topic中partition存储分布
Topic在逻辑上可以被认为是一个queue。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得 Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储 这个partition的所有消息和索引文件。partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
partition中文件存储方式
下面示意图形象说明了partition中文件存储方式:
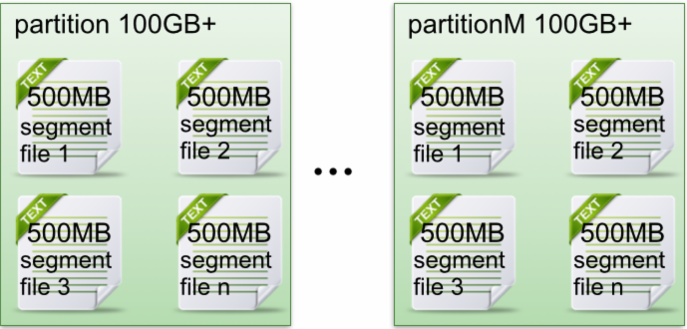
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中,但每个段segment file消息数量不一定相等,下面会提到一消息数量的算法,因为每个segment的大小是一定的,但是每条消息的大小可能不相同,因此数量不同。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定,这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
partition中segment文件存储结构
前面提到了每个topic被分成了多个partition分布到各个broker上,而每个partition的文件夹中又又多个小文件组成。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
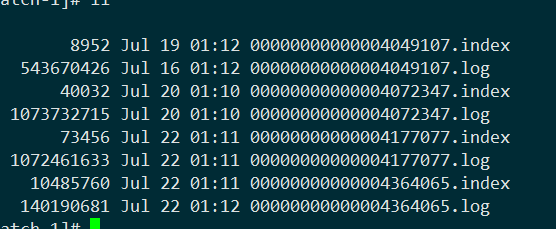
一对segment file文件为例,说明segment中index<—->data file对应关系物理结构

索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移址为497。
从上述了解到segment data file由许多message组成,下面详细说明message物理结构如下:

| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
在partition中如何通过offset查找message
例如读取offset=368776的message,需要通过下面2个步骤查找。
-
第一步查找segment file
其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件 00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。
当offset=368776时定位到00000000000000368769.index|log
-
第二步通过segment file查找message通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和 00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到 offset=368776为止。
从上述图3可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它 比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
高效性的保证
每条消息都被append到该partition中,是顺序写入磁盘的,在机械盘中随机写入的效率是很低的,但是如果是顺序写入效率非常高这是kafka高吞吐率的一个很重要的保证。
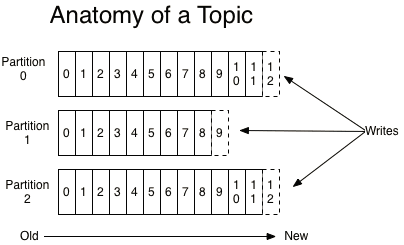
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有 消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在
$KAFKA_HOME/config/server.properties
中指定这个partition的数量(如下所示),当然也可以在topic创建之后去修改parition数量
# The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=3
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。 paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现
kafka.producer.Partitioner
接口。本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际 上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。例如可以通过配置
$KAFKA_HOME/config/server.properties
,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据,如下所示。
############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=300000 # By default the log cleaner is disabled and the log retention policy will default to #just delete segments after their retention expires. # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs #can then be marked for log compaction. log.cleaner.enable=false
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只与磁盘 以及具体的需求有关。另外,Kafka会为每一个consumer group保留一些metadata信息–当前消费的消息的position,也即offset。这个offset由consumer控制。正常情况下 consumer会在消费完一条消息后线性增加这个offset。当然,consumer也可将offset设成一个较小的值,重新消费一些消息。因为 offet由consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些consumer过,不需要通过broker去保证同一个consumer group只有一个consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
转载于:https://www.cnblogs.com/chushiyaoyue/p/5695826.html