文章目录
1、MapReduce 基本概念
1.1、MapReduce 基本定义
MapReduce 是面向大数据并行处理的计算模型、框架和平台。
它包含以下三层含义:
1)MapReduce 是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。
使用它来编写的数据处理应用可以运行在大型的商用硬件集群上来处理大型数据集中的可并行化问题,数据处理可以发生在存储在文件系统(非结构化)或数据库(结构化)中的数据上。MapReduce 可以利用数据的位置,在存储的位置附近处理数据,以最大限度地减少通信开销。
2)MapReduce 是一个并行计算与运行软件框架(Software Framework)。
它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及手机计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce 是一个并行程序设计模型与方法(Programming Model & Methodology)。
它借助于函数式程序设计语言 Lisp 的设计思想,提供了一种简便的并行程序设计方法,用 Map 和 Reduce 两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行变成接口,以便方便地完成大规模数据的编程和计算处理。
1.2、MapReduce 的模型简介
1)MapReduce 将复杂的、云星宇大规模集群上的并行计算过程高度地抽象到了两个函数:Map 和 Redce。
2)MapReduce 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算。
3)MapReduce 采用 “
分而治之
”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被很多个 Map 任务并行处理。
4)MapReduce 设计的一个理念就是 “
计算向数据靠拢
”,而不是“数据向计算靠拢”,因为移动数据需要大量的网络传输开销。
5)MapReduce 框架采用了
Master/Slave 架构
,包括一个 Master 和 若干个 Slave。Master 上运行 JobTracker,Slave 上运行 TaskTracker。
6)Hadoop 框架是用 Java 实现的,但是,MapReduce 应用程序则不一定要用 Java 来写。
1.3、MapReduce 的特点
MapReduce基于Google发布的并行计算框架。MapReduce论文设计开发,用于大规模数据集(大于1TB)的并行计算,具有如下特点:
易于编程
:程序员仅需描述做什么,具体怎么做由系统的执行框架处理。
良好的扩展性
:可通过添加结点以扩展集群能力。
高容错性
:通过计算迁移或数据迁移等策略提高集群的可用性与容错性。
1.4、MapReduce 与传统并行计算框架的对比

1.5、小结
总结:MapReduce 是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为 Map 和 Reduce 两个阶段的编程模型。
MapReduce 核心思想:分而治之
2、MapReduce 的体系结构
MapReduce 的体系结构:
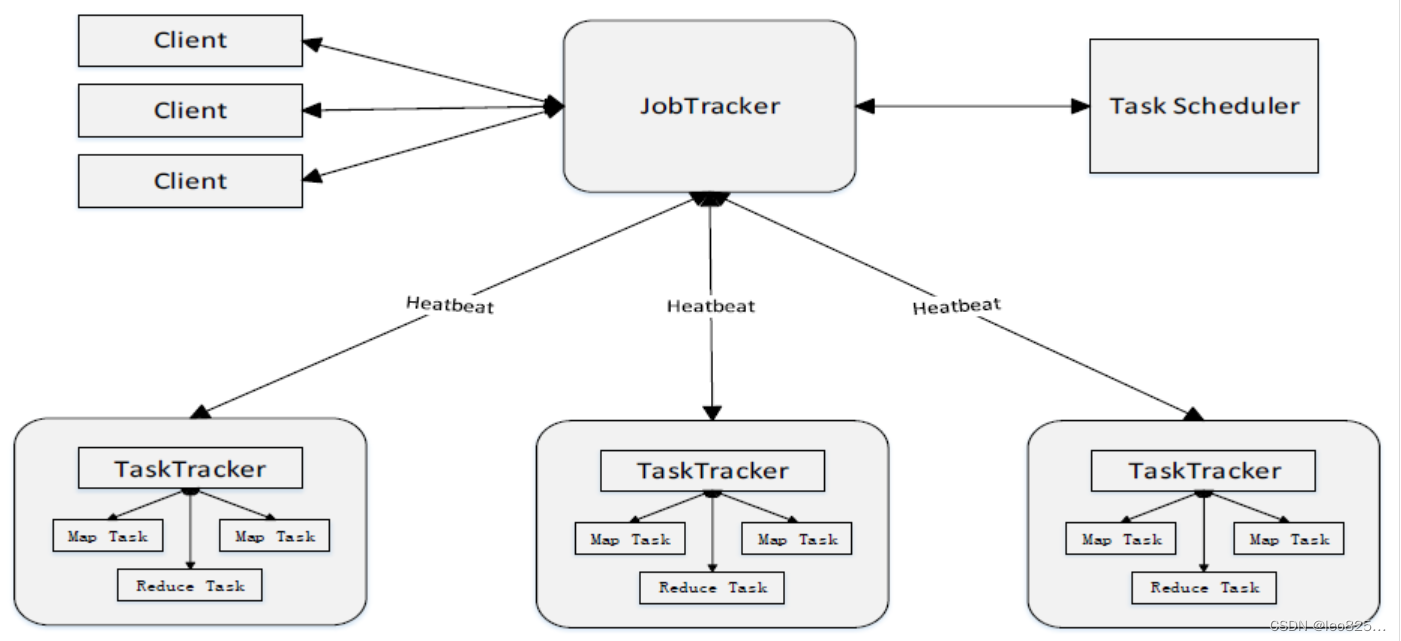
MapReduce 主要有以下4个部分组成
1)Client
- 用户编写的 MapReduce 程序通过 Client 提交到 JobTracker 端。
- 用户可通过 Client 提供的一些接口查看作业运行状态
2)JobTracker(Hadoop 2.0 之前)
- JobTracker 负责资源监控和作业调度
- JobTracker 监控所有 TaskTracker 与 Job 的健康状况,一旦发现失败,就将相应的任务转移到其他节点。
- JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的 任务去使用这些资源。
3)TaskTracker(Hadoop 2.0 之前)
- TaskTracker 会周期性地通过 “心跳” 将本节点上资源使用情况和任务进度汇报给 JobTracker,同时接收 JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
- TaskTracker 使用 “slot” 等量划分本节点上的资源量(CPU、内存等)。一个 Task 获取到一个 slot 后才有机会运行,而 Hadoop 调器的作用就是将各个 TaskTracker 上的空闲 slot 分配给 Task 使用。slot 分为 Map slot 和 Reduce slot 两种,分别供 Map Task 和 Reduce Task 使用。
4)Task
- Task 分为 Map Task 和 Reduce Task 两种,均由 TaskTracker 启动。
3、MapReduce 编程模型
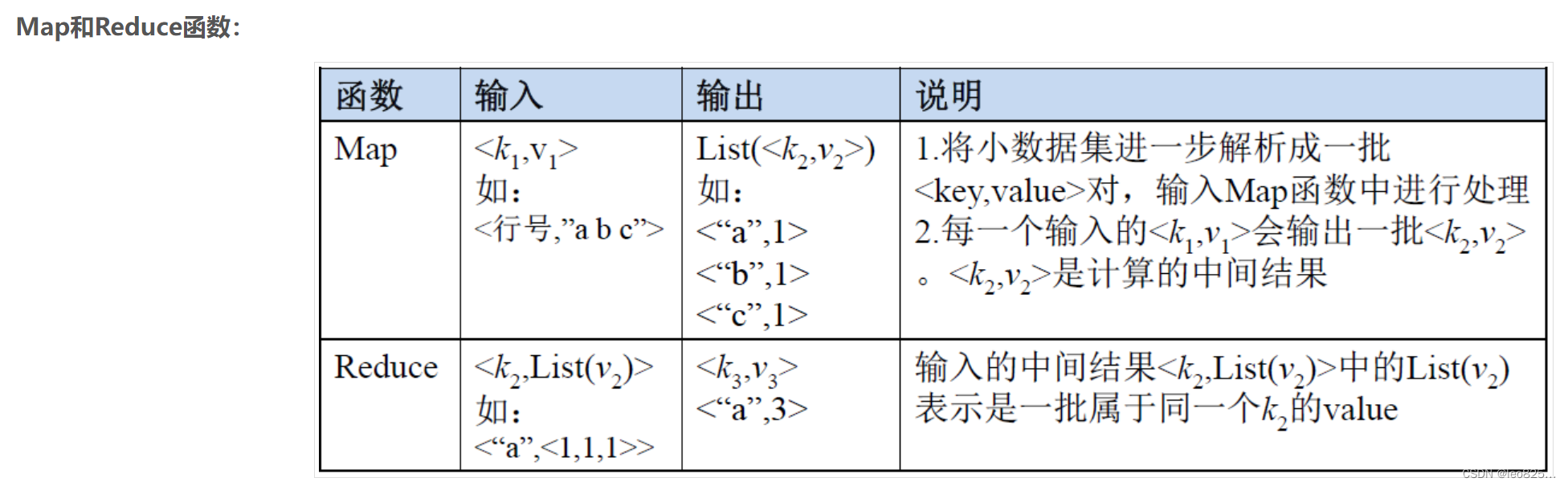
以下示例是以统计单词频度为例说明 MapReduce 处理流程:

1)input
:读取文本文件;
2)splitting
:将文件按照行进行拆分,此时得到的
K1
行数,
V1
标识对应行的文本内容;
3)mapping
:并行将每一行按照空格进行拆分,拆分得到
List(K2,V2)
,其中
K2
代表每一个单词,由于是做单词频度统计,所以
V2
的值为 1,代表出现了 1 次。
4)shuffling
:由于
mapping
操作可能是在不同的机器上并行处理的,所以需要通过
shuffing
将相同的
key
值的数据重排序并分发到同一个节点上去归并,这样才能统计出最终的结果,此时得到
K2
为每一个单词,
List(V2)
为可迭代稽核,
V2
就是
mapping
中的
V2
。
5)reduceing
:例子是统计单词出现的频度,所以
reducing
对
List(V2)
进行归并求和操作,最终输出。
3.1、MapReduce 各个执行阶段
MapReduce各个执行阶段:
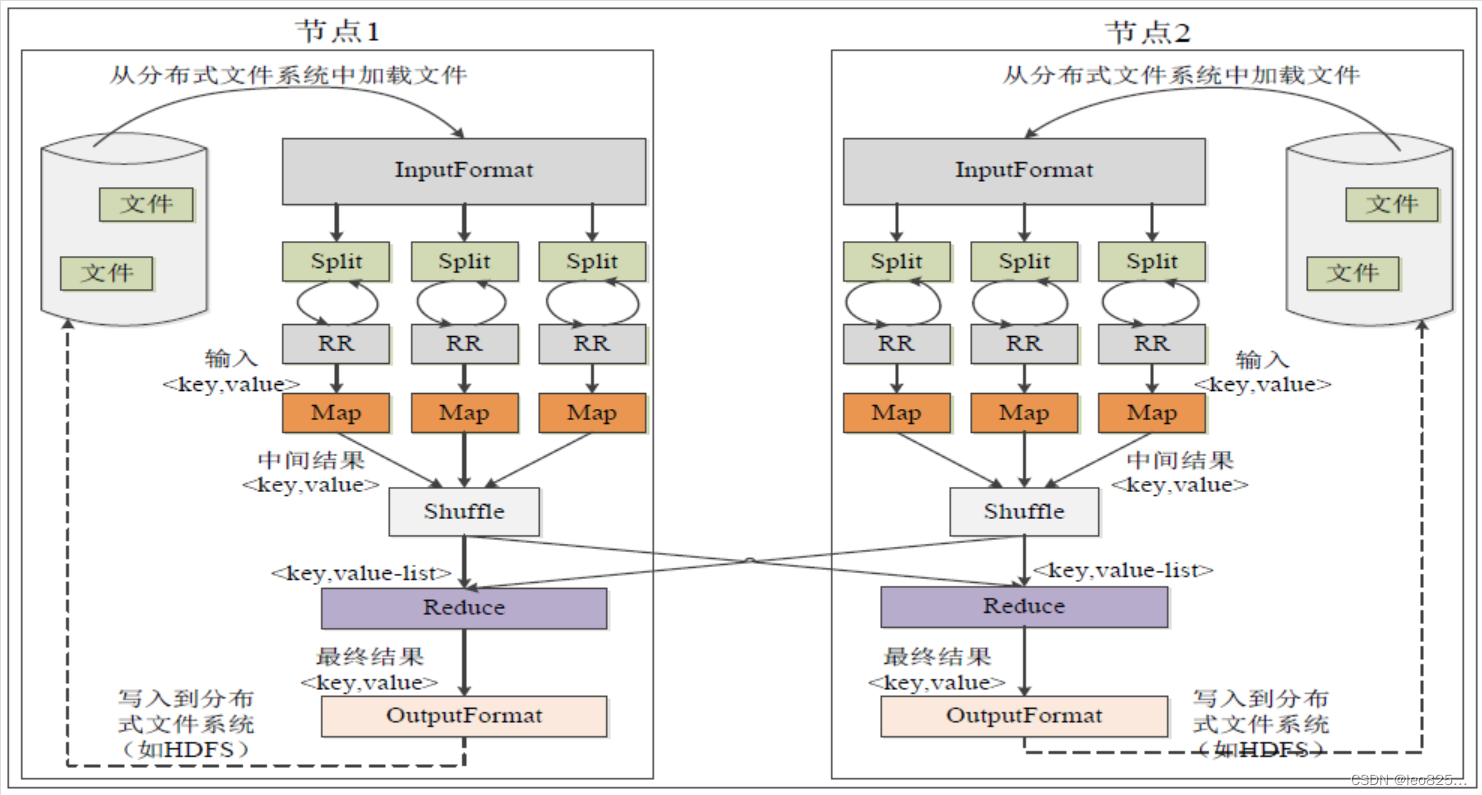
3.2、Split(分片)
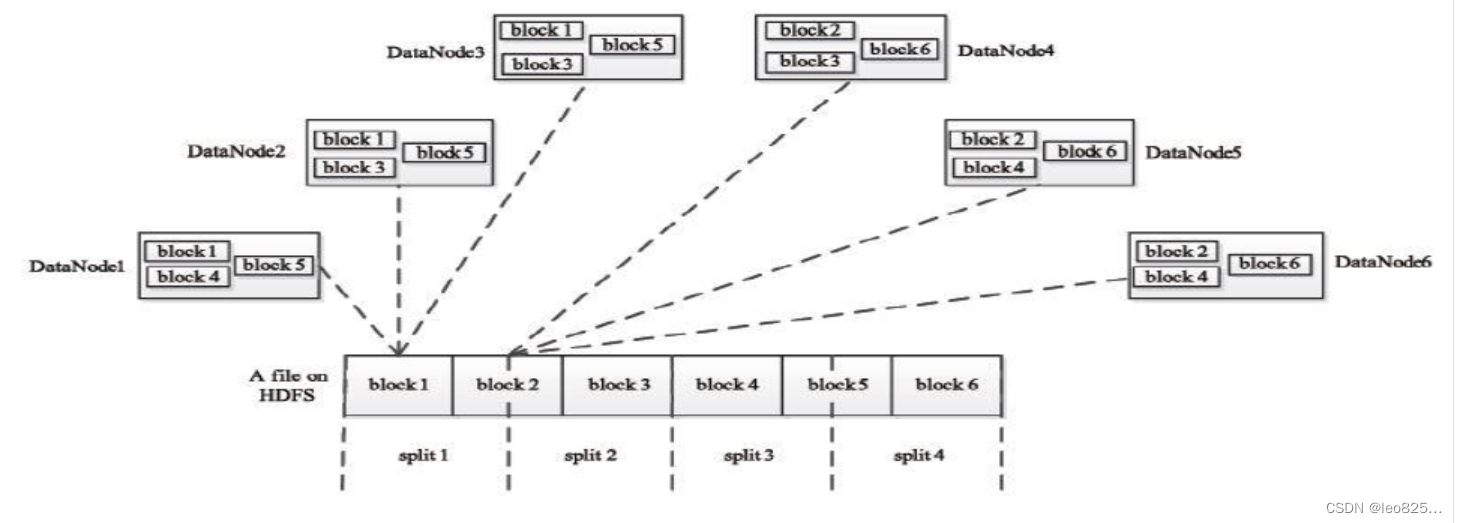
HDFS 以固定大小(默认128MB)的 block 为基本单位存储数据,而对于 MapReduce 而言,其处理单位是 split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据其实位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
Map任务的数量
:
Hadoop 为每个 split 创建一个 Map 任务,split 的多少决定了 Map 任务的数目。大多数情况下,理想的分片大小是一个 HDFS 块。
Reduce 任务的数量
:
最优的 Reduce 任务个数取决于集群中可用的 reduce 任务槽(slot)的数目。
通常设置比 reduce 任务槽数据曹伟小一些的 Reduce 任务个数(这样可以预留一些系统资源处理可能发生的错误)
3.3、Shuffle 过程(洗牌、发牌—核心机制:数据分区,排序,缓存)
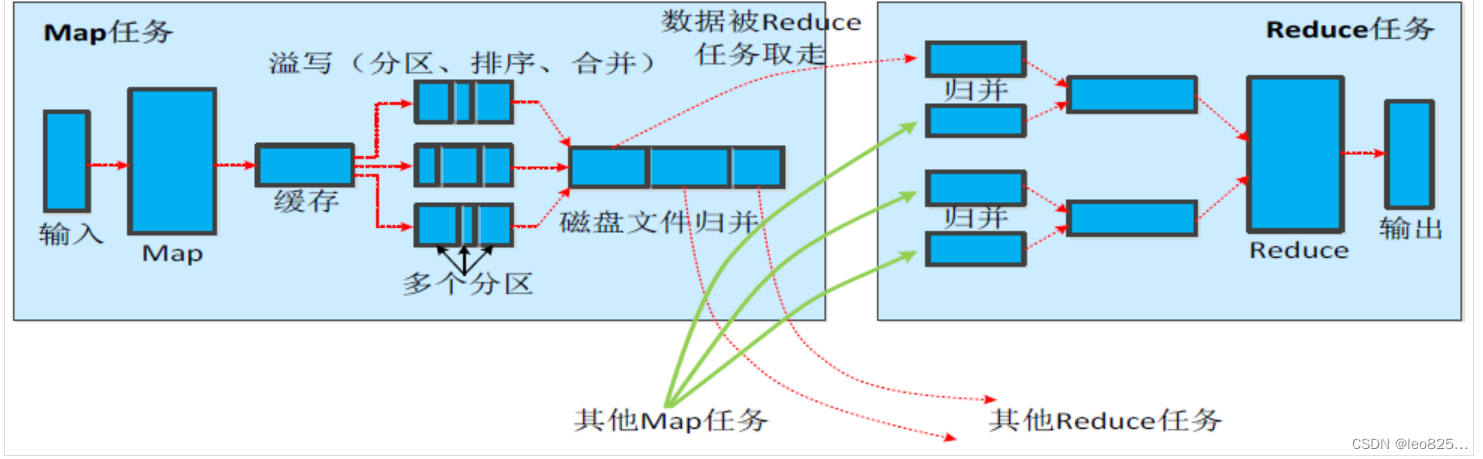
Map 端的 Shufle 过程
:
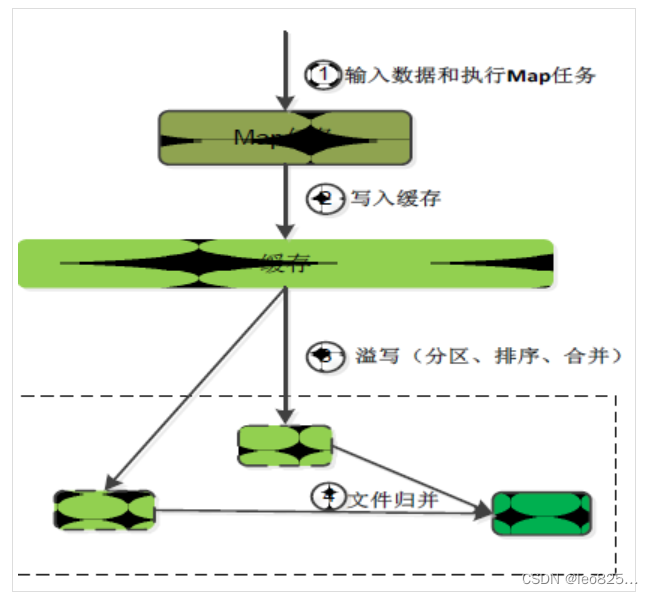
- 每个Map任务分配一个缓存
- MapReduce 默认 100MB 缓存
- 设置溢写比例为 0.8
- 分区默认采用哈希函数
- 排序是默认操作
- 排序后可以合并(Combine)
- 合并不能改变最终结果
- 在 Map 任务全部结束之前进行归并
- 归并得到一个大的文件,放在本地磁盘
- 文件归并时,如果溢写文件大于预定值(默认是3)则可以再次启动 Combiner 。
- JobTracker 会一直检测 Map 任务的执行,并通知 Reduce 任务来领取数据
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
Reduce 端的 Shufle 过程
:
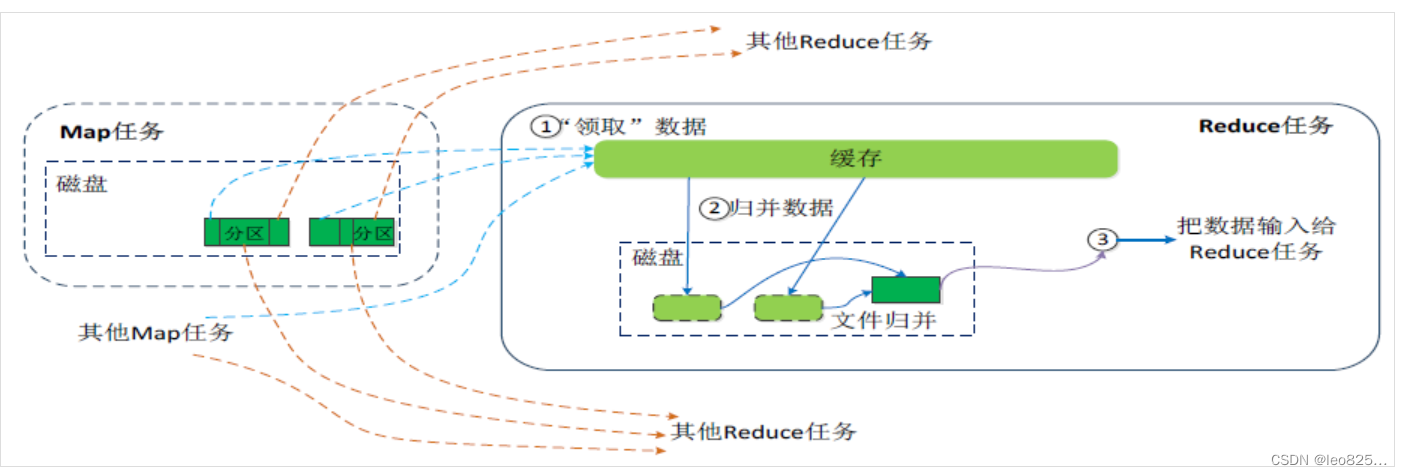
- Reduce 任务通过 RPC 向 JobTracker 询问 Map 任务是否已经完成,若完成,则领取数据。
- Reduce 领取数据先放入缓存,来自不同 Map 机器,先归并,在合并,写入磁盘。
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的。
- 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给 Reduce。
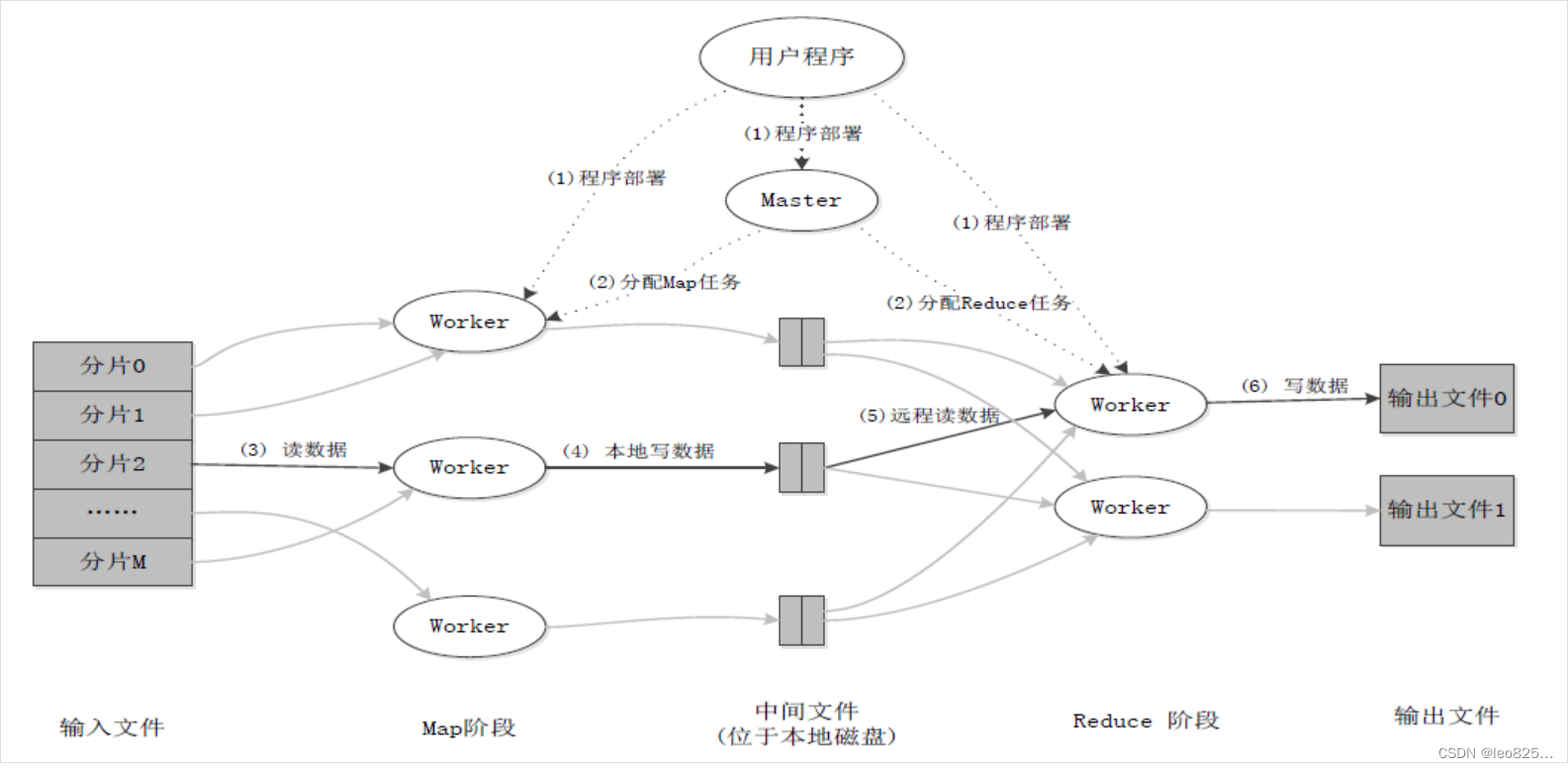
3、MapReduce 应用程序执行过程