1、UIE
训练的时候,把标签信息进行了提示,预测的时候也需要提示
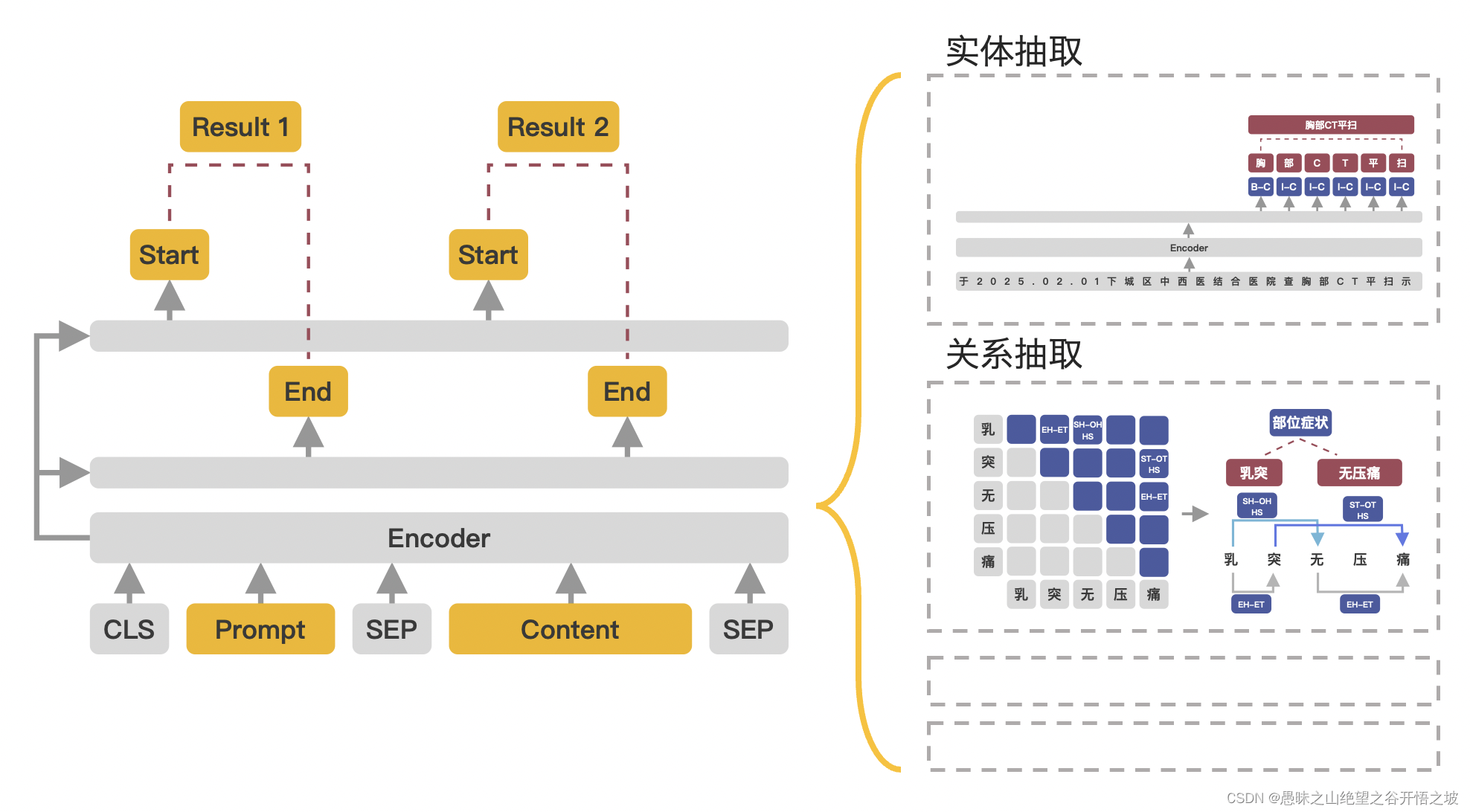
模型内部结构
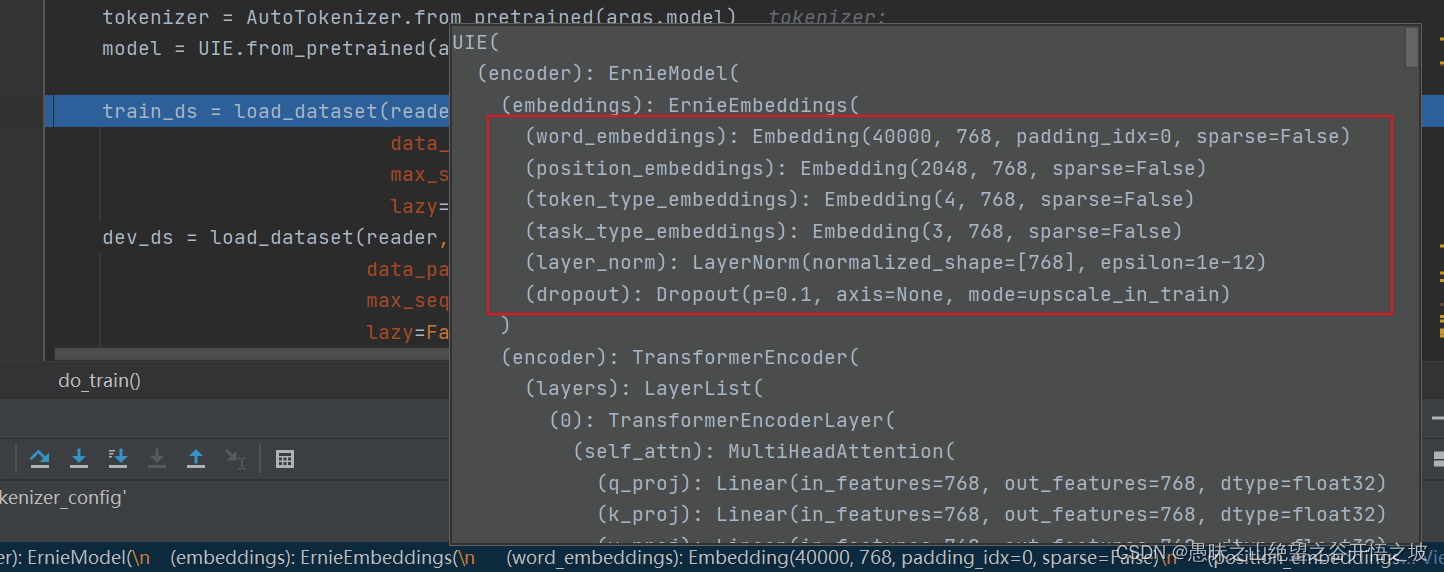
输入结构
文件定义下载链接
定义所有任务流名称
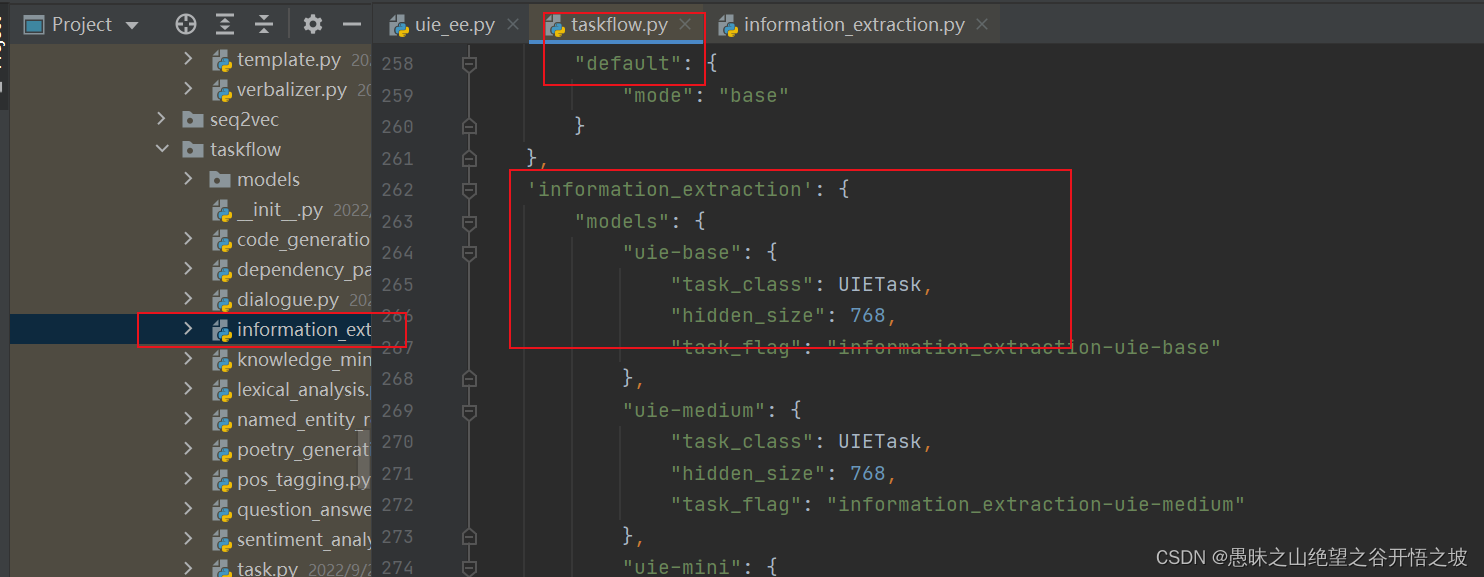
实体抽取

实体或者关系都是这个数据输入
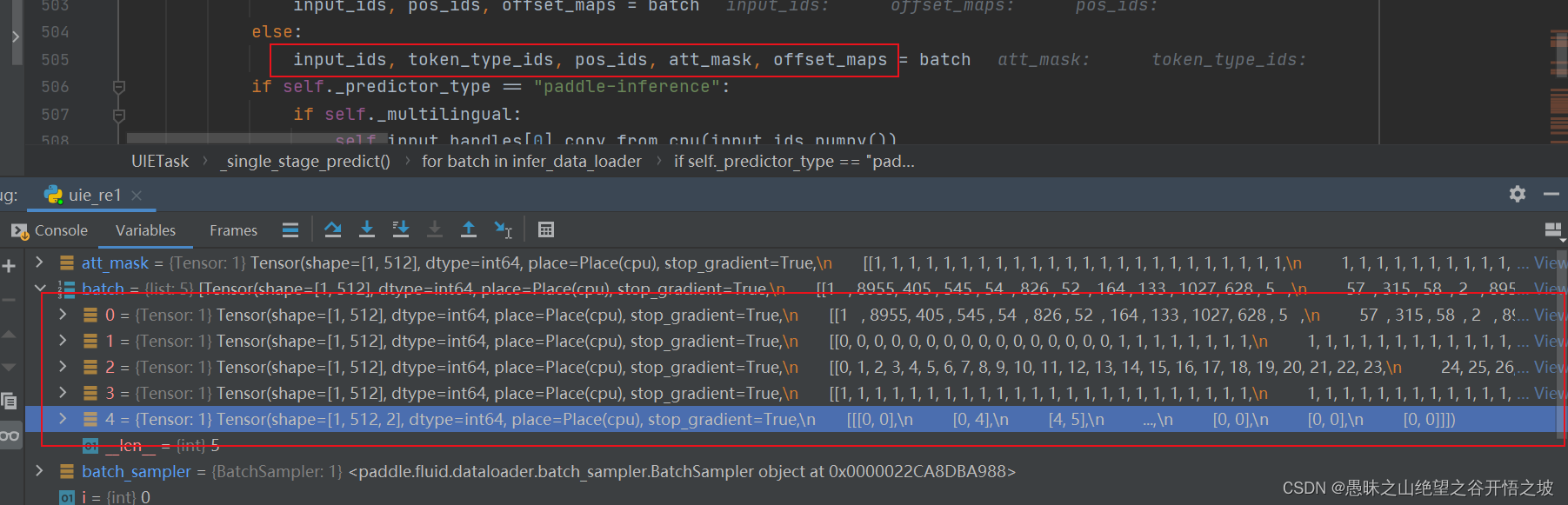
关系抽取
先以主体类型为prompt,抽取之后,再把主体和关系组合成新的prompt继续抽取
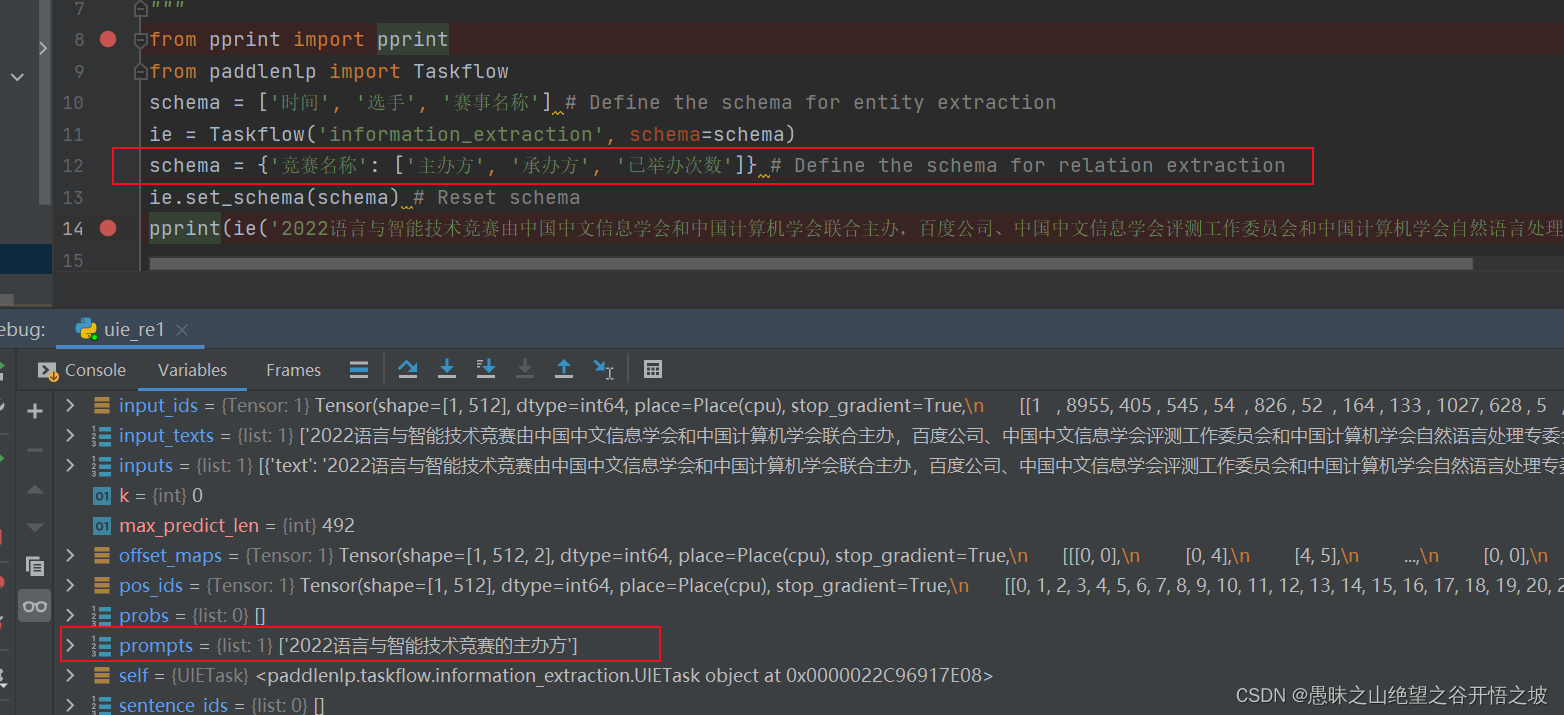
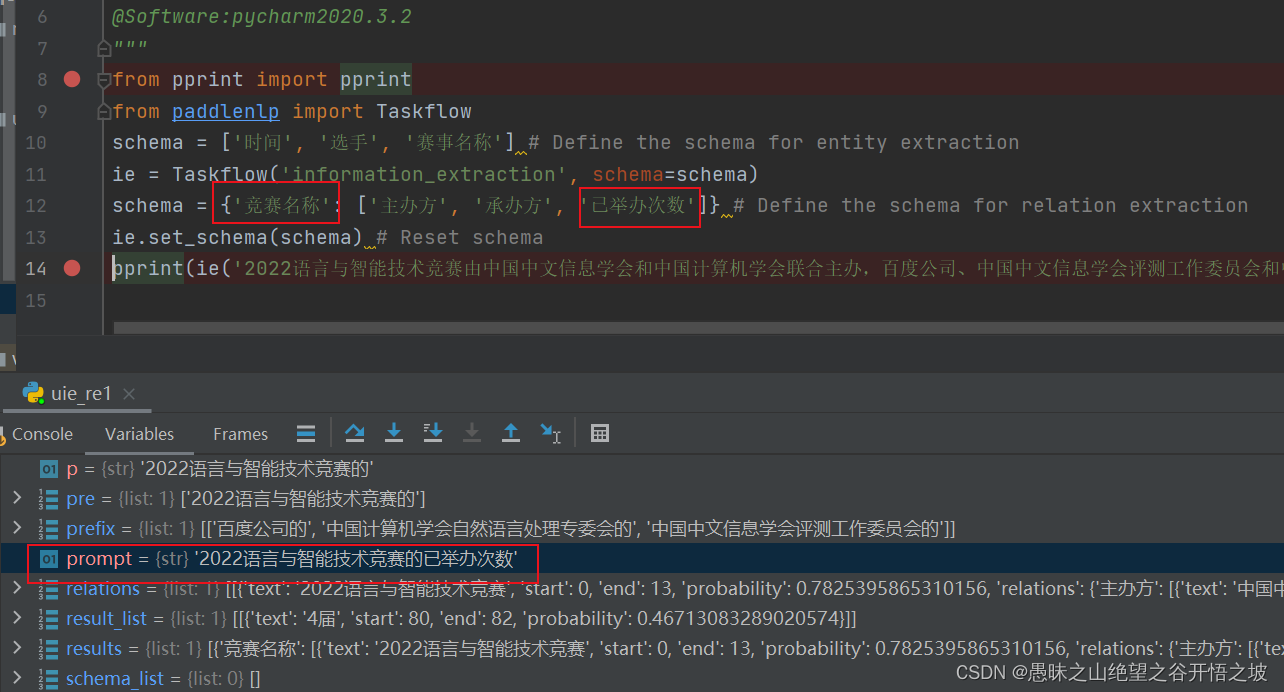
抽取的都是实体的收尾id,转换成了实体抽取
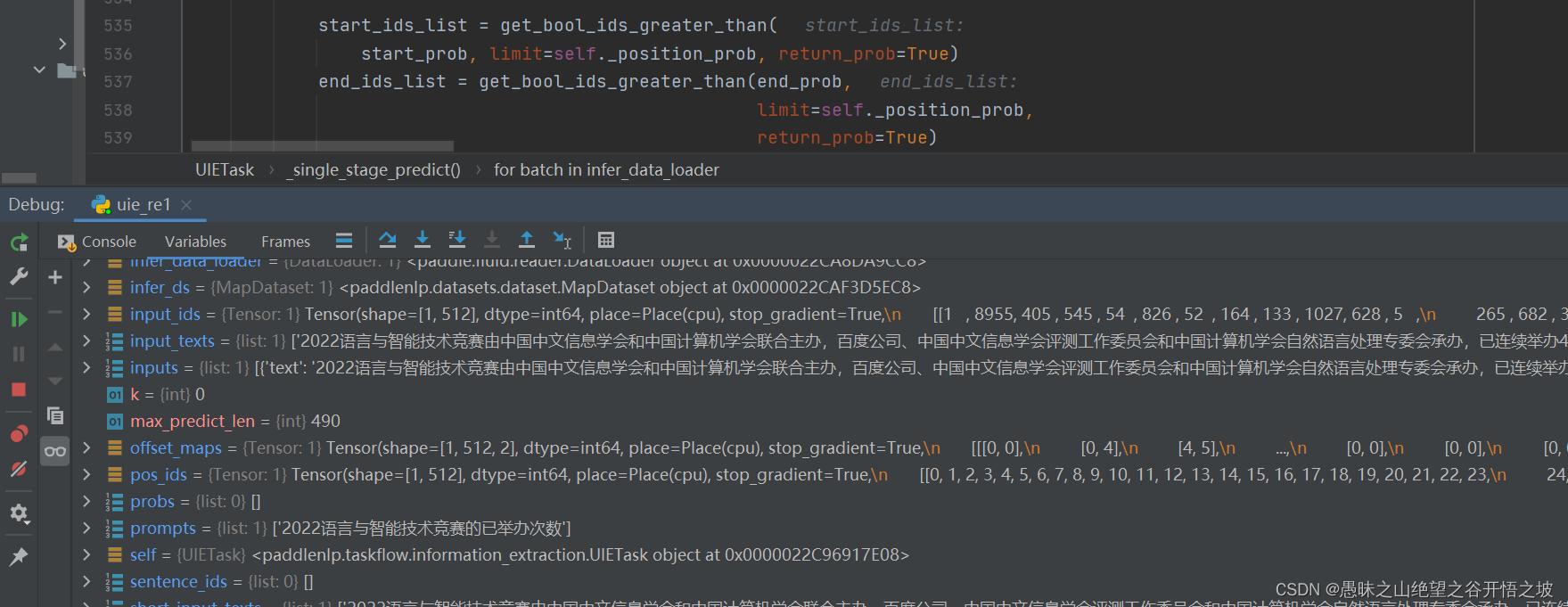
事件抽取,本质是转换为关系抽取
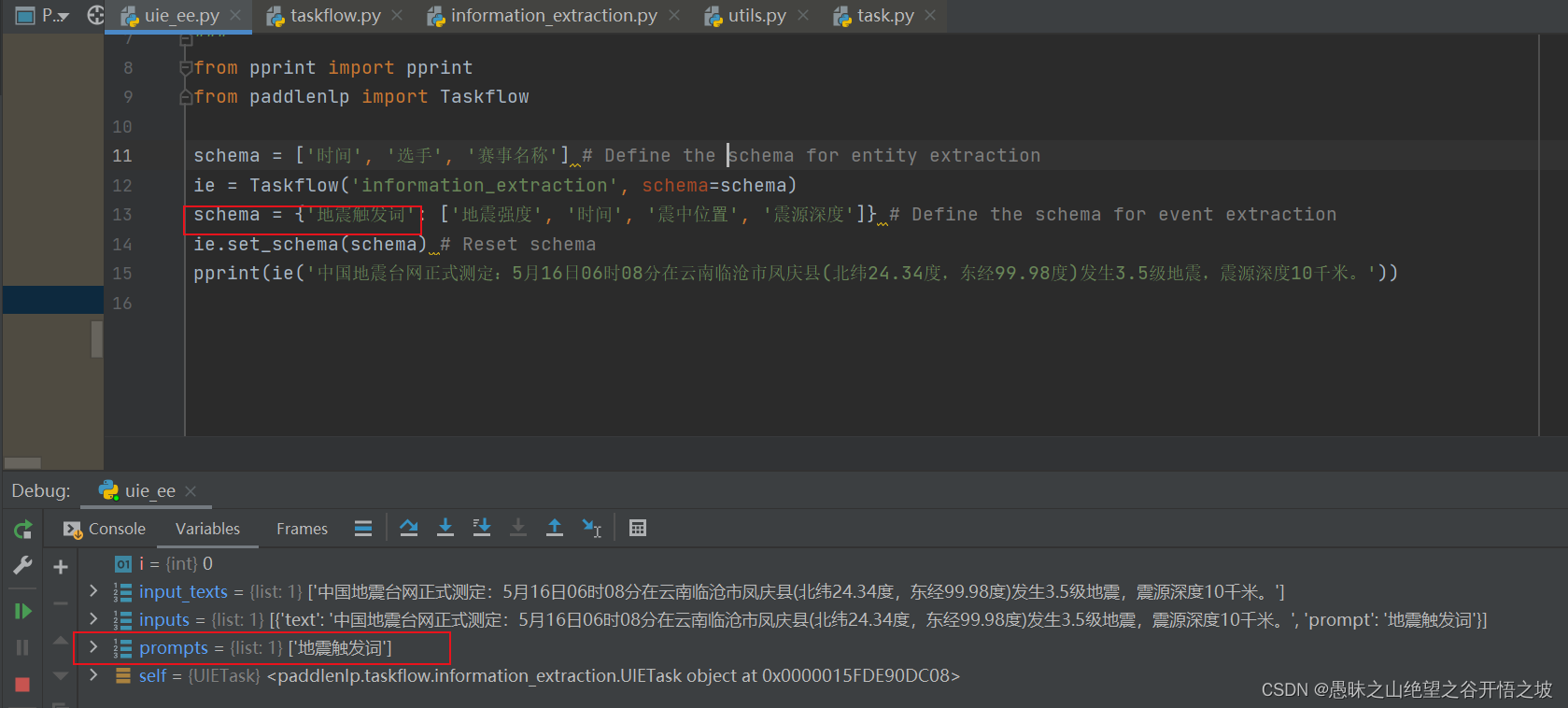
预测完触发词后,触发词和其他的属性做结合,中间加个的
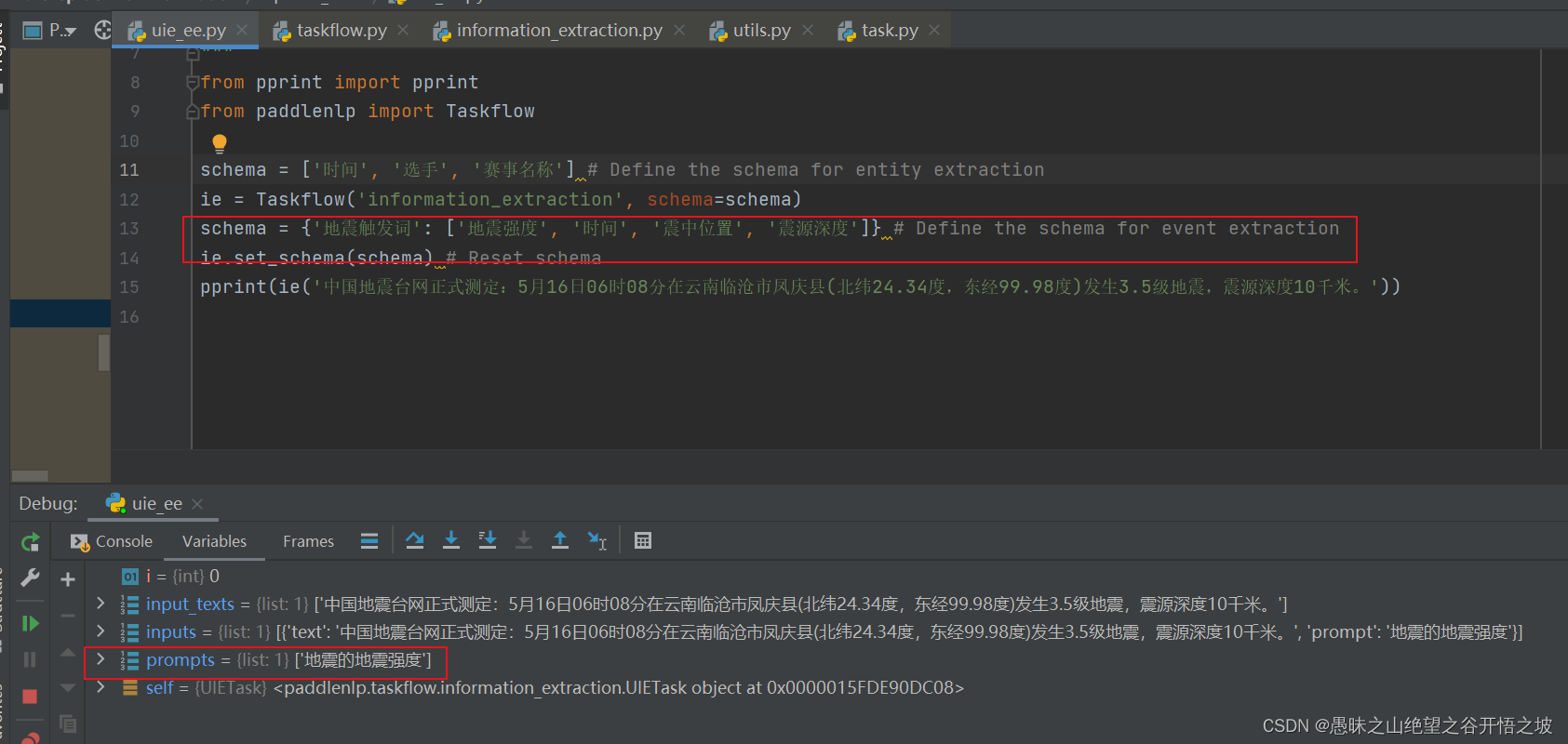
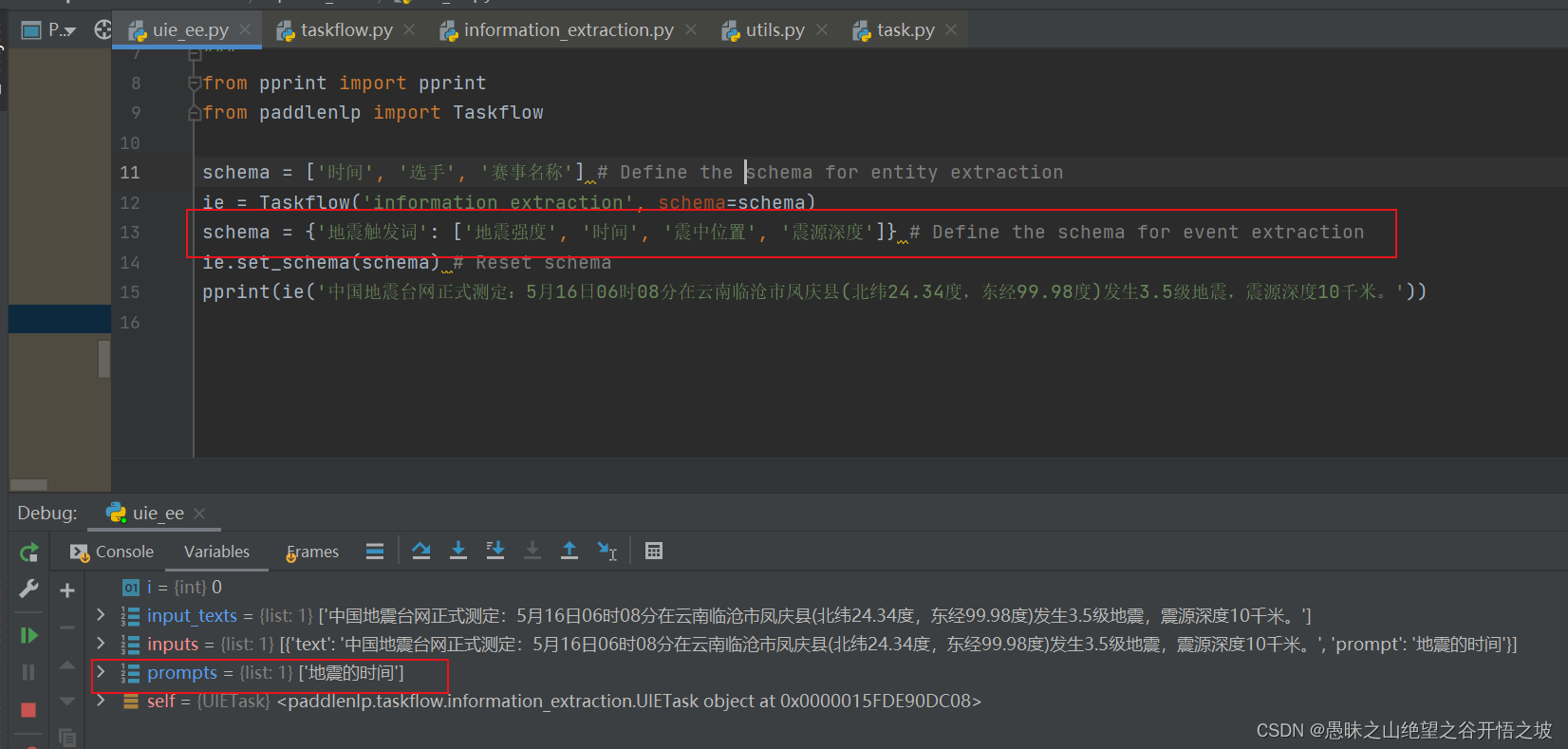
其他属性继续预测
2、数据标注平台
数据标注平台 Label Studio:
https://labelstud.io/
数据标注平台 doccano:
https://github.com/doccano/doccano
数据标注linux
python doccano.py \
--doccano_file ./data/audio-expense-account.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
数据标注win10
--doccano_file ./data/audio-expense-account.json
--task_type ext
--save_dir ./data
--splits 0.8 0.2 0
正负样本
所谓正样本,就是有实际正确结果的样本,负样本就是没有结果或者结果不对的样本

有结果的样本,包括标签都做了一一映射
按比例主动构造负样本,对比抽取出来为空的
3、UIE模型训练
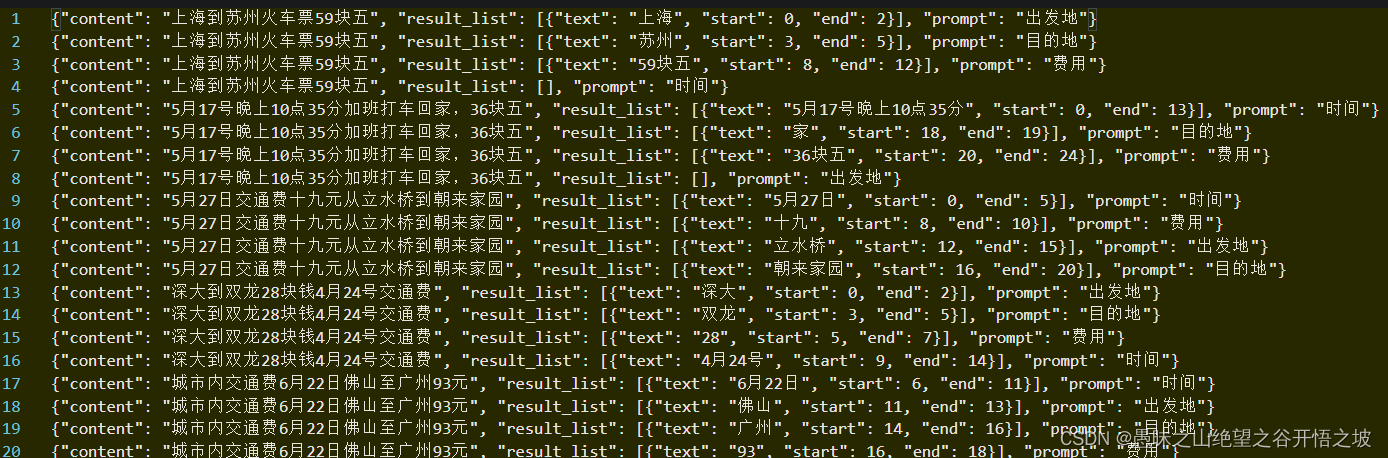
doccano标注数据格式

模型输入数据格式
通过同一个batch的不同样本的组合来形成负样本
模型输入数据,再次增强
同一个样本的,不同的关系也要做增加,关系为空的实体要体现出来,防止预测的时候数据乱串来串去
当前UIE关系抽取任务的负例构造主要是包含以下三种形式
反关系负例(如:b的B,b为A的B的抽取结果)
随机替换A负例(如:C的B,C为文本中不包含的实体)
随机替换B负例(如:A的D,D为文本中不包含的实体类型)
增加同一样本不同关系的负样本
relation_dict = {'时间': ['交通工具', '地点', '行为', '接触者']}
for subject_id in subject_id_list:
if entity_map[subject_id]["label"] in relation_dict:
for rel in relation_dict[entity_map[subject_id]["label"]]:
prompt_new = entity_map[subject_id]["name"] + "的" + rel
if prompt_new not in relation_example_map:
relation_example_map[prompt_new] = {
"content": text,
"result_list": [],
"prompt": prompt_new
}
模型输入数据,多个主体的增强
# #************************add by robert*************************
relation_dict = {'时间': ['交通工具', '地点', '行为', '接触者'], '接触者': ['电话', '身份证']}
for subject_id in subject_id_list:
if entity_map[subject_id]["label"] in relation_dict:
for rel in relation_dict[entity_map[subject_id]["label"]]:
prompt_new = entity_map[subject_id]["name"] + "的" + rel
if prompt_new not in relation_example_map:
relation_example_map[prompt_new] = {
"content": text,
"result_list": [],
"prompt": prompt_new
}
# #************************add by robert*************************
完整代码
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import re
import math
import json
import random
from tqdm import tqdm
import numpy as np
import paddle
from paddlenlp.utils.log import logger
MODEL_MAP = {
# vocab.txt/special_tokens_map.json/tokenizer_config.json are common to the default model.
"uie-base": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base_v1.0/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json"
}
},
"uie-medium": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_medium_v1.0/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_medium/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json"
}
},
"uie-mini": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_mini_v1.0/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_mini/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json"
}
},
"uie-micro": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_micro_v1.0/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_micro/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json"
}
},
"uie-nano": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_nano_v1.0/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_nano/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json"
}
},
# Rename to `uie-medium` and the name of `uie-tiny` will be deprecated in future.
"uie-tiny": {
"resource_file_urls": {
"model_state.pdparams":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_tiny_v0.1/model_state.pdparams",
"model_config.json":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_tiny/model_config.json",
"vocab_file":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_tiny/vocab.txt",
"special_tokens_map":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_tiny/special_tokens_map.json",
"tokenizer_config":
"https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_tiny/tokenizer_config.json"
}
}
}
def set_seed(seed):
paddle.seed(seed)
random.seed(seed)
np.random.seed(seed)
def create_data_loader(dataset, mode="train", batch_size=1, trans_fn=None):
"""
Create dataloader.
Args:
dataset(obj:`paddle.io.Dataset`): Dataset instance.
mode(obj:`str`, optional, defaults to obj:`train`): If mode is 'train', it will shuffle the dataset randomly.
batch_size(obj:`int`, optional, defaults to 1): The sample number of a mini-batch.
trans_fn(obj:`callable`, optional, defaults to `None`): function to convert a data sample to input ids, etc.
Returns:
dataloader(obj:`paddle.io.DataLoader`): The dataloader which generates batches.
"""
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == "train":
sampler = paddle.io.DistributedBatchSampler(dataset=dataset,
batch_size=batch_size,
shuffle=shuffle)
else:
sampler = paddle.io.BatchSampler(dataset=dataset,
batch_size=batch_size,
shuffle=shuffle)
dataloader = paddle.io.DataLoader(dataset,
batch_sampler=sampler,
return_list=True)
return dataloader
def convert_example(example, tokenizer, max_seq_len):
"""
example: {
title
prompt
content
result_list
}
"""
encoded_inputs = tokenizer(text=[example["prompt"]],
text_pair=[example["content"]],
truncation=True,
max_seq_len=max_seq_len,
pad_to_max_seq_len=True,
return_attention_mask=True,
return_position_ids=True,
return_dict=False,
return_offsets_mapping=True)
encoded_inputs = encoded_inputs[0]
offset_mapping = [list(x) for x in encoded_inputs["offset_mapping"]]
bias = 0
for index in range(1, len(offset_mapping)):
mapping = offset_mapping[index]
if mapping[0] == 0 and mapping[1] == 0 and bias == 0:
bias = offset_mapping[index - 1][1] + 1 # Includes [SEP] token
if mapping[0] == 0 and mapping[1] == 0:
continue
offset_mapping[index][0] += bias
offset_mapping[index][1] += bias
start_ids = [0 for x in range(max_seq_len)]
end_ids = [0 for x in range(max_seq_len)]
for item in example["result_list"]:
start = map_offset(item["start"] + bias, offset_mapping)
end = map_offset(item["end"] - 1 + bias, offset_mapping)
start_ids[start] = 1.0
end_ids[end] = 1.0
tokenized_output = [
encoded_inputs["input_ids"], encoded_inputs["token_type_ids"],
encoded_inputs["position_ids"], encoded_inputs["attention_mask"],
start_ids, end_ids
]
tokenized_output = [np.array(x, dtype="int64") for x in tokenized_output]
return tuple(tokenized_output)
def map_offset(ori_offset, offset_mapping):
"""
map ori offset to token offset
"""
for index, span in enumerate(offset_mapping):
if span[0] <= ori_offset < span[1]:
return index
return -1
def reader(data_path, max_seq_len=512):
"""
read json
"""
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
json_line = json.loads(line)
content = json_line['content'].strip()
prompt = json_line['prompt']
# Model Input is aslike: [CLS] Prompt [SEP] Content [SEP]
# It include three summary tokens.
if max_seq_len <= len(prompt) + 3:
raise ValueError(
"The value of max_seq_len is too small, please set a larger value"
)
max_content_len = max_seq_len - len(prompt) - 3
if len(content) <= max_content_len:
yield json_line
else:
result_list = json_line['result_list']
json_lines = []
accumulate = 0
while True:
cur_result_list = []
for result in result_list:
if result['start'] + 1 <= max_content_len < result[
'end']:
max_content_len = result['start']
break
cur_content = content[:max_content_len]
res_content = content[max_content_len:]
while True:
if len(result_list) == 0:
break
elif result_list[0]['end'] <= max_content_len:
if result_list[0]['end'] > 0:
cur_result = result_list.pop(0)
cur_result_list.append(cur_result)
else:
cur_result_list = [
result for result in result_list
]
break
else:
break
json_line = {
'content': cur_content,
'result_list': cur_result_list,
'prompt': prompt
}
json_lines.append(json_line)
for result in result_list:
if result['end'] <= 0:
break
result['start'] -= max_content_len
result['end'] -= max_content_len
accumulate += max_content_len
max_content_len = max_seq_len - len(prompt) - 3
if len(res_content) == 0:
break
elif len(res_content) < max_content_len:
json_line = {
'content': res_content,
'result_list': result_list,
'prompt': prompt
}
json_lines.append(json_line)
break
else:
content = res_content
for json_line in json_lines:
yield json_line
def unify_prompt_name(prompt):
# The classification labels are shuffled during finetuning, so they need
# to be unified during evaluation.
if re.search(r'\[.*?\]$', prompt):
prompt_prefix = prompt[:prompt.find("[", 1)]
cls_options = re.search(r'\[.*?\]$', prompt).group()[1:-1].split(",")
cls_options = sorted(list(set(cls_options)))
cls_options = ",".join(cls_options)
prompt = prompt_prefix + "[" + cls_options + "]"
return prompt
return prompt
def get_relation_type_dict(relation_data):
def compare(a, b):
a = a[::-1]
b = b[::-1]
res = ''
for i in range(min(len(a), len(b))):
if a[i] == b[i]:
res += a[i]
else:
break
if res == "":
return res
elif res[::-1][0] == "的":
return res[::-1][1:]
return ""
relation_type_dict = {}
added_list = []
for i in range(len(relation_data)):
added = False
if relation_data[i][0] not in added_list:
for j in range(i + 1, len(relation_data)):
match = compare(relation_data[i][0], relation_data[j][0])
if match != "":
match = unify_prompt_name(match)
if relation_data[i][0] not in added_list:
added_list.append(relation_data[i][0])
relation_type_dict.setdefault(match, []).append(
relation_data[i][1])
added_list.append(relation_data[j][0])
relation_type_dict.setdefault(match, []).append(
relation_data[j][1])
added = True
if not added:
added_list.append(relation_data[i][0])
suffix = relation_data[i][0].rsplit("的", 1)[1]
suffix = unify_prompt_name(suffix)
relation_type_dict[suffix] = relation_data[i][1]
return relation_type_dict
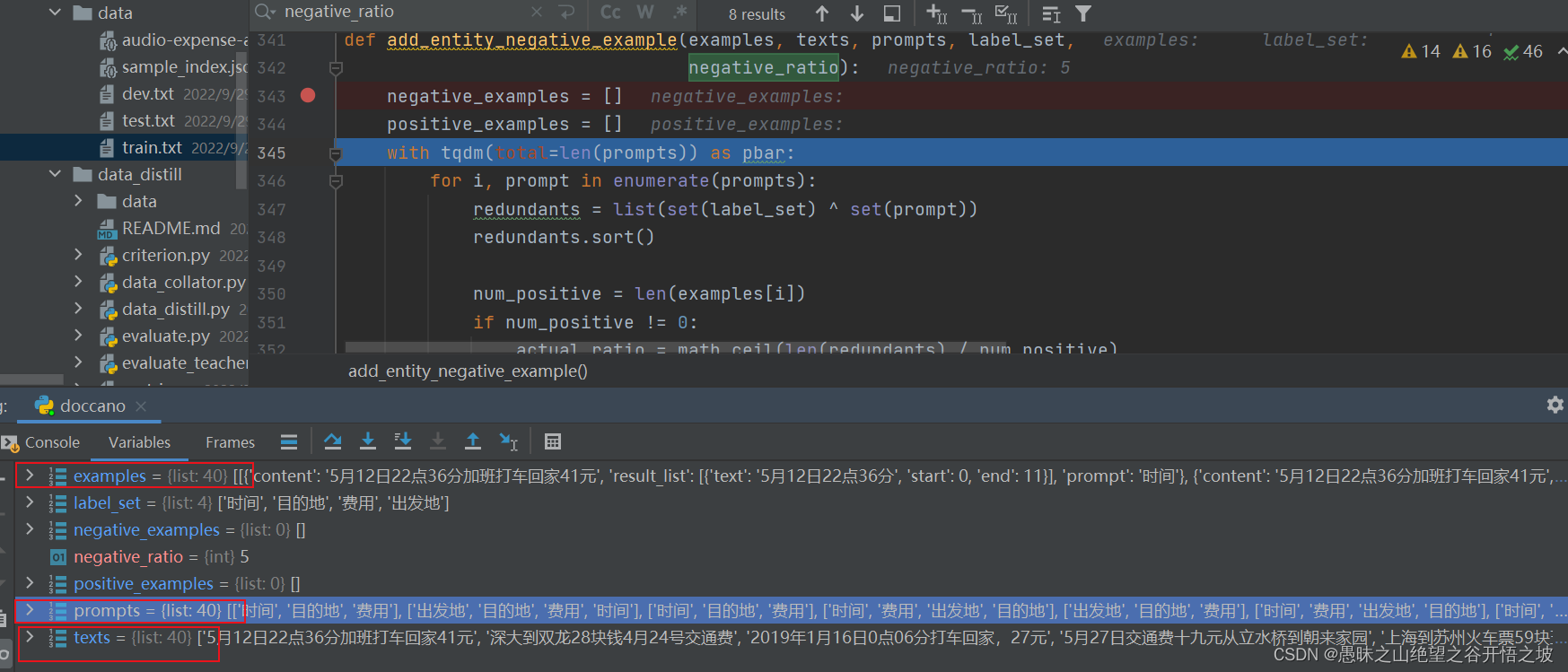
def add_entity_negative_example(examples, texts, prompts, label_set,
negative_ratio):
negative_examples = []
positive_examples = []
with tqdm(total=len(prompts)) as pbar:
for i, prompt in enumerate(prompts):
redundants = list(set(label_set) ^ set(prompt))
redundants.sort()
num_positive = len(examples[i])
if num_positive != 0:
actual_ratio = math.ceil(len(redundants) / num_positive)
else:
# Set num_positive to 1 for text without positive example
num_positive, actual_ratio = 1, 0
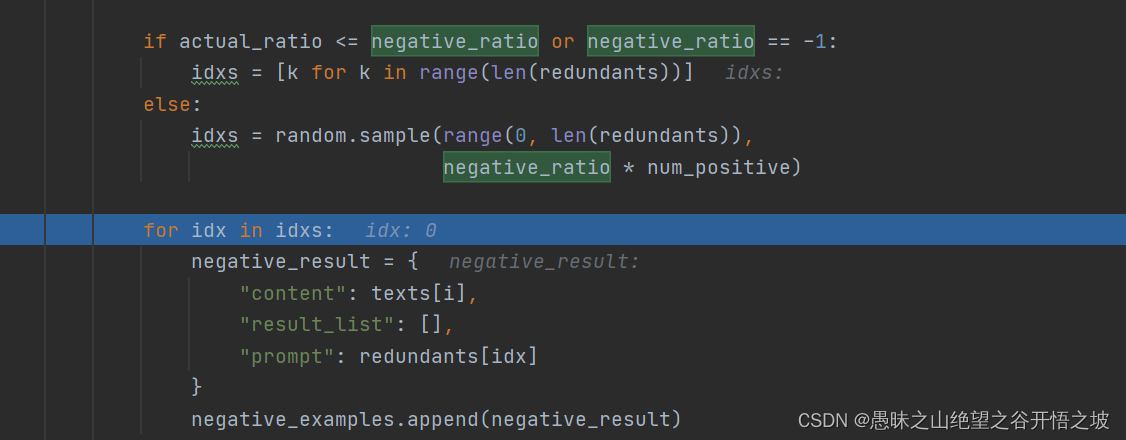
if actual_ratio <= negative_ratio or negative_ratio == -1:
idxs = [k for k in range(len(redundants))]
else:
idxs = random.sample(range(0, len(redundants)),
negative_ratio * num_positive)
for idx in idxs:
negative_result = {
"content": texts[i],
"result_list": [],
"prompt": redundants[idx]
}
negative_examples.append(negative_result)
positive_examples.extend(examples[i])
pbar.update(1)
return positive_examples, negative_examples
def add_relation_negative_example(redundants, text, num_positive, ratio):
added_example = []
rest_example = []
if num_positive != 0:
actual_ratio = math.ceil(len(redundants) / num_positive)
else:
# Set num_positive to 1 for text without positive example
num_positive, actual_ratio = 1, 0
all_idxs = [k for k in range(len(redundants))]
if actual_ratio <= ratio or ratio == -1:
idxs = all_idxs
rest_idxs = []
else:
idxs = random.sample(range(0, len(redundants)), ratio * num_positive)
rest_idxs = list(set(all_idxs) ^ set(idxs))
for idx in idxs:
negative_result = {
"content": text,
"result_list": [],
"prompt": redundants[idx]
}
added_example.append(negative_result)
for rest_idx in rest_idxs:
negative_result = {
"content": text,
"result_list": [],
"prompt": redundants[rest_idx]
}
rest_example.append(negative_result)
return added_example, rest_example
def add_full_negative_example(examples, texts, relation_prompts, predicate_set,
subject_goldens):
with tqdm(total=len(relation_prompts)) as pbar:
for i, relation_prompt in enumerate(relation_prompts):
negative_sample = []
for subject in subject_goldens[i]:
for predicate in predicate_set:
# The relation prompt is constructed as follows:
# subject + "的" + predicate
prompt = subject + "的" + predicate
if prompt not in relation_prompt:
negative_result = {
"content": texts[i],
"result_list": [],
"prompt": prompt
}
negative_sample.append(negative_result)
examples[i].extend(negative_sample)
pbar.update(1)
return examples
def generate_cls_example(text, labels, prompt_prefix, options):
random.shuffle(options)
cls_options = ",".join(options)
prompt = prompt_prefix + "[" + cls_options + "]"
result_list = []
example = {"content": text, "result_list": result_list, "prompt": prompt}
for label in labels:
start = prompt.rfind(label) - len(prompt) - 1
end = start + len(label)
result = {"text": label, "start": start, "end": end}
example["result_list"].append(result)
return example
def convert_cls_examples(raw_examples,
prompt_prefix="情感倾向",
options=["正向", "负向"]):
"""
Convert labeled data export from doccano for classification task.
"""
examples = []
logger.info(f"Converting doccano data...")
with tqdm(total=len(raw_examples)) as pbar:
for line in raw_examples:
items = json.loads(line)
# Compatible with doccano >= 1.6.2
if "data" in items.keys():
text, labels = items["data"], items["label"]
else:
text, labels = items["text"], items["label"]
example = generate_cls_example(text, labels, prompt_prefix, options)
examples.append(example)
return examples
def convert_ext_examples(raw_examples,
negative_ratio,
prompt_prefix="情感倾向",
options=["正向", "负向"],
separator="##",
is_train=True):
"""
Convert labeled data export from doccano for extraction and aspect-level classification task.
"""
def _sep_cls_label(label, separator):
label_list = label.split(separator)
if len(label_list) == 1:
return label_list[0], None
return label_list[0], label_list[1:]
texts = []
entity_examples = []
relation_examples = []
entity_cls_examples = []
entity_prompts = []
relation_prompts = []
entity_label_set = []
entity_name_set = []
predicate_set = []
subject_goldens = []
inverse_relation_list = []
predicate_list = []
logger.info(f"Converting doccano data...")
with tqdm(total=len(raw_examples)) as pbar:
for line in raw_examples:
items = json.loads(line)
entity_id = 0
if "data" in items.keys():
relation_mode = False
if isinstance(items["label"],
dict) and "entities" in items["label"].keys():
relation_mode = True
text = items["data"]
entities = []
relations = []
if not relation_mode:
# Export file in JSONL format which doccano < 1.7.0
# e.g. {"data": "", "label": [ [0, 2, "ORG"], ... ]}
for item in items["label"]:
entity = {
"id": entity_id,
"start_offset": item[0],
"end_offset": item[1],
"label": item[2]
}
entities.append(entity)
entity_id += 1
else:
# Export file in JSONL format for relation labeling task which doccano < 1.7.0
# e.g. {"data": "", "label": {"relations": [ {"id": 0, "start_offset": 0, "end_offset": 6, "label": "ORG"}, ... ], "entities": [ {"id": 0, "from_id": 0, "to_id": 1, "type": "foundedAt"}, ... ]}}
entities.extend(
[entity for entity in items["label"]["entities"]])
if "relations" in items["label"].keys():
relations.extend([
relation for relation in items["label"]["relations"]
])
else:
# Export file in JSONL format which doccano >= 1.7.0
# e.g. {"text": "", "label": [ [0, 2, "ORG"], ... ]}
if "label" in items.keys():
text = items["text"]
entities = []
for item in items["label"]:
entity = {
"id": entity_id,
"start_offset": item[0],
"end_offset": item[1],
"label": item[2]
}
entities.append(entity)
entity_id += 1
relations = []
else:
# Export file in JSONL (relation) format
# e.g. {"text": "", "relations": [ {"id": 0, "start_offset": 0, "end_offset": 6, "label": "ORG"}, ... ], "entities": [ {"id": 0, "from_id": 0, "to_id": 1, "type": "foundedAt"}, ... ]}
text, relations, entities = items["text"], items[
"relations"], items["entities"]
texts.append(text)
entity_example = []
entity_prompt = []
entity_example_map = {}
entity_map = {} # id to entity name
for entity in entities:
entity_name = text[entity["start_offset"]:entity["end_offset"]]
entity_map[entity["id"]] = {
"name": entity_name,
"label": entity["label"], # add by robert
"start": entity["start_offset"],
"end": entity["end_offset"]
}
entity_label, entity_cls_label = _sep_cls_label(
entity["label"], separator)
# Define the prompt prefix for entity-level classification
entity_cls_prompt_prefix = entity_name + "的" + prompt_prefix
if entity_cls_label is not None:
entity_cls_example = generate_cls_example(
text, entity_cls_label, entity_cls_prompt_prefix,
options)
entity_cls_examples.append(entity_cls_example)
result = {
"text": entity_name,
"start": entity["start_offset"],
"end": entity["end_offset"]
}
if entity_label not in entity_example_map.keys():
entity_example_map[entity_label] = {
"content": text,
"result_list": [result],
"prompt": entity_label
}
else:
entity_example_map[entity_label]["result_list"].append(
result)
if entity_label not in entity_label_set:
entity_label_set.append(entity_label)
if entity_name not in entity_name_set:
entity_name_set.append(entity_name)
entity_prompt.append(entity_label)
for v in entity_example_map.values():
entity_example.append(v)
entity_examples.append(entity_example)
entity_prompts.append(entity_prompt)
subject_golden = [] # Golden entity inputs
relation_example = []
relation_prompt = []
relation_example_map = {}
inverse_relation = []
predicates = []
subject_id_list = [] # add by robert
for relation in relations:
predicate = relation["type"]
subject_id = relation["from_id"]
object_id = relation["to_id"]
# The relation prompt is constructed as follows:
# subject + "的" + predicate
subject_id_list.append(subject_id) # add by robert
prompt = entity_map[subject_id]["name"] + "的" + predicate
if entity_map[subject_id]["name"] not in subject_golden:
subject_golden.append(entity_map[subject_id]["name"])
result = {
"text": entity_map[object_id]["name"],
"start": entity_map[object_id]["start"],
"end": entity_map[object_id]["end"]
}
inverse_negative = entity_map[object_id][
"name"] + "的" + predicate
inverse_relation.append(inverse_negative)
predicates.append(predicate)
if prompt not in relation_example_map.keys():
relation_example_map[prompt] = {
"content": text,
"result_list": [result],
"prompt": prompt
}
else:
relation_example_map[prompt]["result_list"].append(result)
if predicate not in predicate_set:
predicate_set.append(predicate)
relation_prompt.append(prompt)
# #************************add by robert*************************
relation_dict = {'时间': ['交通工具', '地点', '行为', '接触者']}
for subject_id in subject_id_list:
if entity_map[subject_id]["label"] in relation_dict:
for rel in relation_dict[entity_map[subject_id]["label"]]:
prompt_new = entity_map[subject_id]["name"] + "的" + rel
if prompt_new not in relation_example_map:
relation_example_map[prompt_new] = {
"content": text,
"result_list": [],
"prompt": prompt_new
}
# #************************add by robert*************************
for v in relation_example_map.values():
relation_example.append(v)
relation_examples.append(relation_example)
relation_prompts.append(relation_prompt)
subject_goldens.append(subject_golden)
inverse_relation_list.append(inverse_relation)
predicate_list.append(predicates)
pbar.update(1)
logger.info(f"Adding negative samples for first stage prompt...")
positive_examples, negative_examples = add_entity_negative_example(
entity_examples, texts, entity_prompts, entity_label_set,
negative_ratio)
if len(positive_examples) == 0:
all_entity_examples = []
else:
all_entity_examples = positive_examples + negative_examples
all_relation_examples = []
if len(predicate_set) != 0:
logger.info(f"Adding negative samples for second stage prompt...")
if is_train:
positive_examples = []
negative_examples = []
per_n_ratio = negative_ratio // 3
with tqdm(total=len(texts)) as pbar:
for i, text in enumerate(texts):
negative_example = []
collects = []
num_positive = len(relation_examples[i])
# 1. inverse_relation_list
redundants1 = inverse_relation_list[i]
# 2. entity_name_set ^ subject_goldens[i]
redundants2 = []
if len(predicate_list[i]) != 0:
nonentity_list = list(
set(entity_name_set) ^ set(subject_goldens[i]))
nonentity_list.sort()
redundants2 = [
nonentity + "的" +
predicate_list[i][random.randrange(
len(predicate_list[i]))]
for nonentity in nonentity_list
]
# 3. entity_label_set ^ entity_prompts[i]
redundants3 = []
if len(subject_goldens[i]) != 0:
non_ent_label_list = list(
set(entity_label_set) ^ set(entity_prompts[i]))
non_ent_label_list.sort()
redundants3 = [
subject_goldens[i][random.randrange(
len(subject_goldens[i]))] + "的" + non_ent_label
for non_ent_label in non_ent_label_list
]
redundants_list = [redundants1, redundants2, redundants3]
for redundants in redundants_list:
added, rest = add_relation_negative_example(
redundants,
texts[i],
num_positive,
per_n_ratio,
)
negative_example.extend(added)
collects.extend(rest)
num_sup = num_positive * negative_ratio - len(
negative_example)
if num_sup > 0 and collects:
if num_sup > len(collects):
idxs = [k for k in range(len(collects))]
else:
idxs = random.sample(range(0, len(collects)),
num_sup)
for idx in idxs:
negative_example.append(collects[idx])
positive_examples.extend(relation_examples[i])
negative_examples.extend(negative_example)
pbar.update(1)
all_relation_examples = positive_examples + negative_examples
else:
relation_examples = add_full_negative_example(
relation_examples, texts, relation_prompts, predicate_set,
subject_goldens)
all_relation_examples = [
r for relation_example in relation_examples
for r in relation_example
]
return all_entity_examples, all_relation_examples, entity_cls_examples
linux
cd uie
python finetune.py --train_path ./data_rl/train.txt --dev_path ./data_rl/dev.txt --save_dir ./checkpoint_rl --model uie-base --learning_rate 1e-5 --batch_size 4 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10 --device gpu
win10
python finetune.py
--train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-base --learning_rate 1e-5 --batch_size 2 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10 --device cpu --init_from_ckpt ./checkpoint_rl/model_best/model_state.pdparams
4、蒸馏模型训练
在UIE强大的抽取能力背后,同样需要较大的算力支持计算。在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,我们基于数据蒸馏技术构建了UIE Slim数据蒸馏系统。
其原理是通过数据作为桥梁
,将UIE模型的知识迁移到封闭域信息抽取小模型,以达到精度损失较小的情况下却能达到大幅度预测速度提升的效果。
UIE数据蒸馏三步
Step 1: 使用UIE模型对标注数据进行finetune,得到Teacher Model。
Step 2: 用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。
Step 3: 使用标注数据以及步骤2得到的合成数据训练出封闭域Student Model。
数据下载
cd uie
wget https://bj.bcebos.com/paddlenlp/datasets/uie/data_distill/data.zip && unzip data.zip -d ../
数据切分
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
教师模型微调
python finetune.py \
--train_path ./data/train.txt \
--dev_path ./data/dev.txt \
--learning_rate 5e-6 \
--batch_size 2
教师模型预测无监督
cd data_distill
python data_distill.py \
--data_path ../data \
--save_dir student_data \
--task_type relation_extraction \
--synthetic_ratio 10 \
--model_path ../checkpoint/model_best
教师模型评估
python evaluate_teacher.py \
--task_type relation_extraction \
--test_path ./student_data/dev_data.json \
--label_maps_path ./student_data/label_maps.json \
--model_path ../checkpoint/model_best
学生模型训练
python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 200 \
--encoder ernie-3.0-mini-zh
笔记
python基础视频教程(7小时入门)
:
https://www.bilibili.com/video/BV1V64y1h7mZ?p=2&vd_source=6824a60429337b880936b4f7a2d42d38
python decimal
【python】Decimal的使用:
https://blog.csdn.net/qq_39147299/article/details/124200896
我们可以通过实例化Decimal对象时传入value参数把其他的数据类型转换成Decimal类型。注意,尽量传入整数和字符串,如果传入float会导致结果不准确(float本身就存在精度问题)
Decimal类型也可以像python基本数据类型那样进行加减乘除等运算
1、概念
python原生数据类型在进行浮点运算时,可能会由于精度问题导致计算结果不准确,尤其是浮点数和较大的数据进行运算,所以如果对数据精度有要求,比如说金额,我们就需要使用decimal这个库
decimal意思为十进制,这个模块提供了十进制浮点运算支持。主要是用来处理小数的,针对与浮点型我们比较熟悉flocat 这个也可以针对小数进行处理,但是它会四舍五入,也可以用到关于金额,或者需求要求特别精确的方面。
2、优点
(1)Decimal所表示的数是完全精确的。
(2)Decimal类包含有效位的概念,因此1.30 + 1.20的结果是2.50,保留尾随零以表示有效位。
3、实例
与基于硬件的float不同,Decimal具有用户可更改的精度(默认为28位)
>>> from decimal import *
>>> getcontext().prec = 6
>>> Decimal(1) / Decimal(7)
Decimal('0.142857')
>>> getcontext().prec = 28
>>> Decimal(1) / Decimal(7)
np.random.permutation
>>> np.random.permutation(10)
array([1, 7, 4, 3, 0, 9, 2, 5, 8, 6]) # random
>>> np.random.permutation([1, 4, 9, 12, 15])
array([15, 1, 9, 4, 12]) # random
>>> arr = np.arange(9).reshape((3, 3))
>>> np.random.permutation(arr)
array([[6, 7, 8], # random
[0, 1, 2],
[3, 4, 5]])
集合运算
python集合的运算(交集、并集、差集、补集):
https://www.jianshu.com/p/c9fe1c1479b8

>>> aset = set([10,20,30])
>>> bset = set([20,30,40])
>>> set1 = aset&bset #交集运算
>>> set2 = aset|bset #并集运算
>>> set3 = aset-bset #差集运算
>>> set4 = aset^bset #补集运算
>>> set1
{20, 30}
>>> set2
{20, 40, 10, 30}
>>> set3
{10}
>>> set4
{40, 10}
>>> set1<aset #子集测试
True
>>> aset<set2 #超集测试
True
>>> aset>set2
False