二叉树的遍历
以下会通过递归和迭代两种方法来实现二叉树的遍历,并通过前中后序三种方式来表达。
首先给出前序、后序、中序三种情况在leetcode上对应的题目。
二叉树的前序遍历
二叉树的后序遍历
二叉树的中序遍历
递归
首先,递归需要记住以下三个步骤,可以解决大部分的递归问题的逻辑:
-
确定递归函数的参数和返回值:
明确哪些参数是要参与递归过程的,以及确定每次递归的返回值。 -
确定终止条件:
如果递归没有终止,那么就会造成溢出。 -
确定单层递归的逻辑:
确定每一层递归需要完成的内容。
前序遍历
思路
- 确定递归函数的参数和返回值:因为需要将答案记录在vector<int>中,所以需要在函数定义的时候加上这个数组,其他的不需要额外处理,所以函数类型为void,每次递归就是返回一个数组就好。
- 确定终止条件:就是当前遍历到的节点是NULL时,结束当前遍历过程。
- 确定单层递归的逻辑:因为是前序遍历,所以是一个左中右的进入顺序,所以先将当前节点存入数组,然后对左子树和右子树进行遍历。
代码
class Solution {
public:
void traversal(TreeNode* root, vector<int>& vec){
if(root == NULL){
return ;
}
vec.push_back(root->val);
traversal(root->left, vec);
traversal(root->right, vec);
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> ans;
traversal(root, ans);
return ans;
}
};
后序遍历
思路
和前序遍历一样,进行三个步骤的思考。基本一致,就是在单层逻辑上用后序遍历的思想,按照左右中的顺序。
代码
class Solution {
public:
void traversal(TreeNode* root, vector<int>& vec){
if(root == NULL){
return ;
}
traversal(root->left, vec);
traversal(root->right, vec);
vec.push_back(root->val);
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> ans;
traversal(root, ans);
return ans;
}
};
中序遍历
思路
一致。使用中序遍历的顺序,左中右进行输入。
代码
class Solution {
public:
void traversal(TreeNode* root, vector<int>& vec){
if(root == NULL){
return ;
}
traversal(root->left, vec);
vec.push_back(root->val);
traversal(root->right, vec);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> ans;
traversal(root, ans);
return ans;
}
};
迭代(非递归)
递归的
实质
就是每一次递归都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后在递归返回的时候,栈顶弹出上一次递归的各项参数,所以这就是递归可以返回上一层位置的原因。
所以这里我们也可以用栈来实现二叉树的前中后序遍历。
前序遍历
思路
前序遍历是中左右,每次先处理中间节点,所以先加入根节点,然后放入右节点,最后放入左节点。
为什么明明是中左右的顺序,但是在进入栈的时候要中 右 左 呢?
因为根节点在入栈之后最先出栈了,完成了中左右的中。但是左右子树还要分别向下迭代,由于栈是先进后出的,所以需要让左先出栈的话,右子树需要先进入栈中。
代码
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> ans;
if(root == NULL){//根节点为空,直接结束
return ans;
}
stk.push(root);
while(!stk.empty()){
TreeNode* node = stk.top();
stk.pop();
ans.push_back(node->val);// 中
if(node->right){
stk.push(node->right);// 右(NULL)不入栈
}
if(node->left){
stk.push(node->left);// 左(NULL)不入栈
}
}
return ans;
}
};
后序遍历
思路
前序遍历是中左右,后序遍历是左右中,这里可以通过几次变换得到。
前序遍历:中左右。
通过调换左右的入栈顺序可以得到中间过程:中右左
然后进行整个数组的反转可以得到:左右中,即后序遍历
代码
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> ans;
if(root == NULL){//根节点为空
return ans;
}
stk.push(root);
while(!stk.empty()){
TreeNode* node = stk.top();
stk.pop();
ans.push_back(node->val);// 中
if(node->left){
stk.push(node->left);// 左
}
if(node->right){
stk.push(node->right);//右
}
}
reverse(ans.begin(), ans.end());
return ans;
}
};
中序遍历
思路
中序遍历的过程和前序后序不太一样,由于不是先处理中,但是得先运行到中,即处理和运行顺序不一致,所以不好直接对中进行简单处理。这里需要用指针来进行遍历。由于中序遍历是左中右,所以要先遍历到左子树的最左下角的节点,然后再进行输出,期间要保存每个路径的节点信息到数组。
代码
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> ans;
if(root == NULL){
return ans;
}
TreeNode* cur = root;
while(cur || !stk.empty()){
if(cur){//cur不为空,进入栈
stk.push(cur);
cur = cur->left;
}
else{
cur = stk.top();//此前cur已经是NULL,所以现在要回到父节点,然后对右节点进行判断,同时输出父节点
stk.pop();
ans.push_back(cur->val);
cur = cur->right;
}
}
return ans;
}
};
两道练手题目
剑指 Offer 07. 重建二叉树
思路
首先需要了解前序遍历和中序遍历。可知的是前序遍历的第一个为根节点,可以以此作为index来查找在中序遍历中的位置,从而划分出左子树和右子树。
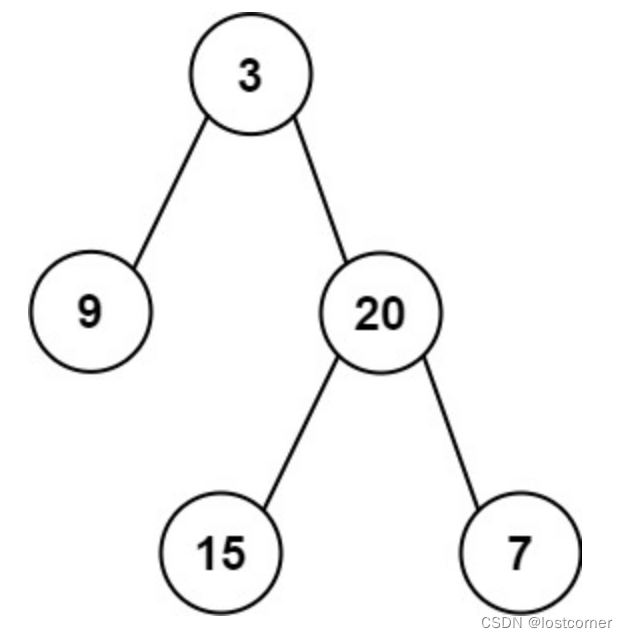
以此树为例:
前序遍历为[3, 9, 20, 15, 7]
中序遍历为[9, 3, 15, 20, 7]
其中根节点为[
3
, 9, 20, 15, 7]中的
3
,在中序遍历中的位置为[9,
3
, 15, 20, 7]。
所以可以划分左右子树为
前序遍历为[
3
, (9), {20, 15, 7}]
中序遍历为[(9),
3
, {15, 20, 7}]
然后可以继续分解为子问题,针对每一个树再重复一次,所以这里需要一个函数。
这个函数需要定义要分解的子树再前序遍历中的左边界l1和右边界r1,以及在中序遍历中的左边界l2和右边界r2。
TreeNode* build(vector<int>& preorder, int l1, int r1, vector<int>& inorder, int l2, int r2)
这是一个递归函数,所以要确定结束条件为左边界超过右边界
if(l1 > r1 && l2 > r2){
return NULL;
}
然后需要探讨子树的边界怎么划分。
首先要得到根节点在中序遍历中的下标i
对于根节点的左子树,其中序遍历数组为
[(9),
3
, {15, 20, 7}]
根节点的下标为
i
左子树的左边界为
l2
,右边界为
i - 1
右子树的左边界为
i + 1
,右边界为
r2
前序遍历数组为
[
3
, (9), {20, 15, 7}]
根节点的下标为
l1
左子树的左边界
l1 + 1
,右边界为
l1 + (i - l2)
右子树的左边界为
l1 + (i - l2) + 1
,其实就是左子树右边界+1,右边界为
r2
然后在主函数中先对中序遍历进行映射,然后运行递归函数,得到结果。
代码
class Solution {
public:
//用哈希表来映射中序遍历的值和下标
unordered_map<int,int> umap;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
for(int i = 0; i < inorder.size(); i++){
umap[inorder[i]] = i;
}
return build(preorder, 0, preorder.size() - 1, inorder, 0, inorder.size() - 1);
}
TreeNode* build(vector<int>& preorder, int l1, int r1, vector<int>& inorder, int l2, int r2){
//终止条件
if(l1 > r1 && l2 > r2){
return NULL;
}
//先定义root节点
TreeNode* root = new TreeNode(preorder[l1]);
//找到中序遍历中的root节点,即前序遍历的第一个
int i = umap[preorder[l1]];
//分解成子问题,进行递归
root->left = build(preorder, l1 + 1, l1 + (i - l2), inorder, l2, i - 1);
root->right = build(preorder, l1 + (i - l2) + 1, r1, inorder, i + 1, r2);
return root;
}
};
剑指 Offer 33. 二叉搜索树的后序遍历序列
思路
首先需要了解后序遍历,数组的最后一个元素就是根节点,前面分成两个部分,先是左子树然后是右子树。
这道题目用的是BST,BST的特点就是左子树的数值都比root的数值校,右子树都比root大。
所以一个正确的BST的后序遍历数组应该是:从头开始遍历找到的第一个比root大的数,前面的都是左子树,之后到最后一个元素之前都是右子树。
据此,可以写出以下代码。由于子树中的所有节点的值都小于root,但是子树中还有子树,所以需要用递归来判断所有的节点。
代码
class Solution {
public:
bool verifyPostorder(vector<int>& postorder) {
return check(postorder, 0, postorder.size() - 1);
}
bool check(vector<int>& postorder, int i, int j){//i,j 分别为左边界和右边界的下标
//终止条件
if(i >= j){
return true;
}
int root = postorder[j];
//因为后序遍历是左右中,所以左子树和右子树的边界都比较好定义,一个参数就够了
int left = i;//左子树的边界
while(left < j && postorder[left] < root){//BST的左子树都比root小
left++;
}
int right = left;//右子树的左边界从左子树的右边界+1开始,之前的left++了,所以left这时候就是右子树的左边界
while(right < j && postorder[right] > root){
right++;
}
if(right != j){//如果right不能遍历到数组的最后一位,说明数组不满足BST的后序遍历
return false;
}
return check(postorder, i, left - 1) && check(postorder, left, j - 1);
}
};
再来两道BST的题目
剑指 Offer 54. 二叉搜索树的第k大节点
思路
首先是BST,特性就是左子树和右子树的所有节点都分别小于或者大于root。所以为了得到递增的效果,需要用中序遍历的方法。
代码
class Solution {
public:
vector<int> vec;
int kthLargest(TreeNode* root, int k) {
inorder(root);
return vec[vec.size()-k];
}
void inorder(TreeNode* root){
if(root == NULL){
return ;
}
inorder(root->left);
vec.push_back(root->val);
inorder(root->right);
}
};
改进
但是这样用了一个vector,然而除了第k大的数都用不上,所以为了降低空间复杂度,可以用一个参数来指定输出结果。
因为不能统计整个vector的数量,所以可以稍微改一下中序遍历的输出,改为右中左的顺序,这样的输出结果就是一个降序的过程,可以直接得到第k大的数。
class Solution {
public:
int ans;
int rank = 0;
int kthLargest(TreeNode* root, int k) {
inorder(root, k);
return ans;
}
void inorder(TreeNode* root, int k){
if(root == NULL){
return ;
}
inorder(root->right, k);
rank++;
if(rank == k){
ans = root->val;
return ;
}
inorder(root->left, k);
}
};
练习
把中序遍历用非递归的方法来一次。
class Solution {
public:
int kthLargest(TreeNode* root, int k) {
return inorder(root, k);
}
int inorder(TreeNode* root, int k){
stack<TreeNode*> stk;
vector<int> vec;
int ans;
if(root == NULL){
return ans;
}
TreeNode* cur = root;
while(cur || !stk.empty()){
if(cur){
stk.push(cur);
cur = cur->right;
}
else{
cur = stk.top();
stk.pop();
vec.push_back(cur->val);
cur = cur->left;
}
}
for(int i = 0; i < k ; i++){
ans = vec[i];
}
return ans;
}
};
不用vector来辅助,直接用一个int来记录结果
class Solution {
public:
int kthLargest(TreeNode* root, int k) {
return inorder(root, k);
}
int inorder(TreeNode* root, int k){
stack<TreeNode*> stk;
int ans;
int rank = 0;
if(root == NULL){
return ans;
}
TreeNode* cur = root;
while(cur || !stk.empty()){
if(cur){
stk.push(cur);
cur = cur->right;
}
else{
cur = stk.top();
stk.pop();
//开始中序过程
rank++;
if(rank == k){
ans = cur->val;
return ans;
}
cur = cur->left;
}
}
return ans;
}
};
剑指 Offer 68 – I. 二叉搜索树的最近公共祖先
思路
BST的特点是左子树都小于root,右子树都大于root。
所以从root开始遍历,只有三种情况:
- 如果p和q都小于root,说明公共祖先节点在root的左侧
- 如果p和q都大于root,说明公共祖先节点在root的右侧
- 如果p和q分别在一左一右,说明当前就是公共祖先节点。
代码
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
while(root){
if(p->val < root->val && q->val < root->val){
root = root->left;
}
else if(p->val > root->val && q->val > root->val){
root = root->right;
}
else{
return root;
}
}
return NULL;
}
};
再来点二叉树的题目
剑指 Offer 37. 序列化二叉树
思路
这道题需要先对给出的二叉树结构进行序列化,得到字符串来记录二叉树的每个节点的值和构成顺序。然后要对这个字符串进行反序列化,得到对应的二叉树结构。
这里采用迭代、前序遍历的方式来进行。
在序列化过程中用一个辅助函数来迭代,得到一个字符串。
在反序列化过程中先在主函数中对字符串进行拆解,得到vector来存储节点信息。再用一个辅助函数对对应的vector进行抽离,将vector的第一个元素作为节点进行二叉树的构建。
代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
string SEP = ",";
string EMPTY = "#";//这里就用单个字符,否则会超时
// Encodes a tree to a single string.
//序列化,这里用前序遍历
//主函数
string serialize(TreeNode* root) {
string ans = "";
serialize(root, ans);
return ans;
}
//辅助函数
void serialize(TreeNode* root, string& ans){
if(root == NULL){
ans += EMPTY + SEP;
return ;
}
//===============
//preorder
ans += to_string(root->val) + SEP;
//===============
serialize(root->left, ans);
serialize(root->right, ans);
}
// Decodes your encoded data to tree.
//反序列化,也是前序遍历
//主函数
TreeNode* deserialize(string data) {
cout<<data<<endl;
vector<string> nodes;
string str = "";//记录每一个节点的值
for(auto c : data){
if(c == SEP[0]){
nodes.push_back(str);
str = "";
}
else{
str += c;
}
}
for(auto x:nodes){
cout<<x<<' ';
}
cout<<endl;
return deserialize(nodes);
}
//辅助函数
TreeNode* deserialize(vector<string>& nodes){
if(nodes.empty()){
return NULL;
}
//===============
//preorder
string temp = nodes[0];
nodes.erase(nodes.begin());
if(temp == EMPTY){
return NULL;
}
TreeNode* root = new TreeNode(stoi(temp));
//===============
root->left = deserialize(nodes);
root->right = deserialize(nodes);
return root;
}
};
// Your Codec object will be instantiated and called as such:
// Codec codec;
// codec.deserialize(codec.serialize(root));
543. 二叉树的直径
思路
就是相当于左右子树的最大深度之和,所以辅助函数就可以直接用一个递归函数来得到每个节点的左右子树的最大高度,得出每个节点的直径。
代码
class Solution {
public:
int ans = 0;
int diameterOfBinaryTree(TreeNode* root) {
dfs(root);
return ans;
}
int dfs(TreeNode* root){
if(root == NULL){
return 0;
}
int left = dfs(root->left);
int right = dfs(root->right);
ans = max(ans, left + right);
return 1 + max(left, right);
}
};
199.二叉树的右视图
思路
就是层序遍历的那一套,只是只存最后这一个节点的值。
代码
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
queue<TreeNode*> que;
vector<int> ans;
if(root == NULL){
return ans;
}
que.push(root);
while(!que.empty()){
int size = que.size();
while(size--){
TreeNode* temp = que.front();
if(size == 0){
ans.push_back(temp->val);
}
que.pop();
if(temp->left) que.push(temp->left);
if(temp->right) que.push(temp->right);
}
}
return ans;
}
};