一、Oozie:大数据调度工具
1.1、官方介绍
1、Oozie是一个管理 Apache Hadoop 作业的工作流调度系统。
2、Oozie的 workflow jobs 是由 actions 组成的 有向无环图(DAG)。
3、Oozie的 coordinator jobs 是由时间 (频率)和数据可用性触发的重复的 workflow jobs
。
4、Oozie与Hadoop生态圈的其他部分集成在一起,支持多种类型的Hadoop作业(如Java mapreduce、流式map-reduce、Pig、Hive、Sqoop和Distcp)以及特定于系统的工作(如Java程序
和shell脚本)。
5、Oozie是一个可伸缩、可靠和可扩展的系统。

在没有工作流调度系统之前,公司里面的任务都是通过
crontab
来定义的,时间长了后会 发现很多问题:
1、大量的crontab任务需要管理
2、任务没有按时执行,各种原因失败,需要重试
3、多服务器环境下,crontab分散在很多集群上,光是查看log就很花时间
于是,出现了一些管理crontab任务的调度系统,如
CronHub
、
CronWeb
等。而在
大数据领 域
,现在市面上常用的工作流调度工具有
Oozie
、
Azkaban
、
Cascading
、
Hamake
等。
Oozie和Azkaban来做对比:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过
org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上
可能Oozie会比较好。
工作流定义: Oozie是通过xml定义的而Azkaban为properties来定义。
部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是
BUG,但是Oozie能有效的检测任务的成功与失败。
操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
运行环境: Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器
中。
记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在
Mysql中。
出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行由于公司安装CDH集群时已经安装好Oozie,且有对应的可视化操作工具Hue,所以直接选 择Oozie进行工作流调度啦!
1.2、Oozie 核心概念
Oozie主要有三个主要概念,分别是
workflow
,
coordinator
,
bundle
。
1、Workflow:工作流,由我们需要处理的每个工作组成,进行需求的流式处理。
2、Coordinator:协调器,可以理解为工作流的协调器,可以将多个工作流协调成一个工作流来进行
处理。
3、Bundle:捆,束。将一堆的coordinator进行汇总处理。
简单来说,workflow是对要进行的顺序化工作的抽象,coordinator是对要进行的顺序化的
workflow的抽象,bundle是对一堆coordiantor的抽象。层级关系层层包裹。
Oozie本质是通过
launcher job
运行某个具体的Action。
launcher job
是一个
map-only
的 MR作业,而且并不知道它将在集群的哪台机器上执行这个MR作业。

1.3、Job 组成
一个oozie 的 job(Workflow) 一般由以下文件组成:
1、job.properties :记录了job的属性
2、workflow.xml :使用hPDL 定义任务的流程和分支
3、lib目录:用来执行具体的任务
1.3.1、job.properties

1、这个文件如果是在本地通过命令行进行任务提交的话,这个文件在本地就可以了,当
然也可以放在hdfs上,与workflow.xml和lib处于同一层级。
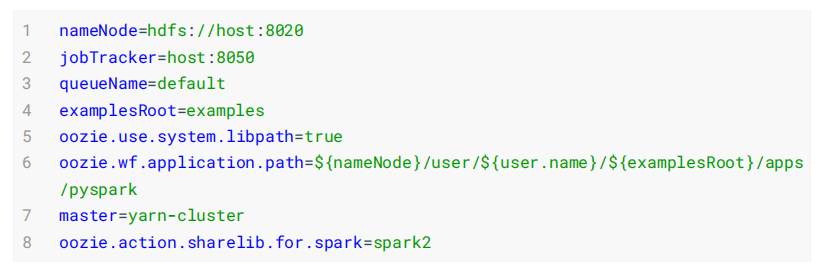
2、nameNode,jobTracker和 workflow.xml在hdfs中的位置必须设置。例如,Shell节点的job.properties文件示例如下:
nameNode=hdfs://cm1:8020
jobTracker=cm1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/workflow/oozie/shell
1.3.2、workflow.xml
这个文件是定义任务的整体流程的文件,官网wordcount例子如下:



可以看到:
文件需要被放在HDFS上才能被oozie调度,如果在启动需要调动MR任务,jar包同样需要在hdfs上
1.3.3、lib目录
在
workflow
工作流定义的同级目录下,需要有一个lib目录,在lib目录中存在MapReduce使用的jar包。
需要注意的是,Oozie并不是使用指定jar包的名称来启动任务的,而是通过制定主类来启动任务的。在lib包中绝对不能存在某个jar包的不同版本,不能够出现多个相同主类。
1.4、工作流:Workflow
workflow
是一组
actions
集合(例如Hadoop map/reduce作业,pig作业),它被安排在一 个控制依赖项DAG(Direct Acyclic Graph)中。 “控制依赖”从一个action到另一个action意味着第二个action不能运行,直到第一个action完成。

1、Oozie Workflow 定义是用 hPDL 编写的(类似于JBOSS JBPM jPDL的XML过程定义语言)。
2、Oozie Workflow actions 在远程系统(如Hadoop、Pig)中启动工作。在action完成时,远
程系统 回调 Oozie通知action完成,此时Oozie将继续在workflow 中进行下一步操作。
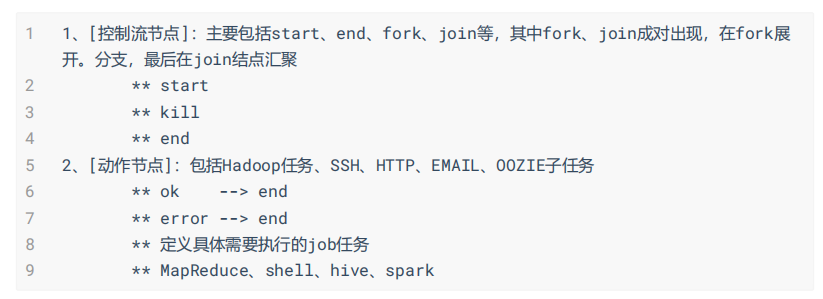
3、Oozie Workflow 包含控制流节点(control flow nodes)和动作节点(action nodes).
4、控制流节点定义workflow的开始和结束(start、end 和 fail 节点),并提供一种机制来控制
workflow执行路径(decision、fork和join节点)。
5、action 节点是workflow触发计算/处理任务执行的机制。Oozie为不同类型的操作提供了支持:
Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、电子邮件和Oozie子工作流。Oozie
可以扩展来支持其他类型的操作。Oozie Workflow 可以被参数化(在工作流定义中使用诸如$inputDir之类的变量)。在提交workflow作业值时,必须提供参数。如果适当地参数化(即使用不同的输出目录),几个相同的workflow作业可以并发。
1.5、定时器:Coordinator
通常,
workflow
作业是基于常规的
时间间隔
(time intervals)和
数据可用性
(data availability)运行的。在某些情况下,它们可以由外部事件触发。

表示触发
workflow
作业的条件可以被建模为必须满足的谓词(predicate )。
workflow
作业是在谓词满足之后开始的。谓词可以引用数据、时间和/或外部事件。在将来,可以扩展模型来支持额外的事件类型。
还需要连接定期运行的workflow 作业,但在不同的时间间隔内。多个后续运行的workflow的输出成为下一个workflow 的输入。例如,每15分钟运行一次的workflow 的4次运行的输出,就变成了每隔60分钟运行一次的workflow 的输入。将这些workflow 链接在一起会导致它被称为数据应用程序管道。
Oozie Coordinator 系统允许用户定义和执行周期性和相互依赖的workflow 作业(数据应用程序管道)。
1.6、Bundle:批任务集
Bundle
是一个更高级的oozie抽象,它将批处理一组
Coordinator
应用程序。

用户将能够在bundle级别启动/停止/暂停/恢复/重新运行,从而获得更好、更容易的操作控制。
更具体地说,oozie Bundle系统允许用户定义和执行一堆通常称为数据管道的Coordinator应用程序。在Bundle中,Coordinator应用程序之间没有显式的依赖关系。然而,用户可以使用Coordinator应用程序的数据依赖来创建隐式数据应用程序管道。
二、
Oozie 调度 Spark2
使用Hue可以方便的通过界面制定Oozie的工作流,支持Hive、Pig、Spark、Java、Sqoop、MapReduce、Shell等等。但是Oozie默认情况下支持Spark1,如果 支持Spark 2 需要进行配置。
1、项目背景
公司部门成立初期,现在业务是由Shell脚本编写然后定时进行运行。由于现在公司一般都是搭
建的CDH,内置有Oozie。且Oozie操作简单,功能强大,并且有很好的图形化界面所以还是想要搞一
下。在搞的过程中出现了一堆问题,就是spark2与Oozie的整合现在不是很成熟,网上资料也很少,
基本是淌着过去的。。。
2、运行环境
CDH: CDH-5.14.0
Java: 1.8
Scala: 2.11.8
Spark: 2.2.0
3、环境说明
- Spark2
Apache 版本Spark 2.2.0
jar包:/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/jars/
- Oozie
oozie-4.1.0-cdh5.14.0
HDFS 上Shared lib目录地址:/user/root/share/lib/lib_20190723215106
2.1、HDP Oozie 集成Spark2
HDP官方Spark 使用配置文档中关于如何配置Spark2集成Oozie,相关配置截图如下。
https://docs.cloudera.com/HDPDocuments/HDP2/HDP-2.6.0/bk_spark-componentguide/content/ch_oozie-spark-action.html#spark-config-oozie-spark2

To use Oozie Spark action with Spark 2 jobs, create a spark2 ShareLib directory, copy associated files into it, and then point Oozie to spark2 . (The Oozie ShareLib is a set of libraries that allow jobs to run on any node in a cluster.)
1. Create a spark2 ShareLib directory under the Oozie ShareLib directory associated with the
oozie service user:
hdfs dfs -mkdir /user/oozie/share/lib/lib_<ts>/spark22. Copy spark2 jar files from the spark2 jar directory to the Oozie spark2 ShareLib:
hdfs dfs -put \
/usr/hdp/current/spark2-client/jars/* \
/user/oozie/share/lib/lib_<ts>/spark2/3. Copy the oozie-sharelib-spark jar file from the spark ShareLib directory to the spark2 ShareLib directory:
hdfs dfs -cp \
/user/oozie/share/lib/lib_<ts>/spark/oozie-sharelib-spark-*.jar \
/user/oozie/share/lib/lib_<ts>/spark2/4. Copy the hive-site.xml file for Spark2 to the spark2 ShareLib:
hdfs dfs -put \
/usr/hdp/current/spark2-client/conf/hive-site.xml \
/user/oozie/share/lib/lib_<ts>/spark2/5. Run the Oozie sharelibupdate command:
oozie admin –sharelibupdate 6. To verify the configuration, run the Oozie shareliblist command. You should see spark2 in the results.
oozie admin –shareliblist spark27. To run a Spark job with the spark2 ShareLib, add the action.sharelib.for.spark property to the job.properties file, and set its value to spark2 :
oozie.action.sharelib.for.spark=spark2The following examples show a workflow definition XML file, an Oozie job configuration file, and a Python script for running a Spark2-Pi job.
Sample Workflow.xml file for spark2-Pi :


Sample Job.properties file for spark2-Pi :
2.2、安装spark2-lib到oozie
按照上述文档具体操作命令如下:
## 参考文档:https://blog.csdn.net/zkf541076398/article/details/79941598
# 1. 在HDFS目录中创建spark2目录,存储Spark2相关jar包
hdfs dfs -mkdir -p /user/root/share/lib/lib_20190723215106/spark2
### 向spark2目录添加spark2的jars和oozie-sharelib-spark*.jar
# 2. 上传Spark2相关jar包至创建目录中(共享库spark2目录)
hdfs dfs -put /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/jars/*
/user/root/share/lib/lib_20190723215106/spark2
# 3. 拷贝oozie-spark集成jar包至共享库spark2目录
hdfs dfs -cp /user/root/share/lib/lib_20190723215106/spark/oozie-sharelibspark-4.1.0-cdh5.14.0.jar /user/root/share/lib/lib_20190723215106/spark2/
hdfs dfs -cp /user/root/share/lib/lib_20190723215106/spark/oozie-sharelibspark-4.1.0-cdh5.14.0.jar
/user/root/share/lib/lib_20190723215106/spark2/oozie-sharelib-spark.jar效果截图如下所示:

# 4. 更新Oozie的share-lib
oozie admin -oozie http://bigdata-cdh01.itcast.cn:11000/oozie -
sharelibupdate

# 5. 确认spark2已经添加到共享库
[root@bigdata-cdh01 ~]# oozie admin -oozie http://bigdatacdh01.itcast.cn:11000/oozie -shareliblist
[Available ShareLib]
hive
spark2
distcp
mapreduce-streaming
spark
oozie
hcatalog
hive2
sqoop
pig
2.3、Oozie Spark Action
Oozie中使用Spark Action官方文档如下:
http://bigdatacdh01.itcast.cn:11000/oozie/docs/DG_SparkActionExtension.html
1、The spark action runs a Spark job.
2、The workflow job will wait until the Spark job completes before
continuing to the next action.
3、To run the Spark job, you have to configure the spark action with the
job-tracker , name-node , Spark master elements as well as the necessary
elements, arguments and configuration.
4、Spark options can be specified in an element called spark-opts .
5、A spark action can be configured to create or delete HDFS directories
before starting the Spark job.WorkFlow具体配置语法案例如下:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.3">
...
<action name="[NODE-NAME]">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path="[PATH]"/>
...
<mkdir path="[PATH]"/>
...
</prepare>
<job-xml>[SPARK SETTINGS FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
...
</configuration>
<master>[SPARK MASTER URL]</master>
<mode>[SPARK MODE]</mode>
<name>[SPARK JOB NAME]</name>
<class>[SPARK MAIN CLASS]</class>
<jar>[SPARK DEPENDENCIES JAR / PYTHON FILE]</jar>
<spark-opts>[SPARK-OPTIONS]</spark-opts>
<arg>[ARG-VALUE]</arg>
...
<arg>[ARG-VALUE]</arg>
...
</spark>
<ok to="[NODE-NAME]"/>
<error to="[NODE-NAME]"/>
</action>
...
</workflow-app>

当Spark Application运行在YARN上时,为了监控运行完成的应用,相关设置如下:
To ensure that your Spark job shows up in the Spark History Server, make
sure to specify these three Spark configuration properties either in sparkopts with --conf or from
oozie.service.SparkConfigurationService.spark.configurations in ooziesite.xml.
1. spark.yarn.historyServer.address=SPH-HOST:18080
2. spark.eventLog.dir=hdfs://NN:8020/user/spark/applicationHistory
3. spark.eventLog.enabled=true
2.4、测试 Oozie 调度Spark2
编写相关job.properties属性文件和Workflow配置文件及Coordinator调度文件,运行Spark 框
架官方案例:圆周率PI,分别运行在
local[2]本地模式、YANR集群(
client和cluster)模式
。
2.4.1、本地模式:spark2–local
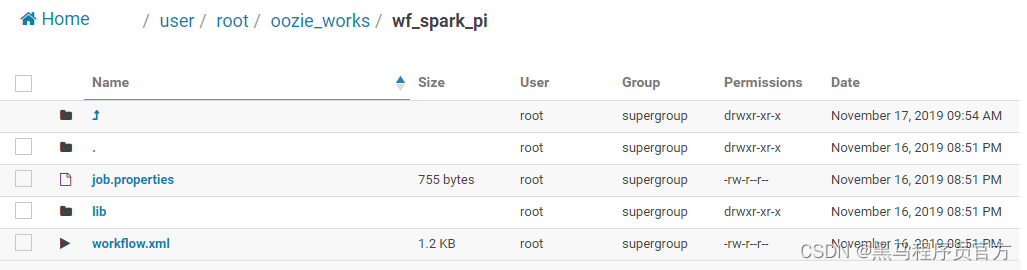
编写配置文件,运行SparkPi程序在本地模式local[2],具体说明如下。
job属性文件:
job.properties

Workflow配置文件:
workflow.xml


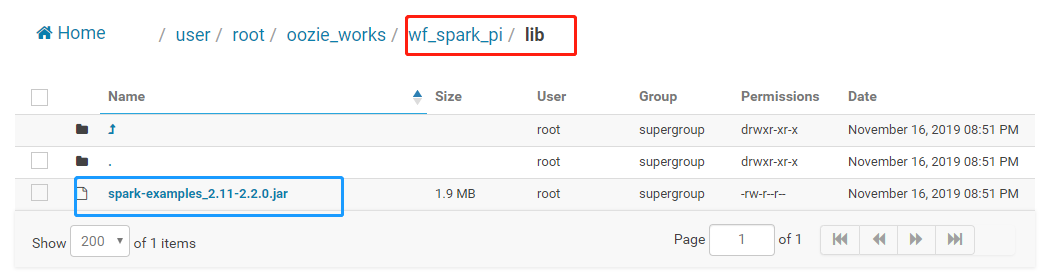
应用jar包及依赖包:
lib
目录
将应用运行所需jar包存放于lib目录下,截图如下
提交执行工作流Workflow,命令如下:
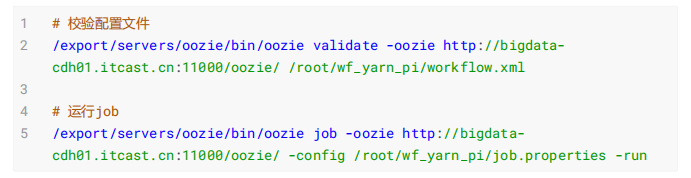
# 校验配置文件
/export/servers/oozie/bin/oozie validate -oozie http://bigdatacdh01.itcast.cn:11000/oozie/ /root/wf_spark_pi/workflow.xml
# 运行job
/export/servers/oozie/bin/oozie job -oozie http://bigdatacdh01.itcast.cn:11000/oozie/ -config /root/wf_spark_pi/job.properties -run
运行结束后监控截图:

由于本地模式运行Spark 应用,所以Spark 应用运行在Oozie Workflow中MapTask任务中。
2.4.2、YARN 集群:spark2–client
编写配置文件,运行SparkPi程序在yarn集群上,使用client部署运行模式,具体说明如下。
job属性文件:
job.properties

Workflow配置文件:
workflow.xml

提交执行工作流Workflow,命令如下:
运行结束后监控截图:

查看运行结果:

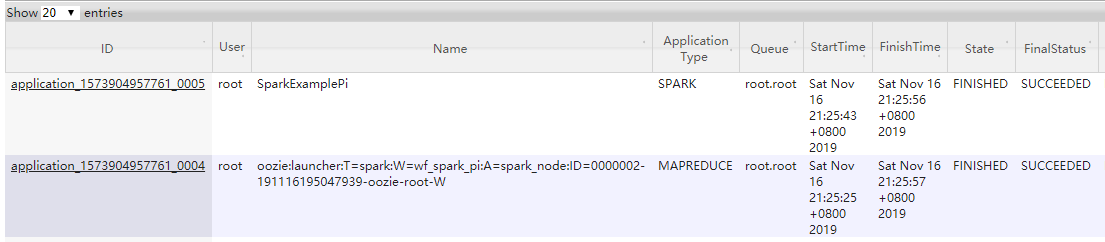
Spark Application监控截图:


2.4.3、YARN 集群:spark2–cluster
修改上述job属性文件,将Spark Application以cluster Deploy Mode运行YARN上,运行截图如下。
# 1. job.properties修改如下内容:
mode=cluster
# 2. 提交运行
/export/servers/oozie/bin/oozie job -oozie http://bigdatacdh01.itcast.cn:11000/oozie/ -config /root/wf_yarn_pi/job.properties -run具体截图如下:
WEB UI界面:

查看Driver Program日志中PI值:

2.5、测试Oozie定时调度
定时触发任务执行,编写配置文件,具体如下:
job属性文件:
job.properties

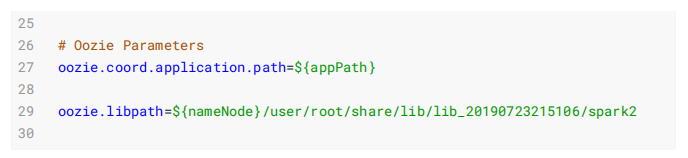
Workflow配置文件:
workflow.xml


Coordnator调度配置文件:
coordinator.xml
,内容如下:

执行任务:

Oozie UI监控页面,关于Coord任务详细:

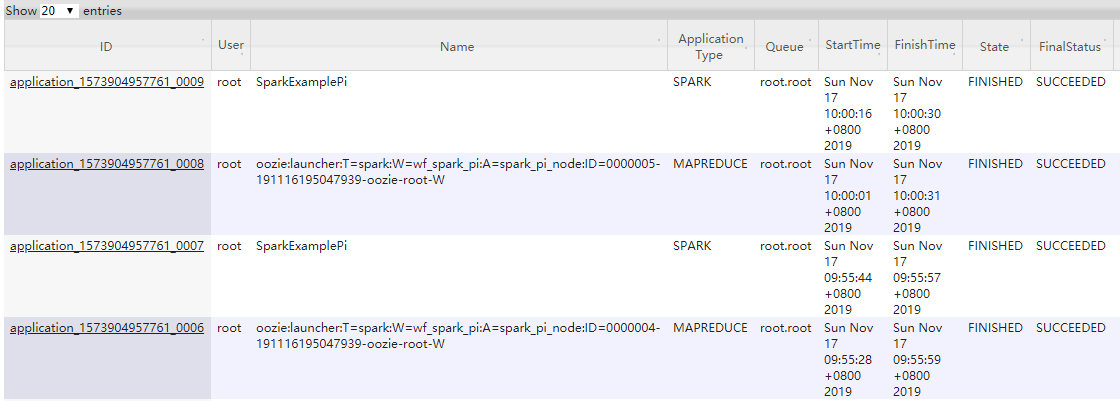
在YARN上监控执行任务截图如下:
三、Hue创建Oozie工作流
3.1、local 模式
登录Hue,创建Oozie工作流,点击【Workspace】按钮,新页面打开,上传jar包至lib目录中

进入WorkSpace,上传JAR包至lib目录:

添加Spark2任务:

选择jar包所在目录和jar包名称:

选择jar包所在文件夹

填写JAR包名称:

填写MainClass及添加JAR包文件:

设置使用Spark2,否则默认使用的Spark1:

保存Oozie,然后点击提交:


运行成功:

3.2、yarn client模式
进入 Workspace,进入 lib 目录,并上传 jar 包,拖拽 Spark Program,填写业务主类名称和 配置参数:

点击小齿轮,查看其他参数:
保存配置,提交运行:

运行截图如下:

其中Hue自动生成的workflow配置文件内容如下:


3.3、yarn cluster模式
按照上述yarn client模式使用hue构建workflow,设置应用运行为yarn-cluster模式,提交运行。

运行成功截图:

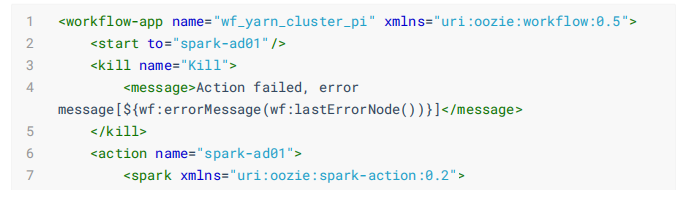
Hue自动生成WorkFlow配置文件内容如下:

3.4、Schedule 调度
选择进入Scheduler页面,基于Workflow构建调度任务,可以设置时间调度。

设置名称和描述,选择Workflow及定时执行表达式(注意时区选择):

上图中【How Ox en】值的选择,建议使用表达式:
0/5 * * * *调度界面图如下所示:

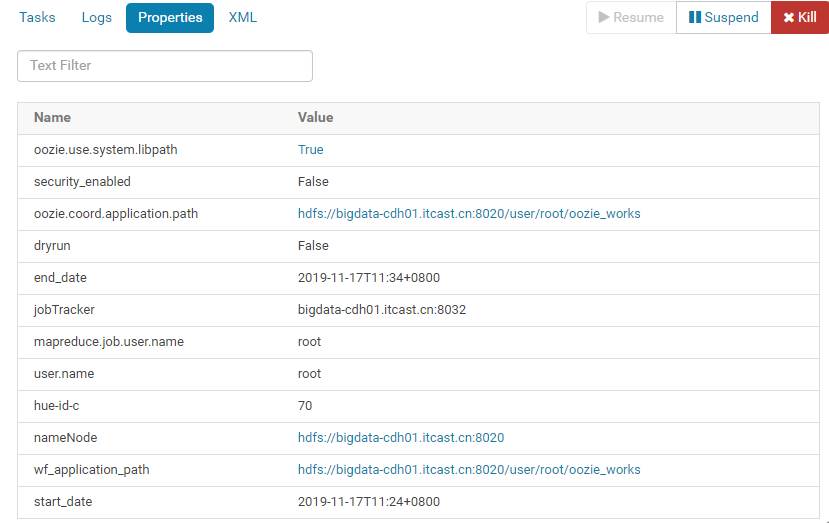
Hue生成属性配置文件及调度配置文件内容如下所示:

最终运行结束:


4、Oozie Java Client API
在Hadoop技术栈中可以使用Oozie做为
任务的调度与定时触发
的工具,更加方便的帮助进行管理和调度常见的9种作业调度

Apache Oozie是一个工作流调度系统,具有如下特性优势:
1)、工作流的调度是DAG(有向无环图)-Directed Acyclical Graphs
2)、Coordinator job可以通过时间和数据集的可用性触发
3)、集成了Hadoop生态系统的其它任务,如mr,pig,hive,sqoop,distcp
4)、可扩展:一个Oozie就是一个mr程序,但是仅仅是map,没有reduce
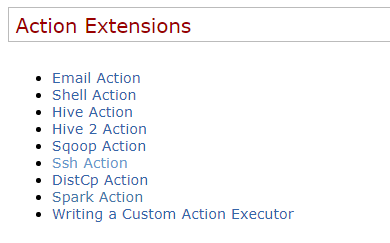
5)、可靠性:任务失败后的重试在Oozie中支持9种Action任务操作,具体如下:
4.1、Java API Example
编写JAVA 程序提交Oozie作业,在运行提交程序前,首先需要把相应的程序打成jar包,定义好workflow.xml,再把它们上传到HDFS中,然后在程序中指定作业的属性。
官方文档:http://oozie.apache.org/docs/4.1.0/DG_Examples.html
主要涉及类:
OozieClient,传递OozieUrl地址、工作流参数配置及配置文件,提交执行即可
,伪代码:

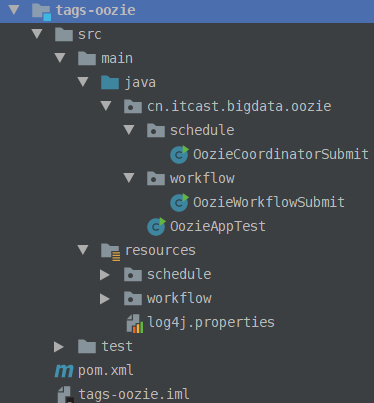
创建Maven Module,结构如下所示:
其中POM文件内容如下:



4.2、Workflow Submit
将SparkPi圆周率程序提交到YARN上以cluster DeployMode运行,相关配置文件内容如下:
属性文件
job.properties
:

Workflow工作流配置文件
workflow.xml
:


编写Java程序 OozieWorkflowSubmit ,构建 OozieClient 对象,将属性配置文件中Key/Value设置到roperties 中,当运行Workflow时传递properties对象,具体代码如下 所示:



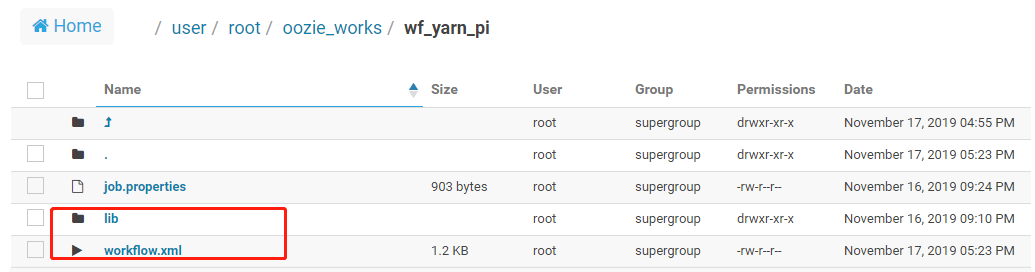
注意,将Spark Application程序依赖包及workflow.xml文件上传到HDFS目录中,结构如下所示:
4.3、Coordinator Submit
修改上述代码,添加定时调度时间设置及执行Coordinator配置文件,提交执行即可,具体如下:


运行执行后,通过Hue监控界面观察如下:
