一、MapReduce程序运行模式
概述
所谓的运行模式指的是︰
MapReduce程序是单机运行还是分布式运行?
MapReduce程序需要的运算资源是Hadoop YARN分配还是本机系统自己分配?
●运行在何种模式取决于参数:mapreduce.framework.name
yarn : YARN集群模式
local :本地模式
●如果不指定,默认是local模式。
在mapred-default.xml中定义。
如果代码中( conf. set )、运行的环境中有配置( mapred-site.xml ),会默认覆盖default配置。
(一)YARN集群模式
MapReduce程序提交给yarn集群,分发到多个节点上分布式并发执行。数据通常位于HDFS.需要配置参数︰
mapreduce.framework. name=yarn
yarn. resourcemanager. hostname=node1.itcast.cn
提交集群的实现步骤︰
确保Hadoop集群启动(HDFS集群、YARN集群);
将程序打成jar包,上传jar到Hadoop集群的任意一个节点;执行命令启动。

clean一下
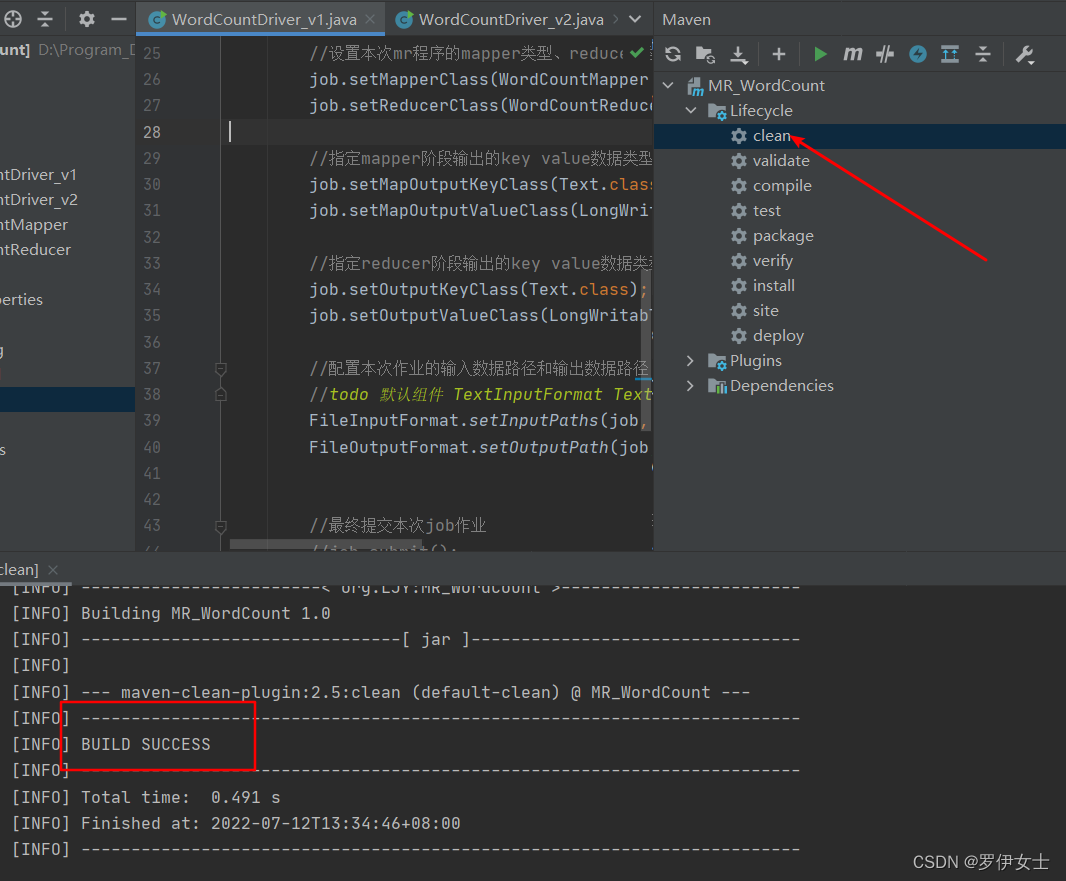
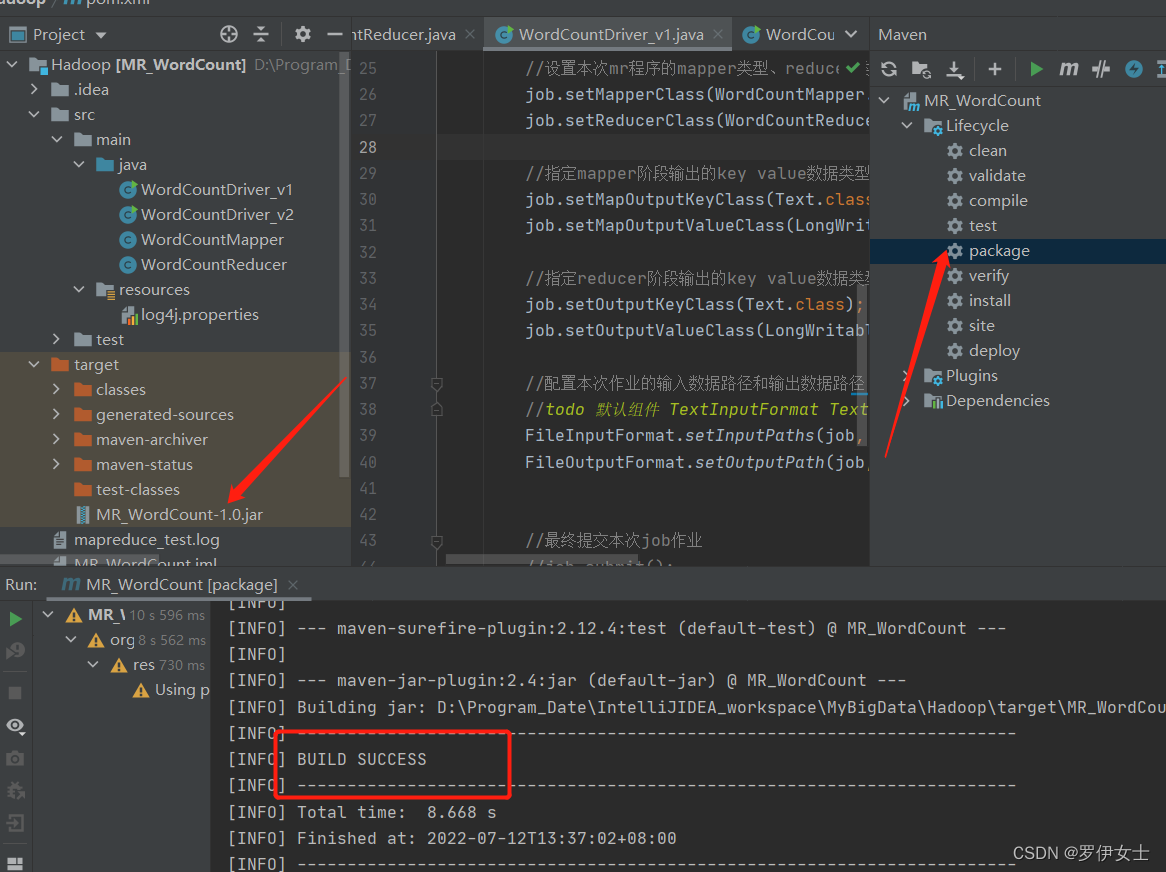
打成jar包
打开虚拟机,且确认hadoop的节点已经启动
访问http协议web信息界面,本人的端口号是50070,网址格式为:http://ip名称 :50070 把要读取的文本文件存放到某个路径中
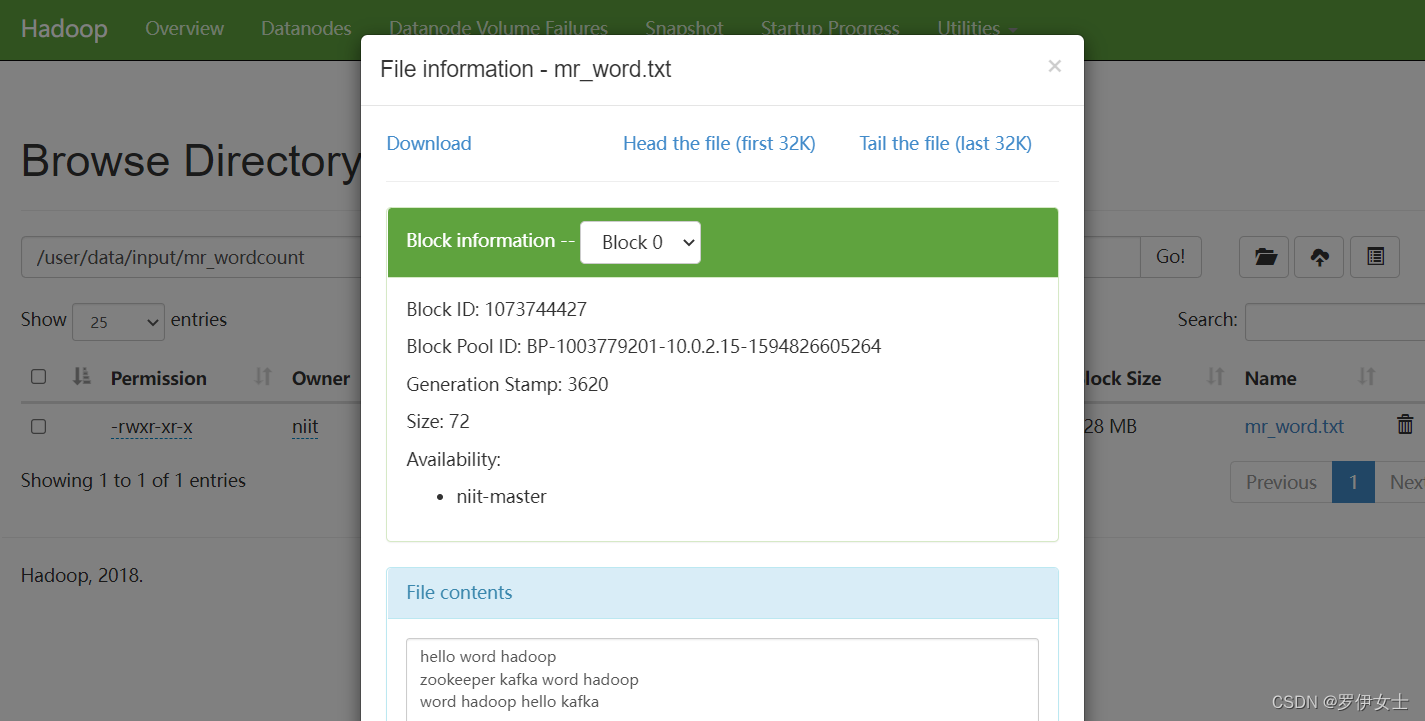
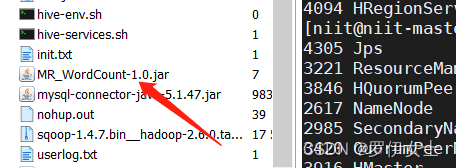
把jar包移到虚拟机的文件目录下
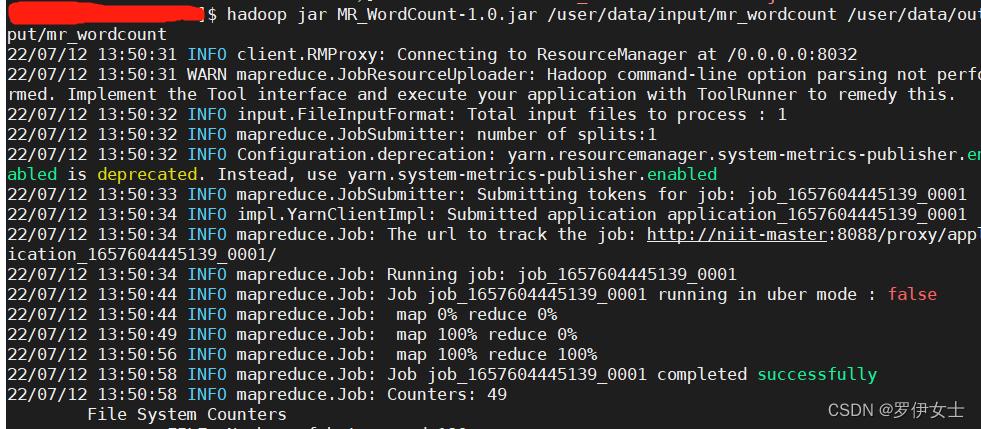
输入指令: hadoop jar jar包名称 输入路径 输出路径
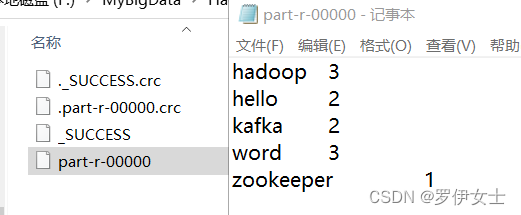
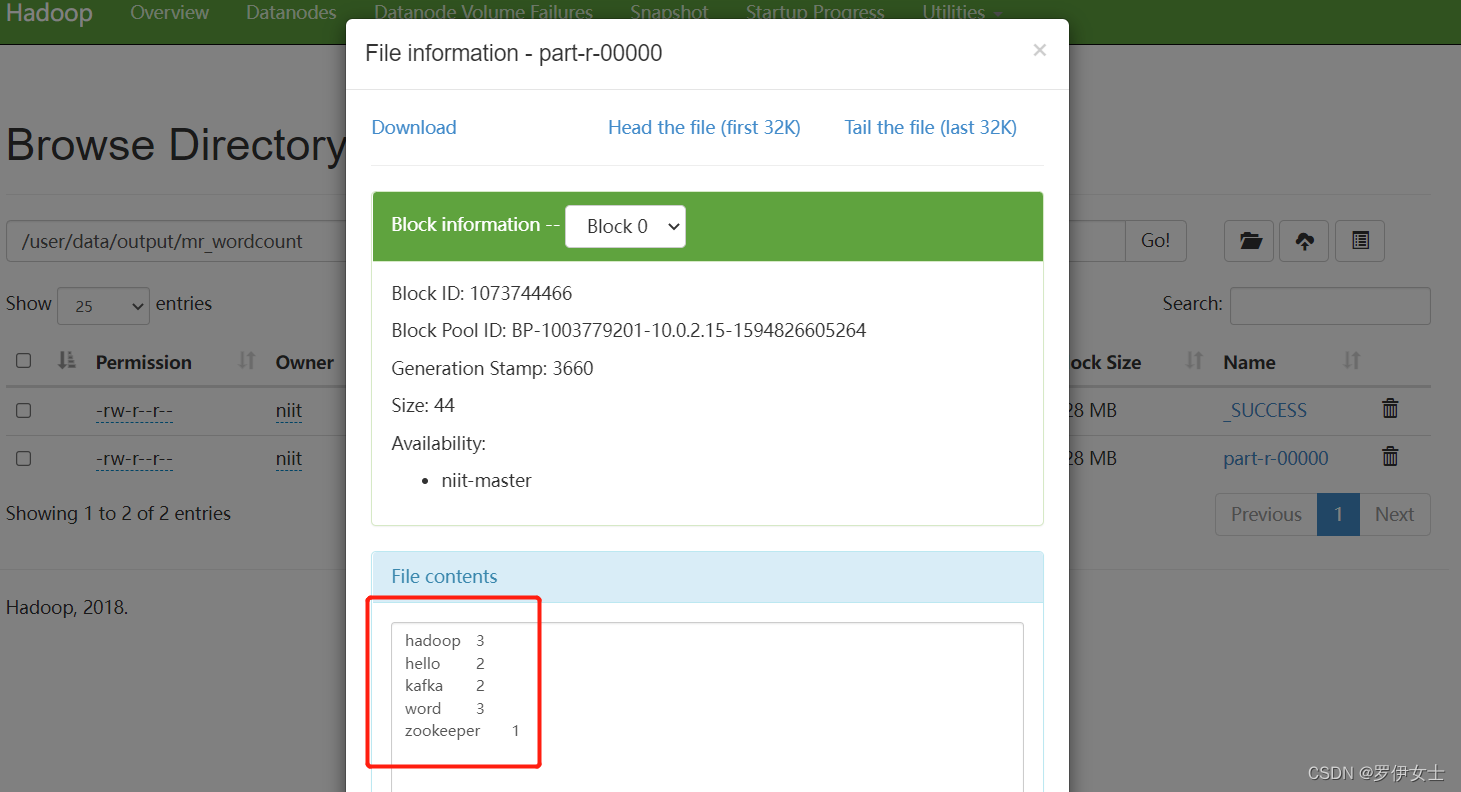
打开输出路径,即可看到结果
(二)Local本地模式
MapReduce程序是被提交给LocalJobRunner在本地以单进程的形式运行。是单机程序。输入和输出的数据可以在本地文件系统,也可以在HDFS上。
本地模式非常便于进行业务逻辑的debug。
右键直接运行main方法所在的主类即可。
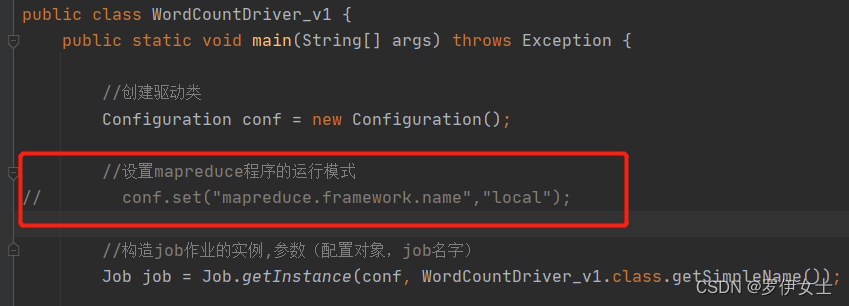
设置mapreduce的运行模式
如果默认是本地模式,可以不用写以下代码
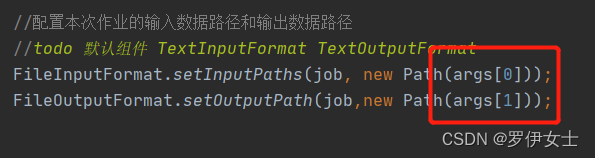
因为这个路径是以动态传参的形式,所以我们要指定输入输出路径
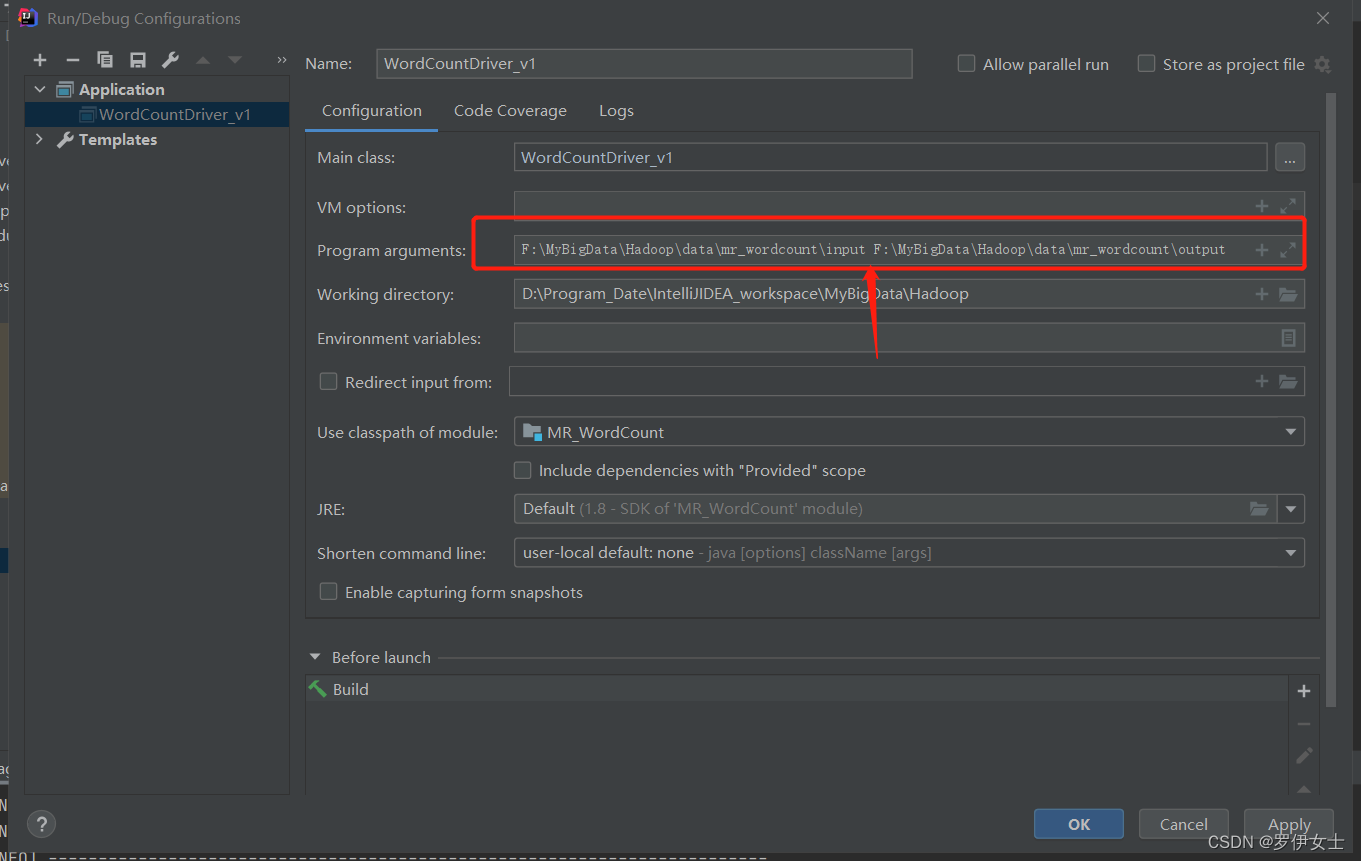
运行成功
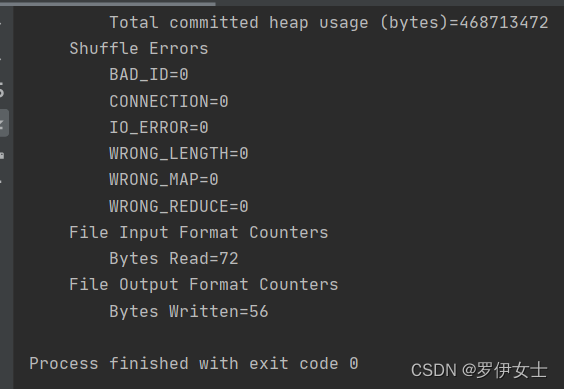
可以找到输出路径下的结果