多线程爬虫与单线程爬虫的效率对比
1.什么是进程?
当一个程序正在运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源,而一个进程又包含多个线程。
2.线程是什么?
线程是程序中的一个执行流,每个线程都有自己专有的寄存器(栈指针、程序计数器等),但一个进程内的多个线程是共享代码区的,也就是同一个函数可以被多个线程所执行。
3.多线程是什么?
多线程一般指的是同一个程序的多个执行流,即在一个程序中可以同时运行多个不同的线程来执行不同的任务,也就是允许端个程序创建多个并行执行的线程来完成各自的任务。
4.多线程的优点?
可以提高CPU的利用率。在多线程程序中,一个线程必须等待的时候,CPU可以运行其它的线程而不是等待,这样就大大提高了程序的效率。
5.多线程的缺点?
线程也是程序,所以线程需要占用内存,线程越多占用内存也越多;
多线程需要协调和管理,所以需要CPU时间跟踪线程;
线程之间对共享资源的访问会相互影响,必须解决竞用共享资源的问题;
线程太多会导致控制太复杂,最终可能造成很多Bug;
转载:
https://blog.csdn.net/function__/article/details/80883084
—————————–以上内容属转载———————————-
6.我们为什么要使用多线程?
举个栗子:比如我们要运输一趟货物,以进程代表火车,线程代表火车的车厢,理论上如果我们使用车厢数更多的火车去运输这趟货物,单位时间内就能运输更多地货物,效率也就更高。所以这就是为什么我们要使用多线程的缘故,就是能够去提高程序的效率。
7.对比单线程和多线程爬虫 ——-以爬取斗图网(
http://www.bbsnet.com/)的表情为例
(1).实现的思路
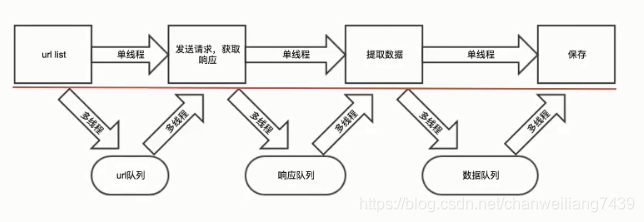
(2).单线程爬虫
代码如下:
# coding="utf-8"
import requests
from urllib.request import urlretrieve
from lxml import html
import json
import os
import datetime
class Doutu_Spider:
def __init__(self): # 类初始参数
self.url_temp = "http://www.bbsnet.com/author/panxingquan/page/{}" #设置一个临时url,之后可以更改{}的内容而快速拿到其他页面的链接
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"} # 拿到头信息,可以让对方服务器更加信任你是一个正常的浏览者而非一个爬虫程序
def start_url(self): #拿到所要爬取的网页的链接
return [self.url_temp.format(i) for i in range(1, 11)] # fomat函数可以用字符去代替{},测试爬取十页的数据,返回所有的链接列表
def parse_url(self,url): # 3. 提交请求,获取响应
response = requests.get(url, headers=self.headers) # 向服务器发送一个get请求,和接受服务器所返回的内容
return response.content.decode() # 拿到服务器返回的内容的编码格式为utf-8的byte型的二进制数据
def get_content_list(self,html_str): # 4. 提取数据
os.makedirs('./images/',exist_ok=True) # 打开当前目录的images文件夹
htmlDiv = html.etree.HTML(html_str) #解析html文件
content_list = htmlDiv.xpath("//ul[@id='post_container']/li/div[@class='thumbnail']") # xpath直接定位到包含有图像资源的所有div中
div_list =[]
for content in content_list:
item={} # 初始化一个字典
item["title"] = content.xpath("./a/img/@alt")[0] if len(content.xpath("./a/img/@alt"))>0 else None # 拿到图片的标题
item["url"] = content.xpath("./a/img/@src")[0] if len(content.xpath("./a/img/@src"))>0 else None # 拿到图片的Url地址
urlretrieve(item["url"], 'images/' + item['title']+'.gif') # 下载图片,保存在imgaes下,格式为:标题.gif
div_list.append(item) #将字典保存列表中
return div_list # 返回这一页的数据列表
def save_data(self,content_list): # 保存数据
with open("doutu.json","a",encoding="utf-8") as f:# 打开doutu,json文件,没有就创建一个;"a",追加的形式打开,这样新生成的数据才不会覆盖原有的数据,编码格式为"utf-8"
for content in content_list: # 遍历这个数据列表
f.write(json.dumps(content,ensure_ascii=False)) # 将每一个字典都写入到json文件中
f.write("\n")
print("保存成功")
def run(self):
# 测试时间,开端
starttime = datetime.datetime.now()
# 1. start_url
# 2. url_list # 链接列表
url_list = self.start_url()
# 3. 提交请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
# 4. 提取数据
content_list = self.get_content_list(html_str)
# 5. 保存数据
self.save_data(content_list)
# 打印时间
endtime = datetime.datetime.now()
print(endtime - starttime).seconds
if __name__ == '__main__':
DoutuSpider = Doutu_Spider() #实例化这个类
DoutuSpider.run() #程序执行
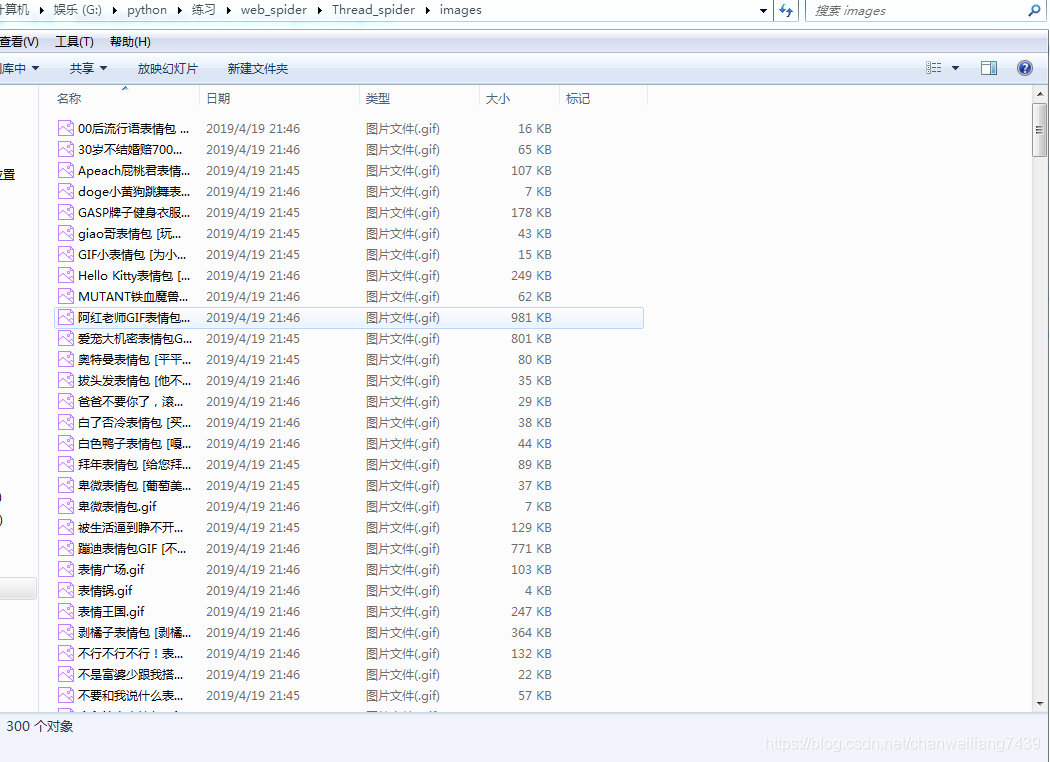
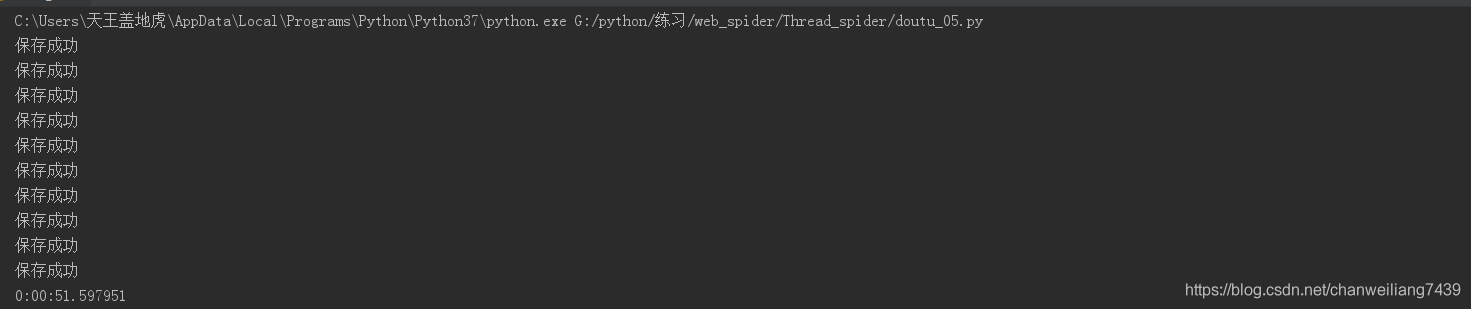
单线程程序运行结果
我们可以看到,在单线程的情况下,爬取和下载这十个链接共花费了51s左右的时间。共获取了300张图片。

(3).多线程爬虫
代码如下:
# 这份代码只注释解释多线程部分
# coding="utf-8"
import requests
from urllib.request import urlretrieve
from lxml import html
import json
import os
import datetime
# 导入多线程与队列模块
import threading
import queue
class Doutu_Spider:
def __init__(self):
self.url_temp = "http://www.bbsnet.com/author/panxingquan/page/{}"
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
self.url_queue = queue.Queue() # 定义一个url队列
self.html_queue = queue.Queue() # 定义一个htmld队列
self.content_queue = queue.Queue() # 定义一个content队列
def start_url(self):
for i in range(1, 11):
self.url_queue.put(self.url_temp.format(i)) # 将所有要爬的网页url都添加在url队列中
def parse_url(self):
while True:
url = self.url_queue.get() # 在url队列中取出一个url来
response = requests.get(url, headers=self.headers)
self.html_queue.put(response.content.decode()) # 将服务器反馈回来的信息进行编码后,放入到html队列里
self.url_queue.task_done() # url队列完成本次任务,从队列中删除该元素
def get_content_list(self):
global gNum
os.makedirs('./images/',exist_ok=True)
while True:
html_str = self.html_queue.get() # 在html队列中取出一个html信息
etree = html.etree
htmlDiv = etree.HTML(html_str)
content_list = htmlDiv.xpath("//ul[@id='post_container']/li/div[@class='thumbnail']")
div_list =[]
for content in content_list:
item={}
item["title"] = content.xpath("./a/img/@alt")[0] if len(content.xpath("./a/img/@alt"))>0 else None
item["url"] = content.xpath("./a/img/@src")[0] if len(content.xpath("./a/img/@src"))>0 else None
urlretrieve(item["url"], 'image/' + item['title']+'.gif')
gLock.acquire()
gNum +=1
print('下载了 %d' %gNum)
gLock.release()
div_list.append(item)
self.content_queue.put(div_list) # 将本次html中所提取的到信息放到content列表上
self.html_queue.task_done() # html队列完成本次任务,从队列中删除该元素
def save_data(self):
while True:
content_list = self.content_queue.get()# 从content队列中拿出一个信息列表出来
with open("doutu.json","a",encoding="utf-8") as f:
for content in content_list:
f.write(json.dumps(content,ensure_ascii=False))
f.write("\n")
print("保存成功")
self.content_queue.task_done() # content 队列完成本次任务,从队列中删除该元素
def run(self):
# 测试时间,开端
starttime = datetime.datetime.now()
thread_list = [] # 初始化一个线程列表
# 2. url_list
t_url = threading.Thread(target=self.start_url) # 使用一个线程完成获取Url_list的任务
thread_list.append(t_url) # 添加到线程列表中
# 3. 提交请求,获取响应
for i in range(10):
t_parse = threading.Thread(target=self.parse_url) # 遍历一次就使用一个线程来去完成请求任务
thread_list.append(t_parse)
# 4. 提取数据
for i in range(5):
t_html = threading.Thread(target=self.get_content_list) #遍历一次就使用一个线程来去完成提取数据任务
thread_list.append(t_html)
# 5. 保存数据
for i in range(4):
t_save = threading.Thread(target=self.save_data) #遍历一次就使用一个线程来去完成保存数据的任务
thread_list.append(t_save)
for t in thread_list: #遍历线程列表
t.setDaemon(True) #设置守护线程,确保有线程在执行,当只有守护线程时,程序结束运行
t.start()# 线程开始运行
for q in [self.url_queue,self.html_queue, self.content_queue]: #依次遍历三个队列
q.join() # 阻塞进程,直到该线程执行完毕
print("主线程结束")
# 打印时间
endtime = datetime.datetime.now()
print(endtime - starttime).seconds
if __name__ == '__main__':
DoutuSpider = Doutu_Spider()
DoutuSpider.run()
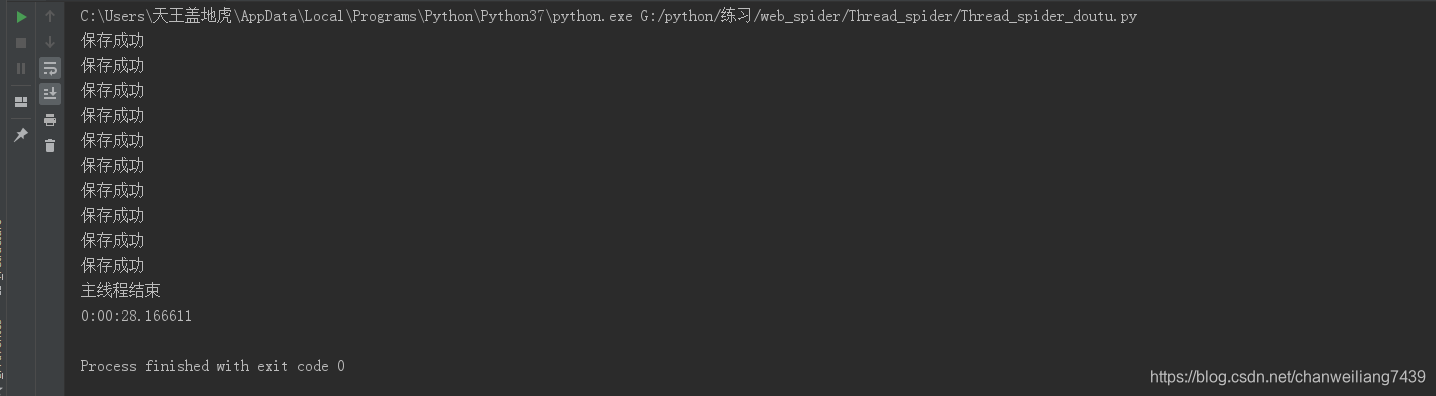
多线程程序运行结果
我们可以看到,在多线程的情况下,爬取和下载这十个链接只花费了282s左右的时间。共获取了300张图片。

8.总结
两份代码都是执行同一个任务,就是爬取斗图网上前十页的表情包。但单线程程序花了51s多的时间,而多线程程序只用了28s就完成了,这缩减了接近一半的时间,大大提升了效率。
多线程程序可以充分利用cpu,在同等情况,会比单线程程序的执行效率高得多。一般对于一些复杂的程序,我们通过多线程可以提高其执行效率,但对于普通简单的程序,我们写多线程程序无疑大材小用了。但对于爬虫的项目来说,利用多线程程序可以更有效率完成我们的任务,因此学会多线程编程是很有必要的。最后祝福我们一起都能把多线程学好!!
版权声明:本文为chanweiliang7439原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。