一、项目需求
项目中数据量比较大,单表千万级别的,需要实现分表,于是在网上搜索这方面的开源框架,最常见的就是mycat,sharding-sphere,最终我选择后者,用它来做分库分表比较容易上手。
二、简介sharding-sphere
官网地址(有中文版)
sharding-jdbc 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
三、项目实战
本项目使用sharding-sphere + tk.mybatis 实现分库分表
1.pom依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.22</version>
</dependency>
2.创建分表

3.application.properties (重点)基本是在这个文件配置的
# 配置Sharding-JDBC的分片策略
# 配置数据源,给数据源起名ds1,ds2...此处可配置多数据源
spring.shardingsphere.datasource.names=ds1,ds2
# 一个实体类对应两张表,覆盖
#spring.main.allow-bean-definition-overriding=true
# 配置数据源具体内容————————包含 连接池, 驱动, 地址, 用户名, 密码
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
spring.shardingsphere.datasource.ds1.url=jdbc:sqlserver://localhost:1433;DatabaseName=heinz;loginTimeout=30;sendStringParametersAsUnicode=false
spring.shardingsphere.datasource.ds1.username=sa
spring.shardingsphere.datasource.ds1.password=506617
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
spring.shardingsphere.datasource.ds2.url=jdbc:sqlserver://localhost:1433;DatabaseName=heinz;loginTimeout=30;sendStringParametersAsUnicode=false
spring.shardingsphere.datasource.ds2.username=sa
spring.shardingsphere.datasource.ds2.password=506617
# 配置默认数据源
spring.shardingsphere.sharding.default-data-source-name=ds2
# 配置表的分布,表的策略
spring.shardingsphere.sharding.tables.multistage_level_qr_code.actual-data-nodes=ds1.multistage_level_qr_code_$->{0..4}
spring.shardingsphere.sharding.tables.code_circulation.actual-data-nodes=ds1.code_circulation_$->{0..4}
# 指定multistage_level_qr_code表 主键id 生成策略为 SNOWFLAKE
#spring.shardingsphere.sharding.tables.multistage_level_qr_code.key-generator.column=id
#spring.shardingsphere.sharding.tables.multistage_level_qr_code.key-generator.type=SNOWFLAKE
# 指定分片策略 约定id值hash后取模
spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.standard.sharding-column=id
#spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.inline.algorithm-expression=multistage_level_qr_code_$->{product_id % 5}
#spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.hint.algorithm-class-name=com.sigmatrix.configuration.MyTableHintShardingAlgorithm
spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.standard.precise-algorithm-class-name=com.sigmatrix.configuration.MyTablePreciseShardingAlgorithm
spring.shardingsphere.sharding.tables.code_circulation.table-strategy.standard.sharding-column=qr_code
spring.shardingsphere.sharding.tables.code_circulation.table-strategy.standard.precise-algorithm-class-name=com.sigmatrix.configuration.MyTablePreciseShardingAlgorithm
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
- 之所以配置两个数据源,是因为项目中肯定有表并不需要分表操作,分表和不分表必须使用不同的数据源。不做分表的使用指定的默认数据源。
-
分片策略

- 使用标准分片策略:自定义分片字段算法
import com.qcloud.cos.utils.Jackson;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Collection;
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
private static Logger logger = LoggerFactory.getLogger(MyTablePreciseShardingAlgorithm.class);
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<String> preciseShardingValue) {
logger.info("tableNames:{}, hintShardingValue:{}", Jackson.toJsonString(tableNames), Jackson.toJsonString(preciseShardingValue));
int hashCode = preciseShardingValue.getValue().hashCode();
String tableName = preciseShardingValue.getLogicTableName() + "_" + hashCode % 5;
if (!tableNames.contains(tableName)){
tableName = tableNames.iterator().next();
}
return tableName;
}
}
4.使用复杂秘钥分片算法
# 指定分片策略为complex策略,使用复杂秘钥分片算法
spring.shardingsphere.sharding.tables.multistage_level_qr_code.logic-table=multistage_level_qr_code
spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.complex.sharding-columns=id,ipc_code
spring.shardingsphere.sharding.tables.multistage_level_qr_code.table-strategy.complex.algorithm-class-name=com.sigmatrix.configuration.ComplexKeysShardingAlgorithmImpl
- 自定义复杂的密钥分片算法:匹配多字段
import com.alibaba.fastjson.JSONObject;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import java.util.*;
/**
* 自定义复杂的密钥分片算法
*
* @author
* @date 2021-10-25
*/
public class ComplexKeysShardingAlgorithmImpl implements ComplexKeysShardingAlgorithm<String> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComplexKeysShardingAlgorithmImpl.class);
/**
* 分片
*
* @param availableTargetNames 可用的数据源或表的名称
* @param shardingValue 分片值
* @return 数据源或表名称的分片结果
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
LOGGER.info("ComplexKeysShardingAlgorithm availableTargetNames=" + JSONObject.toJSONString(availableTargetNames));
LOGGER.info("ComplexKeysShardingAlgorithm shardingValue=" + JSONObject.toJSONString(shardingValue));
List<String> tableNames = new ArrayList<>();
String[] shardingColumns = new String[]{"id", "ipc_code"};
Map<String, Collection<String>> shardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
// 命中分片列为id
if (shardingValuesMap.containsKey(shardingColumns[0])) {
List<String> shardingValues = (List<String>) shardingValuesMap.get(shardingColumns[0]);
int hashCode = Math.abs(shardingValues.get(0).hashCode());
String tableName = shardingValue.getLogicTableName() + "_" + hashCode % 5;
if (availableTargetNames.contains(tableName)) {
tableNames.add(tableName);
}
}
// 命中分片列为ipc_code
if (shardingValuesMap.containsKey(shardingColumns[1])) {
List<String> shardingValues = (List<String>) shardingValuesMap.get(shardingColumns[1]);
int hashCode = Math.abs(shardingValues.get(0).hashCode());
String tableName = shardingValue.getLogicTableName() + "_" + hashCode % 5;
if (availableTargetNames.contains(tableName)) {
tableNames.add(tableName);
}
}
if (CollectionUtils.isEmpty(tableNames)) {
List<String> availableTableNames = (List<String>) availableTargetNames;
Collections.shuffle(availableTableNames);
tableNames.add(availableTableNames.get(0));
}
LOGGER.info("ComplexKeysShardingAlgorithm actual sharding tables=" + JSONObject.toJSONString(tableNames));
return tableNames;
}
}
5、执行sql后的效果

6、分表后会出现的问题
-
使用SQLSever时,聚合列不加别名会报错。
– 例
– 错误:
SELECT SUM(num), SUM(num2) FROM tablexxx;
– 正确:
SELECT SUM(num) AS sum_num, SUM(num2) AS sum_num2 FROM tablexxx;
-
在inline分表策略时,允许执行范围查询操作(BETWEEN AND、>、<、>=、<=)
– 需要使用4.1.0以上的版本。
– 将配置项allow.range.query.with.inline.sharding设置为true即可(默认为false)。
– 需要注意的是,此时所有的范围查询将会使用广播的方式查询每一个分表。 -
分表使用pagehelper分页插件可能出现异常(本项目使用tk_mybatis)
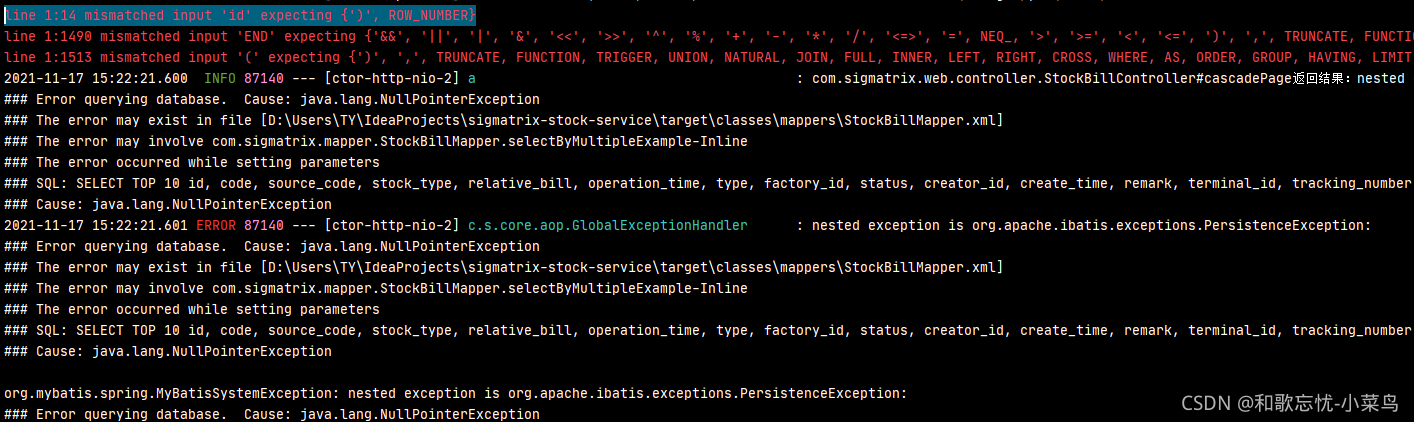
在properties文件中添加
pagehelper.helper-dialect=sqlserver2012
属性,将pagehelper分页方式从
top
改为
OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY
,但是后者有个缺陷就是前面必须有
order by
- 不支持使用case when语句
- 有限支持子查询(官网说的有限不清楚具体界限,但是本人发现一些简单的子查询也会有异常,但不会报错)
版权声明:本文为weixin_50954940原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。