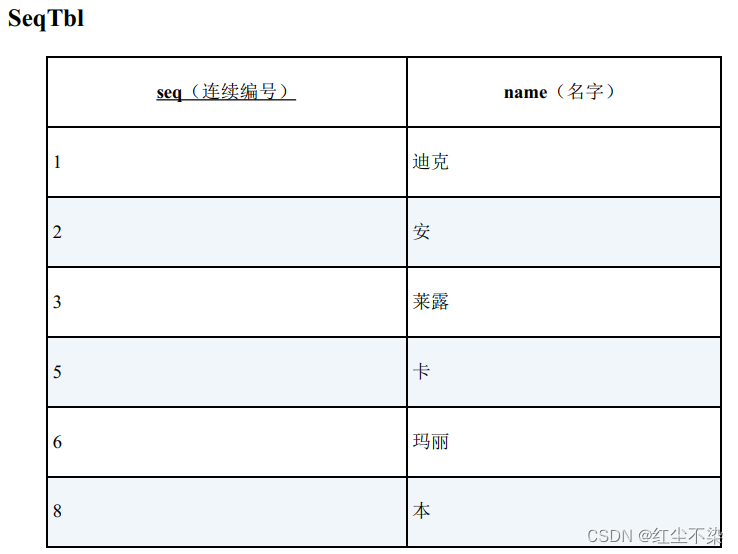
编号那一列叫作连续编号, 但实际上编号并不是连续的, 缺少了4 和 7。 我们要做的第一件事,就是查询这张表里是否存在数据缺失。
如果这张表的数据存储在文件里, 那么用面向过程语言查询时, 步骤应该像下面这样。
- 对“连续编号”列按升序或者降序进行排序。
- 循环比较每一行和下一行的编号。
表的记录是没有顺序的,而且 SQL 也没有排序的运算符。SQL 会将多条记录作为一个集合来处理, 因此如果将表整体看作一个集合,就可以像下面这样解决这个问题。
-- 如果有查询结果, 说明存在缺失的编号
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
-- 查询结果
gap
----------
'存在缺失的编号
如果用 COUNT() 统计出来的行数等于“连续编号”列的最大值, 就说明编号从开始到最后是连续递增
的, 中间没有缺失。 如果有缺失, COUNT() 会小于 MAX(seq) , 这样 HAVING 子句就变成真了。
如果用集合论的语言来描述, 那么这个查询所做的事情就是检查自然数集合和 SeqTbl 集合之间是否存在一一映射。MAX(seq) 计算的, 是由“到 seq 最大值为止的没有缺失的连续编号(即自然数) ”构成的集合的元素个数, 而 COUNT(*) 计算的是 SeqTbl 这张表里实际的元素个数(即行数)。
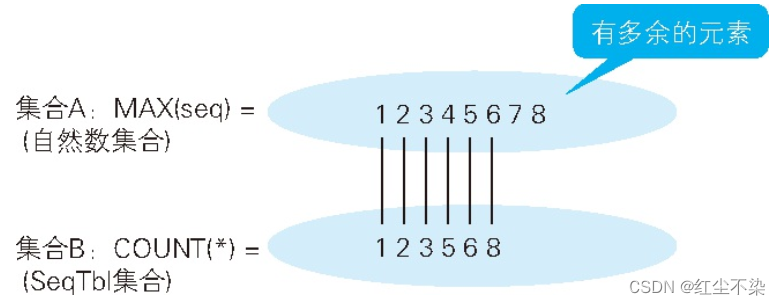
上面的 SQL 语句里没有 GROUP BY 子句, 此时整张表会被聚合为一行。 这种情况下 HAVING 子句也是可以使用的。在以前的 SQL 标准里, HAVING 子句必须和 GROUP BY 子句一起使用, 所以到现在也有人会有这样的误解。 但是, 按照现在的 SQL 标准来说, HAVING 子句是可以单独使用的 。 不过这种情况下, 就不能在 SELECT 子句里引用原来的表里的列了, 要么就得像示例里一样使用常量, 要么就得像 SELECT COUNT(*) 这样使用聚合函数。
查询一下缺失编号的最小值。 求最小值要用 MIN 函数
-- 查询缺失编号的最小值
SELECT MIN(seq + 1) AS gap
FROM SeqTbl
WHERE (seq+ 1) NOT IN ( SELECT seq FROM SeqTbl);
-- 查询结果
gap
---
4
使用 NOT IN 进行的子查询针对某一个编号, 检查了比它大 1 的编号是否存在于表中。 然后 “3,莱露”,“6,玛丽”,“8,本” 这几行因为找不到紧接着的下一个编号, 所以子查询的结果为真。
如果表 SeqTbl 里包含 NULL , 那么这条 SQL 语句的查询结果就不正确了(具体原因见1.3)。需要改写成下面的语句。
SELECT MIN(s.seq + 1) AS gap
FROM SeqTbl s
WHERE NOT EXISTS ( SELECT * FROM SeqTbl as t where (s.seq + 1) = t.seq );
-- 查询结果
gap
---
4
如果表 SeqTbl 里没有编号 1, 那么缺失编号的最小值应该是 1, 但是这两条 SQL 语句都不能得出正确的结果。需要改写为下面的语句。
SELECT CASE WHEN COUNT(*) = 0 OR MIN( seq ) > 1 THEN 1
ELSE ( SELECT MIN( seq + 1 ) FROM SeqTbl S1
WHERE NOT EXISTS ( SELECT * FROM SeqTbl S2 WHERE S2.seq = S1.seq + 1 )) END
FROM SeqTbl;
-- 查询结果
gap
---
4
用 HAVING 子句进行子查询: 求众数

众数(mode) 它指的是在群体中出现次数最多的值。在这张表中就是10000和20000。
求众数的思路是将收入相同的毕业生汇总到一个集合里, 然后从汇总后的各个集合里找出元素个数最多的集合。 用 SQL 这么操作集合正如探囊取物一样简单。
-- 求众数的SQL 语句(1): 使用谓词
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ALL (
SELECT COUNT(*)
FROM Graduates
GROUP BY income
);
-- 执行结果
income cnt
------ ---
10000 3
20000 3
GROUP BY 子句的作用是根据最初的集合生成若干个子集,因此, 将收入(income) 作为 GROUP BY 的列时, 将得到 S1 ~ S5 这样 5 个子集,如下图所示。
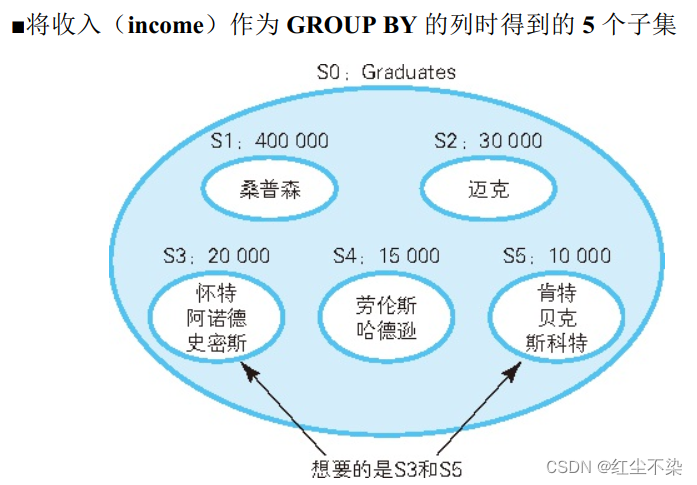
这几个子集里, 元素数最多的是 S3 和 S5, 都是 3 个元素, 因此查询的结果也是这 2 个集合。
1-3 节提到过 ALL 谓词用于 NULL 或空集时会出现问题,可以用极值函数来代替。
-- 求众数的SQL 语句(2) : 使用极值函数
SELECT income,COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ( SELECT MAX(cnt) FROM (
SELECT COUNT(*) AS cnt
FROM Graduates
GROUP BY income) TMP
);
用 HAVING 子句进行自连接:求中位数
中位数(median),指的是将集合中的元素按升序排列后恰好位于正中间的元素。如果集合的元素个数为偶数, 则取中间两个元素的平均值作为中位数。
求中位数的思路,将集合里的元素按照大小分为上半部分和下半部分两个子集,同时让这 2 个子集共同拥有集合正中间的元素。 这样, 共同部分的元素的平均值就是中位数。
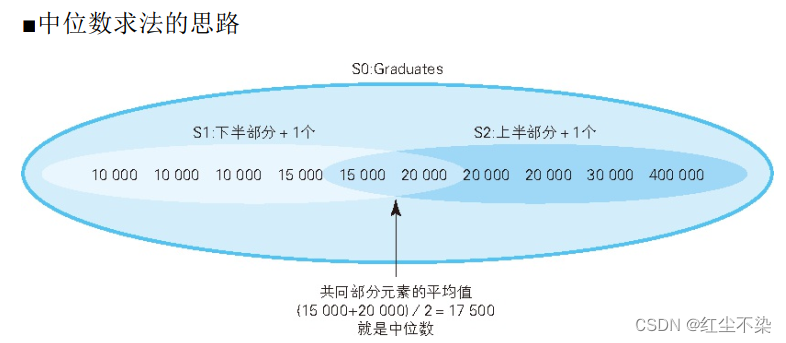
像这样需要根据大小关系生成子集时, 就轮到非等值自连接出场了。
-- 求中位数的SQL 语句: 在HAVING 子句中使用非等值自连接
SELECT AVG(DISTINCT income)
FROM (
-- 求出 s1 和 s2 的公共部分
SELECT T1.income
FROM Graduates T1, Graduates T2
GROUP BY T1.income
HAVING
-- S1 的条件
SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END) >= COUNT(*) / 2
AND
-- S2 的条件
SUM(CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END) >= COUNT(*) / 2
)
TMP;
查询不包含 NULL 的集合
COUNT 函数的使用方法有 COUNT(*) 和 COUNT( 列名 ) 两种, 它们的区别有两个:
第一个是性能上的区别; 第二个是 COUNT(*) 可以用于 NULL , 而 COUNT( 列名 ) 与其他聚合函数一样,要先排除掉NULL 的行再进行统计。
第二个区别也可以这么理解: COUNT(*) 查询的是所有行的数目, 而 COUNT( 列名 ) 查询的则不一定是。

-- 在对包含NULL 的列使用时, COUNT(*) 和COUNT( 列名) 的查询结果是不同的
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
count(*) count(col_1)
-------- ------------
3 0
示例:
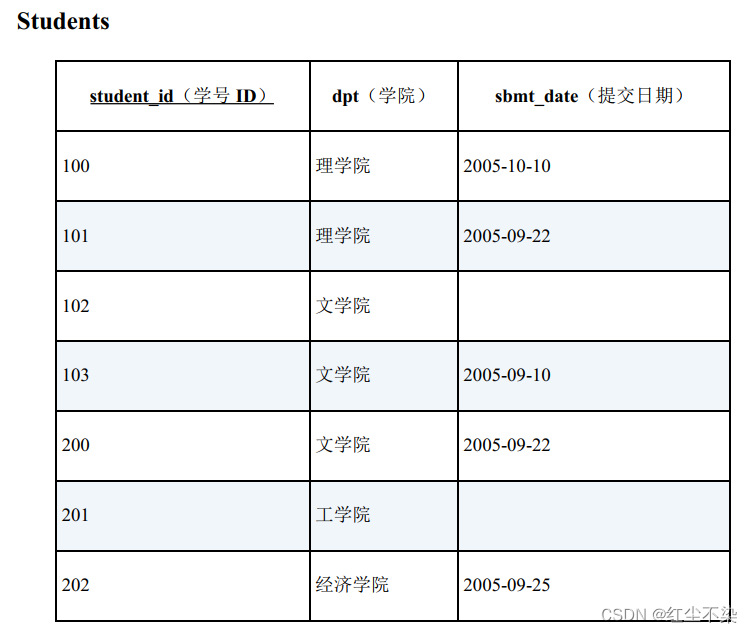
所有学生都提交了报告的学院有哪些
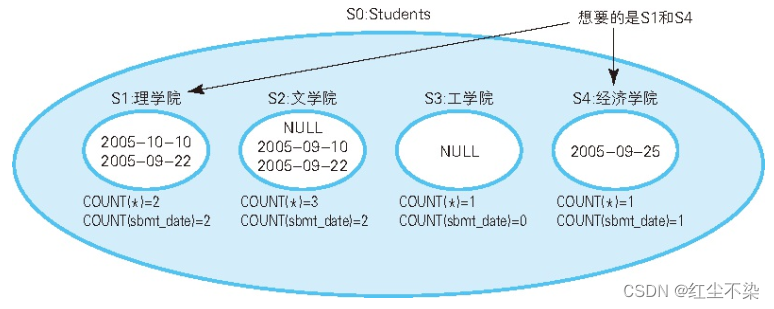
-- 查询“提交日期”列内不包含NULL 的学院(1) : 使用COUNT 函数
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = COUNT(sbmt_date);
-- 查询结果
dpt
--------
理学院
经济学院
-- 查询“提交日期”列内不包含NULL 的学院(2) : 使用CASE 表达式
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = SUM( CASE WHEN sbmt_date IS NOT NULL THEN 1 ELSE 0 END );
使用CASE表达式时,将“提交日期”不是 NULL 的行标记为 1,将“提交日期”为 NULL 的行标记为 0 。在这里,CASE 表达式的作用相当于进行判断的函数, 用来判断各个元素(= 行) 是否属于满足了某种条件的集合。 这样的函数我们称为特征函数。
用关系除法运算进行购物篮分析
有这样两张表: 商品表 Items,库存管理表 ShopItems。

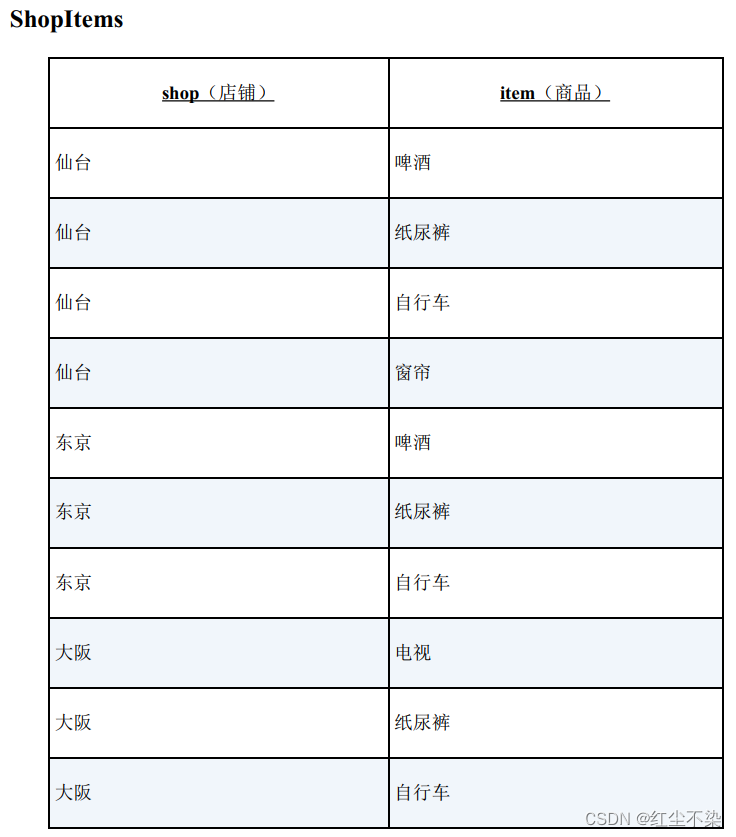
查询的是囊括了表 Items 中所有商品的店铺。 即仙台店和东京店。
遇到像表 ShopItems 这种一个实体(在这里是店铺) 的信息分散在多行的情况时, 仅仅在 WHERE 子句里通过 OR 或者 IN 指定条件是无法得到正确结果的。 这是因为, 在 WHERE 子句里指定的条件只对表里的某一行数据有效。
-- 查询啤酒、 纸尿裤和自行车同时在库的店铺: 错误的SQL 语句
SELECT DISTINCT shop
FROM ShopItems
WHERE item IN (SELECT item FROM Items);
-- 查询结果
shop
----
仙台
东京
大阪
谓词 IN 的条件其实只是指定了“店内有啤酒或者纸尿裤或者自行车的店铺”, 所以店铺只要有这三种商品中的任何一种, 就会出现在查询结果里。
-- 查询啤酒、 纸尿裤和自行车同时在库的店铺: 正确的SQL 语句
SELECT SI.shop
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items);
-- 执行结果
shop
----
仙台
东京
HAVING 子句的子查询 (SELECT COUNT(item) FROM Items) 的返回值是常量 3。 因此, 对商品表和店铺的库存管理表进行连接操作后结果是 3 行的店铺会被选中。
精确关系除法,只选择没有剩余商品的店铺(与此相对, 前一个问题被称为“带余除法”(division with a remainder) )。解决这个问题我们需要使用外连接。
-- 精确关系除法运算: 使用外连接和COUNT 函数
SELECT SI.shop
FROM ShopItems SI LEFT OUTER JOIN Items I
ON SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items) -- 条件1
AND COUNT(I.item) = (SELECT COUNT(item) FROM Items); -- 条件2
-- 查询结果
shop
----
东京
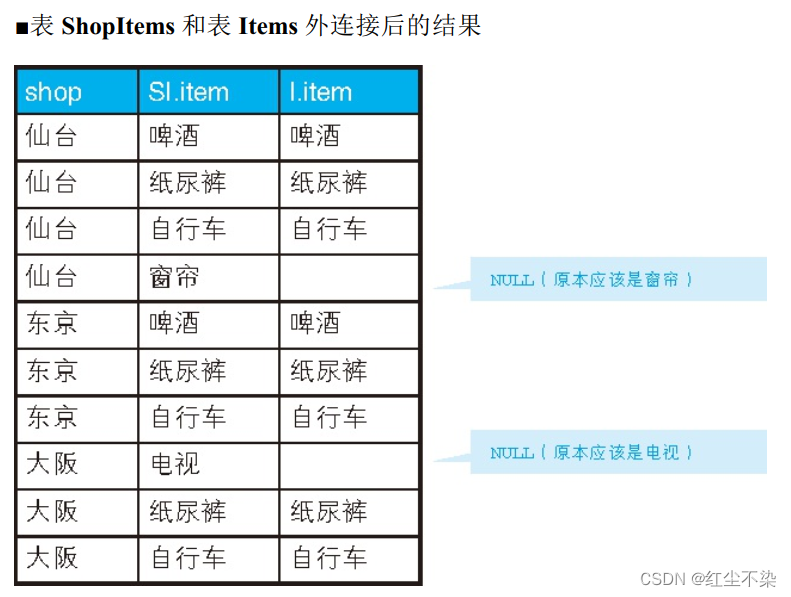
一般来说, 使用外连接时, 大多会用商品表 Items 作为主表进行外连接操作, 而这里颠倒了一下主从关系, 表使用 ShopItems 作为了主表。
关系除法运算
本节介绍的运算主要是关系除法运算。 如果模仿数值运算的写法来写, 可以写作 ShopItems ÷ Items。 至于为什么称它为除法运算, 我们可以从除法运算的逆运算——乘法运算的角度来理解一
下。
除法运算和乘法运算之间有这样的关系: 除法运算的商和除数的乘积等于被除数。
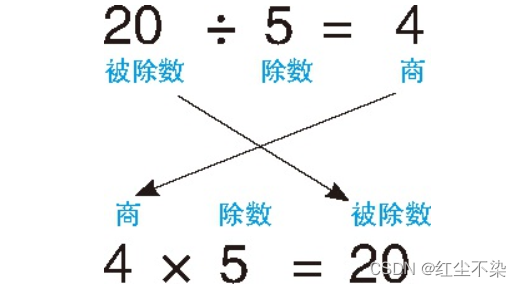
在 SQL 里,交叉连接相当于乘法运算。把商和除数(表 Items)交叉连接,然后求笛卡儿积,就能得到表 ShopItems 的子集(不一定是完整的表 ShopItems),也就是被除数。这就是“除法运算”这一名称的由来。
本节小结
很多人觉得 HAVING 子句像是影视剧里的配角一样, 并没有太多的出场机会, 仿佛是一种附属品,从而轻视了它。 但是读过本节内容后,相信大家就能明白, HAVING 子句其实是非常强大的, 它是面向集合语言的一大利器。 特别是与 CASE 表达式或自连接等其他技术结合使用更能发挥它的威力。
本节要点:
- 表不是文件, 记录也没有顺序, 所以 SQL 不进行排序。
- SQL 不是面向过程语言, 没有循环、 条件分支、 赋值操作。
-
SQL 通过不断生成子集来求得目标集合。 SQL不像面向过程语言那样通过画流程图来思考问题,而是通过画集合的关系图来思考。
- GROUP BY 子句可以用来生成子集。
- WHERE 子句用来调查集合元素的性质, 而 HAVING 子句用来调查集合本身的性质。
1.5 外连接的用法
SQL 的弱点及其趋势和对策
数据库工程师经常面对的一个难题是无法将 SQL 语句的执行结果转换为想要的格式。 因为 SQL 语言本来就不是为了这个目的而出现的, 所以需要费些工夫。 说起来,SQL终究也只是主要用于查询数据的语言而已。格式转换中具有代表性的行列转换和嵌套式侧栏的生成方法, 本节深入理解一下其中起着重要作用的外连接。
用外连接进行行列转换 (1)(行→列):制作交叉表
课程表:用于管理员工学习过的培训课程的表

利用上面这张表生成下面这样一张交叉表。○ 表示已学习过, NULL 表示尚未学习。
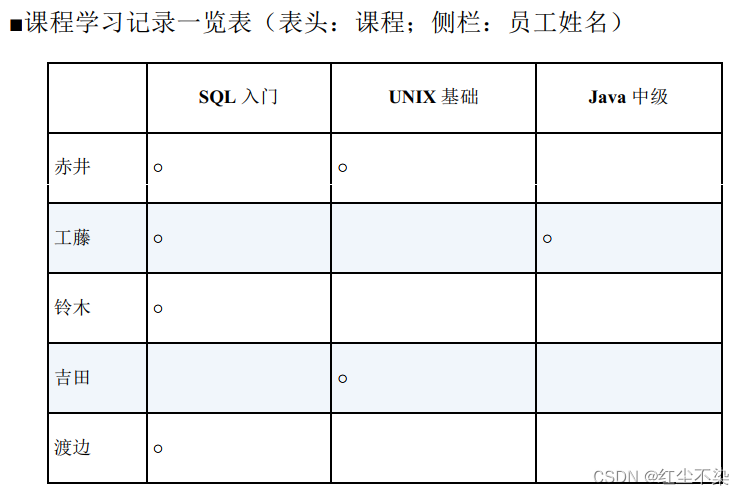
-- 水平展开求交叉表(1): 使用外连接
SELECT C0.name,
CASE WHEN C1.name IS NOT NULL THEN '○' ELSE NULL END AS "SQL 入门",
CASE WHEN C2.name IS NOT NULL THEN '○' ELSE NULL END AS "UNIX 基础",
CASE WHEN C3.name IS NOT NULL THEN '○' ELSE NULL END AS "Java 中级"
FROM (SELECT DISTINCT name FROM Courses) C0 -- 这里的C0 是侧栏
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = 'SQL 入门' ) C1
ON C0.name = C1.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = 'UNIX 基础' ) C2
ON C0.name = C2.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = 'Java 中级' ) C3
ON C0.name = C3.name;
主表 C0,使用外连接分别连接 C1,C2,C3。



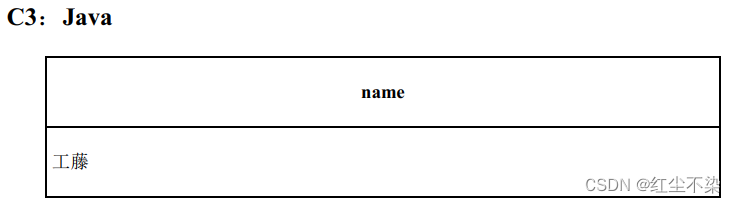
C0 包含了全部员工, 起到了员工主表的作用,C1~C3 是每个课程的学习者的集合。 这里以 C0 为主表, 依次对 C1 ~ C3 进行外连接操作。如果某位员工学习过某个课程,则相应的课程列会出现他的姓名,否则为NULL 。 最后, 通过 CASE 表达式将课程列中员工的姓名转换为○就算完成了。
一般情况下, 外连接都可以用标量子查询替代, 因此可以像下面这样写。
标量子查询可以出现在select、where和having子句中。也可以不使用聚集函数来定义标量子查询。在编译时并非总能判断一个子查询返回的结果中是否有多个元组,如果在子查询被执行后其结果中有不止一个元组,则产生一个运行时错误。
-- 水平展开(2): 使用标量子查询
SELECT C0.name,
(SELECT '○' FROM Courses C1 WHERE course = 'SQL 入门' AND C1.name = C0.name) AS "SQL 入门",
(SELECT '○' FROM Courses C2 WHERE course = 'UNIX 基础' AND C2.name = C0.name) AS "UNIX 基础",
(SELECT '○' FROM Courses C3 WHERE course = 'Java 中级' AND C3.name = C0.name) AS "Java 中级"
FROM (SELECT DISTINCT name FROM Courses) C0;
使用标量子查询来生成 3 列表头。 最后一行 FROM 子句的集合 C0 和前面的“员工主表”是一样的。 标量子查询的条件也和外连接一样, 即满足条件时返回○, 不满足条件时返回 NULL 。这种做法的优点在于,需要增加或者减少课程时,只修改 SELECT 子句即可,代码修改起来比较简单。
这种做法不仅
利于应对需求变更,对于需要动态生成 SQL 的系统也是很有好处的。缺点是性能不太好,目前在SELECT子句中使用标量子查询(或者关联子查询)的话,性能开销还是相当大的。
介绍第三种方法,即嵌套使用CASE表达式。CASE表达式可以写在SELECT子句里的聚合函数内部, 也可以写在聚合函数外部。
-- 水平展开(3): 嵌套使用CASE 表达式
SELECT name
CASE WHEN SUM(CASE WHEN course = 'SQL 入门' THEN 1 ELSE NULL END) = 1
THEN '○' ELSE NULL END AS "SQL 入门",
CASE WHEN SUM(CASE WHEN course = 'UNIX 基础' THEN 1 ELSE NULL END) = 1
THEN '○' ELSE NULL END AS "UNIX 基础",
CASE WHEN SUM(CASE WHEN course = 'Java 中级' THEN 1 ELSE NULL END) = 1
THEN '○' ELSE NULL END AS "Java 中级"
FROM Courses
GROUP BY name;
先把 SUM 函数的结果处理成 1 或者NULL , 然后在外层的 CASE 表达式里将 1 转换成○。
这种做法和标量子查询的做法一样简洁, 也能灵活地应对需求变更。 关于将聚合函数的返回值用于条件判断的写法,其实在 SELECT 子句里,
聚合函数的执行结果也是标量值
, 因此可以像常量和普通列一样使用。
SUM是对符合条件的记录的数值列求和
用外连接进行行列转换(2)(列→行):汇总重复项于一列
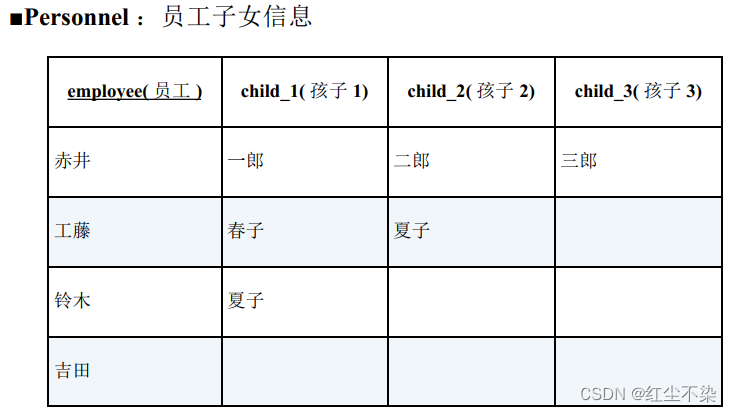
将这张表转换成行格式的数据。 这里使用 UNION ALL 来实现。
-- 列数据转换成行数据: 使用UNION ALL
SELECT employee, child_1 AS child FROM Personnel
UNION ALL
SELECT employee, child_2 AS child FROM Personnel
UNION ALL
SELECT employee, child_3 AS child FROM Personnel;
-- 查询结果
employee child
-----------------
赤井 一郎
赤井 二郎
赤井 三郎
工藤 春子
工藤 夏子
工藤
铃木 夏子
铃木
铃木
吉田
吉田
吉田
因为 UNION ALL 不会排除掉重复的行, 所以即使吉田没有孩子, 结果里也会出现 3 行相关数据。
根据具体需求,有时需要把没有孩子的吉田也留在表里,像下面这张员工子女列表这样。
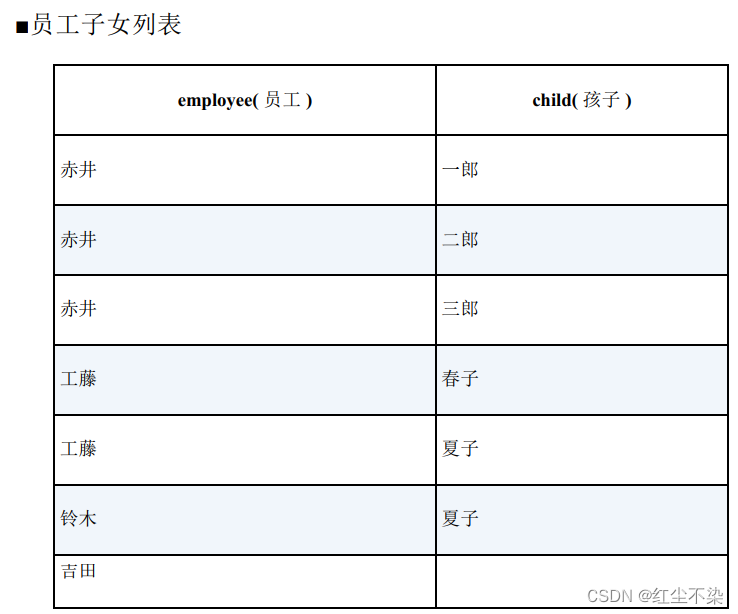
-- 创建子女表视图
CREATE VIEW Children(child)
AS SELECT child_1 FROM Personnel
UNION
SELECT child_2 FROM Personnel
UNION
SELECT child_3 FROM Personnel;
child
-- 员工子女表和子女表左连接,没有子女的员工也带出来
SELECT EMP.employee, CHILDREN.child
FROM Personnel EMP
LEFT OUTER JOIN Children
ON CHILDREN.child IN (EMP.child_1, EMP.child_2, EMP.child_3);
在交叉表里制作嵌套式表侧栏
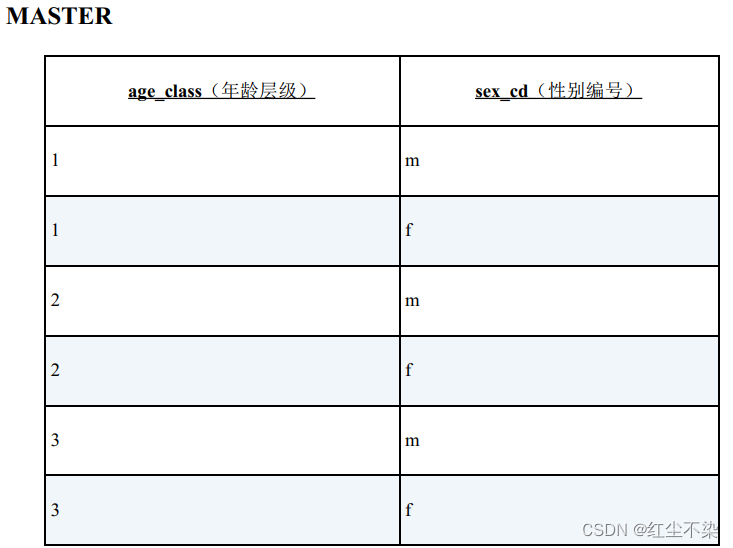
表 TblPop 是一张按照县、 年龄层级和性别统计的人口分布表, 要求根据表 TblPop 生成交叉表“包含嵌套式表侧栏的统计表。
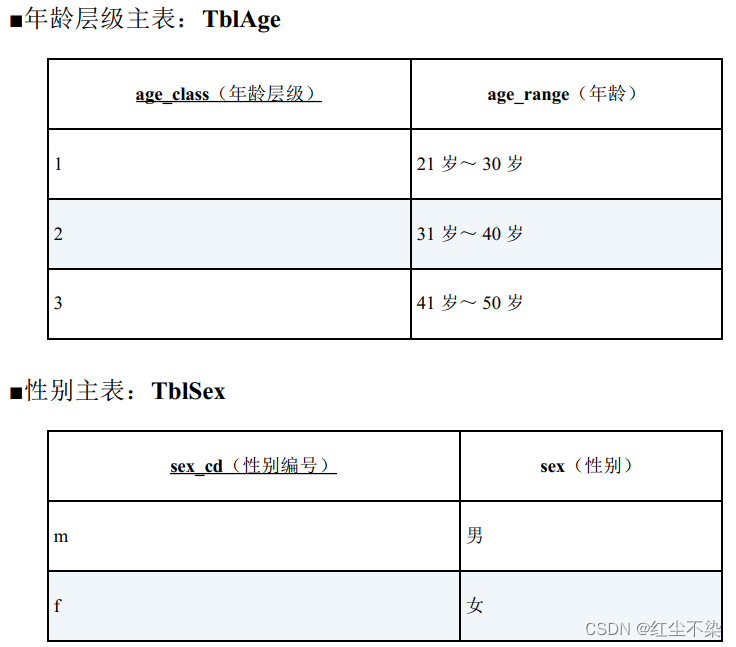
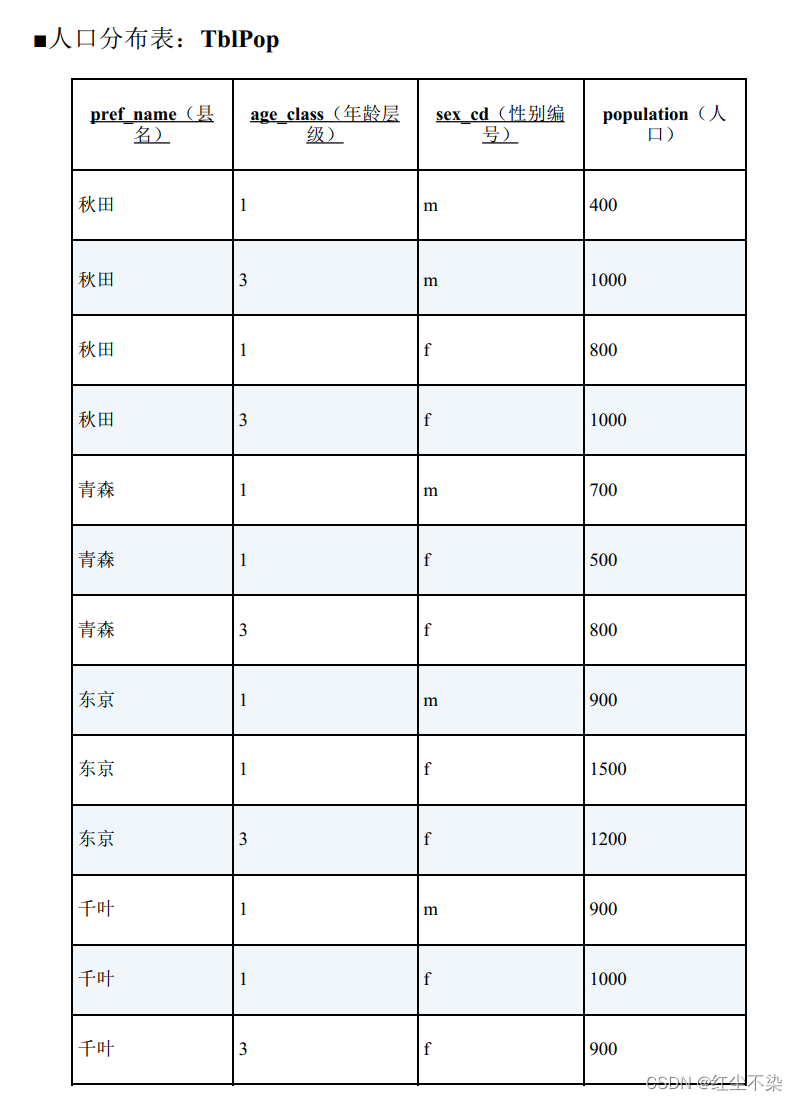
从上述表中获取数据,组织出下表中的数据
这个问题的要点在于, 虽然表 TblPop 中没有一条年龄层级为 2 的数据, 但是返回结果还是要包含这个年龄层级, 固定输出 6 行。 生成固定的表侧栏需要用到外连接。
目标表的侧栏是年龄层级和性别, 所以我们需要使用表 TblAge 和表 TblSex 作为主表。
-- 使用外连接生成嵌套式表侧栏: 错误的SQL 语句
SELECT MASTER1.age_class AS age_class,MASTER2.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN ('青森', '秋田')
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN ('东京', '千叶')
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop GROUP BY age_class, sex_cd)
DATA RIGHT OUTER JOIN TblAge MASTER1 -- 外连接1:和年龄层级主表进行外连接
ON MASTER1.age_class = DATA.age_class
RIGHT OUTER JOIN TblSex MASTER2 -- 外连接2:和性别主表进行外连接
ON MASTER2.sex_cd = DATA.sex_cd;
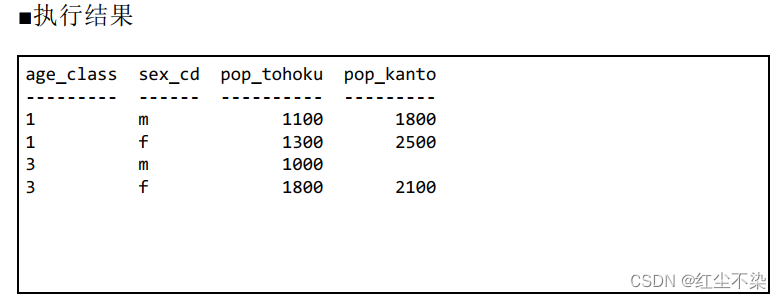
观察返回结果可以发现, 结果里没有出现年龄层级为 2 的行。
核心点: 虽然年龄层级 2 确实可以通过外连接从表 TblAge 获取, 但是在表 TblPop 里, 与之相应的“性别编号”列却是NULL 。 表 TblPop 里本来就没有年龄层级为 2 的数据, 自然也没有相应的性别信息 m 或 f, 于是“性别编号”列只能是NULL 。 因此与性别主表进行外连接时,连接条件会变成 ON
MASTER2.sex_cd = NULL ,结果是 unknown。因此,最终结果里永远不会出现年龄层级为 2 的数
据,即使改变两次外连接的先后顺序,结果也还是一样的。
调整成一次外连接就可以了。
-- 使用外连接生成嵌套式表侧栏: 正确的SQL 语句
SELECT MASTER.age_class AS age_class,MASTER.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,DATA.pop_kanto AS pop_kanto
-- 使用交叉连接生成两张主表的笛卡儿积
FROM (SELECT age_class, sex_cd FROM TblAge CROSS JOIN TblSex )
MASTER LEFT OUTER JOIN (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN ('青森', '秋田')
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN ('东京', '千叶')
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop GROUP BY age_class, sex_cd) DATA
ON MASTER.age_class = DATA.age_class AND MASTER.sex_cd = DATA.sex_cd;
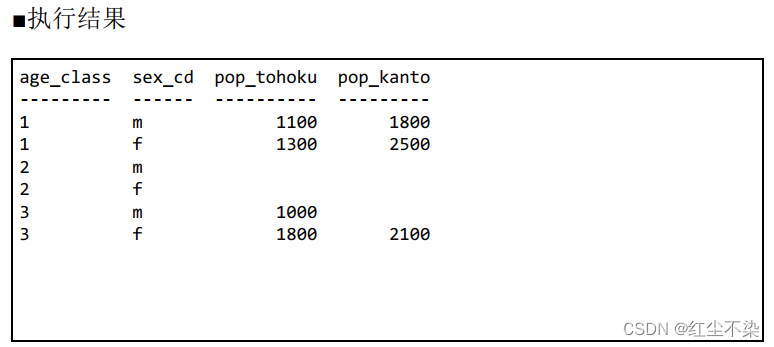
无论表 TblPop 里的数据有怎样的缺失, 结果的表侧栏总能固定为 6 行。
技巧是对表 TblAge 和表 TblSex 进行交叉连接运算, 生成下面这样的笛卡儿积。 行数是 3×2 = 6。
只需对这张 MASTER 视图进行一次外连接操作即可。 也就是说, 需要生成嵌套式表侧栏时, 事先按照需要的格式准备好主表就可以了。 当需要 3 层或 3 层以上的嵌套式表侧栏时, 也可以按照这种方法进行扩展。
作为乘法运算的连接
交叉连接(cross join)相当于乘法运算。
示例:
使用这两张表生成一张统计表, 以商品为单位汇总出各自的销量。

-- 解答(1): 通过在连接前聚合来创建一对一的关系
SELECT I.item_no, SH.total_qty
FROM Items I LEFT OUTER JOIN
(SELECT item_no, SUM(quantity) AS total_qty
FROM SalesHistory
GROUP BY item_no) SH
ON I.item_no = SH.item_no;
这条语句首先在连接前按商品编号对销售记录表进行聚合, 进而生成了一张以 item_no 为主键的临时视图。
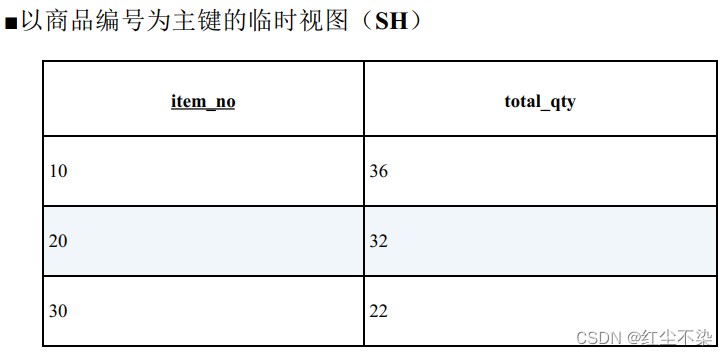
通过item_no列对商品主表和这个视图进行连接操作后,商品主表和临时视图就成为了在主键上进行的一对一连接。 虽然可以查询到想要的结果,但是从性能角度考虑, 这条 SQL 语句还是有些问题的。比如临时视图 SH 的数据需要临时存储在内存里, 还有就是虽然通过聚合将 item_no 变成了主键, 但是 SH 上却不存在主键索引, 因此我们也就无法利用索引优化查询。
要改善这个查询, 关键在于导入“把连接看作乘法运算”这种视点。 商品主表 Items 和视图 SH 确实是一对一的关系, 但其实从item_no列看, 表 Items 和表 SalesHistory 是一对多的关系。 而且, 当连接操作的双方是一对多关系时,结果的行数并不会增加。
-- 解答(2) : 先进行一对多的连接再聚合
SELECT I.item_no, SUM(SH.quantity) AS total_qty
FROM Items I LEFT OUTER JOIN SalesHistory SH
ON I.item_no = SH.item_no 一对多的连接
GROUP BY I.item_no;
如果表 Items 里的“items_no”列内存在重复行, 就属于多对多连接了, 因而这种做法就不能再使用。 这时, 需要先把某张表聚合一下,使两张表变成一对多的关系 。一对一或一对多关系的两个集合, 在进行连接操作后行数不会(异常地) 增加。
全外连接
标准 SQL 里定义了外连接的三种类型, 如下所示。
- 左外连接(LEFT OUTER JOIN)
- 右外连接(RIGHT OUTER JOIN)
- 全外连接(FULL OUTER JOIN)
其中, 左外连接和右外连接没有功能上的区别。 用作主表的表写在运算符左边时用左外连接, 写在运算符右边时用右外连接。
在这三种里, 全外连接相对来说使用较少。 从面向集合的角度来看, 它有很多有趣的特点。
示例:
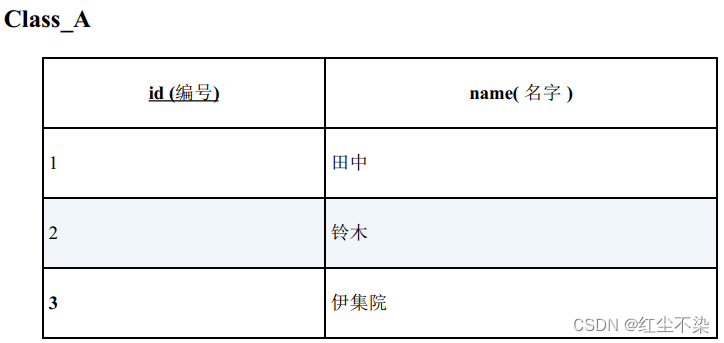
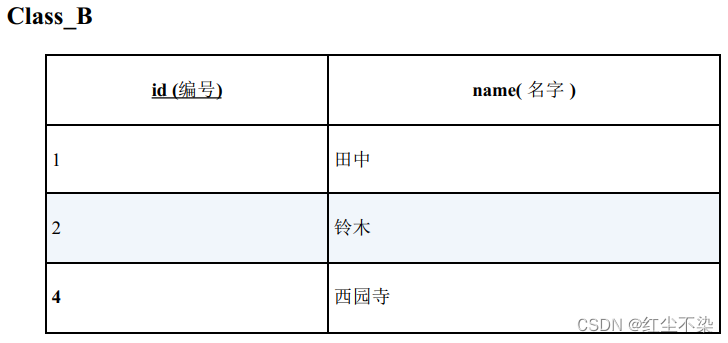
全外连接是能够从这样两张内容不一致的表里, 没有遗漏地获取全部信息的方法, 所以也可以理解成把两张表都当作主表来使用的连接。
-- 全外连接保留全部信息
SELECT COALESCE(A.id, B.id) AS id,
A.name AS A_name,
B.name AS B_name
FROM Class_A A FULL OUTER JOIN Class_B B
ON A.id = B.id;

COALESCE 是SQL 的标准函数, 可以接受多个参数, 功能是返回第一个非 NULL 的参数。
使用左(右)外连接时,只能使用两张表中的一张作为主表,所以不能同时获取到伊集院和西园寺两个人。 而全外连接的全就是保留全部信息的意思。如果所用的数据库不支持全外连接, 可以分别进行左外连接和右外连接,再把两个结果通过 UNION 合并起来,也能达到同样的目的。
-- 数据库不支持全外连接时的替代方案
SELECT A.id AS id, A.name, B.name
FROM Class_A A LEFT OUTER JOIN Class_B B
ON A.id = B.id
UNION
SELECT B.id AS id, A.name, B.name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id;
这种写法虽然也能获取到同样的结果, 但是代码比较冗长, 而且使用两次连接后还要用 UNION 来合并, 性能也不是很好。
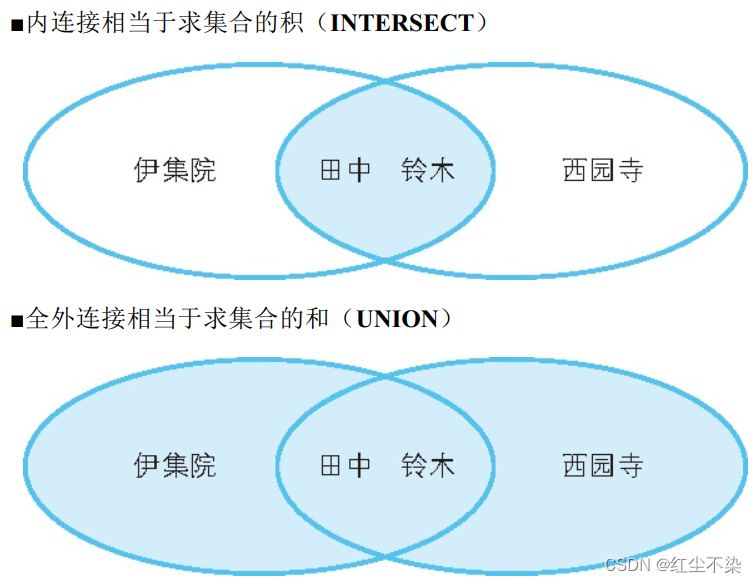
其实,我们还可以换个角度,把表连接看成集合运算。内连接相当于求集合的积(INTERSECT , 也称交集),全外连接相当于求集合的和(UNION , 也称并集) 。
用外连接进行集合运算
SQL 是以集合论为基础的,但令人费解的是,很长一段时间内它连基础的集合运算都不支持,UNION是SQL-86标准开始加入的,还算比较早。INTERSECT 和 EXCEPT 都是 SQL-92 标准才加入的。关系除法运算还没有被标准化。
集合运算符会进行排序, 所以可能会带来性能上的问题。 因此, 了解一下集合运算符的替代方案还是有意义的。
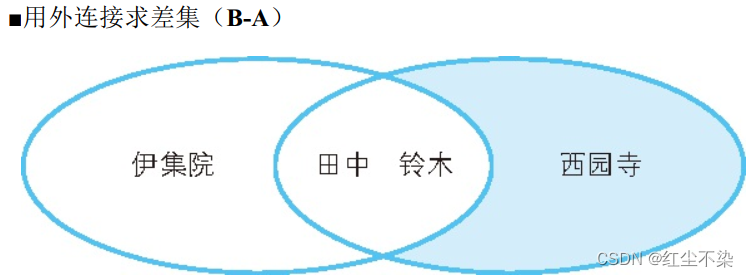
用外连接求差集: A - B
SELECT A.id AS id, A.name AS A_name
FROM Class_A A LEFT OUTER JOIN Class_B B
ON A.id = B.id
WHERE B.name IS NULL;
-- 执行结果
id A_name
---- ------
3 伊集院
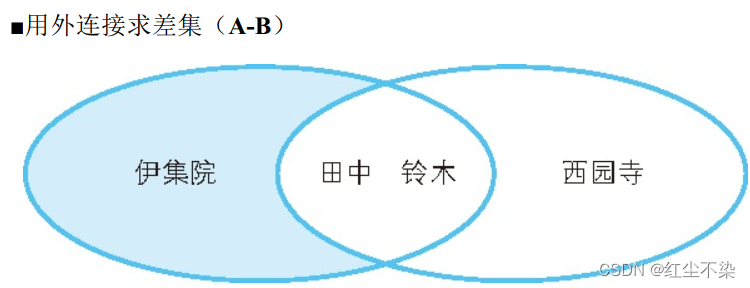
左连接带出 A 中所有数据,然后去除 B中不为NULL的数据,就是 A – B 的数据。
用外连接求差集: B - A
SELECT B.id AS id, B.name AS B_name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL;
-- 执行结果
id B_name
---- ------
4 西园寺
当然, 用外连接解决这个问题不太符合外连接原本的设计目的。 但是对于不支持差集运算的数据库来说, 这也可以作为 NOT IN 和 NOTEXISTS 之外的另一种解法, 而且
它可能是差集运算中效率最高的,这也是它的优点。
用全外连接求异或集
SQL 没有定义求异或集的运算符, 如果用集合运算符,可以有两种方法。 一种是 (A UNION B) EXCEPT (A INTERSECT B) , 另一种是 (A EXCEPT B) UNION (B EXCEPT A) 。
两种方法都比较麻烦, 性能开销也会增大。
SELECT COALESCE(A.id, B.id) AS id, COALESCE(A.name , B.name ) AS name
FROM Class_A A FULL OUTER JOIN Class_B B ON A.id = B.id
WHERE A.name IS NULL OR B.name IS NULL;
-- 执行结果
id name
---- -----
3 伊集院
4 西园寺
先求全集,然后去除 A 和 B独有的部分,求出异或集。
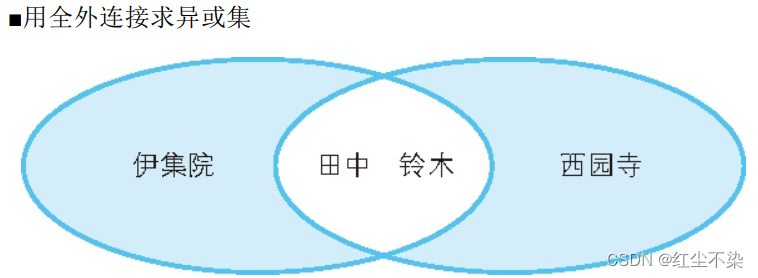
像这样改变一下 WHERE 子句的条件, 就可以进行各种集合运算。
本节小结
SQL 有很多的方言, 例如外连接, Oracle 数据库使用“(+) ”, 而 SQL Server 数据库使用“*= ”等, 非常依赖于数据库的具体实现。 从代码的可移植性来说, 我们应该避免采用这样独特的写法, 并遵循 ANSI 标准。 因此,本书统一采用了标准的写法。
还有, OUTER 也是可以省略的, 所以我们也可以写成 LEFT JOIN 和 FULL JOIN(标准 SQL 也是允许的)。但是为了区分是内连接和外连接,最好还是写上。
下面是本节要点。
- SQL 不是用来生成报表的语言, 所以不建议用它来进行格式转换。
- 必要时考虑用外连接或 CASE 表达式来解决问题。
- 生成嵌套式表侧栏时, 如果先生成主表的笛卡儿积再进行连接,很容易就可以完成。
- 从行数来看,表连接可以看成乘法。因此,当表之间是一对多的关系时,连接后行数不会增加。
- 外连接的思想和集合运算很像,使用外连接可以实现各种集合运算。
1.6 用关联子查询比较行与行
使用 SQL 进行行间比较时, 发挥主要作用的技术是关联子查询, 特别是与自连接相结合的自关联子查询。
增长、减少、维持现状
一张记录了某个公司每年的营业额的表 Sales。
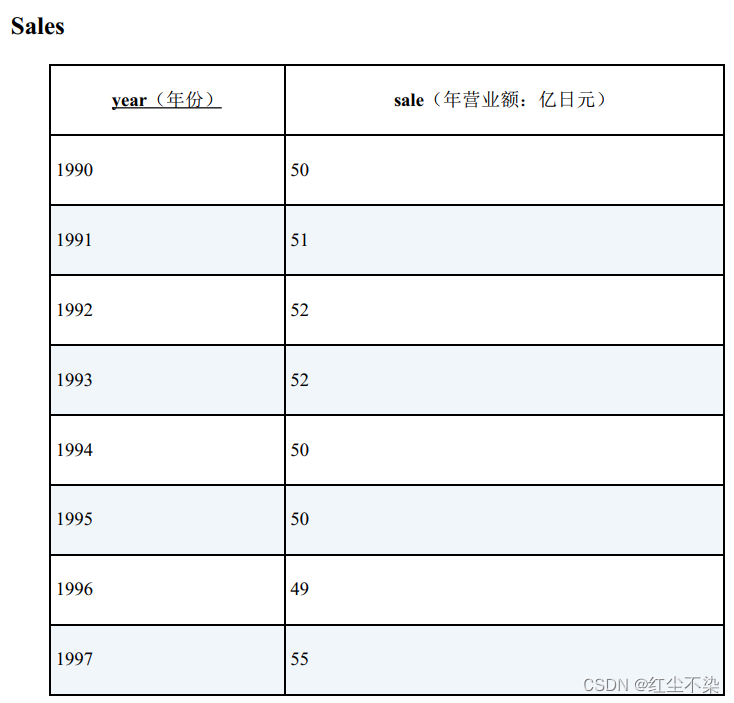
请根据这张表里的数据, 使用 SQL 输出与上一年相比营业额是增加了还是减少了, 抑或是没有变化。
求与上一年相比,没有变化的年份。
-- 求与上一年营业额一样的年份(1): 使用关联子查询
SELECT year,sale
FROM Sales S1
WHERE sale = (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) ORDER BY year;
-- 查询结果
year sale
----- ----
1993 52
1995 50
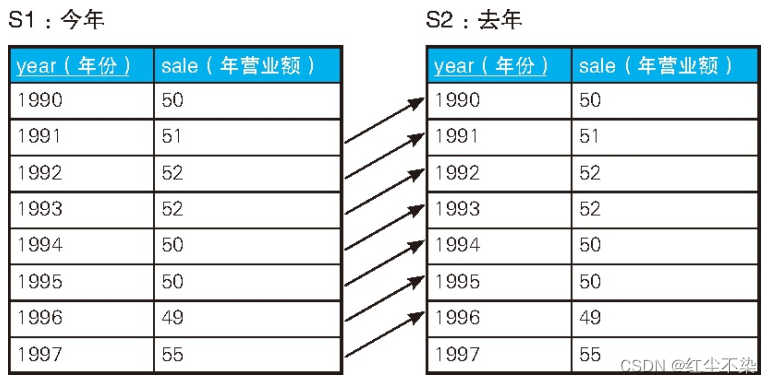
-- 求与上一年营业额一样的年份(2): 使用自连接
SELECT S1.year, S1.sale
FROM Sales S1, Sales S2
WHERE S2.sale = S1.sale AND S2.year = S1.year - 1
ORDER BY year;
用列表展示与上一年的比较结果
-- 求出是增长了还是减少了, 抑或是维持现状(1): 使用关联子查询
SELECT S1.year, S1.sale,
CASE WHEN sale = (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '→' -- 持平
WHEN sale > (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '↑' -- 增长
WHEN sale < (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '↓' -- 减少
ELSE '—' END AS var
FROM Sales S1
ORDER BY year;

-- 求出是增长了还是减少了, 抑或是维持现状(2): 使用自连接查询(最早的年份不会出现在结果里)
SELECT S1.year, S1.sale,
CASE WHEN S1.sale = S2.sale THEN '→'
WHEN S1.sale > S2.sale THEN '↑'
WHEN S1.sale < S2.sale THEN '↓'
ELSE ' — ' END AS var
FROM Sales S1, Sales S2
WHERE S2.year = S1.year - 1
ORDER BY year;
采用这种实现方法时, 由于这里没有 1990 年之前的数据, 所以 1990年会被排除掉, 执行结果会少一行。
继续看当前例题的执行结果可以发现, 时间轴是竖着展示的。 那么我们能不能像下面这样把时间轴改成横着展示呢?
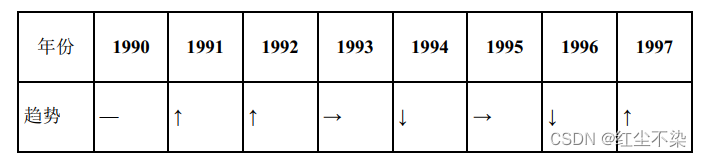
在上一节的外连接进行行列转换已经介绍了实现方法。 但是使用 SQL 进行格式转换并不是根本的办法。
针对查询结果的格式化,还是应该尽量交给宿主语言或者应用程序来完成。
时间轴有间断时:和过去最临近的时间进行比较
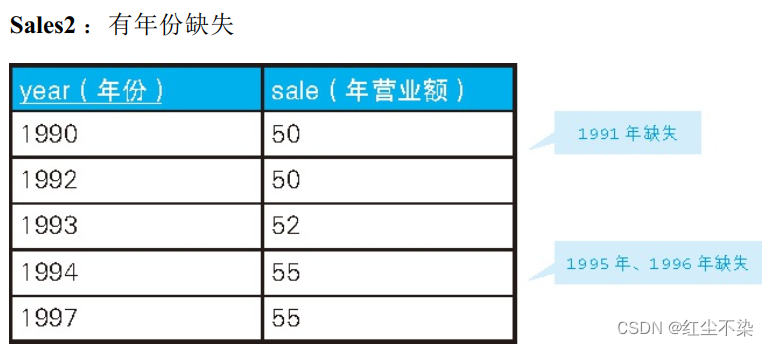
这样一来, 年份 – 1 这个条件就不能用了。 我们需要把它扩展成更普遍的情况, 用某一年的数据和它过去最临近的年份进行比较。
-- 查询与过去最临近的年份营业额相同的年份
SELECT year, sale FROM Sales2 S1
WHERE sale = (SELECT sale FROM Sales2 S2 WHERE S2.year =
-- 条件1 : 与该年份相比是过去的年份
-- 条件2 : 在满足条件1 的年份中, 年份最早的一个
(SELECT MAX(year) FROM Sales2 S3 WHERE S1.year > S3.year))
ORDER BY year;
查询与过去最临近的年份营业额相同的年份: 同时使用自连接
SELECT S1.year AS year, S1.year AS year
FROM Sales2 S1, Sales2 S2
WHERE S1.sale = S2.sale
AND S2.year = (SELECT MAX(year) FROM Sales2 S3 WHERE S1.year > S3.year)
ORDER BY year;
-- 查询结果
year sale
----- ----
1992 50
1997 55
通过这个方法,我们可以查询每一年与过去最临近的年份之间的营业额之差。
-- 求每一年与过去最临近的年份之间的营业额之差(1): 结果里不包含最早的年份
SELECT S2.year AS pre_year,S1.year AS now_year,S2.sale AS pre_sale,
S1.sale AS now_sale, S1.sale - S2.sale AS diff
FROM Sales2 S1, Sales2 S2
WHERE S2.year = (SELECT MAX(year) FROM Sales2 S3 WHERE S1.year > S3.year)
ORDER BY now_year;
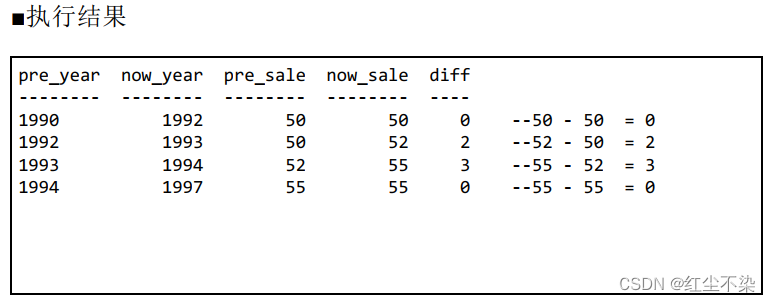
从执行结果可以发现, 这条 SQL 语句无法获取到最早年份 1990 年的数据。 这是因为, 表里没有比 1990 年更早的年份, 所以在进行内连接的时候 1990 年的数据就被排除掉了。 如果想让结果里出现 1990 年的数据, 可以使用“自外连接”来实现。
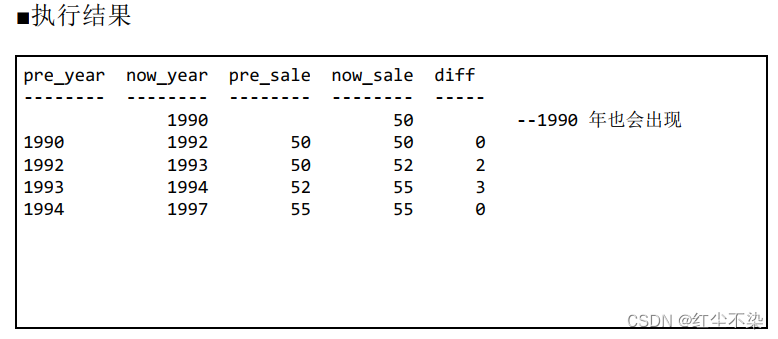
-- 求每一年与过去最临近的年份之间的营业额之差(2): 使用自外连接。 结果里包含最早的年份
SELECT S2.year AS pre_year, S1.year AS now_year, S2.sale AS pre_sale,
S1.sale AS now_sale, S1.sale - S2.sale AS diff
FROM Sales2 S1 LEFT OUTER JOIN Sales2 S2
ON S2.year = (SELECT MAX(year) FROM Sales2 S3 WHERE S1.year > S3.year)
ORDER BY now_year;
移动累计值和移动平均值
把截止到某个时间点且按时间记录的数值累加而得出来的数值称为累计值。
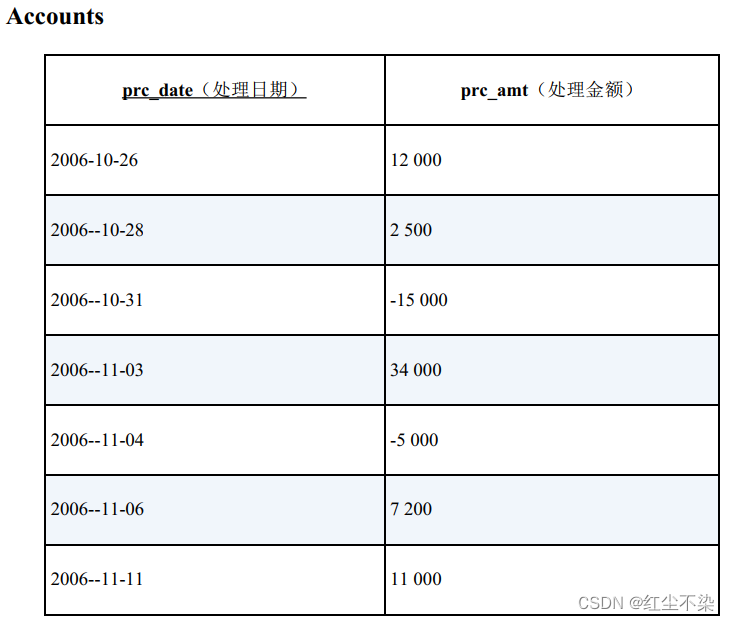
处理金额为正数代表存钱, 为负数代表取钱。 然后, 求截止到某个处理日期的处理金额的累计值, 实际上就是求截止到那个时间点的账户余额。 首先可以使用窗口函数来实现。
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date) AS onhand_amt
FROM Accounts;
这种实现方法还是依赖于具体的数据库的。 而如果使用标准 SQL-92,可以像下面这样写 SQL 语句。
-- 求累计值: 使用冯· 诺依曼型递归集合
SELECT prc_date, A1.prc_amt,( SELECT SUM(prc_amt)
FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date ) AS onhand_amt
FROM Accounts A1
ORDER BY prc_date;

接下来, 我们考虑一下如何以 3 次处理为单位求累计值, 即移动累计值。 所谓移动, 指的
168是将累计的数据行数固定(本例中为 3 行) , 一行一行地偏移, 如下表所示。
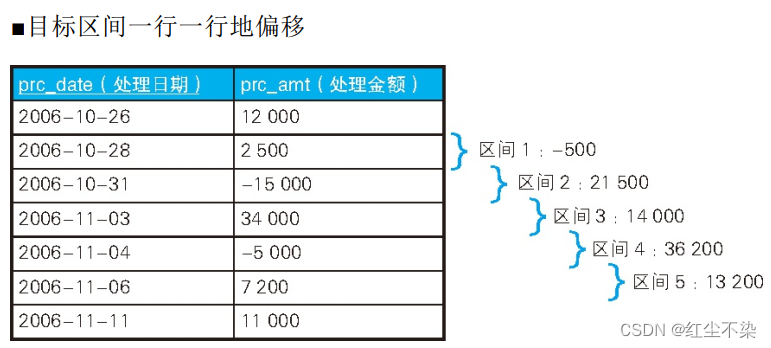
-- 求移动累计值(1): 使用窗口函数
SELECT prc_date, prc_amt, SUM(prc_amt)
OVER (ORDER BY prc_date ROWS 2 PRECEDING) AS onhand_amt
FROM Accounts;
如果使用关联子查询, 我们还可以像下面这样用标量子查询来计算行数。
-- 求移动累计值(2): 不满3 行的时间区间也输出
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date
AND A1.prc_date ) <= 3 ) AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;

这条语句的要点是, A3.prc_date 在以 A2.prc_date 为起点, 以 A1.prc_date 为终点的区间内移动。
通过修改“ <= 3 ”里的数字, 我们可以以任意行数为单位来进行偏移。
在处理前 2 行时,即使数据不满 3 行,这条 SQL 语句还是计算出了相应的累计值。其实,我们还可以将这样的情况作为无效来处理。
-- 移动累计值(3): 不满3 行的区间按无效处理
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt) FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date AND
(SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <= 3
HAVING COUNT(*) = 3 ) AS mvg_sum -- 不满3 行数据的不显示
FROM Accounts A1
ORDER BY prc_date;

到目前为止,写出来累计值的求法,所以使用的是SUM 函数。 如果求移动平均值( moving average),那么将 SUM 函数改写成 AVG 函数就可以了。
-- 求移动平均值
SELECT prc_date, A1.prc_amt,
(SELECT avg(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date ) AS onhand_amt
FROM Accounts A1
ORDER BY prc_date;
-- 求移动平均值(2): 不满3 行的时间区间也输出
SELECT prc_date, A1.prc_amt,
(SELECT avg(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date ) <= 3 ) AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;
-- 移动平均值(3): 不满3 行的区间按无效处理
SELECT prc_date, A1.prc_amt,
(SELECT avg(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date AND
(SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date) <= 3
HAVING COUNT(*) =3) AS mvg_sum -- 不满3 行数据的不显示
FROM Accounts A1
ORDER BY prc_date;
查询重叠的时间区间
有下面这样一张表 Reservations, 记录了酒店或者旅馆的预约情况。
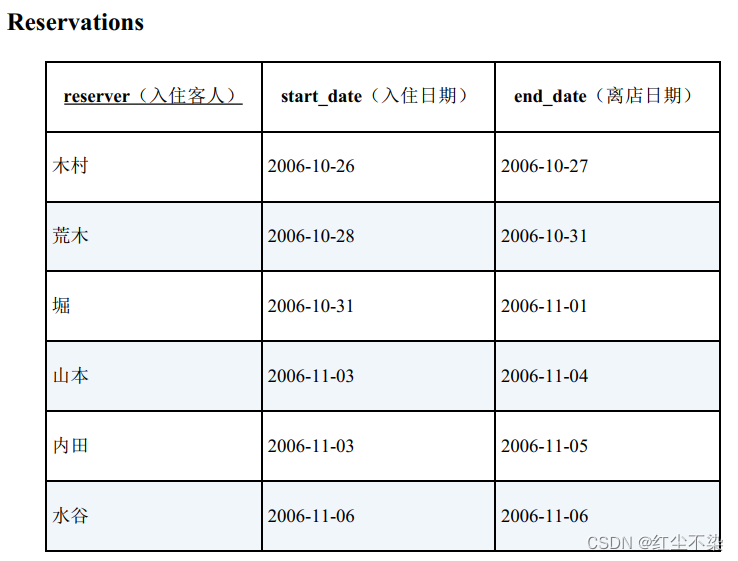
这张表里没有房间编号,请把表中数据当成是某一房间在某段期间内的预约情况。那么,正常情况下,每天只能有一组客人在该房间住宿。从表中数据可以看出,这里存在重叠的预定日期。
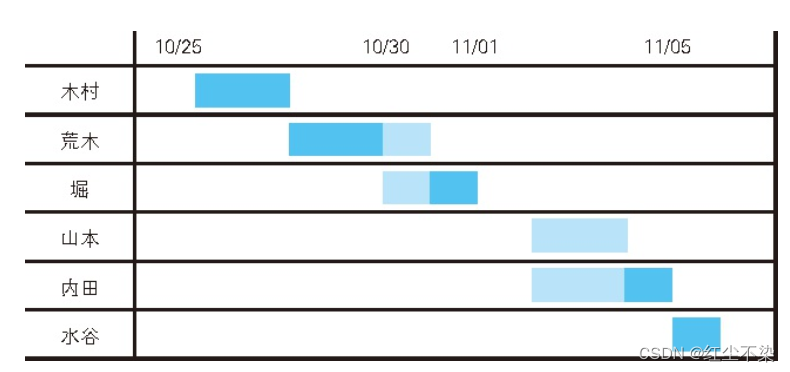
显然, 这样会有问题, 必须马上重新分配房间。现在面对的问题是如何查出住宿日期重叠的客人并列表显示。

-- 求重叠的住宿期间
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT * FROM Reservations R2
-- 与自己以外的客人进行比较
WHERE R1.reserver <> R2.reserver
-- 条件(1):自己的入住日期在他人的住宿期间内
AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date
-- 条件(2):自己的离店日期在他人的住宿期间内
OR R1.end_date BETWEEN R2.start_date AND R2.end_date));
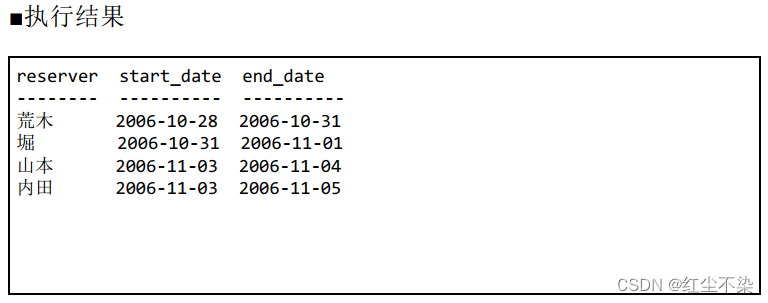
如果山本的入住日期不是 11 月 3号, 而是推迟了一天, 即 11 月 4 号, 那么查询结果里将不会出现内田。 这是因为, 内田的入住日期和离店日期都不再与任何人重叠, 于是条件 (1) 和条件 (2) 就都不满足了。 换句话说, 像内田这种自己的住宿期间完全包含了他人的住宿期间的情况, 会被这条 SQL 语句排除掉。
-- 升级版: 把完全包含别人的住宿期间的情况也输出
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT * FROM Reservations R2
WHERE R1.reserver <> R2.reserver
AND ( ( R1.start_date BETWEEN R2.start_date AND R2.end_date
OR R1.end_date BETWEEN R2.start_date AND R2.end_date)
OR ( R2.start_date BETWEEN R1.start_date AND R1.end_date
AND R2.end_date BETWEEN R1.start_date AND R1.end_date)));
本节小结
关联子查询是一种非常强大的运算,但是它也有缺点。
第一个缺点是代码的可读性不好。
可能也是因为还不太习惯使用关联子查询, 所以使用了关联子查询的 SQL 语句一般都不能让人一眼就看明白。
第二个缺点是性能不好。
特别是在 SELECT 子句里使用标量子查询时, 性能可能会变差, 需要注意一下。
下面是本节要点。
- 作为面向集合语言, SQL 在比较多行数据时, 不进行排序和循环。
- SQL 的做法是添加比较对象数据的集合, 通过关联子查询(或者自连接) 一行一行地偏移处理。 如果选用的数据库支持窗口函数, 也可以考虑使用窗口函数。
- 求累计值和移动平均值的基本思路是使用冯·诺依曼型递归集合。
- 关联子查询的缺点是性能及代码可读性不好。
- 人生中不可能所有的事情都一帆风顺。
1.7 用 SQL 进行集合运算
集合论是 SQL 语言的根基——这是贯穿全书的主题之一。因为它的这个特性, SQL 也被称为面向集合语言。只有从集合的角度来思考,才能明白 SQL 的强大威力。
集合运算的几个注意事项
集合运算符的参数是集合,从数据库实现层面上来说就是表或者视图。因为和高中学过的集合代数很像, 所以理解起来相对比较容易。 但是, SQL 还是有几个特别的地方需要注意一下。
-
注意事项: SQL 能操作具有重复行的集合,可以通过可选项 ALL来支持。
一般的集合论是不允许集合里存在重复元素的, 因此集合 {1, 1, 2, 3,3, 3} 和集合 {1, 2, 3} 被视为相同的集合。但是关系数据库里的表允许存在重复的行,称为多重集合。
SQL 的集合运算符也提供了允许重复和不允许重复的两种用法。如果直接使用 UNION或INTERSECT , 结果里就不会出现重复的行。 如果想在结果里留下重复行, 可以加上可选项 ALL , 写作UNION ALL。
集合运算符为了排除掉重复行, 默认地会发生排序, 而加上可选项 ALL 之后, 就不会再排序, 所以性能会有提升。这是非常有效的用于优化查询性能的方法,所以如果不关心结果是否存在重复行,或者确定结果里不会产生重复行,加上可选项 ALL 会更好些。
-
注意事项: 集合运算符有优先级
INTERSECT 比 UNION 和 EXCEPT 优先级更高。
-
注意事项: 各个 DBMS 提供商在集合运算的实现程度上参差不齐,SQL Server 从
2005 版开始支持 INTERSECT 和 EXCEPT , 而 MySQL 还都不支持。还有像 Oracle 这样, 实现了 EXCEPT 功能但却命名为 MINUS 的数据库。 -
注意事项 4: 除法运算没有标准定义
四则运算里的和(UNION ) 、 差(EXCEPT ) 、 积(CROSS JOIN )
都被引入了标准 SQL。商(DIVIDE BY )因为各种原因迟迟没能标准化。
比较表和表:检查集合相等性之基础篇
要判断两张表是否相等,相等指的是行数和列数以及内容都相同, 即“是同一个集合”的意思。
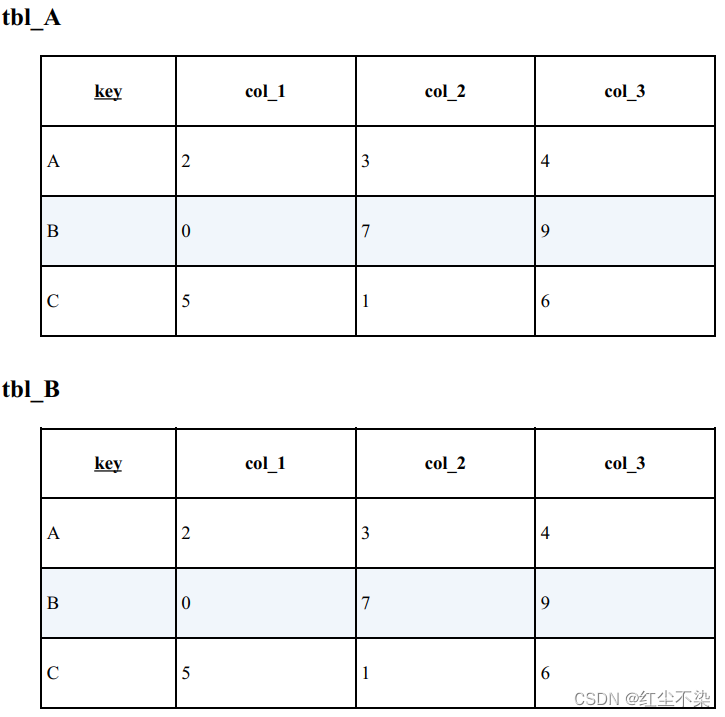
事先确认了表 tbl_A 和表 tbl_B 的行数是一样的(如果行数不一样, 那就不需要比较其他的了)。这两张表的行数都是3。如果下面这条 SQL 语句的执行结果是 3, 则说明两张表是相等的。 相反, 如果结果大于 3,则说明两张表不相等。
SELECT COUNT(*) AS row_cnt
FROM ( SELECT * FROM tbl_A UNION SELECT * FROM tbl_B ) TMP;
-- 执行结果
row_cnt
-------
3
如果表 tbl_A 和表 tbl_B 是相等的, 排除掉重复行后, 两个集合是完全重合的。
当然,也可以只比较表里的一部分列或者一部分行。只需要指定一下想要比较的列的名称,或者在 WHERE 子句里加入过滤条件就可以比较了。
对于任意的表 S, 都有下面的公式成立 : S UNION S = S
这是 UNION 的一个非常重要的性质, 在数学上我们称之为幂等性。
同一个集合无论加多少次结果都相同
S UNION S UNION S UNION S …… UNION S = S
有一点需要注意的是,如果改成对 S 执行多次 UNION ALL 操作,那么每次结果都会有变化,所以说 UNION ALL 不具有幂等性。 类似地, 如果对拥有重复行的表进行 UNION 操作, 也会失去幂等性。 换句话说,
UNION 的这个优雅而强大的幂等性只适用于数学意义上的集合, 对 SQL 中有重复数据的多重集合是不适用的。
比较表和表:检查集合相等性之进阶篇
在集合论里,判定两个集合是否相等时,一般使用下面两种方法。
- (A ⊂ B) 且 (A ⊃ B) ⇔ (A = B)
- (A ∪ B) = (A ∩ B) ⇔ (A = B)
第一种方法利用两个集合的包含关系来判定其相等性,如果集合 A 包含集合 B,且集合 B 包含集合A,则集合 A 和集合 B 相等。
第二种方法利用两个集合的并集和差集来判定其相等性。 如果用SQL 语言描述, 那就是如果 A UNION B = A INTERSECT B , 则集合 A 和集合 B 相等。
如果集合 A 和集合 B 相等, 那么 A UNION B = A = B 以及 A INTERSECT B = A = B 都是成立的。
除了 UNION 之外,另一个具有幂等性的运算符就是 INTERSECT 。
下面的图描述了两个不相同的集合 A 和 B 之间的差异逐渐变小、 相互接近的动画。
只需要判定 (A UNION B) EXCEPT (A INTERSECT B) 的结果集是不是空集就可以了。 如果 A = B, 则这个结果集是空集, 否则, 这个结果集里肯定有数据。
-- 两张表相等时返回“相等”, 否则返回“不相等”
SELECT CASE WHEN COUNT(*) = 0 THEN '相等' ELSE '不相等' END AS result
FROM ( (SELECT * FROM tbl_A UNION SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A INTERSECT SELECT * FROM tbl_B) ) TMP;
如果两张表的数据有差异, 需要把不同的行输出来。diff 命令是用来比较文件的,而这里的 SQL 语句就相当于 diff ,只不过是用来比较表的。 只需要求出两个集合的异或集就可以了,代码如下。
-- 用于比较表与表的diff
(SELECT * FROM tbl_A EXCEPT SELECT * FROM tbl_B)
UNION ALL
(SELECT * FROM tbl_B EXCEPT SELECT * FROM tbl_A);
因为 A-B 和 B-A 之间不可能有交集, 所以合并这两个结果时使用 UNION ALL 也没有关系。
用差集实现关系除法运算
SQL 里还没有能直接进行关系除法运算的运算符。因此,为了进行除法运算,必须自己实现。方法比较多, 其中具有代表性的是下面这三个。
- 嵌套使用 NOT EXISTS 。
- 使用 HAVING 子句转换成一对一关系。
- 把除法变成减法。
本节将介绍一下第三种方法。
集合论里的减法指的是差集运算。
示例,选用的是两张员工技术信息管理表。

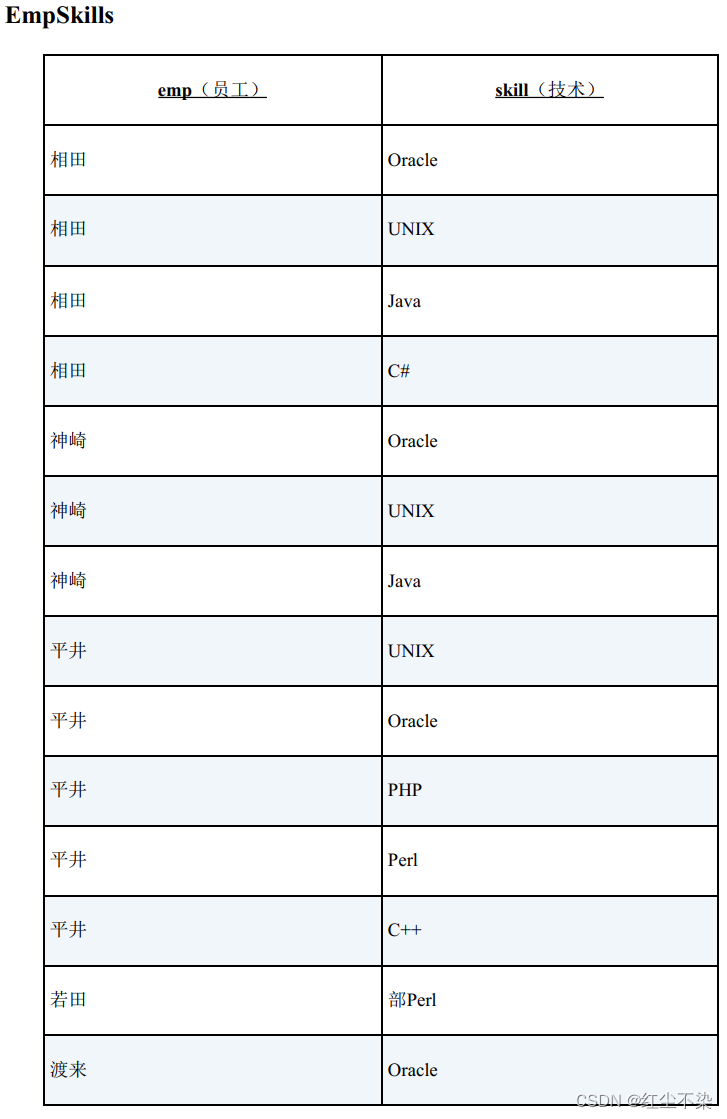
从表 EmpSkills 中找出精通表 Skills 中所有技术的员工。
-- 用求差集的方法进行关系除法运算(有余数)
SELECT DISTINCT emp
FROM EmpSkills ES1
WHERE NOT EXISTS (SELECT skill FROM Skills
EXCEPT SELECT skill FROM EmpSkills ES2 WHERE ES1.emp = ES2.emp);
-- 执行结果
emp
---
相田
神崎
集合运算的结果是空集,所以符号条件。
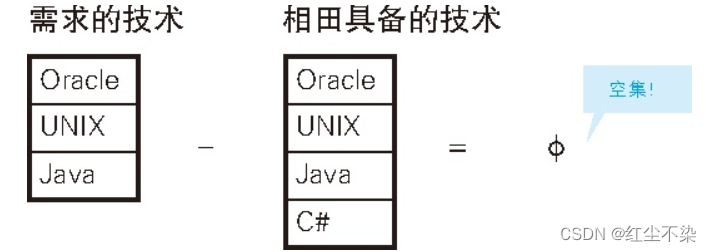
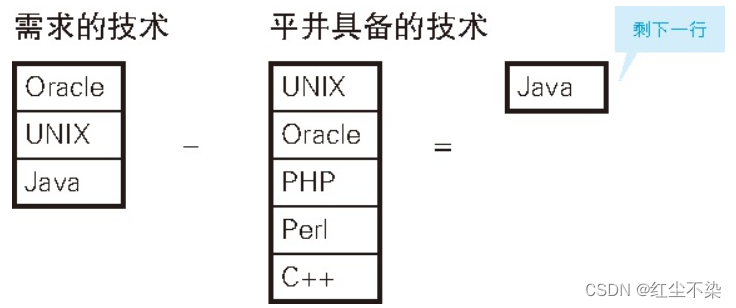
结果里剩下了Java这一行,平井不符合条件。这里的解题思路是先把处理的单位分割成了以员工为单位,然后将除法运算还原成了更加简单的减法运算。
寻找相等的子集
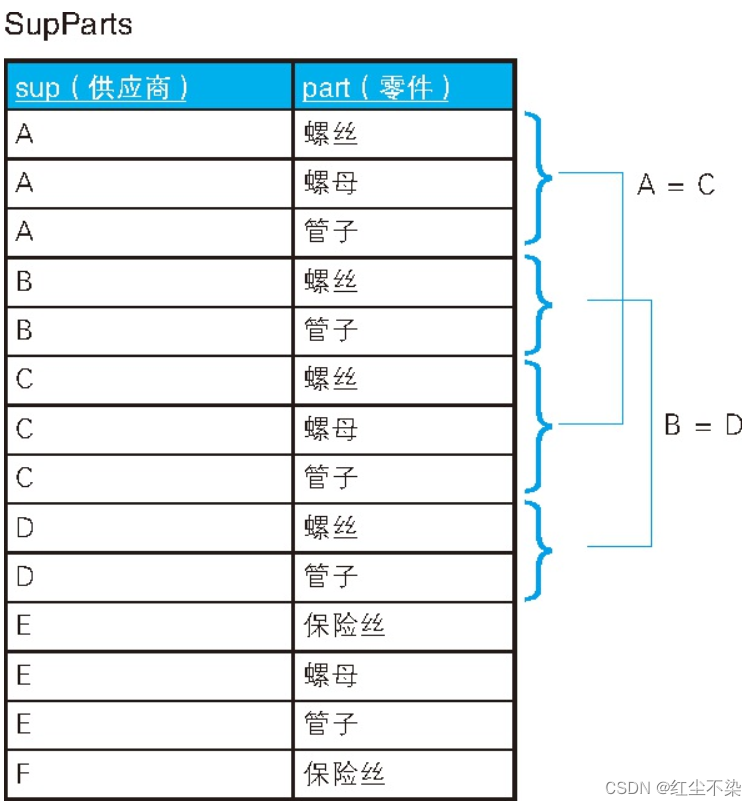
我们需要求的是,经营的零件在种类数和种类上都完全相同的供应商组合。 由上面的表格我们可以看出,答案是 A – C 和 B – D 这两组。A 和 E 虽然经营的零件种类数都是 3,但是零件的种类却不完全相同,所以不符合要求。F 则在种类数和种类上跟其他供应商都不相同,所以也不考虑。
SQL 并没有提供任何用于检查集合的包含关系或者相等性的谓词。 IN 谓词只能用来检查元素是否属于某个集合(∈ ) , 而不能检查集合是否是某个集合的子集(⊂)。
这个问题的特点在于比较的对象是集合。
首先, 我们来生成供应商的全部组合。
-- 生成供应商的全部组合
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
GROUP BY SP1.sup, SP2.sup;
接下来, 我们检查一下这些供应组合是否满足以下公式: (A ⊆ B)且(A ⊇ B) =>(A = B) 。 这个公式等价于下面两个条件。
条件 1:两个供应商都经营同种类型的零件
条件 2:两个供应商经营的零件种类数相同(即存在一一映射)
条件 1 只需要简单地按照“零件”列进行连接, 而条件 2 需要用 COUNT 函数来描述。
-- 生成供应商的全部组合
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
-- 条件1 : 经营同种类型的零件
WHERE SP1.sup < SP2.sup AND SP1.part = SP2.part
GROUP BY SP1.sup, SP2.sup
-- 条件2 : 经营的零件种类数相同
HAVING COUNT(*) = (SELECT COUNT(*) FROM SupParts SP3 WHERE SP3.sup = SP1.sup)
AND COUNT(*) = (SELECT COUNT(*) FROM SupParts SP4 WHERE SP4.sup = SP2.sup)
-- 执行结果
s1 s2
----------
A C
B D
如果我们把 HAVING 子句里的两个条件当成精确关系除法运算, 就会很好理解。加上这两个条件后,我们就能保证集合 A 和集合 B 的元素个数一致, 不会出现不足或者过剩(即存在一一映射)。
本例介绍的方法对关系除法运算进行了一般化,充分运用了 SQL 的面向集合的特性,是一种比较巧妙的解法。这种解法告诉我们,
SQL 在比较两个集合时,并不是以行为单位来比较的,而是把集合当作整体来处理的。
用于删除重复行的高效 SQL
通过关于删除重复行的例题来练习一下如何应用集合运算。关于这个问题,在1.2 节也曾练习过。
-- 删除重复行: 使用关联子查询
DELETE FROM Products WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2 WHERE Products.name = P2. name AND Products.price = P2.price ) ;
上面这条语句的思路是, 按照“商品名,价格”的组合汇总后, 求出每个组合的最大 rowid , 然后把其余的行都删除掉。 直接求删除哪些行比较困难, 所以这里先求出了要留下的行, 然后将它们从全部组合中提取出来除掉,把剩下的删除——这就是补集的思想。
我们假设表中加上了“rowid”列, 如下所示。
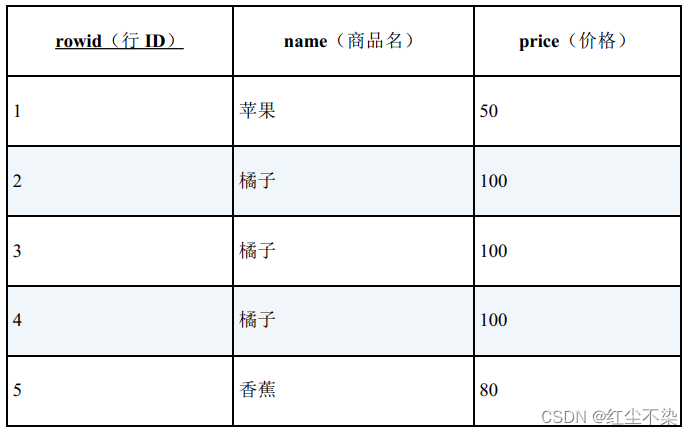
接下来,我们在子查询里直接求出要删除的 rowid。
使用极值函数让每组只留下一个 rowid 这一点与之前的做法一样。 不同的是, 这次需要把要留下的集合从表 Products 这个集合中减掉。 SQL 语句如下所示。
-- 用于删除重复行的高效SQL 语句(1): 通过EXCEPT 求补集
DELETE FROM Products
WHERE rowid IN (
-- 全部rowid
SELECT rowid FROM Products
EXCEPT -- 减去要留下的rowid
SELECT MAX(rowid) FROM Products GROUP BY name, price) ;
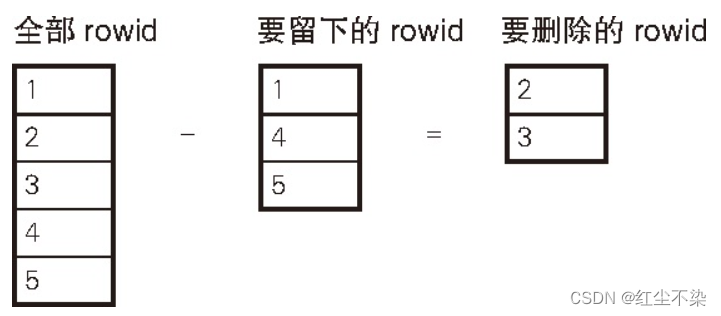
使用 EXCEPT 后,可以轻松求得补集。 把 EXCEPT 改写成 NOT IN 也是可以实现的。
-- 删除重复行的高效SQL 语句(2): 通过NOT IN 求补集
DELETE FROM Products
WHERE rowid NOT IN (SELECT MAX(rowid) FROM Products GROUP BY name, price);
本节小结
本节,学习了集合运算的使用方法。关于集合运算,SQL 的标准化进行得比较缓慢,所以尽管集合运算可以用来解决很多问题,但是很多人并不知道。
本节要点。
- 在集合运算方面, SQL 的标准化进行得比较缓慢, 直到现在也是实现状况因数据库不同而参差不齐, 因此使用的时候需要注意。
- 如果集合运算符不指定 ALL 可选项, 重复行会被排除掉, 而且,这种情况下还会发生排序,所以性能方面不够好。
- UNION 和 INTERSECT 都具有幂等性这一重要性质, 而 EXCEPT 不具有幂等性。
- 标准 SQL 没有关系除法的运算符, 需要自己实现。
- 判断两个集合是否相等时, 可以通过幂等性或一一映射两种方法。
- 使用 EXCEPT 可以很简单地求得补集。
1.8 EXISTS 谓词的用法
支撑 SQL 和关系数据库的基础理论主要有两个:一个是数学领域的集合论,另一个是作为现代逻辑学标准体系的谓词逻辑(predicate logic),准确地说是一阶谓词逻辑。
本节将重点介绍 EXISTS 谓词。EXISTS 不仅
可以将多行数据作为整体来表达高级的条件,而且使用关联子查询时性能仍然非常好
,这对SQL来说是不可或缺的功能。
理论篇
什么是谓词?
用一句话来说,谓词就是函数。当然,谓词与 SUM 或 AVG 这样的函数并不一样。谓词是一种特殊的函数, 返回值是真值。 前面提到的每个谓词,返回值都是 true、false 或者 unknown(一般的谓词逻辑里没有 unknown , 但是 SQL 采用的是三值逻辑, 因此具有三种真值)。
谓词逻辑提供谓词是为了判断命题(可以理解成陈述句) 的真假。
在关系数据库里,表中的一行数据可以看作是一个命题。
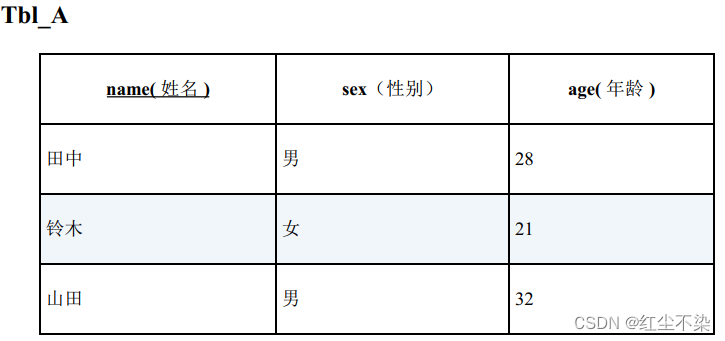
这张表里第一行数据就可以认为表示这样一个命题: 田中性别是男, 而且年龄是 28 岁。
表常常被认为是行的集合, 但从谓词逻辑的观点看, 也可以认为是命题的集合。
C.J. Date
曾经这样调侃过:
数据库这种叫法有点名不副实, 它存储的与其说是数据, 还不如说是命题 。
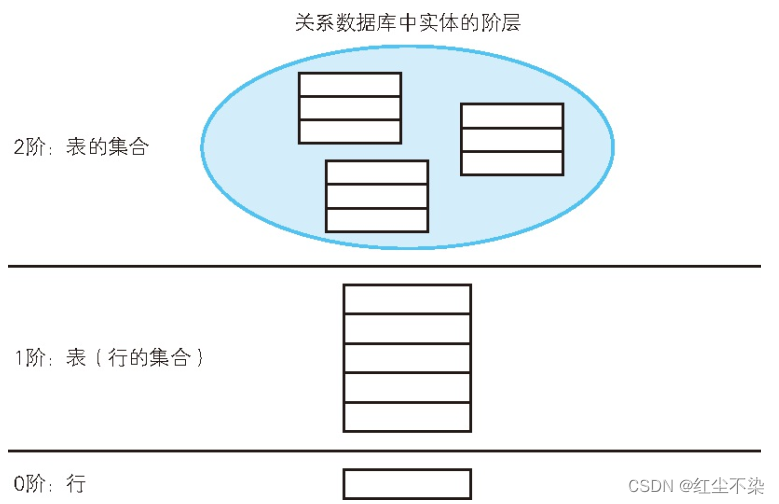
实体的阶层
同样是谓词,但是与 = 、BETWEEN 等相比,EXISTS 的用法还是大不相同的。概括来说,区别在于谓词的参数可以取什么值。
= 、BETWEEN 等谓词可以取的参数是单一值,我们称之为标量值。
EXISTS的参数不是单一值,而是行数据的集合。
无论子查询中选择什么样的列,对于 EXISTS 来说都是一样的。在 EXISTS 的子查询里,SELECT 子句的列表可以有下面这三种写法。
- 通配符: SELECT *
- 常量: SELECT ‘这里的内容任意’
- 列名: SELECT col
但是, 不管采用上面这三种写法中的哪一种, 得到的结果都是一样的。
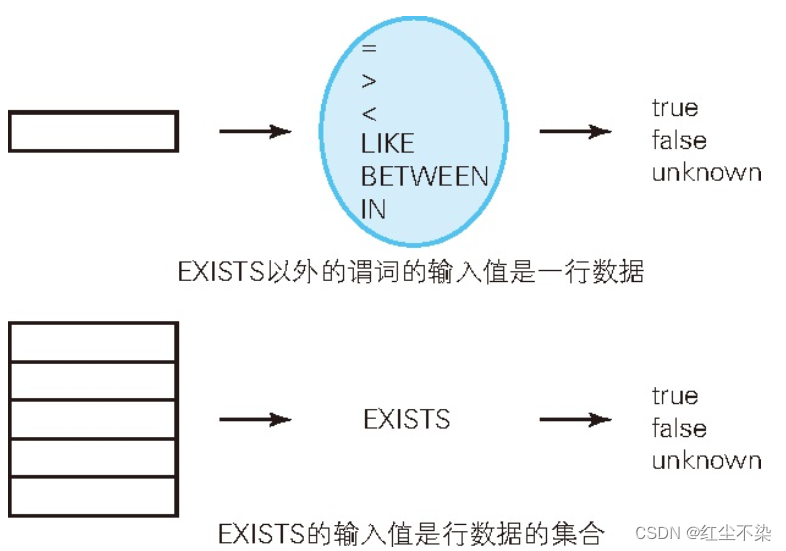
EXISTS 的特殊性在于输入值的阶数(输出值和其他谓词一样,都是真值)。谓词逻辑中,根据输入值的阶数对谓词进行分类。= 或者 BETWEEEN 等输入值为一行的谓词叫作一阶谓词,而像
EXISTS 这样输入值为行的集合的谓词叫作二阶谓词。
EXISTS 因接受的参数是集合这样的一阶实体而被称为二阶谓词。
全称量化和存在量化
谓词逻辑中有量词(限量词、 数量词) 这类特殊的谓词。 我们可以用它们来表达一些这样的命题: “所有的 x 都满足条件 P” 或者 “存在(至少一个)满足条件 P 的 x”。前者称为全称量词,后者称为存在量词,分别记作 ∀、 ∃ 。
SQL 中的 EXISTS 谓词实现了谓词逻辑中的存在量词。
然而遗憾的是, 对于与本节核心内容有关的另一个全称量词, SQL 却并没有予以实现。 C.J. Date 在自己的书里写了 FORALL 谓词, 但实际上 SQL 里并没有这个实现。
但是没有全称量词并不算是 SQL 的致命缺陷。因为全称量词和存在量词只要定义了一个,另一个就可以被推导出来。
∀ x P x = ¬ ∃ x ¬P(所有的 x 都满足条件 P = 不存在不满足条件 P 的x)
∃ x P x = ¬ ∀ x ¬P x(存在 x 满足条件 P = 并非所有的 x 都不满足条件P)
实践篇
查询表中“不”存在的数据。
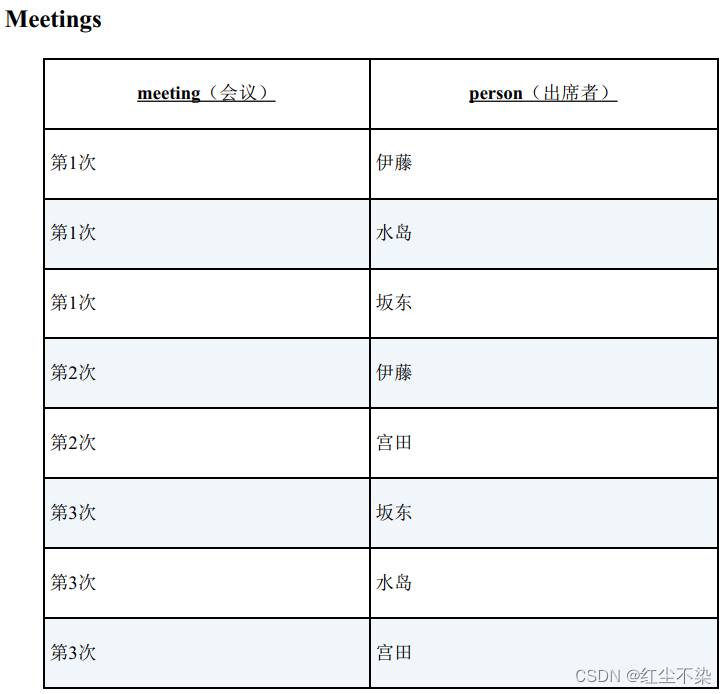
求没有参加某次会议的人。
思路:假设所有人都参加了全部会议,并以此生成一个集合,然后从中减去实际参加会议的人。这样就能得到缺席会议的人。
-- 交叉连接,求出所有参加会议的集合
SELECT DISTINCT M1.meeting, M2.person FROM Meetings M1 CROSS JOIN Meetings M2;
-- 求出缺席者的SQL 语句(1):存在量化的应用
SELECT DISTINCT M1.meeting, M2.person FROM Meetings M1 CROSS JOIN Meetings M2
WHERE NOT EXISTS (SELECT * FROM Meetings M3
WHERE M1.meeting = M3.meeting AND M2.person = M3.person);
还可以用集合论的方法来解答, 即像下面这样使用差集运算。
---- 求出缺席者的SQL 语句(2): 使用差集运算
SELECT M1.meeting, M2.person FROM Meetings M1, Meetings M2
EXCEPT
SELECT meeting,person FROM Meetings;
通过以上两条 SQL 语句的比较我们可以明白,
NOT EXISTS 直接具备了差集运算的功能。
全称量化(1) : 习惯肯定(任意一个都满足) ⇔ 双重否定(不存在不满足)之间的转换
使用 EXISTS 谓词来表达全称量化。 这是EXISTS 的用法中很具有代表性的一个用法。通过学习,希望能习惯
从全称量化 (所有的行都满足) 到其双重否定(不存在不满足的行)的转换。
示例:
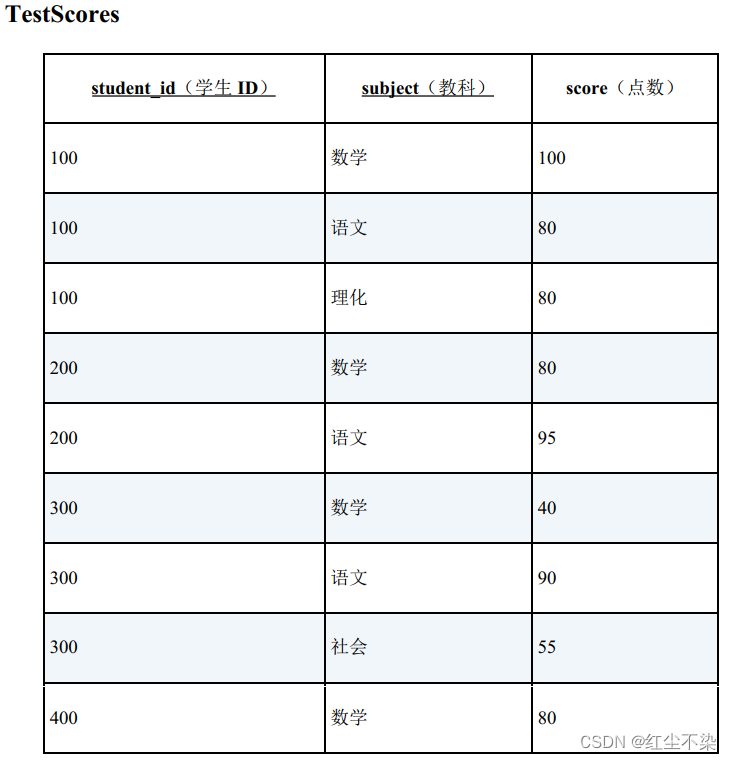
请查询出所有科目分数都在 50 分以上的学生。
将查询条件“所有科目分数都在 50 分以上”转换成它的双重否定“没有一个科目分数不满 50 分”,然后用 NOT EXISTS 来表示转换后的命题。
select distinct t.student_id from testscores t
where not exists (
select * from testscores t2
where t2.student_id = t.student_id and t2.score < 50
)
-- 查询结果
student_id
-----------
100
200
400
请思考一下如何查询出满足下列条件的学生。
- 数学的分数在 80 分以上。
- 语文的分数在 50 分以上。
结果应该是学号分别为 100、 200、 400 的学生。 这里, 学号为 400 的学生没有语文分数的数据, 但是也需要包含在结果里。
如果改成下面这样的说法, 就能明白它是全称量化的命题了。
某个学生的所有行数据中, 如果科目是数学, 则分数在 80 分以上; 如果科目是语文, 则分数在 50 分以上。
这其实是针对同一个集合内的行数据进行了条件分支后的全称量化。
对于满足条件的行,该 SQL 语句会返回 1 ,否则返回 0 。
select distinct t.student_id from testscores t
where t.subject in ('数学','语文')
and not exists (
select * from testscores t2
where t2.student_id = t.student_id and
case when t2.subject = '数学' and t2.score < 80 then 1
when t2.subject = '语文' and t2.score < 50 then 1
else 0
end
)
student_id
-----------
100
200
400
首先, 数学和语文之外的科目不在我们考虑范围之内, 所以通过 IN 条件进行一下过滤。 然后, 通过子查询来描述“数学 80 分以上, 语文 50 分以上”这个条件。
排除掉没有语文分数的学号为 400 的学生。
这里, 学生必须两门科目都有分数才行, 所以我们可以加上用于判断行数的 HAVING 子句来实现。
SELECT student_id FROM TestScores TS1
WHERE subject IN ('数学', '语文')
AND NOT EXISTS (
SELECT *
FROM TestScores TS2 WHERE TS2.student_id = TS1.student_id AND
1 = CASE WHEN subject = '数学' AND score < 80 THEN 1
WHEN subject = '语文' AND score < 50 THEN 1
ELSE 0 END)
GROUP BY student_id
HAVING COUNT(*) = 2; -- 必须两门科目都有分数
-- 执行结果
student_id
----------
100
200
这里已经以学号为列进行了聚合, 所以 SELECT 子句里的 DISTINCT 就不需要了。
全称量化 (2) : 集合 VS 谓词——哪个更强大?
EXISTS 和 HAVING 有一个地方很像, 即都是以集合而不是个体为单位来操作数据。两者在很多情况下都是可以互换的,用其中一个写出的查询语句,大多时候也可以用另一个来写。
假设存在下面这样的项目工程管理表
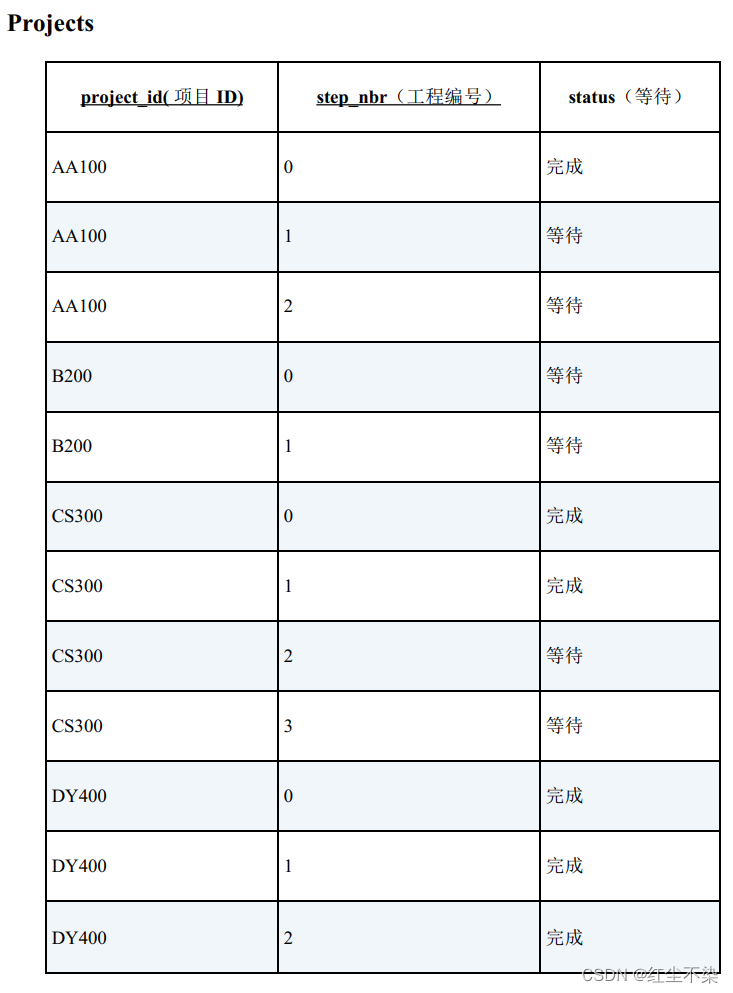
这张表的主键是项目 ID,工程编号。
已经完成的工程其状态列的值是完成, 等待上一个工程完成的工程其状态列的值是等待。
问题:从这张表中查询出哪些项目已经完成到了工程 1。
-- 查询完成到了工程1 的项目: 面向集合的解法
SELECT P.PROJECT_ID
FROM PROJECTS P
GROUP BY P.PROJECT_ID
HAVING COUNT(*) = SUM(CASE WHEN P.STATUS = '完成' AND P.STEP_NBR <= '1' THEN 1
WHEN P.STATUS = '等待' AND P.STEP_NBR > '1' THEN 1
ELSE 0 END)
针对每个项目,将工程编号为 1 以下且状态为“完成”的行数,和工程编号大于 1 且状态为“等待”的行
数加在一起, 如果和等于该项目数据的总行数, 则该项目符合查询条件。
这道例题用谓词逻辑该如何解决呢? 其实这道例题也能看作是全称量化的一个特例。
把查询条件看作是下面这样的全称量化命题。
某个项目的所有行数据中, 如果工程编号是 1 以下,则该工程已完成;如果工程编号比 1 大, 则该工程还在等待。(肯定)
等价于
不存在某个项目的行数据中,如果工程编号是 1 以下,该工程等待;如果工程编号比 1 大, 则该工程完成。(双重否定)
-- 查询完成到了工程1 的项目: 谓词逻辑的解法
SELECT * FROM Projects P1
WHERE NOT EXISTS (
SELECT status FROM Projects P2
-- 以项目为单位进行条件判断
WHERE P1.project_id = P2. project_id
-- 使用双重否定来表达全称量化命题
AND status <> (CASE WHEN step_nbr <= 1 THEN '完成' ELSE '等待' END)
);
NOT EXISTS 的优缺点
:
缺点:
- 代码看起来不是那么容易理解。
优点:
- 性能好(只要有一行满足条件,查询就会终止,不一定需要查询所有行的数据,能通过连接条件,使用project_id列的索引,这样查询起来会更快)。
- 结果里能包含的信息量更大(使用 HAVING,结果会被聚合,只能获取到项目 ID,使用 EXISTS,则能把集合里的元素整体都获取到)。
对列进行量化:查询全是 1 的行。
不好的表在设计上一般都会存在一些典型的问题。例如没有主键且允许重复的行存在,或者是完全忽略掉列应该作为属性来定义的这个习惯, 让某一列拥有了多个含义。
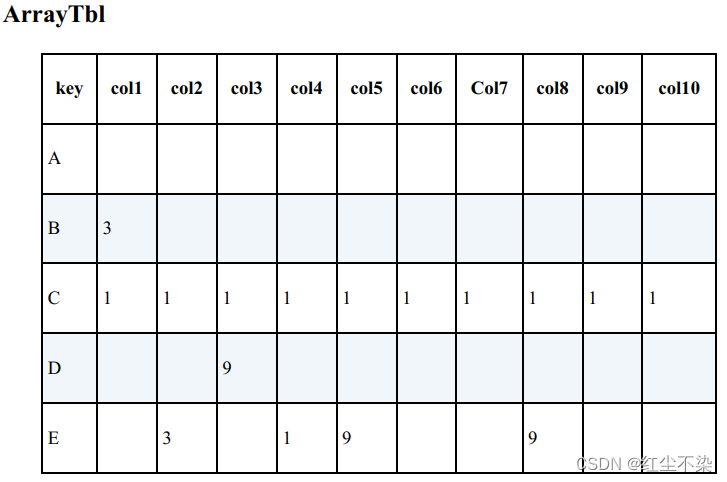
在设计表时有一条原则:让列具有一定的扩展性。数组中的元素不应该对应表中的列,而是应该对应行。
表是对现实世界中实体(entity) 的抽象
查询“都是 1”的行。
EXISTS 谓词主要用于进行“行方向”的量化, 而对于这个问题,需要进行“列方向”的量化。
--“列方向”的全称量化: 不优雅的解答
SELECT *
FROM ArrayTbl
WHERE col1 = 1
AND col2 = 1
···
AND col10 = 1;
--“列方向”的全称量化: 优雅的解答
SELECT *
FROM ArrayTbl
WHERE 1 = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
这条 SQL 语句将“ col1 ~ col10 的全部列都是 1” 这个全称量化命题直接翻译成了 SQL 语句, 既简洁又很好理解。
如果想表达“至少有一个 9”这样的存在量化命题, 可以使用 ALL 的反义谓词 ANY 。
-- 列方向的存在量化(1)
SELECT *
FROM ArrayTbl
WHERE 9 = ANY (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
也可以使用 IN 谓词代替 ANY 。
-- 列方向的存在量化(2)
SELECT *
FROM ArrayTbl
WHERE 9 IN (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
但是,如果左边不是具体值而是 NULL , 这种写法就不行了。
-- 查询全是NULL 的行: 错误的解法
SELECT *
FROM ArrayTbl
WHERE NULL = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
这种情况下, 我们需要使用 COALESCE 函数。
-- 查询全是NULL 的行: 正确的解法
SELECT *
FROM ArrayTbl
WHERE COALESCE(col1, col2, col3, col4, col5, col6, col7, col8, col9, col10) IS NULL
这样,列方向的量化也就不足为惧了。
本节小结
从集合论的角度来看, SQL 具备的能力配得上它面向集合语言的称号。而从谓词逻辑的角度来看,又能发现它作为一种函数式语言的特点。
在 SQL中, EXISTS 谓词是很重要的。 如果能灵活运用 EXISTS , 那么可以说就突破了中级水平关卡中的一个。
本节要点
- SQL 中的谓词指的是返回真值的函数。
- EXISTS 与其他谓词不同,接受的参数是集合。
- 因此 EXISTS 可以看成是一种高阶函数。
- SQL 中没有与全称量词相当的谓词, 可以使用 NOT EXISTS 代替。
1.9 用 SQL 处理数列
关系模型的数据结构里, 并没有“顺序”这一概念。因此,基于它实现的关系数据库中的表和视图的行和列也必然没有顺序。同样地,处理有序集合也并非 SQL 的直接用途。
因此, SQL 处理有序集合的方法, 与原本就以处理顺序为目的的面向过程语言及文件系统的处理方法在性质上是不同的。
生成连续编号
如何只用一条 SQL 就能生成任意长的连续编号序列呢?例如生成 0 ~ 99 这 100 个连续编号。
谜题: 00 ~ 99 的 100 个数中, 0, 1, 2,…, 9 这 10 个数字分别出现了多少次?
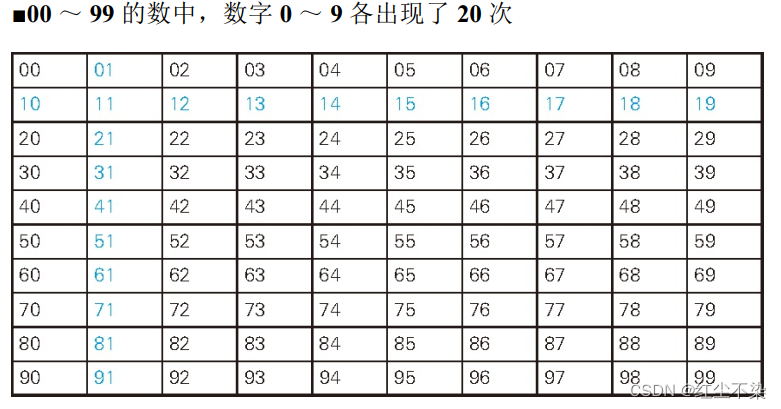
通过这个谜题想让大家明白的是,如果把数看成字符串,其实它就是由各个数位上的数字组成的集合。
首先存储一个数字表。

-- 求连续编号(1): 求 0 ~ 99 的数
SELECT D1.digit + (D2.digit * 10) AS seq
FROM digit D1 CROSS JOIN digit D2
ORDER BY seq;
D1 代表个位数字的集合, D2 代表十位数字的集合。交叉连接可以得到两个集合中元素的所有可能的组合。
笛卡儿积: 得到所有可能的组合
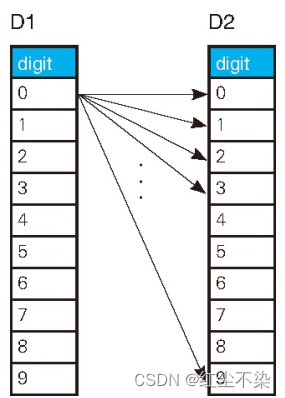
同样地,通过追加 D3、D4 等集合,不论多少位的数都可以生成。
-- 求连续编号(2): 求1~542 的数
SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100) AS seq
FROM Digits D1 CROSS JOIN Digits D2 CROSS JOIN Digits D3
WHERE D1.digit + (D2.digit * 10) + (D3.digit * 100) BETWEEN 1 AND 542
ORDER BY seq;
这种生成连续编号的方法,完全忽略了数的顺序这一属性。仅把数看成是数字的组合。这种解法更能体现出 SQL 语言的特色。
通过将这个查询的结果存储在视图里,就可以在需要连续编号时通过简单的 SELECT 来获取需要的编号。
-- 生成序列视图(包含0~999)
CREATE VIEW Sequence (seq) AS SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100)
FROM Digits D1 CROSS JOIN Digits D2 CROSS JOIN Digits D3;
-- 从序列视图中获取1~100
SELECT seq FROM Sequence
WHERE seq BETWEEN 1 AND 100
ORDER BY seq;
求全部的缺失编号
1.4 节介绍了查找连续编号中的缺失编号的方法。这里求出缺失的全部编号。
生成 0 ~ n 的自然数集合, 和比较的对象表进行差集运算,就可以求出全部编号。
一张编号有缺失的表

-- EXCEPT 版
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
EXCEPT
SELECT seq FROM SeqTbl;
-- NOT IN 版
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12 AND seq NOT IN (SELECT seq FROM SeqTbl);
动态地指定目标表的最大值和最小值。
-- 动态地指定连续编号范围的SQL 语句
SELECT seq
FROM Sequence
WHERE seq BETWEEN (SELECT MIN(seq) FROM SeqTbl) AND (SELECT MAX(seq) FROM SeqTbl)
EXCEPT
SELECT seq FROM SeqTbl;
这种写法在查询上限和下限未必固定的表时非常方便。两个自查询没有相关性,而且只会执行一次,如果在“seq”列上建立索引,那么极值函数的运行可以变得更快速。
三个人能坐得下吗
一张存储了火车座位预订情况的表。

假设一共 3 个人一起去旅行, 准备预订这列火车的车票。 问题是, 从 1 ~ 15 的座位编号中, 找出连续 3 个空位的全部组合。
假设所有的座位排成了一条直线。

需要满足的条件是, 以 n 为起点、 n + (3-1) 为终点的座位全部都是未预订状态。
-- 找出需要的空位(1): 不考虑座位的换排
SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat
FROM Seats S1, Seats S2
WHERE S2.seat = S1.seat + (:head_cnt -1) AND NOT EXISTS
(SELECT * FROM Seats S3 WHERE S3.seat BETWEEN S1.seat AND S2.seat
AND S3.status <> '未预订' );
其中,“:head_cnt ”是表示需要的空位个数的参数。通过往这个参数里赋具体值,可以应对任意多个人的预约。
对于这个查询的要点,我们分成两个步骤来理解更容易一些。
第一步: 通过自连接生成起点和终点的组合
保证结果中出现的只有从起点到终点刚好包含 3 个空位的序列。
第二步: 描述起点到终点之间所有的点需要满足的条件
增加一个在起点和终点之间移动的所有点的集合。限定移动范围时使用 BETWEEN 谓词很方便。
假设这列火车每一排有 5 个座位。在表中加上表示行编号“row_id”列。
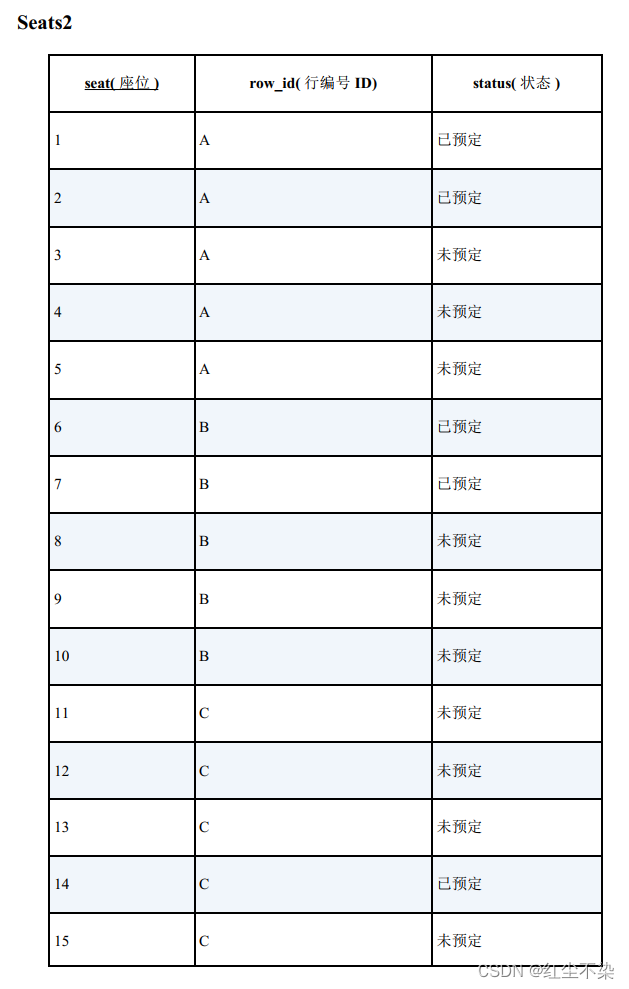
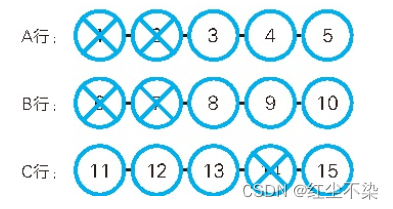
要想解决换排的问题,除了要求序列内的所有座位全部都是空位,还需要加入“全部都在一排”这样一个条件。
-- 找出需要的空位(2): 考虑座位的换排
SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat
FROM Seats2 S1, Seats2 S2
WHERE S2.seat = S1.seat + (:head_cnt -1)
AND NOT EXISTS ( SELECT * FROM Seats2 S3
WHERE S3.seat BETWEEN S1.seat AND S2.seat AND (
S3.status <> '未预订' OR S3.row_id <> S1.row_id));
序列内的点需要满足的条件是, “所有座位的状态都是‘未预订’, 且行编号相同”。 这里新加的条件是“行编号相同”, 等价于“与起点的行编号相同”。
S3.status = '未预订' AND S3.row_id = S1.row_id
由于 SQL 中不存在全称量词,所以必须使用这个条件的否定,即改成下面这样的否定形式。
NOT (S3.status = '未预订' AND S3.row_id = S1.row_id)
-- 等价于
S3.status <> '未预订' OR S3.row_id <> S1.row_id
肯定 ⇔ 双重否定之间的等价转换是使用 SQL 进行全称量化时的必备技巧
最多能坐下多少人

求最长的序列。
就这张表而言, 长度为 4 的序列“2 ~ 5”就是答案。
要想保证从座位 A 到另一个座位 B 是一个序列, 则下面的 3 个条件必须全部都满足。
条件 1: 起点到终点之间的所有座位状态都是“未预订”。
条件 2: 起点之前的座位状态不是“未预订”。
条件 3: 终点之后的座位状态不是“未预订”。
分两个步骤来解决。第一步生成符合条件的视图,第二步求出最长的序列。
-- 第一阶段: 生成存储了所有序列的视图
CREATE VIEW Sequences (start_seat, end_seat, seat_cnt) AS
SELECT S1.seat AS start_seat,S2.seat AS end_seat,S2.seat - S1.seat + 1 AS seat_cnt
FROM seats3 S1, seats3 S2
-- 第一步: 生成起点和终点的组合
WHERE S1.seat <= S2.seat
-- 第二步:描述序列内所有点需要满足的条件
AND NOT EXISTS
(SELECT * FROM seats3 S3
WHERE -- 条件1 的否定
( S3.seat BETWEEN S1.seat AND S2.seat AND S3.status <> '未预订')
-- 条件2 的否定
OR (S3.seat = S2.seat + 1 AND S3.status = '未预订' )
-- 条件3 的否定
OR (S3.seat = S1.seat - 1 AND S3.status = '未预订' ));
-- 第二阶段: 求最长的序列
SELECT start_seat, '~', end_seat, seat_cnt
FROM Sequences
WHERE seat_cnt = (SELECT MAX(seat_cnt) FROM Sequences);
单调递增和单调递减
存在下面这样一张反映了某公司股价动态的表。
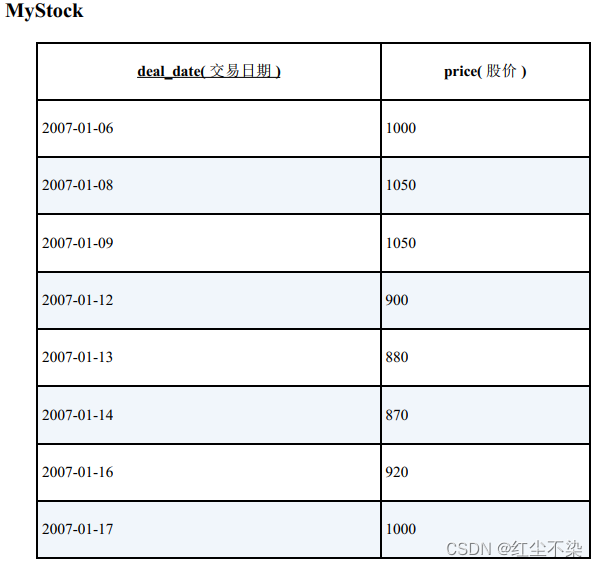
求一下股价单调递增的时间区间。
第一步——通过自连接生成起点和终点的组合。
-- 生成起点和终点的组合的SQL 语句
SELECT S1.deal_date AS start_date,S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date;
第二步——描述起点和终点之间的所有点需要满足的条件。
能够保证某个时间区间内股价单调递增的充分条件是,对于区间内的任意两个时间点,命题“较晚时间的股价高于较早时间的股价”都成立。等价于
区间内不存在两个时间点使得较早时间的股价高于较晚时间的股价。
-- 求单调递增的区间的SQL语句:子集也输出
SELECT S1.deal_date AS start_date,
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date
AND NOT EXISTS
( SELECT * FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date AND S3.price >= S4.price);
因为需要取区间内的两个点, 所以需要相应地增加两个集合, 即S3 和 S4。 子查询里的两个 BETWEEN 谓词用于保证 S3 和 S4 的移动范围在区间内。后面的 S3.deal_date < S4.deal_date 描述了 S4 里的日期比 S3 里的日期晚的条件。 最后的 S3.price >= S4.price 描述了过去的股价更高(或者持平) 的条件。

最后,要把这些不需要的子集排除掉。 使用极值函数很容易就能实现。
-- 排除掉子集, 只取最长的时间区间
SELECT MIN(start_date) AS start_date,end_date
FROM (
SELECT S1.deal_date AS start_date,MAX(S2.deal_date) AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date AND NOT EXISTS
(
SELECT * FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price
)
GROUP BY S1.deal_date
) TMP
GROUP BY end_date;
这段代码的关键在于最大限度地延伸起点和终点。
本节小结
本节主要介绍了以数列为代表的有序集合的处理方法, 不只列举出了解决问题的 Tips, 还试着挖掘出了隐藏在解法背后的 SQL 的原理。所有的问题都能用集合论和谓词逻辑的方法来解决。熟练掌握这两个概念的用法, 对于提升 SQL 技能来说是必不可少的。
本节要点。
- SQL 处理数据的方法有两种。
- 第一种是把数据看成忽略了顺序的集合。
-
第二种是把数据看成有序的集合, 此时的基本方法如下。
a. 首先用自连接生成起点和终点的组合
b. 其次在子查询中描述内部的各个元素之间必须满足的关系 - 要在 SQL 中表达全称量化时, 需要将全称量化命题转换成存在量化命题的否定形式,并使用 NOT EXISTS 谓词。这是因为SQL 只实现了谓词逻辑中的存在量词。
1.10 HAVING 子句又回来了
我在教 SQL 课程的时候, 最重要的课题之一是让学生们暂时忘掉他们已经习惯了的面向过程语言。 我使用的方法是强调
SQL 的处理单位不是记录, 而是集合。
——Joe Celko
学习 HAVING 子句的用法是帮助我们顺利地忘掉面向过程语言的思考方式并理解 SQL面向集合特性的最为有效的方法。这是因为,HAVING 子句的处理对象是集合而不是记录,所以只有习惯了面向集合的思考方式,才能真正地学好它。
各队, 全体点名
查出现在可以出勤的队伍。 可以出勤即队伍里所有队员都处于“待命”状态。
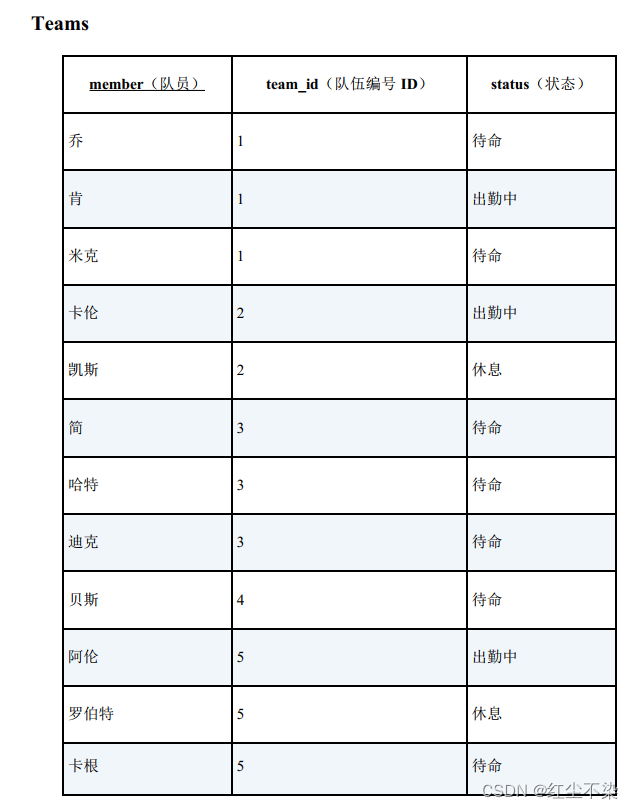
“所有队员都处于‘待命’状态”这个条件是全称量化命题, 所以可以用NOT EXISTS 来表达。
-- 用谓词表达全称量化命题
SELECT team_id,member
FROM Teams T1
WHERE not exists (
SELECT * FROM Teams T2
WHERE T1.team_id = T2.team_id AND status <> '待命'
);
-- 用集合表达全称量化命题(1)
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING COUNT(*) = SUM(CASE WHEN status = '待命' THEN 1 ELSE 0 END);
GROUP BY 子句将 Teams 集合以队伍为单位划分成几个子集。
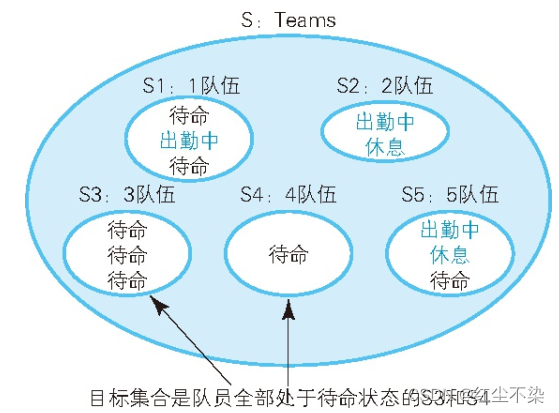
目标集合是 S3 和 S4,只有这两个集合拥有而其他集合没有的特征,
处于“待命”状态的数据行数与集合中数据总行数相等。
这个条件可以用 CASE 表达式来表达, 状态为“待命”的情况下返回 1 , 其他情况下返回 0。
-- 用集合表达全称量化命题(2)
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING MAX(status) = '待命' AND MIN(status) = '待命';
某个集合中, 如果元素最大值和最小值相等,那么这个集合中肯定只有一种值。因为如果包含多种值, 最大值和最小值肯定不会相等。
-- 列表显示各个队伍是否所有队员都在待命
SELECT team_id,
CASE WHEN MAX(status) = '待命' AND MIN(status) = '待命'
THEN '全都在待命'
ELSE '队长! 人手不够' END AS status
FROM Teams
GROUP BY team_id;
也可以把条件放在 SELECT 子句里, 以列表形式显示出各个队伍是否所有队员都在待命, 这样的结果更加一目了然。需要注意的是, 条件移到 SELECT 子句后, 查询可能就不会被数据库优化了, 所以性能上相比 HAVING 子句的写法会差一些。
单重集合与多重集合
关系数据库中的集合是允许重复数据存在的多重集合。与之相反,通常意义的集合论中的集合不允许数据重复,被称为“单重集合”(这是笔者自己造的词, 并非公认的术语)。
一张管理各个生产地的材料库存的表。
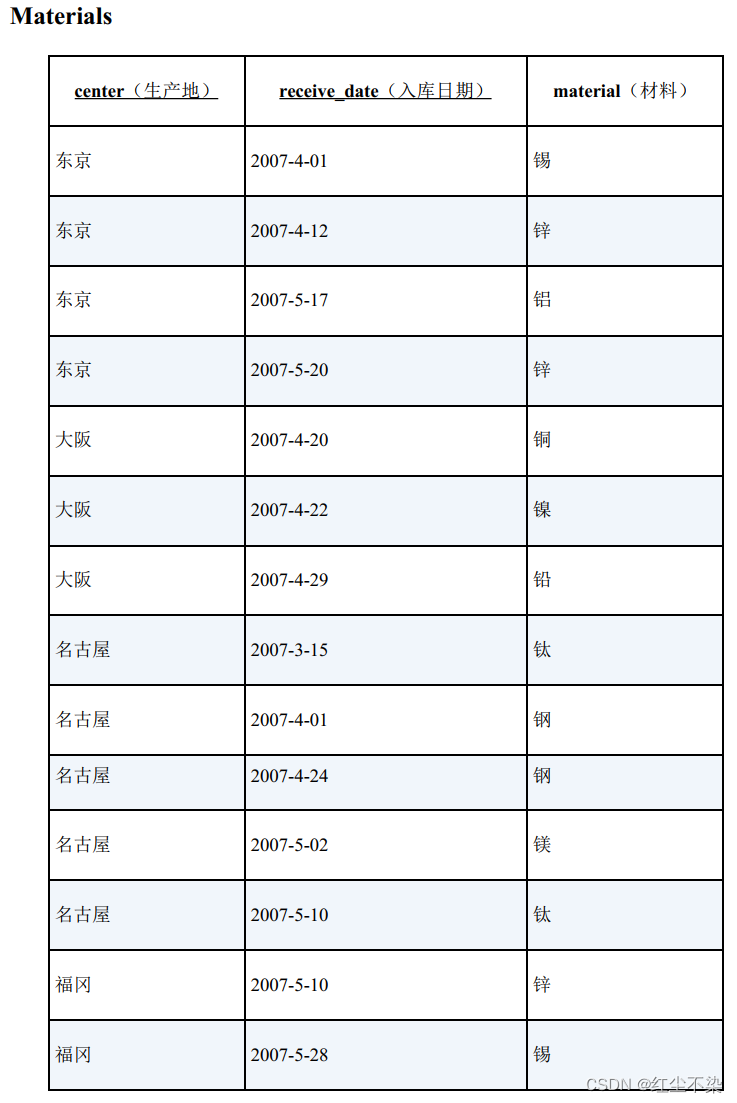
调查出存在重复材料的生产地。
一个生产地对应着多条数据, 因此“生产地”这一实体在表中是以集合的形式, 而不是以元素的形式存在的。 处理这种情况的基本方法就是使用 GROUP BY 子句将集合划分为若干个子集, 像下面这样。
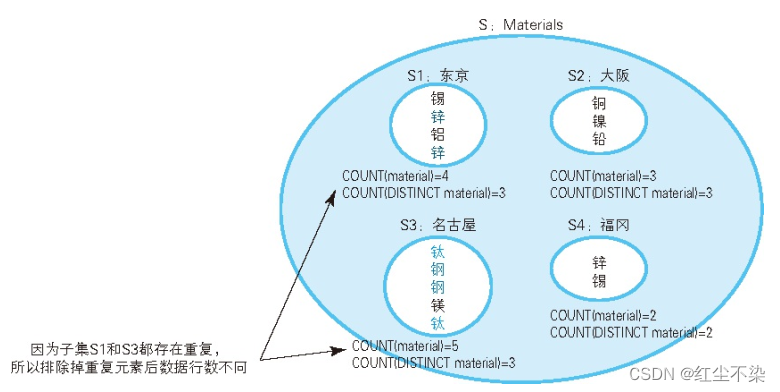
目标集合是锌重复的东京,以及钛和钢重复的名古屋。
集合的特征是排除掉重复元素后和排除掉重复元素前元素个数不相同。
-- 选中材料存在重复的生产地
SELECT center
FROM Materials
GROUP BY center
HAVING COUNT(material) <> COUNT(DISTINCT material);
通过在 WHERE 子句中加上具体的材料作为参数, 可以查出某种材料存在重复的生产地。
select m.center from materials m
where m.material = '铜'
group by m.center
having count(*) <> count(distinct m.material)
可以把条件移到SELECT 子句中, 这样就能在结果中清晰地看到各个生产地是否存在重复材料了。
SELECT center, CASE WHEN COUNT(material) <> COUNT(DISTINCT material) THEN '存在重复'
ELSE '不存在重复' END AS status
FROM Materials
GROUP BY center;
在数学中,通过 GROUP BY 生成的子集有一个对应的名字, 叫作划分(partition)。 它是集合论和群论中的重要概念,指的是将某个集合按照某种规则进行分割后得到的子集。 这些子集相互之间没有重复的元素, 而且它们的并集就是原来的集合。 这样的分割操作被称为划分操作。 SQL 中的GROUP BY,其实就是针对集合的划分操作的具体实现
-- 存在重复的集合: 使用EXISTS
SELECT center, material
FROM Materials M1
WHERE EXISTS (
SELECT * FROM Materials M2
WHERE M1.center = M2.center AND M1.receive_date <> M2.receive_date
AND M1.material = M2.material
);
用 EXISTS 改写后的 SQL 语句也能够查出重复的具体是哪一种材料,而且使用 EXISTS 后性能也很好。 相反地,如果想要查出不存在重复材料的生产地有哪些, 只需要把 EXISTS 改写为 NOT EXISTS 就可以了。
寻找缺失的编号: 升级版
判断该数列是否连续的 SQL语句。(不论数列的起始值是多少。)
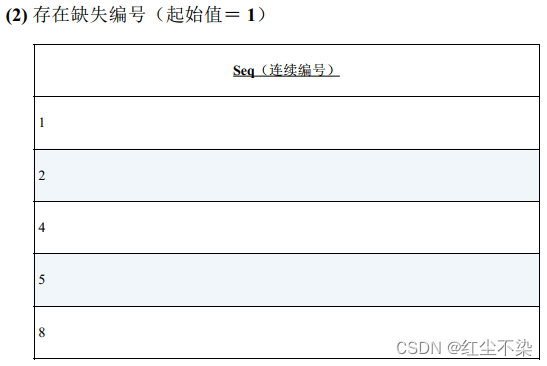
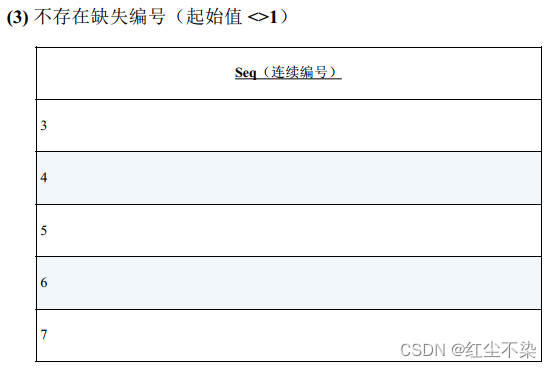
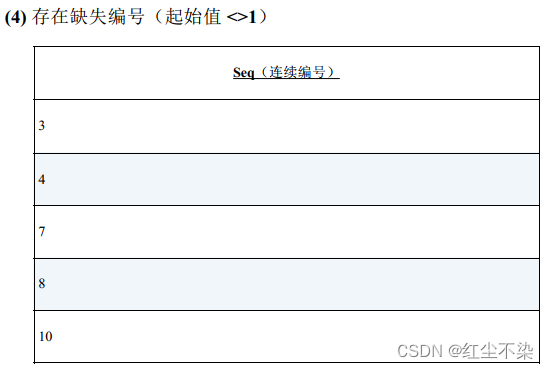
解决这个问题的基本思路和之前是一样的, 即将表整体看作一个集合,使用 COUNT(*) 来获得其中的元素个数。 如果数列的最小值和最大值之间没有缺失的编号,它们之间包含的元素的个数应该是最大值-最小值+ 1。
-- 如果有查询结果,说明存在缺失的编号:只调查数列的连续性
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq) - MIN(seq) + 1 ;
如果不论是否存在缺失的编号,都想要返回结果,那么只需要像下面这样把条件写到SELECT 里就可以了。
-- 不论是否存在缺失的编号都返回一行结果
SELECT CASE WHEN COUNT(*) = 0 THEN '表为空'
WHEN COUNT(*) <> MAX(seq) - MIN(seq) + 1 THEN '存在缺失的编号'
ELSE '连续' END AS gap
FROM SeqTbl;
查找最小的缺失编号的 SQL 语句
-- 查找最小的缺失编号: 表中没有1 时返回1
SELECT CASE WHEN COUNT(*) = 0 OR MIN(seq) > 1 THEN 1
ELSE (
SELECT MIN(seq +1) FROM SeqTbl S1
WHERE NOT EXISTS (
SELECT * FROM SeqTbl S2
WHERE S2.seq = S1.seq + 1
)
) END
FROM SeqTbl;
简单版的 SQL 语句以标量子查询的方式整体地嵌入到了CASE 表达式的返回结果块里。 考虑到表可能为空, 所以这里加上了COUNT(*) = 0 这个条件。 而且相比简单版,NOT IN 也改写成了 NOT EXISTS ,这样写是为了处理值为 NULL 的情况, 以及略微优化一下性能。
为集合设置详细的条件
最后,再练习一些使用 CASE 表达式来描述特征函数的方法。 熟练掌握这些方法之后,不管多么复杂的条件都能轻松地表达出来。
记录了学生考试成绩的表
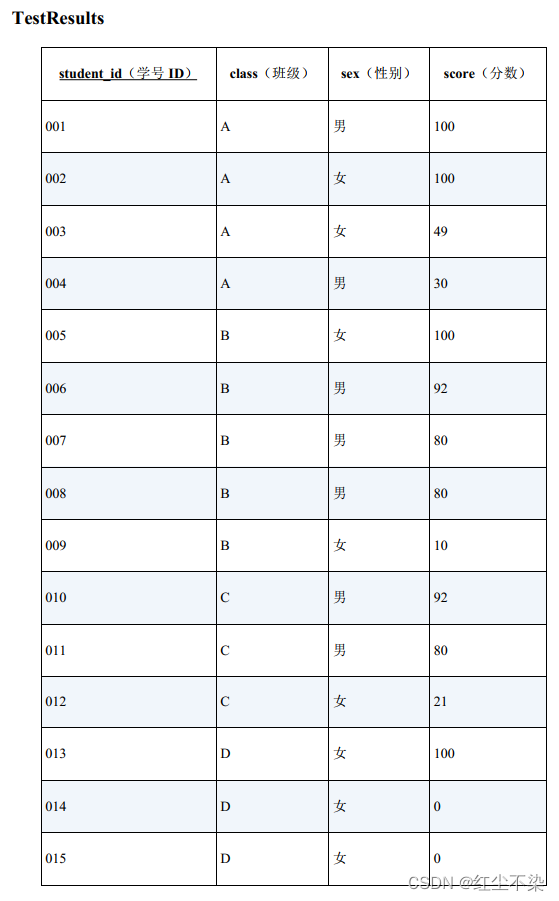
第 1 题: 请查询出 75% 以上的学生分数都在 80 分以上的班级。
SELECT class FROM TestResults
GROUP BY class
HAVING COUNT(*) * 0.75 <= SUM(CASE WHEN score >= 80 THEN 1 ELSE 0 END);
第 2 题: 请查询出分数在 50 分以上的男生的人数比分数在 50 分以上的女生的人数多的班级。
SELECT class FROM TestResults
GROUP BY class
HAVING SUM(CASE WHEN score >= 50 AND sex = '男' THEN 1 ELSE 0 END)
> SUM(CASE WHEN score >= 50 AND sex = '女' THEN 1 ELSE 0 END) ;
第 3 题: 请查询出女生平均分比男生平均分高的班级。
-- 比较男生和女生平均分的SQL 语句(1): 对空集使用AVG 后返回0
SELECT class FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = '男' THEN score ELSE 0 END)
< AVG(CASE WHEN sex = '女' THEN score ELSE 0 END) ;
-- 执行结果
class
-------
A
D
从表中的数据我们可以发现, D 班全是女生。 在上面的解答中, 用于判断男生的 CASE 表达式里分支 ELSE 0 生效了, 于是男生的平均分就成了 0 分。 对于女生的平均分约为 33.3 的 D 班, 条件 0 < 33.3也成立, 所以 D 班也出现在查询结果里了。
如果学号 013 的学生分数刚好也是 0 分, 女生的平均分会变为 0 分,D 班不会被查询出来。男生和女生的平均分都是 0, 但是两个 0 的意义完全不同。 女生的平均分是正常计算出来的, 而男生的平均分本来就无法计算, 只是强行赋值为 0 而已。
真正合理的处理方法是, 保证对空集求平均的结果是“未定义”, 就像除以 0 的结果是未定义一样。
-- 比较男生和女生平均分的SQL 语句(2): 对空集求平均值后返回NULL
SELECT class FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = '男' THEN score ELSE NULL END)
< AVG(CASE WHEN sex = '女' THEN score ELSE NULL END) ;
这回 D 班男生的平均分是 NULL 。 因此不管女生的平均分多少, D 班都会被排除在查询结果之外。这种处理方法和 AVG 函数的处理逻辑也是一致的。
关注集合的性质, 反过来说其实就是忽略掉单个元素的特征。
关注集合的性质, 反过来说其实就是忽略掉单个元素的特征。
本节小结
用一句话概括使用 HAVING 子句时的要点, 就是要搞清楚将什么东西抽象成集合。在 SQL 中一件东西能否抽象成集合, 和它在现实世界中的实际意义无关, 只取决于它在表中的存在形式。
根据需要, 我们可以把实体抽象成集合, 也可以把它抽象成集合中的元素。
如果实体对应的是表中的一行数据, 那么该实体应该被看作集合中的元素, 因此指定查询条件时应该使用 WHERE 子句。
如果实体对应的是表中的多行数据, 那么该实体应该被看作集合, 因此指定查询条件时应该使用 HAVING 子句。
最后,整理一下在调查集合性质时经常用到的条件。 这些条件可以在 HAVING 子句中使用, 也可以通过 SELECT 子句写在 CASE 表达式里使用。
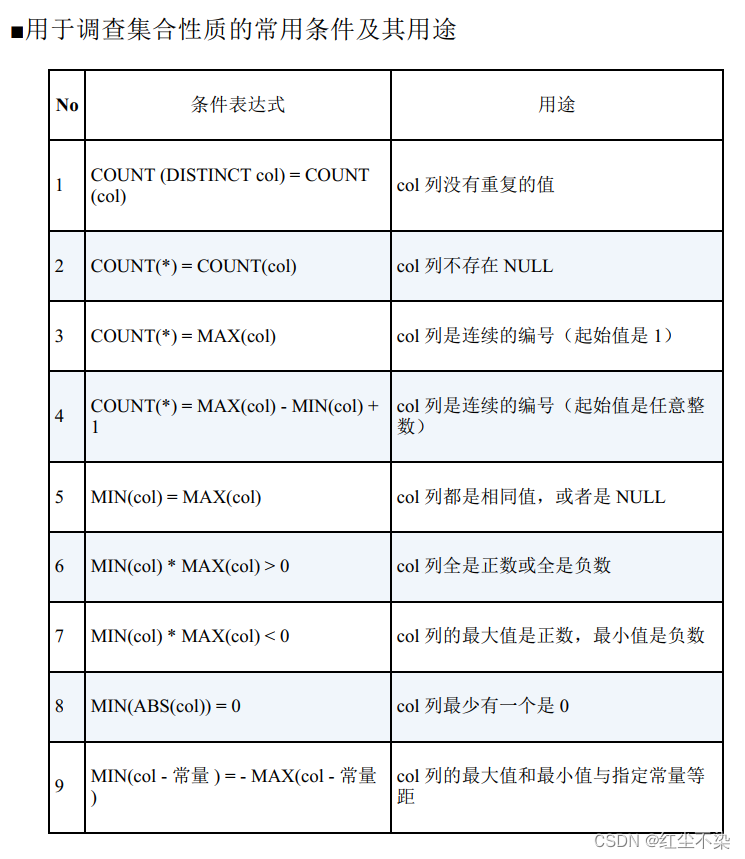
本节要点
- 在 SQL 中指定搜索条件时, 最重要的是搞清楚搜索的实体是集合还是集合的元素。
- 如果一个实体对应着一行数据→ 那么就是元素, 所以使用 WHERE 子句。
- 如果一个实体对应着多行数据→ 那么就是集合, 所以使用 HAVING 子句。
- HAVING 子句可以通过聚合函数(特别是极值函数) 针对集合指定各种条件。
- 如果通过 CASE 表达式生成特征函数, 那么无论多么复杂的条件都可以描述。
- HAVING 子句很强大。
1.11 让 SQL 飞起来
使用高效的查询
参数是子查询时,使用 EXISTS 代替 IN
IN 谓词非常方便, 而且代码也容易理解, 所以使用的频率很高。 但是方便的同时, IN 谓词却有成为性能优化的瓶颈的危险。 如果代码中大量用到了 IN 谓词, 那么一般只对它们进行优化就能大幅度地提升性能。
如果 IN 的参数是“1, 2, 3 ”这样的数值列表,一般还不需要特别注意。但是如果参数是子查询, 那么就需要注意了。
在大多时候, [NOT] IN 和 [NOT] EXISTS 返回的结果是相同的。 但是两者用于子查询时, EXISTS 的速度会更快一些。

从 Class_A 表中查出同时存在于 Class_B 表中的员工。
-- 慢
SELECT * FROM Class_A
WHERE id IN (SELECT id FROM Class_B);
-- 快
SELECT * FROM Class_A A
WHERE EXISTS (SELECT * FROM Class_B B WHERE A.id = B.id);
使用 EXISTS 时更快的原因有以下两个。
- 如果连接列(id ) 上建立了索引, 那么查询 Class_B 时不用查 实际的表, 只需查索引就可以了。
- 如果使用 EXISTS , 那么只要查到一行数据满足条件就会终止查询,不用像使用 IN 时一样扫描全表。 在这一点上 NOT EXISTS 也一样。
当 IN 的参数是子查询时,数据库首先会执行子查询,然后将结果存储在一张临时的工作表里,然后扫描整个视图。这种做法都非常耗费资源。 使用 EXISTS 的话,数据库不会生成临时的工作表。
从代码的可读性上来看, IN 要比 EXISTS 好。 使用 IN 时的代码看起来更加一目了然, 易于理解。 因此, 如果确信使用 IN 也能快速获取结果, 就没有必要非得改成 EXISTS 了。
参数是子查询时, 使用连接代替 IN
要想改善 IN 的性能, 除了使用 EXISTS , 还可以使用连接。
-- 使用连接代替IN
SELECT A.id, A.name
FROM Class_A A INNER JOIN Class_B B ON A.id = B.id;
这种写法至少能用到一张表的“id”列上的索引。 而且,因为没有子查询,所以数据库也不会生成中间表。很难说与 EXISTS 相比哪个更好,但是如果没有索引, 那么与连接相比,可能 EXISTS 会略胜
一筹。
避免排序
与面向过程语言不同,在 SQL 语言中,用户不能显式地命令数据库进行排序操作。对用户隐藏这样的操作正是 SQL 的设计思想。这样并不意味着在数据库内部也不能进行排序。其实正好相反,在数据库内部频繁地进行着暗中的排序。因此对于用户来说,了解都有哪些运算会进行排序很有必要。
(可以避免排序所带来的性能开销)
会进行排序的代表性的运算有下面这些。
- GROUP BY 子句
- ORDER BY 子句
- 聚合函数(SUM 、 COUNT 、 AVG 、 MAX 、 MIN )
- DISTINCT
- 集合运算符(UNION 、 INTERSECT 、 EXCEPT )
- 窗口函数(RANK 、 ROW_NUMBER 等)
尽量避免(或减少)无谓的排序可以优化sql 的性能。
灵活使用集合运算符的 ALL 可选项
SQL 中有 UNION 、 INTERSECT 、 EXCEPT 三个集合运算符。在默认的使用方式下, 这些运算符会为了排除掉重复数据而进行排序。
如果不在乎结果中是否有重复数据,或者事先知道不会有重复数据,请使用 UNION ALL 代替 UNION 。这样就不会进行排序了。
对于 INTERSECT 和 EXCEPT 也是一样的,
加上 ALL 可选项后就不会进行排序了。
加上 ALL 可选项是优化性能的一个非常有效的手段, 但问题是各种数据库对它的实现情况参差不齐。 下表中汇总了目前各种数据库的实现情况。
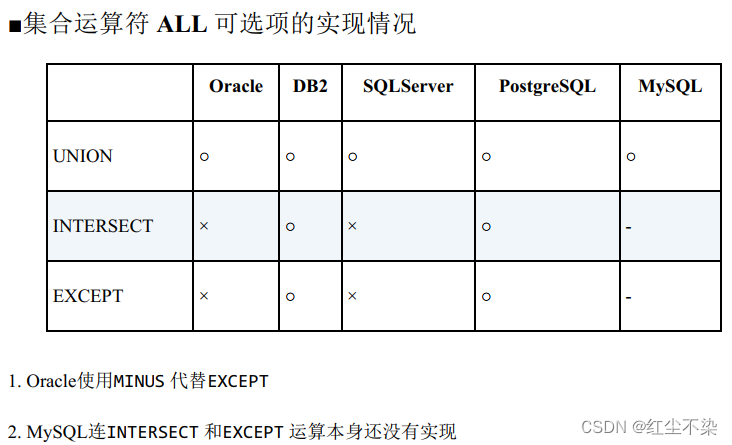
使用 EXISTS 代替 DISTINCT
为了排除重复数据, DISTINCT 也会进行排序。 如果需要对两张表的连接结果进行去重, 可以考虑使用 EXISTS 代替 DISTINCT , 以避免排序。
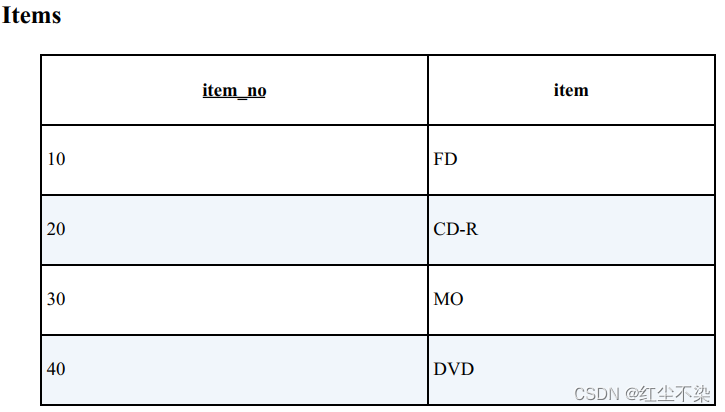
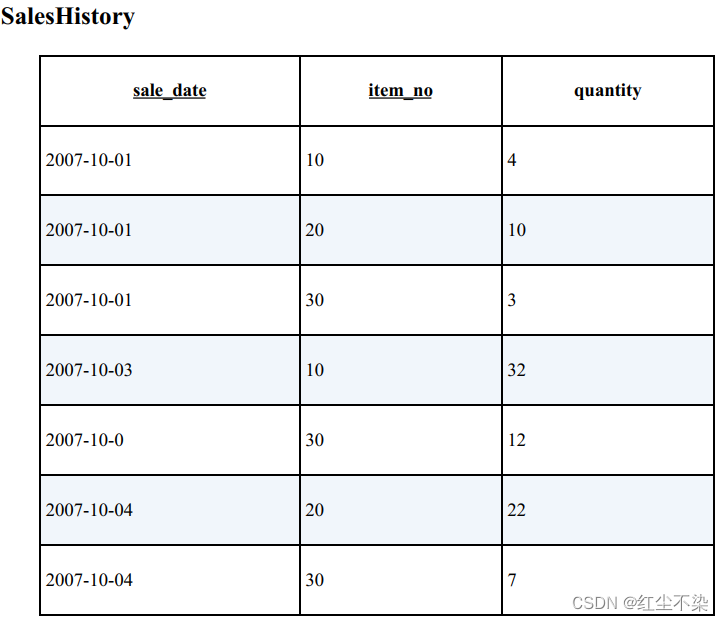
从商品表 Items 中找出同时存在于销售记录表 SalesHistory 中的商品。
-- 为了排除重复数据,需要使用 DISTINCT 。
SELECT DISTINCT I.item_no
FROM Items I INNER JOIN SalesHistory SH ON I.item_no = SH.item_no;
-- 使用 exists
SELECT item_no
FROM Items I
WHERE EXISTS (SELECT * FROM SalesHistory SH WHERE I.item_no = SH.item_no);
这条语句在执行过程中不会进行排序。 而且使用 EXISTS 和使用连接一样高效。
在极值函数中使用索引(MAX/MIN)
SQL 语言里有 MAX 和 MIN 两个极值函数。
使用这两个函数时都会进行排序。但是如果参数字段上建有索引,则只需要扫描索引,不需要扫描整张表。
-- 这样写需要扫描全表
SELECT MAX(item) FROM Items;
-- 这样写能用到索引
SELECT MAX(item_no) FROM Items;
因为 item_no 是表 Items 的唯一索引, 所以效果更好。 对于联合索引, 只要查询条件是联合索引的第一个字段, 索引就是有效的, 所以也可以对表 SalesHistory 的 sale_date 字段使用极值函数。
这种方法并不是去掉排序这一过程,而是优化了排序前的查找速度,减弱排序对整体性能的影响。
能写在 WHERE 子句里的条件不要写在 HAVING 子句里
下面的两条sql语句作用是一样的。
-- 聚合后使用HAVING 子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING sale_date = '2007-10-01';
-- 聚合前使用 WHERE 子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory
WHERE sale_date = '2007-10-01'
GROUP BY sale_date;
从性能上来看, 第二条语句写法效率更高。 原因通常有两个。
- 第一个是在使用 GROUP BY 子句聚合时会进行排序, 如果事先通过 WHERE 子句筛选出一部分行, 就能够减轻排序的负担。
- 第二个是在 WHERE 子句的条件里可以使用索引。 HAVING 子句是针对聚合后生成的视图进行筛选的, 但是很多时候聚合后的视图都没有继承原表的索引结构 。
在 GROUP BY 子句和 ORDER BY 子句中使用索引
一般来说, GROUP BY 子句和 ORDER BY 子句都会进行排序, 来对行进行排列和替换。
通过指定带索引的列作为 GROUP BY 和ORDER BY 的列, 可以实现高速查询。
特别是, 在一些数据库中, 如果操作对象的列上建立的是唯一索引, 那么排序过程本身都会被省略掉。
真的用到索引了吗
一般情况下,都会对数据量相对较大的表建立索引。 简单理解起来,索引的工作原理与 C 语言中指针数组是一样的。即相比查找复杂对象的数组,查找轻量的指针会更高效。而且最流行的 B 树索引还进行了一些优化, 以使用二分查找来提升查询的速度。
在索引字段上进行运算
假设在一个叫作 col_1 的列上建立了索引,然后来看一看下面这条 SQL 语句。
-- 在索引字段上进行运算
SELECT * FROM SomeTable
WHERE col_1 * 1.1 > 100;
这条 SQL 语句本来是想使用索引, 但实际上执行时却进行了全表扫描。
把运算的表达式放到查询条件的右侧, 就能用到索引了, 像下面这样 写就 OK 了。
SELECT * FROM SomeTable
WHERE col_1 > 100 / 1.1;
同样,在查询条件的左侧使用函数时,也不能用到索引。
SELECT * FROM SomeTable
WHERE SUBSTR(col_1, 1, 1) = 'a';
使用索引时, 条件表达式的左侧应该是原始字段。请牢记, 这一点是在优化索引时首要关注的地方。
使用 IS NULL 谓词
通常,索引字段是不存在 NULL 的,所以指定 IS NULL 和 IS NOT NULL 的话会使得索引无法使用,进而导致查询性能低下。
SELECT * FROM SomeTable
WHERE col_1 IS NULL;
关于索引字段不存在 NULL 的原因, 简单来说是 NULL 并不是值。 非值不会被包含在值的集合中。
如果需要使用类似 IS NOT NULL 的功能, 又想用到索引, 那么可以使用下面的方法, 假设“col_1”列的最小值是 1 。
-- IS NOT NULL 的代替方案
SELECT * FROM SomeTable
WHERE col_1 > 0;
原理很简单,只要使用不等号并指定一个比最小值还小的数, 就可以选出 col_1 中所有的值。
使用否定形式
下面这几种否定形式不能用到索引。
- <>
- !=
- NOT IN
因此, 下面的 SQL 语句也会进行全表扫描。
SELECT * FROM SomeTable
WHERE col_1 <> 100;
使用 OR
在 col_1 和 col_2 上分别建立了不同的索引, 或者建立了(col_1,col_2 ) 这样的联合索引时, 如果使用 OR 连接条件, 那么要么用不到索引, 要么用到了但是效率比 AND 要差很多。
SELECT * FROM SomeTable
WHERE col_1 > 100 OR col_2 = 'abc';
使用联合索引时, 列的顺序错误
假设存在这样顺序的一个联合索引“col_1, col_2, col_3 ”。这时,指定条件的顺序就很重要。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500;
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 ;
× SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500 ;
× SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500 ;
× SELECT * FROM SomeTable WHERE col_2 = 100 AND col_1 = 10 ;
联合索引中的第一列(col_1 )必须写在查询条件的开头,而且索引中列的顺序不能颠倒。
有些数据库里顺序颠倒后也能使用索引, 但是性能还是比顺序正确时差一些。如果无法保证查询条件里列的顺序与索引一致, 可以考虑将联合索引拆分为多个索引。
使用 LIKE 谓词进行后方一致或中间一致的匹配
使用 LIKE 谓词时,只有前方一致的匹配才能用到索引。
○ SELECT * FROM SomeTable WHERE col_1 LIKE 'a%';
× SELECT * FROM SomeTable WHERE col_1 LIKE '%a';
× SELECT * FROM SomeTable WHERE col_1 LIKE '%a%';
进行默认的类型转换
对 char 类型的“col_1”列指定条件的示例
× SELECT * FROM SomeTable WHERE col_1 = 10;
○ SELECT * FROM SomeTable WHERE col_1 = '10';
○ SELECT * FROM SomeTable WHERE col_1 = CAST(10, AS CHAR(2));
默认的类型转换不仅会增加额外的性能开销, 还会导致索引不可用,可以说是有百害而无一利。
在需要类型转换时显式地进行类型转换(转换要写在条件表达式的右边)。
减少中间表
在 SQL 中,子查询的结果会被看成一张新表,这张新表与原始表一样,可以通过代码进行操作。这种高度的相似性使得 SQL 编程具有非常强的灵活性,但是如果不加限制地大量使用中间表,会导致查询
性能下降。
频繁使用中间表会带来两个问题,一是展开数据需要耗费内存资源,二是原始表中的索引不容易使用到。因此,尽量减少中间表的使用也是提升性能的一个重要方法。
灵活使用 HAVING 子句
对聚合结果指定筛选条件时,使用 HAVING 子句是基本原则。
先生成中间表,在where子句中写过滤条件。
SELECT * FROM (SELECT sale_date, MAX(quantity) AS max_qty
FROM SalesHistory
GROUP BY sale_date) TMP ←----- 没用的中间表
WHERE max_qty >= 10;
对聚合结果指定筛选条件时不需要专门生成中间表, 像下面这样使用 HAVING 子句就可以。
SELECT sale_date, MAX(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;
HAVING 子句和聚合操作是同时执行的, 所以比起生成中间表后再执行的 WHERE 子句, 效率会更高一些, 而且代码看起来也更简洁。
需要对多个字段使用 IN 谓词时, 将它们汇总到一处
SQL-92 中加入了行与行比较的功能。比较谓词 = 、 < 、 > 和 IN 谓词的参数就不能是标量值, 而应是值列表了。
SELECT id, state, city
FROM Addresses1 A1
WHERE state IN (SELECT state FROM Addresses2 A2 WHERE A1.id = A2.id)
AND city IN (SELECT city FROM Addresses2 A2 WHERE A1.id = A2.id);
这段代码中用到了两个子查询。
SELECT * FROM Addresses1 A1
WHERE id || state || city IN (SELECT id || state|| city FROM Addresses2 A2);
把字段连接在一起, 那么就能把逻辑写在一处了。这样一来, 子查询不用考虑关联性, 而且只执行一次就可以。
SELECT * FROM Addresses1 A1
WHERE (id, state, city) IN (SELECT id, state, city FROM Addresses2 A2);
这种方法与前面的连接字段的方法相比有两个优点。 一是不用担心连接字段时出现的类型转换问题, 二是这种方法不会对字段进行加工,因此可以使用索引。
先进行连接再进行聚合
连接和聚合同时使用时, 先进行连接操作可以避免产生中间表。 原因是,从集合运算的角度来看,连接做的是“乘法运算”。连接表双方是一对一、 一对多的关系时,连接运算后数据的行数不会增加。
合理地使用视图
视图的定义语句中包含以下运算的时候, SQL 会非常低效, 执行速度也会变得非常慢。
- 聚合函数(AVG 、 COUNT 、 SUM 、 MIN 、 MAX )
- 集合运算符(UNION 、 *NTERSECT 、 EXCEPT 等)
本节小结
本节重点介绍了 SQL 性能优化方面的一些注意事项。 虽然这里列举了几个要点, 但其实
优化的核心思想只有一个, 那就是找出性能瓶颈所在, 重点解决它。
其实不只是数据库和 SQL, 计算机世界里容易成为性能瓶颈的也是对硬盘, 也就是文件系统的访问。
不管是减少排序还是使用索引, 抑或是避免中间表的使用, 都是为了减少对硬盘的访问。 请务必理解这一本质。
本节要点
- 参数是子查询时, 使用 EXISTS 或者连接代替 IN 。
- 使用索引时, 条件表达式的左侧应该是原始字段。
- 在 SQL 中排序无法显式地指定, 但是请注意很多运算都会暗中进行排序。
- 尽量减少没用的中间表
1.12 SQL 编程方法
代码要清晰, 不要为了“效率”牺牲可读性。
表的设计
名字和意义。
对于列、表、索引,以及约束,命名时都请做到名副其实。绝对不要使用 A、AA,或者 idx_123 这样无意义的符号。特别需要注意的是,如果没有为索引和约束显式地指定名称,DBMS 就会自动为之分配随机的名称, 这也是应该避免的。
命名时允许的字符有以下 3 种。
- 英文字母
- 阿拉伯数字
- 下划线“_”
- 标准 SQL 中规定名称的第一个字符应该是英文字母
一个列包含多个意义的表的设计。例如,对于存储了“年份不同格式就不同的报表”这类值的表, 格式切换的时间点不同,某一列中存储的值的意义就会发生变化。
在数据库中,列代表的是“属性”,因此应该具有一贯性。
编程的方针
注释是编程风格中一个比较有争议的话题。 有些人极力主张必须要添加注释, 相反也有人认为注释只会使代码的可读性降低, 因此努力方向应该是
把代码写得不需要注释也能看懂。
就 SQL 而论, 最好还是写注释。这样说主要有两个原因: 一个是,SQL 是声明式语言,即使表达同样的处理过程,逻辑仍然比面向过程语言凝练得多;另一个是,SQL 很难进行分步的执行调试。
注释的写法有以下两种。
-- 单行注释
-- 从SomeTable 中查询col_1
SELECT col_1 FROM SomeTable;
/*
多行注释
从SomeTable 中查询col_1
*/
SELECT col_1 FROM SomeTable;
此外,SQL 语句中不能有空行,却可以像下面这样加入注释。
SELECT col_1 FROM SomeTable;
WHERE col_1 = 'a' AND col_2 = 'b'
-- 下面的条件用于指定col_3 的值是'c'或者'd'
AND col_3 IN ( 'c', 'd' );
需要把揉在一起难以阅读的条件分割成有意义的代码块时, 比如必须往 WHERE 子句中写很多条件的时候, 这种写法很方便。 注释也可以与代码在同一行。
SELECT col_1 -- 从SomeTable 中查询col_1
FROM SomeTable;
缩进
代码难以阅读的原因里, 也许排在第一位的是没有进行缩进(排在第二位的是没有对长代码划分模块, 所有的都揉在一起) 。
-- √好的示例
SELECT col_1,
col_2,
col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1,
col_2,
col_3
--× 坏的示例
SELECT col_1, col_2, col_3, COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = (
SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
) GROUP BY col_1, col_2, col_3
从上面“好的示例”中可以看到,**子查询的代码缩进了一层。**请牢记这个规则。子查询这个名称的开头是“子”,这就说明它是低一层的逻辑。在 SELECT 子句和 GROUP BY 子句中指定多列时,也需要缩进一层。缩进之后,“子句”的代码块就变得很清晰,更方便阅读。
在上面“坏的示例”中, GROUP BY 子句之前没有进行换行, 这种写法也不太好。
SQL 中 SELECT、 FROM 等语句都有着明确的作用, 请务必以这样的单位进行换行。
-- ①所有关键字左对齐
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
-- ②所有关键字右对齐
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
笔者认为, 比起①这种所有关键字都顶格左齐的写法, ②这种让关键字右齐的写法更好。原因是紧接着的列名或表名的位置也能对齐, 代码更易读。
空格
不管用什么语言编程都一样, 代码中需要适当地留一些空格。 如果一点都不留, 所有的代码都紧凑到一起, 代码的逻辑单元就会不明确,也会给阅读的人带来额外负担。
-- √好的示例
SELECT col_1
FROM tbl_A A, tbl_B B
WHERE ( A.col_1 >= 100 OR A.col_2 IN ( 'a', 'b' ) )
AND A.col_3 = B.col_3;
--× 坏的示例
SELECT col_1
FROM tbl_A A,tbl_B B
WHERE (A.col_1>=100 OR A.col_2 IN ('a','b'))
AND A.col_3=B.col_3;
大小写
英文中需要强调某句重要的话时, 一般会使用斜体或者大写字母。
因此在编程中,也有重要的语句使用大写字母,不重要的语句使用小写字母的习惯。
在 SQL 里,关于应该如何区分使用大小写字母有着不成文的约定:
关键字使用大写字母, 列名和表名使用小写字母。
-- √大小写有区分, 易读
SELECT col_1, col_2, col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1, col_2, col_3;
--× 大小写没有区分, 难读: 全是小写
select col_1, col_2, col_3,
count(*)
from tbl_a
where col_1 = 'a'
and col_2 = ( select max(col_2)
from tbl_b
where col_3 = 100 )
group by col_1, col_2, col_3;
逗号
在 SQL 中, 分割列或表等要素时需要使用逗号。 很多人都习惯把逗号写在要素的后面。 例如写“col_1, col_2, col_3 ”时, 先写 col_1 ,再在后面写逗号,然后写 col_2 ,再在后面写逗号……但是如果按照这种规则, 就不能解释为什么 col_3 的后面没有写逗号。 同时,也并不是说逗号得统一写在要素的前面, 因为这样就不能解释为什么 col_1 的前面没有写逗号了。 正确的写法是把逗号写在要素和要素的中间。
SELECT col_1
, col_2
, col_3
, col_4
FROM tbl_A;
这种“前置逗号”的写法有两个好处。 第一个是删掉最后一列“col_4”后执行也不会出错。
第二个好处是,每行中逗号都出现在同一列,因此使用 Emacs 等可以进行矩形区域选择的编辑器就会非常方便操作。如果将逗号写在列后面,那么逗号的列位置就会因列的长度不同而参差不齐。
除了这些好处, 这种写法也有一个缺点, 那就是可读性稍微差些。
不使用通配符
使用通配符 (*) 指定所有列后,表的全部列都会被选中。虽然这种写法很方便,但最好还是不要这样做。使用通配符后查出的结果中会包含理论上来说并不需要的列,不仅会降低代码的可读性,也不利于需求变更。
× SELECT * FROM SomeTable;
√ SELECT col_1, col2, col3 ... FROM SomeTable;
ORDER BY 中不使用列编号
在 ORDER BY 子句中,我们可以使用列的编号代替实际的列名,作为排序的列来使用。在动态生成SQL 等情况下, 这是很有用的功能,但是这样的代码可读性很不好。
而且这个功能在 SQL-92 中已经被列 为了“未来会被删除的功能”。 因此来讲, 最好不要使用它。
× SELECT col_1, col2 FROM SomeTable ORDER BY 1, 2;
√ SELECT col_1, col2 FROM SomeTable ORDER BY col_1, col2;
SQL 编程方法
SQL 是一种有多种方言的语言, 各种数据库实现都为我们做了各种扩展(不管是好的还是坏的) 。 SQL 官方其实已经制定了标准语法。近年标准 SQL 越来越完善, 也越来越实用了。所以尽可能使用标准语法。
在日常开发中养成使用标准语法的习惯吧。下面列出了几个需要注意的地方。
不使用依赖各种数据库实现的函数和运算符
很多依赖数据库实现的函数都是转换函数或字符串处理函数。不要使用这些函数:DECODE (Oracle)、IF (MySQL)、 NVL(Oracle)、 STUFF (SQL Server) 等。请使用 CASE 表达式或者
COALESCE 、 NULLIF 等标准函数代替它们。
连接操作使用标准语法
在 SQL 的语法中,依赖数据库实现最严重的是连接语句。在很早的时候,连接条件和普通的查询条件一样,都是写在 WHERE 子句里的。
SELECT *
FROM Foo F, Bar B
WHERE F.state = B.state
AND F.city = '东京';
标准 SQL 使用 INNER 或 CROSS 等表明连接类型的关键字, 连接条件可以使用 ON 子句分开写。
-- 内连接, 而且一眼就能看明白连接条件是F.state = B.state
SELECT *
FROM Foo F INNER JOIN Bar B
ON F.state = B.state
WHERE F.city = '东京';
这样写的话, 一眼就能看明白连接的类型和条件, 代码可读性很好。
外连接请使用 LEFT OUTER JOIN 、 RIGHT OUTER JOIN 或者 FULL OUTER JOIN 来写。 使用 (+) 运算符 (Oracle)、 *= 运算符 (SQL Server) 等依赖数据库实现的写法会降低代码的可移植性, 而且表达能力也有限, 所以尽量避免。
标准 SQL 中允许省略关键字 OUTER , 但是这个关键字便于我们理解它是外连接而非内连接, 所以还是写上吧。
外连接有左连接、 右连接和全连接三种类型。 其中, 左连接和右连接的表达能力是一样的, 理论上讲使用哪个都可以。
但是笔者认为,在代码风格方面,左连接有一个优势:一般情况下表头都出现在左边。使用左边的表作为主表的话,SQL 就能和执行结果在格式上保持一致。这样一来,在看到 SQL 语句时,我们很容易就能想象出执行结果的格式。
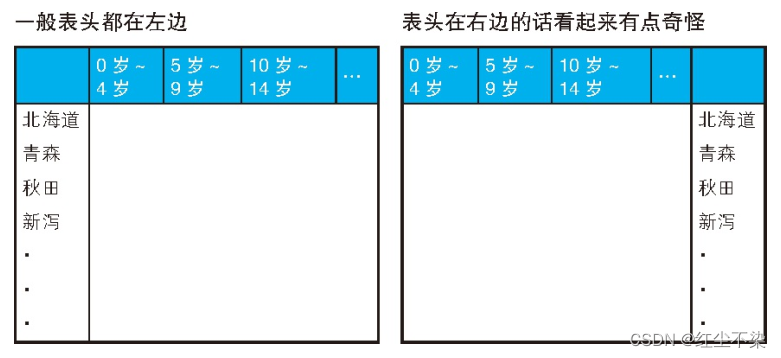
从 FROM 子句开始写
SQL 中各部分的执行顺序是:FROM → WHERE → GROUP BY →HAVING → SELECT( → ORDER BY) 。严格地说,ORDER BY 并不是SQL 语句的一部分, 因此可以排除在外。 SELECT 是最后才被执行的部分了。
SELECT 子句的主要作用是完成列的格式转换和计算,并没有做很多工作,用做菜来类比的话就像是最后添加调料的环节。因为它总是出现在最开始的位置,所以很容易引起人们的注意,但是在考虑具体逻辑的时候,我们完全可以先忽略它。相对而言,WHERE 、GROUP BY 和 HAVING 等起到的作用更重要一些。
因此,如果需要写很复杂的 SQL 语句,可以考虑按照执行顺序从 FROM 子句开始写,这样添加逻辑时更加自然。
如果把从 SELECT 子句开始写的方法称为自顶向下法,那么从 FROM子句开始写的方法就可以称为自底向上法。
本节小结
其实本节内容与前面各节相互矛盾。 前面各节介绍的很多技巧都为了追求效率而牺牲了可读性。 但是到了本节,就反过来说不能为了效率而牺牲可读性,这难道不是相互矛盾的吗? 其实, 可读性和效
率并非水火不容的关系, 有些时候鱼和熊掌是可以兼得的。 但是, 大部分情况下, 我们还是很难兼顾两者。
如果要问笔者倾向于哪一边,不用说,肯定是本节强调的可读性。原因很简单,如果硬件和数据库本身的性能提升了,即使我们不对SQL 做什么优化,性能也能得到提升。相反,代码难读的问题没有谁能帮我们解决,能保证代码可读性的只有开发者自己。 因此当需要从两者中做出选择时,笔者会毫不犹豫地选择可读性。