1,Sqoop 基本命令介绍
-
1,帮助信息
sqoop help -
2,查看具体某个命令的使用方式
sqoop help command 例如:sqoop help import
2,MySQL 数据准备
-
1,开启 MySQL
service mysql start
-2 ,查看 MySQL 的数据
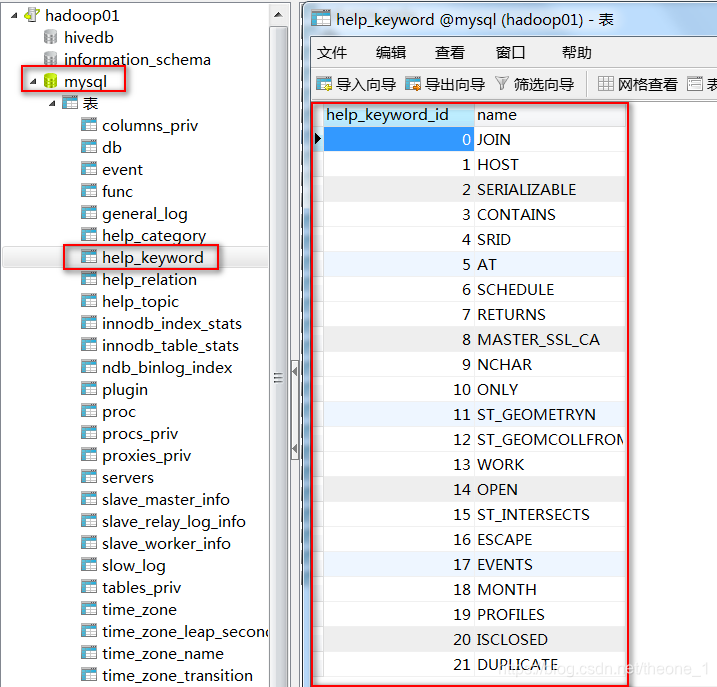
Sqoop 数据导入
MySQL 数据导入 HDFS
1,语法
-
sqoop import (generic-args) (import-args)
“import工具”:导入单个表从 RDBMS 到 HDFS。
表中的每一行被视为 HDFS 的记录。所有记录都存储为文本文件的文本数据(或者 Avro、 sequence 文件等二进制数据)。 -
常用参数
--connect <jdbc-uri> ## JDBC 连接地址
--connection-manager <class-name> ## 指定使用的连接管理类
--driver <class-name> ## 指定JDBC要使用的驱动类
--help ## 打印用法帮助信息
-P ## 从控制台读取输入的密码
-m ## 复制过程中使用1个map作业,若是不写默认是使用4个map任务并行导入
--password <password> ## 密码
--username <username> ## 账号
--table <tablename> ## MySQL表名
--fields-terminated-by <separator> ## 输出文件中的行的字段分隔符
--target-dir <dir> ## 指定HDFS路径
--where <condition> ## 指定导出时所使用的查询条件
--verbose ## 在控制台打印出详细运行信息
--connection-param-file <filename> ## 可选,一个记录着数据库连接参数的文件
2,应用案例
- 1,普通导入
命令:
sqoop import \
--connect jdbc:mysql://hadoop01:3306/mysql \
--username root \
--password shiny \
--table help_keyword \
-m 1
验证结果
默认会保存在 HDFS 上的 /user/shiny/help_keyword 目录中,用逗号对字段进行分隔
- 2,指定分隔符和导出路径
命令:
sqoop import \
--connect jdbc:mysql://hadoop01:3306/mysql \
--username root \
--password shiny \
--table help_keyword \
--target-dir /mysqltohdfs/help_keyword \
--fields-terminated-by '\t' \
-m 1
验证结果:
使用 –target-dir 参数,指定导出的文件存储路径为/mysqltohdfs/help_keyword,并指定用”\t”对字段进行分隔
- 3,指定 where 条件
命令:
sqoop import \
--connect jdbc:mysql://hadoop01:3306/mysql \
--username root \
--password shiny \
--table help_keyword \
--where 'name = "ONLY"' \
--target-dir /mysqltohdfs/where/help_keyword \
--fields-terminated-by '\t' \
-m 1
验证结果:
将name = “ONLY” 的记录写入 /mysqltohdfs/where/help_keyword 目录中,并用”\t”对字段进行分隔
-
4,导入 Query 结果数据
语法解释:–query,-e (statement)
从查询结果中导入数据,该参数使用时必须指定 –-target-dir,在查询语句中一定要有 where 条件且在 where 条件中需要包含 $CONDITIONS
示例:--query 'select * from person where $CONDITIONS ' --target-dir /user/mysqltohdfs/person
语法解释:–split-by (column-name)
表的列名,用来切分导入的数据,默认值为主键。一般后面跟主键及数字类型的字段。
命令:
sqoop import \
--connect jdbc:mysql://hadoop01:3306/mysql \
--username root \
--password shiny \
--query 'select * from help_keyword where help_keyword_id < 10 and $CONDITIONS' \
--split-by help_keyword_id \
--target-dir /mysqltohdfs/query/help_keyword \
--fields-terminated-by '\t' \
-m 2
验证结果:
将HQL查询的结果写入/mysqltohdfs/query/help_keyword 目录中,并用”\t”对字段进行分隔
-
5,增量导入
-
1,什么是增量导入?
仅导入表中新添加的行 -
2,为什么引入?
在实际的生产环境下,我们常常会往表中不断增加数据,避免发生数据冗余,所以引入增量导入。
在数据库的表字段中常常会设置一个自增的字段来作为数据表的主键,我们这里以 ID 字段来作为判断数据行是否为增量数据的依据。last-value 设置上次导入的 ID 的最大值。若是不指定 last-value 值,将会将表的所有数据进行导入。 -
3,语法解释:

-
4,命令
sqoop import \ --connect jdbc:mysql://hadoop01:3306/mysql \ --username root \ --password shiny \ --table help_category \ --target-dir /mysqltohdfs/help_category \ --incremental append \ --check-column help_category_id \ --last-value 30 \ -m 1 -
5,验证结果
导入的是 help_category_id > 30 的数据,不包含 help_category_id = 30
-
MySQL 数据导入 Hive
1,实现过程
- 1,将数据导入 HDFS(可在 HDFS 上找到相应目录);
- 2,创建 Hive 表名相同的表;
- 3,将 HDFS 上数据 Load 到 Hive 表中。
2,语法
-
sqoop import (generic-args) (import-args)
-
常用参数
--hive-home <dir> ## 直接指定Hive安装目录 --hive-import ## 使用默认分隔符导入Hive --hive-overwrite ## 覆盖掉在Hive表中已经存在的数据 --create-hive-table ## 生成与关系数据库表的表结构对应的Hive表。如果表不存在,则创建,如果存在,报错 --hive-table <table-name> ## 导入到Hive指定的表,可以创建新表 --fields-terminated-by ## 指定分隔符(Hive默认的分隔符是/u0001) --lines-terminated-by ## 设定每条记录行之间的分隔符,默认是换行,但也可以设定自己所需要的字符串 --delete-target-dir ## 每次运行导入命令前,若有就先删除target-dir指定的目录
3,应用案例
1,普通导入
-
1,命令
sqoop import \ --connect jdbc:mysql://hadoop01:3306/mysql \ --username root \ --password shiny \ --table help_keyword \ --hive-import \ -m 1 -
2,验证结果
导入数据到 Hive 表,默认表在 default 数据库下,表名与 MySQL 中的一样,字段之间采用’/u0001’分隔。HDFS中的存储地址为/user/hive/warehouse/help_keyword(表名)。
2,指定分隔符和数据库
-
1,命令
sqoop import \ --connect jdbc:mysql://hadoop01:3306/mysql \ --username root \ --password shiny \ --table help_keyword \ --hive-import \ -m 1 \ --create-hive-table \ --hive-table shiny.new_help_keyword \ --fields-terminated-by "," \ --lines-terminated-by "\n" -
2,验证结果
导入数据到数据库 shiny 下的new_help_keyword表中,字段之间采用’,’分隔。HDFS中的存储地址为/user/hive/warehouse/shiny.db/new_help_keyword(表名)。
3,覆盖表中数据
-
1,命令
sqoop import \ --connect jdbc:mysql://hadoop01:3306/mysql \ --username root \ --password shiny \ --table help_category \ --hive-import \ -m 1 \ --hive-overwrite \ --hive-table shiny.new_help_keyword \ --fields-terminated-by "," \ --lines-terminated-by "\n" \ --delete-target-dir -
2,验证结果
只是覆盖表中的数据,并不覆盖表结构。HDFS中的存储地址为/user/hive/warehouse/shiny.db/new_help_keyword(表名)。
MySQL 数据导入 HBase
1,语法
-
sqoop import (generic-args) (import-args)
-
常用参数
--column-family <family> ## 把内容导入到HBase当中,默认是用主键作为split列 --hbase-create-table ## 创建HBase表 --hbase-row-key <col> ## 指定字段作为RowKey,如果输入表包含复合主键,用逗号分隔 --hbase-table < table-name > ## 指定HBase表
2,应用案列
普通导入
-
1,创建 HBase 表
hbase(main):002:0> create 'help_keyword','person' -
2,命令
sqoop import \ --connect jdbc:mysql://hadoop01:3306/mysql \ --username root \ --password shiny \ --table help_keyword \ --hbase-table help_keyword \ --column-family person \ --hbase-row-key help_keyword_id \ -m 1 -
3,验证结果
将数据导入HBase表help_keyword’,行键为help_keyword_id,列簇为person,列为name,value为help_keyword_id和name对应的值
Sqoop 数据导出
1,HDFS 导出数据到 MySQL
语法
-
sqoop export (generic-args) (export-args)
“export工具”:是将 HDFS 平台的数据,导出到外部的结构化存储系统中。 -
常用参数
--direct ## 使用直接导出模式(优化速度) --export-dir <dir> ## HDFS 导出数据的目录 -m,--num-mappers <n> ## 使用n个 map 任务并行导出 --table <table-name> ## 导出的目的表名称 --update-key <col-name> ## 更新参考的列名称,多个列名使用逗号分隔 --update-mode <mode> ## 插入模式,默认是只更新(updateonly),可以设置为 allowinsert --input-null-string <null-string> ## 使用指定字符串,替换字符串类型值为 null 的列 --input-null-non-string <null-string> ## 使用指定字符串,替换非字符串类型值为 null 的列 --staging-table <staging-table-name> ## 临时表,在数据导出到数据库之前,数据临时存放的表名称 --clear-staging-table ## 清空临时表 --batch ## 使用批量模式导出
默认操作是从将文件中的数据使用 INSERT 语句插入到 MySQL 表中。
更新模式下,是生成 UPDATE 语句更新表数据。
数据导出详细步骤
-
1,HDFS 导出数据目录中的数据
-
2,在 MySQL 中创建目标表
mysql> create database sqoopdb default character set utf8 COLLATE utf8_general_ci; mysql> use sqoopdb; mysql> CREATE TABLE sqoopstudents ( -> name VARCHAR(20), -> age INT, -> address VARCHAR(20)); -
3,执行导出命令
sqoop export \ --connect jdbc:mysql://hadoop01:3306/sqoopdb \ --username root \ --password shiny \ --table sqoopstudents \ --export-dir /student/student.txt \ --fields-terminated-by '\t' -
4,MySQL 验证
命令:select * from sqoopstudents;
2,Hive 导出数据到 MySQL
1,语法
- 与将数据从 HDFS 导出到 MySQL的语法一样。
2,数据导出详细步骤
-
1,Hive 导出数据样式

-
2,在 MySQL 中创建目标表
mysql> use sqoopdb; mysql> CREATE TABLE sqoopstudent ( -> id INT NOT NULL PRIMARY KEY, -> name VARCHAR(20)); -
3,执行导出命令
sqoop export \ --connect jdbc:mysql://hadoop01:3306/sqoopdb \ --username root \ --password shiny \ --table sqoopstudent \ --export-dir /user/hive/warehouse/shiny.db/studenta/studenta.txt \ --fields-terminated-by '\t' --input-fields-terminated-by '\t' -
4,执行导出命令
命令:select * from sqoopdb.sqoopstudent;
3,HBase 导出数据到 MySQL
没有直接的命令将 HBase 的数据导出到 MySQL
- 实现过程
(1)先将 HBase 的数据导出到 HDFS;
(2)再将数据导出到 MySQL。