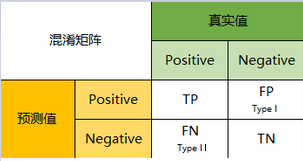
混淆矩阵(confusion_matrix)是由预测值和标签值组成的二维矩阵,共n行n列。n表示class类别数。
二分类
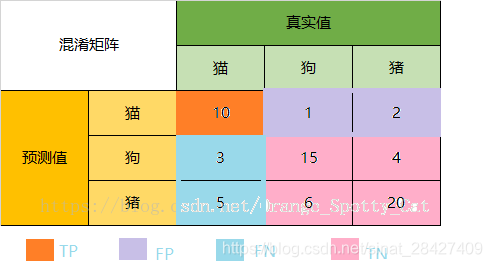
图片源自https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839
多分类
#计算 overall accuracy
oa = np.diag(conf_mat).sum() / conf_mat.sum()
#计算各类别 accuracy
acc_cls = np.aidg(conf_mat) / conf_mat.sum(axis = 1)
# axis 0:gt, axis 1:prediction
#计算各类别 precision和 recall
precision_cls = np.diag(conf_mat) / conf_mat.sum(axis = 1)
recall_cls = np.diag(conf_mat) / conf_mat.sum(axis = 0)
#计算各类别 f1-score
f1_cls = (2 * precision_cls * recall_cls) / (precision_cls + recall_cls)
#计算 mean f1-score
mf1 = np.nanmean(f1_cls)
版权声明:本文为sinat_28427409原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。