二分类指标的区别
我们可以采用一些定量的分类指标来评价一个二分类器性能的好坏,这些指标往往根据分类器对某个数据集的分类结果进行计算。
分类矩阵
我们可以使用一个矩阵来描述分类结果:
| 实际\预测 | 预测为正 | 预测为负 |
|---|---|---|
| 实际为正 | TP | FN |
| 实际为负 | FP | TN |
TP
T
P
:实际为正、且划分为正的样本数,真正数。
FP
F
P
:实际为负、但划分为正的样本数,假正数。
TP
T
P
:实际为负、且划分为负的样本数,真负数。
FN
F
N
:实际为正、但划分为负的样本数,假负数。
对于一个理想的分类器,自然是希望
FN=FP=0
F
N
=
F
P
=
0
,但是实际场景不尽人意,所以出现了一些分类指标,来根据这四类样本的数量,对分类器进行评价。这些分类指标的目标是一致的:
FN,FP
F
N
,
F
P
越小,分类器性能越高。
分类指标
-
正确率(Accuracy):预测正确的结果所占总数的比例。
Accuracy=TP+TNTP+TN+FP+FN
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
正确率高并不能说明分类器效果好。比如识别是否一个人是否有艾滋病,就算全部预测为负样本,那正确率也有
99%
99
%
以上(因为每万人才有6个艾滋病人),但是这种高正确率的分类器其实并没有任何作用。
-
精确率(Precision):预测为正且预测正确的样本占所有预测为正的样本的比例,又叫做查准率。
Precision=TPTP+FP
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
精确率高意味着,只要识别出来是正的,就肯定是正的。侧重将不易区分的样本划分为负样本。考察的是识别出来的正样品是否靠谱。适用于 宁缺毋滥 的场景,比如识别一个面试者是否符合录取条件。 -
召回率(Recall,Sensitivity):预测为正且预测正确的样本占所有实际为正的样本的比例,又叫敏感度、查全率。
Recall=TPTP+FN
R
e
c
a
l
l
=
T
P
T
P
+
F
N
召回率高意味着,只要是正的,都能识别出来。侧重将不易区分的样本划分为正样本。考察的是对正样品是否敏感。适用于 宁可错杀一百不可放过一人 的场景,比如识别是否是犯罪嫌疑人、非典期间识别是否可能患了非典。 -
特异性(Specificity):预测为负且预测正确的样本占所有实际为负的样本的比例。
Specificity=TNTN+FP
S
p
e
c
i
f
i
c
i
t
y
=
T
N
T
N
+
F
P
特异性相当于负样本的“召回率”。
特异性高意味着,只要是负的,都能识别出来。侧重将不易区分的样本划分为负样本。考察的是对负样本是否敏感。注意:以上提到,精确率高意味着,只要识别出来是正的,就肯定是正的。这和特异性高的表现为逆反命题,但是不要认为精确率高等价于特异性高,因为高并不意味着百分百,这两句话只是从感性上来让大家有个直观的认识。
举一个反例:
TP=900 ,FN=10
FP=10,TN=1
预测出的910个正样本中有900个的确是正样本,准确率很高,为
9091
90
91
;但是实际的11个负样本中只预测出了1个,特异性仅为
111
1
11
。
但如果达到了百分百,那么就真的是逆反条件了,因此:
精确率=100%⟺特异性=100%
精
确
率
=
100
%
⟺
特
异
性
=
100
%
-
Fb-score:综合考虑了精确率和召回率而得出的指标。
Fb−score=(1+b2)×Precision×Recallb2×Precision+Recall
F
b
−
s
c
o
r
e
=
(
1
+
b
2
)
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
b
2
×
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
常用的是 F1-score:
F1−score=2×Precision×RecallPrecision+Recall
F
1
−
s
c
o
r
e
=
2
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
当Precision=Recall=1时,F1-score=1达到最大值。如果任意一个值很小,那么分子就会很小,F1-score就不会大,便说明分类性能不好。 -
ROC(Receiver Operating Characteristic)曲线:
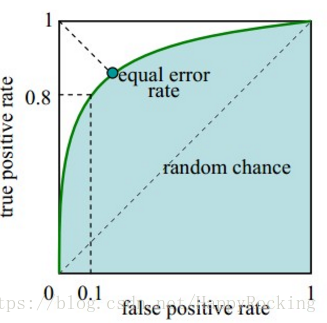
ROC曲线叫做受试者工作特征曲线,又叫做感受性曲线,是反映敏感性和特异性的综合指标。
ROC是一个二维曲线,纵坐标为真正率(即敏感性、召回率),表示真实正样本中预测正确的比例;横坐标为假正率,表示真实负样本中误分成正样本的比例,计算公式为
FTP=1−Specificity=FPTN+FP
F
T
P
=
1
−
S
p
e
c
i
f
i
c
i
t
y
=
F
P
T
N
+
F
P
ROC曲线的范围为
x∈[0,1]
x
∈
[
0
,
1
]
和
y∈[0,1]
y
∈
[
0
,
1
]
,一般在左上部分。定型来看,越靠近左上顶点(即
(0,1)
(
0
,
1
)
点),说明分类器性能越好。如果曲线为
(0,0)
(
0
,
0
)
到
(1,1)
(
1
,
1
)
的直线,说明是随机识别,分类器的作用为0。如果曲线在右下方,说明还不如随机识别的结果好,但是只要我们将结果反过来取值,还是会在左上方的。
定量分析,曲线与横轴之间的面积(AUC,Area Under roc Curve)越大,分类器性能越好。
作用:ROC曲线可以用来判断两种分类方法哪个好,也可以用来对同一种分类方法的不同参数进行评价,选择出最佳参数。