时间序列是一系列按照时间顺序排列的数据,
这些数据之间的间隔可以是等距的,也可以是不等距的。
时间序列的预测过程包括通过对时间序列的过去行为进行建模(自回归)或使用其他外部变量来预测时间序列的未来值。

本文介绍了如何使用Scikit-learn回归模型来进行时间序列的预测。具体而言,它介绍了
Skforecast
,一个简单的库,包含了将任何Scikit-learn回归模型适应于预测问题所需的类和函数。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
好的文章离不开粉丝的分享、推荐,资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过500人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:
dkl88194
,备注:来自CSDN + 机器学习
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:
机器学习
时序预测基础
为了将机器学习模型应用于预测问题,需要将时间序列转换为一个矩阵,其中每个值与其之前的时间窗口(滞后)相关联。
在时间序列的背景下,滞后是指相对于时间步长 ? 的值,即系列在之前时间步长上的取值。例如,滞后1是指时间步长 ?−1 的值,而滞后 ? 是指时间步长 ?−? 的值。
这种转换还允许包含额外的变量。
一旦数据被重新排列成新的形式,任何回归模型都可以被训练来预测系列的下一个值(步长)。在模型训练过程中,每一行被视为一个独立的数据实例,其中滞后1、2、… ? 的值被视为时间步长 ?+1 上目标时间序列的预测变量。
多步时间序列预测
在处理时间序列时,很少只需要预测系列中的下一个元素 (?+1)。相反,最常见的目标是预测整个未来的时间间隔 (?+1, …, ?+?) 或者一个较远的时间点 (?+?)。有几种策略可以生成这种类型的预测。
递归多步预测
由于预测 需要知道值 ,而 是未知的,因此采用递归过程,每个新的预测都基于前一个预测。这个过程被称为递归预测或递归多步预测,可以通过
ForecasterAutoreg
和
ForecasterAutoregCustom
类轻松生成。
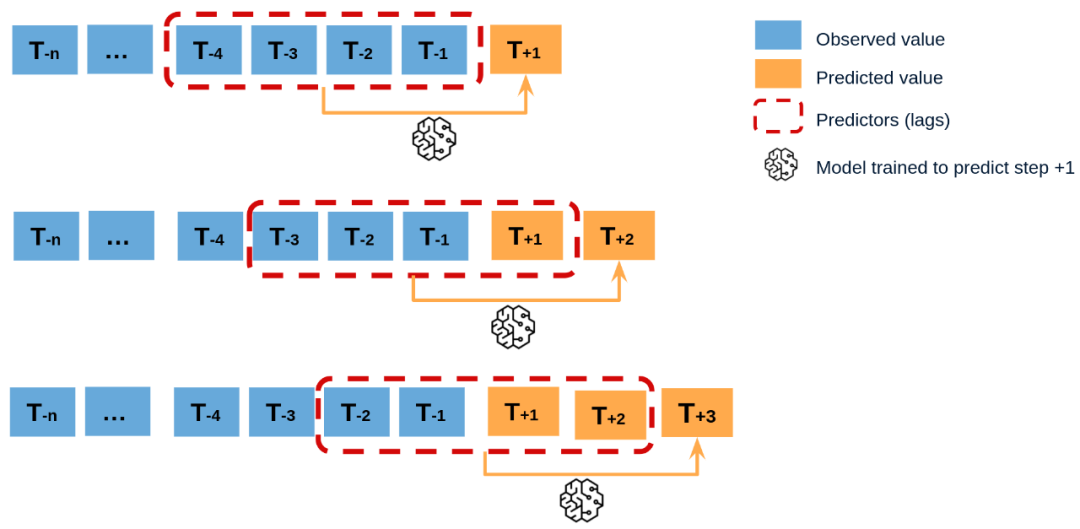
直接多步预测
直接多步预测包括针对预测时间跨度的每个步骤训练一个不同的模型。例如,要预测时间序列的接下来的5个值,需要训练5个不同的模型,每个步骤一个模型。因此,预测是相互独立的。

这种方法的主要复杂性在于为每个模型生成正确的标签矩阵。
skforecast
库中的
ForecasterAutoregDirect
类自动化了这个过程。同时需要注意的是,这种策略的计算成本较高,因为需要训练多个模型。下面的图示展示了一个具有响应变量和两个外生变量的情况下的过程。
多输出预测
某些机器学习模型,例如长短期记忆(LSTM)神经网络,可以同时预测一个序列的多个值(一次性预测)。目前skforecast库尚未实现这种策略。
案例1:递归自回归预测
数据集记录了1991年至2008年期间澳大利亚卫生系统在皮质类固醇药物上的月度支出(以百万美元为单位)。
目标是创建一个自回归模型,能够预测未来的月度支出。

使用
ForecasterAutoreg
类,可以创建一个模型,并使用
RandomForestRegressor
回归器进行训练,时间窗口为6个滞后值。这意味着模型使用前6个月的数据作为自变量。
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 6
)
forecaster.fit(y=data_train['y'])
forecaster

也可以设置模型超参数进行调参:
steps = 36
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 12 # This value will be replaced in the grid search
)
# Lags used as predictors
lags_grid = [10, 20]
# Regressor's hyperparameters
param_grid = {'n_estimators': [100, 500],
'max_depth': [3, 5, 10]}
results_grid = grid_search_forecaster(
forecaster = forecaster,
y = data_train['y'],
param_grid = param_grid,
lags_grid = lags_grid,
steps = steps,
refit = True,
metric = 'mean_squared_error',
initial_train_size = int(len(data_train)*0.5),
fixed_train_size = False,
return_best = True,
verbose = False
)
回测是建模中的一个术语,指对历史数据上进行预测模型的测试。回测涉及向过去逐步移动,根据需要进行多个阶段的测试。回测是一种特殊类型的交叉验证,应用于之前的时间段。

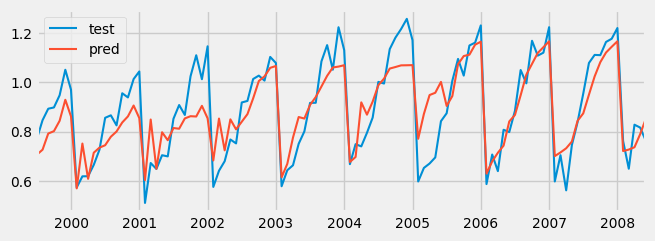
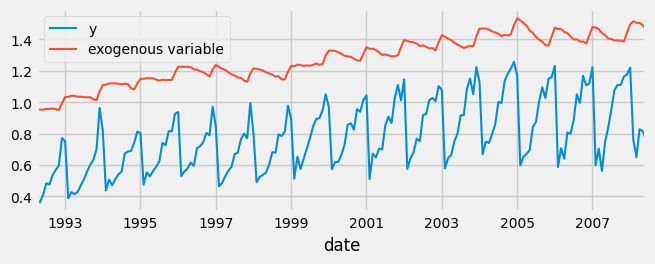
案例2:外部特征多元回归
在前面的例子中,只使用了预测变量本身的滞后值作为预测变量。在某些情况下,可能会有关于其他变量的信息,其未来值是已知的,因此可以作为模型中的额外预测变量。
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 8
)
forecaster.fit(y=data_train['y'], exog=data_train['exog_1'])
forecaster

案例3:模型多步预测
ForecasterAutoreg
和
ForecasterAutoregCustom
模型采用递归预测策略,每个新的预测都建立在前一个预测的基础上。另一种方法是为要预测的每个步骤训练一个模型。
这种策略通常被称为直接多步预测,它在计算上比递归更昂贵,因为需要训练多个模型。然而,在某些情况下,它可以获得更好的结果。使用ForecasterAutoregDirect类可以获得这种类型的模型,并且可以包括一个或多个外生变量。

forecaster = ForecasterAutoregDirect(
regressor = Lasso(random_state=123),
transformer_y = StandardScaler(),
steps = 36,
lags = 8
)
forecaster