原文:Assran, Mahmoud et al. “Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments with Support Samples.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (2021): 8423-8432.
源码:https://github.com/facebookresearch/suncet
本文提出了一种基于支持样本预测视图类别的学习方法。该方法通过训练一个模型来最小化一致性损失,从而确保为同一无标签实例的不同视图指定相似的伪标签。通过将无标签图像视图的表示与一组随机采样的有标签图像的表示进行比较,以非参数的方式生成伪标签。视图表示和标签表示之间的距离用于提供类别标签的权重,我们将其解释为软伪标签。通过以这种方式非参数地融合有标签样本,PAWS将自监督方法(如BYOL和SwAV)中使用的距离度量损失扩展到半监督学习中。尽管这种方法很简单,但PAWS在各种架构上都优于其他半监督方法,在ImageNet上用10%或1%的标签训练ResNet-50,分别达到了75.5%和66.5%的Top-1精度。与以往最好的方法相比,PAWS需要的训练量减少了4到12倍。
★ 相关工作
★ 论文故事
使用较少的标记数据进行学习一直是计算机视觉和机器学习研究的一个长期挑战。一种流行方法是,首先在大型数据集上进行无监督的预训练,然后利用少量标记数据进行有监督的微调。自监督方法通常遵循这种范式,并且在各种半监督学习基准上表现出了强大的竞争力。然而,与其他方法相比,自监督范式也需要更多的计算工作,并且在有标签数据可用时却不用它们。
另一种方法是利用有标签数据给无标签数据生成伪标签,然后使用有标签和伪标签数据来训练模型。这就引出了一个问题:我们能否在训练过程中充分利用有标签数据,同时在自监督学习的基础上取得进步,从而两全其美?
本文提出了一种利用支持样本预测视图类别的学习方法。该方法通过训练一个模型来最小化一致性损失,从而确保为同一无标签实例的不同视图指定相似的伪标签。通过将无标签图像视图的表示与一组随机采样的有标签图像的表示进行比较,以非参数的方式生成伪标签。视图表示和标签表示之间的距离用于提供类别标签的权重,我们将其解释为软伪标签。通过以这种方式非参数地融合有标签样本,PAWS将自监督方法(如BYOL和SwAV)中使用的距离度量损失扩展到半监督学习中。
尽管这种方法很简单,但PAWS在各种架构上都优于其他半监督方法,在ImageNet上用10%或1%的标签训练ResNet-50,分别达到了75.5%和66.5%的Top-1精度。与以往最好的方法相比,PAWS需要的训练量减少了4到12倍。同样的结论也适用于更广泛的ResNet架构(即ResNet-50 2×或4×)。

图1:当只有10%的ImageNet标记数据时,训练的ResNet-50的Top-1精度。与以往的方法相比,PAWS方法在训练时间显著减少的情况下获得了更高的精度。具体来说,使用64个NVIDIA V100-16G GPU,PAWS训练100个epoch的时间不到8.5小时。
★ 模型方法
我们针对一个大的无标签的数据集D和一个小的有标签的支持集S,目标是在预训练期间同时利用D和S来学习图像表示。在使用D和S进行预训练后,我们只使用有标签数据集S对学习到的表示进行微调。
如图2所示,我们从D中选取一张图像,通过随机数据增强生成两张视图,即一张锚视图和一张正视图。通过非参数化地将软伪标签指定给锚视图和正视图,然后最小化它们之间的交叉熵损失H来实现学习。软伪标签是由可微的基于相似度的分类器
πd
生成的,该分类器能够度量视图表示与支持集S中小批量有标签样本的相似度,并输出软类别标签。对于相似度分类器
πd
,我们使用了一种简单的软近邻策略。支持集S只用于给无标签的图像视图指定伪标签,而损失只与指定给无标签图像视图的伪标签有关。

图2:PAWS方法。该方法将软伪标签指定给图像的锚视图和正视图,随后最小化它们之间的交叉熵损失H。软伪标签是由可微的相似度分类器
πd
生成的,该分类器能够度量视图表示与小批量有标签支持样本的相似度,并输出软类别分布。正视图是由锚视图经过数据增强创建的。
★
实验结果

表1:当只有1%或10%的ImageNet标记数据时,训练的ResNet-50的Top-1精度。

表2:使用更大的ResNet架构进行训练时,ImageNet上的半监督分类结果。

图3:当只有1%的ImageNet标记数据时,训练的ResNet-50的Top-1精度。PAWS方法比之前的工作获得了更高的精度,同时需要的训练时间显著减少。具体来说,使用64个NVIDIA V100-16G GPU,PAWS训练100个epoch的时间不到8.5小时。

表3:在ImageNet上,针对各种ResNet架构进行更长时间训练的结果。在1%和10%的标签设置中,以及在ResNet-50和ResNet-50(2×)架构中,训练超过200步通常是没有必要的,只会产生微小的改进。

图4:当只有10%的ImageNet标记数据时,训练一个ResNet-50的各种指标。图4a是训练期间锚视图和(目标)正视图之间的交叉熵损失。正如预期的那样,这种损失在训练过程中减少,表明模型正在学习为同一图像的不同视图指定相似的伪标签。图4b是训练过程中使用采样的小批量和支持集计算的额外损失。训练过程中实例识别损失的减少表明,该模型正在学习对用于训练的数据增强保持不变的表示。分类损失的减少表明模型正在学习如何正确地分类有标签的支持样本。图4c是训练期间argmax目标预测的平均置信度。随着训练的进行,模型的目标预测变得越来越自信。

表4:支持数据集的影响。在ImageNet上训练ResNet-50时,关于采样的小批量支持数据集的消融研究。我们的默认设置用绿色阴影显示。增加支持集的大小可以提高性能。然而,在对固定数量的实例进行采样时,最好是采样大量类别,每个类别使用少量图像,而不是采样少量类别,每个类别使用大量图像。

表5:预测头的影响。当只有10%的ImageNet标记数据时,训练一个ResNet-50,观察预测头对结果的影响。我们的默认设置用绿色阴影显示。自监督方法在没有预测头的情况下会坍塌,但PAWS在没有预测头的情况下仍然收敛。

表6:ME-Max正则化的影响。
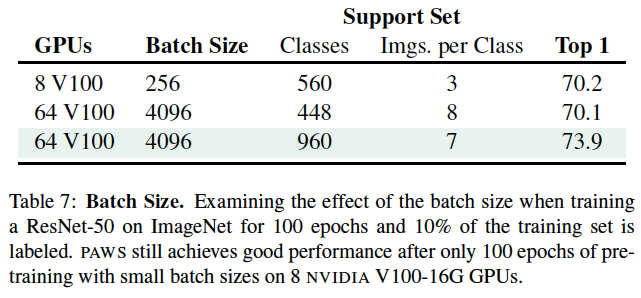
表7:批量大小的影响。
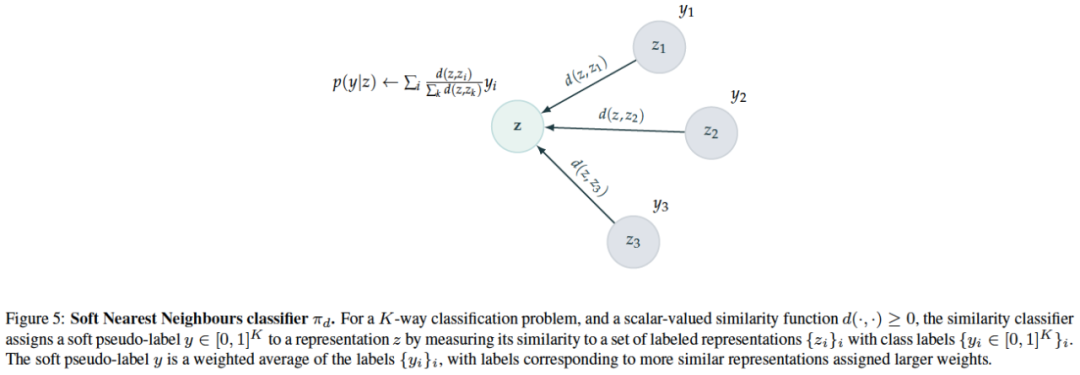
图5:软最近邻分类器
πd
。
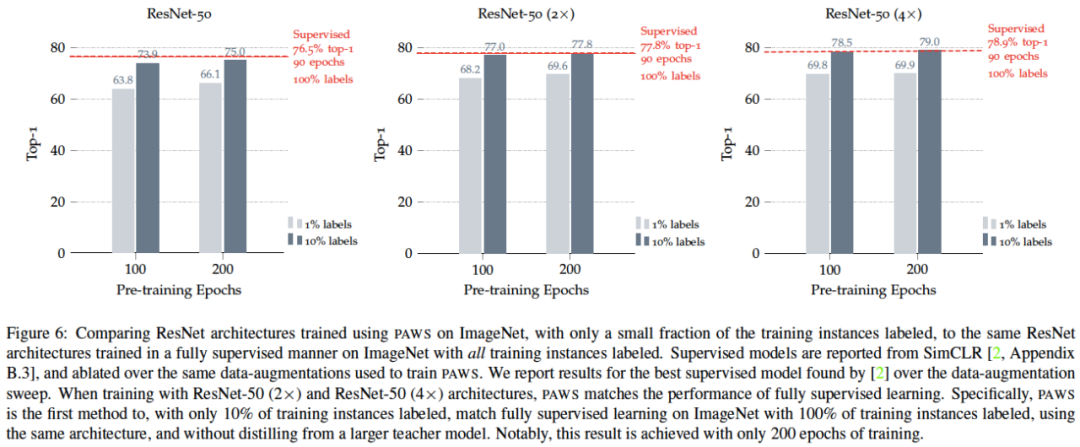
图6:在ImageNet上使用PAWS训练的不同ResNet架构的结果。
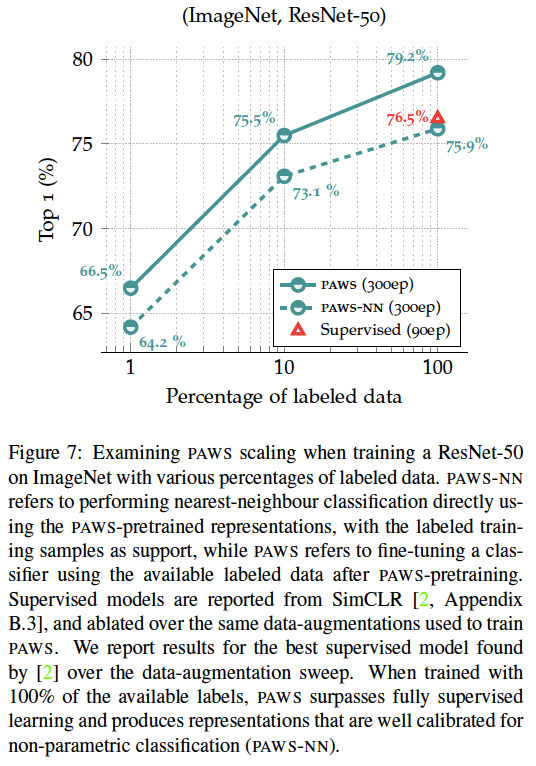
图7:不同比例的标记数据的影响。

图8:在CIFAR10上训练WideResNet-28-2的结果。
★
总结讨论
PAWS在预训练期间通过利用一个小的有标签的支持集,在半监督问题上实现了有竞争力的分类精度,并且需要的训练量更少。事实证明,PAWS还避免了坍塌的风险,这是自监督方法中一个常见的挑战。PAWS可以被解释为一种具有外部记忆的神经网络架构,该架构是通过“同化和适应”原理来训练的。在同化过程中,PAWS会更新新观察结果的表示,以便通过其外部记忆轻松地描述它们;而在适应过程中,PAWS会更新其外部记忆以解释新观察结果。使用有监督的支持集也有一些实际优势,因为它使模型能够有效地学习。然而,在这个框架中,如果只使用实例监督和更灵活的记忆表示,是否可以学习到有竞争力的表示,这仍然是一个有趣的问题。我们计划在未来的工作中研究这些方向。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“
多模态人工智能
”公众号,一起进步^_^↑