超级详细的Python学习笔记,适合Python二级备考和自学Python的小白(me too)。
写作不易,喜欢的话点个赞吧??,同时欢迎访问
我的博客 zkkk123.cn
??
1.程序设计基本方法
-
思维导图
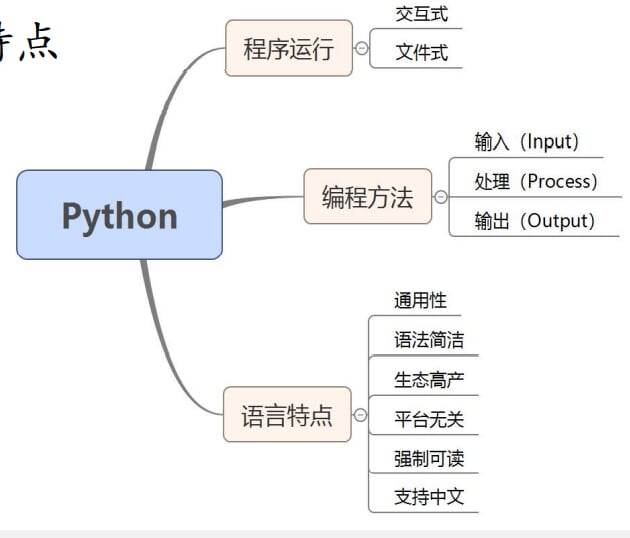
1.1高级编程语言两类执行机制
| 语言 | 执行机制 | 示例 | 区别 |
|---|---|---|---|
| 静态语言 | 编译执行 | 如C语言、Java语言 | 编译是一次性地翻译,一旦程序被编译,不再需要编译程序或者源代码。 |
| 脚本语言 | 解释执行 | 如Python语言、JavaScript语言、PHP语言 | 解释则在每次程序运行时都需要解释器和源代码。 |
-
编译是将源代码转换成目标代码的过程,通常,
源代码是高级语言代码,目标代码是机器语言代
码,执行编译的计算机程序称为编译器
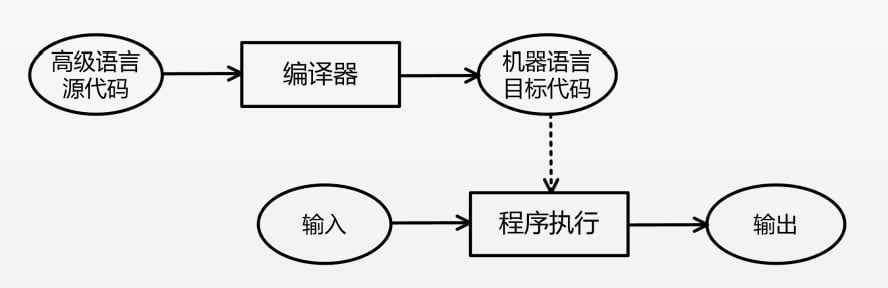
-
解释是将源代码逐条转换成目标代码同时逐条运
行目标代码的过程。执行解释的计算机程序称为
解释器。

1.2 Python解释器的两个重要工具
IDLE:Python集成开发环境,用来编写和调试
Python代码;
Pip:Python第三方库安装工具,用来在当前计算
机上安装第三方库
关于python的安装,发展历史,程序设计IPO方法,Pythond优缺点为避免繁琐,这里不予过多介绍,有问题的可以
留言
或自己百度解决~~
2.Python语言基本语法元素
-
思维导图
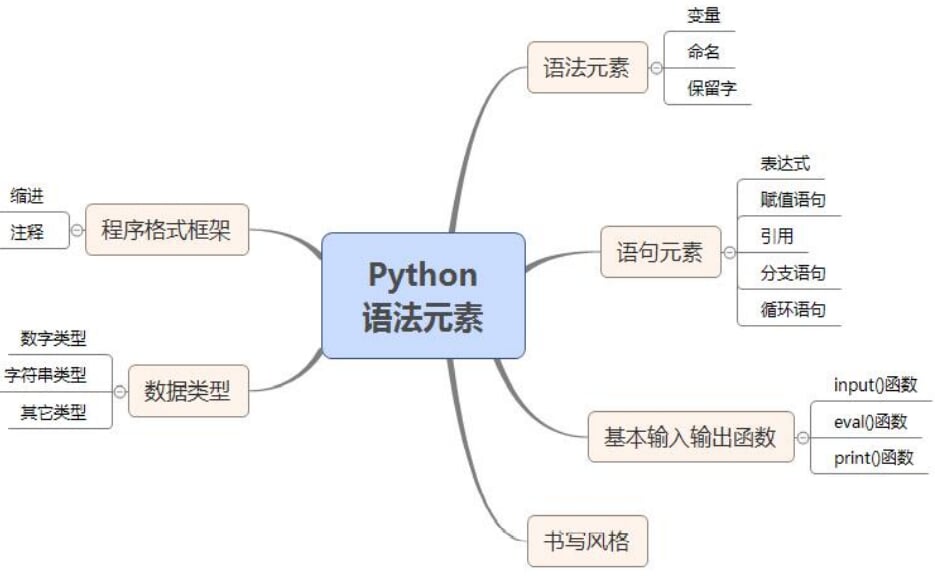
考纲考点
程序的基本语法元素:程序的格式框架、缩进、注释、变量、命名、保留字、数据类型、赋值语句、引用
基本输入输出函数:input()、eval()、print()
源程序的书写风格
2.1程序的格式
2.1.1缩进
- Python语言采用严格的“缩进”来表明程序的格式框架。缩进指每一行代码开始前的空白区域,用来表示代码之间的包含和层次关系
- 1个缩进 = 4个空格
- 缩进是Python语言中表明程序框架的唯一手段
2.1.2注释
-
注释是代码中的辅助性文字,会被编译或解释器略去,不被计算机执行,一般用于程序员对代码的说明。Python语言采用#表示一行注释的开始,
多行注释用’”或”””将内容前后包含
2.1.3续行符
- Python程序是逐行编写的,每行代码长度并无限制,但从程序员角度,单行代码太长并不利于阅读,因此,Python提供“续行符”将代码分割为多行表达。续行符由反斜杠()符号表达。
2.2语法元素的名称
2.2.1变量
- 变量是保存和表示数据值的一种语法元素,在程序中十分常见。顾名思义,变量的值是可以改变的,能够通过赋值(使用等号=表达)方式被修改,例如:
>>>a = 99
>>>a = a + 1
>>>print(a)
100
2.2.2命名
- Python语言允许采用大写字母、小写字母、数字、下划线(_)和汉字等字符及其组合给变量命名,但名字的首字符不能是数字,中间不能出现空格,长度没有限制
-
注意:
标识符对大小写敏感
,python和Python是两个不同的名字
2.2.3保留字
- 保留字,也称为关键字,指被编程语言内部定义并保留使用的标识符。
- 程序员编写程序不能定义与保留字相同的标识符。
- 每种程序设计语言都有一套保留字,保留字一般用来构成程序整体框架、表达关键值和具有结构性的复杂语义等。
- 掌握一门编程语言首先要熟记其所对应的保留字。
- Python 3.x保留字列表 (33个)
| | | |
-|-|-|-
and |elif |import| raise
as |else |in |return
assert |except |is| try
break| finally| lambda| while
class |for| nonlocal| with
continue| from| not |yield
def |global| or |True
del |if| pass| False
None
2.2.4数据类型
- Python语言支持多种数据类型,最简单的包括数字类型、字符串类型,略微复杂的包括元组类型、集合类型、列表类型、字典类型等。
数据类型各种编程语言大同小异,文章后面章节也会详细介绍,这里就不再赘述。
2.3程序的语句元素
2.3.1表达式
- 产生或计算新数据值的代码片段称为表达式。表达式类似数学中的计算公式,以表达单一功能为目的,运算后产生运算结果,运算结果的类型由操作符或运算符决定。
- 表达式一般由数据和操作符等构成,这是构成Python语句的重要部分。
2.3.2赋值语句
-
Python语言中,= 表示“赋值”,即将等号右侧的值计算后将结果值赋给左侧变量,包含等号(=)的语句称为“赋值语句”
<变量> = <表达式>
-
同步赋值语句:同时给多个变量赋值
<变量1>, …, <变量N> = <表达式1>, …, <表达式N>
2.3.3引用
-
Python程序会经常使用当前程序之外已有的功能代码,这个过程叫“引用”。Python语言使用import保留字引用当前程序以外的功能库,使用方式如下:
import <功能库名称>
-
引用功能库之后,采用
<功能库名称>.<函数名称>()
方式调用具体功能
2.3.4其他语句
- 除了赋值语句外,Python程序还包括一些其他的语句类型,例如,分支语句和循环语句等。更多的分支和循环内容将在第4章介绍。这里不再赘述。
2.4基本输入输出函数
| 函数 | 语法 | 介绍 |
|---|---|---|
| input | <变量> = input(<提示性文字> | 获得用户输入之前,input()函数可以包含一些提示性文字 |
| eval | eval(<字符串>) | eval(<字符串>)函数是Python语言中一个十分重要的函数,它能够以Python表达式的方式解析并执行字符串,将返回结果输出 |
| print() |
1.print(<待输出字符串>) 2.print(<变量1>, <变量2>,…, <变量n>) 3.print(<输出字符串模板>.format(<变量1>, <变量2>,…, <变量n>)) 4.print(<待输出内容>, end=“<增加的输出结尾>”) |
1.仅用于输出字符串 2.仅用于输出一个或多个变量 3.用于混合输出字符串与变量值 4.对print()函数的end参数进行赋值 |
3.Python 基本数据类型
-
思维导图
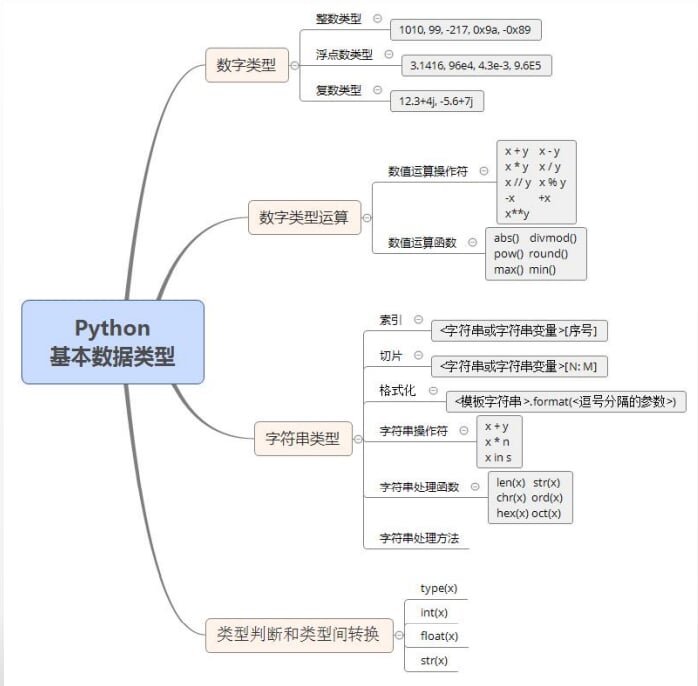
3.1数字类型
3.1.1整数类型
整数(int)的4种进制的表示:
| 进制种类 | 引导符号 | 描述 |
|---|---|---|
| 十进制 | 无 | 默认情况,例:1010,-1010 |
| 二进制 | ob或oB | 由数字0和1组成,例:0b1010,0B1010 |
| 八进制 | 0o或0O | 由数字0到7组成,例:0o1010,0O1010 |
| 十六进制 | 0x或0X | 由字符0到9,a到f或A到F组成,例:0x1010,0X1010 |
3.1.2浮点类型
| 类型 | 样式 | 例子 |
|---|---|---|
| 科学计数法 |
=a×10 b |
1.23e4=12300 |
| 小数类型 | 整数.小数 | 0.3 |
3.1.3复数类型
| 方法 | 作用 |
|---|---|
| z.real | 取实部 |
| z.iamg | 取虚部 |
>>> z = 1.23e4+4.56e4j
>>> z.real
12300.0
>>> z.imag
45600.0
>>>1.23e4+5.67e4j.imag # 先获得5.67e4j的虚部,再与1.23e4进行求和计算
69000.0
3.2数字类型的运算
3.2.1数值运算操作符
Python提供了9个运算操作符,如表所示:
| 操作符及运算 | 描述 |
|---|---|
| x+y | x与y的和 |
| x-y | x与y的差 |
| x*y | x与y的积 |
| x/y | x与y的商,产生结果为浮点数 |
| x//y | x与y的整数商,即:不大于x与y之商的最大整数 |
| x%y | x与y之商的余数,也称为模运算 |
| -x | x的负值,即:x*(-1) |
| +x | x本身 |
| x**y |
x的y次幂,即:x y |
增强赋值操作符
:+=、-=、*=、/=、//=、%=、**=,用op表示二元运算操作符,增强操作符用法如下:
x op= y
等价与
x = x op y
3.2.2数值运算函数
内置的数值运算函数:
| 函数 | 描述 |
|---|---|
| abs(x) | x的绝对值 |
| divmod(x, y) | (x//y, x%y),输出为二元组形式(也称为元组类型) |
| pow(x,y)或pow(x,y,z) |
|
| round(x)或round(x,d) | 对x四舍五入,保留ndigits位小数。round(x)返回四舍五入的整数值 |
| max(x1, x2, …, xn) | x1, x2, …, xn的最大值,n没有限定 |
| min(x1, x2, …, xn) | x1, x2, …, xn的最小值,n没有限定 |
3.3字符串类型及格式化
3.3.1字符串的索引
<字符串或字符串变量>[序号]
3.3.2字符串的切片
<字符串或字符串变量>[N: M]
3.3.3format()的方法的基本使用
<模板字符串>.format(<逗号分隔的参数>)
3.3.4format()的方法的格式控制
{<参数序号>: <格式控制标记>}
| : | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 |
<左对齐 >右对齐 ^中间对齐 |
槽的设定输出宽度 |
数字的千位分隔符 适用于整数和浮点数 |
浮点数小数部分的精度 或 字符串的最大输出长度 |
整数类型b,c,d,o,x,X< 浮点数类型e,E,f,% |
格式控制标记包括:<填充><对齐><宽度>,<.精度><类型>6个
字段,这些字段都是可选的,可以组合使用
- <填充>、<对齐>和<宽度>主要用于对显示格式的规范。
- <.精度><类型>主要用于对数值本身的规范
-
对于整数类型,输出格式包括6种:
• b: 输出整数的二进制方式;
• c: 输出整数对应的Unicode字符;
• d: 输出整数的十进制方式;
• o: 输出整数的八进制方式;
• x: 输出整数的小写十六进制方式;
• X: 输出整数的大写十六进制方式;
>>>"{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425)
'110101001,Ʃ,425,651,1a9,1A9'
3.4字符串类型的操作
3.4.1字符串操作符
基本的字符串操作符:
| 操作符 | 描述 |
|---|---|
| x + y | 连接两个字符串x与y |
| x * n 或 n * x | 复制n次字符串x |
| x in s | 如果x是s的子串,返回True,否则返回False |
3.4.2字符串处理函数
字符串处理函数:
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度,也可返回其他组合数据类型的元素个数 |
| str(x) | 返回任意类型x所对应的字符串形式 |
| chr(x) | 返回Unicode编码x对应的单字符 |
| ord(x) | 返回单字符x表示的Unicode编码 |
| hex(x) | 返回整数x对应十六进制数的小写形式字符串 |
| oct(x) | 返回整数x对应八进制数的小写形式字符串 |
3.4.3字符串处理方法
常用的字符串处理方法
| 方法 | 描述 |
|---|---|
| str.lower() | 返回字符串str的副本,全部字符小写 |
| str.upper() | 返回字符串str的副本,全部字符大写 |
| str.split(sep=None) | 返回一个列表,由str根据sep被分割的部分构成 |
| str.count(sub) | 返回sub子串出现的次数 |
| str.replace(old, new) | 返回字符串str的副本,所有old子串被替换为new |
| str.center(width, fillchar) | 字符串居中函数,fillchar参数可选 |
| str.strip(chars) | 从字符串str中去掉在其左侧和右侧chars中列出的字符 |
| str.join(iter) | 将iter变量的每一个元素后增加一个str字符串 |
3.5类型判断和类型转换
类型判断函数
| 函数 | 描述 |
|---|---|
| type(x) | 函数对变量x进行类型判断,适用于任何数据类型。 |
类型转换函数
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为整数,x可以是浮点数或字符串 |
| float(x) | 将x转换为浮点数,x可以是整数或字符串 |
| str(x) | 将x转换为字符串,x可以是整数或浮点数 |
3.6实例解析——凯撒密码
4.程序的控制结构
-
思维导图
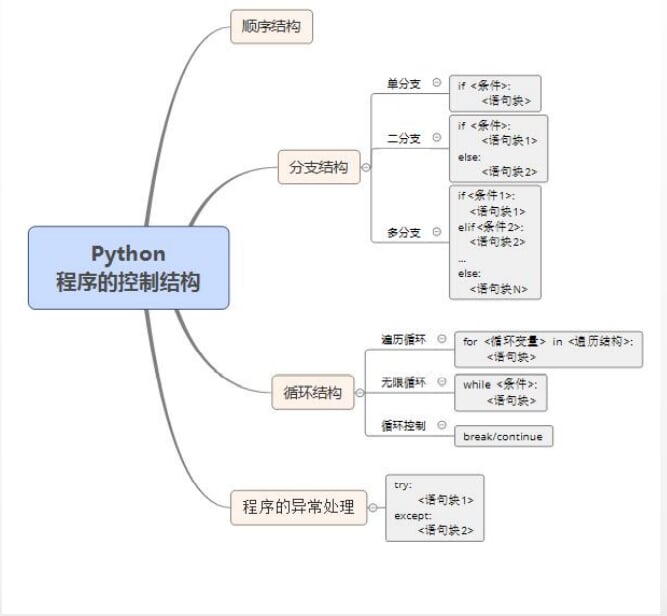
4.1顺序结构
顺序结构是程序按照线性顺序依次执行的一种运行
方式
4.2分支结构
#单分支结构: if语句
if <条件>:
语句块
#二分支结构:if-else
if <条件>:
<语句块1>
else:
<语句块2>
#多分支结构:if-elif-else
if <条件1>:
<语句块1>
elif <条件2>:
<语句块2>
...
else:
<语句块N>
4.3循环结构
4.3.1遍历循环: for
for <循环变量> in <遍历结构>:
<语句块>
遍历循环还有一种扩展模式,使用方法如下:
for <循环变量> in <遍历结构>:
<语句块1>
else:
<语句块2>
当for循环正常执行之后,程序会继续执行else语句中内容。else语句只在循环正常执行之后才执行并结束,因此,可以在<语句块2>中放置判断循环执行情况的语句。
4.3.2无限循环: while
while <条件>:
<语句块>
while <条件>:
<语句块1>
else:
<语句块2>
4.3.3循环控制: break和continue
| 语句 | 区别 |
|---|---|
| continue | 只结束本次循环,不终止整个循环的执行 |
| break | 具备结束循环的能力 |
4.4判断条件组合
Python关系操作符
| 操作符 | 数学符号 | 操作符含义 |
|---|---|---|
| < | ﹤ | 小于 |
| <= | ≤ | 小于等于 |
| >= | ≥ | 大于等于 |
| > | > | 大于 |
| == | = | 等于 |
| != | ≠ | 不等于 |
Python语言使用保留字not、and和or对条件进行逻辑运算或组着。
保留字not表示单个条件的“否”关系,and表示多个条件之间的“与”关系,保留字or表示多个条件之间的“或”关系。
>>>not True
False
>>>a = 80
>>>( a > 100) or ( a > 50 and a < 90)
True
4.4程序的异常处理
Python语言使用保留字try和except进行异常处理,基本的语法格式如下:
try:
<语句块1>
except:
<语句块2>
4.5实例解析——猜数字游戏
5.函数和代码复用
-
思维导图
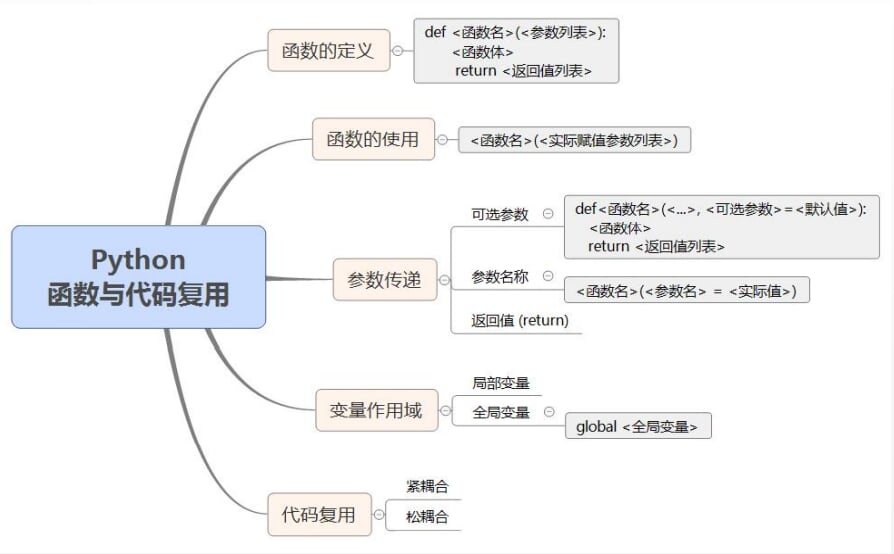
5.1函数的基本使用
5.1.1函数的定义
Python定义一个函数使用def保留字,语法形式
如下:
def <函数名>(<参数列表>):
<函数体>
return <返回值列表>
5.1.2函数的使用
<函数名>(<实际赋值参数列表>
# 定义一个对整数n求阶乘的函数
def fact(n):
s = 1
for i in range(1, n+1):
s *= i
return s
# 调用整数阶乘的函数
print(fact(100))
函数定义->函数调用->函数执行->函数返回
5.2函数的传递
5.2.1可选参数传递
def <函数名>(<非可选参数列表>, <可选参数> = <默认值>):
<函数体>
return <返回值列表>
5.2.2参数名称传递
<函数名>(<参数名> = <实际值>)
>>>def multiply(x, y = 10):
print(x*y)
>>>multiply(x = 99)
990
>>>multiply(y = 2, x = 99)
198
5.2.3函数的返回值
return语句可以出现在函数中的任何部分,同时可以将0个、1个或多个函数运算的结果返回给函数被调用处的变量。
>>>def multiply(x, y = 10):
return x*y
>>>s = multiply(99, 2)
>>>print(s)
198
5.3变量的作用域
| 变量 | 作用域 |
|---|---|
| 局部变量 | 局部变量指在函数内部使用的变量,仅在函数内部有效,当函数退出时变量将不再存在。但可以用global声明在函数内做为全局变量用。 |
| 全局变量 | 全局变量指在函数之外定义的变量,在程序执行全过程有效。 |
5.4代码复用
函数封装的直接好处是代码复用,任何其他代码只要输入参数即可调用函数,从而避免相同功能代码在被调用处重复编写。
模块化设计
是使用函数设计程序的思考方法,以功能块为基本单位,一般有两个基本要求:
| 方法 | 含义 | 作用 |
|---|---|---|
| 紧耦合 | 尽可能合理划分功能块,功能块内部耦合紧密 | 紧耦合的缺点在于更新一个模块可能导致其它模块变化,复用较困难。 |
| 松耦合 | 模块间关系尽可能简单,功能块之间耦合度低 | 松耦合一般基于消息或协议实现,系统间交互简单。 |
5.5实例解析——软文的诗词风
6.组合数据类型
-
思维导图

6.1集合
集合类型是一个元素集合,元素之间无序,相同元素在
集合中唯一存在。
>>>S = {1010, "1010", 78.9}
>>>type(S)
<class 'set'>
>>>len(S)
3
>>>print(S)
{78.9, 1010,'1010'}
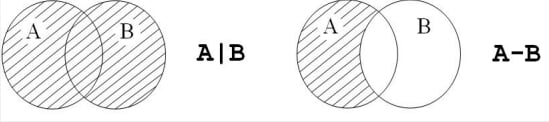
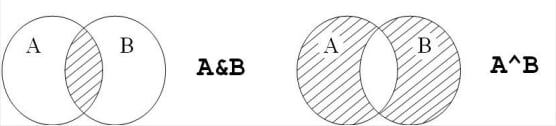
集合类型的操作符
| 操作符的运算 | 描述 |
|---|---|
| S – T | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S & T | 返回一个新集合,包括同时在集合S和T中的元素 |
| S^T | 返回一个新集合,包括集合S和T中非共同元素 |
| S∣T | 返回一个新集合,包括集合S和T中所有元素 |
-
图例
集合类型常用的操作函数和方法
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError |
| S.clear() | 移除S中所有数据项 |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
6.2列表
6.2.1列表定义
列表是包含0个或多个元组组成的有序序列,属于序列类型。列表可以元素进行增加、删除、替换、查找等操作。列表没有长度限制,元素类型可以不同,不需要预定义长度。
列表类型用中括号[]表示,也可以通过list(x)函数将集合或字符串类型转换成列表类型。
6.2.2列表的操作函数
| 操作函数 | 描述 |
|---|---|
| len(ls) | 列表ls的元素个数(长度) |
| min(ls) | 列表ls中的最小元素 |
| max(ls) | 列表ls中的最大元素 |
| list(x) | 将x转变成列表类型 |
6.2.3列表的操作方法
语法形式是:
<列表变量>.<方法名称>(<方法参数>)
| 方法 | 描述 |
|---|---|
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.insert(i, x) | 在列表ls第i位置增加元素x |
| ls.clear() | 删除ls中所有元素 |
| ls.pop(i) | 将列表ls中第i项元素取出并删除该元素 |
| ls.remove(x) | 将列表中出现的第一个元素x删除 |
| ls.reverse() | 列表ls中元素反转 |
| ls.copy() | 生成一个新列表,复制ls中所有元素 |
6.2.4列表的删除操作
del <列表变量>[<索引序号>] 或
del <列表变量>[<索引起始>: <索引结束>]
6.3字典
6.3.1字典定义
Python语言中的字典使用大括号{}建立,每个元
素是一个键值对,使用方式如下:{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
6.3.2字典索引
字典中键值对的索引模式如下,采用中括号格式:
<值> = <字典变量>[<键>]
>>>d = {"201801":"小明","201802":"小红""201803":"小白"}
>>>d["201802"] = '新小红'
>>>print(d)
{'201801': '小明','201803': '小白','201802': '新小红'
6.3.3字典的操作函数
| 操作函数 | 描述 |
|---|---|
| len(d) | 字典d的元素个数(长度) |
| min(d) | 字典d中键的最小值 |
| max(d) | 字典d中键的最大值 |
| dict() | 生成一个空字典 |
6.3.4字典的操作方法
字典类型存在一些操作方法,使用语法形式是:
<字典变量>.<方法名称>(<方法参数>)
| 操作方法 | 描述 |
|---|---|
| d.keys() | 返回所有的键信息 |
| d.values() | 返回所有的值信息 |
| d.items() | 返回所有的键值对 |
| d.get(key, default) | 键存在则返回相应值,否则返回默认值 |
| d.pop(key, default) | 键存在则返回相应值,同时删除键值对,否则返回默认值 |
| d.popitem() | 随机从字典中取出一个键值对,以元组(key, value)形式返回 |
| d.clear() | 删除所有的键值对 |
此外,如果希望删除字典中某一个元素,可以使用Python保留字
del
。
>>>d = {"201801":"小明", "201802":"小红", "201803":"小白"}
>>>del d["201801"]
>>>print(d)
{'201802': '小红', '201803': '小白'}
字典类型也支持保留字
in
,用来判断一个键是否在字典中。如果在则返回True,否则返回False。
>>>d = {"201801":"小明", "201802":"小红", "201803":"小白"}
>>>"201801" in d
True
>>>"201804" in d
False
6.3.4字典的遍历
与其他组合类型一样,字典可以遍历循环对其元素进行遍历,基本语法结构如下:
for <变量名> in <字典名>
<语句块>
6.4实例解析:文本词频统计
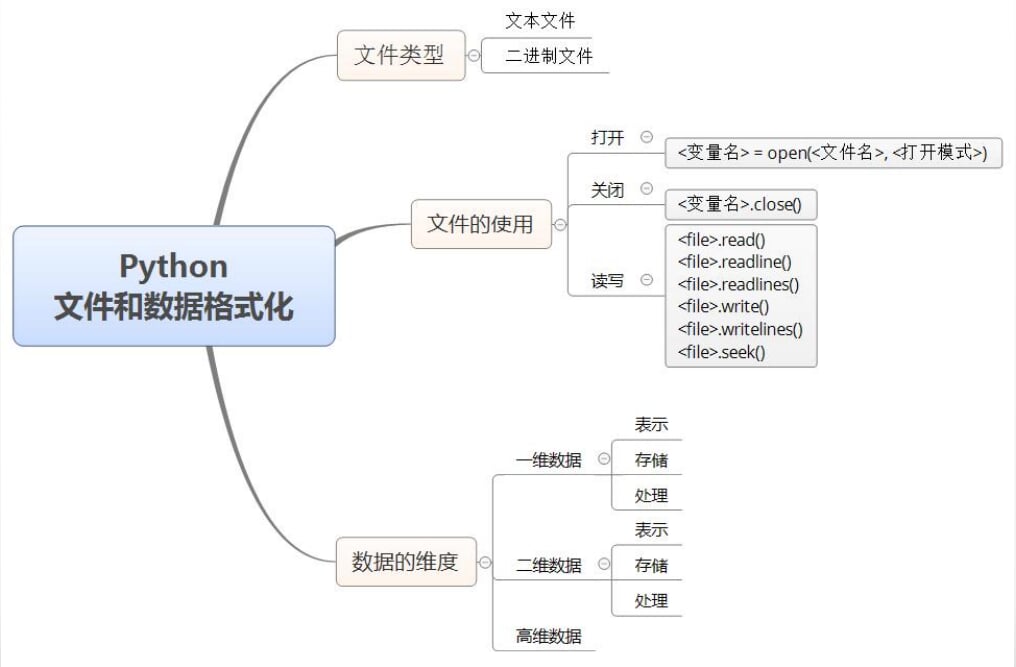
7.文件和数据格式化
-
思维导图
7.1文件类型
| 类型 | 含义 |
|---|---|
| 文本文件 | 文本文件一般由单一特定编码的字符组成,如UTF-8编码,内容容易统一展示和阅读。 |
| 二进制 | 二进制文件直接由比特0和比特1组成,文件内部数据的组织格式与文件用途有关。二进制是信息按照非字符但特定格式形成的文件,如,png格式的图片文件、avi格式的视频文件。 |
二进制文件和文本文件最主要的区别在于是否有统一的字符编码。
Python对文本文件和二进制文件采用统一的操作步骤,即“
打开-操作-关闭
”
7.2文件的使用
7.2.1文件的打开
Python通过open()函数打开一个文件,并返回一个操作这个文件的变量,语法形式如下:
<变量名> = open(<文件路径及文件名>, <打开模式>)
| 打开模式 | 含义 |
|---|---|
| ‘r’ | 只读模式,如果文件不存在,返回异常FileNotFoundError,默认值 |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖源文件 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回异FileExistsError ‘a’ |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与r/w/x/a一同使用,在原功能基础上增加同时读写功能 |
7.2.2文件的关闭
<变量名>.close()
7.2.3文件的读
| 方法 | 含义 |
|---|---|
| f.read(size=-1) | 从文件中读入整个文件内容。参数可选,如果给出,读入前size长度的字符串或字节流 |
| f.readline(size = -1) | 从文件中读入一行内容。参数可选,如果给出,读入该行前size长度的字符串或字节流 |
| f.readlines(hint=-1) | 从文件中读入所有行,以每行为元素形成一个列表。参数可选,如果给出,读入hint行 |
| f.seek(offset) | 改变当前文件操作指针的位置,offset的值:0:文件开头; 2: 文件结尾 |
f = open(<文件路径及名称>,“r”)
for line in f:
# 处理一行数据
f.close()
f = open("D://b.txt", "r")
for line in f:
print(line)
f.close()
>>
新年都未有芳华,二月初惊见草芽。
白雪却嫌春色晚,故穿庭树作飞花。
7.2.4文件的写
| 方法 | 含义 |
|---|---|
| f.write(s) | 向文件写入一个字符串或字节流 |
| f.writelines(lines) | 将一个元素为字符串的列表写入文件 |
f.write(s)
向文件写入字符串s,每次写入后,将会记录一个写入指针。该方法可以反复调用,将在写入指针后分批写入内容,直至文件被关闭。
>>>f = open("D://c.txt", "w")
>>>f.write('新年都未有芳华\n')
>>>f.write('二月初惊见草芽\n')
>>>f.write('白雪却嫌春色晚\n')
>>>f.write('故穿庭树作飞花\n')
>>>f.close()
>>
新年都未有芳华
二月初惊见草芽
白雪却嫌春色晚
故穿庭树作飞花
f.writelines(lines)
直接将列表类型的各元素连接起来写入文件f。
>>>ls = ['新年都未有芳华\n','二月初惊见草芽\n','白雪却嫌春色晚\n','故穿庭树作飞花\n']
>>>f = open("D://c.txt", "w")
>>>f.writelines(ls)
>>>f.close()
7.3数据的维度
一维数据由对等关系的有序或无序数据构成,采用线性方式组织,对应于数学中数组的概念。
- 一维数据
北京、上海、天津、重庆
二维数据,也称表格数据,由关联关系数据构成,采用二维表格方式组织,对应于数学中的矩阵,常见的表格都属于二维数据。
高维数据由键值对类型的数据构成,采用对象方式组织,可以多层嵌套。
-
二维数据
-
高维数据
一维数据的存储
| 采用空格分隔元素 |
例如: 北京 上海 天津 重庆 |
| 采用逗号分隔元素 |
例如: 北京,上海,天津,重庆 |
| 采用换行分隔包括 |
例如: 北京 上海 天津 重庆 |
| 其他特殊符号分隔,以分号分隔为例 |
例如: 北京;上海;天津;重庆 |
7.4实例解析:国家财政数据趋势演算
8.Python计算生态
-
思维导图

8.1计算思维
人类在认识世界、改造世界过程中表现出
三种基本的思维特征
:以实验和验证为特征的
实证思维
,以物理学科为代表;以推理和演绎为特征的
逻辑思维
,以数学学科为代表;以设计和构造为特征的
计算思维
,以计算机学科为代表。
计算思维的本质是
抽象
(Abstraction)和
自动化
(Automation)
8.2程序设计方法
| 方法 | 解释 |
|---|---|
| 自顶而下的设计 | 一个解决复杂问题行之有效的方法,基本思想是以一个总问题开始,试图把它表达为很多小问题组成的解决方案。再用同样的技术依次攻破每个小问题,最终问题变得非常小,以至于可以很容易解决。然后只需把所有的碎片组合起来,就可以得到一个程序。 |
| 自底向上执行 | 开展测试的更好办法也是将程序分成小部分逐个测试执行中等规模程序的最好方法是从结构图最底层开始,而不是从顶部开始,然后逐步上升。或者说,先运行和测试每一个基本函数,再测试由基础函数组成的整体函数,这样有助于定位错误 |
8.3Python标准库
有一部分Python计算生态随Python安装包一起发布,用户可以随时使用,被称为Python标准库。
受限于Python安装包的设定大小,标准库数量270个左右。
8.4Python第三方库
更广泛的Python计算生态采用额外安装方式服务用户,被称为Python第三方库。这些第三方库由全球各行业专家、工程师和爱好者开发,没有顶层设计,由开发者采用“尽力而为”的方式维护。Python通过新一代安装工具pip管理大部分Python第三方库的安装。
8.5基本的Python内置函数
Python解释器提供了68个内置函数(下面介绍32个)
| 函数名称 | 函数说明 |
|---|---|
| abs(x) |
x的绝对值 如果x是复数,返回复数的模 |
| all(x) | 组合类型变量x中所有元素都为真时返回True,否则返回False;若x为空,返回True |
| any(x) | 组合类型变量x中任一元素都为真时返回True,否则返回False;若x为空,返回False |
| bin(x) | 将整数x转换为等值的二进制字符串 |
| bin(1010) | 的结果是’0b1111110010’ |
| bool(x) |
将x转换为Boolean类型,即True或False bool(‘’) 的结果是False |
| chr(i) |
返回Unicode为i的字符 chr(9996)的结果是’✌ ’ |
| complex(r,i) |
创建一个复数 r + i*1j,其中i可以省略 complex(10,10)的结果是10+10j |
| dict() |
创建字典类型 dict()的结果是一个空字典{} |
| divmod(a,b) |
返回a和b的商及余数 divmod(10,3)结果是一个(3,1) |
| eval(s) |
计算字符串s作为Python表达式的值 eval(‘1+99’)的结果是100 |
| exec(s) |
计算字符串s作为Python语句的值 exec(‘a = 1+999’)运行后,变量a的值为1000 |
| float(x) |
将x转换成浮点数 float(1010)的结果是1010.0 |
| hex(x) |
将整数转换为16进制字符串 hex(1010)的结果是’0x3f2’ |
| input(s) |
获取用户输入,其中s是字符串,作为提示信息 s可选 |
| int(x) |
将x转换成整数 int(9.9)的结果是9 |
| list(x) |
创建或将变量x转换成一个列表类型 list({10,9,8})的结果是[8,9,10] |
| max(a1,a2,…) |
返回参数的最大值 max(1,2,3,4,5)的结果是5 |
| min(a1,a2,…) |
返回参数的最小值 min(1,2,3,4,5)的结果是1 |
| oct(x) |
将整数x转换成等值的八进制字符串形式 oct(1010)的结果是’0o1762’ |
| open(fname, m) |
打开文件,包括文本方式和二进制方式等 其中,m部分可以省略,默认是以文本可读形式打开 |
| ord© |
返回一个字符的Unicode编码值 ord(‘字’)的结果是23383 |
| pow(x,y) |
返回x的y次幂 pow(2,pow(2,2))的结果是16 |
| print(x) |
打印变量或字符串x print()的end参数用来表示输出的结尾字符 |
| range(a,b,s) |
从a到b(不含)以s为步长产生一个序列 list(range(1,10,3))的结果是[1, 4, 7] |
| reversed® |
返回组合类型r的逆序迭代形式 for i in reversed([1,2,3])将逆序遍历列表 |
| round(n) |
四舍五入方式计算n round(10.6)的结果是11 |
| set(x) |
将组合数据类型x转换成集合类型 set([1,1,1,1])的结果是{1} |
| sorted(x) |
对组合数据类型x进行排序,默认从小到大 sorted([1,3,5,2,4])的结果是[1,2,3,4,5] |
| str(x) |
将x转换为等值的字符串类型 str(0x1010)的结果是’4112’ |
| sum(x) |
对组合数据类型x计算求和结果 sum([1,3,5,2,4])的结果是15 |
| type(x) |
返回变量x的数据类型 type({1:2})的结果是<class ‘dict’> |
8.5实例解析:Web页面元素提取
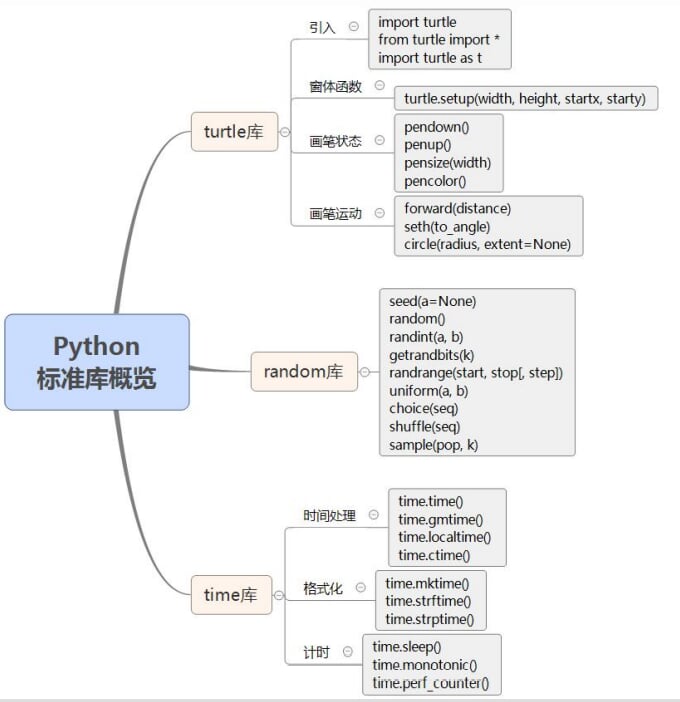
9.Python标准库概览
-
思维导图
考纲考点
标准库: turtle库(必选)
标准库: random库(必选)、time库(可选)
9.1 turtle库
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制。
9.1.1 对turtle库的引用
使用import保留字对turtle库的引用有如下三种方式:
| 方式 | 调用 | 示例 |
|---|---|---|
| import turtle | turtle.<函数名>()形式 |
|
| from turtle import * | <函数名>() |
|
| import turtle as t | t.<函数名>() |
|
turtle库包含100多个功能函数,主要包括窗体函数、画笔状态函数、画笔运动函数等三类。
9.1.2 窗体函数
turtle.setup(width, height, startx, star)
作用:设置主窗体的大小和位置
| 参数 | 作用 |
|---|---|
| width |
窗口宽度 如果值是整数,表示的像素值;如果值是小数,表示窗口宽度与屏幕的比例; |
| height |
窗口高度 如果值是整数,表示的像素值;如果值是小数,表示窗口高度与屏幕的比例; |
| startx |
窗口左侧与屏幕左侧的像素距离 如果值是None,窗口位于屏幕水平中央; |
| starty |
窗口顶部与屏幕顶部的像素距离 如果值是None,窗口位于屏幕垂直中央; |
9.1.3 画笔状态函数
| 函数 | 描述 | 参数 |
|---|---|---|
|
pendown() pd() down() |
放下画笔 | |
| penup() | 提起画笔,与pendown()配对使用 | turtle.pu(), turtle.up() |
|
pensize(width) width() |
设置画笔线条的粗细为指定大小 | width :设置的画笔线条宽度,如果为None或者为空,函数则返回当前画笔宽度。 |
|
color() pencolor((r,g,b)) |
设置画笔的颜色 |
colorstring :表示颜色的字符串,例如:“purple”、“red”、”blue”等 (r,g,b): 颜色对应RGB的01数值,例如:1, 0.65, 0 |
| begin_fill() | 填充图形前,调用该方法 | |
| end_fill() | 填充图形结束 | |
| filling() | 返回填充的状态,True为填充,False为未填充 | |
| clear() | 清空当前窗口,但不改变当前画笔的位置 | |
| reset() | 清空当前窗口,并重置位置等状态为默认值 | |
| screensize() | 设置画布的长和宽 | |
| hideturtle() | 隐藏画笔的turtle形状 | |
| showturtle() | 显示画笔的turtle形状 | |
| isvisible() | 如果turtle可见,则返回True |
9.1.4 画笔运动函数
| 函数 | 描述 | 参数 |
|---|---|---|
|
forward() fd() |
沿着当前方向前进指定距离 | distance :行进距离的像素值,当值为负数时,表示向相反方向前进。 |
| backward() | 沿着当前相反方向后退指定距离 | |
| right(angle) | 向右旋转angle角度 | |
| left(angle) | 向左旋转angle角度 | |
| goto(x,y) | 移动到绝对坐标(x,y)处 | |
| setx( ) | 将当前x轴移动到指定位置 | |
| sety( ) | 将当前y轴移动到指定位置 | |
|
setheading(angle) seth() |
设置当前朝向为angle角度 | to_angle :角度的整数值。 |
| home() | 设置当前画笔位置为原点,朝向东。 | |
| circle(radius,e) | 绘制一个指定半径r和角度e的圆或弧形 |
radius :弧形半径,当值为正数时,半径在小海龟左侧,当值为负数时,半径在小海龟右侧; extent : 绘制弧形的角度,当不给该参数或参数为None时,绘制整个圆形。 |
| dot(r,color) | 绘制一个指定半径r和颜色color的圆点 | |
| undo() | 撤销画笔最后一步动作 | |
| speed() | 设置画笔的绘制速度,参数为0-10之 |
9.2 random库
使用random库主要目的是
生成随机数
9.2.1 random库的常用函数
| 函数 | 描述 |
|---|---|
| seed(a=None) | 初始化随机数种子,默认值为当前系统时间 |
| random() | 生成一个[0.0, 1.0)之间的随机小数 |
| randint(a, b) | 生成一个[a,b]之间的整数 |
| getrandbits(k) | 生成一个k比特长度的随机整数 |
| randrange(start, stop[, step]) | 生成一个[start, stop)之间以step为步数的随机整数 |
| uniform(a, b) | 生成一个[a, b]之间的随机小数 |
| choice(seq) | 从序列类型(例如:列表)中随机返回一个元素 |
| shuffle(seq) | 将序列类型中元素随机排列,返回打乱后的序列 |
| sample(pop, k) | 从pop类型中随机选取k个元素,以列表类型返回 |
9.3 time库
9.3.1time库概述
处理时间是程序最常用的功能之一,time库是Python提供的处理时间标准库。time库提供系统级精确计时器的计时功能,可以用来分析程序性能也可让程序暂停运行时间。
time库的功能主要分为3个方面:
时间处理
、
时间格式化
和
计时
。
9.3.2 时间处理函数
| 函数 | 说明 |
|---|---|
| time.time( ) | 获取当前时间戳 |
| time.gmtime() | 获取当前时间戳对应的struct_time对象 |
| time.localtime() | 获取当前时间戳对应的本地时间的struct_time对象 |
| time.ctime() | 获取当前时间戳对应的易读字符串表示,内部会调用time.localtime()函数以输出当地时间。 |
9.3.3 时间格式化函数
| 函数 | 说明 |
|---|---|
| time.mktime() | 将struct_time对象t转换为时间戳,注意t代表当地时间。 |
| time.strftime() | 时间格式化最有效的方法,几乎可以以任何通用格式输出时间。该方法利用一个格式字符串,对时间格式进行表达。 |
| time.strptime() | 法与strftime()方法完全相反,用于提取字符串中时间来生成strut_time对象,可以很灵活的作为time模块的输入接口 |
-
使用
time.mktime(t)
将struct_time对象t转换为时间戳,注意t表当地时间。struct_time对象的元素如下
| 下标 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 年份,整数 |
| 1 | tm_mon | 月份[1, 12] |
| 2 | tm_mday | 日期[1, 31] |
| 3 | tm_hour | 小时[0, 23] |
| 4 | tm_min | 分钟[0, 59] |
| 5 | tm_sec | 秒[0, 61] |
| 6 | tm_wday | 星期[0, 6](0表示星期一) |
| 7 | tm_yday | 该年第几天[1, 366] |
| 8 | tm_isdst | 是否夏时令,0否, 1是, -1未 |
- **strftime()**方法的格式化控制符
| 格式化字符串 | 日期/时间 | 值范围和实例 |
|---|---|---|
| %Y | 年份 | 0001~9999,例如:1900 |
| %m | 月份 | 01~12,例如:10 |
| %B | 月名 | January~December,例如:April |
| %b | 月名缩写 | Jan~Dec,例如:Apr |
| %d | 日期 | 01 ~ 31,例如:25 |
| %A | 星期 | Monday~Sunday,例如:Wednesday |
| %a | 星期缩写 | Mon~Sun,例如:Wed |
| %H | 小时(24h制) | 00 ~ 23,例如:12 |
| %I | 小时(12h制) | 01 ~ 12,例如:7 |
| %p | 上/下午 | AM, PM,例如:PM |
| %M | 分钟 | 00 ~ 59,例如:26 |
| %S | 秒 | 00 ~ 59,例如:26 |
9.3.4 计时
程序计时是非常常用的功能,尤其是对于运行时间较长的程序,往往需要先进行小规模(短时间)的实验,并根据实验结果预估最终程序的大致运行时间。
程序计时主要要包含三个要素:程序开始/结束时间、程序运行总时间、程序各核心模块运行时间。
time模块里的计时函数:
| 函数 | 说明 |
|---|---|
| time.sleep( ) | |
| time.monotonic() | |
| time.perf_counter() |
以1千万次循环为主体,模拟实际程序的核心模块,用time.sleep()来模拟实际程序的其他模块。
import time
def coreLoop():
limit = 10**8
while (limit > 0):
limit -= 1
def otherLoop1():
time.sleep(0.2)
def otherLoop2():
time.sleep(0.4)
def main():
startTime = time.localtime()
print('程序开始时间:', time.strftime('%Y-%m-%d %H:%M:%S', startTime))
startPerfCounter = time.perf_counter()
otherLoop1()
otherLoop1PerfCounter = time.perf_counter()
otherLoop1Perf = otherLoop1PerfCounter - startPerfCounter
coreLoop()
coreLoopPerfCounter = time.perf_counter()
coreLoopPerf = coreLoopPerfCounter - otherLoop1PerfCounter
otherLoop2()
otherLoop2PerfCounter = time.perf_counter()
otherLoop2Perf = otherLoop2PerfCounter - coreLoopPerfCounter
endPerfCounter = time.perf_counter()
totalPerf = endPerfCounter - startPerfCounter
endTime = time.localtime()
print("模块1运行时间是:{}秒".format(otherLoop1Perf))
print("核心模块运行时间是:{}秒".format(coreLoopPerf))
print("模块2运行时间是:{}秒".format(otherLoop2Perf))
print("程序运行总时间是:{}秒".format(totalPerf))
print('程序结束时间:', time.strftime('%Y-%m-%d %H:%M:%S', endTime))
main()
程序运行的输出效果如下
程序开始时间: 2017-12-26 13:46:39
模块1运行时间是:0.20003105182731706秒
核心模块运行时间是:5.987101639820927秒
模块2运行时间是:0.40018931343066555秒
程序运行总时间是:6.587323585324574秒
程序结束时间: 2017-12-26 13:46:4
9.4 实例解析:雪景艺术绘图
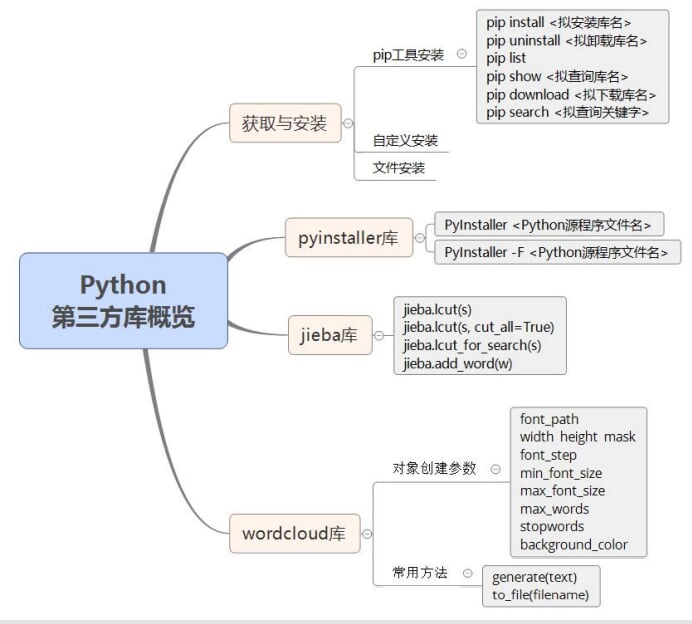
10.Python第三方库概览
-
思维导图
考纲考点
第三方库的获取和安装
脚本程序转变为可执行程序的第三方库:PyInstaller库(必选)
第三方库: jieba库(必选)、wordcloud库(可选)
10.1 Python第三方库的获取与安装
Python第三方库依照安装方式灵活性和难易程度有三个方法:
pip工具安装
、
自定义安装
和
文件安装
。
10.1.1 pip工具安装
最常用且最高效的Python第三方库安装方式是采用pip工具安装。pip是Python官方提供并维护的在线第三方库安装工具。
pip install<拟安装库名称>
:\>pip install pygame
...
Installing collected packages: pygame
Successfully installed pygame-1.9.2b1
pip常用指令,可以通过
pip help
查看:
C:\Users\86159>pip -h
Usage:
pip <command> [options]
Commands:
install Install packages.
download Download packages.
uninstall Uninstall packages.
freeze Output installed packages in requirements format.
list List installed packages.
show Show information about installed packages.
check Verify installed packages have compatible dependencies.
config Manage local and global configuration.
search Search PyPI for packages.
cache Inspect and manage pip's wheel cache.
wheel Build wheels from your requirements.
hash Compute hashes of package archives.
completion A helper command used for command completion.
debug Show information useful for debugging.
help Show help for commands.
10.1.2 自定义安装
自定义安装指按照第三方库提供的步骤和方式安装。第三方库都有主页用于维护库的代码和文档。以科学计算用的numpy为例,开发者维护的官方主页是:http://www.numpy.org/
浏览该网页找到下载链接,如下:https://www.scipy.org/scipylib/download.html
进入根据指示步骤安装。
10.1.3 文件安装
为了解决这类第三方库安装问题,美国加州大学尔湾分校提供了一个页面,帮助Python用户获得Windows可直接安装的第三方库文件,链接地址如下:https://www.lfd.uci.edu/~gohlke/pythonlibs/
这里以scipy为例说明,首先在上述页面中找到scipy库对应的内容。选择其中的.whl文件下载,这里选择适用于Python 3.5版本解释器和32位系统的对应文件:scipy- 0 . 1 7 . 1 – cp3 5 – cp3 5m-win3 2 .whl,下载该文件到D:\pycodes目录。
然后,采用pip命令安装该文件。
:\>pip install D:\pycodes\scipy-0.17.1-cp35-cp35m-win32.whl
Processing d:\pycodes\scipy-0.17.1-cp35-cp35m-win32.whl
Installing collected packages: scipy
Successfully installed scipy-0.17.1
对于上述三种安装方式,一般优先选择采用pip工具安装,如果安装失败,则选择自定义安装或者文件安装。另外,如果需要在没有网络条件下安装Python第三方库,请直接采用文件安装方式。其中,.whl文件可以通过pip download指令在有网络条件的情况下获得。
10.2 pyinstaller库
10.2.1 pyinstaller库概述
PyInstaller是一个十分有用的Python第三方库,它能够在Windows、Linux、Mac OS X等操作系统下将Python源文件打包,变成直接可运行的可执行文件。
通过对源文件打包,Python程序可以在没有安装Python的环境中运行,也可以作为一个独立文件方便传递和管理。
:\>pip install PyInstaller
10.2.2 PyInstaller库与程序打包
使用PyInstaller库对Python源文件打包十分简单,使用方法如下:
:\>PyInstaller <Python源程序文件名>
执行完毕后,源文件所在目录将生成dist和build两个文件夹。最终的打包程序在dist内部与源文件同名的目录中。
可以通过-F参数对Python源文件生成一个独立的可执行文件,如下:
:\>PyInstaller -F SnowView.py
执行后在dist目录中出现了SnowView.exe文件,没有任何依赖库,执行它即可显示雪景效果。
| 参数 | 功能 |
|---|---|
| -h, –help | 查看帮助 |
| –clean | 清理打包过程中的临时文件 |
| -D, –onedir | 默认值,生成dist目录 |
| -F, –onefile | 在dist文件夹中只生成独立的打包文件 |
| -i <图标文件名.ico > | 指定打包程序使用的图标(icon)文件 |
10.3 jieba库
10.3.1 jieba库概述
jieba(“结巴”)是Python中一个重要的第三方中文分词函数库。
jieba库安装:
:\>pip install jieba
jieba库支持三种分词模式:
精确模式
,将句子最精确地切开,适合文本分析;
全模式
,把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
搜索引擎模式
,在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
对中文分词来说,jieba库只需要一行代码即可。
>>>import jieba
>>>jieba.lcut("全国计算机等级考试")
Building prefix dict from the default dictionary ...
Loading model from cache C:\AppData\Local\Temp\jieba.cache
Loading model cost 1.001 seconds.
Prefix dict has been built succesfully.
['全国','计算机','等级','考试']
10.3.2 jieba库与中文分词
| 模式 | 功能 |
|---|---|
| jieba.lcut(s) | 最常用的中文分词函数,用于精准模式,即将字符串分割成等量的中文词组,返回结果是列表类型 |
| jieba.lcut(s, cut_all = True) | 用于全模式,即将字符串的所有分词可能均列出来,返回结果是列表类型,冗余性最大 |
| jieba.lcut_for_search(s) | 返回搜索引擎模式,该模式首先执行精确模式,然后再对其中长词进一步切分获得最终结果 |
| jieba.add_word() | 顾名思义,用来向jieba词库增加新的单词。 |
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国','计算机','等级','考试','Python','科目']
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目", cut_all=True)
>>>print(ls)
['全国','国计','计算','计算机','算机','等级','考试','Python','科目']
>>>import jieba
>>>ls = jieba.lcut_for_search("全国计算机等级考试Python科目")
>>>print(ls)
['全国','计算','算机','计算机','等级','考试','Python','科目']
>>>import jieba
>>>jieba.add_word("Python科目")
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国','计算机','等级','考试','Python科目']
10.4 worldcloud库
10.4.1 worldcloud库概述
wordcloud库是专门用于根据文本生成词云的Python第三方库,十分常用且有趣。
装wordcloud库在Windows的cmd命令行使用如下命令:
:\>pip install wordcloud
wordcloud库的使用十分简单,以一个字符串为例。其中,产生词云只需要一行语句,在第三行,并可以将词云保存为图片。
>>>from wordcloud import WordCloud
>>>txt='I like python. I am learning python'
>>>wordcloud = WordCloud().generate(txt)
>>>wordcloud.to_file('testcloud.png')
<wordcloud.wordcloud.WordCloud object at 0x000001583E26D208>
10.4.2 worldcloud库与可视化词云
在生成词云时,wordcloud默认会以空格或标点为分隔符对目标文本进行分词处理。对于中文文本,分词处理需要由用户来完成。
一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数。
import jieba
from wordcloud import WordCloud
txt = '程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按
照特定规则组织计算机指令,使计算机能够自动进行各种运算处理。'
words = jieba.lcut(txt) # 精确分词
newtxt = ' '.join(words) # 空格拼接
wordcloud = WordCloud(font_path="msyh.ttc").generate(newtxt)
wordcloud.to_file('词云中文例子图.png') # 保存图片
wordcloud库的核心是WordColoud类,所有的功能都封装在WordCloud类中。使用时需要实
例化一个WordColoud类的对象,并调用其generate(text)方法将text文本转化为词云。
WordCloud对象创建的常用参数:
| 参数 | 功能 |
|---|---|
| font_path | 指定字体文件的完整路径,默认None |
| width | 生成图片宽度,默认400像素 |
| height | 生成图片高度,默认200像素 |
| mask | 词云形状,默认None,即,方形图 |
| min_font_size | 词云中最小的字体字号,默认4号 |
| font_step | 字号步进间隔,默认1 |
| min_font_size | 词云中最大的字体字号,默认None,根据高度自动调节 |
| max_words | 词云图中最大词数,默认200 |
| stopwords | 被排除词列表,排除词不在词云中显示 |
| background_color | 图片背景颜色,默认黑色 |
WordCloud类的常用方法:
| 方法 | 功能 |
|---|---|
| generate(text) | 由text文本生成词云 |
| to_file(filename) | 将词云图保存为名为filename的文件 |
10.5 实例解析:《红楼梦》人物出场词
11.Python第三方库纵览
-
思维导图
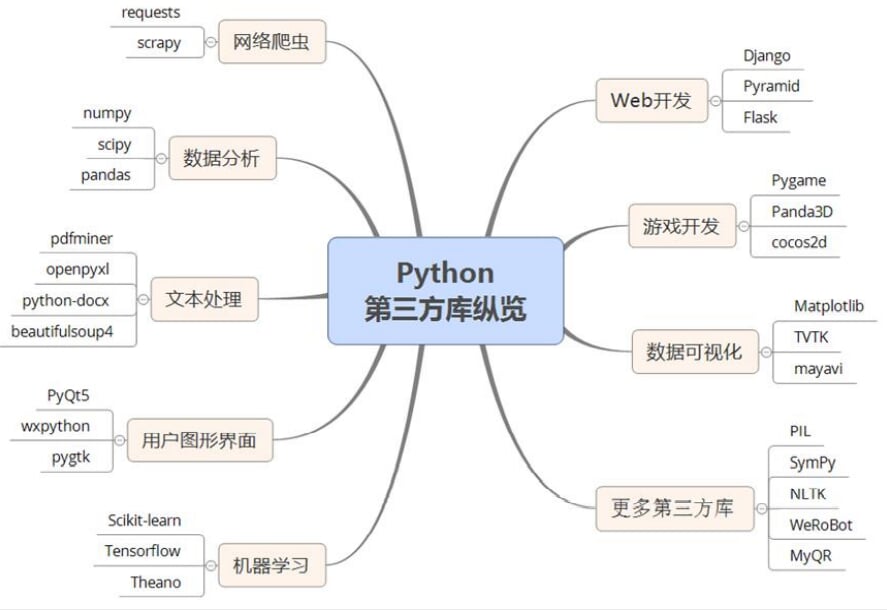
考纲考点
更广泛的Python计算生态,只要求了解第三方库的名称,不限于以下领域: 网络爬虫、数据分析、文本处理、数据可视化、用户图形界面、机器学习、Web开发、游戏开发等
| 方向 | 第三方库 | 介绍 |
|---|---|---|
| 网络爬虫方向 |
requests scrapy |
requests库是一个简洁且简单的处理HTTP请求的第三方库,它的最大优点是程序编写过程更接近正常URL访问过程。 scrapy是Python开发的一个快速的、高层次的Web获取框架。 |
| 数据分析方向 |
numpy scipy pandas |
numpy是Python的一种开源数值计算扩展第三方库,用于处理数据类型相同的多维数组(ndarray),简称“数组” scipy是一款方便、易于使用、专为科学和工程设计的Python工具包。 pandas是基于numpy扩展的一个重要第三方库,它是为了解决数据分析任务而创建的。 |
| 文本处理方向 |
pdfminer openpyxl python-docx beautifulsoup4 |
pdfminer是一个可以从PDF文档中提取各类信息的第三方库 openpyxl是一个处理Microsoft Excel文档Python第三方库 python-docx是一个处理Microsoft Word文档的Python第三方库 beautifulsoup4库,也称为Beautiful Soup库或bs4库,用于解析和处理HTML和XML |
| 数据可视化 |
matplotlib TVTK mayavi |
matplotlib是提供数据绘图功能的第三方库,主要进行二维图表数据展示,广泛用于科学计算的数据可视化 TVTK库在标准的VTK库之上用Traits库进行封装的Python第三方库 mayavi基于VTK开发,完全用Python编写,提供了一个更为方便实用的可视化软件 |
| 用户图形界面方向 |
pyqt5 wxpython pygtk |
Python语言当前最好的GUI第三方库,它可以在Windows、Linux和Mac OS X等操作系统上跨平台使用 wxPython是Python语言的一套优秀的GUI图形库,它是跨平台GUI库wxWidgets的Python封装 pygtk是基于GTK+的Python语言封装,它提供了各式的可视元素和功能,能够轻松创建具有图形用户界面的程序。 |
| 机器学习方向 |
Scikit-learn TensorFlow Theano |
Scikit-learn是一个简单且高效的数据挖掘和数据分析工具 TensorFlow是谷歌公司基于DistBelief进行研发的第二代人工智能学习系统,也是用来支撑著名的AlphaGo系统的后台框架 Theano为执行深度学习中大规模神经网络算法的运算而设计,擅长处理多维数组 |
| Web开发方向 |
Django Pyramid Flask |
Django是Python生态中最流行的开源Web应用框架 Pyramid是一个通用、开源的Python Web应用程序开发框架 Flask是轻量级Web应用框架,相比Django和Pyramid,它也被称为微框架 |
| 游戏开发方向 |
Pygame Panda3D cocos2d |
Pygame是在SDL库基础上进行封装的、面向游戏开发入门的Python第三方库,除了制作游戏外,还用于制作多媒体应用程序 Panda3D是一个开源、跨平台的3D渲染和游戏开发库,简答说,它是一个3D游戏引擎,由迪士尼和卡耐基梅隆大学娱乐技术中心共同进行开发 cocos2d是一个构建2D游戏和图形界面交互式应用的框架,它包括C++、JavaScript、Swift、Python等多个版本 |
Python语言有超过12万个第三方库,覆盖信息技术几乎所有领域。即使每个方向,也会有大量的专业人员开发多个第三方库来给出具体设计。除了本章所提到的方向外,这里再列出5个
有趣且有用
的Python第三方库,展示Python在工程实践方面强大的魅力。
| 更多第三方库 | 介绍 |
|---|---|
| PIL | PIL库是Python语言在图像处理方面的重要第三方库,支持图像存储、显示和处理,它能够处理几乎所有图片格式,可以完成对图像的缩放、剪裁、叠加以及向图像添加线条、图像和文字等操作。 |
| SymPy | SymPy是一个支持符号计算的Python第三方库,它是一个全功能的计算机代数系统。SymPy代码简洁、易于理解,支持符号计算、高精度计算、模式匹配、绘图、解方程、微积分、组合数学、离散数学、几何学、概率与统计、物理学等领域计算和应用。 |
| NLTK | NLTK是一个非常重要的自然语言处理Python第三方库,它支持多种语言,尤其对中文支持良好。NLTK可以进行语料处理、文本统计、内容理解、情感分析等多种应用,具备非常可靠的应用价值。 |
| WeRoBot | WeRoBot 是一个微信公众号开发框架,也称为的微信机器人框架。WeRoBot可以解析微信服务器发来的消息,并将消息转换成成Message或者Event类型。 |
| MyQR | MyQR是一个能够产生基本二维码、艺术二维码和动态效果二维码的Python第三方库。图11.1给出了一些MyQR生成二维码的实例。 |
-
图11.1

本章小结
本章通过8个具体方向30个Python功能库的简要介绍纵览Python语言计算生态的丰富性,希望读者能够从Python基础语法出发,看到更广阔的程序设计生态,进一步“理解和运用计算生态”,掌握符合信息时代需要的程序设计能力。
国家计算机等级考试不仅仅是一场考试,更是检验能力提升的手段,加油!