数据中心网络堆叠原理与部署
1.堆叠技术简介
定义:堆叠是将多台设备通过物理线缆连接,虚拟成一台逻辑上的交换机系统
特点:
-
交换机多虚一:将多台交换机虚拟成一台交换机,控制平面合一,统一管理
-
转发平面合一:堆叠内物理设备实时同步各种转发表项,对外展现出一台设备在转发数据
-
跨设备链路聚合:多台物理设备堆叠后可以认为是逻辑的一台设备,不同物理设备的链路可以聚合成一条链路

2.堆叠技术的作用
-
简化运维:整个堆叠系统控制平面合一,在管理时可以当作一台设备管理。
简化运维,降低Opex(运营成本)
-
可靠性高:堆叠内一台物理设备故障,可以由其他设备接管堆叠的控制以及数据转发,
避免单点故障
-
无环网络:多台设备虚拟成一台,加上跨设备的链路聚合,多根链路虚拟成一根。
可以构建天然的无环网络
-
链路均衡:通过设备间链路聚合的ECMP(等价多路径),可以实现
100%的链路和带宽利用率
3.堆叠技术的部署方式
-
物理设备之间组建堆叠需要通过线缆连接,根据堆叠口的不同,分为两种方式
-
堆叠卡堆叠:交换机之间使用专用的堆叠卡及专用的堆叠线缆连接
-
业务口堆叠:使用业务口和普通业务线缆连接(业务口需要绑定逻辑堆叠口)
-
-
堆叠系统的连接方式又分为两种
-
环形连接:堆叠系统内的设备互联形成一个环形
-
链形连接:设备两两相连,但头尾不连
区别:环形连接可靠性高,设备之间的堆叠链路故障后,可以通过另外一边线缆交互信息。链形连接可靠性低,一般用于头尾交换机距离较远,无法连接的场景
-
4.堆叠技术的种类
iStack:用于盒式交换机之间的堆叠技术
-
部署方式:交换机之间使用
业务口+高速铜缆/光纤
互联。可连成环形或链形(必须使用>=10GE接口) -
部署收益:无需使用专用堆叠卡,堆叠线,
提升带宽,避免环路
-
典型产品:CE5800、CE6800、CE7800,最多可以
堆叠16台交换机

CSS:用于框式交换机之间的堆叠技术
专用线卡式CSS
-
部署方式:CSS内各交换机在各自的主控板上通过
专用线卡+专用线缆
互联 -
部署收益:不占用业务卡槽,不影响系统性能。专业线卡速率高于业务线卡,提升了CSS互联线路的带宽
-
典型产品:S9300

业务线卡式CSS
-
部署方式:CSS内各交换机使用
业务线卡+业务线缆
互联 -
部署收益:无需采购额外部件,支持
长距离连接
(根据使用的线缆决定),互联链路使用Eth-Trunk可以
提升带宽
。虽然占用了部分业务口,但随着交换机转发性能的提升,对整个系统的转发性能没有太大影响 -
典型产品:CE12800
5.iStack堆叠
典型设备:CE5800,CD6800,CE7800
iStack基本概念

-
iStack:堆叠(Intelligent Stack),是指将多台交换机通过堆叠线缆连接在一起,从逻辑上变成一台交换设备,作为一个整体参与数据转发
-
堆叠域:交换机通过堆叠线缆组成一个堆叠系统,这个堆叠系统就是一个
堆叠域
。在网络中可能由多个堆叠域,堆叠域之间通过编号
(堆叠域ID)
来区分 -
角色:堆叠中的单台交换机称为成员交换机,按照功能不同可以分为以下角色:
-
主交换机:主交换机(Master)负责管理整个堆叠。堆叠中只有一台主交换机。
-
备交换机:备交换机(Standby)是主交换机的备份交换机。当主交换机故障时,备交换机会接替原主交换机的所有业务。堆叠中只有一台备交换机。
-
从交换机:从交换机(Slave)主要用于业务转发,从交换机数量越多,堆叠系统的转发能力越强。除主交换机和备交换机外,堆叠中其他所有的成员交换机都是从交换机。
-
-
堆叠优先级:堆叠优先级是成员交换机的一个属性。在堆叠建立时,会通过一系列参数竞选一个主交换机,堆叠优先级是其中一个参数(不是第一比较项,也不是唯一比较项,细节部分请看后续描述堆叠建立)
-
堆叠成员ID:在堆叠系统中,成员交换机之间通过
堆叠ID
标识,每个设备的堆叠ID必须唯一,
取值范围1-2
-
堆叠端口及堆叠成员端口:
堆叠端口
是一个
逻辑接口
,可以将多个做堆叠的物理接口放入到堆叠端口中,形成绑定关系。这些做堆叠的
物理接口
又叫做
堆叠成员端口
iStack堆叠建立

iStack堆叠建立分为四个阶段:(1)物理连接;(2)主交换机选举;(3)拓扑收集;(4)稳态运行
物理连接

连接方式有两种:
-
链形连接:设备两两相连,但头尾不连
-
优点:首尾不需要有物理连接,适合长距离堆叠。
-
缺点:整个堆叠系统只有一条路径,堆叠链路带宽利用率低。可靠性低,其中某条堆叠链路出现故障,就会造成堆叠分裂。
-
适用场景:堆叠成员交换机距离较远时,组建环形连接比较困难,可以使用链形连接。
-
-
环形连接:堆叠系统内的设备互联形成一个环形
-
优点: 可靠性高,当其中某条堆叠链路出现故障时,环形拓扑变成链形拓扑,不影响堆叠系统正常工作。 堆叠链路带宽利用率高,数据能够按照最短路径转发。
-
缺点:首尾需要有物理连接,不适合长距离堆叠。
-
适用场景:堆叠成员交换机距离较近时,从可靠性和堆叠链路利用率上考虑,建议使用环形连接。
-
主交换机选举

堆叠建立时,成员设备间相互发送堆叠竞争报文,选举出主交换机。主交换机选举规则如下:
-
运行状态比较,已经运行的交换机比处于启动状态的交换机优先竞争为主交换机。
-
堆叠优先级比较,堆叠优先级高的交换机优先竞争为主交换机。
-
软件版本比较,软件版本高的交换机优先竞争为主交换机。
-
桥MAC地址比较,桥MAC地址小的交换机优先竞争为主交换机。
说明:
设备在出厂时会被分配一段MAC地址(16个),其中最小的MAC地址即为桥MAC地址。
拓扑收集
主交换机选举完成后,主交换机会收集所有成员交换机的信息并计算拓扑。如果成员交换机的堆叠成员ID冲突,主交换机将为冲突的成员交换机重新分配堆叠成员ID。
稳态运行
主交换机计算出拓扑信息后,将整个堆叠系统的拓扑信息同步给所有成员交换机,并选举出一台备交换机。备交换机选举规则如下:(依次从第一条开始判断,直至找到最优的交换机才停止比较)
-
堆叠优先级比较,堆叠优先级高的交换机优先竞争为备交换机。
-
MAC地址比较,MAC地址小的交换机优先竞争为备交换机。
iStack堆叠同步机制
软件版本同步
(可选)
堆叠具有版本同步的功能,组成堆叠的成员交换机不需要具有相同的软件版本,只需要版本间兼容即可。主交换机选举结束后,如果其他交换机与主交换机的软件版本号或软件名称不一致,其他交换机会自动从主交换机下载系统软件,然后使用新的系统软件重启,并重新加入堆叠。
配置同步
堆叠具有严格的配置文件同步机制,用来保证堆叠中的多台交换机能够像一台设备一样在网络中工作。
-
堆叠建立时,成员交换机在启动开始阶段使用各自的配置文件启动。启动完成后,备、从交换机会将本设备的堆叠相关配置合并到主交换机的配置文件中,形成堆叠系统的配置文件。
-
堆叠正常运行后,主交换机作为堆叠系统的管理节点,负责将用户的配置同步给其他交换机,从而使堆叠内各成员交换机的配置随时保持一致。
通过即时同步,堆叠中的所有交换机均保存有相同的配置文件,即使主交换机出现故障,其他交换机仍能够按照相同的配置文件执行各项功能。
iStack堆叠成员加入

堆叠成员加入过程
-
新加入的交换机启动后,进行角色选举,新加入的交换机会选举为从交换机,原有主备从角色不变。
-
角色选举结束后,主交换机更新堆叠拓扑信息,同步到其他成员交换机上,并向新加入的交换机分配堆叠ID(新加入的交换机没有配置堆叠ID或配置的堆叠ID与原堆叠系统的冲突时)。
-
新加入的交换机更新堆叠ID,并同步主交换机的配置文件和系统软件,之后进入稳定运行状态
堆叠成员加入操作
-
分析当前堆叠的物理连接,选择加入点。
-
如果是链形连接,新加入的交换机建议添加到链形的两端,这样对现有的业务影响最小。
-
如果是环形连接,需要把当前环形拆成链形,然后在链形的两端添加设备,重新组成环形。
-
-
在堆叠及新加入的交换机上进行堆叠的相关配置并保存。
-
新加入的交换机下电后连接堆叠线缆,然后重新上电
iStack堆叠成员退出

堆叠成员退出是指成员交换机从堆叠系统中离开。根据退出成员角色的不同,对堆叠系统的影响也有所不同:
-
当主交换机退出,备交换机升级为主交换机,重新计算堆叠拓扑并同步到其他成员交换机,指定新的备交换机,之后进入稳定运行状态。
-
当备交换机退出,主交换机重新指定备交换机,重新计算堆叠拓扑并同步到其他成员交换机,之后进入稳定运行状态。
-
当从交换机退出,主交换机重新计算堆叠拓扑并同步到其他成员交换机,之后进入稳定运行状态。
堆叠成员交换机退出的过程,主要就是拆除堆叠线缆和移除交换机的过程:
-
对于环形堆叠:成员交换机退出后,为保证网络的可靠性还需要把退出交换机连接的两个端口通过堆叠线缆进行连接。
-
对于链形堆叠:拆除中间交换机会造成堆叠分裂。这时需要在拆除前进行业务分析,尽量减少对业务的影响。
iStack堆叠合并

堆叠合并是指稳定运行的两个堆叠系统合并成一个新的堆叠系统。
堆叠系统合并时,两个堆叠系统的主交换机进行竞争,选举出一个更优的作为新堆叠系统的主交换机。竞争规则如下:(依次从第一条开始判断,直至找到最优的主交换机才停止比较):
-
主交换机的堆叠优先级比较,堆叠优先级高的竞争胜出。
-
主交换机的软件版本比较,软件版本高的竞争胜出。
-
主交换机的桥MAC地址比较,桥MAC地址小的竞争胜出。
竞争胜出的主交换机所在的堆叠系统将保持原有主、备、从角色和配置不变,业务也不会受到影响;而另外一个堆叠系统的所有成员交换机将重新启动,以从交换机的角色加入到新堆叠系统,该堆叠系统的原有业务也将中断。
堆叠合并通常在以下两种情形下出现:
-
堆叠链路或设备故障导致堆叠分裂,链路或设备故障恢复后,分裂的堆叠系统重新合并。
-
待加入堆叠系统的交换机配置了堆叠功能,在不下电的情况下,使用堆叠线缆连接到正在运行的堆叠系统。通常情况下,不建议使用该方式,因为在合并过程中可能会导致正在运行的堆叠系统重启,影响业务运行。
iStack堆叠分裂

堆叠分裂是指稳定运行的堆叠系统中带电移出部分交换机,或者堆叠线缆故障导致一个堆叠系统变成多个堆叠系统
根据原堆叠系统主备交换机分裂后所处位置的不同,堆叠分裂可分为以下两类:
-
堆叠分裂后,原主、备交换机在同一个堆叠系统中。
原主交换机会重新计算堆叠拓扑,将移出的成员交换机的拓扑信息删除,并将新的拓扑信息同步给其他成员交换机;而移出的成员交换机将自动复位,重新进行选举,形成新的堆叠系统。
-
堆叠分裂后,原主、备交换机在不同的堆叠系统中。
原主交换机所在堆叠系统重新指定备交换机,重新计算拓扑信息并同步给其他成员交换机;原备交换机所在堆叠系统将发生备升主,原备交换机升级为主交换机,重新计算堆叠拓扑并同步到其他成员交换机,并指定新的备交换机。
双主检测
由于堆叠系统中所有成员交换机都使用同一个IP地址和MAC地址(堆叠系统MAC),一个堆叠分裂后,可能产生多个具有相同IP地址和MAC地址的堆叠系统。为防止堆叠分裂后,产生多个具有相同IP地址和MAC地址的堆叠系统,引起网络故障,必须进行IP地址和MAC地址的冲突检查——双主检测(原理部分请看CSS双主检测)
堆叠升级
|
升级方式 |
原理概述及适用场景 |
|---|---|
| 传统升级方式 | 传统的升级即通过指定启动文件后整机重启的方式进行升级。这种升级方式业务中断时间比较长,不适用于对业务中断影响要求较高的场景。 |
| 快速升级 | 堆叠快速升级提供了一种在堆叠系统的成员设备软件版本升级过程中尽量减少转发业务中断的机制,减少了升级设备对业务的影响。 |
| ISSU升级 | ISSU升级通过单板级倒换实现堆叠系统的升级,可靠性更高,且业务中断时间短。 |
6.CSS堆叠实现
典型设备:CE12800,CE12800S
CSS基本概念

-
CSS:集群交换系统(Cluster Switch System),用于
框式交换机
的堆叠技术,只能
两台设备
做堆叠 -
堆叠域:交换机通过堆叠线缆组成一个堆叠系统,这个堆叠系统就是一个
堆叠域
。在网络中可能由多个堆叠域,堆叠域之间通过编号
(堆叠域ID)
来区分 -
角色:在CSS的堆叠系统中,只有两台交换机,一台为
主
,负责管理和控制整个堆叠系统,另一台为
备
,作为主交换机的备份。 -
堆叠优先级:堆叠优先级是成员交换机的一个属性。在堆叠建立时,会通过一系列参数竞选一个主交换机,堆叠优先级是其中一个参数(不是第一比较项,也不是唯一比较项,细节部分请看后续描述堆叠建立)
-
堆叠成员ID:在堆叠系统中,成员交换机之间通过
堆叠ID
标识,每个设备的堆叠ID必须唯一,
取值范围1-2
-
堆叠端口及堆叠成员端口:
堆叠端口
是一个
逻辑接口
,可以将多个做堆叠的物理接口放入到堆叠端口中,形成绑定关系。这些做堆叠的
物理接口
又叫做
堆叠成员端口
CSS物理架构

CSS中有两个通道:
管理通道
和
转发通道
管理通道:CSS设备间管理平面和控制平面的报文交互通道。负责:备设备管理、路由同步、CSS状态同步等工作
转发通道:CSS设备间转发平面的报文交互通道。负责:报文转发、MAC表同步等工作
两种架构
-
带外管理型:独立的管理通道+独立的转发通道。主控板之间互联线缆,作为管理通道。业务板卡之间互联线缆,作为转发通道
-
带内管理型:转发通道中内置管理通道。在业务板卡之间互联线缆,既作为管理通道,又作为转发通道
优点:
-
带外管理型:主控板的GE端口互联,作为管理通道;带外管理,可靠性高,不占用业务资源
-
带内管理型:管理通道部署在CSS转发通道内;简化网络部署,节省布线,便于CSS拉远
CSS中的职责分工

管理平面
-
MPU:Main Processing Unit,主控处理单元。简称:主控板。每个框式交换机满配有两个MPU
-
两台设备组成堆叠系统后,会有一个主MPU,一个备MPU,两个从MPU。主备MPU必须分布在不同的设备中,主MPU的作用是管理整个堆叠系统,备MPU作为主MPU的备份。从MPU作为备MPU的备份,如果一个备MPU故障了或主MPU故障导致备MPU升级为主了,从MPU会升级为备MPU
-
在带外管理型CSS中,MPU之间通过线缆互联,可以形成独立的管理通道
转发平面
-
业务线卡:也叫做LPU,每个LPU中有若干个以太网口作为业务口,通过线缆互联,形成转发通道。负责转发平面的配置同步以及数据转发。
-
在带内管理型CSS中,管理通道是部署在转发通道中的
注意:
管理通道和管理堆叠系统是两码事
在带外管理型CSS中,堆叠管理由MPU完成,管理通道使用MPU互联形成
在带内管理型CSS中,虽然管理通道和转发通道都是使用LPU互联形成,但是管理堆叠系统的还是MPU
总结:在CSS中,MPU负责堆叠的管理平面,LPU负责数据平面。管理通道既可以由MPU互联形成,也可以由LPU互联形成
CSS管理接口

-
Combo口:每个MPU中有两个Combo口,每个Combo口由两个以太网接口组成,一个光口一个电口,内部只有一个转发接口。使用光口,电口不能用,使用电口,光口不能用,也叫做光电互斥口
-
SIP口:系统互联口(System Inter-Connect Port),该名称是管理意义,一个SIP口就是一块MPU上的两个Combo接口,不需要进行任何配置,可以即插即用。
-
MPU、Combo口、SIP口之间的关系:每个MPU(主控板)上面有一个SIP口,这个SIP口其实就是两个Combo口
-
堆叠管理接口:主控板上的Combo口(SIP口),就是堆叠管理接口
-
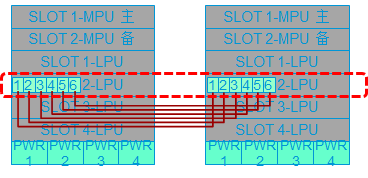
堆叠管理链路:框式交换机建立堆叠时,可以用主控板上的管理接口互联,形成独立的堆叠管理链路。每个设备有两个主控板,即2个SIP口或4个Combo口,这些接口一般交叉互联,提高可靠性,如图所示。
注意:每个设备有两块主控板,不管实际上作为主还是作为备,它们的名字都叫做主控板
CSS业务接口

-
LPU:Line Processing Unit,业务处理单元。简称:业务板
-
每个LPU中有若干个以太网接口,作为业务口,业务口通过线缆互相可以形成转发通道
转发通道连接方式有两种:
-
1+1组网:两台设备各自使用一个LPU的若干个接口互联,依靠一块单板上的堆叠链路实现堆叠连接
-
N+M组网:N>=1, M>=2,N个LPU的端口可以连接到M个LPU上,例如1个LPU的4个接口,可以连接到对端2个LPU的4个接口上
无论是1+1模式,还是N+M模式,都可以交叉互联来提高可靠性
注意:
本端的堆叠成员端口不能与对端的普通业务口相连,否则有可能会产生流量不通或设备异常重启等问题。
CE12800支持不同型号组建CSS

硬软件要求
|
项目 |
描述 |
备注 |
|---|---|---|
| 交换机型号 | CE12804、CE12808、CE12812、CE12816 CE12804S、CE12808S | CE12800不同型号间的设备也可以组建堆叠,如CE12804和CE12808之间可以组建堆叠。 CE12800S不同型号间的设备也可以组建堆叠,如CE12804S和CE12808S之间可以组建堆叠。 CE12800和CE12800S之间不可以组建堆叠。 |
| 成员交换机数量 | 2 | – |
| 每台成员交换机的主控板数量 | 每台成员交换机上至少配备一块主控板。 | 为了保证高可靠性,建议用户每台交换机都配备两块主控板。 |
| 用于堆叠连接的端口类型 | 10GE光口 10GE电口 40GE光口 100GE光口 | 10GE光口只能插入10GE光模块,不能插入GE光模块或GE光电转换模块,否则不能组建堆叠。 40GE光口拆分出的10GE光口可以用于堆叠连接。如果40GE光口已经被配置为堆叠物理成员端口,则不能进行拆分配置。 100GE光口拆分出的10GE或40GE光口可以用于堆叠连接。 |
| 堆叠端口中成员端口的数量 | 1~32 | 一个堆叠端口中不支持同时加入10GE、40GE和100GE的光口。 一个堆叠端口中可以同时加入10GE光口和10GE电口。 建议每个堆叠端口至少加入2个成员端口,以提高链路的带宽和可靠性。 |
单板的100GE接口可以作为40GE接口使用,或者拆分为4个25GE接口使用,或者拆分为4个10GE接口使用,支持最高16×40GE、64×25GE或者64×10GE的接口容量。
7.CSS工作过程
CSS的一生

CSS诞生:建立CSS,自己协商CSS主备,同步配置和数据信息
CSS日常生活:CSS正常运行,处理业务转发流量,实时同步配置信息和数据信息
CSS定期体检:在CSS正常运行时,执行双主检测,避免CSS因为出现故障,导致双主
CSS就医诊治:如果双主检测发现了故障,则执行CSS分裂处理
CSS寿终正寝:不需要运行CSS时,可以解除掉CSS功能
CSS建立

-
竞选主设备:
两台设备组成CSS后根据规则竞选主设备:-
运行状态:最先完成启动的优先成为主交换机
-
CSS优先级:优先级数值高的优先成为主交换机,优先级默认为100,取值范围 1-255
-
软件版本号:软件版本高的优先成为主交换机
-
主控板数量:主控板数量多的优先成为主交换机,例如2块主控板的比只有1块主控板的交换机优先
-
桥MAC地址:桥MAC地址小的优先成为主交换机
说明:
设备在出厂时会被分配一段MAC地址(16个),其中最小的MAC地址即为桥MAC地址。如果主和备的堆叠ID相同,则主交换机将为备交换机重新分配堆叠ID,备交换机重新启动后再加入堆叠。
堆叠系统建立后,主交换机的主用主控板成为堆叠系统主用主控板,作为整个系统的管理主角色。备交换机的主用主控板成为堆叠系统备用主控板,作为系统的管理备角色。主交换机和备交换机的备用主控板作为堆叠系统候选备用主控板
-
-
版本同步:
堆叠具有版本同步的功能,组成堆叠的成员交换机只需要版本间兼容即可。 当主交换机选举结束后,如果备交换机与主交换机的软件版本号不一致,备交换机会自动从主交换机下载系统软件,使用新的系统软件重新启动后再加入堆叠。 -
配置同步:
堆叠具有严格的配置文件同步机制,用来保证堆叠中的多台交换机能像一台设备一样在网络中工作-
堆叠建立时,成员交换机使用各自的配置文件启动。启动完成后,成员交换机会将原有配置文件备份到Flash中。然后主备交换机会将本设备的堆叠相关配置合并到主交换机的配置文件中,形成堆叠系统的配置文件,主备设备运行新的配置文件
-
堆叠正常运行后,主交换机作为堆叠系统的管理节点,负责将用户的配置同步给备交换机,从而使堆叠内各成员交换机的配置随时保持一致。
通过即时同步,堆叠中的所有成员交换机均保持相同的配置。即使主交换机出现故障,备交换机仍能够按照相同的配置执行各项功能。
-
CSS稳态运行
实时同步配置和数据

CSS逻辑上是一台设备,成员交换机之间会实时同步配置和转发数据,其中同步分为两种
-
转发平面的数据同步:业务线卡之间直接完成同步,通过CSS转发通道完成。主设备和备设备都可发起同步 典型业务:MAC地址表同步,普通数据转发
-
控制平面的数据同步:所有控制平台信息上送主设备,主MPU执行计算和处理,然后向给所有的业务线卡,备MPU发送数据,完成同步。通过CSS管理通道完成。 典型业务:路由表,ARP表同步
CSS堆叠成员加入与堆叠合并
堆叠成员加入
堆叠成员加入是指向稳定运行的单框堆叠系统(一台独立运行堆叠功能的交换机)中添加一台新的交换机。如 图所示,新交换机SwitchB将加入单框堆叠系统从而形成新的堆叠系统。原单框堆叠的交换机成为主交换机,新 加入的交换机成为备交换机。

堆叠加入通常在以下两种情形下出现:
-
在建立堆叠时,先将一台交换机使能堆叠功能后重启,重启后这台交换机将进入单框堆叠状态。然后再使能另外一台交换机的堆叠功能后重启,则后启动的交换机按照堆叠成员加入的流程加入堆叠系统,成为备交换机。
-
在稳定运行的两框堆叠场景中,将其中一台交换机重启,则这台交换机将以堆叠成员加入的流程重新加入堆叠系统,并成为备交换机。
堆叠合并
堆叠合并是指稳定运行的两个单框堆叠系统合并成一个新的堆叠系统。如图所示,两个单框堆叠系统将自动选出一个更优的作为合并后堆叠系统的主交换机(选举规则与选举主交换机的规则一致)。被选为主交换机的配置不变,业务也不会受到影响。而备交换机将整框重启,以堆叠备的角色加入新的堆叠系统,并将同步主交换机的配置,该交换机原有的业务也将中断。

堆叠合并通常在以下两种情形下出现:
-
将两台交换机分别使能堆叠功能后重启(重启后的两台交换机都属于单框堆叠),再使用堆叠线缆将两台交换机连接,之后会进入堆叠合并流程。
-
堆叠链路或设备故障导致堆叠分裂。故障恢复后,分裂后的两个单框堆叠系统重新合并。
CSS堆叠分裂
堆叠建立后,主和备交换机之间会定时发送心跳报文来维护堆叠系统的状态。堆叠线缆、主控板发生故障时或者其中一台交换机下电、重启都将导致两台交换机之间失去通信,导致堆叠系统分裂为两台独立的交换机,如图所示。

堆叠分裂后,若两台交换机都在正常运行,则其全局配置完全相同,会以相同的IP地址和MAC地址(堆叠系统MAC)与网络中的其他设备交互,这样就导致IP地址和MAC地址冲突,引起整个网络故障,此时可以依靠堆叠的双主检测来避免堆叠分裂后出现双主。
CSS双主检测
双主检测DAD:
Dual-Active Detect,是一种检测和处理堆叠分裂的协议,可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。
工作原理
堆叠成员之间建立一个用于双主检测的链路(可以有很多种形式),
主交换机
在检测链路上发送DAD竞争报 文。堆叠分裂后,多个堆叠系统
互发竞争报文
,并将接收到的竞争报文信息与本部分竞争信息做比较,如果本 部分 竞争胜出,则不做处理,保持Active状态(正常工作状态),正常转发业务报文;如果本部分竞争失败, 则除保 留端口外的所有业务端口Error-Down,转入Recovery状态(业务禁用状态),停止转发业务报文。
DAD竞争规则
-
堆叠优先级比较,堆叠优先级高的交换机优先竞争胜出。
-
设备MAC地址比较,MAC地址小的交换机优先竞争胜出。
检测方式

1. 直连检测:堆叠成员交换机间通过业务口连接的专用链路发生DAD报文进行双主检测

2. 通过中间设备的直连检测:使用中间设备透传BPDU(DAD报文),进行双主检测。中间设备要配透传BPDU

3. 代理方式检测:让网络中现有的业务交换机作为代理,通过Eth-Trunk接口代理转发DAD报文,进行双主检测。但代理设备需要启动DAD代理功能。与业务口直连检测方式相比,代理检测方式无需占用额外的接口,业务接口可以同时运行DAD代理检测和其它业务。

4. 堆叠间互为代理检测:即两个堆叠系统之间互相作为对方的代理
说明:为防止检测干扰,两个堆叠系统必须配置不同的Domain ID。用于检测的端口和用于代理的端口不能使用同一个Eth-Trunk口

5. 管理网口检测:使用堆叠成员交换机的管理网口链路进行双主检测
说明:在管理网口检测方式中,要求堆叠系统的管理网口必须配置IP地址。堆叠后,整个系统只显示一个管理网口MEth0/0/0/0,只需要在这一个管理网口下配置IP地址。

6. 堆叠端口检测:使用堆叠物理成员端口之间的链路进行双主检测
说明:只有当堆叠连接方式为主控板直连时,才可以使用堆叠端口检测方式。
故障恢复
堆叠链路故障修复后,分裂成多部分的堆叠系统进行合并。处于Recovery状态的交换机将重新启动,同时将 Error-Down的业务端口恢复正常,整个堆叠系统恢复。
如果在链路故障修复前,承载业务的Active状态的交换机系统也出现了故障。此时,可以先将Active状态的交换 机从网络中移除,再通过命令行启用Recovery状态的交换机,接替原来的业务,然后再修复原Active状态交换 机的故障及链路故障。故障修复后,重新合并堆叠系统。
CSS堆叠主备倒换
定义:主备倒换指堆叠系统中,主MPU复位或故障,备MPU升级为主的行为。
主备倒换常见于两种情况
1.系统MPU故障导致主备倒换

系统主MPU故障:
-
原备交换机升为主交换机,原系统备MPU升为系统主MPU。
-
原主交换机降为备交换机。
-
原主交换机内的候选备用MPU升为系统备用MPU,从系统主用MPU进行数据同步。
说明:候选备用MPU是系统备用MPU的备份,有时也叫做从MPU

系统备MPU故障后:
-
主交换机和备交换机的角色不会发生变化。
-
备交换机的后续备MPU升为系统备MPU,从系统主用主控板进行数据同步。
2.通过命令执行主备倒换

执行主备倒换后:
-
原备交换机升为主交换机,原系统备MPU升为系统主MPU。
-
原系统主MPU重启降为候选备MPU,主交换机降为备交换机。
-
原主交换机内的备用主控板升为系统备MPU,从系统主MPU进行数据同步。
CSS快速升级

-
管理员给堆叠系统设备快速升级,主设备将快速升级的配置同步给备设备
-
开始快速升级,备设备关机,以新版本启动,所有业务由主设备接管
-
备设备启动后恢复重启前配置,然后提升主设备开启主备倒换
-
主设备开始主备倒换,原主设备变为备设备,原备设备变为主设备
-
原主设备变为备设备后,关机,以新版本启动,所有设备由原备设备(现主设备)接管
-
原主设备重启后,执行堆叠加入动作,变为备设备稳定运行
跨设备链路聚合

交换机配置完堆叠后,逻辑上认为是一个设备,可以直接将不同设备的物理接口捆绑在一起,做跨设备的链路聚合
跨设备的链路聚合转发流量分为三种情况
-
设备正常时:根据Eth-Trunk的Hash计算,流量均匀分布在聚合链路上。开启本地优先转发后,从本设备进入的流量,优先从本设备转发出去
-
链路故障时:当其中一条链路失效时,跨设备链路聚合技术能够通过堆叠链路将流量自动重新分布到其余聚合链路以实现链路备份,从而提高网络可靠性
-
设备故障时:当堆叠系统中一台成员交换机故障时,跨设备链路聚合技术能够将流量重新分布到与另一台成员交换机相连的聚合链路上以实现设备间的备份,从而提高网络可靠性。
CSS本地优先转发

背景
堆叠系统配置Eth-Trunk后,Eth-Trunk接口会通过Hash算法选择转发出接口,如果从成员设备A收到的流量经过Hash计算后选择的出接口在成员设备B上,就会导致跨设备转发流量的情况。
由于堆叠设备间堆叠线缆的带宽有限,跨设备转发流量增加了堆叠设备之间的带宽承载压力,同时也降低了流量转发效率。此时可以通过
本地优先转发
功能解决此问题
作用
配置了本地优先转发后,从本设备进入的流量,优先从本设备的出接口转发出去;如果本设备的出接口故障,则流量从其它成员交换机的接口转发出去。
说明:只对已知单播有效,对广播、组播和未知单播均不生效
工作原理
设备执行Hash计算时,会在本设备中计算出一条优选Hash链路,在另一个成员设备中计算出一条次优Hash链路,正常工作时流量优先走优选Hash链路,优选Hash链路故障时,走次优Hash链路
CSS解除

当管理员需要解除CSS时,可以执行以上操作
8.堆叠技术常见应用
堆叠典型应用

-
一个区域内,使用堆叠技术,增加网络可靠性,简化网络结构
-
多个区域间,使用大二层技术,打通区域间的二层通道
Core交换机背靠背堆叠(CSS)

-
通过堆叠技术把核心交换机虚拟化成一台交换机,控制平面合一,易管理,数据平面合一,上下行接口使用Eth-Trunk实现跨设备的链路聚合,分担流量转发
TOR交换机环形堆叠

-
Tor交换机环形连接,形成一个堆叠系统,提高网络可靠性,简化网络拓扑,连接到做了堆叠的核心设备。上下行接口也可做跨设备的链路聚合,分担流量转发
TOR交换机链形堆叠

-
链形和环形连接差不多,区别是链接连接没有环形连接可靠性高。一般用于距离较远,无法连成环形的场景
堆叠实际部署举例

使用2台CE12812构成CSS,下行通过40GE端口接入由CE6800组成的堆叠组;CE12800和CE6800之间Mesh互联,并通过跨设备链路聚合把互联链路组成一个Trunk端口;整网可向下提供高达5808个10GE端口。
特点:
-
高可靠的网络:Mesh组网
-
高性能的网络:41T的双向转发能力
-
高接入的网络:5808个10GE端口
接口计算方法:每个CE12812可拿出11个卡槽下联TOR,每个卡槽有24个40GE端口,连接每个TOR需要4个接口
所以两台CE12812可以连接 2 * 11 * 24 / 4 = 132台TOR
每个TOR(CE6800)有44个10GE接口(有4个接口拿去连接Core设备了)
所以132台TOR可以提供 44 * 132 = 5808个接口
堆叠其他部署实例

9.堆叠系统的数据转发
单播转发路径

-
A到E的下行流量路径:
-
A将流量通过TRUNK接口HASH算法分流到成员设备C和D;
-
C本地优先转发,直接将流量转发至E,不经过成员设备之间的堆叠链路;
-
D的处理过程与C相同。
-
-
E到A的上行流量路径:
-
E将流量通过TRUNK接口HASH到成员设备C和D;
-
C本地优先转发,直接将流量转发至A,不经过成员设备之间的堆叠链路;
-
D的处理过程与C相同。
-
组播转发路径

-
A到E的组播流量路径:
-
A将2个组播流1和2 HASH到成员设备C和D;
-
C将组播流1复制到E以及通过成员设备之间的堆叠链路复制到D,但D到E和C到E的组播流在TRUNK出端口处由组播剪枝表剪枝,只会有一路组播流到达设备E;
-
D上的组播流2的处理流程相同。
-
堆叠组网数据转发路径

如图所示,核心设备配置了堆叠,接入设备有VLAN10和VLAN20两种流量,转发路径如下:
-
TOR设备VLAN10或VLAN20的南北向流量根据Eth-Trunk的Hash算法分摊发送到核心A和核心B,接收到流量的核心设备按照本地优先转发原则转发
-
TOR设备之间VLAN10或VLAN20的东西向流量根据Eth-Trunk的Hash算法分摊发送到核心A和核心B,如果TOR A设备将流量发给了Core A,则需要穿过堆叠链路,发给Core B ,Core B再发给TOR B。如果TOR A设备将流量发给了Core B,那么Core B直接把流量发给TOR B,无需穿过堆叠链路。
10.堆叠故障切换
堆叠主整机故障

-
堆叠备D感知到堆叠主C故障,升级为堆叠主;
-
与堆叠系统连接的Trunk接口感知到堆叠主的链路故障,Trunk表删除掉与故障设备连接的成员接口,流量不再经过与故障主相连的Trunk链路;
-
经过D的流量不受影响;
堆叠备整机故障

-
与堆叠系统连接的Trunk接口感知到堆叠主的链路故障,Trunk表删除掉与故障设备连接的成员接口,流量不再经过与备设备相连的Trunk链路;
-
经过堆叠主C的流量不受影响;
-
堆叠角色无需切换。
Trunk链路部分成员链路故障

-
端口down或者堆叠链路探测报文会检测到堆叠链路down故障,堆叠和Trunk将故障链路从堆叠成员设备之间的Trunk中删除;
-
经过故障堆叠链路的报文会被丢弃,不经过故障堆叠链路的流量不受影响。
下行Trunk链路全部成员链路故障

-
端口down或者堆叠链路探测报文会检测到Trunk链路down故障,不再向该链路转发上下行流量;
-
堆叠主C从上行链路接收到的下行流量会通过堆叠链路转发到堆叠备D,D再转发到E;
-
E检测到Trunk成员链路故障,刷新Trunk成员端口,上行流量不再选择去往C的链路。
堆叠成员间链路全部故障

-
堆叠备会升主,导致双主故障出现,需要进行双主故障处理,堆叠主的所有业务端口全部关闭;
-
故障处理完成后,接入设备的流量全部由新堆叠主转发;
-
新的堆叠备关闭除保留端口和双主检测端口外的所有业务端口,处于Recovery状态,停止转发业务报文;
-
堆叠链路修复后,处于Recovery状态的堆叠将重新启动,同时将被关闭的业务端口恢复Up,堆叠系统恢复。