一、课程导入
什么是ORM(对象关系映射)
makemigrations根据模型创建数据迁移文件
migrate使数据库状态与当前模型集和迁移集同步
导出数据命令 – dumpdata
导入数据命令 – loaddata
二、新课讲授
Django对数据库的数据进行增、删、改操作是借助内置ORM框架所提供的API方法实现的,简单来说,ORM框架的数据操作API是在QuerySet类里面定义的,然后由开发者自定义的模型对象调用QuerySet类,从而实现数据操作。
(一)Shell模式新增数据
Django提供了多种数据新增方法,开发者可以根据实际情况以及个人使用习惯选择某一种新增方式。为了更好地演示数据库的增、删、改操作,在项目babies使用Shell模式(启动命令行和执行脚本)进行讲述,该模式方便开发人员开发和调试程序。
在PyCharm的Terminal下开启Shell模式,输入python manage.py shell指令即可,如下图所示。
如果Shell模式示符是“>>>”
可以安装IPython,如下图所示
此时,再进入Shell模式
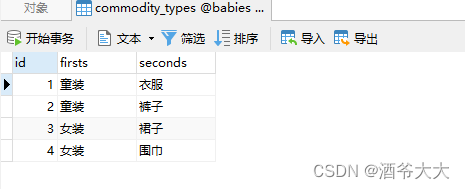
下面准备针对商品类别表进行操作,表里目前有
4
条记录
1、使用实例化 – 赋值 – save新增数据
-
在Shell模式下,若想对数据表
commodity_types
新增数据,则可输入以下代码实现
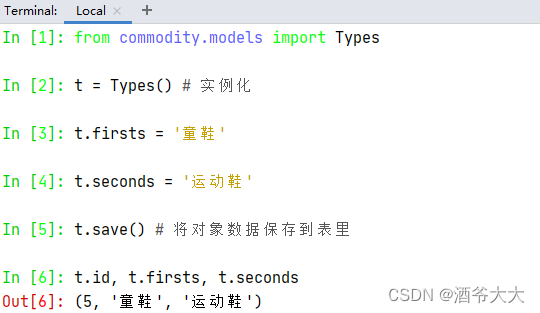
-
新增数据步骤:导入模型 —— 实例化 —— 属性赋值 —— 调用save()方法保存数据
-
查看commodity_types数据表,看是否新增一条记录

2、使用create方法新增数据
-
执行命令:
t = Types.objects.create(firsts='儿童用品', seconds='婴儿车')

-
对应的SQL语句:
INSERT INTO commodity_types (firsts, seconds) VALUES ('儿童用品', '婴儿车')
-
查看
commodity_types
数据表,看是否新增一条记录

3、使用字典与create方法新增数据
-
依次执行下述命令
-
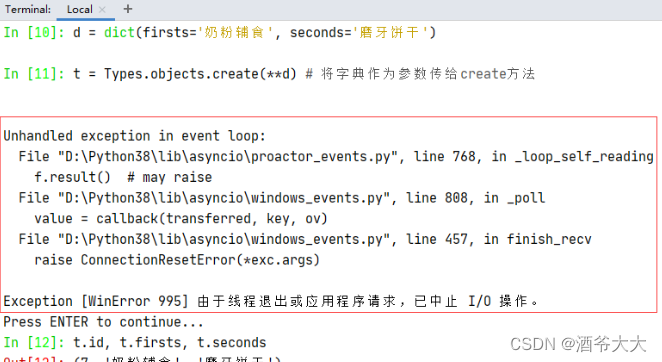
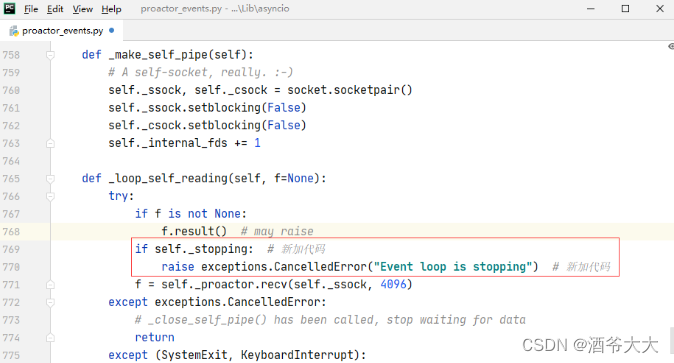
我们来处理一下这个讨厌的异常,打开
D:\Python38\lib\asyncio\proactor_events.py
文件,在768行后面添加两行语句,如下图所示
查看
commodity_types
数据表,看是否新增一条记录
4、使用实例化赋值 – save新增数据
-
依次执行下述命令,调用有参构造方法实例化:
t = Types(firsts='早教产品', seconds='格林童话')

查看
commodity_types
数据表,看是否新增一条记录

5、使用get_or_create新增无重数据
在执行数据新增时,为了保证数据的有效性,我们需要对数据进行去重判断,确保数据不会重复新增。以往的方案都是对数据表进行查询操作,如果查询的数据不存在,就执行数据新增操作。为了简化这一过程,Django提供了get_or_create方法。

只要有一个模型字段的值与数据表的数据不相同(除主键之外),就会执行数据新增操作。
如果每个模型字段的值与数据表的某行数据完全相同,就不执行数据新增,而是返回这行数据的数据对象,比如对上述的字典d重复执行get_or_create,第一次是执行数据新增(若执行结果显示为True,则代表数据新增),第二次是返回数据表已有的数据信息(若执行结果显示为False,则数据表已存在数据,不再执行数据新增)
查看commodity_types数据表,看是否新增一条记录

6、使用update_or_create新增或更新数据
update_or_create是根据字典d的内容查找数据表的数据,如果能找到相匹配的数据,就执行数据修改,修改内容以字典格式传递给参数defaults即可;如果在数据表找不到匹配的数据,就将字典d的数据新增到数据表里。
第一次是新增数据

查看
commodity_types
数据表

第二次是修改数据

查看
commodity_types
数据表

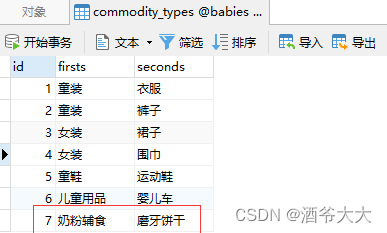
7、使用bulk_create批处理添加数据
-
在使用
bulk_create
之前,数据类型为模型
Types
的实例化对象,并且在实例化过程中设置每个字段的值,最后将所有实例化对象放置在列表或元组里,以参数的形式传递给
bulk_create
,从而实现数据的
批量新增操作
。

探索一下
bulk_create()
的返回值是什么东东
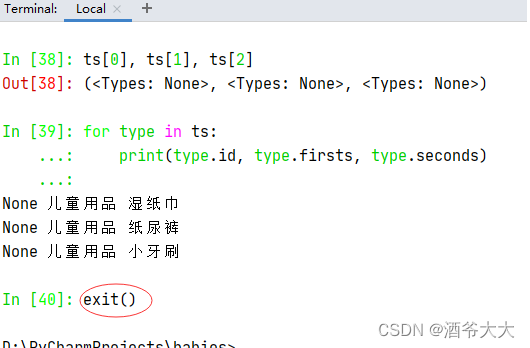
查看
commodity_types
数据表
退出Shell模式
(二)Shell模式更新数据
1、使用get – 修改 – save方式
-
更新数据的步骤与数据新增的步骤大致相同,唯一的区别在于数据对象来自数据表,因此需要执行一次数据查询,查询结果以对象的形式表示,并将对象的属性进行赋值处理,代码如下:

打开数据表
commodity_types
查看数据修改情况

第二条记录的
firsts
属性还是应该改成
儿童服装

上述命令没有报错,是因为
firsts=‘童装’
的记录只有一条
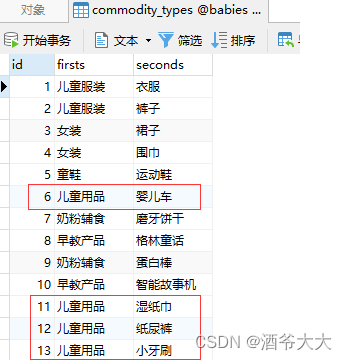
看一看,
firsts='儿童用品'
的记录有
4
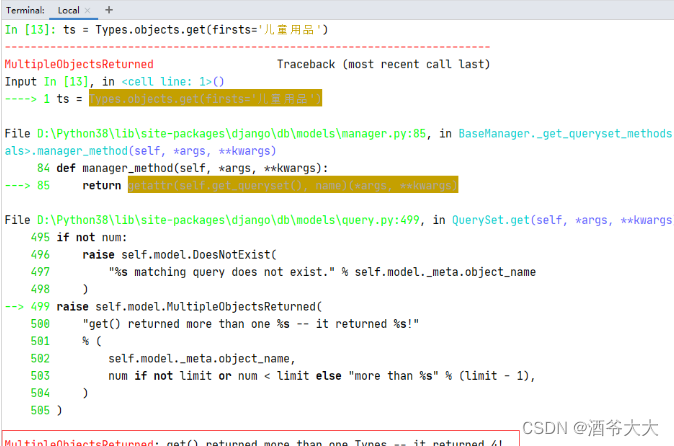
条,此时用get()方法就要报错 –
MultipleObjectsReturned
2、使用filter – update方式
-
批量更新
一条或多条
数据,查询方法使用
filter
,
filter
以列表格式返回,查询结果可能是零条、一条或多条数据构成的列表 -
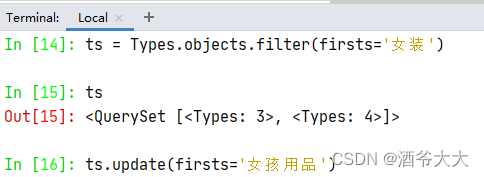
任务:将firsts为
女装
的值改为
女孩用品
打开数据表
commodity_types
查看数据修改情况

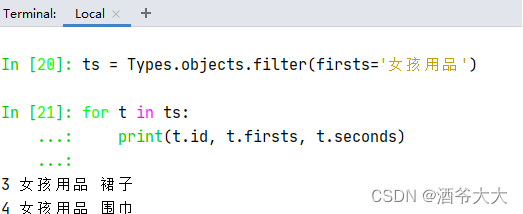
遍历查询集(QuerySet)
可以同时更新多个字段值,比如
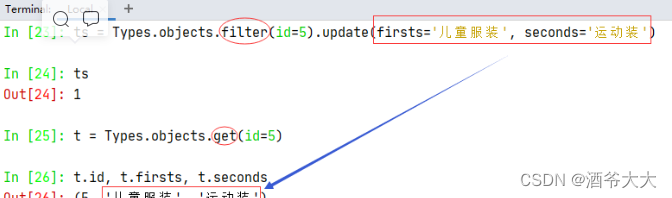
Types.objects.filter(id=5).update(firsts='儿童服装', seconds='运动装')
,大家不妨一试
3、使用dict – filter – update方式
- 更新数据以字典格式表示
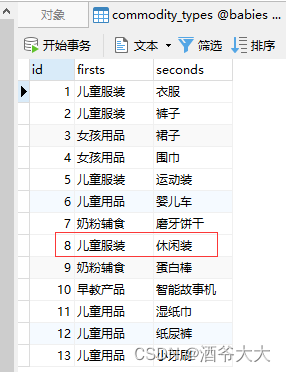
- 任务:将第8条记录修改为(儿童服装,休闲装)

打开数据表
commodity_types
查看数据修改情况
导出SQL脚本
4、使用update方式实现全表更新
-
不使用查询方法
get
或
filter
,
默认
对全表数据进行更新 -
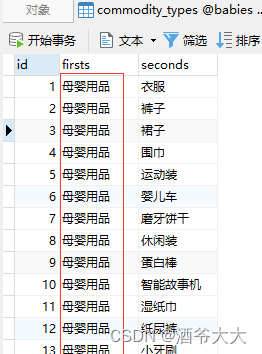
任务:将全部记录的
firsts
字段修改为
母婴用品

打开数据表
commodity_types
查看数据修改情况
{ 祝大家都能学有所成! }