前置准备
为了彻底搞懂zk选举leader的过程,需要在windows本地搭建一个伪集群出来,通过实际操作,观察集群的节点的变化。但是在实操过程中,发现windows搭建的一些坑,这记录下。
伪集群搭建步骤
1.参考此博客进行搭建,
https://www.cnblogs.com/qlqwjy/p/10491456.html
2.依次启动,启动后,无法使用zkServer.cmd status命令,无法观察哪一个节点是leader,各种查阅后,发现zkServer.cmd在windows上就是用不了,硬伤啊。google一下后,发现可以使用nc命令去查看状态,参考博客:
https://blog.csdn.net/hongweigg/article/details/52933113
3.尝试后,发现nc命令用不了,window需要安装nc客户端,参考博客:
https://blog.csdn.net/qq_37585545/article/details/82250984
4.执行nc命令,报错,解决方案:
https://blog.csdn.net/qq_32575047/article/details/93487304
5.修改zk节点内zoo.cfg文件,重启集群后,生效。
Leader选举流程
前提条件:以三台机器为例子,分别是:zk1, zk2, zk3,myid分别是1,2,3
名词解释:
MYID: 机器服务标识ID
myid一般也是数字,用来标识zk的机器,例如在zk1的data目录下有一个myid的文件,里面写入一个数值1,在zk2的data目录下有一个myid文件,里面写入一个数值2,以此类推。同时zoo.cfg的配置文件内,也是采用server.1=xx,server2=xx。
zk集群中的n是根据这里配置的服务节点数来计算的。这里配置了三个,n即为3。
tickTime=2000
initLimit=10
syncLimit=5
dataDir=E:\\aa_new_devlope\\apache_zookeeper_cluster\\zk1\\data
clientPort=2181
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883
4lw.commands.whitelist=*
SID:服务器ID
SID是一个数字,用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid的值一致。
ZXID:事务ID
ZXID是一个事务ID,用来唯一标识一次服务器状态的变更。在某一个时刻,集群中每台机器的ZXID值不一定全都一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
Vote:投票
Leader 选举
,顾名思义必须通过投票来实现。当集群中的机器发现自己无法检测到Leader机器的时候,就会开始尝试进行投票。
大概逻辑:
leader选举的逻辑与人类世界的投票非常相似。从客观公平的角度来说,投票是投给能力比较强的人,zk中可以通过zxId以及myId来对比出能力较强的节点。假如,在一个陌生环境内投票,人与人之间都不熟,很有可能,投票一开始是投给自己,这就和zk节点在启动一开始,会把选票投给自己一样。但是后来发现,有其他人能力比自己强,这个时候人类世界可能会改票,zk也一样,对比完zxId以及myId后,会有改票的操作,改完后,再把结果发送给其他节点。每一个zk节点都有一个投票箱,其实就是修改投票箱内的结果,再把修改的结果发送给其他节点,再次进行对比。最后,根据过半机制,筛选出leader。
详细流程:
zk集群启动时选举
前提:
1、按照顺序启动zk1,zk2,zk3, 假设三台zk的zxId相同,myid分别是1,2,3,ZooKeeper的集群规模至少是2台机器。
2、只有启动了两个节点后,两个节点能够互相通信,才进入选举leader的流程。
3、在集群启动时,一台服务器需要去连另外一台服务器,从而建立Socket用来进行选票传输。那么如果现在A服务器去连B服务器,同时B服务器也去连A服务器,那么就会导致建立了两条Socket,我们知道Socket是双向的,Socket的双方是可以相互发送和接收数据的,那么现在A、B两台服务器建立两条Socket是没有意义的,所以ZooKeeper在实现时做了限制,只允许
服务器ID较大者去连服务器ID较小者,小ID服务器去连大ID服务器会被拒绝。
ps: 只能zk2连接zk1,zk3连接zk2,zk3连接zk1,但是通道是双向的,既可以接受投票也可以写入投票
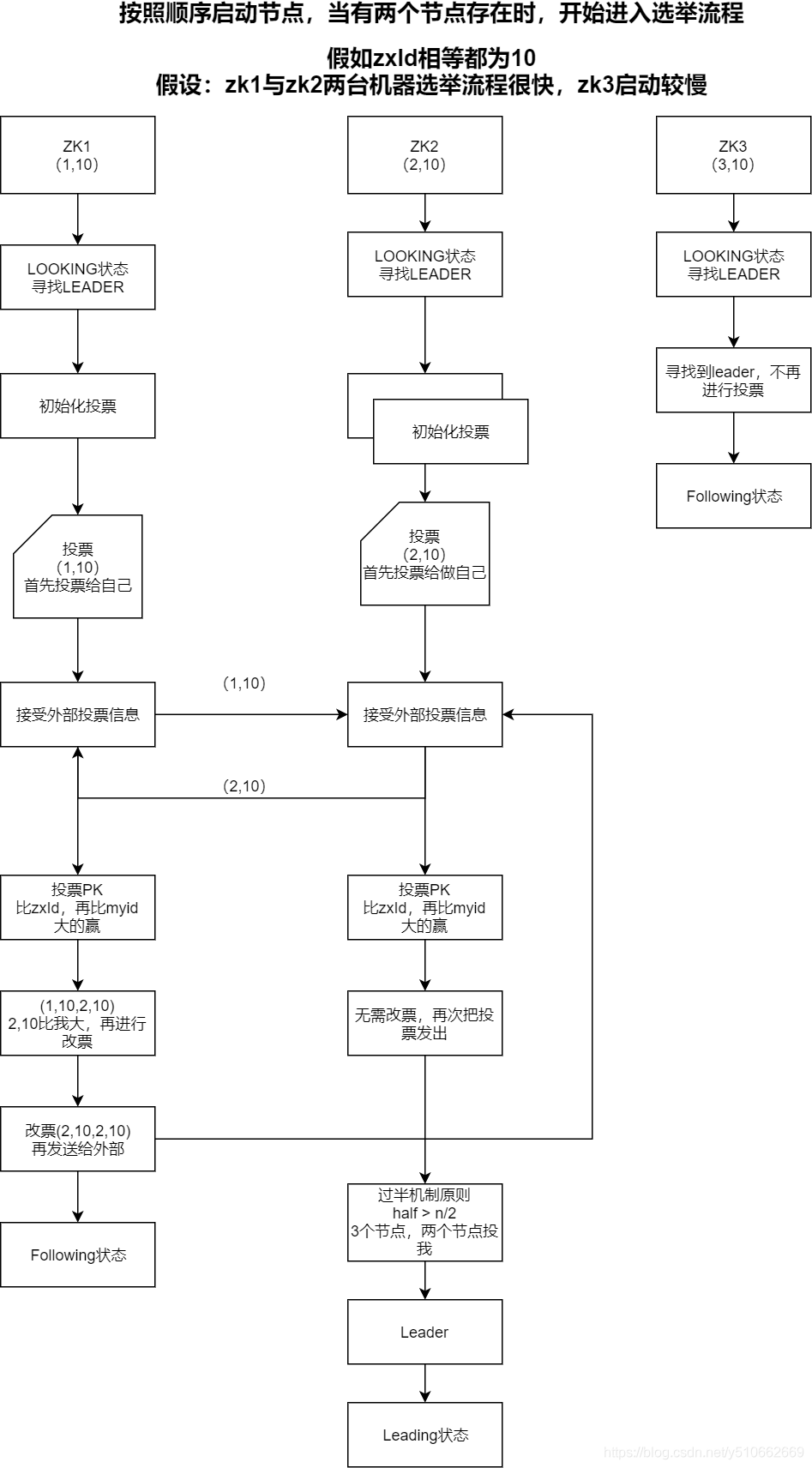
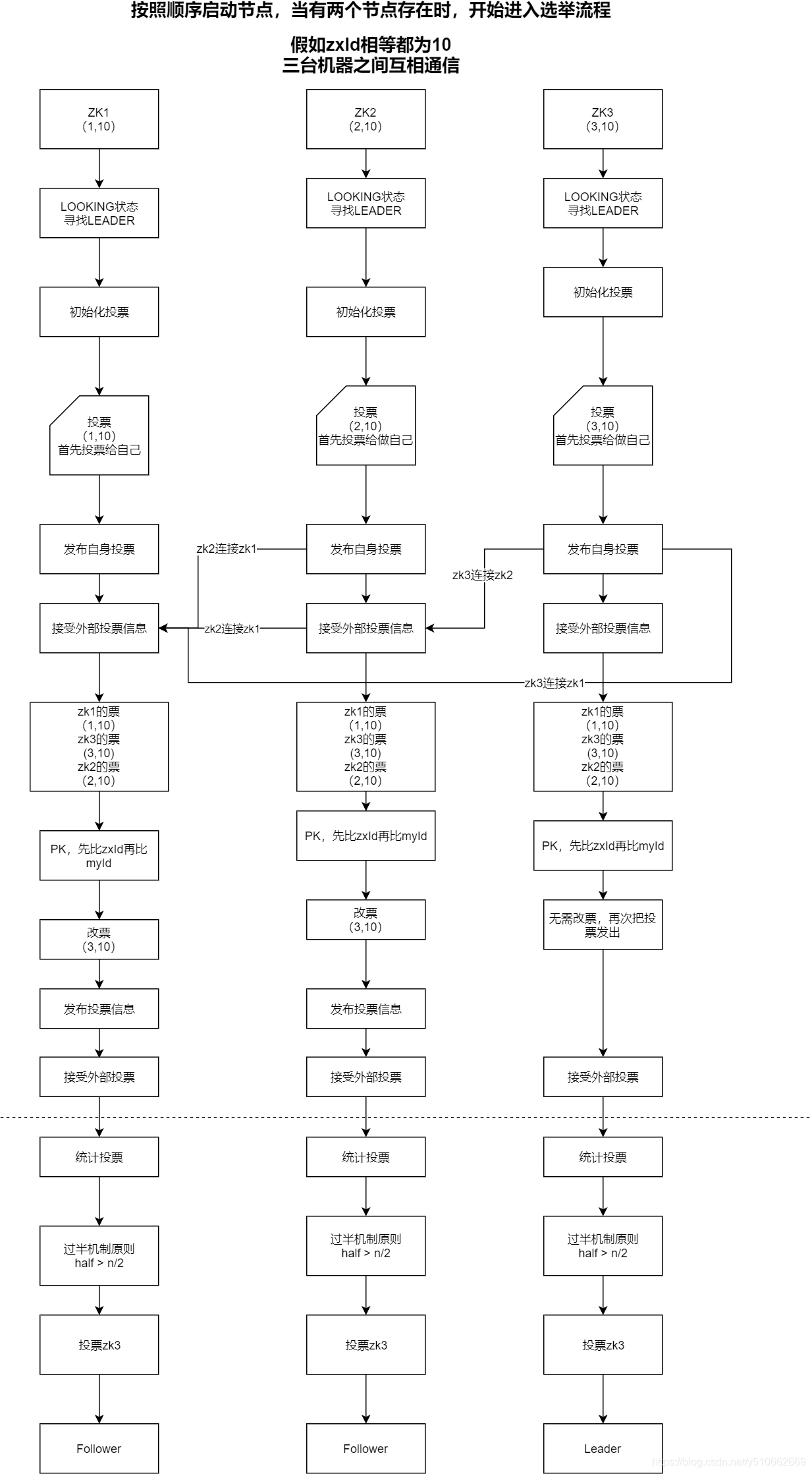
Leader宕机时的选举流程,同以上的流程类似。假如节点在启动时进行选举,有可能前两个节点启动的速度快,那么根据前两个节点就已经选出了leader,后面的节点就不需要参与投票选举了,即便后面的节点zxid和myid都比leader节点要大,也是会作为一个follower加入。
实例演示:
zxId都相等,zk1,zk2,zk3的myid分别是1,2,3
端口说明:
218x:客户端(应用程序)连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端
288x:该服务器与集群中的 Leader 服务器交换信息的端口
388x:选举通信端口,如果集群中的 Leader 服务器挂了,需要选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口
启动步骤:
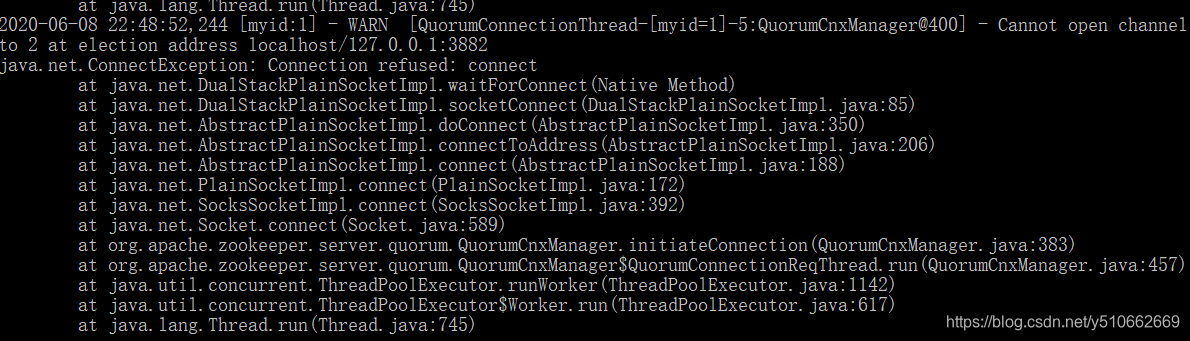
第一台节点启动时,会出现连接不上3883端口的异常,这个是正常的,因为目前只有这一个节点,还暂时无法同集群内的其他节点进行选举通信。
第二台节点启动完成后,我们使用nc命令,观察下集群中的状态:
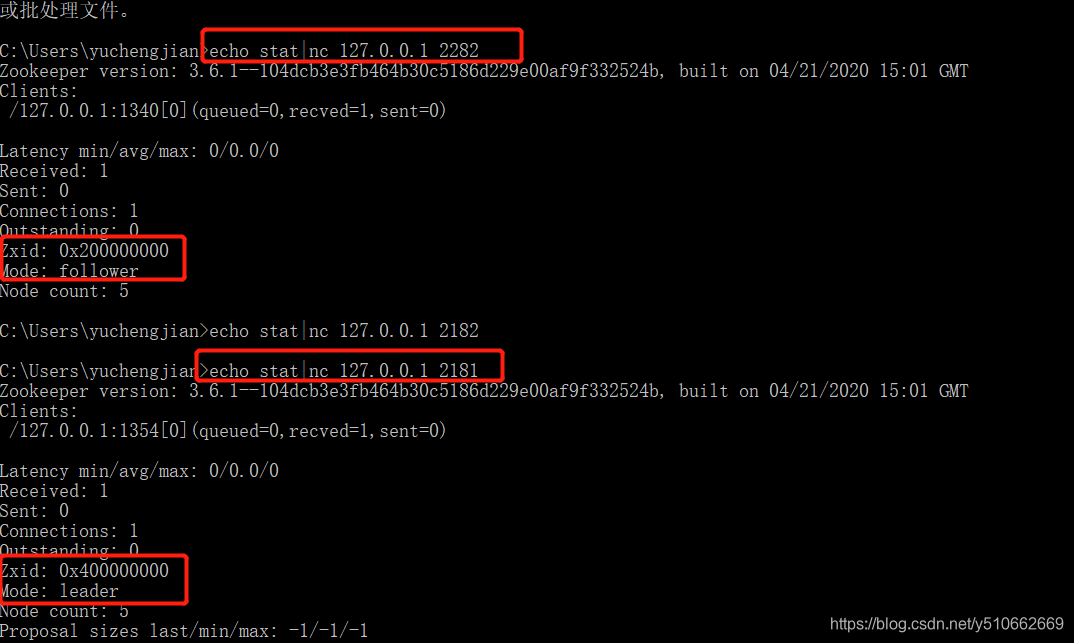
目前启动了两个节点,已经选举出了leader,第三台机器就不会再参与投票选举了。
注意:
ZooKeeper集群在进行领导者选举的过程中不能对外提供服务,根据网上的说法,最多有30秒不可用时间。这对于高可用的互联网应用来说是致命的,所以这也是阿里选择nacos的原因之一吧。
总结:
-
文章参考《从paxos到zookeeper》以及
https://mp.weixin.qq.com/s/z73f6rQXYvh2byfkO8tMoA
- 对于leader选举的流程有了一个大概的认知,zk能够保持数据一致性的原因,主要是有三点:1)leader选举机制。2)两阶段的事务。3)过半机制。后面重点研究下zab协议以及两阶段的事务。