T5全称是Text-to-Text
Transfer Transformer
,是一种模型架构或者说是一种解决NLP任务的一种范式。它的主要目标就是使
用
文本生成
的方式来解决各种自然语言处理任务,例如机器翻译、摘要、问答等。T5通过使用一种
统一的编码和解码
方法来解决不同的任务,从而避免了为每个任务单独设计模型的问题,在训练过程中使用了
大量的数据
和计算资源,以便在比较小的数据集上训练任务特定的模型。并且在大型的数据集上进行了广泛的评估,在许多自然语言处理任务中表现出优越的性能。

零样本文本分类
使用
生成模型进行零样本分类
的主要思路是将
候选标签
与
待分类文本
按照
一定格式进行拼接
后作为
模型输入
,期望模型可
以输入文本所属的标签
。图4展示了在ModelScope上进行测试的结果(该用例并未在训练过程中学习过)。
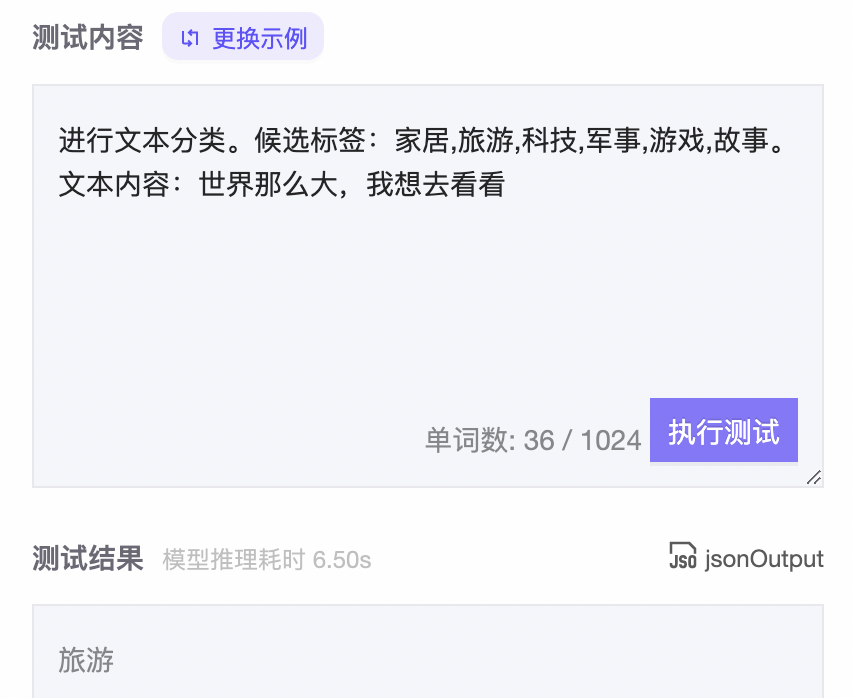
零样本分类增强
由于
文本生成
模型的输出
具有一定的随机性
,在使用基于
文本生成
的零样本学习模型进行零样本分类时,模型输出的结果可能并不在所给的候选标签之中,从而导致模型不可用。因此,我们使用了一种数据增强的方式来提升模型在零样本分类中的稳定性,并设计了零样本分类稳定性评测对模型分类的稳定性进行指标的量化。
零样本
分类稳定性评测
评测方式
从40万条文本
中随机挑选了
1万条文本
作为待分类文本,再为每条文本从130个标签库中随机挑选随机数量的标签作为候选标签,最后结合文本和候选标签得到评测数据集。
对于每个模型均使用其在训练时
使用的prompt
构建模型输入。如果模型最终的输出存在于候选标签中,则认为该模型在该样本上的预测稳定,否则认为模型不稳定。
评测结果
|
模型名字 |
零样本分类稳定率(%) |
|
PromptCLUE [3] |
48.65 |
|
PromptCLUE-base-v1-5 [4] |
76.32 |
|
未进行分类增强 |
64.32 |
|
98.51 |
从评测结果中可以发现,经过零样本分类增强之后,该模型零样本分类稳定率从64.32提升到了98.51。
样例测试
测试流程
-
使用模型
指定的prompt构建输入
,进行第
一次分类
。
-
如果
分类结果稳定
,即输出的
内容属于候选标签
,那么将
输出的标签从候选标签中剔除
。
-
再次根据
指定的prompt
构建输入,进行分类。
-
重复步骤b和步骤c,直到
分类结果不稳定
或
候选标签已
清空。
测试用例
测试用例使用
PromptCLUE
中所给的demo用例。
待分类文本:如果日本沉没,中国会接收日本难民吗?
候选标签:故事,文化,娱乐,体育,财经,房产,汽车,教育,科技,军事,旅游,国际,股票,农业,游戏
测试结果
PromptCLUE
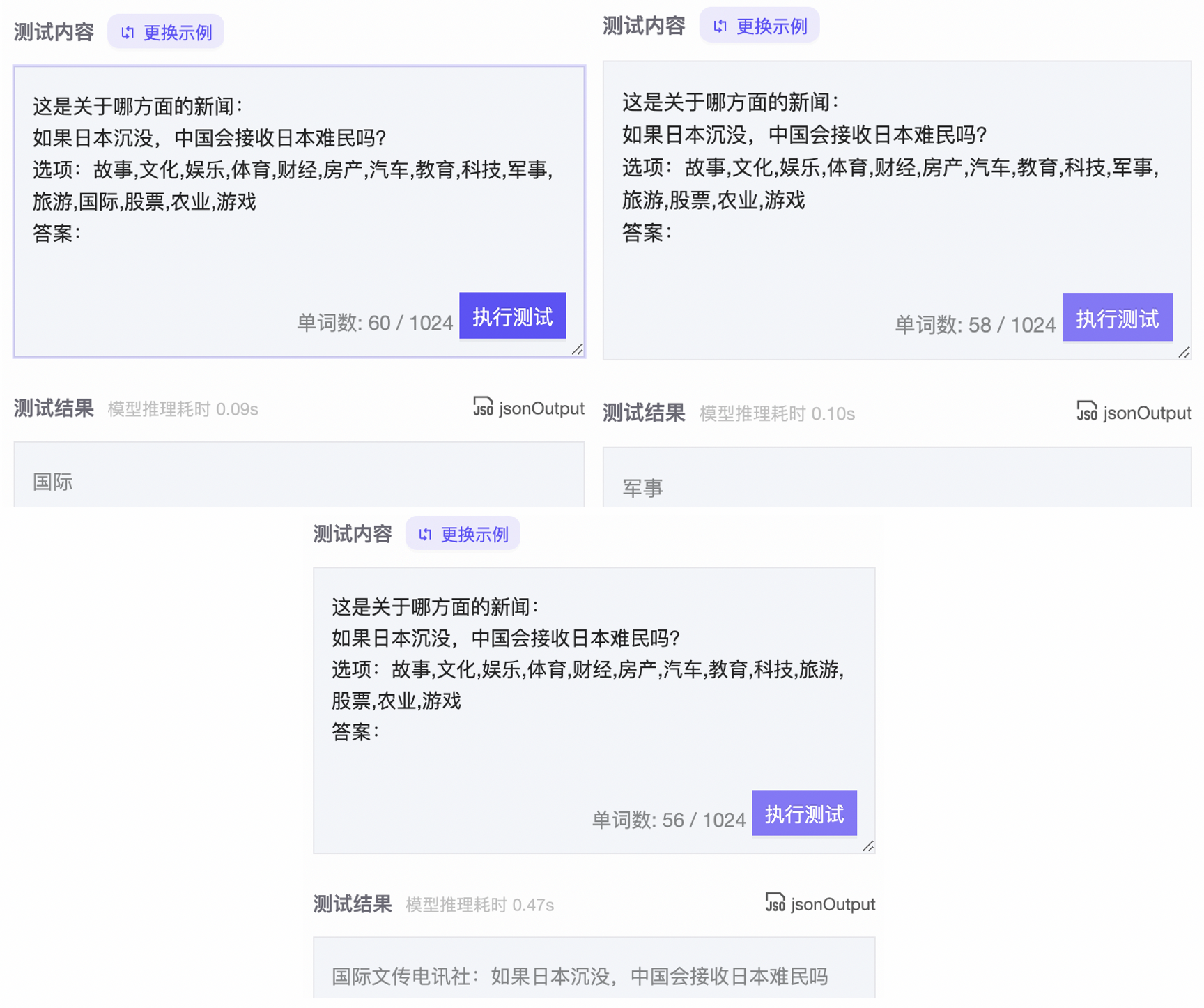
从测试结果中可以发现,Prompt CLUE在第3次分类时,已经出现了
模型不稳定
的情况。
全任务零样本学习-
mT5分类增强版-
中文-base

在测试过程中,该模型可以一直保持输出稳定直到候选标签被完全清空。
零样本学习评测
基于
文本生成
的零样本学习模型
不仅支持零样本分类
,同时还可以支持其他任务,如阅读理解、摘要生成、翻译等。因此,该模型选用了
pCLUE
[5]进行评测,同时与PromptCLUE进行了对比。整体评测结果如下:
|
模型名字 |
Score |
阅读理解(F1) |
阅读理解(EM) |
分类(acc) |
推理(acc) |
生成(rouge-l) |
|
PromptCLUE |
0.495 |
0.650 |
0.518 |
0.539 |
0.515 |
0.342 |
|
nlp_mt5_zero-shot-augment_chinese-base |
0.528 |
0.685 |
0.560 |
0.582 |
0.550 |
0.357 |
本章小结
使用
文本生成
的方式实现零样本分类时,可以将所有候选标签进行结合,只需要
生成一个样本
进行分类。相比基于NLI的零样本分类模型,在推理效率上优势比较大。但该模型会带来了分类结果不稳定的问题,即输出的文本不存在于候选标签中。而
全任务零样本学习-mT5分类增强版-中文-base
通过一种数据增强的方式大幅提升了在文本分类场景下的稳定性,在零样本分类稳定性评测中表现出的准确率可达98.51%,远大于其他模型,但在稳定性方面依然不如基于nli的模型。因此,该模型适用于对推理时间较为敏感的低资源文本分类场景。
总结
本文主要介绍了两类可以用于零样本文本分类的模型。
-
基于自然语言推理的零样本分类模型
:适用于对模型
推理时间不敏感的低资源文本
分类场景,在抹零战役工单分类任务中,表现出了优异的性能。
-
基于
文本生成
的零样本学习模型:适用于
对模型推理时间要求较高
的低资源本文分类场景,同时还能进行其他任务的零样本学习。而本文介绍的模型在分类场景下进行了特定的数据增强,大幅提高了分类的稳定性,相比于其他模型更加适合应用于零样本文本分类场景。
参考文献
[1] Wang W, Bi B, Yan M, et al. Structbert: Incorporating language structures into pre-training for deep language understanding[J]. arXiv preprint arXiv:1908.04577, 2019.
[2] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 5485-5551.
[3] https://www.modelscope.cn/models/ClueAI/PromptCLUE/summary
[4] https://www.modelscope.cn/models/ClueAI/PromptCLUE-base-v1-5/summary
[5] https://github.com/CLUEbenchmark/pCLUE