在训练卷积神经网络时需要预定义很多参数,例如batch_size, backbone,dataset,dataset_root等等,这些
参数多而且特别零散
;如果我们
最初不
把这些参数
定义
,到时候修改是一件特别
麻烦
的事情,需要
逐个修改
;所以这个时候用到了python的
add_argument()
很好的
规避
了这些
问题
。
首先讲,argparse是Python内置的一个用于命令项选项与参数解析的模块,argparse模块可以让人轻松编写用户友好的命令接口。程序定义它需要的参数,然后argparse将弄清如何从sys.argv解析出那些参数。argparse模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
出自官网:
argparse — 命令行选项、参数和子命令解析器
![]()
https://docs.python.org/zh-cn/3/library/argparse.html#argumentparser-objects
本文主要以训练卷积神经网络的角度,对argparse使用进行讲解。
首先给出
代码示例
,在对其进行分析,再将其应用在训练卷积神经网络中:
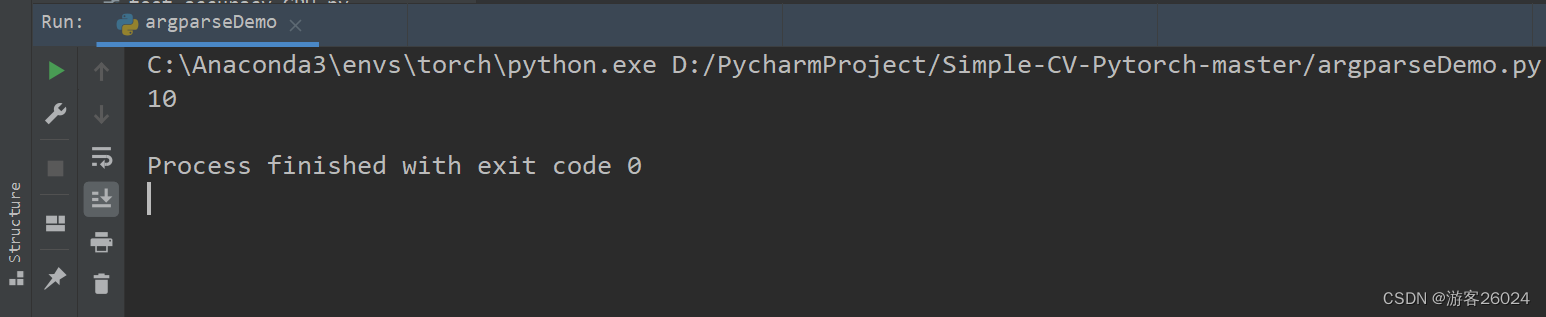
import argparse
parser = argparse.ArgumentParser(description='CV Train')
parser.add_argument('--epochs', type=int, default=10, help='Number of epochs to train.')
args = parser.parse_args()
print(args.epochs)
运行结果:
分析:
- 首先,创建解析器ArgumentParser()对象
ArgumentParser
对象包含将命令行解析成 Python 数据类型所需的全部信息
parser = argparse.ArgumentParser(description='CV Train')- 其次,添加参数调用add_argument()方法添加参数
给一个
ArgumentParser
添加程序参数信息是通过调用
add_argument()
方法完成的。通常,这些调用指定
ArgumentParser
如何获取命令行字符串并将其转换为对象。这些信息在
parse_args()
调用时被存储和使用
parser.add_argument('--epochs', type=int, default=10, help='Number of epochs to train.')然后调用parse_args()将返回一个具有epochs属性的对象,epochs属性将是一个包含一个或多个整数的列表。
这个epochs属性的名字叫做epochs,类型为int,默认情况下其值为10,对其的解释为Number of epochs to train->训练的epoch数。
- 最后,解析参数使用parse_args()解析添加参数
ArgumentParser
通过
parse_args()
方法解析参数。它将检查命令行,把每个参数转换为适当的类型然后调用相应的操作。在脚本中,通常
parse_args()
会被不带参数调用,而
ArgumentParser
将自动从
sys.argv
中确定命令行参数
args = parser.parse_args()- 将args.epoch打印出来
print(args.epochs)
ArgumentParser对象的参数
很多,其参数解释如下:[这些
仅作了解,知道description即可
,在训练卷积神经网络中并不会用到很多]
prog - The name of the program (default: os.path.basename(sys.argv[0]))
usage - 描述程序用途的字符串(默认值:从添加到解析器的参数生成)
description - 在参数帮助文档之前显示的文本(默认值:无)
epilog - 在参数帮助文档之后显示的文本(默认值:无)
parents - 一个 ArgumentParser 对象的列表,它们的参数也应包含在内
formatter_class - 用于自定义帮助文档输出格式的类
prefix_chars - 可选参数的前缀字符集合(默认值: '-')
fromfile_prefix_chars - 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合(默认值: None)
argument_default - 参数的全局默认值(默认值: None)
conflict_handler - 解决冲突选项的策略(通常是不必要的)
add_help - 为解析器添加一个 -h/--help 选项(默认值: True)
allow_abbrev - 如果缩写是无歧义的,则允许缩写长选项 (默认值:True)
exit_on_error - 决定当错误发生时是否让 ArgumentParser 附带错误信息退出。 (默认值: True)
add_argument()方法定义如何解析命令行参数
:
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])其参数解释如下:
name or flags - 一个命名或者一个选项字符串的列表,例如 foo 或 -f, --foo。
action - 当参数在命令行中出现时使用的动作基本类型,其默认值是store。
nargs - 命令行参数应当消耗的数目。
const - 被一些 action 和 nargs 选择所需求的常数。
default - 当参数未在命令行中出现并且也不存在于命名空间对象时所产生的值。[不指定参数时的默认值]
type - 命令行参数应当被转换成的类型。
choices - 可用的参数的容器。
required - 此命令行选项是否可省略 (仅选项可用)。
help - 一个此选项作用的简单描述。
metavar - 在使用方法消息中使用的参数值示例。
dest - 被添加到 parse_args() 所返回对象上的属性名。
parser.add_argument(argparse)
应用在训练卷积神经网络中
,代码:
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Detection Training')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='ImageNet',
choices=['ImageNet', 'CIFAR'],
help='ImageNet, CIFAR')
parser.add_argument('--dataset_root',
type=str,
default=ImageNet_ROOT,
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='VGG',
help='Pretrained base model')
parser.add_argument('--batch_size',
type=int,
default=64,
help='Batch size for training')
parser.add_argument('--resume',
type=str,
default=None,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to train model')
parser.add_argument('--momentum',
type=float,
default=0.9,
help='Momentum value for SGD optim')
parser.add_argument('--gamma',
type=float,
default=0.1,
help='Gamma update for SGD')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--lr',
type=float,
default=1e-2,
help='learning rate')
parser.add_argument('--epochs',
type=int,
default=100,
help='Number of epochs')
parser.add_argument('--num_classes',
type=int,
default=1000,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=224,
help='image size, like ImageNet:224, cifar:32')
parser.add_argument('--pretrained',
type=str,
default=False,
help='Models was pretrained')
return parser.parse_args()
args = parse_args()
分析:
dataset数据集: ImageNet
dataset_root数据集的路径: ImageNet_ROOT = 'data/public/ImageNet'
basenet即backbone: VGG
batch_size: 64
resume接着上次训练的文件继续训练:None 或者 'XX.pth'
cuda cuda是否使用:True
momentum 使用SGD学习的动量: 0.9(初始值)
gamma 使用SGD更新的gamma: 0.1
save_folder 训练好之后保存的.pth文件
log_folder 日志文件
lr 学习率
epochs 训练使用的epochs
num_classes 使用数据集的类别总数
image_size 图像大小的尺寸
pretrained 是否使用预训练此文参考: