XGBoost二分类模型中树的绘制
背景介绍:
本文是
XGBoost模型调参、训练、评估、保存和预测
文章的后续,这里详细解释graphviz软件的配置和模型中树的绘制。
一.graphviz安装与配置

不安装软件to_graphviz()和plot_tree()两个方法都无法使用,报错如上图。
安装步骤:
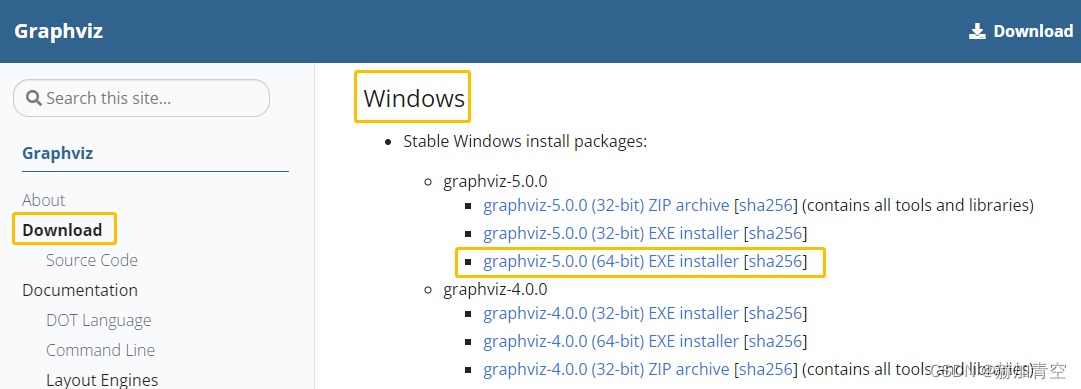
步骤1
:下载对应系统版本的graphviz软件,
graphviz官网下载链接
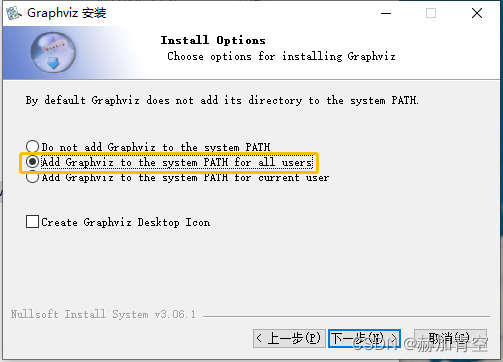
步骤2
:EXE文件双击安装graphviz,但是需要注意勾选环境变量添加的安装方式,如果没添加则要手动在步骤2中补上,否则无法dot作图。
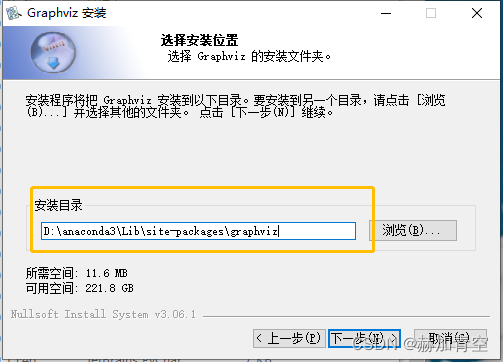
安装至anaconda的site-packages内,具体路径如下,下方路径就是环境变量的路径
步骤3
:环境变量检查,如果步骤2选了add path那就是验证,否则就是手动添加,总之必须要有这两个环境变量。
右键“我的电脑”——“属性”——“高级系统设置”——“高级”——“环境变量”
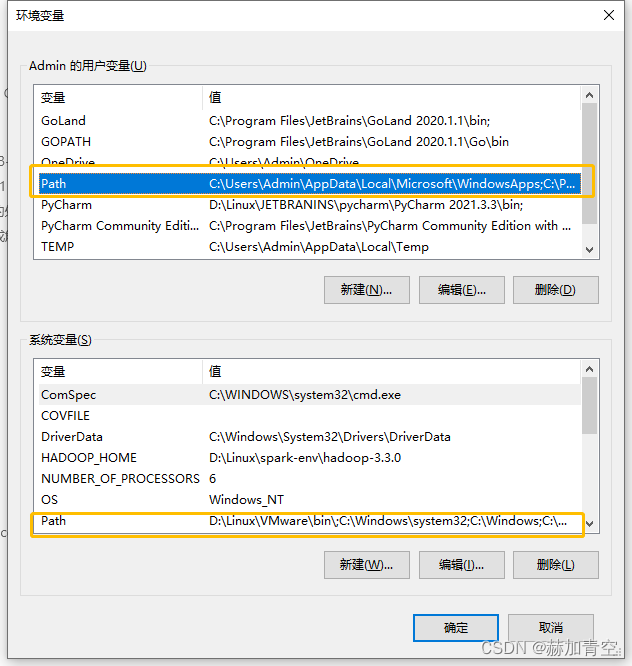
用户环境变量:双击Path,没有这个环境变量就手动添加,位置与graphviz安装位置相同\bin
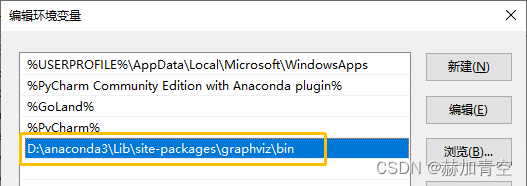
系统环境变量值:同样没有这个环境变量就手动添加,位置与graphviz安装位置相同\bin\dot.exe,如D:\anaconda3\Lib\site-packages\graphviz\bin\dot.exe
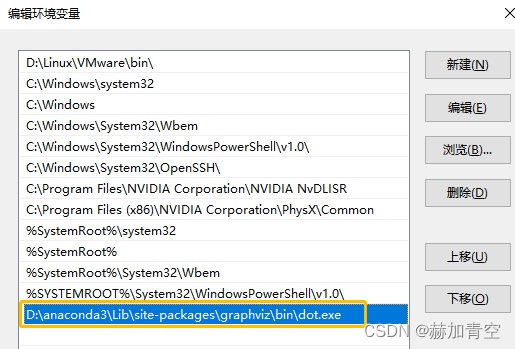
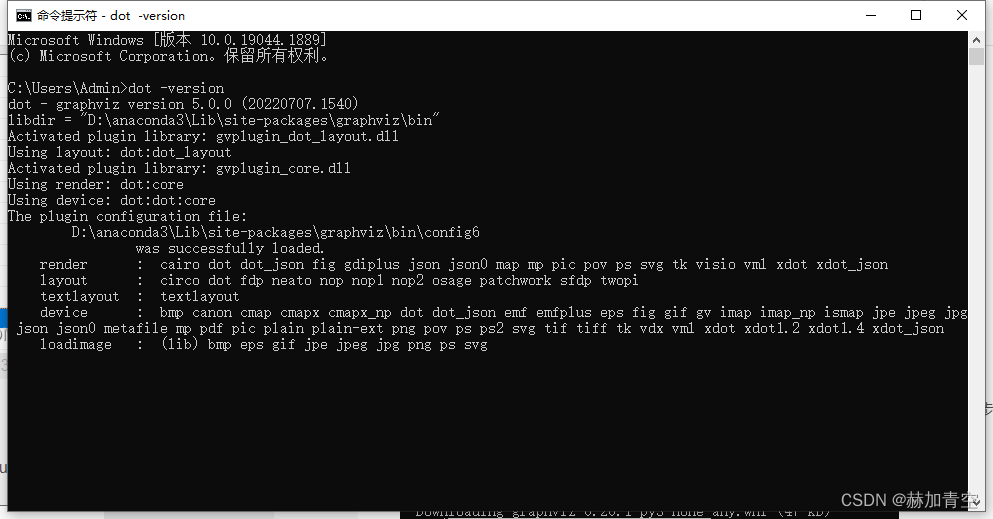
步骤4
:graphviz安装成功验证,cmd执行
dot -version
,出现下图结果即安装成功
步骤5
:pip install graphviz(如果提前安装了先pip uninstall graphviz卸载,重新按步骤执行)
如果没有pip安装会报下图错误

步骤6
:运行脚本,执行绘制,如果依然报如下图错误(缺少环境变量),重启软件;重启软件不行就重启电脑(我在重启电脑这个环境卡了2个小时,一直在安装不同版本都是这个错误,重启电脑即可)

二.树模型绘制脚本
百度网盘提取本文数据和完整脚本(提取码:54ul)
下面2.1和2.2都是画图的参数指定,结合脚本看更容易理解
2.1关于fmap文件的简单解释
1.fmap文件是用于替换节点名称的文件(参数
fmap='xgb.fmap'
)。如果没有指定这个文件,或文件中特征数量不够,节点名称会按照f1、f2、f3……依次展开。
2.fmap文件有特定结构,文件中每一行都是如下结构
[feature_id, feature_name, q or i or int]:
第1列为特征的id,第2列为特征的名称;第3列为数据类型
feature_id:从0开始直到len(feature)-1为止。
q:表示数值特征,xgb模型只能导入数值类特征,所以这里直接写了q
i:表示是二分类特征
int:决策边界将为整数
这里我试了q/i/int没差别,int绘制图依然条件是小数。
2.2绘制树的两个方法
1.xgb.to_graphviz(),必须指定模型;可以指定要绘制树的序号,默认0;可以指定fmap、条件节点颜色形状、叶子结点颜色形状。模型保存可以format指定格式,view保存到本地,如果format未指定格式则默认保存为pdf格式文件,
优点:清晰度高
。
2.xgb.plot_tree(),模型参数指定与to_graphviz()相同,其实底层都是通过graphviz软件来做,不过plot_tree()是通过plt.show()展示,清晰度较差,要想改变需要指定ax参数,这里不做展开了。通过for循环展示了每一颗树,绘制的树不做保存。
2.3树模型绘制的完整脚本
具体步骤都有注释,原理和用法上述内容均已解释,不再赘述。
两段代码放在一起便可完整执行,数据自己随便造一份即可
。
def model_plot_trees(clf, features, **n):
"""绘制树模型"""
# 保存特征名称到fmap文件,用于图形绘制
with open('xgb.fmap', 'w', encoding="utf-8") as fmap:
for k, ft in enumerate(features):
fmap.write(''.join(str([k, ft, 'p']) + '\n'))
# 构建条件节点和叶子节点的形状、填充颜色
c_node_params = {'shape': 'box',
'style': 'filled,rounded',
'fillcolor': '#78bceb'
}
l_node_params = {'shape': 'box',
'style': 'filled',
'fillcolor': '#e48038'
}
# 树模型绘制:有向图
# 绘制和保存第num_trees+1棵树,num_trees为树的序号
digraph = xgb.to_graphviz(clf, num_trees=0, condition_node_params=c_node_params,
leaf_node_params=l_node_params, fmap='xgb.fmap')
# digraph.format = 'png'
digraph.view('./oil_xgb_trees')
# 分别绘制子图,不保存
for i in range(n.get('n')):
xgb.plot_tree(clf, num_trees=i, condition_node_params=c_node_params,
leaf_node_params=l_node_params, fmap='xgb.fmap')
plt.show()
这里的model_fit()模块是
XGBoost模型调参、训练、评估、保存和预测
中model_fit()模块的简化调用,此处省略了验证、评估等内容。
def model_fit():
"""模型训练"""
# XGBoost训练过程,为了便于解释下面调整下参数,树的个数为10,树的最大深度为5
model = XGBClassifier(learning_rate=0.3, n_estimators=10, max_depth=5, min_child_weight=1,
subsample=1, colsample_bytree=1, gamma=0.1, reg_alpha=0.01, reg_lambda=3)
model.fit(X_train, y_train)
# 模型保存为txt格式,便于分析、优化和提供可解释性
clf = model.get_booster()
clf.dump_model('dump_10tree.txt')
# 绘制树模型:n <= n_estimators
model_plot_trees(model, dataset.columns[:-1], n=50)
return model
if __name__ == '__main__':
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import xgboost as xgb
from xgboost import XGBClassifier
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 数据集
dataset = pd.read_csv('Oil_well_parameters_train.csv', engine='python')
# 划分训练集和验证集
X_train, X_test, y_train, y_test = train_test_split(dataset.iloc[:, :-1], dataset.iloc[:, -1], test_size=0.2,
random_state=42)
# 模型训练
model_xgb_clf = model_fit()
2.4模型中第1颗树绘制图
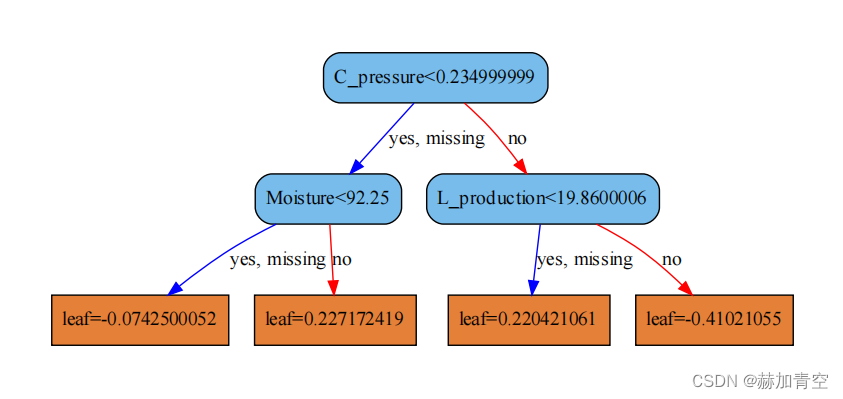
运行脚本后,全部树的结构会保存到dump.txt文件,下图为第1颗树的文本结构。对照上图可知,第1颗树编号[0],根据最顶端根节点0的条件划分为1和2两个条件节点,再根据两个条件节点分别划分了编号为3,4,5,6的叶子节点,叶子节点带有结果权值。(其中missing是对缺失值的划分标准)

限于篇幅过长,关于绘制的树的更多分析见另一文章
Graphviz绘制模型树2——XGBoost模型的可解释性
,这篇文章将从模型中的树着手解释XGBoost模型,并用EXCEL构建出模型。
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。