Redis超详细入门(图文结合)原来redis这么简单
Redis入门
概述
redis简介
Redis 是一种开源(BSD 许可)、内存中
数据结构存储
,用作
数据库
、
缓存
和
消息代理
。Redis 提供了诸如
字符串
、
散列
、
列表
、
集合
、带范围查询的
排序集合
、
位图
、
超级日志
、
地理空间索引
和
流
等
数据结构
。Redis 内置了
复制
、
Lua 脚本
、
LRU 驱逐
、
事务
和不同级别的
磁盘持久化
,并通过
Redis Sentinel
和
Redis Cluster
自动分区。
您可以 对这些类型运行
原子操作
,例如
附加到字符串
;
增加散列中的值
;
将元素推入列表
;
计算集合交集
、
并集
和
差集
;或
获取排序集中排名最高的成员
。
为了获得最佳性能,Redis 使用
内存数据集
。根据您的用例,您可以通过定期
将数据集转储到磁盘
或
将每个命令附加到基于磁盘的日志
来保留数据。如果您只需要一个功能丰富的网络内存缓存,您也可以禁用持久性。
Redis 还支持
异步复制
,具有非常快的非阻塞第一次同步,自动重新连接和网络拆分部分重新同步。
其他功能包括:
您可以从
大多数编程语言中
使用 Redis 。
Redis 是用
ANSI C
编写的,可在大多数 POSIX 系统(如 Linux、
BSD 和 OS X)中运行,无需外部依赖。Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,我们
推荐使用 Linux 进行部署
。Redis 可能在 SmartOS 等 Solaris 派生系统中工作,但支持是
尽力而为的*。没有对 Windows 构建的官方支持。
安装
-
下载安装包
注意:ContOS7支持5,如果需要安装更高版本需要升级gcc
-
解压
程序一般放在/opt目录下
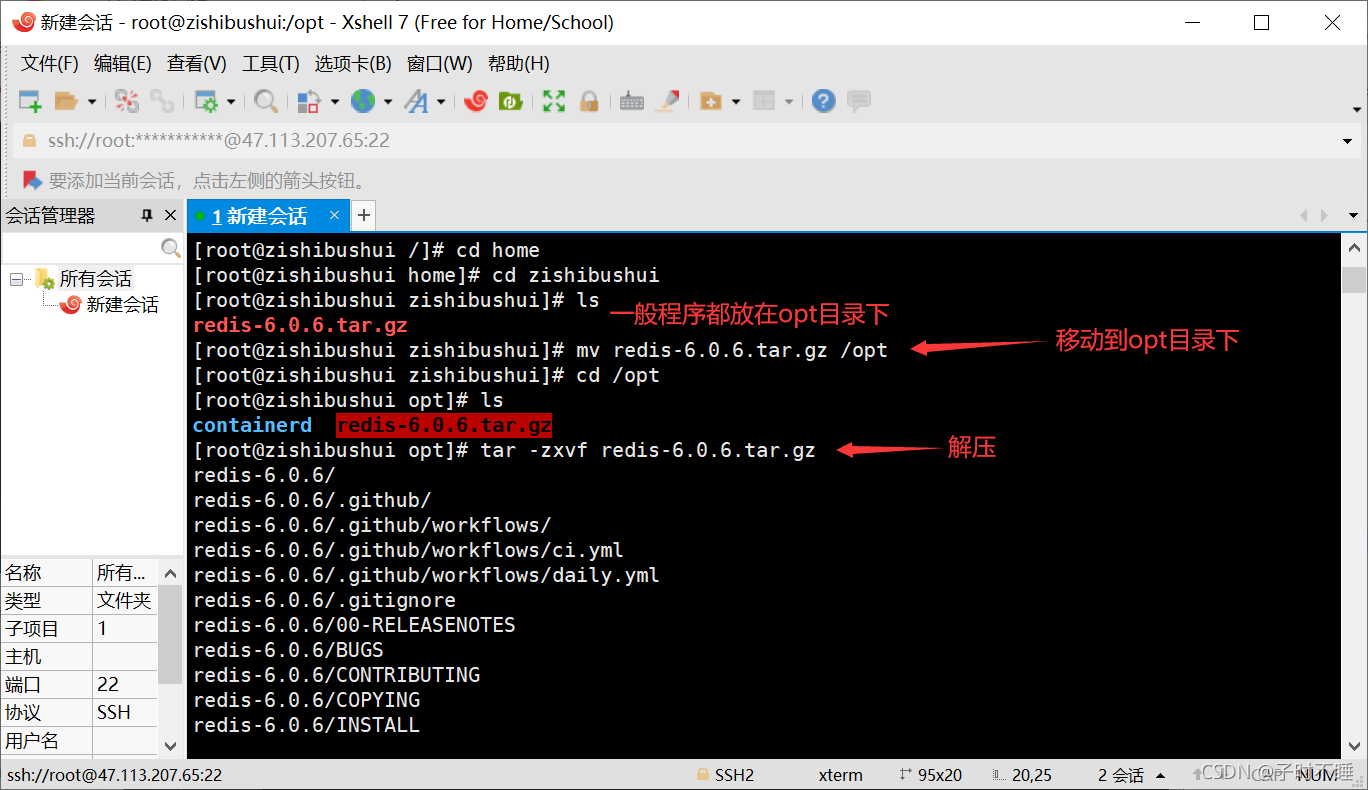
-
解压后的文件

-
基本的环境安装
yum install -y gcc-c++ make make install因为redis是用c写的,所有需要安装c的编译环境
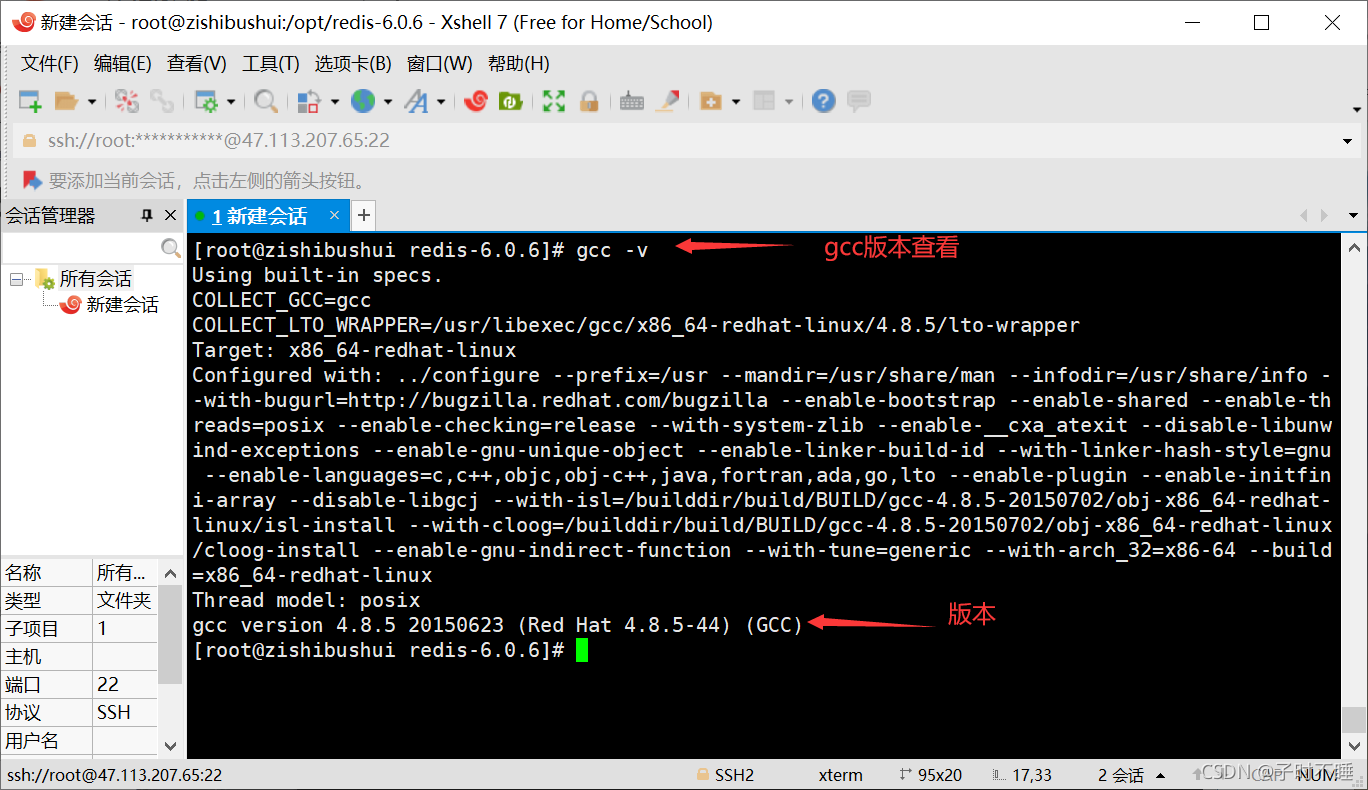
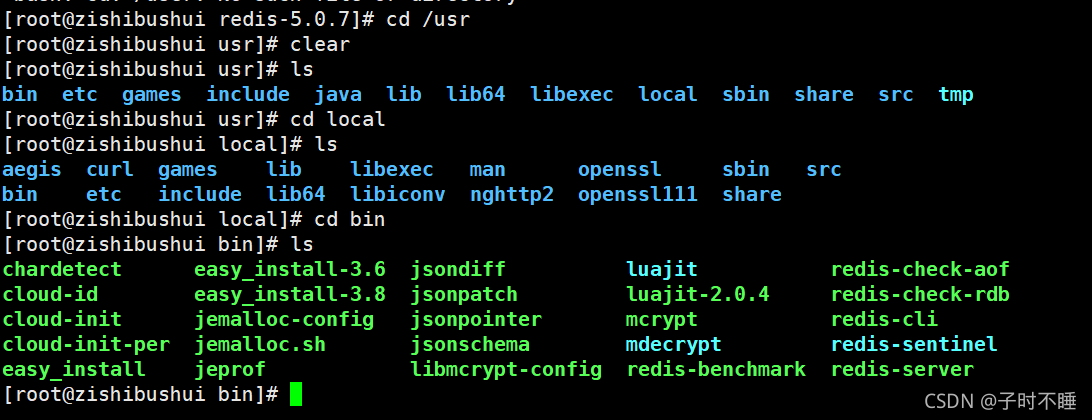
redis的默认安装路径:
usr/local/bin
-
将redis配置文件复制到当前目录下
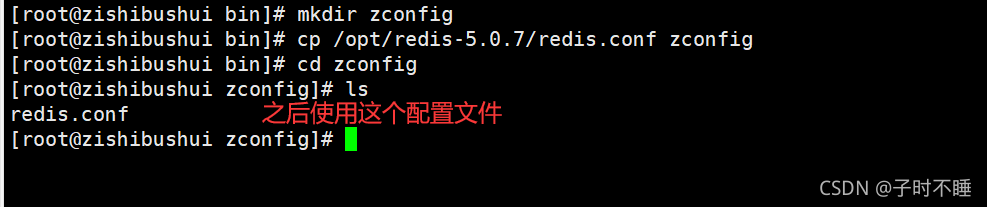
-
redis默认不是后台启动,如果后台启动,则需要修改配置
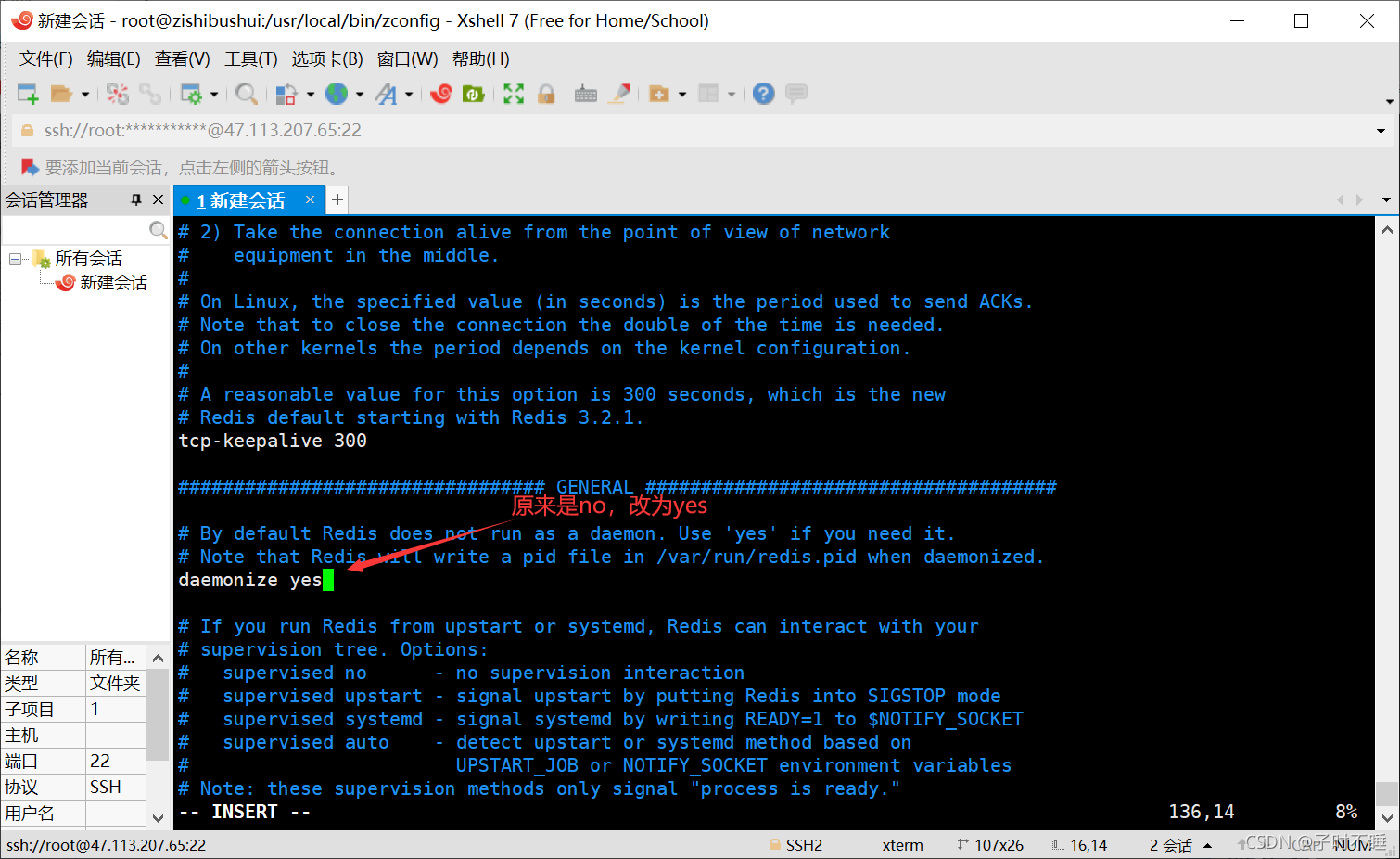
端口号 6379
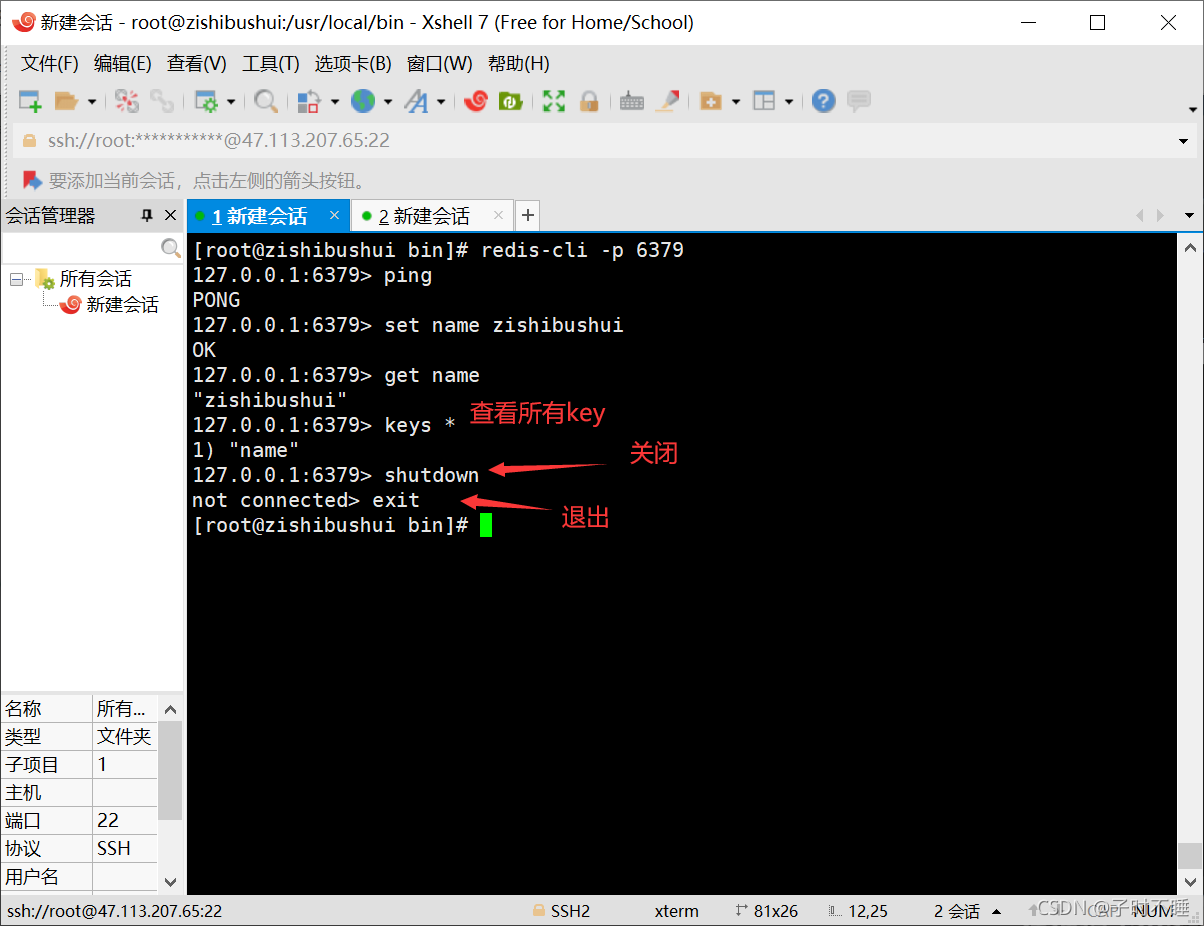
- 启动redis服务
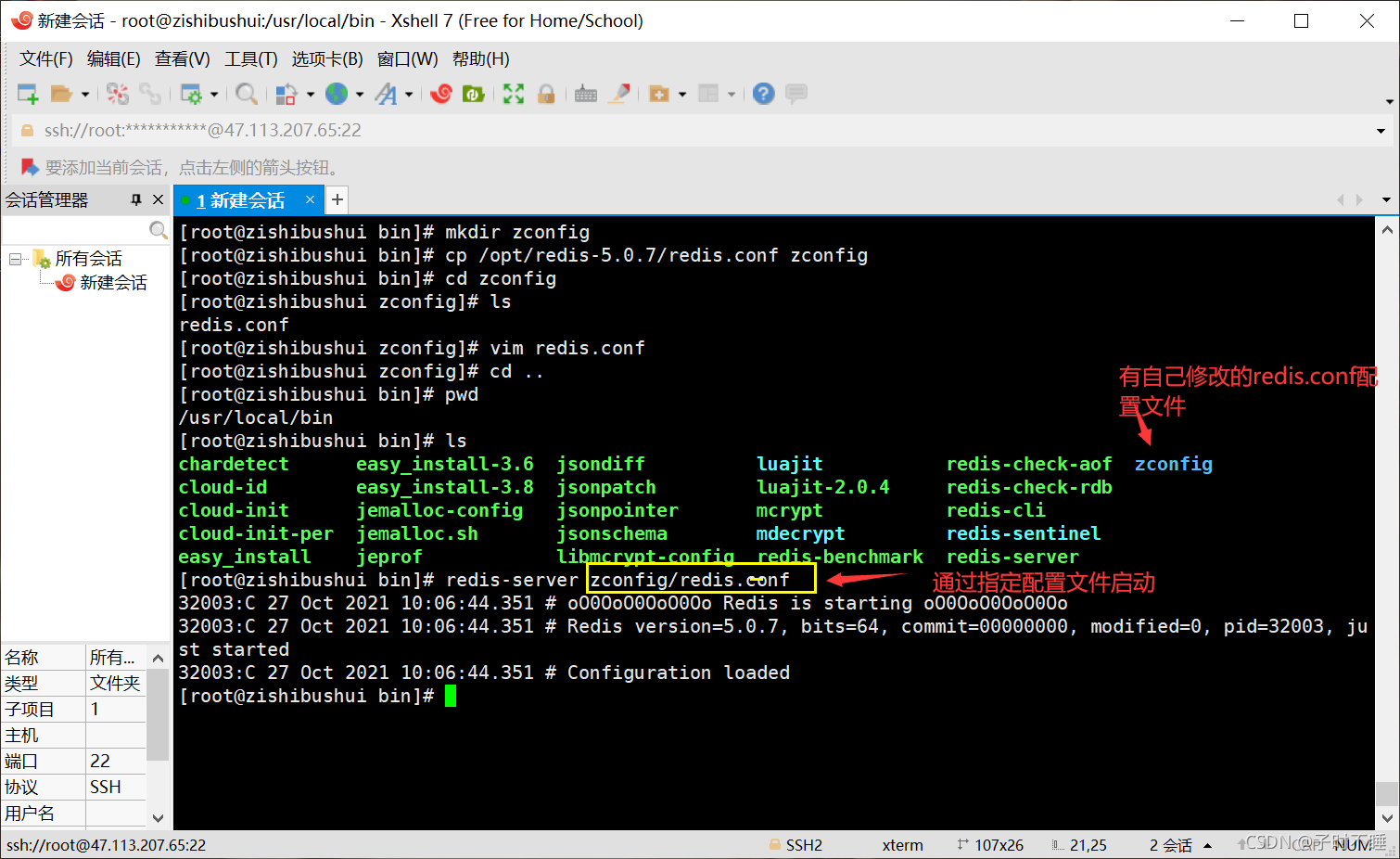
- 连接测试
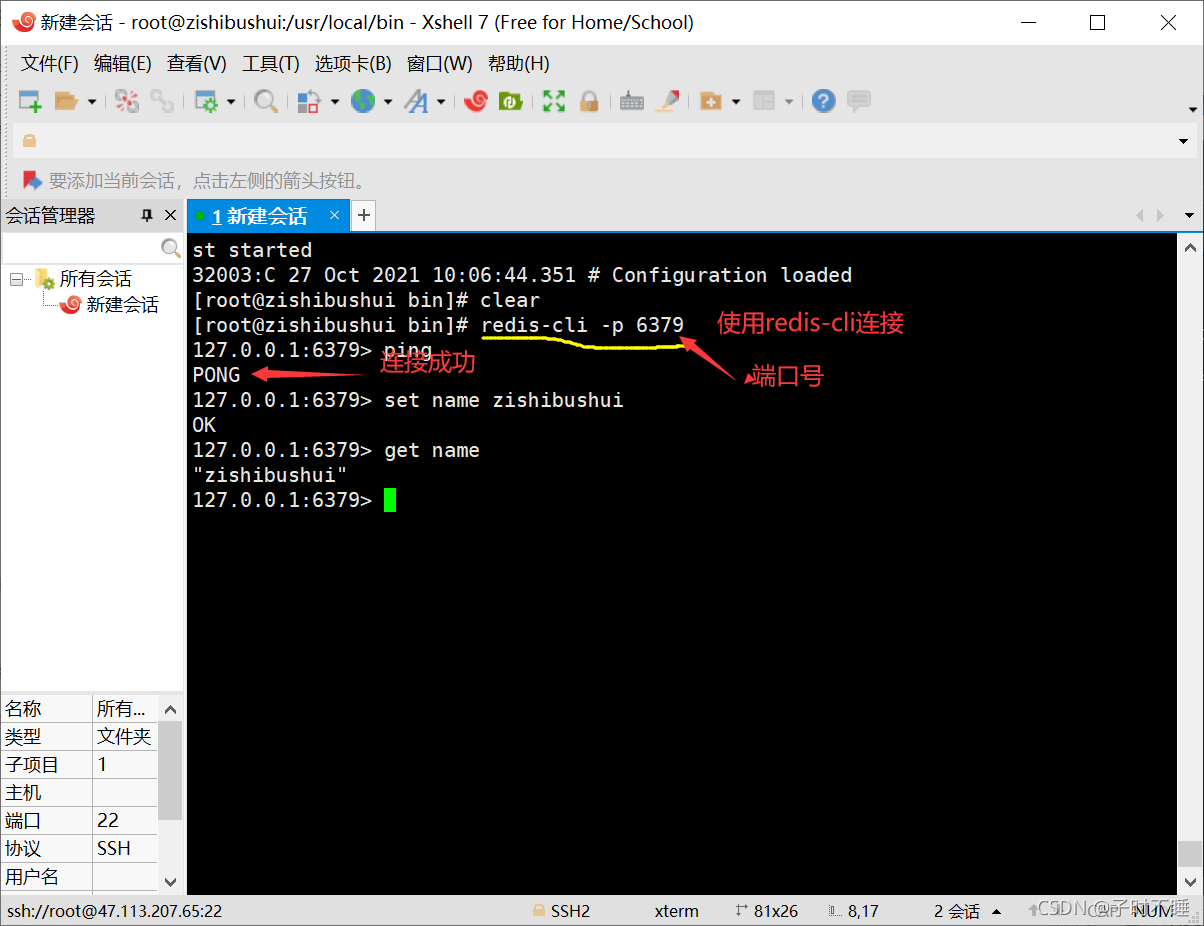
-
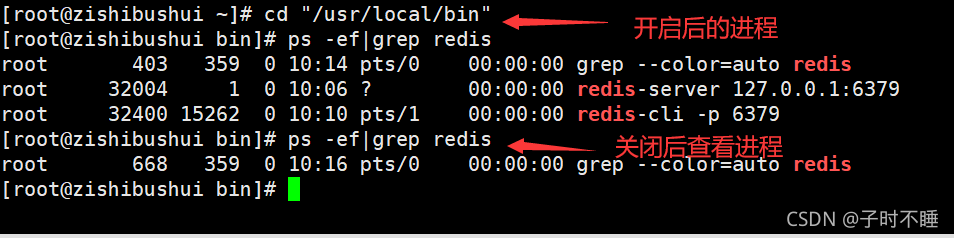
查看redis进程是否开启
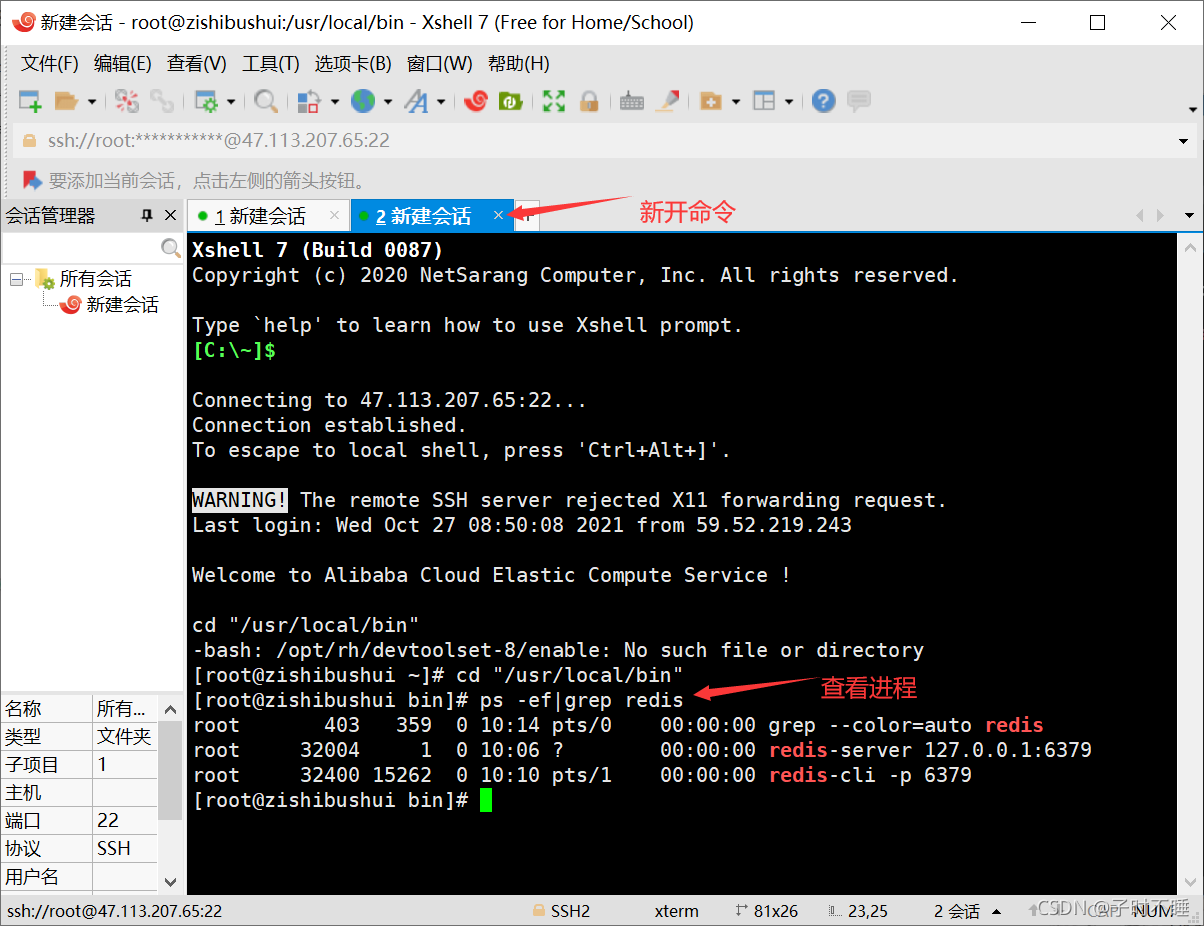
-
关闭redis服务
shutdown exit
性能测试
-
使用
redis-benchmark
语法
redis-benchmark [option] [option value]
可选参数如下
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 |
-h |
指定服务器主机名 | 127.0.0.1 |
| 2 |
-p |
指定服务器端口 | 6379 |
| 3 |
-s |
指定服务器 socket | |
| 4 |
-c |
指定并发连接数 | 50 |
| 5 |
-n |
指定请求数 | 10000 |
| 6 |
-d |
以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 |
-k |
1=keep alive 0=reconnect | 1 |
| 8 |
-r |
SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 |
-P |
通过管道传输 请求 | 1 |
| 10 |
-q |
强制退出 redis。仅显示 query/sec 值 | |
| 11 |
–csv |
以 CSV 格式输出 | |
| 12 |
* -l*(L 的小写字母) |
生成循环,永久执行测试 | |
| 13 |
-t |
仅运行以逗号分隔的测试命令列表。 | |
| 14 |
* -I*(i 的大写字母) |
Idle 模式。仅打开 N 个 idle 连接并等待。 |
-
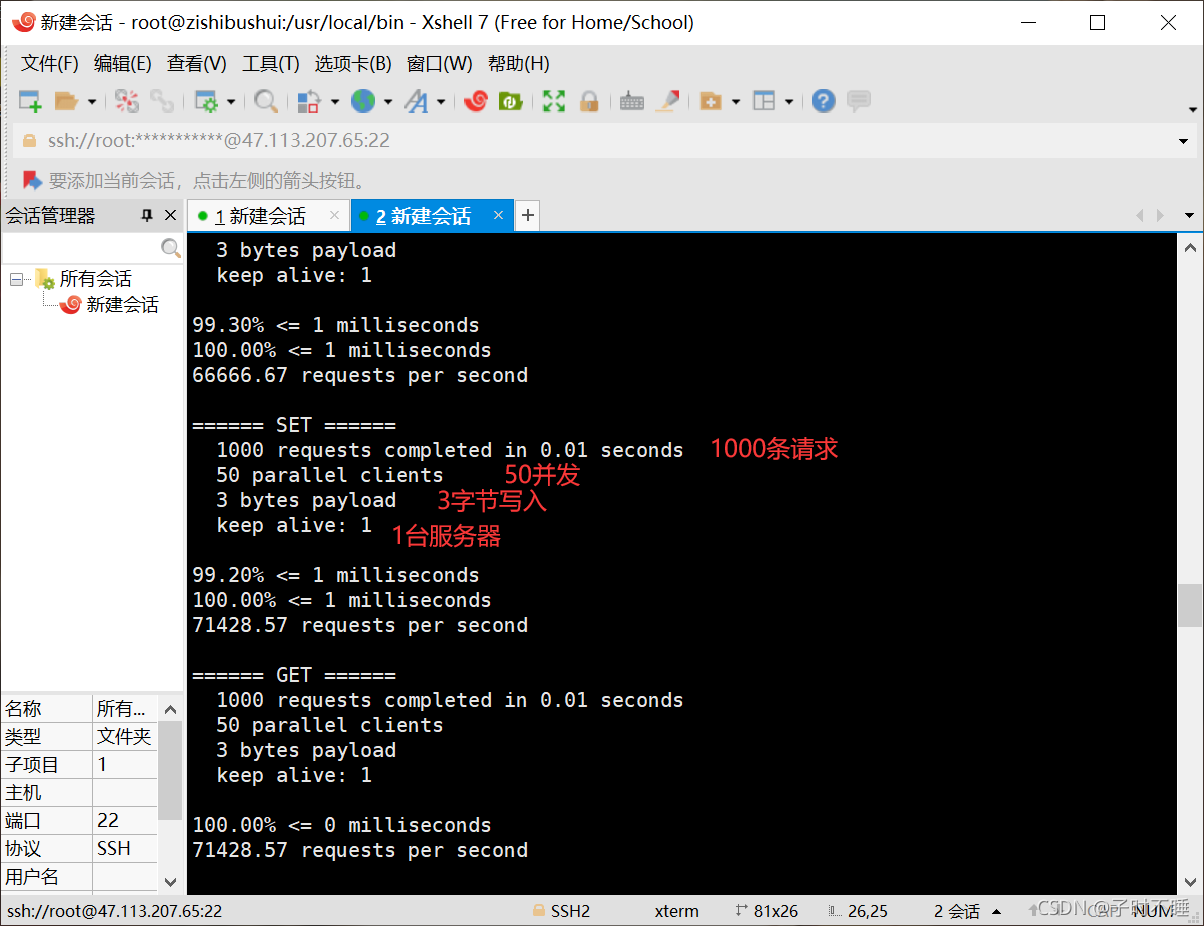
测试
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 1000
redis基本操作
- redis 有16个数据库,默认使用第0个
- redis对大小写不敏感
命令:
select
进行切换数据库
DEL key
key存在时删除
EXISTS key
判断key是否纯在
EXPIRE key seconds
给定key设置过期时间 (秒)
MOVE key db
将当前数据库的key移到给定的数据库中
TTL key
返回key的剩余生存秒
RENAME key newkey
修改key名字
TYPE key
返回key所对应值的类型
FLUSHALL
清空所有数据库
FLUSHDB
清空当前的数据库
127.0.0.1:6379> set name "zishibushui" #设置key-value
OK
127.0.0.1:6379> select 2 #切换数据库2
OK
127.0.0.1:6379[2]> keys * #查看所有key
(empty list or set)
127.0.0.1:6379[2]> set age 12
OK
127.0.0.1:6379[2]> keys *
1) "age"
127.0.0.1:6379[2]> select 0
OK
127.0.0.1:6379> keys *
1) "name"
2) "myset:__rand_int__"
3) "counter:__rand_int__"
4) "mylist"
5) "key:__rand_int__"
127.0.0.1:6379> DEL "myset:__rand_int__" #删除该key
(integer) 1
127.0.0.1:6379> DEL ["counter:__rand_int__","mylist"] #好像不能这样删除多个?
Invalid argument(s)
127.0.0.1:6379> EXISTS "mylist" #判断是否存在该key
(integer) 1
127.0.0.1:6379> EXPIRE "mylist" 10 #设置过期时间
(integer) 1
127.0.0.1:6379> keys *
1) "name"
2) "counter:__rand_int__"
3) "key:__rand_int__"
127.0.0.1:6379> RENAME "key:__rand_int__" "key3" #修改key名称
OK
127.0.0.1:6379> EXISTS name
(integer) 1
127.0.0.1:6379> EXPIRE key3 20
(integer) 1
127.0.0.1:6379> ttl key3
(integer) 2 #还剩2秒过期
127.0.0.1:6379> ttl key3
(integer) -2 #已被删除
127.0.0.1:6379> MOVE name 2 #将name key 移到数据库2中
(integer) 1
127.0.0.1:6379> keys*
(error) ERR unknown command `keys*`, with args beginning with:
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> select 2
OK
127.0.0.1:6379[2]> keys *
1) "age"
2) "name"
127.0.0.1:6379[2]> FLUSHALL
OK
127.0.0.1:6379[2]> keys *
(empty list or set)
Redis是单线程的
Redis很快,是居于内存操作,所以CPU不是redis的瓶颈,Redis的瓶颈是根据机器的内存和网络宽带。
Redis为什么单线程还这么快
1、误区1:高性能的服务器一定是多线程? ❌
2、误区2:多线程一定比单线程效率高? ❌
速度:CPU > 内存 > 硬盘 。但是多线程(CPU上下切换 是耗时的)
Redis是将所有数据都放在内存里,所以使用单线程去操作效率是最高的,多线程(CPU上下切换 :是耗时的操作!!!)对于内存系统来说,如果没有上下文切换效率就是最高的。多次读写都是在一个CPU上,在内存情况下,这就是最佳的方案。
Redis五大基本类型
1、String 类型
命令:
SET key value
指定key的值
GET key
获取指定key的值
GETRANGE key start end
返回key中字符串值得子字符
GETSET key value
将给定得key设置为value,并返回key得旧值
MSET key1 [key2..]
获取所有、一个或多个给定的值
SETNX key value
只有key不存在时,设置key得值
STRLEN key
获取key储存得value得长度
MSET key value[key value...]
同时设置一个或多个key-value
MSETNX key value[key value...]
同时设置一个或多个key-value,当且仅当所有key都不纯在时,否则都不成功
APPEND key value
如果key存在并且是一个字符串,将value添加到原来得末尾
127.0.0.1:6379> set name zishibushui
OK
127.0.0.1:6379> set name kangxiaozi
OK
127.0.0.1:6379> get name #值会被覆盖
"kangxiaozi"
127.0.0.1:6379> set name1 zishibushui
OK
127.0.0.1:6379> set name2 kangxiaozi
OK
127.0.0.1:6379> get name1
"zishibushui"
127.0.0.1:6379> getrange name2 0 -1 #获取key所有的字符
"kangxiaozi"
127.0.0.1:6379> getrange name1 0 -1
"zishibushui"
127.0.0.1:6379> getrange name 0 5 #获取下标0到5的字符。[0,5]闭区间
"kangxi"
127.0.0.1:6379> getrange name1 0 5
"zishib"
127.0.0.1:6379> getset name2 hukangzhe #先get再set
"kangxiaozi"
127.0.0.1:6379> getset name3 xiaoztongxue
(nil)
127.0.0.1:6379> get name2
"hukangzhe"
127.0.0.1:6379> get name3
"xiaoztongxue"
127.0.0.1:6379> mget name1 name2 name3 name4 #获取多个key的值
1) "zishibushui"
2) "hukangzhe"
3) "xiaoztongxue"
4) (nil)
127.0.0.1:6379> setnx name1 zishibushuishui #只有当key不存在时,设置值
(integer) 0 #失败
127.0.0.1:6379> set name4 suyu
OK
127.0.0.1:6379> append name4 suyu #向末尾添加value
(integer) 8
127.0.0.1:6379> mget name1 name2 name3 name4
1) "zishibushui"
2) "hukangzhe"
3) "xiaoztongxue"
4) "suyusuyu"
127.0.0.1:6379> mset name5 xiao name6 yang #多个设置
OK
127.0.0.1:6379> mget name1 name2 name3 name4 name5 name6
1) "zishibushui"
2) "hukangzhe"
3) "xiaoztongxue"
4) "suyusuyu"
5) "xiao"
6) "yang"
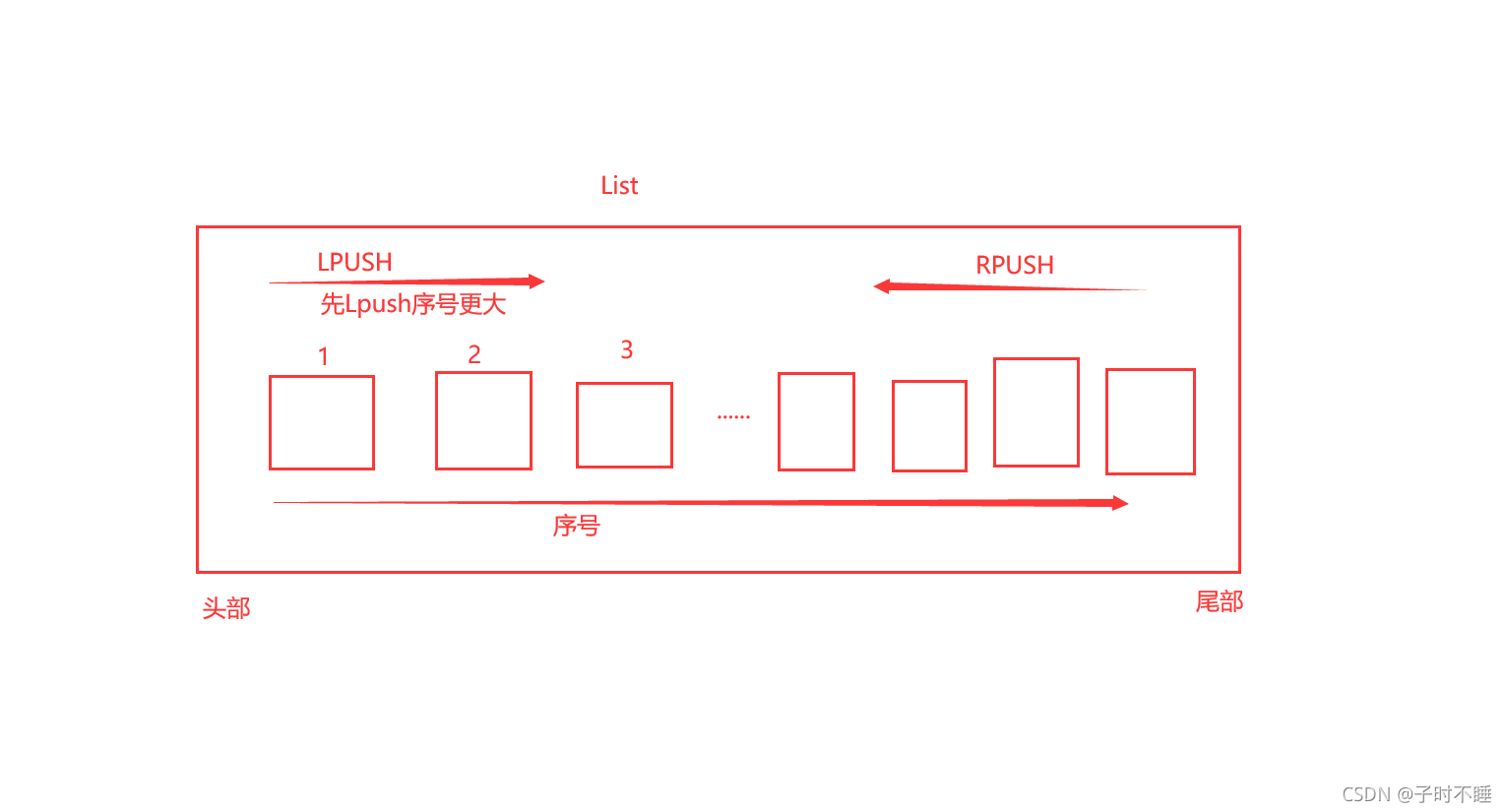
2、List(列表)
——————————增删改查——————————
LPUSH key value1 [value2]
从左边添加值
LPOP key
移除并获取列表的第一个元素
RPUSH key value1 [value2]
从右边添加值
RPOP key
移除列表的最后一个元素,返回值为移除的元素。
LINDEX key index
通过索引获取列表中的元素
LLEN key
获取列表长度
LREM key count value
移除列表中与参数value相同的值
- count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
- count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
- count = 0 : 移除表中所有与 VALUE 相等的值。
LTRIM key start stop
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除
LSET key index value
通过索引设置列表元素的值
LRANGE key start stop
获取列表指定范围内的元素
LINSERT key BEFORE|AFTER pivot value
在列表的前面或者后面插入元素
###############################################################
#头部尾部添加
#查询所有元素
127.0.0.1:6379> LPUSH list1 one two three #添加多个值
(integer) 3
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> RPUSH list1 zi shi bu shui #向尾部添加
(integer) 7
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "two"
3) "one"
4) "zi"
5) "shi"
6) "bu"
7) "shui"
###############################################################
#移除
127.0.0.1:6379> LPOP list1 #移除第一个(最左边)元素,并返回
"three"
127.0.0.1:6379> RPOP list1 #移除最后一个(最右边)元素,并返回
"shui"
127.0.0.1:6379> LRANGE list1 0 -1
1) "two"
2) "one"
3) "zi"
4) "shi"
5) "bu"
###############################################################
#查询长度 LLEN
127.0.0.1:6379> Llen list1
(integer) 5 #返回列表的长度
###############################################################
#精准移除 LREM key count value
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "three"
3) "one"
4) "two"
5) "one"
6) "zi"
7) "shi"
8) "bu"
127.0.0.1:6379> LREM list1 2 one #count>0,从表头开始搜索,移除2个one
(integer) 2 #表示移除了2个
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "three"
3) "two"
4) "zi"
5) "shi"
6) "bu"
127.0.0.1:6379> LREM list1 -2 zi #从表尾开始搜索,移除2个zi,如果zi小于2也移除
(integer) 1 #表示移除了1个
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "three"
3) "two"
4) "shi"
5) "bu"
###############################################################
#插入 LINSERT key BEFORE|AFTER pivot value
127.0.0.1:6379> LINSERT list1 before two one #在two前面插入one
(integer) 6
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "three"
3) "one"
4) "two"
5) "shi"
6) "bu"
###############################################################
#截断 LTRIM key start stop
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "three"
3) "one"
4) "two"
5) "shi"
6) "bu"
127.0.0.1:6379> LTRIM list1 1 5 #截断下标1到5,闭区间[1,5]
OK
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "one"
3) "two"
4) "shi"
5) "bu"
###############################################################
# 更新 LSET key index value
#RPOPLPUSH 移除列表最后一个值,到新的列表
127.0.0.1:6379> LSET list1 4 jiao #通过下标更改值
OK
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "one"
3) "two"
4) "shi"
5) "jiao"
127.0.0.1:6379> RPOPLPUSH list1 list3
"jiao"
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "one"
3) "two"
4) "shi"
###############################################################
问题:
redis 不是 key-value的键值对吗?可以可以是key对应列表。只能key是列表,value是列表中的值吗?
- 并不能单纯get 列表,来获取列表的值
127.0.0.1:6379> keys *
1) "list1"
2) "l1"
3) "list2"
127.0.0.1:6379> get l1
"list1"
127.0.0.1:6379> get list1
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get list2
(error) WRONGTYPE Operation against a key holding the wrong kind of value
3、Set(集合)
无序不重复
——————————增删改查——————————
SADD key member1[mermber2]
向集合添加一个或多个成员
SCARD key
获取集合的成员数量
SMEMBERS key
获取所有成员
SISMEMBER key member
判断member是否是集合成员
SPOP key
移除并返回一个随机成员
SMOVE source destination member
将member从source集合移到destination集合
SREM key member1[member2]
移除一个或多个成员
SRANDMEMBER key [count]
返回一个或count个成员
—————————-数学集合的交并补——————–
SDIFF key1 [key2]
返回第一个集合与其他集合之间的差异。
SDIFFSTORE destination key1 [key2]
返回给定所有集合的差集并存储在 destination 中
SINTER key1 [key2]
返回给定所有集合的交集
SINTERSTORE destination key1 [key2]
返回给定所有集合的交集并存储在 destination 中
SUNION key1 [key2]
返回所有给定集合的并集
SUNION STORE destination key1 [key2]
所有给定集合的并集存储在 destination 集合中
###############################################################
127.0.0.1:6379> SADD myset hello #添加一个值
(integer) 1
127.0.0.1:6379> SADD myset world and zishibushui #添加多个值
(integer) 3
127.0.0.1:6379> SCARD myset #查看set中的成员个数
(integer) 4
127.0.0.1:6379> SMEMBERS myset #查看所有成员
1) "and"
2) "world"
3) "hello"
4) "zishibushui"
127.0.0.1:6379> SISMEMBER myset hello #判断set是否包含值
(integer) 1
127.0.0.1:6379> SISMEMBER myset you
(integer) 0
###############################################################
#随机移除
127.0.0.1:6379> SPOP myset #随机移除一个值
"hello"
127.0.0.1:6379> SPOP myset 2 #随机移除多个值
1) "and"
2) "zishibushui"
127.0.0.1:6379> SMEMBERS myset
1) "world"
###############################################################
#精准移除
#移动
127.0.0.1:6379> SMEMBERS myset
1) "my"
2) "hello"
3) "world"
127.0.0.1:6379> SREM myset hello #移除指定元素
(integer) 1
127.0.0.1:6379> SMOVE myset tempset my #将my元素从myset移动到tempset
(integer) 1
127.0.0.1:6379> smembers myset
1) "world"
127.0.0.1:6379> SMEMBERS tempset
1) "my"
127.0.0.1:6379>
###############################################################
#随机返回元素(并不是移除)
127.0.0.1:6379> SMEMBERS myset
1) "my"
2) "hello"
3) "world"
4) "zishibushui"
5) "your"
127.0.0.1:6379> SRANDMEMBER myset #随机返回一个元素
"world"
127.0.0.1:6379> SRANDMEMBER myset 2 #随机返回两个元素
1) "world"
2) "your"
127.0.0.1:6379> SMEMBERS myset
1) "zishibushui"
2) "world"
3) "hello"
4) "your"
5) "my"
#####################################################
#数学集合的交并补 #tempste:{my}
#myset:{your,hello,world,zishibushui,my}
127.0.0.1:6379> SDIFF myset tempset #差值
1) "your"
2) "hello"
3) "world"
4) "zishibushui"
127.0.0.1:6379> SINTER myset tempset #交值
1) "my"
127.0.0.1:6379> SUNION myset tempset #并值
1) "zishibushui"
2) "world"
3) "hello"
4) "your"
5) "my"
4、Hash(哈希)
Redis hash 是一个string类型的field(字段)和value(值)的映射表,特别适合存储对象
——————————增——————————
HMSET key field1 value1[field2 value2]
设置多个值
HSET key field value
HSETNX key field value
只有当字段不存在时,设置
———————————-查———————————–
HGET key field
获取字段的值
HMGET key field1 [field2]
获取所有给定字段的值
HGETALL key
获取所有的字段和值
HKEYS key
获取所有哈希表中的字段
HLEN key
获取哈希表中字段的数量
HVALS key
获取哈希表中所有值
HEXISTS key field
查看哈希表key中,指定的字段是否存在
——————————删—————————————-
HDEL key field1 [field2]
删除一个或多个字段
—————————–改—————————————–
HINCRBY key field increment
HINCRBYFLOAT key field increment
5、ZSet(有序集合)
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
ZADD key score1 member1[score2 member2]
向一个有序集合添加一个或多个成员
ZREM key member1 [member2]
移除一个或多个成员
ZREMRANGEBYLEX key min max
移除有序集合中给定的字典区间的所有成员
ZREMRANGEBYRANK key start stop
移除有序集合中给定的排名区间的所有成员
ZREMRANGEBYSCORE key min max
移除有序集合中给定的分数区间的所有成员
ZCARD key
获取有序集合的成员数
ZCOUNT key min max
计算在有序集合中指定区间的成员数
ZLEXCOUNT key min max
在有序集合中计算指定字典区间内成员数量
ZRANGE key start stop
通过索引区间返回有序集合指定区间内的成员
ZRANGEBYLEX key min max
通过字典区间返回有序集合的成员
ZRANGEBYSCORE key min max
通过分数返回有序集合指定区间内的成员
ZRANK key member1
返回有序集合中指定成员的索引
ZSCORE key member
返回成员的分数
ZREVRANK key member
返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
ZREVRANGEBYSCORE key max min
返回有序集中指定分数区间内的成员,分数从高到低排序
特殊类型
1、地理空间geospatial
-
GEOADD
-
GEODIST
-
GEOHASH
-
GEOPOS 返回由
key
处的排序集表示的地理空间索引的所有指定成员的位置(经度、纬度)。 -
GEORADIUS
-
GEORADIUSBYMEMBER
-
GEOSEARCH
-
GEOSEARCHSTORE
GEOADD key 经度 维度 名称
127.0.0.1:6379> GEOADD china:city 115.89 28.67 nanchang 121.47 31.23 shanghai
(integer) 2
127.0.0.1:6379> GEOADD china:city 118.76 32.04 nanjing
(integer) 1
127.0.0.1:6379> GEOADD china:city 114.08 22.54 shenzhen
(integer) 1
GEOPOS 获取经纬度
127.0.0.1:6379> GEOPOS china:city shenzhen
1) 1) "114.08000081777572632"
2) "22.53999903789756587"
127.0.0.1:6379> GEOPOS china:city nanchang shanghai
1) 1) "115.88999837636947632"
2) "28.66999910629679249"
2) 1) "121.47000163793563843"
2) "31.22999903975783553"
GEODIST:获取两地之间的距离
默认单位米
-
m
为米。 -
km
为公里。 -
mi
数英里。 -
ft
为英尺。
127.0.0.1:6379> GEODIST china:city nanchang shanghai
"608368.9697"
127.0.0.1:6379> GEODIST china:city nanchang shanghai km
"608.3690"
GEORADIUS
根据 Redis 6.2.0,GEORADIUS 命令系列被视为
已弃用
。请在新代码中
优先
选择
GEOSEARCH
和
GEOSEARCHSTORE
。
-
WITHDIST
: 同时返回返回的物品与指定中心的距离。距离以与命令的半径参数指定的单位相同的单位返回。 -
WITHCOORD
: 同时返回匹配项的经纬度坐标。 -
WITHHASH
:还以 52 位无符号整数的形式返回项目的原始 geohash 编码的排序集分数。这仅对低级黑客或调试有用,否则一般用户几乎没有兴趣。
命令默认是返回未排序的项目。可以使用以下两个选项调用两种不同的排序方法:
-
ASC
:相对于中心,从最近到最远对返回的项目进行排序。 -
DESC
:相对于中心,从最远到最近对返回的项目进行排序
默认情况下,该命令将项目返回给客户端。可以使用以下选项之一存储结果:
-
STORE
:将项目存储在填充了其地理空间信息的排序集中。 -
STOREDIST
:将项目存储在一个排序的集合中,以它们到中心的距离作为浮点数,以半径中指定的相同单位填充。
127.0.0.1:6379> GEORADIUS china:city 115.89 28.67 700 km WITHCOORD
1) 1) "nanchang"
2) 1) "115.88999837636947632"
2) "28.66999910629679249"
2) 1) "shanghai"
2) 1) "121.47000163793563843"
2) "31.22999903975783553"
3) 1) "nanjing"
2) 1) "118.75999957323074341"
2) "32.03999960287850968"
127.0.0.1:6379> GEORADIUS china:city 115.89 28.67 700 km WITHCOORD ASC
1) 1) "nanchang"
2) 1) "115.88999837636947632"
2) "28.66999910629679249"
2) 1) "nanjing"
2) 1) "118.75999957323074341"
2) "32.03999960287850968"
3) 1) "shanghai"
2) 1) "121.47000163793563843"
2) "31.22999903975783553"
127.0.0.1:6379> GEORADIUS china:city 114 28 700 km WITHDIST DESC
1) 1) "nanjing"
2) "641.7613"
2) 1) "shenzhen"
2) "607.3489"
3) 1) "nanchang"
2) "199.4704"
GEORADIUSBYMEMBER
该命令与
GEORADIUS
完全一样,唯一的区别是,它不以经纬度值作为要查询的区域的中心,而是以排序集表示的地理空间索引中已经存在的成员的名称。
根据 Redis 6.2.0,GEORADIUS 命令系列被视为已弃用。请在新代码中
优先
选择
GEOSEARCH
和
GEOSEARCHSTORE
。
127.0.0.1:6379> GEORADIUSBYMEMBER china:city nanchang 700 km WITHDIST DESC
1) 1) "shanghai"
2) "608.3690"
2) 1) "nanjing"
2) "465.1110"
3) 1) "nanchang"
2) "0.0000"
GEOHASH
返回有效的
Geohash
字符串,表示一个或多个元素在表示地理空间索引的排序集合值中的位置(其中元素是使用
GEOADD
添加的)
将二维的经度转成一维字符串
#如果这两个字符越接近,就代表距离越近
127.0.0.1:6379> GEOHASH china:city nanchang shanghai
1) "wt47j5hwbe0"
2) "wtw3sj5zbj0"
GEO底层的实现原理就是Zset
一些Zset操作GEO
127.0.0.1:6379> ZRANGE china:city 0 -1 #查看所有元素
1) "shenzhen"
2) "nanchang"
3) "shanghai"
4) "nanjing"
127.0.0.1:6379> ZREM china:city nanjing #移除一个元素
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "shenzhen"
2) "nanchang"
3) "shanghai"