背景
Crawlab支持多语言多框架,但是本文爬虫都是基于Scrapy 1.8.0
前言
- 开发语言是Golang
- Crawlab主要解决的是
大量爬虫
管理
困难的问题
,例如需要监控上百个网站的参杂scrapy和
selenium(自动化测试框架)
的项目不容易做到同时管理,而且命令行管理的成本非常高,还容易出错。Crawlab支持
任何语言和任何框架
,配合任务调度、任务监控,很容易做到对成规模的爬虫项目进行有效监控管理。- 可配置爬虫,节省时间;自定义爬虫,更加灵活,适合复杂的爬虫(例如需要登陆)
功能介绍
Crawlab 是一个企业级的开箱即用的爬虫管理平台,包含很多针对爬虫调度监控的实用功能,例如节点注册发现、任务调度、文件编辑、结果查看、日志管理等。
这些功能帮助爬虫开发者专注于页面抓取,而不用担心生产环境中要求的调度、监控、储存等繁琐的逻辑,大幅提升开发者的工作效率。
-
节点管理
Crawlab 天然支持分布式爬虫,因此支持多节点管理,让爬虫程序能够在多个节点、多台服务器上运行,以便最大化利用带宽及计算资源。爬虫程序通常会有一些第三方依赖的包和库,也可以通过界面来安装。
-
爬虫管理
爬虫管理是 Crawlab 的核心功能,Crawlab 能帮助开发者们省去很多管理爬虫的繁琐工作。可以在线编辑爬虫文件,还支持爬虫程序的数据统计功能,包括运行次数、抓取结果数、运行时长等等。
也支持日志,还支持查看任务结果,开发者可以在界面上可视化浏览抓取到的数据,方便调试、检验任务的结果内容。
-
定时任务
-
消息通知
Crawlab 的消息通知功能支持邮件、钉钉、企业微信三个渠道,能在任务结束或出错的时候及时报警。
还有很多功能探索。
安装
推荐配置:
- centos7
- Docker: 20.10+
docker安装链接
- Docker-Compose: 4.4.4+
Docker-Compose安装链接
- python3、pip3(
python3、pip3安装链接
)- 官网拉Crawlab镜像,需要配置镜像加速,我在安装docker的时候已经配置了阿里云的镜像加速,效果是一样的。
# 创建docker-compose.yml
touch /opt/docker-compose/docker-compose.yml
# 内容 version: '3.8'
services:
master:
image: crawlab:lx
container_name: master
networks:
lx_net:
environment:
# CRAWLAB_API_ADDRESS: "https://<your_api_ip>:<your_api_port>" # backend API address 后端 API 地址. 适用于 https 或者源码部署
eRAWLAB_SERVER_MASTER: "Y" # whether to be master node 是否为主节点,主节点为 Y,工作节点为 N
CRAWLAB_MONGO_HOST: "mongo" # MongoDB host address MongoDB 的地址,在 docker compose 网络中,直接引用服务名称
# CRAWLAB_MONGO_PORT: "27017" # MongoDB port MongoDB 的端口
# CRAWLAB_MONGO_DB: "crawlab_test" # MongoDB database MongoDB 的数据库
# CRAWLAB_MONGO_USERNAME: "username" # MongoDB username MongoDB 的用户名
# CRAWLAB_MONGO_PASSWORD: "password" # MongoDB password MongoDB 的密码
# CRAWLAB_MONGO_AUTHSOURCE: "admin" # MongoDB auth source MongoDB 的验证源
CRAWLAB_REDIS_ADDRESS: "redis" # Redis host address Redis 的地址,在 docker compose 网络中,直接引用服务名称
# CRAWLAB_REDIS_PORT: "6379" # Redis port Redis 的端口
# CRAWLAB_REDIS_DATABASE: "1" # Redis database Redis 的数据库
# CRAWLAB_REDIS_PASSWORD: "password" # Redis password Redis 的密码
# CRAWLAB_LOG_LEVEL: "info" # log level 日志级别. 默认为 info
# CRAWLAB_LOG_ISDELETEPERIODICALLY: "N" # whether to periodically delete log files 是否周期性删除日志文件. 默认不删除
# CRAWLAB_LOG_DELETEFREQUENCY: "@hourly" # frequency of deleting log files 删除日志文件的频率. 默认为每小时
# CRAWLAB_SERVER_REGISTER_TYPE: "mac" # node register type 节点注册方式. 默认为 mac 地址,也可设置为 ip(防止 mac 地址冲突)
# CRAWLAB_SERVER_REGISTER_IP: "127.0.0.1" # node register ip 节点注册IP. 节点唯一识别号,只有当 CRAWLAB_SERVER_REGISTER_TYPE 为 "ip" 时才生效
# CRAWLAB_TASK_WORKERS: 8 # number of task executors 任务执行器个数(并行执行任务数)
# CRAWLAB_RPC_WORKERS: 16 # number of RPC workers RPC 工作协程个数
# CRAWLAB_SERVER_LANG_NODE: "Y" # whether to pre-install Node.js 预安装 Node.js 语言环境
# CRAWLAB_SERVER_LANG_JAVA: "Y" # whether to pre-install Java 预安装 Java 语言环境
# CRAWLAB_SETTING_ALLOWREGISTER: "N" # whether to allow user registration 是否允许用户注册
# CRAWLAB_SETTING_ENABLETUTORIAL: "N" # whether to enable tutorial 是否启用教程
CRAWLAB_NOTIFICATION_MAIL_SERVER: "smtp.qq.com" # STMP server address STMP 服务器地址
CRAWLAB_NOTIFICATION_MAIL_PORT: 587 # STMP server port STMP 服务器端口
CRAWLAB_NOTIFICATION_MAIL_SENDEREMAIL: "1393519068@qq.com" # sender email 发送者邮箱
CRAWLAB_NOTIFICATION_MAIL_SENDERIDENTITY: "clefobwffuuzgjfe" # sender ID 发送者 ID
CRAWLAB_NOTIFICATION_MAIL_SMTP_USER: "1393519068@qq.com" # SMTP username SMTP 用户名
CRAWLAB_NOTIFICATION_MAIL_SMTP_PASSWORD: "clefobwffuuzgjfe" # SMTP password SMTP 密码
ports:
- "8080:8080" # frontend port mapping 前端端口映射
depends_on:
- mongo
- redis
# volumes:
# - "/var/crawlab/log:/var/logs/crawlab" # log persistent 日志持久化
# worker:
# image: tikazyq/crawlab:latest
# container_name: worker
# environment:
# CRAWLAB_SERVER_MASTER: "N"
# CRAWLAB_MONGO_HOST: "mongo"
# CRAWLAB_REDIS_ADDRESS: "redis"
# depends_on:
# - mongo
# - redis
# environment:
# MONGO_INITDB_ROOT_USERNAME: username
# MONGO_INITDB_ROOT_PASSWORD: password
# volumes:
# - "/var/crawlab/log:/var/logs/crawlab" # log persistent 日志持久化
mongo:
image: mongo:latest
restart: always
networks:
lx_net:
# volumes:
# - "/opt/crawlab/mongo/data/db:/data/db" # make data persistent 持久化
ports:
- "27017:27017" # expose port to host machine 暴露接口到宿主机
redis:
image: redis:latest
restart: always
networks:
lx_net:
# command: redis-server --requirepass "password" # set redis password 设置 Redis 密码
# volumes:
# - "/opt/crawlab/redis/data:/data" # make data persistent 持久化
ports:
- "6379:6379" # expose port to host machine 暴露接口到宿主机
# splash: # use Splash to run spiders on dynamic pages
# image: scrapinghub/splash
# container_name: splash
# ports:
# - "8050:8050"
elasticsearch:
image: elasticsearch:7.6.1
restart: always
ports:
- "9200:9200"
networks:
lx_net:
ipv4_address: 172.18.0.7
environment:
discovery.type: "single-node"
ES_JAVA_OPTS: "-Xms64m -Xmx512m"
kibana:
image: kibana:7.6.1
restart: always
ports:
- "5601:5601"
volumes:
- "/home/docker-volume/kibana:/etc/kibana"
networks:
lx_net:
networks:
lx_net:
ipam:
driver: default
config:
- subnet: "172.18.0.0/24"
# - gateway: "172.18.0.1"
# 安装完后,在浏览器输入服务器ip:8080就可以看到crawlab的界面了
# 启动Crawlab,需要进入/opt/docker-compose目录下
docker-compose up -d
todo 有时间试试k8s部署,需要几台服务器
还有多节点部署,得复习完mongo和redis再回来看这个
更新或重启
# 关闭并删除 Docker 容器
docker-compose down
# 拉取最新镜像
docker pull tikazyq/crawlab:latest
# 启动 Docker 容器
docker-compose up -d
爬虫
自定义爬虫
自定义爬虫是指用户可以添加的任何语言任何框架的爬虫,高度自定义化。当用户添加好自定义爬虫之后,Crawlab 就可以将其集成到爬虫管理的系统中来。
有两种方式来上传爬虫项目:
- 通过 Web 界面(灵活)
- 通过 CLI 命令行工具(简单,推荐)
这只说通过 Web 界面
-
爬虫项目根目录下打包成zip文件
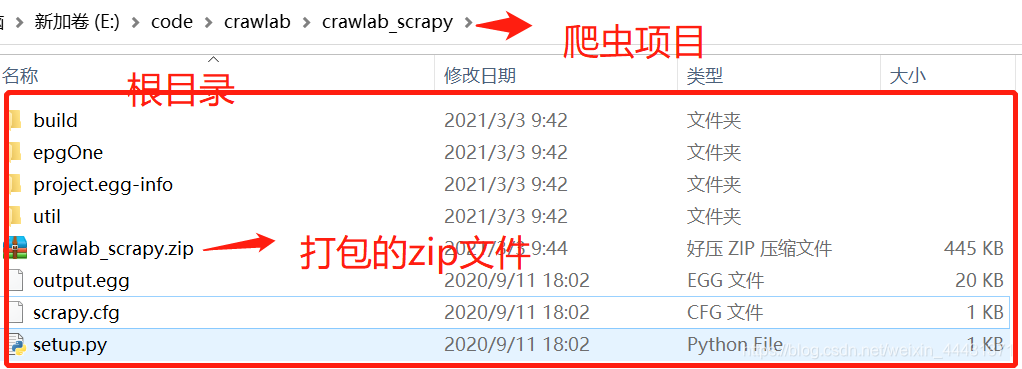
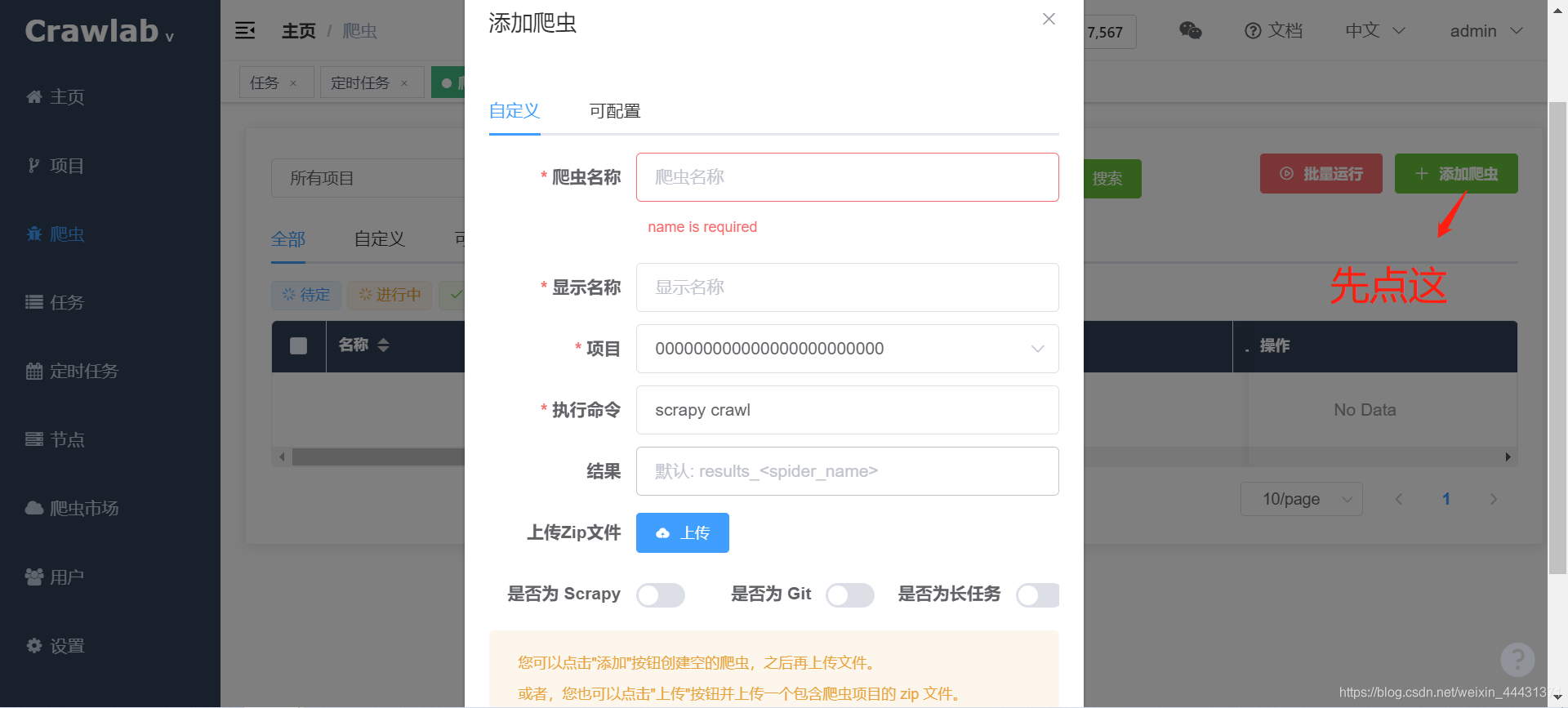
- 输入爬虫数据
- 爬虫名称:爬虫的唯一识别名称建议为没有空格和特殊符号的小写英文,可以带下划线;
- 显示名称:爬虫显示在前端的名称,可以为任何字符串;
- 执行命令:爬虫将在 shell 中执行的命令,最终被执行的命令将为 执行命令 和 参数 的组合,scrapy项目直接把 是否为scrapy 打开会自动填充
- 结果:”结果集“的意思,爬虫抓取结果储存在 MongoDB 数据库里的集合(Collection),类似于 SQL 数据库中的表(Table)。
然后点击上传按钮,上传刚才打包好的zip文件,自定义爬虫创建成功
scrapy多爬虫项目,只需要定义一个全局变量
name
来判定爬虫的唯一性,然后crawlab会自动识别 spiders 文件下的爬虫
可配置爬虫
crawlab可配置爬虫是基于Scrapy,目的是将具有相似网站结构的爬虫项目可配置化,将开发爬虫的过程流程化,大大提高爬虫开发效率。
这句话的意思是,如果你要爬取的网站结构是类似的,例如顶级分类就是 a 标签,下一页就是 b 标签,详情就是 c 标签,那么就可以
直接进行阶段性的配置,不需要再写代码
了。
长任务爬虫
长任务爬虫(Long-Task Spiders)是一种特殊的 自定义爬虫,这种爬虫跑任务不会停止,一般会一直获取消息队列中的 URL 并抓取,只有当用户主动停止或遇到错误时才会停止运行。长任务爬虫通常是分布式运行的,为的是有效的利用网络带宽资源和其他计算资源,将分布式节点的效率利用到极致。典型的例子就是基于 Scrapy 的分布式爬虫 scrapy-redis。
要启用长任务爬虫,只需要在 创建爬虫 或 爬虫详情 中打开 “是否为长任务开关” 就可以了。
部署爬虫
Crawlab是自动部署爬虫的,每60秒主节点会将该节点上的爬虫文件同步给所有在线节点。因此,用户上传了爬虫之后,只需要等待最多60秒,就可以在所有节点上运行爬虫任务了。
运行爬虫
运行节点的分配策略
- 所有节点:该任务在所有在线节点上同时运行,该策略比较适合大型的分布式爬虫;
- 指定节点:指定一个在线节点上运行,该策略适合有不同拓扑结构节点分布的爬虫,例如一些节点分布在国内,另一些分布在国外;
- 随机:系统任意分配一个节点运行该任务,该策略是最简单的运行策略,能够平均分配所有有效资源。
自动安装依赖
对于 Docker 安装 Crawlab 的开发者来说,每次更新容器(例如 down & up)时候会比较繁琐,因为需要重新安装爬虫的依赖,这对于长期使用 Crawlab 的用户来说,是一个痛点。
为了使用自动安装依赖的功能,用户需要将在爬虫项目中,将 requirements.txt(Python)或 package.json (Node.js)放在爬虫根目录,并上传到 Crawlab。Crawlab 会自动扫描代码目录,如果存在 requirements.txt 或 package.json,就会自动执行对应的安装程序,将指定的依赖安装到 Crawlab 节点上。
# python 导出模块版本,注意编码
pip3 list > requirements.txt
手动安装依赖

-
界面安装
在节点列表 -> 节点详情页可以查看安装的依赖,也可以安装依赖,相当于命令
pip3 install 依赖名
- 上传一个特殊爬虫,将 pip、npm 等安装命令写在一个脚本中,然后执行这个脚本,或者直接将安装命令写在“执行命令”中;
- 构建新镜像
由于项目中引入的第三方库并不多,而且并不仅仅是一个
pip3 install
就可以安装好的,所以只能进入
主节点(也就是docker容器内)
一个一个安装,我这是测试项目,只有一个节点,相对容易,如果多节点安装,那么需要每一个节点都安装一遍,这就得想别的办法了。
# 安装pycurl
apt-get install libcurl4-gnutls-dev
apt-get install libghc-gnutls-dev
pip3 install pycurl
# 安装cv2
pip3 install opencv-python
pip3 install opencv-contrib-python
apt-get update
apt-get install -y libgl1-mesa-dev
dpkg --configure -a
apt-get install -y libgl1-mesa-dev
apt-get update
apt-get install libglib2.0-dev
以上python第三方库安装好以后,测试都是统一的,进入python3终端,导入模块
python3
import pycurl
# 不报错的话就证明安装成功了
到这儿我的scrapy爬虫可以正常运行了
任务
任务日志
Crawlab 会收集爬虫任务的运行日志,方便用户调试和监控爬虫程序。查看日志所在位置为
任务详情 > 日志 标签
。
- 打印日志python可以使用print()
- 日志搜索可以使用正则表达式来判断是否为错误日志
- Crawlab 会收集爬虫任务的运行日志,方便用户调试和监控爬虫程序。查看日志所在位置为 任务详情 > 日志 标签。
-
Crawlab 内置了日志异常检测,原理是通过正则表达式来完成的。默认会用
error、exception、traceback
来匹配日志内容判断该日志文本是否为错误日志。 -
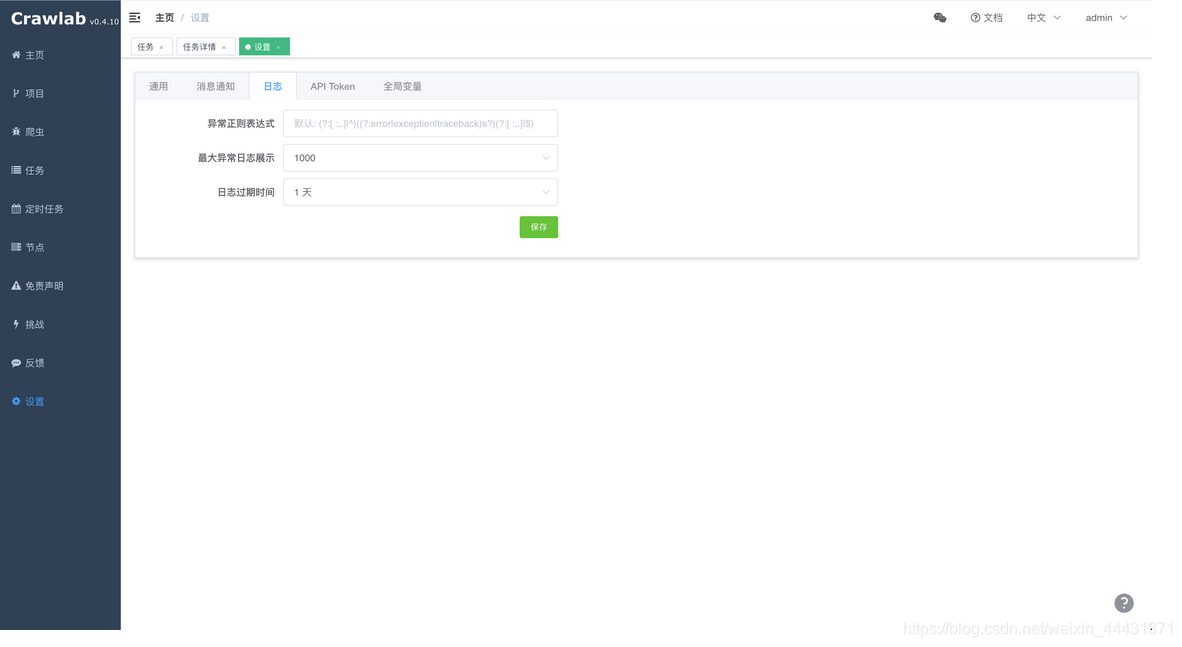
- 异常正则表达式:这是判断异常日志文本的方式,如果该正则表达式能匹配上日志文本行,则该行为错误或异常日志;
- 最大异常日志展示:在日志详情中,“错误数” 的最大展示行数,默认为 1000;
- 日志过期时间:日志在多少时间之后被自动删除,默认不删除,但强烈建议设置一个过期时间以防止日志撑满数据库。
原理
Crawlab 的日志和异常日志是分别储存在 MongoDB 数据库的 logs 和 error_logs collection 中的。对于大数据量的日志来说,数据库很容易撑满,因此我们
强烈推荐设置一个过期时间
。
logs 的索引有三个:
task_id 和 seq 组合索引,方便分页查询(未带搜索条件),查询开销小;
task_id 和 msg 组合索引,方便搜索查询,查询开销较大;
expire_ts TTL 索引,方便自动删除日志。
其中, task_id 为任务 ID,seq 为日志的序号,msg 为日志内容,expire_ts 为过期时间。
sdk
pip install crawlab-sdk
crawlab --help
爬虫集成
如果您想在 Crawlab 的界面上看到您的抓取结果,您需要将您的爬虫与 Crawlab 进行集成。
以下是爬虫集成的前提条件:
-
需要设置结果集;
* 需要将数据写在与 Crawlab 一个数据库中,例如 crawlab_test;
* 需要在爬虫中将结果写回指定的数据集中(CRAWLAB_COLLECTION),并且在 task_id (CRAWLAB_TASK_ID)字段上赋值。
与scrapy集成
todo这种集成好像是需要scrapy的pipeline的,等看完scrapy再回头来看这个
在
settings.py
中找到
ITEM_PIPELINES
(dict 类型的变量),在其中添加如下内容。
ITEM_PIPELINES = {
'crawlab.pipelines.CrawlabMongoPipeline': 888,
}
然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在
任务详情-结果
里。
与通用 Python 爬虫集成
将下列代码加入到您爬虫中的结果保存部分。
# 引入保存结果方法
from crawlab import save_item
# 这是一个结果,需要为 dict 类型
result = {'name': 'crawlab'}
# 调用保存结果方法
save_item(result)
然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在
任务详情-结果
里。
todo
原理暂时看不懂的有些多,有时间再说吧
遇到的问题
之前有个需求是,在运行爬虫的时候需要指定url,这时候,在crawlab填写url参数时发现程序0s运行完成,无日志,服务器无报错,
最终问题是它的参数解析不了&,需要&
部分内容参考自:
https://www.cnblogs.com/kimkat/p/10100365.html
https://blog.csdn.net/RPG_Zero/article/details/109253054?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs&dist_request_id=1328592.24607.16148500388292037&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs
https://blog.csdn.net/qq_33594359/article/details/85067199