一、安装前准备
-
VM
虚拟机安装
Centos 7
操作系统。
-
安装
JDK
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
查看jdk安装路径
并
配置系统路径
rpm -ql java-1.8.0-openjdk
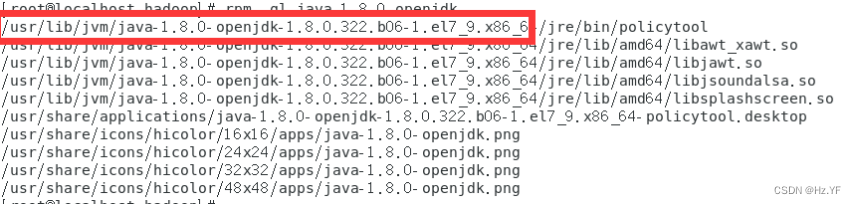
-
下载
Hadoop
安装包
下载 Hadoop-2.7.7 安装包,解压至/home/hj/hadoop-2.7.7 文件夹。

-
下载
Spark
安装包
下载
spark-2. 4.7-bin-hadoop2.7. tar
安装包。并解压至
/home/hj/
spark- 2.4.7-bin-hadoop2.7
文件夹。
二、安装
Hadoop
-
下载
Hadoop
安装包
下载 Hadoop-2.7.7 安装包,解压至/home/hj/hadoop-2.7.7 文件夹。

-
配置环境变量。
使用命令
vi
/etc/profile
打开
/etc/profile
,在文件末尾写入
export J
AVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/
export
HAD00P_H0ME
=/home/hj/hadoop-2.7.7/
export
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
输入命令:
source /etc/profile
使环境变量生效。
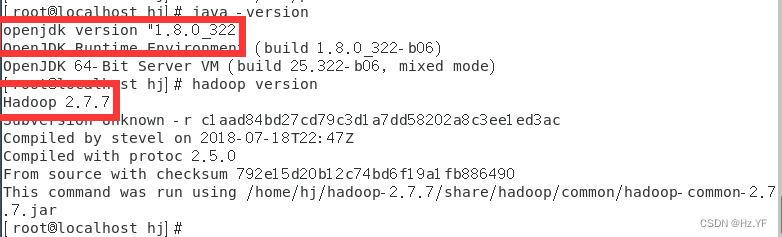
输入命令
java -version
以及
hadoop version
查看
java
环境变量以及
hadoop
环
境变量是否配置正确。
-
输入命令
cd $HADOOP_HOME/etc/hadoop/,
进入
hadoop
配置文件所在的目录,
- 使用 命令vi hadoop-env.sh mapred-env.sh yarn-env.sh,
- 在这三个文件末尾添加export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/

以yarn-env.sh为例:

4.
配置
core-site.xml.
使用命令
vi
core-site.xml
,
在
〈configuration></configuration>
之间插入 以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hj/tmp</value>
</property>
其中第一个
property
是配置默认文件系统所在的位置,将其中主机名替换为自 己的主机名称(
<主机名〉为
/etc/hostname
文件中定义的主机名
)。
第二个
property
是配置
hadoop
临时目录所在位置。使用命令
mkdir -p /home/hj/tmp
创建临时目录。
-
配置
hdfs-site.xml.
在
〈configuration></configuration>
之间插入以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>

该
property
是配置分布式文件系统对于每个文件块的副本数量设置,默认为3,而 在伪分布式环境下设置为 1,因为只有一个节点。
-
将 mapred-site.xml.template 复制一份为 mapred-site.xml,再配置 mapred-site.xml.在<configuration></configuration>之间插入以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
该 property 是配置进行 mapreduce 计算任务的框架,设置为 yarn。
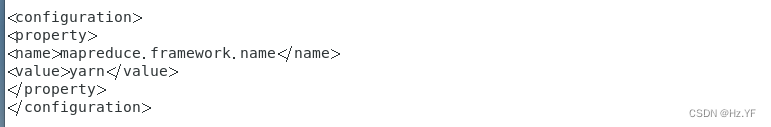
-
配置
yarn-si
t
e.xml.
在
〈configura ti on>〈/configura tion>
之间插入以下内容:
〈property>
〈name>yarn.nodemanager.aux-services〈/name>
〈value>mapreduce_shuffle〈/value>
〈/property>
〈property>
〈name>yarn.resourcemanager.hostname〈/name>
<value>
localhost
〈/value〉
〈/property>
-
第一个
property
配置的是
mapreduce
使用混洗重组模式,第二个
property
指定了
yarn
框架中资源管理者的主机名,因为就一个节点,所以设置为当前主机名。

-
配置本机
ssh
免密登录
-
安装
ssh
服务端。命令:
yum
install openssh-server。

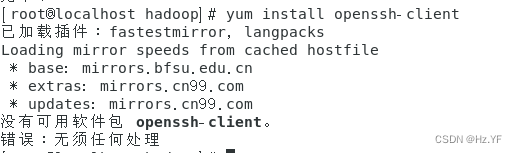
-
安装
ssh
客户端。命令:
yum
install openssh-client
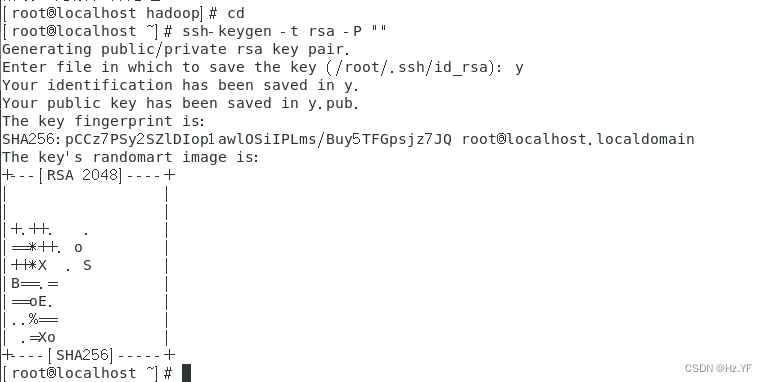
-
配置
ssh
免密登录。进入当前用户的
home
目录,生成本机秘钥。
命令:
cd
ssh-keygen -t rsa -P
“”
-
将公钥追加到
authorized_keys
文件中。
(
首次创建.ssh目录和authorized_keys文件。
创建.ssh目录:
mkdir ~/.ssh
设置正确的权限:
chmod 700 ~/.ssh
创建authorized_keys文件:
touch ~/.ssh/authorized_keys
)
命令:
cat .ssh/id_rsa.pub
>>
.ssh/authorized_keys
然后赋予
authorized_keys
文件权限。
命令:
chmod
600
.ssh/authorized_keys
-
输入命令
ssh localhost
查看
ssh
是否配置成功。
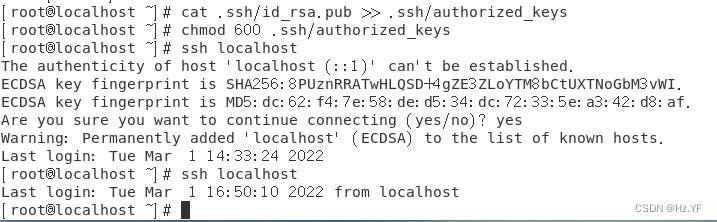
输入命令
exit
退出
ssh
当前登录。

-
使用命令
hdfs namenode -format
对
namenode
进行格式化。若格式化成功,则
/
home/hj/tmp
(
第
4
步创建的
hdfs
临时目录下会生成一个新目录
dfs;
否 则,即为失败,应往回检查是否哪里设置错误。
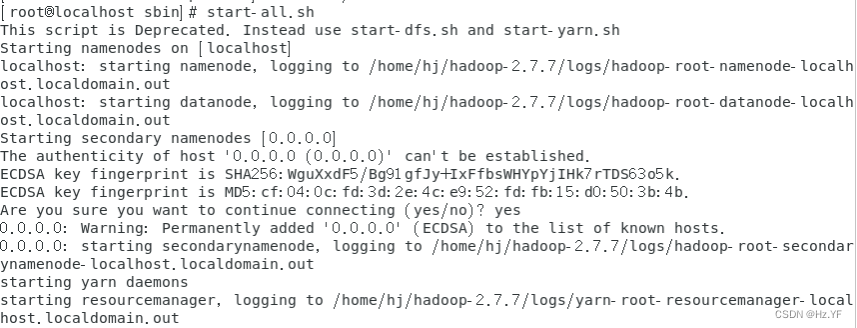

-
使用命令
start-all.sh
开启所有节点(伪分布式只有本机一个节点)及节点所开 启的所有服务,并使用
jps
查看该节点的对应服务是否开启成功。如果现实一下内容, 则证明配置成功。

-
上传文件至
hdfs
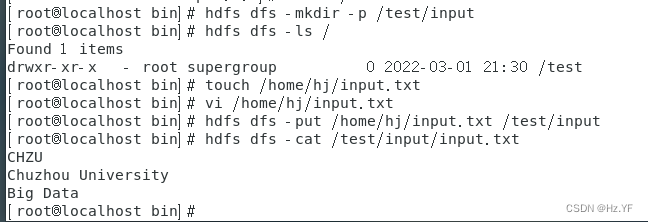
(1)
在
hdfs
文件系统中创建目录
/test/input。
命令:
hdfs dfs -mkdir -p /test
/
input,
使用命令
hdfs dfs -ls
/ 查看目录是 否创建成功。

(2)
在
/home/
〈用户名>/目录中新建一个文件
input.txt,
输入内容如下所示:
CHZU
Chuzhou University
Big Data
(3)
将创建的
inpu t.txt
上传至
hdfs
中的
/t es t/input
目录下。
命令:
hdfs dfs -put /home/
hj
/input.txt /test/input
使用命令
hdfs dfs -cat /test/input/input.txt
查看是否上传成功。
-
使用
hadoop
自带的
WordCount
程序对
input.txt
文件进行单词计数。命令:
(1)
yarn jar /home/
hj
/hadoop-2.7. 7/share/hadoop/mapreduce/hadoop- mapreduce-examples-2.7.7.jar wordcount /test/input /test/output
参数
wordcount
为该
jar
包的主类名
/test/input
为输入文件夹(是文件夹,不 是文件!!!)
/test/output
为输出文件夹(是文件夹,不是文件!!!并且,在执行此 命令之前,
hdfs
中不能有
/test/ou tput
目录
!!!)
三、安装
Spark
-
将
〈Spark
解压路径
〉/conf/spark-env. sh.template
复制为
conf/spark-env.sh
,在
spark-env.sh
文件末尾添加如下所示的内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/
export HADOOP_HOME=/home/hj/hadoop-2.7.7
export HADOOP_CONF_DIR=/home/hj/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=192.168.238.111
export SPARK_LOCAL_IP=192.168.238.111
JAVA_HOME:Java
的安装路径;
HADOOP_HOME:Hadoop
的安装路径;
HADOOP_CONF_DIR: Hadoop
配置文件路径
SPARK_MASTER_IP:Spark
主节点的
IP
或机器名
SPARK_LOCAL_IP:Spark
本地的
IP
或机器名
-
切换到
〈Spark
解压路径
>/sbin
目录下,启动集群。
命令:
./start-all.sh

-
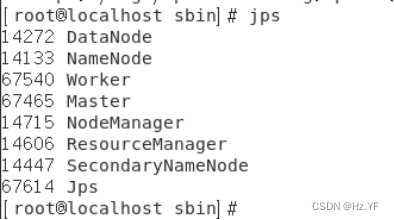
通过
jps
查看进程,即有
Master
也有
Worker
进程,说明启动成功。
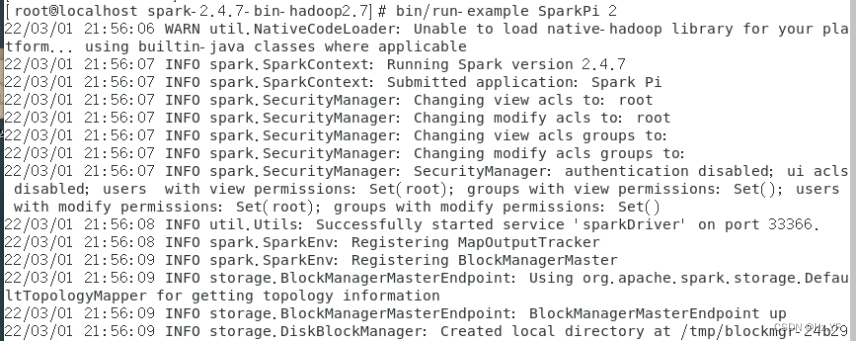
-
使用
SparkPi
来计算
Pi
的值。
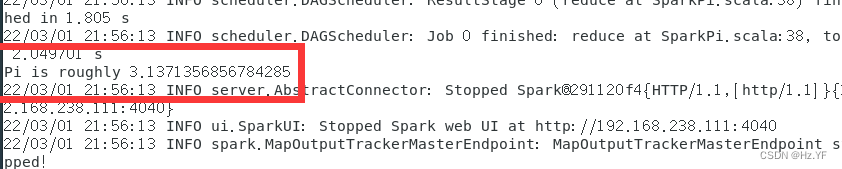
由于计算
Pi
采用随机数,所以每次计算结果也会有差异。
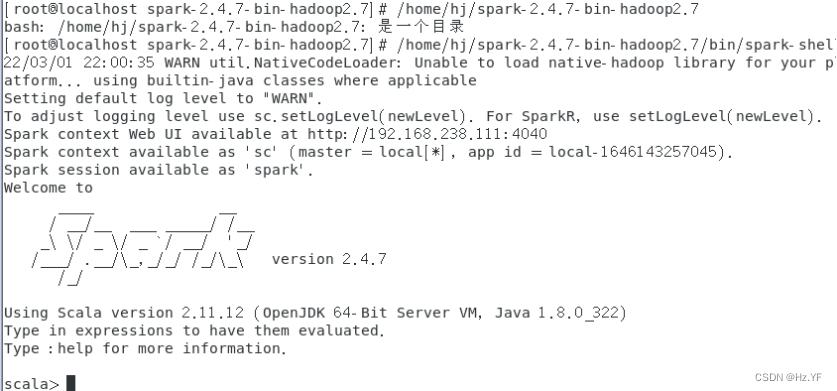
5. 运行字数统计程序
(1) 启动 spark-shell。
命令:<Spark 解压目录>/bin/spark-shell
(2)执行字数统计
在 Spark-shell 中输入以下代码:
sc.textFile(“/test/input/input.txt”).flatMap(_.split(”
“)).map((_,1)).reduceByKey(_+_).saveAsTextFile(“/test/output1”)

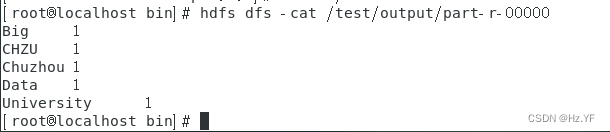
查看运行结果,命令:hdfs dfs -cat /test/output1/part-00000

-
查看
job
监控界面