1. ASCII编码
百度百科 – “ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于
拉丁字母
的一套电脑
编码
系统,主要用于显示现代
英语
和其他
西欧
语言。它是最通用的
信息交换
标准,并等同于
国际
标准ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符”
ASCII码使用一个字节表示128种字符,其中0x00 ~ 0x1F是不可打印(显示)字符,或者说是控制字符,例如:0x08为‘\b’,表示退格的意思(Backspace),0x0A为‘\n’,表示换行的意思。0x20 ~ 0x7F为可打印字符,全部可打印字符有:
!”#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
使用ASCII码可以用一个字节表示一个英文字母、数字或常用符号,但是无法表示中文、日文等字符。
可以看出来,所有ASCII字符的范围为0x00 ~ 0x7F,二进制表示为B0000 0000 ~ B0111 1111,最高位永远是0,如果某个字符的MSB是1的话,那么这个字符就不在ASCII编码规则之内,也就是说它不是一个ASCII字符。
2. GB2312编码
GB2312编码是第一个汉字编码国家标准,由中国国家标准总局1980年发布,1981年5月1日开始使用。GB2312编码共收录汉字6763个,其中一级汉字3755个,二级汉字3008个。同时,GB2312编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
上面说了,如果某个字符的MSB是1的话,那么这个字符就不是一个ASCII字符,利用这个特性就可以设计一套编码方式,使得其可以扩展更多的字符同时兼容ASCII编码格式。
GB2312就是这么设计的。如果MSB为1的话,则表示其为GB2312编码格式(也可能是其它编码格式)。GB2312编码格式规定一个GB2312字符占用两个字节(大端模式),第一个字节(高字节)的取值范围为0xA1 ~ 0xFE,一共94个取值,第二个字节(低字节)的取值范围也是0xA1 ~ 0xFE,一共94个取值。所以两个字节的组合一共有 94 * 94 = 8836个组合,也就是说一共可以表示8836个字符。
GB2312编码对所收录字符进行了“分区”处理,使用上述的两个字节分别表示94个区和94个位,确定了区码和位码就能定位到具体的汉字,这种表示方式也称为区位码:
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
举例来说,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601。
具体的汉字分区参考文章:
GB2312 编码范围, GB2312 编码表
。计算机在处理以GB2312格式编码的字符串的时候会先判断当前字符属于ASCII字符还是属于GB2312字符,如果是GB2312字符的话,会一次性处理两个字节作为一个字符。

3. UTF8编码(Unicode transform format)
仿佛GB2312编码规范还是不够用,虽然它可以兼容ASCII码,但是无法兼容其它国家的字符。所以UTF8编码格式显得更加先进。
UTF8编码参考文章:
计算中心
。
要了解UTF8编码就必须了解Unicode编码,百度百科 – “统一码,也叫万国码、单一码(Unicode)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的
二进制编码
,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式发布1.0版本,2020年发布13.0版本。”。现在用的是UCS-2,即2个字节编码,而UCS-4是为了防止将来2个字节不够用才开发的。
说白了,Unicode编码就是把地球上的所有字符都统一编码到两个字节的空间里面去,所以UCS-2标准的Unicode最多可以容纳65536个字符。那么我们用Unicode编码直接表示字符串的话,由于Unicode编码不兼容ASCII码,比如“我”子的Unicode编码为0x6211,其两个字节单独拿出来都能对应一个ASCII码,所以在进行文本处理的时候,如果Unicode编码和ASCII编码格式混合存在,那么遇到0x6211的时候,不知道这是两个ASCII码还是一个Unicode码,因此使用Unicode编码不兼容ASCII编码。所以每个字符不管是英文字母还是汉字,都占用两个字节的空间。这时候存在空间浪费,因为很多时候纯英文文章,如果使用Unicode编码的话占用的空间是使用ASCII编码的两倍,如果使用UCS-4标准,一个Unicode字符需要4个字节,空间浪费更过分。所以出现了基于Unicode编码的的编码格式UTF8。
简单来说,UTF-8是Unicode的一种实现方式,其兼容ASCII编码。具体的编码格式如下图,图片第一列为Unicode编码的地址空间(0x0000 ~ 7FFF),第三列为对应的UTF8编码格式。
1、其中Unicode(0x0000 ~ 0x007F)的地址空间转换成UTF8编码空间只需要1个字节,也就是ASCII码的空间。
2、Unicode(0x0080 ~ 0x07FF)的地址空间转换成UTF8编码空间需要2个字节,第一个字节的最高三位为“前导码”为 “110”,这高三位中有两个bit ‘1’,表示该字符占用两个字节,也就是除了当前字节外,后面还剩一个字节(同样的,如果第一个字节的最高位为 “1110” 的话,表示该字符占用3个字节,后面还剩两个字节),该字符剩下的字节的前导码固定为 “10”。那么,第一个字节剩下的5位加上第二个字节剩下的6位一共11个位可以表示 2^11 = 2048 个字符。
3、Unicode(0x0800 ~ 0xFFFF)的地址空间转换成UTF8编码空间需要3个字节,第一个字节的最高三位为“前导码”为 “1110”,表示该字符占用3个字节,后面还剩两个字节。那么,第一个字节剩下的5位,第二、第三个字节个剩下的6位一共 5 + 6 + 6 = 17 个位,足够表示Unicode(0x0800 ~ 0xFFFF)16位的地址空间。这个地址空间包含了绝大部分的字符,包括汉字。所以使用UTF8编码汉字,一个汉字占用3个字节,一个ASCII码占用一个字节。
4、剩下的Unicode地址空间原理上和上面的一样,只是前导码不一样而已。这个地址空间很少用到。

另外,UTF-8编码中还有带BOM和不带BOM的区别,做个测试,两个内容相同的文件,一个以UTF-8带BOM编码,另一个以UTF-8不带BOM编码:

前者占用6字节的存储空间,后者占用3字节的存储空间。使用HEX编辑模式打开看看(Notpad++插件):
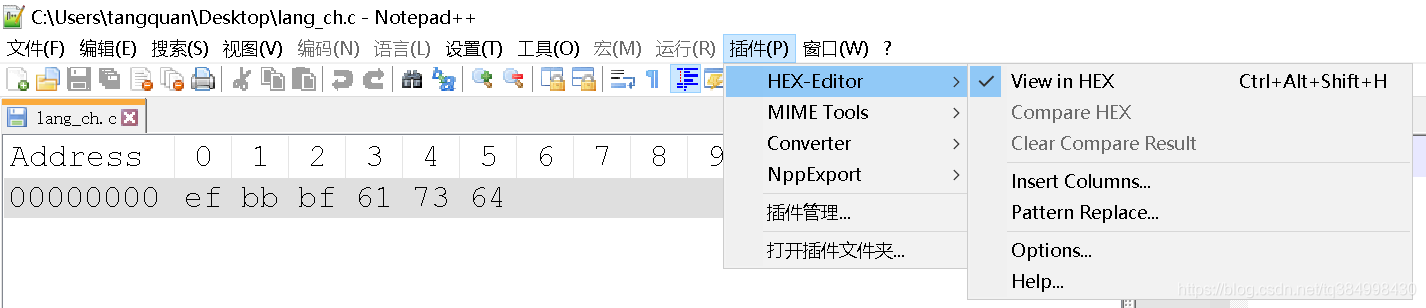

可以看到,UTF-8带BOM编码的文件前面多了0xEF 0xBB 0xBF这三个字节。
“UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE“的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。”
传输过程中,若收到 “EF BB BF”,则表示后面传输的是UTF-8文本。BOM不是必须的,一般都是采用UTF-8无BOM编码方式。
另外,关于UTF8、UTF16、UTF32区别,参考文章:
字符编码的概念(UTF-8、UTF-16、UTF-32都是什么鬼)_顾小暖的博客-CSDN博客
。
1、UTF8编码允许一个字符的最小可以使用一个字节编码,例如ASCII字符。处理速度最慢,存储空间最小。
2、UTF16需要2个或者4个字节表示一个字符,不兼容ASCII编码。对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。处理速度中等,存储空间中等。
3、UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以
直接存储 Unicode 编号
即可,不需要任何编码转换。浪费了空间,提高了效率,处理速度最快,存储空间最大。