先来讲讲安装hadoop的大致流程,备忘:
- 删除系统自带的openjdk
- 安装在官网下载的jdk
- 配置JAVA环境变量
- source /etc/profile
- 输入 java -version,验证JAVA环境安装成功;
-
解压hadoop,并配置环境变量(这一步具体参考
https://www.bilibili.com/video/BV1tT4y1E7xf?p=14); - source /etc/profile
- 输入 hadoop version,验证hadoop安装成功。
HDFS的部署有3种模式:本地模式、伪分布式模式、完全分布式模式。
1. 本地模式(Standalone)
1) 运行在单个机器上;
2) 使用的是本地文件系统;
用途:
1) 用于调试MapReduce程序的逻辑,确保逻辑的正确;
3) 本地模式适用于开发阶段,因为在本地调试MapReduce程序比较方便。
本地模式不需要安装,只需要在已经安装hadoop的机器上运行MapReduce程序即可。
2. 伪分布式模式(Pseudo-Distributed)
1) 运行在单个机器上;
2) 使用的是分布式文件系统;
3) HDFS涉及到的守护进程(NameNode、SecondaryNameNode、DataNode等)都运行在一台机器上(都是独立的JAVA进程);
用途:
1) 比本地模式多了代码调试功能;
2) 允许检查内存使用情况;
3) 可以检查HDFS输入输出、守护进程的交互。
与配置有关的文件解析:
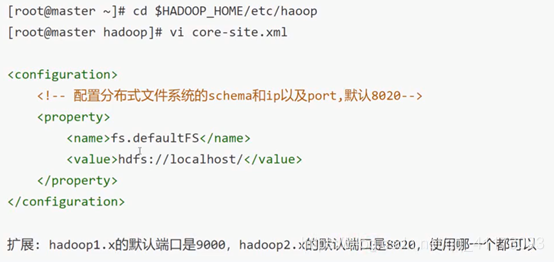
core-site.xml
这里的一开始的“hdfs”不是http,因为进程间不通过http进行通信。
hdfs-site.xml
伪分布式模式的副本设置为1,因为就算配置多个副本,机器坏了,所有副本都在机器里,再多副本也没用。

Hadoop-env.sh
指定jdk的环境

3. 完全分布式模式
1) 运行在不同的机器上;
2) HDFS的各个守护进程会运行在不同的机器上。
用途:
1) 生产环境中使用;
2) NameNode尽量部署在硬件性能较好的机器上;
3) 其它每台机器,都要部署一个DataNode,机器性能可以稍弱(一般DataNode都很多,这样做是为了控制成本);
4) SecondaryNameNode不建议和NameNode部署在同一台机器上。
配置过程:
1) 配置对应环境
2) 格式化集群
3) 启动集群
4) 测试集群
注:这里顺便部署yarn。
教材中是用了3台虚拟机,所以master上面既有NameNode,也有DataNode,这里是因为他虚拟机太少。其实在真实情况下,一台机器配置一个HDFS Node就行。
这里的NodeManager、ResourceManager都是yarn中的结点。其中存在和HDFS中的结点对应关系(yarn和HDFS中的结点并没有特殊的联系):
ResourceManager
**(yarn中的“boss”)
对应
NameNode(HDFS中的“boss”)**;
NodeManager
对应
DataNode
。

在部署完全分布式集群时,需要满足下面的条件:

完全分布式集群所需编辑的配置文件:
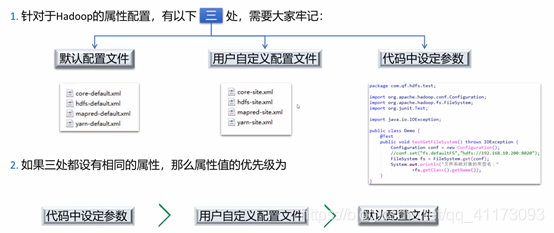
core-site.xml文件相关解析:

hdfs-site.xml解析:

mapred-site.xml解析:

yarn-site.xml解析:

hadoop-env.sh、yarn-env.sh:
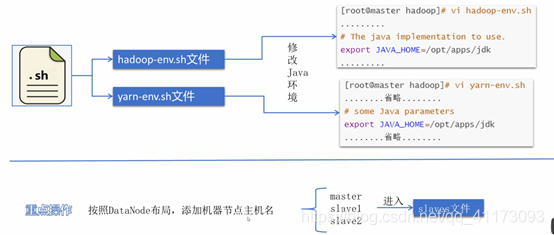
多台机器的配置方法:

格式化集群的目的(hdfs namenode -format格式化必须在NameNode上执行):
- 生成集群id:clusterID;
- 生成块池id:BlockPoolID;
-
生成NameNode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录; - 生成镜像文件fsimage,记录元数据;
- 生成并记录其他信息。
启动集群(最好在NameNode上执行):start-dfs.sh
在启动之后,如果有某些结点没有启动成功,可以查看日志:

在守护进程的启动和关闭方面,官方推荐单个start和单个stop:

下一篇文章记录如何搭建完全分布式模式。