一、目的
这一节我们学习如何使用乐鑫的ESP32开发板通过心知天气API控获取实时天气的数据,并使用串口SPI控制ILI9341 液晶屏,显示出来。
二、环境
ESP32(固件:esp32-20220618-v1.19.1.bin) + Thonny(V4.0.1) +
ILI9341
液晶屏模块 + 几根杜邦线 + Win10 64位商业版
接线方法,请查看上篇文章:物联网开发笔记(93)
心知天气 – 高精度气象数据 – 天气数据API接口 – 行业气象解决方案
心知天气是中国气象局官方授权的商业气象服务公司,基于气象数值预报和人工智能技术,提供高精度气象数据、天气监控机器人、气象数据可视化产品,以及能源、电力、保险、农业、交通、互联网、物联网行业解决方案
![]()
https://www.seniverse.com/
大家自行注册下账号,然后申请免费使用。
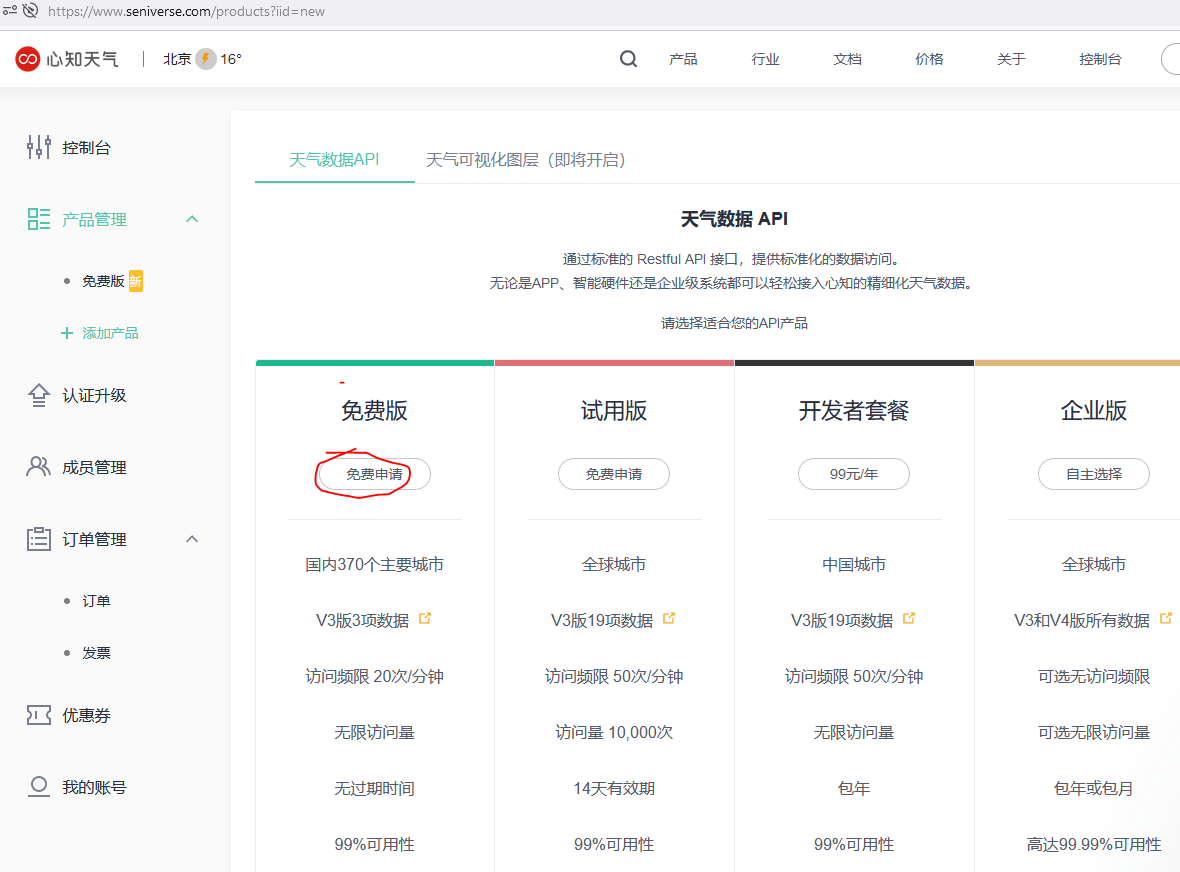
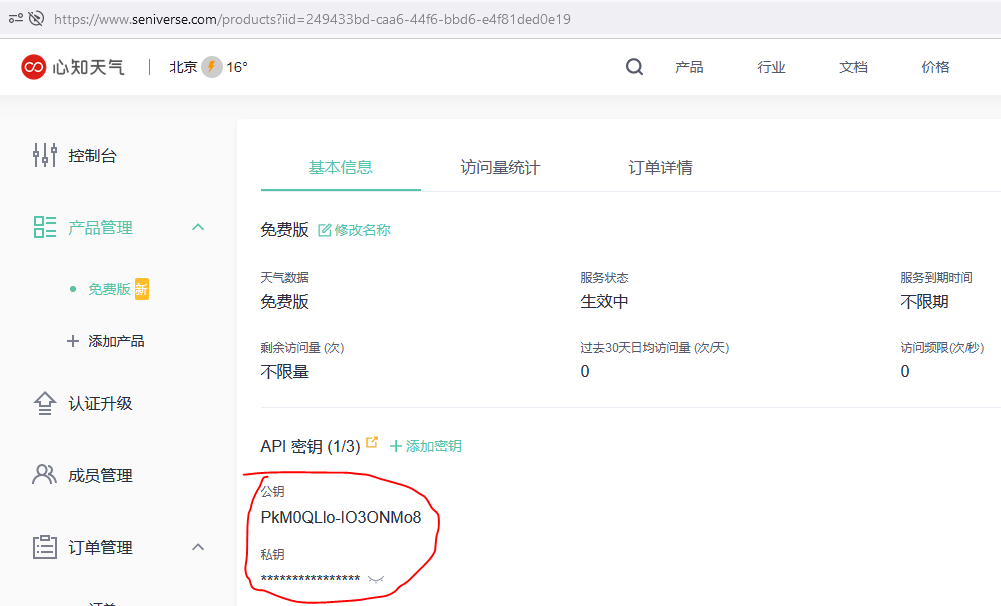
然后你会获取到一个公钥和私钥,亲保存下来待用:
在文档-产品文档中查看使用方法
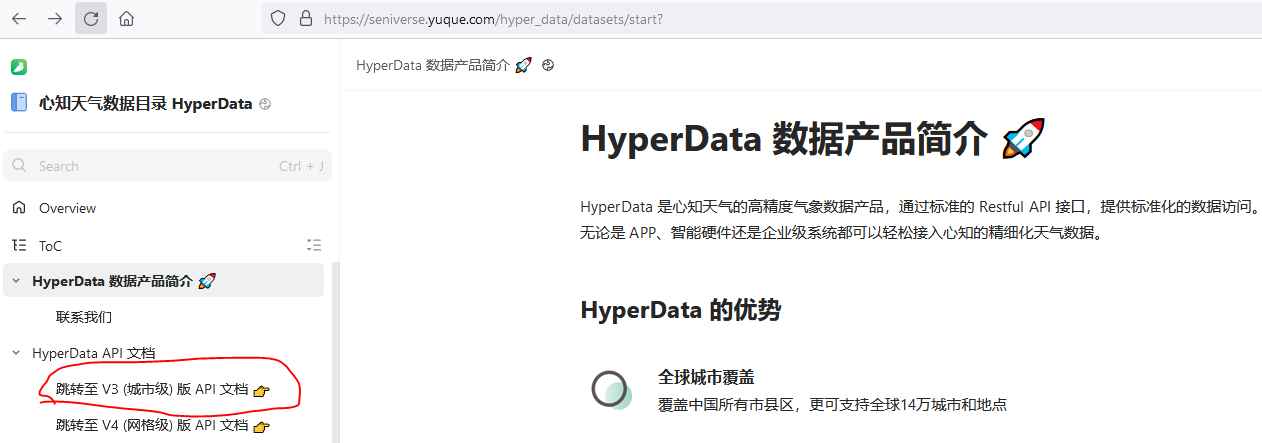
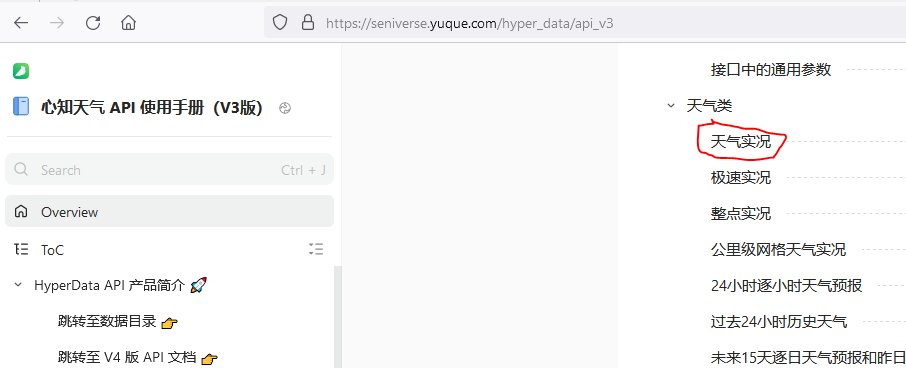
这下图我们可以找到我们需要使用的API地址
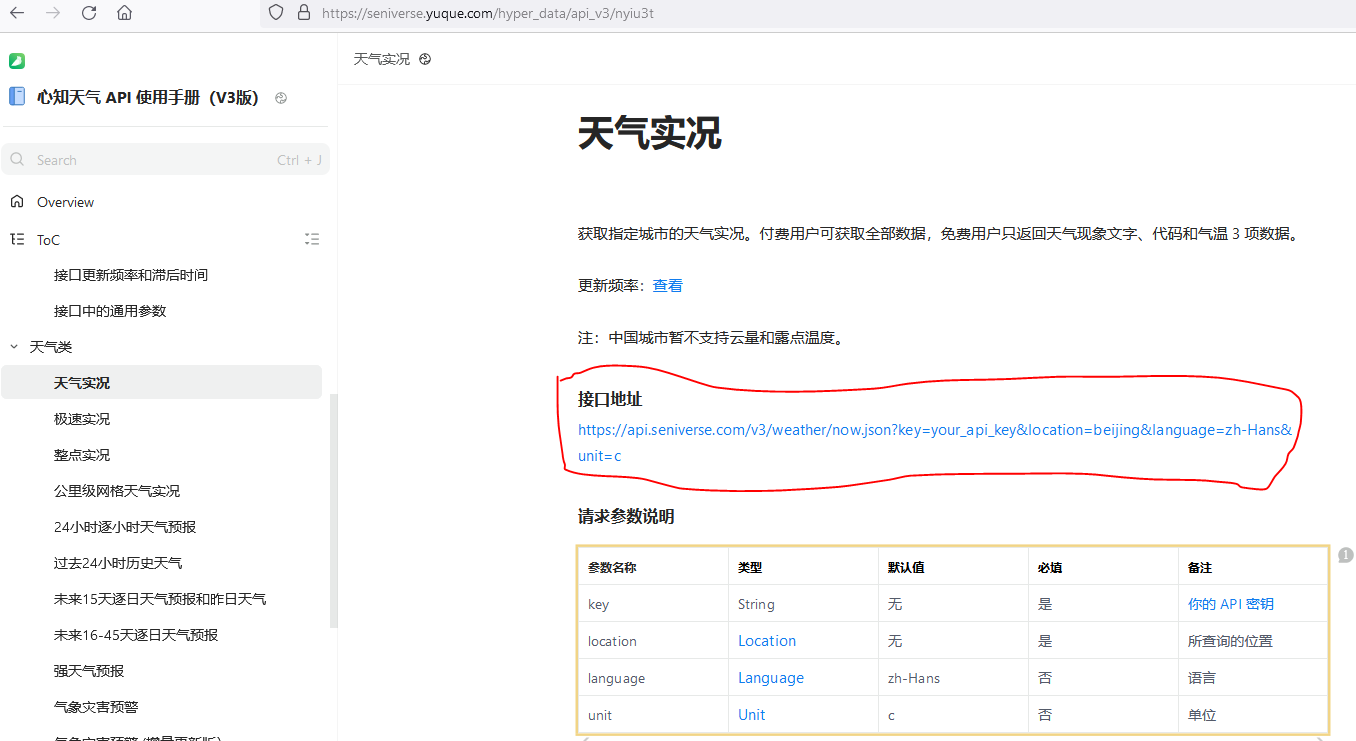
将API的key的值设为你的私钥,location设为你的城市即可。
其他的信息大家在文档中自行查找哈。。。
四、演示示例代码
示例中的库和字体请从下文获取:
from machine import Pin,SPI,PWM
from ili9341 import Display,color565
from xglcd_font import XglcdFont
import network,time,urequests,ujson
# 调节显示亮度,初始亮度为400
blk = PWM(Pin(2),duty = (400),freq = (1000))
# 创建SPI对象
spi = SPI(2, baudrate=40000000, polarity=0, phase=0, bits=8, firstbit=0, sck=Pin(18), mosi=Pin(23), miso=Pin(19))
# 创建屏幕对象
tft = Display(spi,cs=Pin(5,Pin.OUT),dc=Pin(26,Pin.OUT),rst=Pin(27,Pin.OUT),width=240,height=320,rotation=180)
# 字库
font9x11 = XglcdFont("font/ArcadePix9x11.c",9,11)
font12x24 = XglcdFont("font/Unispace12x24.c",12,24)
def do_connect():
tft.draw_text(8,2,"Weather forecast: ",font12x24,color565(0,255,0),color565(0,0,0))
tft.draw_hline(0,32,240,color565(255,255,0))
tft.draw_hline(0,40,240,color565(255,255,0))
wlan = network.WLAN(network.STA_IF)
wlan.active(True)
if not wlan.isconnected():
tft.draw_text(0,52,"connecting to network...",font9x11,color565(0,255,255),color565(0,0,0))
wlan.connect('WIFI名称', 'WIFI密码')
while not wlan.isconnected():
pass
tft.draw_text(0,52,"esp32 2.4G network config...",font9x11,color565(255,0,0),color565(0,0,0))
tft.draw_text(0,63,"IP addr: %s"%wlan.ifconfig()[0],font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,74,"Gateway: %s"%wlan.ifconfig()[1],font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,85,"Mask: %s"%wlan.ifconfig()[2],font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,96,"Dns: %s"%wlan.ifconfig()[3],font9x11,color565(0,255,255),color565(0,0,0))
def Get_Tianqi():
#地区编码
#https://api.seniverse.com/v3/weather/now.json?key=SZuYH2Be_kZZD4lV7&location=WWE0TGW4PX6N&language=zh-Hans&unit=c
#省份加地市
#https://api.seniverse.com/v3/weather/now.json?key=SZuYH2Be_kZZD4lV7&location=shandongjinan&language=zh-Hans&unit=c
#公钥PkM0QLlo-IO3ONMo8 私钥SB8otBmdd8Sz6F0wg
#data = urequests.get("https://api.seniverse.com/v3/weather/now.json?key=SB8otBmdd8Sz6F0wg&location=beijing&language=en&unit=c")
#weather_info = ujson.loads(data.text)
weather_info = {"results":[{"location":{"id":"WX4FBXXFKE4F","name":"Beijing","country":"CN","path":"Beijing,Beijing,China","timezone":"Asia/Shanghai","timezone_offset":"+08:00"},"now":{"text":"Haze","code":"31","temperature":"16"},"last_update":"2023-03-21T21:42:15+08:00"}]}
#城市编码
City_ID = weather_info["results"][0]["location"]["id"]
#城市
name = weather_info["results"][0]["location"]["name"]
#天气
weather = weather_info["results"][0]["now"]["text"]
#温度
temperature = weather_info["results"][0]["now"]["temperature"]
#更新
update = weather_info["results"][0]["last_update"]
#打印调试
#print(City_ID,name,weather,update)
tft.draw_text(0,111,"City_ID: %s"%City_ID,font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,122,"name: %s"%name,font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,133,"weather: %s"%weather,font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,144,"temperature: %s%s"%(temperature,' '),font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,155,"update: %.18s"%update,font9x11,color565(0,255,255),color565(0,0,0))
tft.draw_text(0,185,"temperature: %.3s%s"%(temperature,' '),font12x24,color565(0,255,0),color565(0,0,0))
for i in range(60):
tft.fill_circle(220,198,6,color565(0,255,0))
time.sleep(1)
tft.fill_circle(220,198,6,color565(255,0,0))
time.sleep(1)
tft.draw_text(120,296,"update: %.2d"%(i),font12x24,color565(255,255,i),color565(0,0,0))
def main():
blk.duty(800) # 设置屏幕背光
do_connect() # 连接网络
while True:
Get_Tianqi() # 获取天气
if __name__ == "__main__":
main()
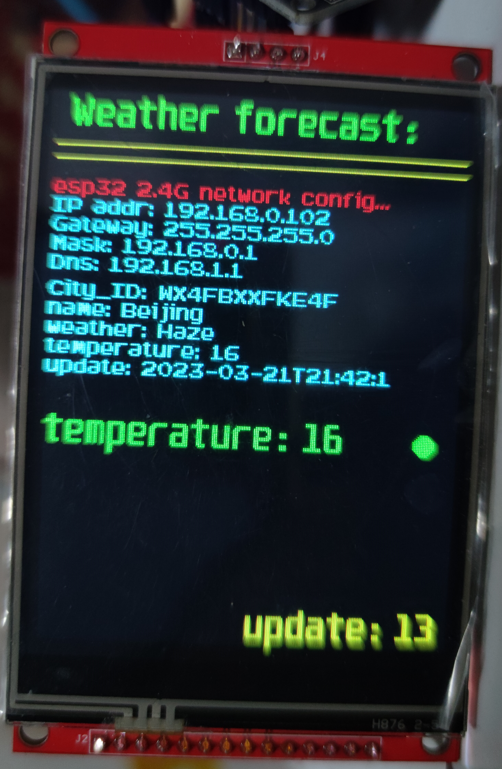
五、演示效果
六、urequest库
urequests.py
import usocket
#from parse import urlencode
import ure
class Response:
def __init__(self, f):
self.raw = f
self.encoding = "utf-8"
self._cached = None
self.status_code = None
self.reason = None
self.headers = None
# cookie support as dict
self.cookies = None
# url to see redirect targets
self.url = None
def close(self):
if self.raw:
self.raw.close()
self.raw = None
self._cached = None
@property
def content(self):
if self._cached is None:
try:
self._cached = self.raw.read()
finally:
self.raw.close()
self.raw = None
return self._cached
# extracts data from a stream, if the direct conversion of the result to a string consumes too much memory
def extract(self, _startStr, _endStr):
# we prepare an array to store
results = []
# prepare regex to reduces spaces to on space
# and remove cr/linefeeds
removeWhiteSpaces = ure.compile("( )+")
removeCR = ure.compile("[\r\n]")
endOfStream = False
_startStrBytes = bytes(_startStr, 'utf-8')
_endStrBytes = bytes(_endStr, 'utf-8')
# start with mininum length of the search String
# if it is smaller than the start - end
pageStreamBytes = self.raw.read(len(_startStr))
if len(pageStreamBytes) < len(_startStr):
endOfStream = True
# we must convert the searchstring to bytes als not for all charcters uft-8 encoding is working
# like in Curacao (special c)
while not endOfStream:
if pageStreamBytes == _startStrBytes:
# we found a matching string
# print('Start found %s ' % pageStreamBytes.decode('utf-8'))
# we need to find the end
endOfTag = False
read = self.raw.read(len(_endStr))
if len(read) == 0:
endOfStream = True
pageStreamBytes += read
while ((not endOfStream) and (not endOfTag)):
# comparing the string with the find method is easier
# than comparing the bytes
if (pageStreamBytes.decode('utf-8')).find(_endStr) > 0:
endOfTag = True
result = removeWhiteSpaces.sub('', pageStreamBytes.decode('utf-8'))
result = removeCR.sub('', result)
results.append(result)
# print('Result: %s' % result)
else:
# read and Append
read = self.raw.read(1)
if len(read) == 0:
endOfStream = True
else:
pageStreamBytes += read
# print('End not Found %s' % pageStreamBytes.decode('utf-8'))
else:
# we did not find a matching string
# and reduce by one character before we add the next
# print('not found %s' % pageStream)
pageStreamBytes = pageStreamBytes[1:len(_startStrBytes)]
read = self.raw.read(1)
if len(read) == 0:
endOfStream = True
pageStreamBytes = pageStreamBytes + read
self.close()
return results
@property
def text(self):
return str(self.content, self.encoding)
def json(self):
import ujson
return ujson.loads(self.content)
""" method = head, get, put, patch, post, delete
url (with our without parameters)
params, cookies, headers - each as dict
if cookies are supplied, new cookies will be added
if parse_headers is false -> no cookies are returned as they are part of the header
if followRedirect = false -> the redirect URL is stored in URL
"""
def request(method, url, params=None, cookies=None, data=None, json=None, headers={}, parse_headers=True, followRedirect=True):
if params is not None:
if params != {}:
#url = url.rstrip('?') + '?' + urlencode(params, doseq=True)
url = url.rstrip('?') + '?'
redir_cnt = 1
while True:
try:
proto, dummy, host, path = url.split("/", 3)
except ValueError:
proto, dummy, host = url.split("/", 2)
path = ""
if proto == "http:":
port = 80
elif proto == "https:":
import ussl
port = 443
else:
raise ValueError("Unsupported protocol: " + proto)
if ":" in host:
host, port = host.split(":", 1)
port = int(port)
ai = usocket.getaddrinfo(host, port, 0, usocket.SOCK_STREAM)
ai = ai[0]
resp_d = None
if parse_headers is not False:
resp_d = {}
# print('Socket create')
s = usocket.socket(ai[0], ai[1], ai[2])
# 60sec timeout on blocking operations
s.settimeout(60.0)
try:
# print('Socket connect')
s.connect(ai[-1])
if proto == "https:":
s = ussl.wrap_socket(s, server_hostname=host)
# print('Socket wrapped')
s.write(b"%s /%s HTTP/1.0\r\n" % (method, path))
# print('Socket write: ')
# print(b"%s /%s HTTP/1.0\r\n" % (method, path))
if "Host" not in headers:
s.write(b"Host: %s\r\n" % host)
# Iterate over keys to avoid tuple alloc
for k in headers:
s.write(k)
s.write(b": ")
s.write(headers[k])
s.write(b"\r\n")
# print(k, b": ".decode('utf-8'), headers[k], b"\r\n".decode('utf-8'))
if cookies is not None:
for cookie in cookies:
s.write(b"Cookie: ")
s.write(cookie)
s.write(b"=")
s.write(cookies[cookie])
s.write(b"\r\n")
if json is not None:
assert data is None
import ujson
data = ujson.dumps(json)
s.write(b"Content-Type: application/json\r\n")
if data:
s.write(b"Content-Length: %d\r\n" % len(data))
# print("Content-Length: %d\r\n" % len(data))
s.write(b"Connection: close\r\n\r\n")
if data:
s.write(data)
# print(data)
l = s.readline()
#print('Received protocoll and resultcode %s' % l.decode('utf-8'))
l = l.split(None, 2)
status = int(l[1])
reason = ""
if len(l) > 2:
reason = l[2].rstrip()
# Loop to read header data
while True:
l = s.readline()
#print('Received Headerdata %s' % l.decode('utf-8'))
if not l or l == b"\r\n":
break
# Header data
if l.startswith(b"Transfer-Encoding:"):
if b"chunked" in l:
# decode added, can't cast implicit from bytes to string
raise ValueError("Unsupported " + l.decode('utf-8'))
elif l.startswith(b"Location:") and 300 <= status <= 399:
if not redir_cnt:
raise ValueError("Too many redirects")
redir_cnt -= 1
url = l[9:].decode().strip()
#print("Redirect to: %s" % url)
# set status as signal for loop
status = 302
if parse_headers is False:
pass
elif parse_headers is True:
l = l.decode()
# print('Headers: %s ' % l)
k, v = l.split(":", 1)
# adding cookie support (cookies are overwritten as they have the same key in dict)
# supplied in the request, not supported is the domain attribute of cookies, this is not set
# new cookies are added to the supplied cookies
if cookies is None:
cookies = {}
if k == 'Set-Cookie':
ck, cv = v.split("=", 1)
cookies[ck.strip()] = cv.strip()
# else it is not a cookie, just normal header
else:
resp_d[k] = v.strip()
else:
parse_headers(l, resp_d)
except OSError:
s.close()
print('Socket closed')
raise
# if redirect repeat else leave loop
if status != 302:
break
# if redirect false leave loop
if (status == 302) and not followRedirect:
break
# if 302 and redirect = true then loop
resp = Response(s)
resp.url = url
resp.status_code = status
resp.reason = reason
if resp_d is not None:
resp.headers = resp_d
# adding cookie support
resp.cookies = cookies
return resp
def head(url, **kw):
return request("HEAD", url, **kw)
def get(url, **kw):
return request("GET", url, **kw)
def post(url, **kw):
return request("POST", url, **kw)
def put(url, **kw):
return request("PUT", url, **kw)
def patch(url, **kw):
return request("PATCH", url, **kw)
def delete(url, **kw):
return request("DELETE", url, **kw)
七、屏幕购买
请查看我的这个文章获取购买地址: