注意:本文对GCD进行剖析的顺序是: GCD的概念–> API基本使用–>GCD源码解读—>常用场景的一些扩展与对比(js的线程对比)
目录
1、异步栅栏+并发队列:dispatch_barrier_async
2、同步栅栏+并发队列:dispatch_barrier_sync
3、dispatch_group_enter、dispatch_group_leave
2、Dispatch Semaphore线程安全和线程同步(为线程加锁)
先从创建队列开始。我们已经很熟悉,创建队列的方法是调用dispatch_queue_create函数。
1、_dispatch_queue_create_with_target
2、_dispatch_global_queue_poke函数
5、_dispatch_root_queues_init函数
6、_pthread_workqueue_init_with_kevent
一、简介
1、什么是GCD?看看百度百科的定义:
GCD为Grand Central Dispatch的缩写。Grand Central Dispatch (GCD)是Apple开发的一个多核编程的较新的解决方法。
全称:
它主要用于优化应用程序以支持多核处理器以及其他对称多处理系统。它是一个在线程池模式的基础上执行的并行任务。在Mac OS X 10.6雪豹中首次推出,也可在IOS 4及以上版本使用。
设计:
GCD是一个替代诸如NSThread等技术的很高效和强大的技术。GCD完全可以处理诸如数据锁定和资源泄漏等复杂的异步编程问题。GCD的工作原理是让一个程序,根据可用的处理资源,安排他们在任何可用的处理器核心上平行排队执行特定的任务。这个任务可以是一个功能或者一个程序段。
GCD仍然在一个很低的水平使用线程,但是它不需要程序员关注太多的细节。GCD创建的队列是轻量级的,苹果声明一个GCD的工作单元需要由15个指令组成。也就是说创造一个传统的线程很容易的就会需要几百条指令。
GCD中的一个任务可被用于创造一个被放置于队列的工作项目或者事件源。如果一个任务被分配到一个事件源,那么一个由功能或者程序块组成的工作单元会被放置于一个适当的队列中。苹果公司认为GCD相比于普通的一个接一个的执行任务的方式更为有效率。
功能:
这个调度框架声明了几种数据类型和函数来创建和操作他们:
一、调度队列
所有的调度队列都是先进先出队列,因此,队列中的任务的开始的顺序和添加到队列中的顺序相同。GCD自动的为我们提供了一些调度队列,我们也可以创建新的用于具体的目的。
下面列出几种可用的调度队列类型以及如何使用。
二、调度资源
它是一个监视某些类型事件的对象。当这些事件发生时,它自动将一个block放入一个调度队列的执行例程中。
三、调度组
允许将多任务分组来方便后来加入执行。任务能作为一个组中的一个成员被加到队列中,客户端能用这个组对象来等待直到这个组中的所有任务完成。
四、调度信号量
允许客户端并行发布一定数量的任务。
2、使用GCD有哪些好处呢?
- GCD 可用于多核的并行运算
- GCD 会自动利用更多的 CPU 内核 (比如双核、四核)
- GCD 会自动管理线程的生命周期(创建线程、请度任务、销段线程)
- 程序员只需要告诉 GCD 想要执行什么任务,不需要编写任何线程管理代码
二、GCD任务和队列
1、什么是任务?
- 任务就是执行操作的患思,换句话说就是你在线程中执行的那段代码。在GCD中是放在 block 中的。
- 执行任务有两种方式:同步执行(sync)和异步执行(async)。
- 两者的主要区别是:是否等待队列的任务执行结束,以及是否具备开启新线程的能力。
2、那么什么是同步执行和异步执行呢?
1、同步执行(sync):
- 同步添加任务到指定的队列中,在添加的任务执行结束之前,会一直等待,直到队列里面的任务完成 之后再继续执行。
- 只能在当前线程中执行任务,不具备开启新线程的能力。
2、异步执行(async):
- 异步添加任务到指定的队列中,它不会健任何等待,可以维续执行任务。
- 可以在新的线程中执行任务,具备开启新线程的能力。
举个例子:
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
所谓
同步异步
,只是对于水壶而言。普通水壶,同步;响水壶,异步。虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。立等的老张,阻塞;看电视的老张,非阻塞。情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
注意:异步执行虽然具有开启新线程的能力,但并不一定开启新线程,这个和任务所指定的队列有关
3、什么是队列(Dispatch Queue)?
队列是 一种特排的线性表,采用FIFO(先进先出)的原则,即新任务总是被插入到队列的末尾,而读取任务的时候总是从队列的头部开始读取。每读取一个任务,则从队列中释放一个任务。队列的结构可参考下图

在GCD中有两种队列:串行队列和并发队列。两者都符合FIFO(先进先出)的原则。两者的主要区别是:执行顺序不同,以及开启线程数不同。
- 串行队列(Serial Dispatch Queue): 每次只有一个任务被执行。让任务一个接着一个地执行。(只开启一个线程,一个任务执行完后, 再执行下一个任务)
- 并发以列(Concurrent Dispatch Queue) :可以让多个任务并发执行。(可以开启多个线程,并且同时执行任务)
- 注意:并发队列的并发功能只有在异步(dispatch_async)函数下才有效


三、GCD的使用步骤
GCD的使用只有两步:
- 创建一个队列(串行队列或并发队列)
- 特任务追加到任务的等特队列中,然后系统就会根据任务类型执行任务(同步执行或异步执行)
1、队列的创建方法/获取方法
可以使用dispatch.queue_create来创建队列,需要传入两个参数,第一个参数表示队列的唯一标识符,用于DEBUG,可为空,Dispatch Queue的名称推荐使用应用程序 ID 这种逆序全称域名:第二个参数用来识别是串行队列还是并发以列,DISPATCH_QUEUE_SERIAL表示串行以列,DISPATCH_QUEUE_CONCURRENT 表示并发队列。
// 串行队列的包建方法
dispatch_queue_t queue1 = dispatch_queue_create("com.lz.testQueueSerial",DISPATCH_QUEUE_SERIAL);
//并发以列的创建方法
dispatch_queue_t queue2 = dispatch_queue_create("com.lz.testQueueConcurrent",DISPATCH_QUEUE_CONCURRENT);对于串行队列,GCD提供了的一种特殊的串行队列:主队列(Main Dispatch Queue)。
- 所有放在主队列中的任务,都会放到主线程中执行。
- 可使用dispatch_get_main_queue()获得主队列。
//主队列的获取方法
dispatch_queue_t queue3 = dispatch_get_main_queue();
对于并发队列,GCD 默认提供了全局并发队列(Global Dispatch Queue)。
可以使用dispatch_get_global_queue来获取。需要传入再个参数。第一个参数表示队列优先级,一般用DISPATCH_QUEUE_PRIORITY_DEFAULT,第二个参数暂时没用,用0即可。
//全局并发队列的获取方法
dispatch_queue_t queue4 = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
2、任务的创建方法
GCD提供了同步执行任务的创建方法dispatch_sync和异步执行任务创建方法dispatch_async。
//同步执行任务创建方法
dispatch_sync(queue1, ^{
//这里放同步执行任务代码
});
//异步执行任务创建方法
dispatch_async(queue2, ^{
//这里放异步执行任务代码
});虽然使用GCD只需两步,但是既然我们有两种队列(串行队列/并发队列),两种任务执行方式 (同步执行/异步执行),那么我们就有了四种不同的组合方式。再加上两种特殊的队列(全局并发队列、主队列),全局并发队列可以作为普通并发队 列来使用。但是主队列因为有点特殊,所以我们就又多了两种组合方式。所以一共有六种不同的组合方式:
- 同步执行+并发队列
- 异步执行 + 并发队列
- 同步执行+串行队列
- 异步执行 + 串行队列
- 同步执行+主队列
-
异步执行+主队列
3、那么这几种不同组合方式各有什么区别呢?
| 区别 | 并发队列 | 串行队列 | 主队列 |
| 同步(sync) | 没有开启新线程 | 串行执行任务没有开启新线程 |
串行执行任务 主线程调用:死锁 卡住不执行 其他线程调用:没有开启新线程,串行执行任务 |
| 异步(async) | 有开启新线程,并发执行任务有开启新线程(1条) | 串行执行任务没有开启新线程 | 串行执行任务 |
四、基本使用
此部分按照先并发后串行的方式介绍
1、同步执行+并发队列
在当前线程中执行任务,不会开启新线程,执行完一个任务,再执行下一个任务。
//同步执行+并发队列
//特点:在当前线程中执行任务,不会开启新线程,执行完-一个任务,再执行下一个任务。
- (void)syncConcurrent{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"syncConcurrent---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_sync(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"syncConcurrent---end");
}
打印结果:
2021-05-01 12:15:42.961187+0800 demo[239:6859799] currentThread---<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:42.961284+0800 demo[239:6859799] syncConcurrent---begin
2021-05-01 12:15:44.962466+0800 demo[239:6859799] 1--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:46.962899+0800 demo[239:6859799] 1--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:48.964264+0800 demo[239:6859799] 2--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:50.964597+0800 demo[239:6859799] 2--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:52.965954+0800 demo[239:6859799] 3--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:54.967214+0800 demo[239:6859799] 3--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-01 12:15:54.967373+0800 demo[239:6859799] syncConcurrent---end结果分析(同步执行+并发队列):
- 所有任务都是在当前线程(主线程)中执行的,没有开启新的线程(同步执行不具备开启新线程的能力)。
- 所有任务都在打印的syncConcurrent— begin和syncConcurrent—end之间执行的(同步任务需要等待队列的任务执行结束)。
- 任务按顺序执行的。按顺序执行的原因:虽然并发队列可以开启多个线程,并且同时执行多个任务。但是因为本身不能创建新线程,只有当前线程这一个线程(同步任务不具备开启新线程的能力),所以也就不存在并发。而且当前线程只有等待当前队列中正在执行的任务执行完毕之后,才能继续接着执行下面的操作(同步任务需要等待队列的任务执行结束)。所以任务只能一个接一个按顺序执行,不能同时被执行。
2、异步执行+并发队列
可以开启多个线程,任务交替(同时)执行。
//异步执行+并发队列
//特点:可以开启多线程,任务交替(同时)执行。
- (void)asyncConcurrent{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"asyncConcurrent---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"asyncConcurrent---end");
}打印结果:
2021-05-01 12:30:37.435518+0800 demo[294:6868019] currentThread---<NSThread: 0x600001700ec0>{number = 1, name = main}
2021-05-01 12:30:37.435587+0800 demo[294:6868019] asyncConcurrent---begin
2021-05-01 12:30:37.435640+0800 demo[294:6868019] asyncConcurrent---end
2021-05-01 12:30:37.463087+0800 demo[294:6868019] Metal API Validation Enabled
2021-05-01 12:30:39.435767+0800 demo[294:6868333] 1--<NSThread: 0x60000175fe80>{number = 2, name = (null)}
2021-05-01 12:30:39.435802+0800 demo[294:6868337] 3--<NSThread: 0x600001773680>{number = 4, name = (null)}
2021-05-01 12:30:39.435772+0800 demo[294:6868332] 2--<NSThread: 0x6000017004c0>{number = 3, name = (null)}
2021-05-01 12:30:41.438511+0800 demo[294:6868337] 3--<NSThread: 0x600001773680>{number = 4, name = (null)}
2021-05-01 12:30:41.438511+0800 demo[294:6868332] 2--<NSThread: 0x6000017004c0>{number = 3, name = (null)}
2021-05-01 12:30:41.438511+0800 demo[294:6868333] 1--<NSThread: 0x60000175fe80>{number = 2, name = (null)}结果分析(异步执行+并发队列):
- 除了当前线程(主线程),系统又开启了3个线程,并且任务是交替/同时执行的。(异步 执行具备开启新线程的能力。且并发队列可开启多个线程,同时执行多个任务)。
- 所有任务是在打印的asyncConcurrent— begin和asyncConcurrent—end之后才执行的。说明当前线程没有等待,而是直接开启了新线程,在新线程中执行任务(异步执行不做等待,可以继续执行任务)
3、同步执行+串行队列
不会开启新线程,在当前线程执行任务。任务是串行的,执行完一个任务,再执行下一个任务。
//同步执行+串行队列
//特点:不会开启新线程,在当前线程执行任务。任务是串行的,执行完一个任务,再执行下一个任务
- (void)syncSerial{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"syncSerial---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_SERIAL);
dispatch_sync(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"syncSerial---end");
}打印结果:
2021-05-02 21:29:53.162186+0800 demo[1406:6983838] currentThread---<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:29:53.162255+0800 demo[1406:6983838] syncSerial---begin
2021-05-02 21:29:55.163373+0800 demo[1406:6983838] 1--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:29:57.163679+0800 demo[1406:6983838] 1--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:29:59.165017+0800 demo[1406:6983838] 2--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:30:01.165695+0800 demo[1406:6983838] 2--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:30:03.167037+0800 demo[1406:6983838] 3--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:30:05.168121+0800 demo[1406:6983838] 3--<NSThread: 0x600001700f80>{number = 1, name = main}
2021-05-02 21:30:05.168296+0800 demo[1406:6983838] syncSerial---end结果分析(同步执行+串行队列):
- 所有任务都是在当前线程(主线程) 中执行的,并没有开启新的线程(同步执行不具备开启新线程的能力)。
- 所有任务都在打印的syncSerial—begin和syncSerial—end之间执行(同步任务需要等待队列的任务执行结束)。
- 任务是按顺序执行的(串行队列每次只有一个任务被执行,任务-个接一个按顺序执行)。
4、异步执行+串行队列
会开启新线程,但是因为任务是串行的,执行完一一个任务,再执行下一个任务
//异步执行+串行队列
//特点:会开启新线程,但是因为任务是串行的,执行完一一个任务,再执行下一个任务。
- (void)asyncSerial{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"asyncSerial---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"asyncSerial---end");
}打印结果:
2021-05-02 21:39:19.551492+0800 demo[1475:6989705] currentThread---<NSThread: 0x600001710e40>{number = 1, name = main}
2021-05-02 21:39:19.551576+0800 demo[1475:6989705] asyncSerial---begin
2021-05-02 21:39:19.551638+0800 demo[1475:6989705] asyncSerial---end
2021-05-02 21:39:19.576664+0800 demo[1475:6989705] Metal API Validation Enabled
2021-05-02 21:39:21.552041+0800 demo[1475:6990008] 1--<NSThread: 0x600001771a00>{number = 2, name = (null)}
2021-05-02 21:39:23.556819+0800 demo[1475:6990008] 1--<NSThread: 0x600001771a00>{number = 2, name = (null)}
2021-05-02 21:39:25.561371+0800 demo[1475:6990008] 2--<NSThread: 0x600001771a00>{number = 2, name = (null)}
2021-05-02 21:39:27.566555+0800 demo[1475:6990008] 2--<NSThread: 0x600001771a00>{number = 2, name = (null)}
2021-05-02 21:39:29.571475+0800 demo[1475:6990008] 3--<NSThread: 0x600001771a00>{number = 2, name = (null)}
2021-05-02 21:39:31.573000+0800 demo[1475:6990008] 3--<NSThread: 0x600001771a00>{number = 2, name = (null)}
结果分析(异步执行+串行队列):
- 开启了一条新线程(异步执行具备开启新线程的能力,串行队列只开启一个线程)。
- 所有任务是在打印的asyncSerial– begin和asyncSerial—end之后才开始执行的(异步执行不会做任何等待,可以继续执行任务)。
- 任务是按顺序执行的(串行队列每次只有一个任务被执行,任务一个接一个按顺序执行)。
5、主队列
主队列是GCD自带的一种特殊的串行队列
- 所有放在主队列中的任务,都会放到主线程中执行
- 可使用dispatch_ get_ main_ _queue0获得主队列
6、同步执行+主队列
同步执行+主队列在不同线程中调用结果也是不一样,在主线程中调用会出现死锁,而在其他线程中则不会。
1 、在主线程中调用同步执行+主队列
互相等待卡住(死锁)
//同步执行+主队列
//特点(主线程调用):互等卡主不执行。
//特点(其他线程调用):不会开启新线程,执行完一个任务,再执行下一个任务。
- (void)syncMain{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"syncMain---begin");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_sync(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_sync(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"syncMain---end");
}
打印结果:
2021-05-02 21:54:35.856060+0800 demo[1660:6999657] currentThread---<NSThread: 0x600001710dc0>{number = 1, name = main}
2021-05-02 21:54:35.856129+0800 demo[1660:6999657] syncMain---begin
并报错:

结果分析(在主线程中调用同步执行+主队列):
在主线程中使用同步执行+主队列,追加到主线程的任务1、任务2、任务3都不再执行了,而且syncMain—end也没有打印,在XCode 9和9以上的开发工具中还会报崩溃。这个地方我们来分析下具体原因:
上面我们提到了,所有放在主队列中的任务,都会放到主线程中执行,而我们在主线程中执行syncMain方法的时候,相当于把syncMain任务放到了主线程的队列中,我们把执行syncMain方法命名为0号任务,然后我们在执行syncMain任务的时候,syncMain方法里面又在主队列中追加1号任务,并且是同步执行该1号任务(同步执行的特点是必须等待当前队列中的任务执行完毕才会被执行),也就是说,1号任务要想被执行,就必须要等待0号任务(syncMain方法)执行完毕,然而0号任务要想执行完毕的第一步条件就是1号任务要先执行完,所以就出现了互相等待,导致2号任务和3号任务都没执行,出现死锁,程序崩溃。
2、在其他线程中调用同步执行+主队列
不会开启新线程,执行完一个任务,再执行下一个任务
//使用detachNewThreadSelector开启新线程并自动执行syncMain方法
[NSThread detachNewThreadSelector:@selector(syncMain) toTarget:self withObject:nil];打印结果:
2021-05-02 22:23:40.866119+0800 demo[1793:7015378] currentThread---<NSThread: 0x600001746fc0>{number = 2, name = (null)}
2021-05-02 22:23:40.866215+0800 demo[1793:7015378] syncMain---begin
2021-05-02 22:23:40.892432+0800 demo[1793:7015081] Metal API Validation Enabled
2021-05-02 22:23:43.012675+0800 demo[1793:7015081] 1--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:45.013716+0800 demo[1793:7015081] 1--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:47.050584+0800 demo[1793:7015081] 2--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:49.051890+0800 demo[1793:7015081] 2--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:51.062918+0800 demo[1793:7015081] 3--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:53.064121+0800 demo[1793:7015081] 3--<NSThread: 0x600001700d00>{number = 1, name = main}
2021-05-02 22:23:53.064335+0800 demo[1793:7015378] syncMain---end结果分析(在其他线程中调用同步执行+主队列):
- 1、所有任务都是在主线程(非当前线程)中执行的,没有开启新的线程(所有放在主队列中的任务,都会放到主线程中执行)。
- 2、所有任务都在打印的syncMain—begin和syncMain—end之间执行(同步任务需要等待队列的任务执行结束)。
- 3、任务是按顺序执行的(主队列是串行队列,每次只有一个任务被执行,任务一个接一个按顺序执行)。
- 4、为什么现在就不会卡住了呢:因为syncMain任务放到了其他线程里,而任务1、任务2、任务3都在追加到主队列中,这三个任务都会在主线程中执行。syncMain 任务在其他线程中执行到追加任务1到主队列中,因为主队列现在没有正在执行的任务,所以,会直接执行主队列的任务1,等任务1执行完毕,再接着执行任务2、任务3。所以这里不会卡住线程。
7、异步执行+主队列
只在主线程中执行任务,执行完一个任务,再执行下一个任务
//异步执行+主队列
//特点:只在主线程中执行任务,执行完一个任务,再执行下一个任务
- (void)asyncMain{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"asyncMain---begin");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"asyncMain---end");
}打印结果:
2021-05-04 12:28:31.356713+0800 demo[6435:7622353] currentThread---<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:31.356812+0800 demo[6435:7622353] asyncMain---begin
2021-05-04 12:28:31.356892+0800 demo[6435:7622353] asyncMain---end
2021-05-04 12:28:31.384916+0800 demo[6435:7622353] Metal API Validation Enabled
2021-05-04 12:28:33.497650+0800 demo[6435:7622353] 1--<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:35.498515+0800 demo[6435:7622353] 1--<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:37.498816+0800 demo[6435:7622353] 2--<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:39.500118+0800 demo[6435:7622353] 2--<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:41.501458+0800 demo[6435:7622353] 3--<NSThread: 0x600001710c80>{number = 1, name = main}
2021-05-04 12:28:43.502064+0800 demo[6435:7622353] 3--<NSThread: 0x600001710c80>{number = 1, name = main}结果分析(异步执行+主队列):
- 所有任务在当前线程(主线程)中执行,没有开启新线程(虽然异步执行具备开启线程的能力,但因为是主队列,所以所有的任务都是在主线程中)。
- 所有任务都是在打印asyncMain—begin和asyncMain—end之后执行(异步执行不会做任何等待,可以继续执行任务)。
- 任务是按顺序执行(因为主队列是串行队列,每次只有一个任务被执行,任务是一个接着一个执行的)
五、GCD线程间的通信
实际开发过程中,UI的刷新是在主线程中进行的,而一些耗时操作是放在其他线程中的(例如:上传、下载)。当我们在其他线程中完成耗时操作后,需要回到主线程,这时就需要线程间通信。
//线程间通信
- (void)communication{
//获取全局并发队列
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
//获取主队列
dispatch_queue_t mainQueue = dispatch_get_main_queue();
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
//回到主线程
dispatch_async(mainQueue, ^{
//追加在主线程中执行的任务
[NSThread sleepForTimeInterval:2];//耗时
NSLog(@"2---%@" ,[NSThread currentThread]);//打印当前线程
});
});
}打印结果:
2021-05-04 14:14:12.973897+0800 demo[6836:7668907] Metal API Validation Enabled
2021-05-04 14:14:14.953424+0800 demo[6836:7669230] 1--<NSThread: 0x600001764e00>{number = 2, name = (null)}
2021-05-04 14:14:16.956083+0800 demo[6836:7669230] 1--<NSThread: 0x600001764e00>{number = 2, name = (null)}
2021-05-04 14:14:18.956857+0800 demo[6836:7668907] 2---<NSThread: 0x600001710dc0>{number = 1, name = main}结果分析(异步执行任务+返回主线程):
在其他线程中执行任务,执行完后返回主线程中再执行主线程中的操作
六、GCD其他API
1、异步栅栏+并发队列:dispatch_barrier_async
在我们需要异步执行两组操作,而且第一组操作执行完之后,才能开始执行第二组操作。这样我们就需要一个相当于栅栏一样的一个方法将两组异步执行的操作组给分割起来,当然这里的操作组里可以包含一个或多个任务。这就需要用到dispatch_barrier_ async方法在两个操作组间形成栅栏。dispatch_ barrier_async函数会等待前边追加到并发队列中的任务全部执行完毕之后,再将指定的任
务追加到该异步队列中。然后在di spatch_ barrier_ async函数追加的任务执行完毕之后,异步队列才
恢复为一般动作,接着追加任务到该异步队列并开始执行。
//异步栅栏+并发队列
//特点:多个栅栏任务串行执行任务,并且都在同一个线程中;栅栏函数之前任务执行完后再执行栅栏,最后再执行栅栏之后的任务;
- (void)barrierAsync{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"barrierAsync---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier_async---start");
dispatch_barrier_async(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier_async---end");
NSLog(@"barrier2_async---start");
dispatch_barrier_async(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier2_async---end");
NSLog(@"barrier3_async---start");
dispatch_barrier_async(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier3_async---end");
dispatch_async(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务4
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"4--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrierAsync---end");
}
打印结果:
2021-05-04 14:53:43.487817+0800 demo[7149:7695149] currentThread---<NSThread: 0x600001704f80>{number = 1, name = main}
2021-05-04 14:53:43.487886+0800 demo[7149:7695149] barrierAsync---begin
2021-05-04 14:53:43.487939+0800 demo[7149:7695149] barrier_async---start
2021-05-04 14:53:43.487978+0800 demo[7149:7695149] barrier_async---end
2021-05-04 14:53:43.488005+0800 demo[7149:7695149] barrier2_async---start
2021-05-04 14:53:43.488032+0800 demo[7149:7695149] barrier2_async---end
2021-05-04 14:53:43.488057+0800 demo[7149:7695149] barrier3_async---start
2021-05-04 14:53:43.488094+0800 demo[7149:7695149] barrier3_async---end
2021-05-04 14:53:43.488143+0800 demo[7149:7695149] barrierAsync---end
2021-05-04 14:53:43.513720+0800 demo[7149:7695149] Metal API Validation Enabled
2021-05-04 14:53:45.490835+0800 demo[7149:7695478] 1--<NSThread: 0x600001765680>{number = 2, name = (null)}
2021-05-04 14:53:45.490835+0800 demo[7149:7695479] 2--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:47.496184+0800 demo[7149:7695478] 1--<NSThread: 0x600001765680>{number = 2, name = (null)}
2021-05-04 14:53:47.496220+0800 demo[7149:7695479] 2--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:49.499824+0800 demo[7149:7695479] barrier--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:51.501022+0800 demo[7149:7695479] barrier--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:53.501271+0800 demo[7149:7695479] barrier2--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:55.502408+0800 demo[7149:7695479] barrier2--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:57.504119+0800 demo[7149:7695479] barrier3--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:53:59.508791+0800 demo[7149:7695479] barrier3--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:54:01.513407+0800 demo[7149:7695479] 3--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:54:01.513411+0800 demo[7149:7695492] 4--<NSThread: 0x600001774400>{number = 4, name = (null)}
2021-05-04 14:54:03.515018+0800 demo[7149:7695479] 3--<NSThread: 0x600001774080>{number = 3, name = (null)}
2021-05-04 14:54:03.515018+0800 demo[7149:7695492] 4--<NSThread: 0x600001774400>{number = 4, name = (null)}结果分析(dispatch_barrier_async):
- 在执行栅栏之前的异步操作完成之后,才开始执行栅栏函数,最后再执行栅栏函数之后的异步任务;
- 由于是异步任务,和异步栅栏,所有在执行任务执行先打印barrier—begin、dispatch_barrier_async—start、dispatch_barrier_async—end、barrier—end
- 栅栏之前和栅栏之后的任务是并发执行的(并发队列),并开启了新线程
- 多个栅栏函数串行执行
2、同步栅栏+并发队列:dispatch_barrier_sync
同步栅栏是在主线程中按顺序执行完一个任务,再执行下一个任务(串行执行);
栅栏函数之前任务执行完后再执行栅栏,最后再执行栅栏之后的任务;
//同步栅栏+并发队列
//特点:同步栅栏是在主线程中串行执行;栅栏函数之前任务执行完后再执行栅栏,最后再执行栅栏之后的任务;
- (void)barrierSync{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"barrierSync---begin");
dispatch_queue_t queue = dispatch_queue_create("com.lz.testQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier_async---start");
dispatch_barrier_sync(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier_sync---end");
NSLog(@"barrier2_sync---start");
dispatch_barrier_sync(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier2_sync---end");
NSLog(@"barrier3_sync---start");
dispatch_barrier_sync(queue, ^{
//追加任务barrier
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"barrier3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrier_sync---end");
dispatch_async(queue, ^{
//追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_async(queue, ^{
//追加任务4
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"4--%@" ,[NSThread currentThread]);//打印当前线程
}
});
NSLog(@"barrierAsync---end");
}打印结果:
2021-05-04 14:58:47.977351+0800 demo[7185:7698406] currentThread---<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:58:47.977419+0800 demo[7185:7698406] barrierSync---begin
2021-05-04 14:58:47.977469+0800 demo[7185:7698406] barrier_async---start
2021-05-04 14:58:49.980344+0800 demo[7185:7698730] 1--<NSThread: 0x600001748340>{number = 3, name = (null)}
2021-05-04 14:58:49.980362+0800 demo[7185:7698737] 2--<NSThread: 0x60000175c700>{number = 2, name = (null)}
2021-05-04 14:58:51.985759+0800 demo[7185:7698730] 1--<NSThread: 0x600001748340>{number = 3, name = (null)}
2021-05-04 14:58:51.985764+0800 demo[7185:7698737] 2--<NSThread: 0x60000175c700>{number = 2, name = (null)}
2021-05-04 14:58:53.986021+0800 demo[7185:7698406] barrier--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:58:55.986319+0800 demo[7185:7698406] barrier--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:58:55.986485+0800 demo[7185:7698406] barrier_sync---end
2021-05-04 14:58:55.986555+0800 demo[7185:7698406] barrier2_sync---start
2021-05-04 14:58:57.987788+0800 demo[7185:7698406] barrier2--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:58:59.989132+0800 demo[7185:7698406] barrier2--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:58:59.989305+0800 demo[7185:7698406] barrier2_sync---end
2021-05-04 14:58:59.989373+0800 demo[7185:7698406] barrier3_sync---start
2021-05-04 14:59:01.990530+0800 demo[7185:7698406] barrier3--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:59:03.990899+0800 demo[7185:7698406] barrier3--<NSThread: 0x600001714e40>{number = 1, name = main}
2021-05-04 14:59:03.991056+0800 demo[7185:7698406] barrier_sync---end
2021-05-04 14:59:03.991151+0800 demo[7185:7698406] barrierAsync---end
2021-05-04 14:59:04.023463+0800 demo[7185:7698406] Metal API Validation Enabled
2021-05-04 14:59:05.996299+0800 demo[7185:7698736] 3--<NSThread: 0x60000176d700>{number = 4, name = (null)}
2021-05-04 14:59:05.996311+0800 demo[7185:7698815] 4--<NSThread: 0x6000017739c0>{number = 5, name = (null)}
2021-05-04 14:59:07.999438+0800 demo[7185:7698815] 4--<NSThread: 0x6000017739c0>{number = 5, name = (null)}
2021-05-04 14:59:07.999438+0800 demo[7185:7698736] 3--<NSThread: 0x60000176d700>{number = 4, name = (null)}结果分析:
- 同步栅栏会在执行完任务后才执行下一个任务,即先打印barrier_async—start,然后会等待执行完栅栏任务后,再打印barrier_sync—end
- 执行完栅栏之前的任务后才执行栅栏任务,最后再执行栅栏之后的异步任务
- 同步栅栏的任务都是在主线程中按顺序执行完一个任务,再执行下一个任务
注意:在使用栅栏函数时.使用自定义队列才有意义,如果用的是串行队列或者系统提供的全局并发队列,这个栅栏函数的作用等同于一个同步函数的作用(这里就不做举例了,实际开发中一般不这样使用,如果是在主线程中调用同步串行同样会死锁);
3、GCD的延迟执行方法:dispatch_after
1、在指定时间之后执行某个任务
//延迟执行
- (void)after{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"barrierSync---begin");
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t) 2.0 * NSEC_PER_SEC ), dispatch_get_main_queue(), ^{
//2秒后追加任务到主队列开始执行
NSLog(@"after--%@" ,[NSThread currentThread]);//打印当前线程
});
}打印结果:
2021-05-04 15:20:09.804974+0800 demo[7306:7710342] currentThread---<NSThread: 0x600001714e00>{number = 1, name = main}
2021-05-04 15:20:09.805044+0800 demo[7306:7710342] barrierSync---begin
2021-05-04 15:20:09.831556+0800 demo[7306:7710342] Metal API Validation Enabled
2021-05-04 15:20:11.974272+0800 demo[7306:7710342] after--<NSThread: 0x600001714e00>{number = 1, name = main}结果分析:
在打印barrierSync—begin 2秒后才打印after–<NSThread: 0x600001714e00>{number = 1, name = main}
注意:dispatch_after并不是在指定时间后开始执行处理,而是在指定时间之后将任务追加到某个队列中(本例是将任务追加到主队列中)。所有严格意义来讲,这个时间并不是绝对的准确(拿本里来说,如果在2秒后追加到主队列中后,主队列中还有耗时操作在执行,那添加到主队列中的这个任务就会迟迟不执行),但想要大致延迟执行任务,此方法还是很有效的。
2、dispatch_after
执行时间不准确证明:
我们在主线程中调用after1方法后再添加一段耗时操作,并添加相应的时间日志:
[self after1];
NSLog(@"耗时begin---:%@",[NSDate date]);
for (NSInteger i=0; i<4; i++) {
[NSThread sleepForTimeInterval:1.0];
}
NSLog(@"耗时end---:%@",[NSDate date]);//延迟执行
- (void)after1{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"barrierSync---begin");
NSLog(@"begin---:%@",[NSDate date]);
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t) 2 * NSEC_PER_SEC ), dispatch_get_main_queue(), ^{
//2秒后追加任务到主队列开始执行
NSLog(@"after---:%@",[NSDate date]);
NSLog(@"after--%@" ,[NSThread currentThread]);//打印当前线程
});
}打印结果:
2021-05-04 15:35:31.358778+0800 demo[7379:7718375] currentThread---<NSThread: 0x60000170ce40>{number = 1, name = main}
2021-05-04 15:35:31.358855+0800 demo[7379:7718375] barrierSync---begin
2021-05-04 15:35:31.358934+0800 demo[7379:7718375] begin---:Tue May 4 15:35:31 2021
2021-05-04 15:35:31.360508+0800 demo[7379:7718375] 耗时begin---:2021-05-04 07:35:31 +0000
2021-05-04 15:35:35.362701+0800 demo[7379:7718375] 耗时end---:2021-05-04 07:35:35 +0000
2021-05-04 15:35:35.432347+0800 demo[7379:7718375] Metal API Validation Enabled
2021-05-04 15:35:35.501987+0800 demo[7379:7718375] after---:Tue May 4 15:35:35 2021
2021-05-04 15:35:35.502076+0800 demo[7379:7718375] after--<NSThread: 0x60000170ce40>{number = 1, name = main}结果分析:
begin—:Tue May 4 15:35:31 2021
耗时begin—:2021-05-04 07:35:31 +0000
耗时end—:2021-05-04 07:35:35 +0000
after—:Tue May 4 15:35:35 2021
从顺序上可以看出:
代码中是在2秒后追加任务到主队列,然后此时主队列中的耗时操作刚好执行到2秒,还剩2秒,所有当主队列中的4秒耗时操作的任务执行完时,才开始执行2秒前追到主队列中的任务,所有此时after—打印结果刚好是延迟4秒的结果
结论:dispatch_after是在指定时间之后将任务追加到主队列中的,并不是在指定时间后执行任务
4、GCD一次性代码:dispatch_once
经常用此方法来实现单利
//一次性代码(只执行一次)
- (void)once{
static dispatch_once_t once;
dispatch_once(&once, ^{
//只执行一次的代码
NSLog(@"只执行一次的代码");
});
}
5、GCD快速迭代方法:dispatch_apply
通常我们会用for循环遍历,但是GCD给我们提供了快速迭代的函数dispatch_ apply。dispatch_apply按照指定的次数将指定的任务追加到指定的队列中,并等待全部队列执行结束。如果是在串行队列中使用dispatch_apply, 那么就和for循环一样,按顺序同步执行。可这样就体现不出快速迭代的意义了。
我们可以利用并发队列进行异步执行。比如说遍历0~5这6个数字,for 循环的做法是每次取出一个元素,逐个遍历。dispatch_apply 可以在多个线程中同时(异步)遍历多个数字。
还有一点,无论是在串行队列,还是异步队列中,dispatch_apply 都会等待全部任务执行完毕,这点就像是同步操作,也像是队列组中的dispatch_group_wait方法。
- (void)apply{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"apply---begin");
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_apply(6, queue, ^(size_t index) {
NSLog(@"%zd -- %@" ,index ,[NSThread currentThread]);
});
NSLog(@"apply---end");
}打印结果:
2021-05-04 16:59:22.875336+0800 demo[7729:7756107] currentThread---<NSThread: 0x600001714dc0>{number = 1, name = main}
2021-05-04 16:59:22.875405+0800 demo[7729:7756107] apply---begin
2021-05-04 16:59:22.875500+0800 demo[7729:7756107] 2 -- <NSThread: 0x600001714dc0>{number = 1, name = main}
2021-05-04 16:59:22.875528+0800 demo[7729:7756442] 1 -- <NSThread: 0x600001754400>{number = 4, name = (null)}
2021-05-04 16:59:22.875528+0800 demo[7729:7756447] 3 -- <NSThread: 0x600001758a80>{number = 3, name = (null)}
2021-05-04 16:59:22.875534+0800 demo[7729:7756441] 0 -- <NSThread: 0x600001744080>{number = 2, name = (null)}
2021-05-04 16:59:22.875564+0800 demo[7729:7756449] 4 -- <NSThread: 0x600001748400>{number = 5, name = (null)}
2021-05-04 16:59:22.875606+0800 demo[7729:7756450] 5 -- <NSThread: 0x600001760fc0>{number = 6, name = (null)}
2021-05-04 16:59:22.875676+0800 demo[7729:7756107] apply---end
结果分析:
- 因为是在并发队列中异步执行任务,所以各个任务的执行时间长短不定,最后结束顺序也不定。
- 但是apply—end 一定在最后执行。这是因为dispatch_apply函数会等待全部任务执行完毕。
- 在多个线程中遍历打印
- 随着手机的多核,同样的for循环遍历,显然使用dispatch_apply执行效率会提高。
- 如果在dispatch_apply外再包一层异步任务,那么就和dispatch_group效果一样了。
6、GCD队列组:dispatch_group
有时候我们会有这样的需求:分别异步执行2个耗时任务,然后当2个耗时任务都执行完毕后再回到主线程执行任务。这时候我们可以用到GCD的队列组。
调用队列组的dispatch_group_async先把任务放到队列中,然后将队列放入队列组中。或者使用队列组的dispatch_group_enter、dispatch_group_leave组合来实现dispatch_ group_ async。
调用队列组的dispatch_group_notify回到指定线程执行任务。或者使用dispatch_group_wait回到当前线程继续向下执行(会阻塞当前线程)。
1、dispatch_group_notify
监听group中任务的完成状态,当所有的任务都执行完成后,追加任务到group 中,并执行任务。
//队列组:dispatch_group_notify
- (void)groupNotify{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"groupNotify---begin");
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
//等待任务1、2执行完后,回到主线程中执行任务3
//主线程追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
NSLog(@"groupNotify---end");
});
}打印结果:
2021-05-04 17:23:54.610572+0800 demo[7883:7772333] currentThread---<NSThread: 0x600001709000>{number = 1, name = main}
2021-05-04 17:23:54.610640+0800 demo[7883:7772333] groupNotify---begin
2021-05-04 17:23:54.635443+0800 demo[7883:7772333] Metal API Validation Enabled
2021-05-04 17:23:56.615585+0800 demo[7883:7772692] 2--<NSThread: 0x600001772c00>{number = 3, name = (null)}
2021-05-04 17:23:56.615584+0800 demo[7883:7772696] 1--<NSThread: 0x600001774f40>{number = 2, name = (null)}
2021-05-04 17:23:58.615805+0800 demo[7883:7772692] 2--<NSThread: 0x600001772c00>{number = 3, name = (null)}
2021-05-04 17:23:58.615824+0800 demo[7883:7772696] 1--<NSThread: 0x600001774f40>{number = 2, name = (null)}
2021-05-04 17:24:00.616600+0800 demo[7883:7772333] 3--<NSThread: 0x600001709000>{number = 1, name = main}
2021-05-04 17:24:02.616919+0800 demo[7883:7772333] 3--<NSThread: 0x600001709000>{number = 1, name = main}
2021-05-04 17:24:02.617066+0800 demo[7883:7772333] groupNotify---end结果分析(队列组dispatch_group_notify):
当所有任务都执行完成之后,才执行dispatch_group_notify的block中的任务。
2、dispatch_group_wait
暂停当前线程(阻塞当前线程),等待指定的group 中的任务执行完成后,才会往下继续执行。
//队列组:dispatch_group_wait
- (void)groupWait{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"groupWait---begin");
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
});
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
NSLog(@"groupWait---end");
}打印结果:
2021-05-04 17:29:10.742494+0800 demo[7931:7776937] currentThread---<NSThread: 0x60000170ce40>{number = 1, name = main}
2021-05-04 17:29:10.742576+0800 demo[7931:7776937] groupWait---begin
2021-05-04 17:29:12.746907+0800 demo[7931:7777277] 1--<NSThread: 0x6000017538c0>{number = 2, name = (null)}
2021-05-04 17:29:12.746923+0800 demo[7931:7777271] 2--<NSThread: 0x60000174d4c0>{number = 3, name = (null)}
2021-05-04 17:29:14.748485+0800 demo[7931:7777271] 2--<NSThread: 0x60000174d4c0>{number = 3, name = (null)}
2021-05-04 17:29:14.748485+0800 demo[7931:7777277] 1--<NSThread: 0x6000017538c0>{number = 2, name = (null)}
2021-05-04 17:29:14.748808+0800 demo[7931:7776937] groupWait---end结果分析(队列组dispatch_group_wait):
当所有任务执行完成之后,才执行dispatch_group_wait 之后的操作。但是使用dispatch_group_wait 会阻塞当前线程。
3、dispatch_group_enter、dispatch_group_leave
dispatch_group_enter 标志着一个任务追加到 group, 执行一次,相当于group中未执行完毕任务数+1;
dispatch_group_leave标志着一个任务离开了group, 执行一次,相当于group中未执行完毕任务数-1。
当group 中未执行完毕任务数为0的时候,才会使dispatch_group_wait解除阻塞,以及执行追加到dispatch_group_notify中的任务。
//队列组:dispatch_group_enter dispatch_group_leave
- (void)groupEnterAndLeave{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"groupWait---begin");
dispatch_group_t group = dispatch_group_create();
dispatch_group_enter(group);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
//追加任务1
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"1--%@" ,[NSThread currentThread]);//打印当前线程
}
dispatch_group_leave(group);
});
dispatch_group_enter(group);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
//追加任务2
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"2--%@" ,[NSThread currentThread]);//打印当前线程
}
dispatch_group_leave(group);
});
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
//等待任务1、2执行完后,回到主线程中执行任务3
//主线程追加任务3
for (int i = 0; i<2; i++) {
[NSThread sleepForTimeInterval:2]; //耗时
NSLog(@"3--%@" ,[NSThread currentThread]);//打印当前线程
}
NSLog(@"groupNotify---end");
});
// dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
// NSLog(@"groupWait---end");
}打印结果:
2021-05-04 17:38:09.330827+0800 demo[8012:7783864] currentThread---<NSThread: 0x60000170ce00>{number = 1, name = main}
2021-05-04 17:38:09.330916+0800 demo[8012:7783864] groupWait---begin
2021-05-04 17:38:09.367985+0800 demo[8012:7783864] Metal API Validation Enabled
2021-05-04 17:38:11.335041+0800 demo[8012:7784186] 1--<NSThread: 0x60000176c540>{number = 2, name = (null)}
2021-05-04 17:38:11.335040+0800 demo[8012:7784185] 2--<NSThread: 0x60000176ba40>{number = 3, name = (null)}
2021-05-04 17:38:13.340338+0800 demo[8012:7784185] 2--<NSThread: 0x60000176ba40>{number = 3, name = (null)}
2021-05-04 17:38:13.340338+0800 demo[8012:7784186] 1--<NSThread: 0x60000176c540>{number = 2, name = (null)}
2021-05-04 17:38:15.340748+0800 demo[8012:7783864] 3--<NSThread: 0x60000170ce00>{number = 1, name = main}
2021-05-04 17:38:17.342019+0800 demo[8012:7783864] 3--<NSThread: 0x60000170ce00>{number = 1, name = main}
2021-05-04 17:38:17.342190+0800 demo[8012:7783864] groupNotify---end结果分析:
- 当所有任务执行完成之后,才执行dispatch_group_notify 中的任务。这里的dispatch_group_enter、dispatch_group_leave组合,其实等同于dispatch_group_async。
- 有了dispatch_group_async为什么还需要dispatch_group_enter、dispatch_group_leave组合呢?
- 这是因为,实际的使用场景中,很大可能是一堆异步回调,并不是一个dispatch_group_async,比如AFN封装的网络请求,就是一个异步回调,并不是一个dispatch_group_async,要想实现网络请求的组合,就需要用到dispatch_group_enter、dispatch_group_leave;
7、GCD信号量:
GCD中的信号量是指Dispatch Semaphore,是持有计数的信号。类似于过高速路收费站的栏杆。可以通过时,打开栏杆,不可以通过时,关闭栏杆。在Dispatch Semaphore中,使用计数来完成这个功能,计数为0时等待,不可通过。计数为1或大于1时,计数减1且不等待,可通过。Dispatch Semaphore提供了三个函数。
- dispatch_semaphore_create: 创建一个Semaphore并初始化信号的总量
- dispatch_semaphore_signal: 发送一个信号, 让信号总量加1
- dispatch_semaphore_wait: 可以使总信号量减1,当信号总量为0时就会一直等待(阻塞所在线程),否则就可以正常执行。
注意:信号量的使用前提是:想清楚你需要处理哪个线程等待(阻塞), 又要哪个线程继续执行,然后使用信号量。
Dispatch Semaphore在实际开发中主要用于:
- 保持线程同步,将异步执行任务转换为同步执行任务
- 保证线程安全,为线程加锁
1、Dispatch Semaphore线程同步
我们在开发中,会遇到这样的需求:|异步执行耗时任务,并使用异步执行的结果进行一些额外的操作。换句话说,相当于,将异步执行任务转换为同步执行任务。
- (void)semaphoreSync{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"semaphoreSync---begin");
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
__block int number = 0;
dispatch_async(queue, ^{
//追加任务1
[NSThread sleepForTimeInterval:2];
NSLog(@"1---%@" ,[NSThread currentThread]);
number=100;
dispatch_semaphore_signal(semaphore);
});
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
NSLog(@"semaphoreSync---end ,number = %d" ,number);
}打印结果:
2021-05-04 20:25:50.925356+0800 demo[8657:7845011] currentThread---<NSThread: 0x600001708f00>{number = 1, name = main}
2021-05-04 20:25:50.925422+0800 demo[8657:7845011] semaphoreSync---begin
2021-05-04 20:25:52.928148+0800 demo[8657:7845353] 1---<NSThread: 0x600001755940>{number = 2, name = (null)}
2021-05-04 20:25:52.928336+0800 demo[8657:7845011] semaphoreSync---end ,number = 100结果分析:
semaphore—end是在执行完number = 100之后才打印的。而且输出结果number 为100。这是因为异步执行不会做任何等待,可以继续执行任务。异步执行将任务1追加到队列之后,不做等待,接着执行di spatch_ semaphore_ wait方法。此时semaphore == 0,当前线程进入等待状态。然后异步任务1开始执行。任务1执行到dispatch_semaphore_signal之后, 此时总信号量semaphore == 1,然后dispatch_semaphore_wait方法使总信号量减1,正在被阻塞的线程(主线程)恢复继续执行。最后打印
semaphoreSync—end ,number = 100
。 这样就实现了线程同步,将异步执行任务转换为同步执行任务。
2、Dispatch Semaphore线程安全和线程同步(为线程加锁)
- 1、什么是线程安全
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样
的,就是线程安全的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作(更改变量),一般都需要考虑线程同步,否则的话就可能影响线程安全。
- 2、什么是线程同步
可理解为线程A和线程B 一块配合,A执行到一定程度时要依靠线程B的某个结果,于是停下来,示意B运行; B依言执行,再将结果给A; A再继续操作。
举个简单例子就是:
两个人在一起聊天。两个人不能同时说话,避免听不清(操作冲突)。等一个人说完(一个线程结束操作),另一个再说(另一个线程再开始操作)。
下面,我们模拟火车票售卖的方式,实现NSThread线程安全和解决线程同步问题。
场景:总共有50张火车票,有两个售卖火车票的窗口,一个是北京火车票售卖窗口,另一个是西安火车票售卖窗口。两个窗口同时售卖火车票,卖完为止。
@interface ViewController(){
dispatch_semaphore_t semaphoreLock;
}
@property(assign ,nonatomic) NSInteger ticketCount;
@end//线程安全:使用semaphore枷锁
//初始化火车票数量、卖票窗口(线程安全)、并开始卖票
- (void)initTacket{
NSLog(@"currentThread---%@" , [NSThread currentThread]); //打印当前线程
NSLog(@"semaphore---begin");
semaphoreLock = dispatch_semaphore_create(1);
self.ticketCount = 50;
//queue1 北京售卖窗口 queue2西安售卖窗口
dispatch_queue_t queue1 = dispatch_queue_create("com.beijin.testQueue1", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue2 = dispatch_queue_create("com.xian.testQueue2", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue1, ^{
[self saleTacket];
});
dispatch_async(queue2, ^{
[self saleTacket];
});
}
- (void)saleTacket{
while (1) {
//相当于加锁
dispatch_semaphore_wait(semaphoreLock, DISPATCH_TIME_FOREVER);
if(self.ticketCount>0){//如果有票,继续售卖
self.ticketCount--;
NSLog(@"剩余票数:%ld,窗口:%@" ,(long)self.ticketCount ,[NSThread currentThread]);
[NSThread sleepForTimeInterval:2];
}else{//如果已售完,关闭售卖窗口
NSLog(@"所有火车票均已经售完");
//相当于解锁
dispatch_semaphore_signal(semaphoreLock);
break;
}
//相当于解锁
dispatch_semaphore_signal(semaphoreLock);
}
}
打印结果:
2021-05-04 21:02:19.678510+0800 demo[8863:7866145] currentThread---<NSThread: 0x600001705180>{number = 1, name = main}
2021-05-04 21:02:19.678580+0800 demo[8863:7866145] semaphore---begin
2021-05-04 21:02:19.678753+0800 demo[8863:7866484] 剩余票数:49,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:19.705312+0800 demo[8863:7866145] Metal API Validation Enabled
2021-05-04 21:02:21.681344+0800 demo[8863:7866480] 剩余票数:48,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:23.684746+0800 demo[8863:7866484] 剩余票数:47,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:25.688437+0800 demo[8863:7866480] 剩余票数:46,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:27.691144+0800 demo[8863:7866484] 剩余票数:45,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:29.693793+0800 demo[8863:7866480] 剩余票数:44,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:31.694281+0800 demo[8863:7866484] 剩余票数:43,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:33.694617+0800 demo[8863:7866480] 剩余票数:42,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:35.699981+0800 demo[8863:7866484] 剩余票数:41,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:37.704744+0800 demo[8863:7866480] 剩余票数:40,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:39.708801+0800 demo[8863:7866484] 剩余票数:39,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:41.713472+0800 demo[8863:7866480] 剩余票数:38,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:43.716771+0800 demo[8863:7866484] 剩余票数:37,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:45.721850+0800 demo[8863:7866480] 剩余票数:36,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:47.723082+0800 demo[8863:7866484] 剩余票数:35,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:49.723433+0800 demo[8863:7866480] 剩余票数:34,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:51.724468+0800 demo[8863:7866484] 剩余票数:33,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:53.724734+0800 demo[8863:7866480] 剩余票数:32,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:55.724944+0800 demo[8863:7866484] 剩余票数:31,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:02:57.726290+0800 demo[8863:7866480] 剩余票数:30,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:02:59.726500+0800 demo[8863:7866484] 剩余票数:29,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:01.727866+0800 demo[8863:7866480] 剩余票数:28,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:03.728177+0800 demo[8863:7866484] 剩余票数:27,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:05.733521+0800 demo[8863:7866480] 剩余票数:26,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:07.738426+0800 demo[8863:7866484] 剩余票数:25,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:09.738757+0800 demo[8863:7866480] 剩余票数:24,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:11.739391+0800 demo[8863:7866484] 剩余票数:23,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:13.741630+0800 demo[8863:7866480] 剩余票数:22,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:15.742803+0800 demo[8863:7866484] 剩余票数:21,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:17.743079+0800 demo[8863:7866480] 剩余票数:20,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:19.748496+0800 demo[8863:7866484] 剩余票数:19,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:31.748573+0800 demo[8863:7866480] 剩余票数:18,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:33.748988+0800 demo[8863:7866484] 剩余票数:17,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:35.749469+0800 demo[8863:7866480] 剩余票数:16,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:03:44.908523+0800 demo[8863:7866484] 剩余票数:15,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:03:55.109256+0800 demo[8863:7866480] 剩余票数:14,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:07.109335+0800 demo[8863:7866484] 剩余票数:13,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:04:17.868055+0800 demo[8863:7866480] 剩余票数:12,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:29.868121+0800 demo[8863:7866484] 剩余票数:11,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:04:38.937986+0800 demo[8863:7866480] 剩余票数:10,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:44.730980+0800 demo[8863:7866484] 剩余票数:9,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:04:46.731503+0800 demo[8863:7866480] 剩余票数:8,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:48.731708+0800 demo[8863:7866484] 剩余票数:7,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:04:50.731975+0800 demo[8863:7866480] 剩余票数:6,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:52.993830+0800 demo[8863:7866484] 剩余票数:5,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:04:54.994015+0800 demo[8863:7866480] 剩余票数:4,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:04:59.880925+0800 demo[8863:7866484] 剩余票数:3,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:05:07.810866+0800 demo[8863:7866480] 剩余票数:2,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:05:09.811191+0800 demo[8863:7866484] 剩余票数:1,窗口:<NSThread: 0x600001739880>{number = 2, name = (null)}
2021-05-04 21:05:11.812873+0800 demo[8863:7866480] 剩余票数:0,窗口:<NSThread: 0x60000176eb80>{number = 3, name = (null)}
2021-05-04 21:05:13.817595+0800 demo[8863:7866484] 所有火车票均已经售完
2021-05-04 21:05:13.817868+0800 demo[8863:7866480] 所有火车票均已经售完结果分析:
从打印结果上来看,2号窗口和3号窗口是交替出现的,实际上2号窗口和3号窗口是有可能不是交替售卖的。
从结果上看,是线程安全的。
七、GCD源码解读之基于UNIX的操作系统内核
要了解GCD源码,首先得了解UNIX的操作系统内核,这里我们只简单了解概念,不深究(可参考
https://www.freebsd.org
)
1、Darwin
接口的易用性是Mac OS X的基石,以UNIX为系统内核使Darwin具有极佳的稳定性、可靠性和性能。Darwin拥有许多技术:Mach 3.0、基于FreeBSD 5的操作系统服务环境、高性能的网络设施和多文件系统支持。Darwin具有模块化的特征,可动态添加和卸载驱动程序,还有良好的网络扩展性。
2、Mach
Mach是Darwin的中心。它提供了操作系统的许多重要功能,这些功能对应用程序而言是透明的。它处理CPU的使用和内存管理,系统调度,内存保护,实现了“以消息为中心”的架构,用于实现多进程信息传递。它为系统提供:
- 内存保护。一个进程如果意外的将数据写入系统的其它进程,会导致数据丢失或系统崩溃。Mach避免这种情况的发生,Mach让系统的一部分不会破坏其它的部分。
- 抢占式多任务。Mach监视CPU,调度任务(task)的运行,保证系统的高效率和资源利用。由系统决定一个任务的执行时间,而不是另一进程
- 虚拟内存。每个进程有自己的唯一的地址空间。32位应用程序有4GB的地址空间,64位应用程序有18EB的地址空间。Mach处理从任务中虚内存到物理内存的映射。在任意时刻,只有一部分虚内存实际驻留在物理内存中。物理内存在需要时被换入(page in)。Mach使用内存对象(memory objects)的概念让一个任务映射一部分内存,逆映射,并送入另一任务
- 实时支持。对时间敏感的应用程序保证低延迟。
Mach也支持合作多任务(cooperative multitasking),强占式线程(preemptive threading)和合作线程(cooperative threading)。
驱动程序支持
Darwin为驱动程序开发提供了面向对象的平台,I/O Kit。它简化了在Mac OS X上的驱动程序开发,提供了一套良好的架构。I/O Kit由C++的子集写成。用于支持一套驱动程序设备家族,并且它是可扩展的。它提供了:
- 即插即用(在设备插入时即可用)
- 动态设备管理(如设备如何处理突然断电的情况)
- 电源管理
I/O Kit提供了编写与标准不符或没有标准的设备的驱动程序所需的资源。这些设备包括AGP卡,PCI和PCIe卡,扫描仪等通常需要自定驱动的设备。如何创建驱动程序,请看I/O Kit 设备驱动程序设计指南。
3、BSD
BSD与Mach结合成为内核的核心部分,它提供:
- 进程模型(进程ID,信号。。)
- 基础的安全策略(文件权限设定和用户和组ID设定)
- 线程支持(POSIX线程)
- 网络支持(BSD套接字)
八、GCD源码解读之mach-o
Mach-O是一种文件格式,是mac上可执行文件的格式,我们编写的C、C++、swift、OC,最终编译链接生成Mach-O可执行文件。
1、mach-o文件类型分为(总共有11种):
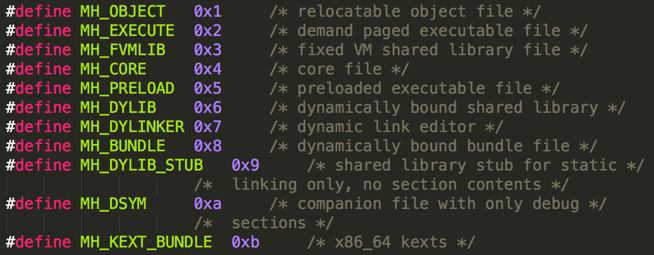
1、MH_OBJECT (0x1 )
- 目标文件(.0)
- 静态库文件(.a),静态库文件其实就是多个.o文件的合集.比如支持多种cpu建构的.a库文件.
2、MH_EXECUTE (0x2) 可执行文件
- 比如.app文件
3、MH_DYLIB 动态库文件
- .dylib文件
- .framework/xx文件
4、MH_DYLINKER (0x7) 动态链接编辑器
- usr/lib/dyld
5、MH_DYSM 符号文件
- dSYM/Content/Resources/DWARF/xx常用与app崩溃信息分析
2、Mach-O格式
Mach-O是一个以数据块分组的二进制字节流,这些数据块包含元信息,比如字节顺序、CPU类型、数据块大小等等。
典型的Mach-O文件包含三个区域:
-
Header
:保存Mach-O的一些基本信息,包括平台、文件类型、指令数、指令总大小,dyld标记Flags等等。 -
Load Commands
:紧跟Header,加载Mach-O文件时会使用这部分数据确定内存分布,对系统内核加载器和动态连接器起指导作用。 -
Data
:每个segment的具体数据保存在这里,包含具体的代码、数据等等。
用一张图表示Mach-O

3、执行流程:
说到可执行文件肯定离不开进程。在
Linux
中,我们会通过
Fork()
来新创建子进程,然后执行镜像通过
exec()
来替换为另一个可执行程序。
-
进程可以通过
fork()
系统调用来创建子进程,子进程得到与父进程地址空间相同的(但是独立的)一份拷贝,包括文本、数据和
bss
段、堆以及用户栈等,但是新线程只会复制调用
fork
的线程。所有父进程中别的线程,到了子进程中都是突然“蒸发”掉的。 -
我们在线程问题中经常会提到锁,每个锁都有一个持有者(最后一次
lock
它的线程)。为了性能,锁对象会因为
fork
复制到子进程中,但是子进程只复制调用
fork
的线程,很可能并不拥有锁持有者线程,那么就没有办法解开锁,导致死锁问题、内存泄漏 -
避免死锁的方法:在子线程中马上调用
exec
函数,一个进程一旦调用
exec
类函数,它本身就”死亡”了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。
综上所述,我们在用户态会通过
exec*
系列函数来加载一个可执行文件,同时
exec*
都只是对系统调用
execve
的封装,那我们加载
Mach-O
的流程,就从
execve
说起。
Mach-O
有多种文件类型,比如
MH_DYLIB
文件、
MH_BUNDLE
文件、
MH_EXECUTE
文件(这些需要
dyld
动态加载),
MH_OBJECT
(内核加载)等。所以一个进程往往不是只需要内核加载器就可以完成加载的,需要
dyld
来进行动态加载配合。如图:
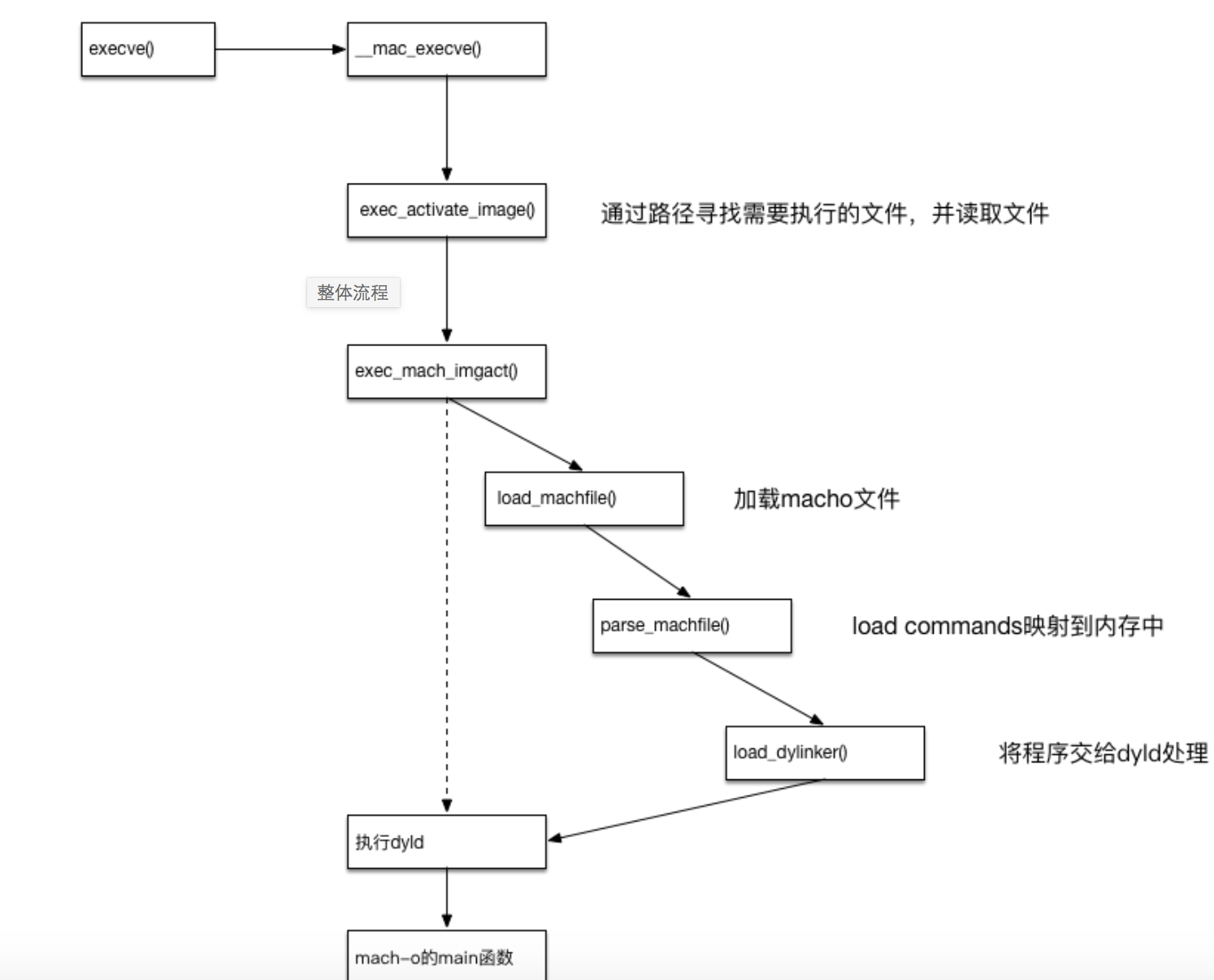
-
execve这个函数只是直接调用
__mac_execve()。
可下载源码解读:
Source Browser (apple.com)
-
__mac_execve():主要是为加载镜像进行数据的初始化,以及资源相关的操作,在其内部会执行
exec_activate_image()
,镜像加载的工作都是由它完成的 -
exec_activate_image:主要是用来对
Mach-O
做检测,会检测
Mach-O
头部,解析其架构、检查
imgp
等内容,并拒绝接受
Dylib
和
Bundle
这样的文件,这些文件会由
dyld
负责加载。然后把
Mach-O
映射到内存中去,调用
load_machfile()
-
load_machfile:
load_machfile
会加载
Mach-O
中的各种
load monmand
命令。在其内部会禁止数据段执行,防止溢出漏洞攻击,还会设置地址空间布局随机化(ASLR),还有一些映射的调整。真正负责对加载命令解析的是
parse_machfile()
-
parse_machfile
会根据
load_command
的种类选择不同的函数来加载,内部是一个
Switch
语句来实现的。常见的命令有
LC_SEGMENT_64
、
LC_LOAD_DYLINKER
、
LC_CODE_SIGNATURE
、
LC_UUID
等,更多命令可以查看
Mach-O
文件格式。对于命令的加载会进行多次扫描,当扫描三次之后,并且存在
dylinker_command
命令时,会执行
load_dylinker()
,启动动态链接器 (dyld) -
动态链接也有区分,一种是加载主程序(很多博客里这么写),是由
load commands
指定的
dylib
,以静态的方式存放在二进制文件里,一种是由
DYLD_INSERT_LIBRARIES
动态指定。下面这种就是提前指定在二进制文件中的动态库,下面的阐述主要是站在前者的角度,对于动态指定的后期再研究 -
内核会加载
dyld
并调用
dyld_start
方法,随后
dyld_start
会调用
_main()
,在_main函数中对数据进行一通初始化之后,就会调用
instantiateFromLoadedImage
函数初始化
ImageLoader
实例 -
instantiateFromLoadedImage:这个函数内的代码比较容易理解,检测
Mach-O
是否合法,合法的话就初始化
ImageLoader
实例,然后将其加入到一个全局的管理
ImageLoader
的数组中去
isCompatibleMachO
会对
Mach-O
头部的一些信息与当前平台进行比较,判断其合法性。
-
ImageLoader:是一个抽象基类,每一个动态加载的可执行文件都会初始化一个
ImageLoader
实例 -
instantiateMainExecutable:
ImageLoaderMachOCompressed
与
ImageLoaderMachOClassic
均继承于
ImageLoaderMachO
,
ImageLoaderMachO
继承于
ImageLoader。sniffLoadCommands
会对
Mach-O
是
classic
还是
compressed
的做一个判断。
instantiateMainExecutable
是对
ImageLoaderMachOCompressed
或
ImageLoaderMachOClassic
做初始化,并加载
load comond
命令
九、GCD源码解读之mach
Mach的独特之处在于选择了通过消息传递的方式实现对象与对象之间的通信。而其他架构一个对象要访问另一个对象需要通过一个大家都知道的接口,而Mach对象不能直接调用另一个对象,而是必须传递消息。
一条消息就像网络包一样,定义为
透明的blob(binary larger object
,二进制大对象),通过固定的包头进行分装
typedef struct
{
mach_msg_header_t header;
mach_msg_body_t body;
} mach_msg_base_t;
typedef struct
{
mach_msg_bits_t msgh_bits; // 消息头标志位
mach_msg_size_t msgh_size; // 大小
mach_port_t msgh_remote_port; // 目标(发消息)或源(接消息)
mach_port_t msgh_local_port; // 源(发消息)或目标(接消息)
mach_port_name_t msgh_voucher_port;
mach_msg_id_t msgh_id; // 唯一id
} mach_msg_header_t;
Mach消息的发送和接收都是通过同一个API
函数mach_msg
()进行的。这个函数在用户态和内核态都有实现。为了实现消息的发送和接收,
mach_msg()
函数调用了一个Mach陷阱(trap)。Mach陷阱就是Mach中和系统调用等同的概念。在用户态调用mach_msg_trap()会引发陷阱机制,切换到内核态,在内核态中,内核实现的
mach_msg()
会完成实际的工作。这个函数也将会在下面的源码分析中遇到。
每一个
BSD
进程都在底层关联一个
Mach
任务对象,因为
Mach
提供的都是非常底层的抽象,提供的API从设计上讲很基础且不完整,所以需要在这之上提供一个更高的层次以实现完整的功能。我们开发层遇到的进程和线程就是
BSD
层对
Mach
的任务和线程的复杂包装。
进程填充的是线程,而线程是二进制代码的实际执行单元。用户态的线程始于对
pthread_create
的调用。这个函数的又由
bsdthread_create
系统调用完成,而
bsdthread_create
又其实是
Mach
中的
thread_create
的复杂包装,说到底真正的线程创建还是有Mach层完成。
在
UNIX
中,进程不能被创建出来,都是通过fork()系统调用复制出来的。复制出来的进程都会被要加载的执行程序覆盖整个内存空间。
十、源码中常见的宏
1、__builtin_expect
这个其实是个函数,针对编译器优化的一个函数,后面几个宏是对这个函数的封装,所以提前拎出来说一下。写代码中我们经常会遇到条件判断语句
if(今天是工作日) {
printf("好好上班");
}else{
printf("好好睡觉");
}
CPU读取指令的时候并非一条一条的来读,而是多条一起加载进来,比如已经加载了if(今天是工作日) printf(“好好上班”);的指令,这时候条件式如果为非,也就是非工作日,那么CPU继续把printf(“好好睡觉”);这条指令加载进来,这样就造成了性能浪费的现象。
__builtin_expect
的第一个参数是实际值,第二个参数是预测值。使用这个目的是告诉编译器if条件式是不是有更大的可能被满足。
2、 likely和unlikely
解开这个宏后其实是对
__builtin_expec
t封装,likely表示更大可能成立,
unlikely
表示更大可能不成立。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)遇到这样的,if(likely(a == 0))理解成if(a==0)即可,unlikely也是同样的。
3、 fastpath和slowpath
跟上面也是差不多的,fastpath表示更大可能成立,
slowpath
表示更大可能不成立
#define fastpath(x) ((typeof(x))__builtin_expect(_safe_cast_to_long(x), ~0l))
#define slowpath(x) ((typeof(x))__builtin_expect(_safe_cast_to_long(x), 0l))这两个理解起来跟likely和unlikely一样,只需要关注里面的条件式是否满足即可。
4、 os_atomic_cmpxchg
其内部就是
atomic_compare_exchange_strong_explicit
函数,这个函数的作用是:第二个参数与第一个参数值比较,如果相等,第三个参数的值替换第一个参数的值。如果不相等,把第一个参数的值赋值到第二个参数上。
#define os_atomic_cmpxchg(p, e, v, m) \
({ _os_atomic_basetypeof(p) _r = (e); \
atomic_compare_exchange_strong_explicit(_os_atomic_c11_atomic(p), \
&_r, v, memory_order_##m, memory_order_relaxed); })
5、os_atomic_store2o
将第二个参数,保存到第一个参数
#define os_atomic_store2o(p, f, v, m) os_atomic_store(&(p)->f, (v), m)
#define os_atomic_store(p, v, m) \
atomic_store_explicit(_os_atomic_c11_atomic(p), v, memory_order_##m)
6、os_atomic_inc_orig
将1保存到第一个参数中
#define os_atomic_inc_orig(p, m) os_atomic_add_orig((p), 1, m)
#define os_atomic_add_orig(p, v, m) _os_atomic_c11_op_orig((p), (v), m, add, +)
#define _os_atomic_c11_op_orig(p, v, m, o, op) \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), v, \
memory_order_##m)
十一、常用数据结构体
1、dispatch_queue_t
typedef struct dispatch_queue_s *dispatch_queue_t;
我们看下dispatch_queue_s怎么定义的。发现其内部有个_DISPATCH_QUEUE_HEADER宏定义。
struct dispatch_queue_s {
_DISPATCH_QUEUE_HEADER(queue);
DISPATCH_QUEUE_CACHELINE_PADDING;
} DISPATCH_ATOMIC64_ALIGN;
解开_DISPATCH_QUEUE_HEADER后发现又一个DISPATCH_OBJECT_HEADER宏定义,继续拆解
#define _DISPATCH_QUEUE_HEADER(x) \
struct os_mpsc_queue_s _as_oq[0]; \
DISPATCH_OBJECT_HEADER(x); \
_OS_MPSC_QUEUE_FIELDS(dq, dq_state); \
uint32_t dq_side_suspend_cnt; \
dispatch_unfair_lock_s dq_sidelock; \
union { \
dispatch_queue_t dq_specific_q; \
struct dispatch_source_refs_s *ds_refs; \
struct dispatch_timer_source_refs_s *ds_timer_refs; \
struct dispatch_mach_recv_refs_s *dm_recv_refs; \
}; \
DISPATCH_UNION_LE(uint32_t volatile dq_atomic_flags, \
const uint16_t dq_width, \
const uint16_t __dq_opaque \
); \
DISPATCH_INTROSPECTION_QUEUE_HEADER
还有一层宏_DISPATCH_OBJECT_HEADER
#define DISPATCH_OBJECT_HEADER(x) \
struct dispatch_object_s _as_do[0]; \
_DISPATCH_OBJECT_HEADER(x)
不熟悉
##
的作用的同学,这里先说明下这个作用就拼接成字符串,比如x为
group
的话,下面就会拼接为
dispatch_group
这样的。
#define _DISPATCH_OBJECT_HEADER(x) \
struct _os_object_s _as_os_obj[0]; \
OS_OBJECT_STRUCT_HEADER(dispatch_##x); \
struct dispatch_##x##_s *volatile do_next; \
struct dispatch_queue_s *do_targetq; \
void *do_ctxt; \
void *do_finalizer来到OS_OBJECT_STRUCT_HEADER之后,我们需要注意一个成员变量,记住这个成员变量名字叫做do_vtable。再继续拆解_OS_OBJECT_HEADER发现里面起就是一个isa指针和引用计数一些信息。
#define OS_OBJECT_STRUCT_HEADER(x) \
_OS_OBJECT_HEADER(\
const void *_objc_isa, \
do_ref_cnt, \
do_xref_cnt); \
// 注意这个成员变量,后面将任务Push到队列就是通过这个变量
const struct x##_vtable_s *do_vtable
#define _OS_OBJECT_HEADER(isa, ref_cnt, xref_cnt) \
isa; /* must be pointer-sized */ \
int volatile ref_cnt; \
int volatile xref_cnt
复制代码
2、dispatch_continuation_t
说到这个结构体,如果没看过源码的话,肯定对这个结构体很陌生,因为对外的api里面没有跟continuation有关的。所以这里先说下这个结构体就是用来封装block对象的,保存block的上下文环境和block执行函数等。
typedef struct dispatch_continuation_s {
struct dispatch_object_s _as_do[0];
DISPATCH_CONTINUATION_HEADER(continuation);
} *dispatch_continuation_t;看下里面的宏:DISPATCH_CONTINUATION_HEADER
#define DISPATCH_CONTINUATION_HEADER(x) \
union { \
const void *do_vtable; \
uintptr_t dc_flags; \
}; \
union { \
pthread_priority_t dc_priority; \
int dc_cache_cnt; \
uintptr_t dc_pad; \
}; \
struct dispatch_##x##_s *volatile do_next; \
struct voucher_s *dc_voucher; \
dispatch_function_t dc_func; \
void *dc_ctxt; \
void *dc_data; \
void *dc_other
3、dispatch_object_t
typedef union {
struct _os_object_s *_os_obj;
struct dispatch_object_s *_do;
struct dispatch_continuation_s *_dc;
struct dispatch_queue_s *_dq;
struct dispatch_queue_attr_s *_dqa;
struct dispatch_group_s *_dg;
struct dispatch_source_s *_ds;
struct dispatch_mach_s *_dm;
struct dispatch_mach_msg_s *_dmsg;
struct dispatch_source_attr_s *_dsa;
struct dispatch_semaphore_s *_dsema;
struct dispatch_data_s *_ddata;
struct dispatch_io_s *_dchannel;
struct dispatch_operation_s *_doperation;
struct dispatch_disk_s *_ddisk;
} dispatch_object_t DISPATCH_TRANSPARENT_UNION;
4、dispatch_function_t
dispatch_function_t
只是一个函数指针
typedef void (*dispatch_function_t)(void *_Nullable);
十二、GCD相关的源码
1、dispatch_queue_create
先从创建队列开始。我们已经很熟悉,创建队列的方法是调用
dispatch_queue_create
函数。
dispatch_queue_create
DISPATCH_TARGET_QUEUE_DEFAULT这个宏其实就是null
dispatch_queue_t dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)
{ // attr一般我们都是传DISPATCH_QUEUE_SERIAL、DISPATCH_QUEUE_CONCURRENT或者nil
// 而DISPATCH_QUEUE_SERIAL其实就是null
return _dispatch_queue_create_with_target(label, attr,
DISPATCH_TARGET_QUEUE_DEFAULT, true);
}其内部又调用了_dispatch_queue_create_with_target函数
1、_dispatch_queue_create_with_target
创建一个
root
队列,并将自己新建的队列绑定到所对应的root队列上
static dispatch_queue_t _dispatch_queue_create_with_target(const char *label, dispatch_queue_attr_t dqa,
dispatch_queue_t tq, bool legacy)
{ // 根据上文代码注释里提到的,作者认为调用者传入DISPATCH_QUEUE_SERIAL和nil的几率要大于传DISPATCH_QUEUE_CONCURRENT。所以这里设置个默认值。
// 这里怎么理解呢?只要看做if(!dqa)即可
if (!slowpath(dqa)) {
// _dispatch_get_default_queue_attr里面会将dqa的dqa_autorelease_frequency指定为DISPATCH_AUTORELEASE_FREQUENCY_INHERIT的,inactive也指定为false。这里就不展开了,只需要知道赋了哪些值。因为后面会用到。
dqa = _dispatch_get_default_queue_attr();
} else if (dqa->do_vtable != DISPATCH_VTABLE(queue_attr)) {
DISPATCH_CLIENT_CRASH(dqa->do_vtable, "Invalid queue attribute");
}
// 取出优先级
dispatch_qos_t qos = _dispatch_priority_qos(dqa->dqa_qos_and_relpri);
// overcommit单纯从英文理解表示过量使用的意思,那这里这个overcommit就是一个标识符,表示是不是就算负荷很高了,但还是得给我新开一个线程出来给我执行任务。
_dispatch_queue_attr_overcommit_t overcommit = dqa->dqa_overcommit;
if (overcommit != _dispatch_queue_attr_overcommit_unspecified && tq) {
if (tq->do_targetq) {
DISPATCH_CLIENT_CRASH(tq, "Cannot specify both overcommit and "
"a non-global target queue");
}
}
// 如果overcommit没有被指定
if (overcommit == _dispatch_queue_attr_overcommit_unspecified) {
// 所以对于overcommit,如果是串行的话默认是开启的,而并行是关闭的
overcommit = dqa->dqa_concurrent ?
_dispatch_queue_attr_overcommit_disabled :
_dispatch_queue_attr_overcommit_enabled;
}
// 之前说过初始化队列默认传了DISPATCH_TARGET_QUEUE_DEFAULT,也就是null,所以进入if语句。
if (!tq) {
// 获取一个管理自己队列的root队列。
tq = _dispatch_get_root_queue(
qos == DISPATCH_QOS_UNSPECIFIED ? DISPATCH_QOS_DEFAULT : qos,
overcommit == _dispatch_queue_attr_overcommit_enabled);
if (slowpath(!tq)) {
DISPATCH_CLIENT_CRASH(qos, "Invalid queue attribute");
}
}
// legacy默认是true的
if (legacy) {
// 之前说过,默认是会给dqa_autorelease_frequency指定为DISPATCH_AUTORELEASE_FREQUENCY_INHERIT,所以这个判断式是成立的
if (dqa->dqa_inactive || dqa->dqa_autorelease_frequency) {
legacy = false;
}
}
// vtable变量很重要,之后会被赋值到之前说的dispatch_queue_t结构体里的do_vtable变量上
const void *vtable;
dispatch_queue_flags_t dqf = 0;
// legacy变为false了
if (legacy) {
vtable = DISPATCH_VTABLE(queue);
} else if (dqa->dqa_concurrent) {
// 如果创建队列的时候传了DISPATCH_QUEUE_CONCURRENT,就是走这里
vtable = DISPATCH_VTABLE(queue_concurrent);
} else {
// 如果创建线程没有指定为并行队列,无论你传DISPATCH_QUEUE_SERIAL还是nil,都会创建一个串行队列。
vtable = DISPATCH_VTABLE(queue_serial);
}
if (label) {
// 判断传进来的字符串是否可变的,如果可变的copy成一份不可变的
const char *tmp = _dispatch_strdup_if_mutable(label);
if (tmp != label) {
dqf |= DQF_LABEL_NEEDS_FREE;
label = tmp;
}
}
// _dispatch_object_alloc里面就将vtable赋值给do_vtable变量上了。
dispatch_queue_t dq = _dispatch_object_alloc(vtable,
sizeof(struct dispatch_queue_s) - DISPATCH_QUEUE_CACHELINE_PAD);
// 第三个参数根据是否并行队列,如果不是则最多开一个线程,如果是则最多开0x1000 - 2个线程,这个数量很惊人了已经,换成十进制就是(4096 - 2)个。
// dqa_inactive之前说串行是false的
// DISPATCH_QUEUE_ROLE_INNER 也是0,所以这里串行队列的话dqa->dqa_state是0
_dispatch_queue_init(dq, dqf, dqa->dqa_concurrent ?
DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |
(dqa->dqa_inactive ? DISPATCH_QUEUE_INACTIVE : 0));
dq->dq_label = label;
#if HAVE_PTHREAD_WORKQUEUE_QOS
dq->dq_priority = dqa->dqa_qos_and_relpri;
if (overcommit == _dispatch_queue_attr_overcommit_enabled) {
dq->dq_priority |= DISPATCH_PRIORITY_FLAG_OVERCOMMIT;
}
#endif
_dispatch_retain(tq);
if (qos == QOS_CLASS_UNSPECIFIED) {
_dispatch_queue_priority_inherit_from_target(dq, tq);
}
if (!dqa->dqa_inactive) {
_dispatch_queue_inherit_wlh_from_target(dq, tq);
}
// 自定义的queue的目标队列是root队列
dq->do_targetq = tq;
_dispatch_object_debug(dq, "%s", __func__);
return _dispatch_introspection_queue_create(dq);
}
这个函数里面还是有几个重要的地方拆出来看下,首先是创建一个
root
队列
_dispatch_get_root_queue
函数。
2、
_dispatch_get_root_queue
函数
_dispatch_get_root_queue
取
root
队列,一般是从一个装有12个
root
队列数组里面取。
static inline dispatch_queue_t
_dispatch_get_root_queue(dispatch_qos_t qos, bool overcommit)
{
if (unlikely(qos == DISPATCH_QOS_UNSPECIFIED || qos > DISPATCH_QOS_MAX)) {
DISPATCH_CLIENT_CRASH(qos, "Corrupted priority");
}
return &_dispatch_root_queues[2 * (qos - 1) + overcommit];
}
3、
_dispatch_root_queues
数组
_dispatch_root_queues
struct dispatch_queue_s _dispatch_root_queues[] = {
#define _DISPATCH_ROOT_QUEUE_IDX(n, flags) \
((flags & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) ? \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS_OVERCOMMIT : \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS)
#define _DISPATCH_ROOT_QUEUE_ENTRY(n, flags, ...) \
[_DISPATCH_ROOT_QUEUE_IDX(n, flags)] = { \
DISPATCH_GLOBAL_OBJECT_HEADER(queue_root), \
.dq_state = DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE, \
.do_ctxt = &_dispatch_root_queue_contexts[ \
_DISPATCH_ROOT_QUEUE_IDX(n, flags)], \
.dq_atomic_flags = DQF_WIDTH(DISPATCH_QUEUE_WIDTH_POOL), \
.dq_priority = _dispatch_priority_make(DISPATCH_QOS_##n, 0) | flags | \
DISPATCH_PRIORITY_FLAG_ROOTQUEUE | \
((flags & DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE) ? 0 : \
DISPATCH_QOS_##n << DISPATCH_PRIORITY_OVERRIDE_SHIFT), \
__VA_ARGS__ \
}
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, 0,
.dq_label = "com.apple.root.maintenance-qos",
.dq_serialnum = 4,
),
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.maintenance-qos.overcommit",
.dq_serialnum = 5,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, 0,
.dq_label = "com.apple.root.background-qos",
.dq_serialnum = 6,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.background-qos.overcommit",
.dq_serialnum = 7,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, 0,
.dq_label = "com.apple.root.utility-qos",
.dq_serialnum = 8,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.utility-qos.overcommit",
.dq_serialnum = 9,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT, DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE,
.dq_label = "com.apple.root.default-qos",
.dq_serialnum = 10,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT,
DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE | DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.default-qos.overcommit",
.dq_serialnum = 11,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, 0,
.dq_label = "com.apple.root.user-initiated-qos",
.dq_serialnum = 12,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-initiated-qos.overcommit",
.dq_serialnum = 13,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, 0,
.dq_label = "com.apple.root.user-interactive-qos",
.dq_serialnum = 14,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-interactive-qos.overcommit",
.dq_serialnum = 15,
),
};
我们可以看到,每一个优先级都有对应的
root
队列,每一个优先级又分为是不是可以过载的队列。
struct dispatch_queue_s _dispatch_root_queues[] = {
#define _DISPATCH_ROOT_QUEUE_IDX(n, flags) \
((flags & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) ? \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS_OVERCOMMIT : \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS)
#define _DISPATCH_ROOT_QUEUE_ENTRY(n, flags, ...) \
[_DISPATCH_ROOT_QUEUE_IDX(n, flags)] = { \
DISPATCH_GLOBAL_OBJECT_HEADER(queue_root), \
.dq_state = DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE, \
.do_ctxt = &_dispatch_root_queue_contexts[ \
_DISPATCH_ROOT_QUEUE_IDX(n, flags)], \
.dq_atomic_flags = DQF_WIDTH(DISPATCH_QUEUE_WIDTH_POOL), \
.dq_priority = _dispatch_priority_make(DISPATCH_QOS_##n, 0) | flags | \
DISPATCH_PRIORITY_FLAG_ROOTQUEUE | \
((flags & DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE) ? 0 : \
DISPATCH_QOS_##n << DISPATCH_PRIORITY_OVERRIDE_SHIFT), \
__VA_ARGS__ \
}
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, 0,
.dq_label = "com.apple.root.maintenance-qos",
.dq_serialnum = 4,
),
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.maintenance-qos.overcommit",
.dq_serialnum = 5,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, 0,
.dq_label = "com.apple.root.background-qos",
.dq_serialnum = 6,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.background-qos.overcommit",
.dq_serialnum = 7,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, 0,
.dq_label = "com.apple.root.utility-qos",
.dq_serialnum = 8,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.utility-qos.overcommit",
.dq_serialnum = 9,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT, DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE,
.dq_label = "com.apple.root.default-qos",
.dq_serialnum = 10,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT,
DISPATCH_PRIORITY_FLAG_DEFAULTQUEUE | DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.default-qos.overcommit",
.dq_serialnum = 11,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, 0,
.dq_label = "com.apple.root.user-initiated-qos",
.dq_serialnum = 12,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-initiated-qos.overcommit",
.dq_serialnum = 13,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, 0,
.dq_label = "com.apple.root.user-interactive-qos",
.dq_serialnum = 14,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-interactive-qos.overcommit",
.dq_serialnum = 15,
),
};
4、
DISPATCH_GLOBAL_OBJECT_HEADER
DISPATCH_GLOBAL_OBJECT_HEADER(queue_root)
,解析到最后是
OSdispatch
##name##_class这样的这样的,对应的实例对象是如下代码,指定了
root
队列各个操作对应的函数。
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_root, queue,
.do_type = DISPATCH_QUEUE_GLOBAL_ROOT_TYPE,
.do_kind = "global-queue",
.do_dispose = _dispatch_pthread_root_queue_dispose,
.do_push = _dispatch_root_queue_push,
.do_invoke = NULL,
.do_wakeup = _dispatch_root_queue_wakeup,
.do_debug = dispatch_queue_debug,
);
其次看下
DISPATCH_VTABLE
这个宏,这个宏很重要。最后解封也是
&OSdispatch##name##_class
这样的。其实就是取
dispatch_object_t
对象。 如下代码,这里再举个
VTABLE
的串行对象,里面有各个状态该执行的函数:销毁函、挂起、恢复、push等函数都是在这里指定的。所以这里的
do_push
我们需要特别留意,后面
push block
任务到队列,就是通过调用
do_push
。
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_serial, queue,
.do_type = DISPATCH_QUEUE_SERIAL_TYPE,
.do_kind = "serial-queue",
.do_dispose = _dispatch_queue_dispose,
.do_suspend = _dispatch_queue_suspend,
.do_resume = _dispatch_queue_resume,
.do_finalize_activation = _dispatch_queue_finalize_activation,
.do_push = _dispatch_queue_push,
.do_invoke = _dispatch_queue_invoke,
.do_wakeup = _dispatch_queue_wakeup,
.do_debug = dispatch_queue_debug,
.do_set_targetq = _dispatch_queue_set_target_queue,
);
继续看下_dispatch_object_alloc和_dispatch_queue_init两个函数,首先看下_dispatch_object_alloc函数
void * _dispatch_object_alloc(const void *vtable, size_t size)
{
// OS_OBJECT_HAVE_OBJC1为1的满足式是:
// #if TARGET_OS_MAC && !TARGET_OS_SIMULATOR && defined(__i386__)
// 所以对于iOS并不满足
#if OS_OBJECT_HAVE_OBJC1
const struct dispatch_object_vtable_s *_vtable = vtable;
dispatch_object_t dou;
dou._os_obj = _os_object_alloc_realized(_vtable->_os_obj_objc_isa, size);
dou._do->do_vtable = vtable;
return dou._do;
#else
return _os_object_alloc_realized(vtable, size);
#endif
}
inline _os_object_t _os_object_alloc_realized(const void *cls, size_t size)
{
_os_object_t obj;
dispatch_assert(size >= sizeof(struct _os_object_s));
while (!fastpath(obj = calloc(1u, size))) {
_dispatch_temporary_resource_shortage();
}
obj->os_obj_isa = cls;
return obj;
}
void _dispatch_temporary_resource_shortage(void)
{
sleep(1);
asm(""); // prevent tailcall
}
再看下_dispatch_queue_init函数,这里也就是做些初始化工作了
static inline void _dispatch_queue_init(dispatch_queue_t dq, dispatch_queue_flags_t dqf,
uint16_t width, uint64_t initial_state_bits)
{
uint64_t dq_state = DISPATCH_QUEUE_STATE_INIT_VALUE(width);
dispatch_assert((initial_state_bits & ~(DISPATCH_QUEUE_ROLE_MASK |
DISPATCH_QUEUE_INACTIVE)) == 0);
if (initial_state_bits & DISPATCH_QUEUE_INACTIVE) {
dq_state |= DISPATCH_QUEUE_INACTIVE + DISPATCH_QUEUE_NEEDS_ACTIVATION;
dq_state |= DLOCK_OWNER_MASK;
dq->do_ref_cnt += 2;
}
dq_state |= (initial_state_bits & DISPATCH_QUEUE_ROLE_MASK);
// 指向DISPATCH_OBJECT_LISTLESS是优化编译器的作用。只是为了生成更好的指令让CPU更好的编码
dq->do_next = (struct dispatch_queue_s *)DISPATCH_OBJECT_LISTLESS;
dqf |= DQF_WIDTH(width);
// dqf 保存进 dq->dq_atomic_flags
os_atomic_store2o(dq, dq_atomic_flags, dqf, relaxed);
dq->dq_state = dq_state;
dq->dq_serialnum =
os_atomic_inc_orig(&_dispatch_queue_serial_numbers, relaxed);
}
最后是_dispatch_introspection_queue_create函数,一个内省函数。
dispatch_queue_t _dispatch_introspection_queue_create(dispatch_queue_t dq)
{
TAILQ_INIT(&dq->diq_order_top_head);
TAILQ_INIT(&dq->diq_order_bottom_head);
_dispatch_unfair_lock_lock(&_dispatch_introspection.queues_lock);
TAILQ_INSERT_TAIL(&_dispatch_introspection.queues, dq, diq_list);
_dispatch_unfair_lock_unlock(&_dispatch_introspection.queues_lock);
DISPATCH_INTROSPECTION_INTERPOSABLE_HOOK_CALLOUT(queue_create, dq);
if (DISPATCH_INTROSPECTION_HOOK_ENABLED(queue_create)) {
_dispatch_introspection_queue_create_hook(dq);
}
return dq;
}至此,一个队列的创建过程我们大致了解了。
5、队列的创建过程大致可以分为以下几点
- 设置队列优先级
- 默认创建的是一个串行队列
- 设置队列挂载的根队列。优先级不同根队列也不同
- 实例化vtable对象,这个对象给不同队列指定了push、wakeup等函数。
2、dispatch_sync
dispatch_sync
直接调用的是
dispatch_sync_f
void dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
// 很大可能不会走if分支,看做if(_dispatch_block_has_private_data(work))
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_private_data(dq, work, 0);
}
dispatch_sync_f(dq, work, _dispatch_Block_invoke(work));
}
void dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func)
{
// 串行队列会走到这个if分支
if (likely(dq->dq_width == 1)) {
return dispatch_barrier_sync_f(dq, ctxt, func);
}
// 全局获取的并行队列或者绑定的是非调度线程的队列会走进这个if分支
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dq))) {
return _dispatch_sync_f_slow(dq, ctxt, func, 0);
}
_dispatch_introspection_sync_begin(dq);
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dq, ctxt, func, 0);
}
// 自定义并行队列会来到这个函数
_dispatch_sync_invoke_and_complete(dq, ctxt, func);
}
1、串行队列
void dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_tid tid = _dispatch_tid_self();
// 队列绑定的是非调度线程就会走这里
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dq, tid))) {
return _dispatch_sync_f_slow(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT);
}
_dispatch_introspection_sync_begin(dq);
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT);
}
// 一般会走到这里
_dispatch_queue_barrier_sync_invoke_and_complete(dq, ctxt, func);
}
static void _dispatch_queue_barrier_sync_invoke_and_complete(dispatch_queue_t dq,
void *ctxt, dispatch_function_t func)
{
// 首先会执行这个函数
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
// 如果后面还有别的任务
if (unlikely(dq->dq_items_tail || dq->dq_width > 1)) {
// 内部其实就是唤醒队列
return _dispatch_queue_barrier_complete(dq, 0, 0);
}
const uint64_t fail_unlock_mask = DISPATCH_QUEUE_SUSPEND_BITS_MASK |
DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_DIRTY |
DISPATCH_QUEUE_RECEIVED_OVERRIDE | DISPATCH_QUEUE_SYNC_TRANSFER |
DISPATCH_QUEUE_RECEIVED_SYNC_WAIT;
uint64_t old_state, new_state;
// 原子锁。检查dq->dq_state与old_state是否相等,如果相等把new_state赋值给dq->dq_state,如果不相等,把dq_state赋值给old_state。
// 串行队列走到这里,dq->dq_state与old_state是相等的,会把new_state也就是闭包里的赋值的值给dq->dq_state
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = old_state - DISPATCH_QUEUE_SERIAL_DRAIN_OWNED;
new_state &= ~DISPATCH_QUEUE_DRAIN_UNLOCK_MASK;
new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK;
if (unlikely(old_state & fail_unlock_mask)) {
os_atomic_rmw_loop_give_up({
return _dispatch_queue_barrier_complete(dq, 0, 0);
});
}
});
if (_dq_state_is_base_wlh(old_state)) {
_dispatch_event_loop_assert_not_owned((dispatch_wlh_t)dq);
}
}
static inline void _dispatch_sync_function_invoke_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
// 保护现场 -> 调用函数 -> 恢复现场
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq);
_dispatch_client_callout(ctxt, func);
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
然后另一种情况,自定义并行队列会走_dispatch_sync_invoke_and_complete函数。
static void _dispatch_sync_invoke_and_complete(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
// 将自定义队列加入到root队列里去
// dispatch_async也会调用此方法,之前我们初始化的时候会绑定一个root队列,这里就将我们新建的队列交给root队列进行管理
_dispatch_queue_non_barrier_complete(dq);
}
static inline void _dispatch_sync_function_invoke_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq);
// 执行任务
_dispatch_client_callout(ctxt, func);
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
## dispatch_async
内部就是两个函数_dispatch_continuation_init和_dispatch_continuation_async
void dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
// 设置标识位
uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT;
_dispatch_continuation_init(dc, dq, work, 0, 0, dc_flags);
_dispatch_continuation_async(dq, dc);
}
_dispatch_continuation_init函数只是一个初始化,主要就是保存Block上下文,指定block的执行函数
static inline void _dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
pthread_priority_t pp, dispatch_block_flags_t flags, uintptr_t dc_flags)
{
dc->dc_flags = dc_flags | DISPATCH_OBJ_BLOCK_BIT;
// block对象赋值到dc_ctxt
dc->dc_ctxt = _dispatch_Block_copy(work);
// 设置默认任务优先级
_dispatch_continuation_priority_set(dc, pp, flags);
// 大多数情况不会走这个分支
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
// 这个标识位多眼熟,就是前面入口赋值的,没的跑了,指定执行函数就是_dispatch_call_block_and_release了
if (dc_flags & DISPATCH_OBJ_CONSUME_BIT) {
dc->dc_func = _dispatch_call_block_and_release;
} else {
dc->dc_func = _dispatch_Block_invoke(work);
}
_dispatch_continuation_voucher_set(dc, dqu, flags);
}
_dispatch_call_block_and_release这个函数就是直接执行block了,所以dc->dc_func被调用的话就block会被直接执行了。
void _dispatch_call_block_and_release(void *block)
{
void (^b)(void) = block;
b();
Block_release(b);
}
上面的初始化过程就是这样,接着看下_dispatch_continuation_async函数
void _dispatch_continuation_async(dispatch_queue_t dq, dispatch_continuation_t dc)
{
// 看看是不是barrier类型的block
_dispatch_continuation_async2(dq, dc,
dc->dc_flags & DISPATCH_OBJ_BARRIER_BIT);
}
static inline void _dispatch_continuation_async2(dispatch_queue_t dq, dispatch_continuation_t dc,
bool barrier)
{
// 如果是用barrier插进来的任务或者是串行队列,直接将任务加入到队列
// #define DISPATCH_QUEUE_USES_REDIRECTION(width) \
// ({ uint16_t _width = (width); \
// _width > 1 && _width < DISPATCH_QUEUE_WIDTH_POOL; })
if (fastpath(barrier || !DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width))) {
return _dispatch_continuation_push(dq, dc);
}
return _dispatch_async_f2(dq, dc);
}
// 可以先看下如果是barrier任务,直接调用_dispatch_continuation_push函数
static void _dispatch_continuation_push(dispatch_queue_t dq, dispatch_continuation_t dc)
{
dx_push(dq, dc, _dispatch_continuation_override_qos(dq, dc));
}
// _dispatch_continuation_async2函数里面调用_dispatch_async_f2函数
static void
_dispatch_async_f2(dispatch_queue_t dq, dispatch_continuation_t dc)
{
// 如果还有任务,slowpath表示很大可能队尾是没有任务的。
// 实际开发中也的确如此,一般情况下我们不会dispatch_async之后又马上跟着一个dispatch_async
if (slowpath(dq->dq_items_tail)) {
return _dispatch_continuation_push(dq, dc);
}
if (slowpath(!_dispatch_queue_try_acquire_async(dq))) {
return _dispatch_continuation_push(dq, dc);
}
// 一般会直接来到这里,_dispatch_continuation_override_qos函数里面主要做的是判断dq有没有设置的优先级,如果没有就用block对象的优先级,如果有就用自己的
return _dispatch_async_f_redirect(dq, dc,
_dispatch_continuation_override_qos(dq, dc));
}
static void _dispatch_async_f_redirect(dispatch_queue_t dq,
dispatch_object_t dou, dispatch_qos_t qos)
{
// 这里会走进if的语句,因为_dispatch_object_is_redirection内部的dx_type(dou._do) == type条件为否
if (!slowpath(_dispatch_object_is_redirection(dou))) {
dou._dc = _dispatch_async_redirect_wrap(dq, dou);
}
// dq换成所绑定的root队列
dq = dq->do_targetq;
// 基本不会走里面的循环,主要做的就是找到根root队列
while (slowpath(DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width))) {
if (!fastpath(_dispatch_queue_try_acquire_async(dq))) {
break;
}
if (!dou._dc->dc_ctxt) {
dou._dc->dc_ctxt = (void *)
(uintptr_t)_dispatch_queue_autorelease_frequency(dq);
}
dq = dq->do_targetq;
}
// 把装有block信息的结构体装进所在队列对应的root_queue里面
dx_push(dq, dou, qos);
}
// dx_push是个宏定义,这里做的就是将任务push到任务队列,我们看到这里,就知道dx_push就是调用对象的do_push。
#define dx_push(x, y, z) dx_vtable(x)->do_push(x, y, z)
#define dx_vtable(x) (&(x)->do_vtable->_os_obj_vtable)
_dispatch_async_f_redirect函数里先看这句dou._dc = _dispatch_async_redirect_wrap(dq, dou);
static inline dispatch_continuation_t _dispatch_async_redirect_wrap(dispatch_queue_t dq, dispatch_object_t dou)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
dou._do->do_next = NULL;
// 所以dispatch_async推进的任务的do_vtable成员变量是有值的
dc->do_vtable = DC_VTABLE(ASYNC_REDIRECT);
dc->dc_func = NULL;
dc->dc_ctxt = (void *)(uintptr_t)_dispatch_queue_autorelease_frequency(dq);
// 所属队列被装进dou._dc->dc_data里面了
dc->dc_data = dq;
dc->dc_other = dou._do;
dc->dc_voucher = DISPATCH_NO_VOUCHER;
dc->dc_priority = DISPATCH_NO_PRIORITY;
_dispatch_retain(dq); // released in _dispatch_async_redirect_invoke
return dc;
}
// dc->do_vtable = DC_VTABLE(ASYNC_REDIRECT); 就是下面指定redirect的invoke函数是_dispatch_async_redirect_invoke,后面任务被执行就是通过这个函数
const struct dispatch_continuation_vtable_s _dispatch_continuation_vtables[] = {
DC_VTABLE_ENTRY(ASYNC_REDIRECT,
.do_kind = "dc-redirect",
.do_invoke = _dispatch_async_redirect_invoke),
#if HAVE_MACH
DC_VTABLE_ENTRY(MACH_SEND_BARRRIER_DRAIN,
.do_kind = "dc-mach-send-drain",
.do_invoke = _dispatch_mach_send_barrier_drain_invoke),
DC_VTABLE_ENTRY(MACH_SEND_BARRIER,
.do_kind = "dc-mach-send-barrier",
.do_invoke = _dispatch_mach_barrier_invoke),
DC_VTABLE_ENTRY(MACH_RECV_BARRIER,
.do_kind = "dc-mach-recv-barrier",
.do_invoke = _dispatch_mach_barrier_invoke),
DC_VTABLE_ENTRY(MACH_ASYNC_REPLY,
.do_kind = "dc-mach-async-reply",
.do_invoke = _dispatch_mach_msg_async_reply_invoke),
#endif
#if HAVE_PTHREAD_WORKQUEUE_QOS
DC_VTABLE_ENTRY(OVERRIDE_STEALING,
.do_kind = "dc-override-stealing",
.do_invoke = _dispatch_queue_override_invoke),
// 留意这个,后面也会被用到
DC_VTABLE_ENTRY(OVERRIDE_OWNING,
.do_kind = "dc-override-owning",
.do_invoke = _dispatch_queue_override_invoke),
#endif
};
再看dx_push(dq, dou, qos);这句,其实就是调用_dispatch_root_queue_push函数
void _dispatch_root_queue_push(dispatch_queue_t rq, dispatch_object_t dou,
dispatch_qos_t qos)
{
// 一般情况下,无论自定义还是非自定义都会走进这个条件式(比如:dispatch_get_global_queue)
// 里面主要对比的是qos与root队列的qos是否一致。基本上都不一致的,如果不一致走进这个if语句
if (_dispatch_root_queue_push_needs_override(rq, qos)) {
return _dispatch_root_queue_push_override(rq, dou, qos);
}
_dispatch_root_queue_push_inline(rq, dou, dou, 1);
}
static void _dispatch_root_queue_push_override(dispatch_queue_t orig_rq,
dispatch_object_t dou, dispatch_qos_t qos)
{
bool overcommit = orig_rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;
dispatch_queue_t rq = _dispatch_get_root_queue(qos, overcommit);
dispatch_continuation_t dc = dou._dc;
// 这个_dispatch_object_is_redirection函数其实就是return _dispatch_object_has_type(dou,DISPATCH_CONTINUATION_TYPE(ASYNC_REDIRECT));
// 所以自定义队列会走这个if语句,如果是dispatch_get_global_queue不会走if语句
if (_dispatch_object_is_redirection(dc)) {
dc->dc_func = (void *)orig_rq;
} else {
// dispatch_get_global_queue来到这里
dc = _dispatch_continuation_alloc();
// 相当于是下面的,也就是指定了执行函数为_dispatch_queue_override_invoke,所以有别于自定义队列的invoke函数。
// DC_VTABLE_ENTRY(OVERRIDE_OWNING,
// .do_kind = "dc-override-owning",
// .do_invoke = _dispatch_queue_override_invoke),
dc->do_vtable = DC_VTABLE(OVERRIDE_OWNING);
_dispatch_trace_continuation_push(orig_rq, dou);
dc->dc_ctxt = dc;
dc->dc_other = orig_rq;
dc->dc_data = dou._do;
dc->dc_priority = DISPATCH_NO_PRIORITY;
dc->dc_voucher = DISPATCH_NO_VOUCHER;
}
_dispatch_root_queue_push_inline(rq, dc, dc, 1);
}
static inline void _dispatch_root_queue_push_inline(dispatch_queue_t dq, dispatch_object_t _head,
dispatch_object_t _tail, int n)
{
struct dispatch_object_s *head = _head._do, *tail = _tail._do;
// 把任务装进队列,大多数不走进if语句。但是第一个任务进来之前还是满足这个条件式的,会进入这个条件语句去激活队列来执行里面的任务,后面再加入的任务因为队列被激活了,所以也就不太需要再进入这个队列了,所以相对来说激活队列只要一次,所以作者认为大多数情况下不需要走进这个条件语句
if (unlikely(_dispatch_queue_push_update_tail_list(dq, head, tail))) {
// 保存队列头
_dispatch_queue_push_update_head(dq, head);
return _dispatch_global_queue_poke(dq, n, 0);
}
}
我们可以看到,我们装入到自定义的任务都被扔到其挂靠的
root
队列里去了,所以我们我们自己创建的队列只是一个代理人身份,真正的管理人是其对应的
root
队列,但同时这个队列也是被管理的
2、
_dispatch_global_queue_poke
函数
_dispatch_global_queue_poke
void
_dispatch_global_queue_poke(dispatch_queue_t dq, int n, int floor)
{
return _dispatch_global_queue_poke_slow(dq, n, floor);
}
继续看_dispatch_global_queue_poke函数调用了_dispatch_global_queue_poke_slow函数,这里也很关键了,里面执行_pthread_workqueue_addthreads函数,把任务交给内核分发处理
_dispatch_global_queue_poke_slow(dispatch_queue_t dq, int n, int floor)
{
dispatch_root_queue_context_t qc = dq->do_ctxt;
int remaining = n;
int r = ENOSYS;
_dispatch_root_queues_init();
_dispatch_debug_root_queue(dq, __func__);
if (qc->dgq_kworkqueue != (void*)(~0ul))
{
r = _pthread_workqueue_addthreads(remaining,
_dispatch_priority_to_pp(dq->dq_priority));
(void)dispatch_assume_zero(r);
return;
}
}
int
_pthread_workqueue_addthreads(int numthreads, pthread_priority_t priority)
{
int res = 0;
if (__libdispatch_workerfunction == NULL) {
return EPERM;
}
if ((__pthread_supported_features & PTHREAD_FEATURE_FINEPRIO) == 0) {
return ENOTSUP;
}
res = __workq_kernreturn(WQOPS_QUEUE_REQTHREADS, NULL, numthreads, (int)priority);
if (res == -1) {
res = errno;
}
return res;
}那么,加入到根队列的任务是怎么被运行起来的?在此之前,我们先模拟一下在GCD内部把程序搞挂掉,这样我们就可以追溯下调用栈关系。
(
0 CoreFoundation 0x00000001093fe12b __exceptionPreprocess + 171
1 libobjc.A.dylib 0x0000000108a92f41 objc_exception_throw + 48
2 CoreFoundation 0x000000010943e0cc _CFThrowFormattedException + 194
3 CoreFoundation 0x000000010930c23d -[__NSPlaceholderArray initWithObjects:count:] + 237
4 CoreFoundation 0x0000000109312e34 +[NSArray arrayWithObjects:count:] + 52
5 HotPatch 0x000000010769df77 __29-[ViewController viewDidLoad]_block_invoke + 87
6 libdispatch.dylib 0x000000010c0a62f7 _dispatch_call_block_and_release + 12
7 libdispatch.dylib 0x000000010c0a733d _dispatch_client_callout + 8
8 libdispatch.dylib 0x000000010c0ad754 _dispatch_continuation_pop + 967
9 libdispatch.dylib 0x000000010c0abb85 _dispatch_async_redirect_invoke + 780
10 libdispatch.dylib 0x000000010c0b3102 _dispatch_root_queue_drain + 772
11 libdispatch.dylib 0x000000010c0b2da0 _dispatch_worker_thread3 + 132
12 libsystem_pthread.dylib 0x000000010c5f95a2 _pthread_wqthread + 1299
13 libsystem_pthread.dylib 0x000000010c5f907d
start_wqthread + 13
)很明显,我们已经看到加入到队列的任务的调用关系是:
start_wqthread -> _pthread_wqthread -> _dispatch_worker_thread3 -> _dispatch_root_queue_drain -> _dispatch_async_redirect_invoke -> _dispatch_continuation_pop -> _dispatch_client_callout -> _dispatch_call_block_and_release
3、加入队列代码:
// 根据优先级取出相应的root队列,再调用_dispatch_worker_thread4函数
static void _dispatch_worker_thread3(pthread_priority_t pp)
{
bool overcommit = pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG;
dispatch_queue_t dq;
pp &= _PTHREAD_PRIORITY_OVERCOMMIT_FLAG | ~_PTHREAD_PRIORITY_FLAGS_MASK;
_dispatch_thread_setspecific(dispatch_priority_key, (void *)(uintptr_t)pp);
dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), overcommit);
return _dispatch_worker_thread4(dq);
}
// 开始调用_dispatch_root_queue_drain函数,取出任务
static void _dispatch_worker_thread4(void *context)
{
dispatch_queue_t dq = context;
dispatch_root_queue_context_t qc = dq->do_ctxt;
_dispatch_introspection_thread_add();
int pending = os_atomic_dec2o(qc, dgq_pending, relaxed);
dispatch_assert(pending >= 0);
_dispatch_root_queue_drain(dq, _dispatch_get_priority());
_dispatch_voucher_debug("root queue clear", NULL);
_dispatch_reset_voucher(NULL, DISPATCH_THREAD_PARK);
}
// 循环取出任务
static void _dispatch_root_queue_drain(dispatch_queue_t dq, pthread_priority_t pp)
{
_dispatch_queue_set_current(dq);
dispatch_priority_t pri = dq->dq_priority;
if (!pri) pri = _dispatch_priority_from_pp(pp);
dispatch_priority_t old_dbp = _dispatch_set_basepri(pri);
_dispatch_adopt_wlh_anon();
struct dispatch_object_s *item;
bool reset = false;
dispatch_invoke_context_s dic = { };
dispatch_invoke_flags_t flags = DISPATCH_INVOKE_WORKER_DRAIN |
DISPATCH_INVOKE_REDIRECTING_DRAIN;
_dispatch_queue_drain_init_narrowing_check_deadline(&dic, pri);
_dispatch_perfmon_start();
while ((item = fastpath(_dispatch_root_queue_drain_one(dq)))) {
if (reset) _dispatch_wqthread_override_reset();
_dispatch_continuation_pop_inline(item, &dic, flags, dq);
reset = _dispatch_reset_basepri_override();
if (unlikely(_dispatch_queue_drain_should_narrow(&dic))) {
break;
}
}
// overcommit or not. worker thread
if (pri & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG) {
_dispatch_perfmon_end(perfmon_thread_worker_oc);
} else {
_dispatch_perfmon_end(perfmon_thread_worker_non_oc);
}
_dispatch_reset_wlh();
_dispatch_reset_basepri(old_dbp);
_dispatch_reset_basepri_override();
_dispatch_queue_set_current(NULL);
}
// 这个函数的作用就是调度出任务的执行函数
static inline void _dispatch_continuation_pop_inline(dispatch_object_t dou,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
dispatch_queue_t dq)
{
dispatch_pthread_root_queue_observer_hooks_t observer_hooks =
_dispatch_get_pthread_root_queue_observer_hooks();
if (observer_hooks) observer_hooks->queue_will_execute(dq);
_dispatch_trace_continuation_pop(dq, dou);
flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;
// 之前说过dispatch_async是有do_vtable成员变量的,所以会走进这个if分支,又invoke方法指定为_dispatch_async_redirect_invoke,所以执行该函数
// 相同的,如果是dispatch_get_global_queue也会走这个分支,执行_dispatch_queue_override_invoke方法,这个之前也说过了
if (_dispatch_object_has_vtable(dou)) {
dx_invoke(dou._do, dic, flags);
} else {
_dispatch_continuation_invoke_inline(dou, DISPATCH_NO_VOUCHER, flags);
}
if (observer_hooks) observer_hooks->queue_did_execute(dq);
}
// 继续按自定义队列的步骤走
void _dispatch_async_redirect_invoke(dispatch_continuation_t dc,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags)
{
dispatch_thread_frame_s dtf;
struct dispatch_continuation_s *other_dc = dc->dc_other;
dispatch_invoke_flags_t ctxt_flags = (dispatch_invoke_flags_t)dc->dc_ctxt;
dispatch_queue_t assumed_rq = (dispatch_queue_t)dc->dc_func;
dispatch_queue_t dq = dc->dc_data, rq, old_dq;
dispatch_priority_t old_dbp;
if (ctxt_flags) {
flags &= ~_DISPATCH_INVOKE_AUTORELEASE_MASK;
flags |= ctxt_flags;
}
old_dq = _dispatch_get_current_queue();
if (assumed_rq) {
old_dbp = _dispatch_root_queue_identity_assume(assumed_rq);
_dispatch_set_basepri(dq->dq_priority);
} else {
old_dbp = _dispatch_set_basepri(dq->dq_priority);
}
_dispatch_thread_frame_push(&dtf, dq);
// _dispatch_continuation_pop_forwarded里面就是执行_dispatch_continuation_pop函数
_dispatch_continuation_pop_forwarded(dc, DISPATCH_NO_VOUCHER,
DISPATCH_OBJ_CONSUME_BIT, {
_dispatch_continuation_pop(other_dc, dic, flags, dq);
});
_dispatch_thread_frame_pop(&dtf);
if (assumed_rq) _dispatch_queue_set_current(old_dq);
_dispatch_reset_basepri(old_dbp);
rq = dq->do_targetq;
while (slowpath(rq->do_targetq) && rq != old_dq) {
_dispatch_queue_non_barrier_complete(rq);
rq = rq->do_targetq;
}
_dispatch_queue_non_barrier_complete(dq);
_dispatch_release_tailcall(dq);
}
// 顺便说下,如果按照的是dispatch_get_global_queue会执行_dispatch_queue_override_invoke函数
void _dispatch_queue_override_invoke(dispatch_continuation_t dc,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags)
{
dispatch_queue_t old_rq = _dispatch_queue_get_current();
dispatch_queue_t assumed_rq = dc->dc_other;
dispatch_priority_t old_dp;
voucher_t ov = DISPATCH_NO_VOUCHER;
dispatch_object_t dou;
dou._do = dc->dc_data;
old_dp = _dispatch_root_queue_identity_assume(assumed_rq);
if (dc_type(dc) == DISPATCH_CONTINUATION_TYPE(OVERRIDE_STEALING)) {
flags |= DISPATCH_INVOKE_STEALING;
} else {
// balance the fake continuation push in
// _dispatch_root_queue_push_override
_dispatch_trace_continuation_pop(assumed_rq, dou._do);
}
// 同样调用_dispatch_continuation_pop函数
_dispatch_continuation_pop_forwarded(dc, ov, DISPATCH_OBJ_CONSUME_BIT, {
if (_dispatch_object_has_vtable(dou._do)) {
dx_invoke(dou._do, dic, flags);
} else {
_dispatch_continuation_invoke_inline(dou, ov, flags);
}
});
_dispatch_reset_basepri(old_dp);
_dispatch_queue_set_current(old_rq);
}
4、_dispatch_continuation_pop
无论是自定义的队列还是获取系统的,最终都会调用这个函数
void _dispatch_continuation_pop(dispatch_object_t dou, dispatch_invoke_context_t dic,
dispatch_invoke_flags_t flags, dispatch_queue_t dq)
{
_dispatch_continuation_pop_inline(dou, dic, flags, dq);
}
static inline void _dispatch_continuation_pop_inline(dispatch_object_t dou,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
dispatch_queue_t dq)
{
dispatch_pthread_root_queue_observer_hooks_t observer_hooks =
_dispatch_get_pthread_root_queue_observer_hooks();
if (observer_hooks) observer_hooks->queue_will_execute(dq);
_dispatch_trace_continuation_pop(dq, dou);
flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;
if (_dispatch_object_has_vtable(dou)) {
dx_invoke(dou._do, dic, flags);
} else {
_dispatch_continuation_invoke_inline(dou, DISPATCH_NO_VOUCHER, flags);
}
if (observer_hooks) observer_hooks->queue_did_execute(dq);
}
static inline void _dispatch_continuation_invoke_inline(dispatch_object_t dou, voucher_t ov,
dispatch_invoke_flags_t flags)
{
dispatch_continuation_t dc = dou._dc, dc1;
dispatch_invoke_with_autoreleasepool(flags, {
uintptr_t dc_flags = dc->dc_flags;
_dispatch_continuation_voucher_adopt(dc, ov, dc_flags);
if (dc_flags & DISPATCH_OBJ_CONSUME_BIT) {
dc1 = _dispatch_continuation_free_cacheonly(dc);
} else {
dc1 = NULL;
}
// 后面分析dispatch_group_async的时候会走if这个分支,但这次走的是else分支
if (unlikely(dc_flags & DISPATCH_OBJ_GROUP_BIT)) {
_dispatch_continuation_with_group_invoke(dc);
} else {
// 这次走这里,直接执行block函数
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);
_dispatch_introspection_queue_item_complete(dou);
}
if (unlikely(dc1)) {
_dispatch_continuation_free_to_cache_limit(dc1);
}
});
_dispatch_perfmon_workitem_inc();
}
至此,任务怎么被调度执行的已经看明白了。
start_wqthread
是汇编写的,直接和内核交互。虽然我们明确了使用了异步的任务被执行的调用顺序,但是想必还是有这样的疑问
_dispatch_worker_thread3
是怎么跟内核扯上关系的。为什么调用的是
_dispatch_worker_thread3
,而不是
_dispatch_worker_thread
或者
_dispatch_worker_thread4
呢? 在此之前需要说的是,在GCD中一共有2个线程池管理着任务,一个是主线程池,另一个就是除了主线程任务的线程池。主线程池由序号1的队列管理,其他有序号2的队列进行管理。加上
runloop
运行的
runloop
队列,一共就有16个队列。
序号 标签
1 com.apple.main-thread
2 com.apple.libdispatch-manager
3 com.apple.root.libdispatch-manager
4 com.apple.root.maintenance-qos
5 com.apple.root.maintenance-qos.overcommit
6 com.apple.root.background-qos
7 com.apple.root.background-qos.overcommit
8 com.apple.root.utility-qos
9 com.apple.root.utility-qos.overcommit
10 com.apple.root.default-qos
11 com.apple.root.default-qos.overcommit
12 com.apple.root.user-initiated-qos
13 com.apple.root.user-initiated-qos.overcommit
14 com.apple.root.user-interactive-qos
15 com.apple.root.user-interactive-qos.overcommit
有那么多
root
队列,所以
application
启动的时候就会初始化这些root队列的
_dispatch_root_queues_init
函数。
5、
_dispatch_root_queues_init
函数
_dispatch_root_queues_init
void
_dispatch_root_queues_init(void)
{
static dispatch_once_t _dispatch_root_queues_pred;
dispatch_once_f(&_dispatch_root_queues_pred, NULL,
_dispatch_root_queues_init_once);
}
static void
_dispatch_root_queues_init_once(void *context DISPATCH_UNUSED)
{
int wq_supported;
_dispatch_fork_becomes_unsafe();
if (!_dispatch_root_queues_init_workq(&wq_supported)) {
size_t i;
for (i = 0; i < DISPATCH_ROOT_QUEUE_COUNT; i++) {
bool overcommit = true;
_dispatch_root_queue_init_pthread_pool(
&_dispatch_root_queue_contexts[i], 0, overcommit);
}
DISPATCH_INTERNAL_CRASH((errno << 16) | wq_supported,
"Root queue initialization failed");
}
}
static inline bool
_dispatch_root_queues_init_workq(int *wq_supported)
{
int r; (void)r;
bool result = false;
*wq_supported = 0;
bool disable_wq = false; (void)disable_wq;
bool disable_qos = false;
bool disable_kevent_wq = false;
if (!disable_wq && !disable_qos) {
*wq_supported = _pthread_workqueue_supported();
if (!disable_kevent_wq && (*wq_supported & WORKQ_FEATURE_KEVENT)) {
r = _pthread_workqueue_init_with_kevent(_dispatch_worker_thread3,
(pthread_workqueue_function_kevent_t)
_dispatch_kevent_worker_thread,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
result = !r;
}
}
return result;
}
这里,已经看到
_pthread_workqueue_init_with_keven
t函数就是绑定了
_dispatch_worker_thread3
函数去做一些
GCD
的线程任务,看到源代码
_pthread_workqueue_init_with_kevent
做了些什么。
6、
_pthread_workqueue_init_with_kevent
_pthread_workqueue_init_with_kevent
int
_pthread_workqueue_init_with_kevent(pthread_workqueue_function2_t queue_func,
pthread_workqueue_function_kevent_t kevent_func,
int offset, int flags)
{
return _pthread_workqueue_init_with_workloop(queue_func, kevent_func, NULL, offset, flags);
}
int
_pthread_workqueue_init_with_workloop(pthread_workqueue_function2_t queue_func,
pthread_workqueue_function_kevent_t kevent_func,
pthread_workqueue_function_workloop_t workloop_func,
int offset, int flags)
{
if (flags != 0) {
return ENOTSUP;
}
__workq_newapi = true;
__libdispatch_offset = offset;
int rv = pthread_workqueue_setdispatch_with_workloop_np(queue_func, kevent_func, workloop_func);
return rv;
}
static int
pthread_workqueue_setdispatch_with_workloop_np(pthread_workqueue_function2_t queue_func,
pthread_workqueue_function_kevent_t kevent_func,
pthread_workqueue_function_workloop_t workloop_func)
{
int res = EBUSY;
if (__libdispatch_workerfunction == NULL) {
// Check whether the kernel supports new SPIs
res = __workq_kernreturn(WQOPS_QUEUE_NEWSPISUPP, NULL, __libdispatch_offset, kevent_func != NULL ? 0x01 : 0x00);
if (res == -1){
res = ENOTSUP;
} else {
__libdispatch_workerfunction = queue_func;
__libdispatch_keventfunction = kevent_func;
__libdispatch_workloopfunction = workloop_func;
// Prepare the kernel for workq action
(void)__workq_open();
if (__is_threaded == 0) {
__is_threaded = 1;
}
}
}
return res;
}
我们看到了
__libdispatch_workerfunction = queue_func
;指定了队列工作函数。然后我们往回看之前说的我们制造了一个人为crash,追溯栈里看到
_pthread_wqthread
这个函数。看下这个函数怎么启用
_dispatch_worker_thread3
的
7、_dispatch_worker_thread3
实际代码很多,这里我精简了下,拿到了__libdispatch_workerfunction对应的_dispatch_worker_thread3,然后直接执行。
void
_pthread_wqthread(pthread_t self, mach_port_t kport, void *stacklowaddr, void *keventlist, int flags, int nkevents)
{
pthread_workqueue_function_t func = (pthread_workqueue_function_t)__libdispatch_workerfunction;
int options = overcommit ? WORKQ_ADDTHREADS_OPTION_OVERCOMMIT : 0;
// 执行函数
(*func)(thread_class, options, NULL);
__workq_kernreturn(WQOPS_THREAD_RETURN, NULL, 0, 0);
_pthread_exit(self, NULL);
}
3、
dispatch_group_async