ElasticSearch(三)SpringBoot 整合ES
使用Java API
这种方式,官方已经明确表示在ES 7.0 版本中弃用 TransportClient 客户端,且在8.0 版本中完全移除它。
可以参考:https://blog.csdn.net/jacksonary/article/details/82729556
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/index.html

ElasticSearch-Rest- client
9300 TCP
spring:data-elasticsearch:transport-api.jar
-
SpringBoot 版本不同,transport-api.jar 不同,不能适配es版本
-
7.x 己经不建议使用,8以后就要废弃
9200: HTTP
- JesClient, 非官方,更新慢
- RestTemplate:模拟发 HTTP 请求,ES 很多操作需要自己封装,麻烦
- HttpClient:同上
- ElasticSearch-Rest- client :官方的RestClient 封装了ES操作,API层次分明,上手简单
最终我们需要使用Rest Client来和ES建立HTTP连接。
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-maven.html
JAVA DOC:https://artifacts.elastic.co/javadoc/org/elasticsearch/client/elasticsearch-rest-high-level-client/7.17.3/index.html
到这的时候发现
所以准备手动更新es和kibana的版本。参考docker hub给出的版本。
出现的第一个错误。

https://github.com/medcl/elasticsearch-analysis-ik/releases找到8.1.2。
我无语。。。。

只有到8.1.2.。。。。。。。。无语死了?
elasticsearch Tags | Docker Hub
去找8.1.2.
总结一下吧。
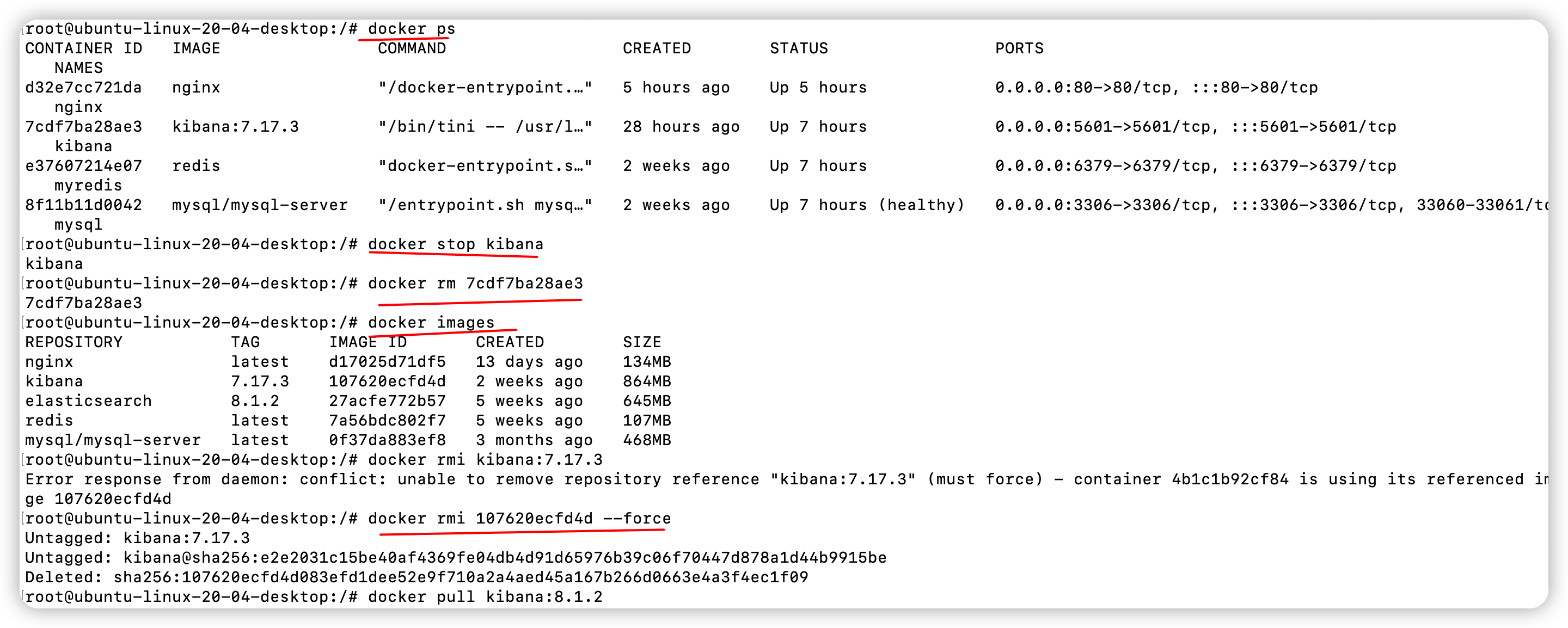
遇到的第一个错误

官方配置介绍:https://www.elastic.co/guide/en/kibana/current/settings.html

所以要看一下kibana的配置文件。
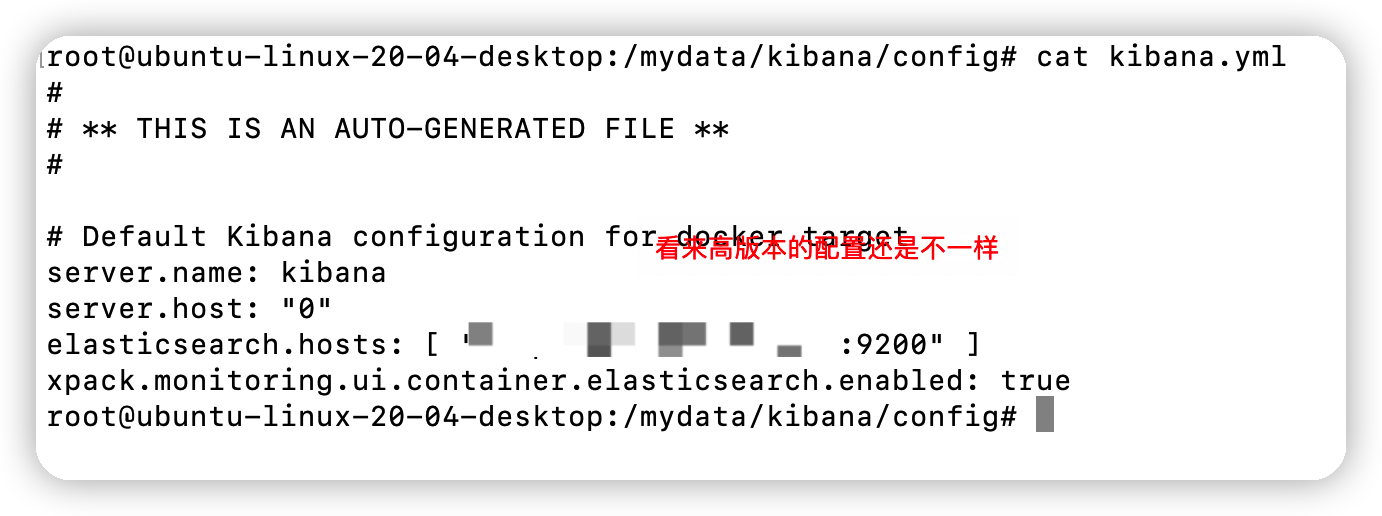
根据官网介绍需要改成自己虚拟机的地址。

起来了。

有发现kibana服务没起来,看了一下日志。

这种问题很常见。

可以看到我们之前的容器还占着。网上有好多教程,哈哈哈哈我打算避其锋芒,改端口。


# 清一下缓存
docker system prune
至此更新完成。
与SpringBoot整合
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-maven.html
导入依赖
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.17.3</elasticsearch.version>
</properties>
<!--elasticsearch依赖-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.3</version>
</dependency>
编写配置
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-initialization.html
给容器中注入一个RestHighLevelClient。
@Configuration
public class EsClientConfig {
@Bean
public RestHighLevelClient RestHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.1.115", 9200, "http")
));
return client;
}
}
测试
如果有报错“datasource”,在启动类上添加:
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
@SpringBootTest
public class EsclientApplicationTests {
@Autowired
RestHighLevelClient client;
@Test
public void test1() {
System.out.println(client);
}
}
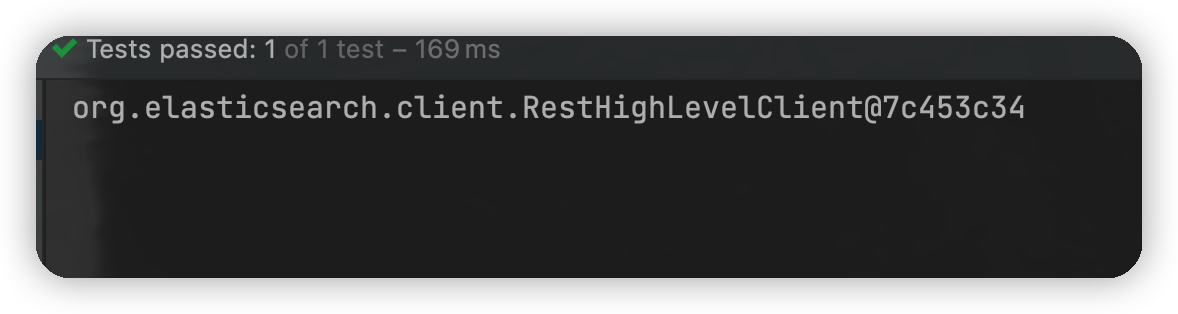
测试增删改查的操作
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-document-index.html#java-rest-high-document-index-request
package com.uin.esclient;
@SpringBootTest
public class EsclientApplicationTests {
@Autowired
RestHighLevelClient client;
@Test
public void test1() {
System.out.println(client);
}
/**
* index Api
*/
@Test
public void test_index() throws IOException {
//设置索引的名字
IndexRequest indexRequest = new IndexRequest("users");
//添加数据
indexRequest.id("1");
//indexRequest.source("username","uin","age","18","gender","男");
//将User对象转化为JSON数据
User user = new User();
user.setUsername("uin");
user.setGender("男");
user.setAge(22);
String s = JSON.toJSONString(user);
indexRequest.source(s, XContentType.JSON);
//执行保存数据分为:同步保存和异步保存
IndexResponse index = client.index(indexRequest, EsClientConfig.COMMON_OPTIONS);
//提取响应的数据
System.out.println(index);
}
@Data
class User {
private String username;
private String gender;
private Integer age;
}
@Test
public void test_search() throws IOException {
//1.创建检索请求
SearchRequest searchRequest = new SearchRequest();
//2.指定要检索的索引
searchRequest.indices("bank");
//3.构建检索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//检索的条件
builder.query(QueryBuilders.matchQuery("address", "mill"));
//对年龄进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg")
.field("age").size(10);
builder.aggregation(ageAgg);
//求出这些年龄分布的平均工资
AvgAggregationBuilder banlanceAvg = AggregationBuilders.avg("banlanceAvg").field(
"balance");
builder.aggregation(banlanceAvg);
//builder.from();
//builder.size();
//builder.sort();
System.out.println("检索条件" + builder);
//4.执行检索
SearchResponse search = client.search(searchRequest, EsClientConfig.COMMON_OPTIONS);
System.out.println(search.toString());
//5.分析结果 将json数据转换成对象
//获取所有命中到的数据
SearchHits hits1 = search.getHits();
//System.out.println(hits1);
SearchHit[] hits = hits1.getHits();
for (SearchHit hit : hits) {
//Map<String, Object> asMap = hit.getSourceAsMap();
String sourceAsString = hit.getSourceAsString();
JsonRootBean bean = JSON.parseObject(sourceAsString, JsonRootBean.class);
System.out.println("检索出来的对象:" + bean);
//System.out.println(sourceAsString);
}
//Map map = JSON.parseObject(String.valueOf(search), Map.class);
//6.获取分析之后的数据
Aggregations aggregations = search.getAggregations();
//aggregations.asList().forEach(aggregation -> System.out.println("当前聚合的名字" + aggregation
// .getName()));
Terms ageAgg1 = aggregations.get("ageAgg");
if (ageAgg1!=null){
// ageAgg1.getBuckets().forEach((Consumer<Terms.Bucket>) bucket -> {
// String keyAsString = bucket.getKeyAsString();
// System.out.println("年龄:" + keyAsString);
// });
for (Terms.Bucket bucket:ageAgg1.getBuckets()){
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:" + keyAsString);
}
}
Avg banlanceAvg1 = aggregations.get("banlanceAvg");
System.out.println("平均薪资:"+banlanceAvg1.getValue());
}
}