首先导入需要的pandas
接着生成一个对象,简单的表格dataframe 这里用的是字典,columns是表头的意思。
df = pd.DataFrame({
'name':['a','b','c'],
'age':[20,12,41],
'sex':[0,1,1],
'birthday': pd.date_range('20111111',periods=3)
}, columns=['name','age','sex','birthday'])
输出如下图所示,第一列的-0、1、2是自动生成的

df.set_index(pandas.Series(['aa','aa','aa']),inplace=True )
修改index序列
如果想还原用
df.reset_index(drop=True,inplace=True) 即可

df.append({'name':'add','age':15,'sex':1,'birthday':'2011-11-23'},ignore_index=True)
再原有基础上追加一行,必须设置ignore_index 就是忽略index
df.insert(3,value=['w','w','w'],column='新添加一列') value参数加字典 或者是一个整数,column是表头

df.insert(3,value=['x','x','x'],column='新添加一列',allow_duplicates=True) 继续新加一列,表头一模一样的一列,需要加参数 allow_duplicates = True
dr.drop([1])
成功删除元数据第二行

df.drop(['新添加一列'],axis=1 ,inplace=True)
就将一列删除成功

df.iloc[0][3]行列定位 跟二位数组使用方法类似。

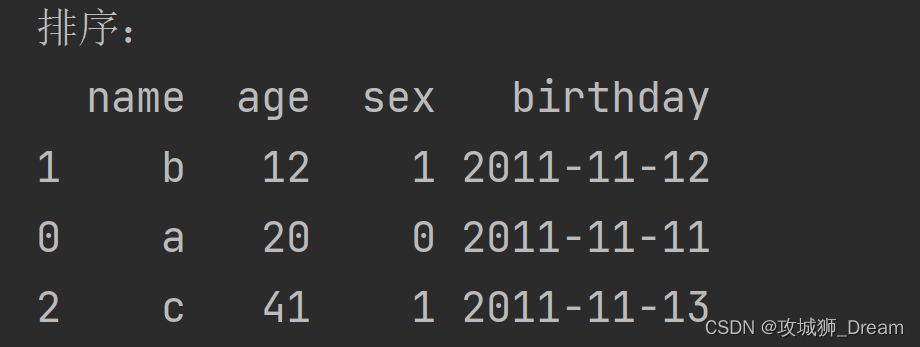
df.sort_values(by=[‘age’],ascending=True,inplace=True) 根据age一列排序 升序
版权声明:本文为qq_33877849原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。