在做 SDK 开发的时候,会将 SDK 中不同功能进行模块化拆分,分解成不同的模块,在对外提供 SDK 时,将多个 AAR 文件交付给使用方。
来看一下这个场景,假设现在 SDK 有
A模块
、
B模块
两个模块,其中
B模块
依赖
A模块
。现在,对这两个模块进行打包,并且要开启混淆。发现了吗?要让
B模块
中的类,能正常使用
A模块
中的接口/类,我们需要将
A模块
中的接口/类进行
keep
,才能满足相应的要求。但是
A模块
中的那些接口/类仅提供给我们自己的模块使用,不需要对外提供,我们希望能够将其混淆,这种情况下,混淆需要怎么处理呢?这两个模块在打包时,也可能会生成相同的混淆名称,这种情况下,又需要怎么处理呢?
当然,作为 Java 混淆界首屈一指的工具,它是有相应的功能去处理这些问题。但使用这些规则就能够非常顺畅的实现需求吗?本文将围绕 ProGuard 的混淆规则
-applymapping
和
-flattenpackagehierarchy
的使用,以及解决后续问题的思考与实践过程来展开。
一、ProGuard 混淆规则:-applymapping
在文首所举的例子中,
A 模块
和
B 模块
中所使用的相同
class
需要使用相同的规则。在 ProGuard 混淆中, 有
-applymapping
可以指定混淆过程中类、变量、方法的映射规则。 在映射规则中没有提到的类、变量、方法会使用新的名称进行映射。在官方文档描述中,它可以用来进行增量编译。使用方式很简单,你只需要在你的
proguard-rules.txt
中添加如下规则:
-applymapping ./keep-same-proguard.txt
通过
-applymapping
指定要使用的映射规则所在的文件,但需要注意的是,此方式只支持一个映射文件。映射文件中的内容与 ProGuard 混淆后生成的
mapping
文件一致,如下所示:
com.example.build.DeviceUtils -> a.a.a.x:
java.lang.String deviceName -> c
java.lang.String deviceId -> b
java.lang.String getDeviceId() -> x
void setup(android.content.Context) -> a
java.lang.String getDeviceName() -> c
假设,我在
DeviceUtils
这个类中添加一个方法和一个变量,最终类信息如下:
import android.content.Context;
public class DeviceUtils {
public String deviceName;
public String deviceId;
public int addTestVerbose;
public String getDeviceName() {
return "";
}
public String getDeviceId() {
return "";
}
public void setup(Context context) {
}
public void addTestMethod() {
}
}
编译混淆后的
mapping
信息如下:
com.example.build.DeviceUtils -> a.a.a.x:
java.lang.String deviceName -> c
java.lang.String deviceId -> b
int addTestVerbose -> a
void addTestMethod() -> a
void setup(android.content.Context) -> a
java.lang.String getDeviceName() -> c
java.lang.String getDeviceId() -> x因为
setup
与
addTestMethod
的签名不一样, 在混淆的时候,可以使用相同的方法名,所以最终混淆出来的方法为
void a()
和
void a(Context val)
。
二、ProGuard 混淆规则:-flattenpackagehierarchy
之所以要使用这个关键字,是因为模块在打包生成 aar 或者 jar 包时,无法感知到其它与此模块无关的模块,生成混淆文件是可能会存在冲突的。这么说,可能不太能理解,为了能搞清楚冲突是怎么来的,先来看一个混淆的例子,在我的项目中,有三个类,类结构如下图所示:

因为这只是三个类文件,并没有被调用到,如果我要对它们进行混淆,我需要去调优化,所以混淆配置如下:
-dontshrink
-keep public class com.example.build.DeviceUtils {
public *;
}
在我做测试的时候发现,ProGuard 与 R8 的混淆还有一些细微的差别。而在使用的 Android Gradle Tools 的版本在 3.4.0 以及以上时,默认将不再使用 ProGuard 执行编译时代码优化,而是使用 R8 进行协同处理
代码压缩
,
资源缩减
,
混淆
,
优化
。因此,我将两种混淆产生的
mapping
文件都贴在下面,可以做一个简单的对比。
在使用 ProGuard 的时候,对于一个类的全路径包名,会去与当前 keep 的包名匹配,只会混淆没有被 keep 的包名, 混淆结果如下:
com.example.build.DeviceUtils -> com.example.build.DeviceUtils:
int testPrivateVerbose -> a
void <init>() -> <init>
int testPrivateMethod() -> a
com.example.build.inner.MainInner -> com.example.build.a.a:
java.lang.String inner -> a
void <init>() -> <init>
com.example.build.inner.test.TestInnerClass -> com.example.build.a.a.a:
void <init>() -> <init>而在使用 R8 是,混淆得比 ProGuard 更多,上面的例子,输出如下结果:
com.example.build.DeviceUtils -> com.example.build.DeviceUtils:
int testPrivateVerbose -> a
int testPrivateMethod() -> a
com.example.build.inner.MainInner -> a.a.a.a.a:
java.lang.String inner -> a
com.example.build.inner.test.TestInnerClass -> a.a.a.a.b.a:
可以看到 ProGuard 和 R8 的细微差别。在回头来看,不管是用 ProGuard 还是 R8,在生成类名的时候,都是用
a
表示,假设我在
A 模块
中有
com.example.build.inner.MainInner
这个类,在
B 模块
中有
com.example.build.inner.SubInner
这个类,那分别打包
A/B模块
时,这两个类生成的名字都可能是
com.example.build.a.a
,那业务在集成的时候,会同时引入
A/B模块
的SDK, 编译时就会出现类冲突,而最终的原因就是混淆时,不同模块间混淆生成了两个类使用了相同的名字,造成了冲突。解决方案也很简单,使用
-flattenpackagehierarchy
或者
-repackageclasses
指定混淆后移入的包路径即可, 不同模块,给定一个不同的包路径即可解决。
三、新问题的引入:代码更改造成 Crash
按照上述的 ProGuard 规则,在本地手动编译模块的 Release 包,并将需要使用相同规则类的混淆映射拷贝到
keep-same-proguard.txt
中,并且在模块下的
proguard-rules.pro
中添加上述配置,示例如下:
# 在 A 模块中使用 com.example.a1 , 在 B 模块中使用 com.example.a2
-flattenpackagehierarchy com.exampe.a1
-applymapping ../keep-same-proguard.txt
多个模块使用同一个
keep-same-proguard.txt
文件, 我们可以将此文件放置到项目根目录下面,方便所有项目访问使用。编译时,模块间直接使用源码依赖即可。
在上述配置中,编译出来的 SDK 满足了混淆的需求,也可以正常使用,一切都是那么的美好。
直到有一天,我们修改了那几个要共用的类,导致在
keep-same-proguard.txt
中的配置不能和新的代码匹配。但其引发的错误需要打 Release 包运行,才能发现。如果是一个新同学,可能需要花很久的时间,才能找到问题的根源。 每一次代码的变更都可能会引发 Crash , 这是一个非常严重的问题,要如何解决它呢?

再来细看一下,
keep-same-proguard.txt
生成的方式:
-
在本地编译 Release 包,获取编译产物中的
build/outputs/mapping/release/mapping.txt
文件 -
从
mapping
文件中拷贝出需要的
映射关系
,将新的映射关系替换掉
keep-dame-proguard.txt
中原有的映射关系 -
将此映射文件提交到代码仓库,用于 SDK 打包时使用
如果内部暴露的 API 不只在一个
模块
里面,你需要重复执行上面1, 2步骤,直到将所有的映射信息都更新完成。在本地开发时,很少会有人将混淆打开,本地几乎感知不到这个配置的存在。如果新同事来开发,不知道需要处理这个关系,上述步骤是很容易被遗忘掉,出现问题并花很多时间去排查,这非常容易引起同事们骂声。

刚刚我们提到,这个
映射关系
就是 ProGuard 生成的
mapping
文件内容,里面分为三部份:
类名
、
变量名
、
方法名
。规则也可以简单的理解为,把这三部分名字,转换成随机生成的字符即可。因此,我们可以将上述步骤用脚本自动化,在编译时在去生成这个
keep-same-proguard.txt
,这就解决了
类
变化引起的问题。
四、这时,Gradle就该上场了
当我们决定使用自动化脚本来生成文件时,Gradle 就是我们必备的利器。为了便于朋友们更好地理解后面的内容,我先介绍一下后面写自动化脚本中涉及的 Gradle 任务相关的基础知识,如果你对 Gradle 很熟悉,可直接跳过。
1. Gradle 任务创建
Gradle 任务是编译构建过程中的原子单元,例如
编译任务
、
生成Javadoc任务
。而我们创建一个新的任务也非常简单,在项目中
build.gradle
文件中,使用如下 DSL 即可定义新的任务 :
task testCreateTask << {
print "这是一个使用 DSL 创建的测试 Task "
}
在项目目录下,执行
./gradlew testCreateTask
即可执行对应的任务。这种方式很简单,针对一些复杂的场景,我们也可以使用 Java 代码编写自定义任务。
-
定义一个类,继承自
DefaultTask
或者其它父类 -
给任务执行的入口函数添加
@TaskAction
注解,如下示例
public class TestCreateTaskByJavaCode extends DefaultTask {
@TaskAction
void process() {
}
}定义完成后,还需要将任务添加到 Project 中:
project.getTasks().create("testCreateTask", TestCreateTaskByJavaCode.class)
当在使用
./gradlew testCreateTask
时,会执行到
@TaskAction
标注的
process
方法,自定义任务的执行逻辑都可以放到这里面。
2. 任务执行顺序
当定义了多个任务时,在执行时,我们希望这些任务能够按照指定的顺序去执行。Gradle 有很好的支持,可以使用任务的
dependsOn
去指定任务间的依赖关系,当前任务被执行时,它所依赖的其它任务都会被先执行。除此之外,当任务依赖的任务中,也需要指定他们的执行顺序,但又不想对任务进行依赖指定时,也可以使用
mustRunAfter
、
shouldRunAfter
去设置,也能让任务执行有先后顺序之分。
3. 任务的 doFirst 和 doLast
doFirst
和
doLast
针对的是任务执行阶段,我们可以通过 doFirst 让一个已经存在的任务执行之前先执行对应
Action
中的逻辑,doLast 与之相反,会在任务执行之前执行对应
Action
中的逻辑。在源码中也可以看到:
public Task doFirst(final String actionName, final Action<? super Task> action) {
hasCustomActions = true;
if (action == null) {
throw new InvalidUserDataException("Action must not be null!");
}
taskMutator.mutate("Task.doFirst(Action)", new Runnable() {
public void run() {
getTaskActions().add(0, wrap(action, actionName));
}
});
return this;
}
public Task doLast(final String actionName, final Action<? super Task> action) {
hasCustomActions = true;
if (action == null) {
throw new InvalidUserDataException("Action must not be null!");
}
taskMutator.mutate("Task.doLast(Action)", new Runnable() {
public void run() {
getTaskActions().add(wrap(action, actionName));
}
});
return this;
}doFirst 是将 Action 添加到列表的第 0 位,而 doLast 是直接添加到最后。
4. buildSrc 目录
在我们编写脚本文件时,可以创建一个独立的工程项目来进行代码编写以及代码管理,但是在开发过程中,会有一些打包调试的工作,独立项目相对会麻烦一些。而在 Gradle 的项目中,可直接在当前项目中,创建
buildSrc
文件夹,用来存放编写的代码 。使用时,在 build.gradle 中,可直接
import
并使用。
调试也是在编写 Gradle 脚本中,必不可少的手段,要想调试 Gradle 脚本,首先在项目运行的配置中添加
Remote JVM Debug
如下图所示:
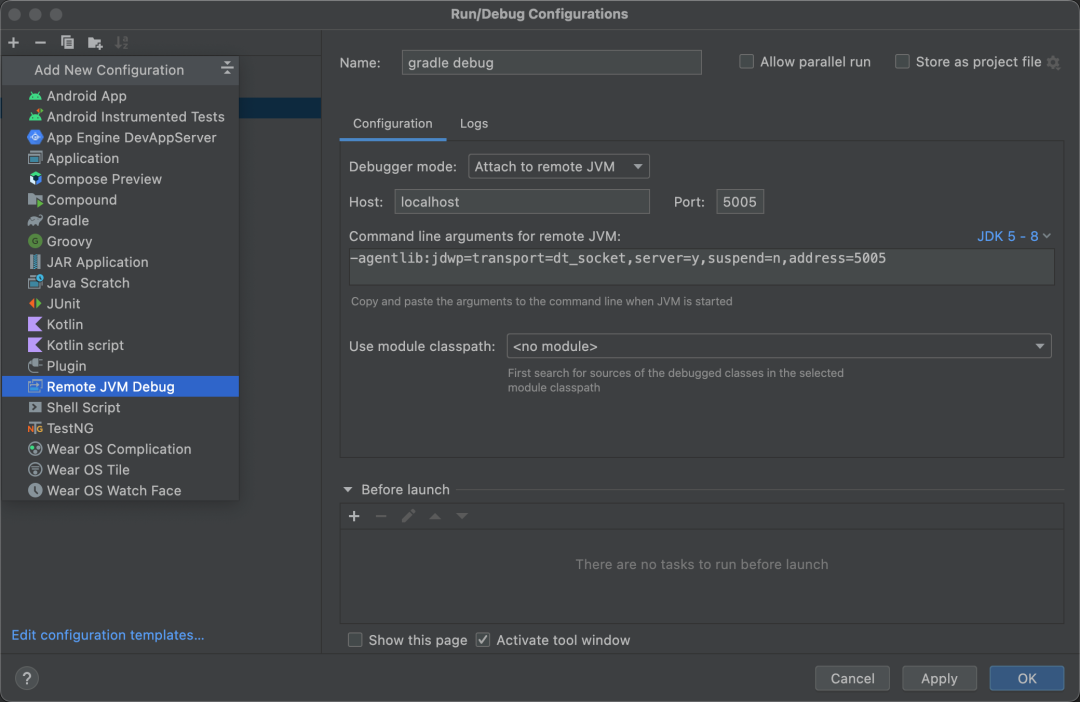
配置好上面的信息后,在控制台执行编译脚本,添加 debug 参数,如下:
./gradlew assembleDebug -Dorg.gradle.daemon=false -Dorg.gradle.debug=true运行后,控制点会启动 Gradle ,并开始执行,在正式执行编译任务是,会等待 Debug 的链接过来,这时候,点击 Debug 的图标就可以愉快地进行调试了。

五、插件的编写与实现
读到此处,我相信大家都对 Gradle 都有一定的了解,对于生成
keep-same-proguard.txt
也肯定有了一定的想法。文章前半段有提到,
keep-same-proguard.txt
中的内容为
类名
、
变量名
、
方法名
的映射关系,而这些信息我们都可以从编译后的
class
文件中获取到。
为了更好的复用,此处将定义一个插件,在
buildSrc
目录下,创建一个
Plugin
, 示例如下:
package com.android.tools.build;
public class KeepSameProguardPlugin implements Plugin<Project> {
@Override
public void apply(Project target) {
}
}
在引入时在对应模块的
build.gradle
中添加
import
, 使用如下:
import com.android.tools.build.KeepSameProguardPlugin
apply plugin: KeepSameProguardPlugin
现在分析一下整个脚本执行的流程, 第一步需要将所有源代码中所有的
class
都遍历出来,并解析这个
class
文件的中的内容,在根据
class
中的内容去生成我们想要的
keep-same-proguard.txt
文件,生成文件后,在将这个文件应用于 ProGuard 流程中。因此可以将流程分为三个任务:
BuildToolsFindAllClassTask
,
BuildToolsGenerateProguardTask
,
BuildToolsAddToProguardRulesTask
。这个三个任务需要添加到整个编译的流程中去,所以,我需要找到我想要加入任务的点。针对这个需求,我们需要编译后的
class
文件,那
class
文件又从哪儿来呢?你可能想到了,在 Android 的编译的过程中,肯定会有
javac
的任务。因此,我们的任务执行需要在
javac
之后。而生成的的
keep-same-proguard.txt
是给混淆使用的,也就是说,我的这些任务需要在
混淆任务
之前。
在本文中,我使用的是 AGT 4.1.0 (不同的 AGT 版本, 编译过程中的名称可能会存在不同),经过查看编译日志,很容易就能找到
compileReleaseJavaWithJavac
和
minifyReleaseWithR8
,因此,上面所说的三个任务就可以放到这两个任务之中,示例代码如下:
target.afterEvaluate(project -> {
Task javacTask = project.getTasks().findByName("compileReleaseJavaWithJavac");
Task proguardTask = project.getTasks().findByName("minifyReleaseWithR8");
javacTask.doLast(task -> {
// 执行 FindAllClassTask
});
Task generateProguardTask = project.getTasks().create("GenerateProguardTask", BuildToolsGenerateProguardTask.class);
Task addToProguardRulesTask = project.getTasks().create("AddToProguardRulesTask", BuildToolsAddToProguardRulesTask.class);
generateProguardTask.dependsOn(javacTask);
addToProguardRulesTask.dependsOn(generateProguardTask);
proguardTask.dependsOn(addToProguardRulesTask);
});
在编译模块时,它所依赖的模块中的 class 会被编译成
jar
,被放到
compileReleaseJavaWithJavac
的入参中,为了能够将依赖模块中的原代码
class
区分出来,所以在此处,做一个小小的改动,将
BuildToolsFindAllClassTask
执行的内容放到
javacTask
的
doLast
中去,编译时,被依赖模块也会执行
javacTask
,就能将被依赖模块中的
class
拿出来。
1. 读取 class 文件中的内容
业界中,针对
class
文件的处理, ASM 库必是首选,在本项目中,我也使用它,直接在 dependencies 中添加:
implementation 'org.ow2.asm:asm:7.0'
当然除了使用 ASM 解析,也可以直接使用 ClassLoader 去加载,有兴趣的同学可以去试试。因为本项目中,仅对
class
文件进行读取,不进行修改,可直接使用最简单的数据结构进行读取,针对 jar 包和文件夹,都是遍历对应的 class 文件,最终生成
ClassNode
。
public static Map<String, ClassNode> readJarFile(File file) {
Map<String, ClassNode> result = new HashMap<>();
try {
JarFile jarFile = new JarFile(file);
Enumeration<JarEntry> entries = jarFile.entries();
while (entries.hasMoreElements()) {
JarEntry entry = entries.nextElement();
String entryName = entry.getName();
if (!ClassNameTools.isClass(entryName)) {
continue;
}
String className = ClassNameTools.getClassName(entryName);
InputStream is = jarFile.getInputStream(entry);
ClassNode classNode = readClass(is);
result.put(className, classNode);
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
public static Map<String, ClassNode> readDirClassFile(File rootDir, File currentDir) {
Map<String, ClassNode> result = new HashMap<>();
String root = rootDir.getAbsolutePath();
File[] files = currentDir.listFiles();
for (File file : files) {
if (file.isDirectory()) {
Map<String, ClassNode> subResult = readDirClassFile(rootDir, file);
result.putAll(subResult);
} else {
String filePath = file.getAbsolutePath();
if (!ClassNameTools.isClass(filePath)) {
continue;
}
String className = ClassNameTools.getClassName(root, filePath);
try {
ClassNode classNode = readClass(new FileInputStream(file));
result.put(className, classNode);
} catch (Exception e) {
e.printStackTrace();
}
}
}
return result;
}
private static ClassNode readClass(InputStream is) {
ClassReader reader = new ClassReader(is);
ClassNode node = new ClassNode();
reader.accept(node, ClassReader.SKIP_CODE);
return node;
}
通过上述代码,就可以轻松的读取出所有的
class
文件的内容,需要注意的是,在
compileReleaseJavaWithJavac
这个任务的
inputFiles
包含了当前模块的所有依赖库(Android SDK、jdk、二方/三方库),
outputFiles
才是当前模块的输出产物。在生成混淆时,如果是二方/三方库或者是Android SDK 中继承的方法,这些方法名称是不能被混淆的。以 Activity 举个例子,如下所示:
public class TestActivity extends AppCompatActivity {
public int value = 1;
public void testMethod() {
}
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
}
}
从 inputFiles 中可以获取到
AppCompatActivity
,而这个类因为是非源码,在打包 SDK 时,从中继承过来的方法是不能被混淆的,在生成规则时,
onCreate
方法需要保持不变。
2. 混淆名称生成规则
Java 的变量名是以
字母和_
开头,后跟
字母、数字、_ 、 $
,为了让逻辑更简单,此处生成的名字仅用
字母
和
_
,因此,变量名列表代码如下:
private static final String[] NAME_DIC = new String[]{
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K",
"L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V",
"W", "X", "Y", "Z",
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k",
"l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v",
"w", "x", "y", "z", "_"
};
在混淆中,生成名字以短、无意义为主,所以我们在生成规则时,也是这种思路,按顺序从
NAME_DIC
中取就行。为了更随机的去生成名字,还可以将
NAME_DIC
中的字母进行随机排序,可使用
Collections
中的
shuffle
算法实现,并且传入一个伪随机数,只要随机种子一致,就可以得到一样的字典。示例代码如下:
private static String getValue(int index, int seed) {
ArrayList<String> dic = toList();
Collections.shuffle(dic, new Random(seed));
return dic.get((index - 1 + seed) % CLASS_NAME_DIC.length);
}
private static ArrayList<String> toList() {
ArrayList<String> items = new ArrayList<>();
for (String item : CLASS_NAME_DIC) {
items.add(item);
}
return items;
}
在上述代码中,是通过 index 来取名称的,以类中变量名称的生成过程来说明一下上述代码的思路。在一个类中,生成变量名不可以相同,要让每一次生成的名称相同,可以先从
ClassNode
中拿出所有的变量,并将所有的变量名按字典排序,生成名字时,就可以使用这个变量名在排序列表中的下标,作为 index,去字典中去取,就可以得到混淆后的名字。
3. 方法名混淆
按照前面所讲的
变量名
的生成逻辑,类名也可以按照类似的逻辑进行排序生成,但需要注意的是,排序所使用的类名列表应该是包含了整个项目中所有需要保持一致名称类的类名。 方法名的生成核心逻辑也也是类似的,只是用于进行排序的列表存在一些特殊情况需要处理。写到这里,生成
keep-same-proguard.txt
的功能我们已经能够编写出来。下面在来处理方法中的特殊情况:方法重载、多接口继承、多模块冲突。
(1)方法重载
在 Java 代码中,方法重载是非常方法重载与重写是非常常见的功能, 针对此类方法,你需要保持和父类一致,也就是说,在生成混淆映射时,如果父类已经生成过了,那此方法就应该直接使用此名称,直接上例子, 如有如下两个类:
package com.example.proguard;
public class Person {
public void name() {}
public void work() {}
}
分割线\\\\\\\\\\\\\\\
package com.example.proguard;
public class Son extends Person {
public void cry() {}
@Override
public void name() {}
public void study() {}
}
在例子中可以看到,在
Person
这个类中,有两个方法,一个是
name
, 一个是
work
, 那生成映射规则时,方法名按字母排序,则生成出来的配置文件如下:
com.example.proguard.Person -> com.example.A:
void name() -> A
void work() -> BPS: 在 Java 中,不同签名的方法,是可以处理成同名的,但为了逻辑简单,直接让不同的方法,使用不同的混淆名称。
所以,当
Son
这个类在生成混淆配置的时候,
name()
方法需要使用想同的名称
A()
。
针对这种方法重载的情况,在子类生成混淆配置的时候,需要判断当前方法是否从父类继承。翻变了 ASM 的 API, 没有查找到相应判断的方法,最终使用了一个笨办法,直接比较子类方法与父类方法的签名是否一致,如果签名一致,则认为这个方法是从父类继承来的。
除了父类中混淆的方法,还有父类中不可混淆的方法,举个例子,比如我在
Person
中重载了
toString
方法,此方法就不能被混淆,生成的规则中就必须要写明:
void toString() -> toString
(2)子类方法名与父类中的方法名应该互斥
还是上面的那个例子,除了
name()
被映射成了
A
以外,
work()
也被映射成了
B
,那对于子类中的
cry()
方法,以及
study()
方法,是都不可以使用
A
,
B
这两个名字,不然就会存在冲突。
为了解决这个冲突的问题,也找了一个取巧的方法,如前面变量名一样,在生成方法名的时候,也是按字典排序,而 index 不从 0 开始,而是把它所有父类(有接口的继承,所以可能会存在多个)中实现的方法数加在一起,用这个值作为 index 的起始坐标,所以示例中的子类会生成如下结果:
com.example.proguard.Son -> com.example.B:
void cry() -> C
void name() -> A
void study() -> E示例中,如果
name()
方法使用生成的,此处会使用
D
, 因为此方法为重载父类的,所以使用父类中的
A
,在计算
study()
方法时,index 会继续加一,使用 3 来生成其名称,所以此处为
E
(3)多继承中方法冲突
前面的例子,只写了一个父类,现在,对
Son
类进行扩展,除了继承
Person
, 还实现了接口
Walkable
接口,如下所示:
package com.example.proguard;
public interface Walkable {
void walk();
}
分割线\\\\\\\\\\\\\\\
package com.example.proguard;
public class Son extends Person implements Walkable {{
public void cry() {}
@Override
public void name() {}
public void study() {}
@Override
public void walk() {}
}
walk()
这个方法名,在
Son
的混淆中,混淆后的名字必须与
Walkable
中的名字相同。 如果不做处理,
Walkable
生成的混淆结果为:
com.example.proguard.Walkable -> com.example.C:
void walk() -> A
那在生成
Son
的时候,就会出现两个一模一样的
A
方法,分别来自
Person.name()
和
Walkable.walk()
, 这就会导致冲突。这种情况下,在生成混淆名称时,出现
关联
的多个类之间,不同签名的方法必须要使用不同的名称才行。知道问题后,解决方案当然也很简单,找到有关联的接口、类,将他们所有的方法进行去重排序, 生成名字时,用整个方法列表中的 index 去生成即可。
(4)多模块中,类关联无法识别出来
生成
keep-same-proguard.txt
本就是为了解决,在多模块打包中,使用相同的混淆配置。生成规则的核心目标时,在分别打包
A模块
B模块
时,他们共用的类生成的混淆配置是一样的。
在多模块中,有两种情况,下面分别介绍,假设,还是上面三个类
Person
、
Walkable
、
Son
-
情况一
现在有两个模块,分别为
A模块
、
B 模块
,其中
Person
和
Walkable
在
A模块
中,而
Son
在
B模块
中。当打包
A模块
时,从编译后的结果中,无法分析出
Person
与
Walkable
是有关联的,这种情况下,生成配置时,就无法实现方法名不一样。当然,我在解决此问题的时候也使用了简单粗暴的办法,将所有类中的方法进行排序生成混淆后的名字,让所有方法都使用不同的名字。 -
情况二
现在有三个模块,分别是
A模块
、
B模块
、
C模块
, 其中
Person
在
A模块
中,
Walkable
在
B模块
中, 而
Son
在
C模块
中,
C模块
依赖
A模块
、
B模块
。在这种情况下,对
A模块
或
B模块
进行打包时,都无法感知到对方的存在,在生成名字的时候就无法做到方法名互斥。那针对这种情况,要怎么处理呢?要让每一个模块中生成的方法名不一致,有一个简单的办法,给每一个方法名前加一个前缀,而不同模块的前缀可以使用
模块名
的混淆结果来做。
方法名的混淆之所以复杂,是因为在编译模块时,无法窥得项目全貌,无法将所有模块中的 class 获取到并构建成一个图。综上所述,在方法名做混淆的时候,为降低逻辑复杂度,解决冲突问题,需要遵循一下几条规则:
-
子类中与父类中,名称和方法签名一致的方法,使用相同的混淆名称,忽略访问控制修饰符
-
一个模块类的所有方法名互斥,生成时,使用
模块中
全量方法名进行排序 -
模块类生成的混淆方法名统一添加前缀,前缀使用当前模块按基础混淆规则生成的混淆名称
按照以上规则,方法混淆处理起来就非常方便,可以很快速的实现方法名的生成。
4. 添加混淆规则给混淆任务使用
到此,已经可以很方便的将混淆配置生成,并写入到文件中,在本项目中,生成的文件写入到
build/generated/proguard/keep-same-proguard.txt
文件中,也可以方便的去查看。下一步是将这个文件给
minifyReleaseWithR8
这个任务使用。
刚开始,我天真的以为,我直接将输出的文件地址放入到
minifyReleaseWithR8
任务的
inputFiles
里面,就可以使用我的混淆配置,经过多翻尝试后,发现这样并不能让
minifyReleaseWithR8
使用我的配置。正当我一筹莫展时,我发现了
build.gradle
里面的一个配置:
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
我可以在我的任务中,直接将混淆规则配置文件添加到
proguardFiles
中,如下所示:
project.android.buildTypes.release.proguardFiles += "generate-proguard-rules.txt";
将生成的混淆配置添加到
proguardFiles
里面,就可以将生成的规则应用于混淆的流程中。
六、总结
以上,本文从 SDK 打包混淆所遇到的问题开始,记录了使用 ProGuard 以及编写自动化脚本过程所遇到的问题、我自己的思考、以及解决方案。在这之中,针对遇到的问题,我所提到的解决方案并不一定是最佳或最优方案,只是在那个时候,实现最方便,也能满足我的需求。如果朋友们有什么新奇的想法,欢迎与我沟通交流。
— 推荐阅读 —
☞ 深入 Android 混淆实践:ProGuard 通关秘籍