-
Apache Pulsar
-
1. Kafka 概述
-
1.1 现存问题
-
1.3 优点
-
1.4 缺点
-
-
2. Pulsar 架构
-
2.4.1 三种写路由策略
-
2.4.2 四种读下发策略
-
2.4.3 Pull & Push 可选请求模式
-
2.4.4 Consume ACK 与 unACK
-
2.4.5 Data Retention
-
2.3.1 多租户
-
2.3.2 Topic 分配
-
2.3.3 Topic Lookup
-
Broker 的 LoadManager 线程
-
bundle 与 ownership
-
Topic 分配流程
-
设计优点
-
2.1.1 数据集合
-
2.1.2 存储节点
-
2.1.3. 一致性保证
-
2.1 Pulsar VS Kafka
-
2.2 Pulsar 架构
-
2.3 多租户与 Topic Lookup
-
2.4 Produce / Consume 策略
-
-
3. Bookkeeper 架构
-
3.4.1 读被均摊
-
3.4.2 读有预期
-
3.4.3 读结果无序
-
3.3.1 三种文件
-
3.3.2 ADD 操作
-
3.3.3 结论
-
3.1.1 特性
-
3.1.2 Ensemble Size / Ensembles / Write Quorum / ACK Quorum / Segment(Ledger) / Fragment
-
3.1.3 结论
-
3.1 概念
-
3.2 架构
-
3.3 写流程
-
3.4 读流程
-
-
4. 水平扩容
-
4.1 水平扩展 Broker
-
4.2 水平扩展 Bookie
-
-
5. Pulsar Consistency
-
5.3.1 场景
-
5.3.2 流程
-
5.3.3 结论:Broker 故障秒级恢复
-
5.2.1 场景
-
5.2.2 流程
-
5.2.3 结论:Bookie 故障秒级恢复
-
5.1.1 冗余副本
-
5.1.2 一致性机制
-
5.1 一致性机制
-
5.2 Bookie Auto Recovery:Ensemble Change
-
5.3 Broker Recovery:Fencing
-
-
6. Distributed Log 与 Raft
-
6.1 概念对比
-
6.2 流程对比
-
6.3 总结
-
-
7. 总结
-
7.1 Pulsar 的优点
-
7.2 Pulsar 的缺点
-
简要总结下对 Pulsar 的调研。
Apache Pulsar
内容:
-
Kafka : 优缺点。
-
Pulsar : 多租户,Topic Lookup,生产消费模式
-
Bookkeeper : 组件概念与读写流程
-
Horizontal Scale : Broker 或 Bookie 的横向扩展
-
Consistency : Broker 或 Bookie crash 后保证日志一致性
-
Distributed Log & Raft 算法
-
总结
1. Kafka 概述
1.1 现存问题
主要问题:
-
负载均衡需人工介入:手动按异构配置的 broker 对应生成 assignment 执行计划。
-
故障恢复不可控:broker 重启后需复制分区新数据并重建索引,其上的读写请求转移到其他 broker,流量激增场景下可能会导致集群雪崩。
其他问题:
-
跨数据中心备份需维护额外组件:MirrorMaker 官方也承认鸡肋,做跨机房的冗余复制依赖第三方组件如 uber 的 uReplicator
注:已脱敏。
1.3 优点
-
生态成熟,易与 Flink 等现有组件集成。
-
可参考资料多,完善的官方文档和书籍。
-
模型简单易上手:partition 有 replication,以 segment 和 index 方式存储。
1.4 缺点
计算与存储耦合
-
存储节点有状态:读写只能走 Partition Leader,高负载集群中 Broker 重启容易出现单点故障,甚至雪崩。
-
手动负载均衡:集群扩容必须手动 Assign Partitions 到新 Broker,才能分散读写的负载。
漫画对比:https://jack-vanlightly.com/sketches/2018/10/2/kafka-vs-pulsar-rebalancing-sketch
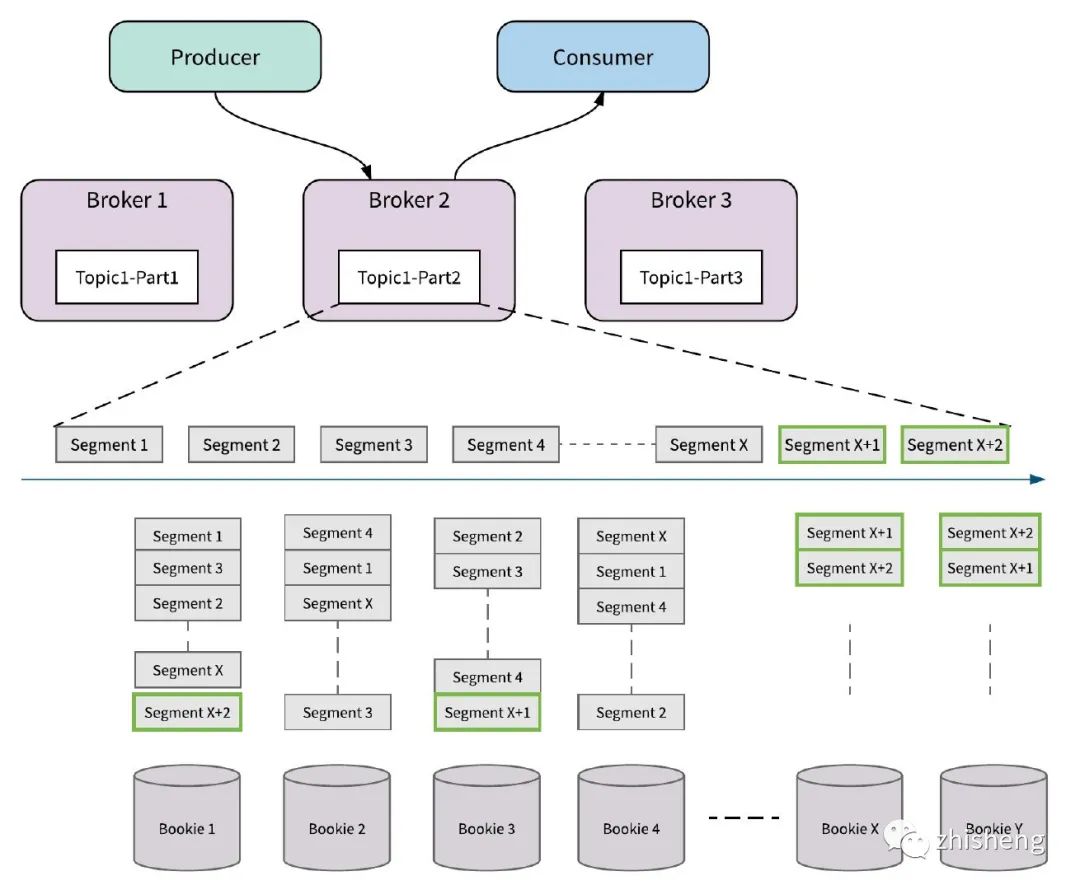
2. Pulsar 架构
2.1 Pulsar VS Kafka
| Pular | Kafka | |
|---|---|---|
| 数据集合 | Topic, Partition | Topic, Partition |
| 存储节点及读写组件 | Bookkeeper Bookie | Broker |
| Pulsar Broker | Client SDK | |
| 数据存储单元 | Partition -> Ledgers -> Fragments | Partition -> Segments |
| 数据一致性保证 | Ensemble Size | metadata.broker.list |
| Write Quorum Size(QW) | Replication Factor | |
| Ack Quorum Size(QA) | request.required.acks |
注:(QW+1)/2 <= QA <= QW <= Ensemble Size <= Bookies Count
2.1.1 数据集合
-
Kafka:topic 切分为多个 partitions,各 partition 以目录形式在 leader broker 及其多副本 brokers 上持久化存储。
-
Pulsar:同样有多个 partitions,但一个 partition 只由一个 broker 负责读写(ownership),而一个 partition 又会均匀分散到多台 bookie 节点上持久化存储。
2.1.2 存储节点
-
Kafka:直接持久化到 broker,由 Client SDK 直接读写。
-
Pulsar:分散持久化到 bookie,由 broker 内嵌的 bookkeeper Client 负责读写。
2.1.3. 一致性保证
-
Kafka:通过多 broker 集群,每个 partition 多副本,producer 指定发送确认机制保证。
-
Pulsar:通过多 broker 集群,broker Quorum Write 到 bookie,返回 Quorum ACK 保证。
2.2 Pulsar 架构
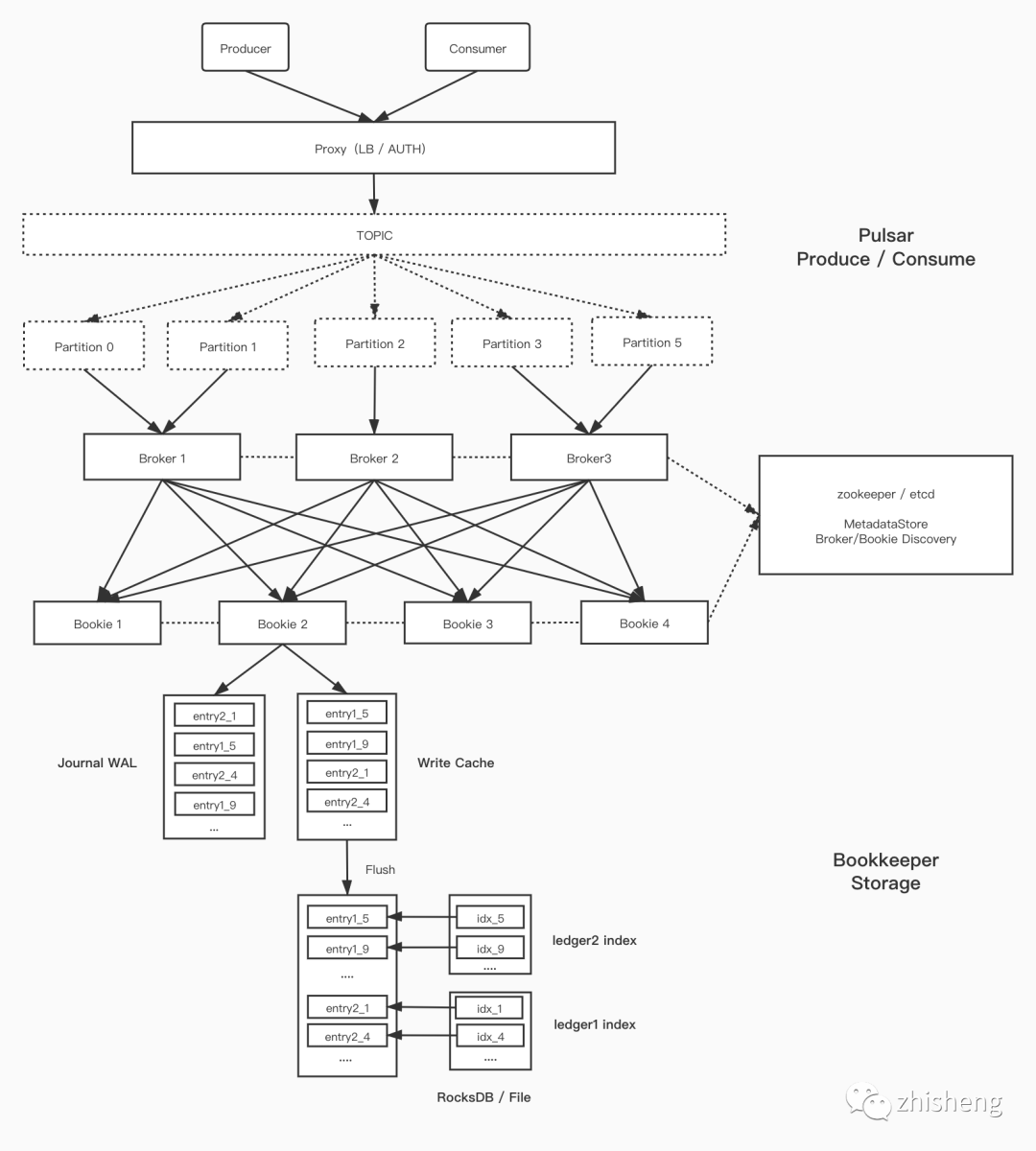
2.3 多租户与 Topic Lookup
2.3.1 多租户
-
topic 分三层:
persistent://tenant/namespace/topic
,对应划分为
department -> app -> topics
,以 namespace 为单位进行过期时间设置,ACL 访问鉴权控制。 -
优点:按租户进行 topic 资源隔离,并混部在同一集群中,提高集群利用率。
2.3.2 Topic 分配
Broker 的 LoadManager 线程
-
Leader:即 Broker Leader,类似 Kafka Controller,汇总所有 Broker 的负载,合理地分配 topic 分区。
-
Wroker:等待分配 bundle 内的所有 topic partition
bundle 与 ownership
-
以 Namespace 为单位在 ZK 维护 bundle ring(broker 的数量 2~3 倍),topic 分区按
hash(topic_partition)%N
落到 bundle 中。 -
Broker 唯一绑定到 bundle,就对 bundle 内的所有 topic partition 持有 ownership,用于 Broker Recovery 保证高可用。
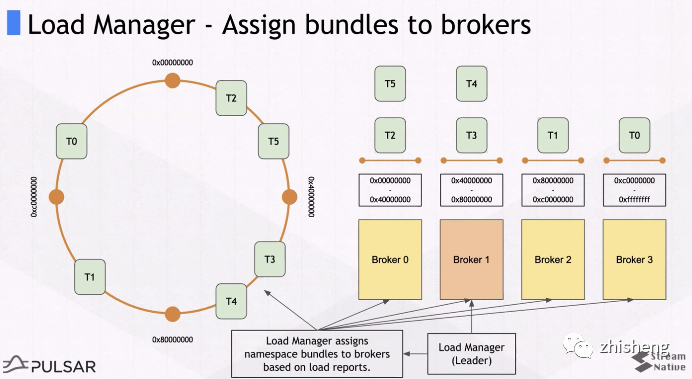
Topic 分配流程
-
上报负载:LoadManager Worker 负责向 ZK 汇报负载指标
zk> get /loadbalance/brokers/localhost:8080 { "pulsarServiceUrl": "pulsar://localhost:6650", "cpu": { "usage": 23, "limit": 50 }, "memory": { "usage": 1, "limit": 10 }, "msgThroughputIn": 100, "msgThroughputOut": 100 } -
bundle 为单位分配:LoadManager Leader 汇总其他 Brokers 的负载,根据负载分配 bundle
zk> get /loadbalance/leader {"serviceUrl":"http://localhost:8080","leaderReady":false} -
分配结果:
zk> ls /namespace/public/default [0x00000000_0x40000000, 0x40000000_0x80000000, 0x80000000_0xc0000000, 0xc0000000_0xffffffff] zk> get /namespace/public/default/0x80000000_0xc0000000 {"nativeUrl":"pulsar://localhost:6650","httpUrl":"http://localhost:8080","disabled":false}
设计优点
不同于 kafka 将所有 topic ISR 等元数据记录到 zk,pulsar 只记录 topic 的分区数,不记录 topic 到 broker 的映射关系,zk 元数据数量极少,所以支持百万量级 topic
|
2.3.3 Topic Lookup
-
Client 向任一 BrokerA 发起 Lookup 请求,如
persistent://public/default/test-topic-1
-
BrokerA 计算 default namespace 下
hash(topic_partition)%N
的值,得到该 topic partition 对应的 bundle,从而查出 ownership BrokerX -
BrokerA 返回 owner BrokerX 地址。
2.4 Produce / Consume 策略
2.4.1 三种写路由策略
-
RoundRobinPartition(默认)
:以 batching 为单位,通过轮询将消息均匀发给 brokers,以获得最大吞吐。 -
SinglePartition
-
有 KEY 则写固定分区,类似
hash(key) mod len(partitions)
写到指定分区。 -
无 KEY 则随机选一个分区,写入该 producer 的所有消息。
-
-
CustomPartition
:用户可自定义针对具体到消息的分区策略,如 Java 实现
MessageRouter
接口。
2.4.2 四种读下发策略
-
Exclusive
(默认)
:独占消费,一对一,保证有序消费,能批量 ACK,是 Failover 特例,不保证高可用。 -
Failover
:故障转移消费,一对一,备选多,保证有序消费,消费者高可用,能批量 ACK,保证高可用。 -
Shared
:共享消费,多对多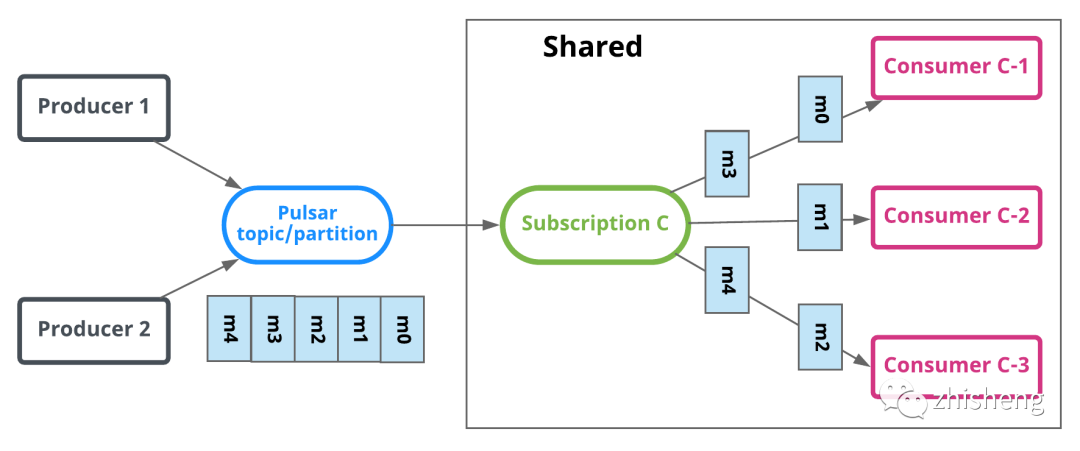
-
Round Robin 分发消息,类似 Consumer Group 但不保证有序消费。
-
只能逐条 ACK:Consumer crash 时才能精确控制消息的重发。
-
水平扩展 Consumer 直接提读吞吐。不像 kafka 必须先扩 Partition 才能扩 Consumer
-
-
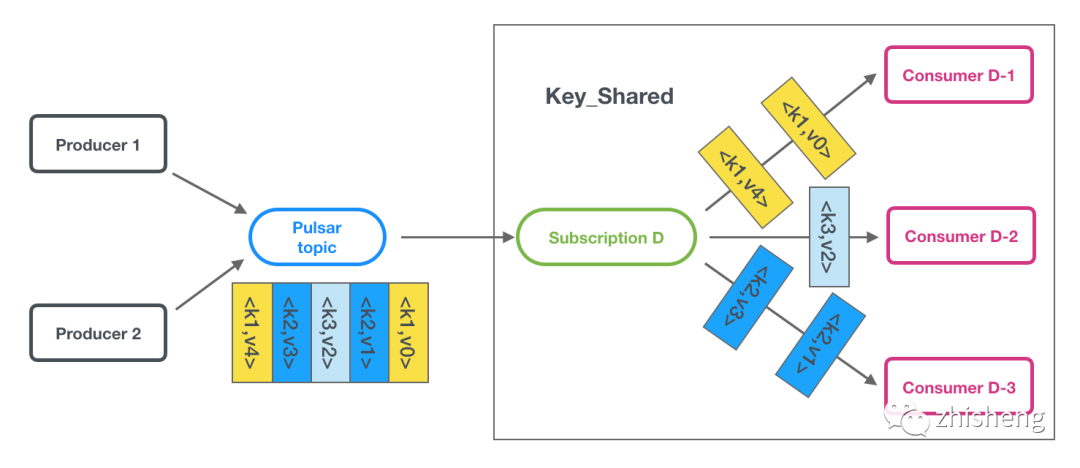
Key_Shared
:按 KEY 共享消费,多对多,Exclusive 和 Shared 的折中模式。-
KEY hash 相同的消息会被相同 consumer 消费,保证有序消费。
-
只能逐条 ACK
-
水平扩展 Consumer 提高读吞吐。
-
2.4.3 Pull & Push 可选请求模式
-
Consumer 可以同步或异步 p Receive 消息。
-
Consumer 可以本地注册 MessageListener 接口来等待 Broker Push 消息。
2.4.4 Consume ACK 与 unACK
-
逐条 ACK、批量 ACK
-
取消 ACK:consumer 消费出错可请求重新消费,发送取消 ACK 后 broker 会重发消息。
-
exclusive, failover:只能取消上一次提交的 ACK,单个 consumer 可控回滚。
-
shared, key_shared:类比 ACK,consumers 只能取消上一条发出的 ACK
-
与
__consumer_offsets
机制类似 ,Broker 收到各消费者的 ACK 后,会更新 Consumer 的消费进度 cursor,并持久化到特定的 ledger 中。
2.4.5 Data Retention
-
默认积极保留:最慢的 subscription 堆积的消息都不能被删除,最坏的情况是某个 subscription 下线后,cursor 依旧会保留在 message streaming 中,会导致消息过期机制失效。
-
消息过期:时间或大小两个维度设置限制,但只对积极保留之前的消息生效
-
TTL:强制移动旧慢 cursor 到 TTL 时间点,若 TTL == Retention,则与 kafka 一样强制过期
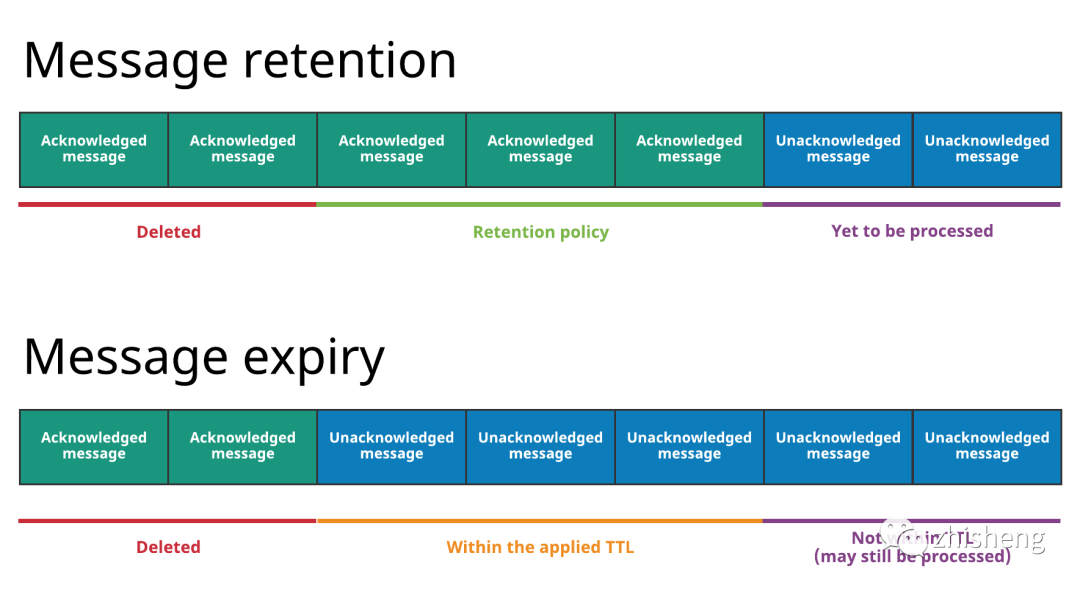
两个指标
-
Topic Backlog:最慢的 subscription 的 cursor 到最新一条消息之间的消息数量。
-
Storage Size:topic 总空间。
-
按 segment 粒度删除,以 Last Motify Time 是否早于 Retention 为标准过期,与 kafka 一致
-
注:bookie 并非同步过期,空间释放是后台进程定期清理
-
3. Bookkeeper 架构
append-only 的分布式 KV 日志系统,K 是
(Ledger_id, Entry_id)
二元组,V 是
(MetaData, RawData)
二进制数据。
3.1 概念
3.1.1 特性
-
高效写:append-only 磁盘顺序写。
-
高容错:通过 bookie ensemble 对日志进行冗余复制。
-
高吞吐:直接水平扩展 bookie 提高读写吞吐。
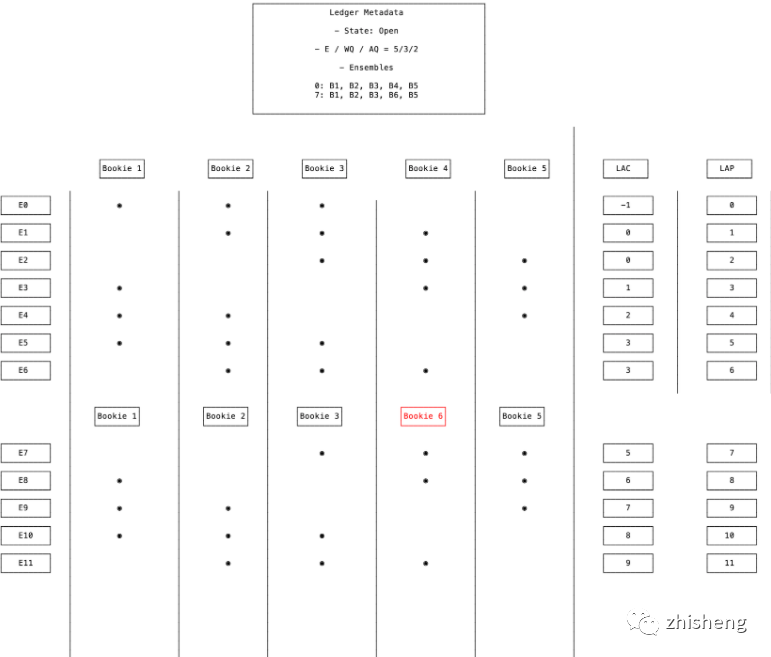
3.1.2 Ensemble Size / Ensembles / Write Quorum / ACK Quorum / Segment(Ledger) / Fragment
-
Ensemble Size:指定
一段
日志要写的 bookies 数量。 -
Ensembles:指定写
一段
日志的目标 bookies 集合。 -
Write Quorum:指定
一条
日志
要写
的 bookie 数量。 -
ACK Quorum:指定
一条
日志要
确认已写
入的 bookie 数量。 -
Segment / Ledger:要写入的
一段
日志。 -
Fragment:写入的
一条
日志。
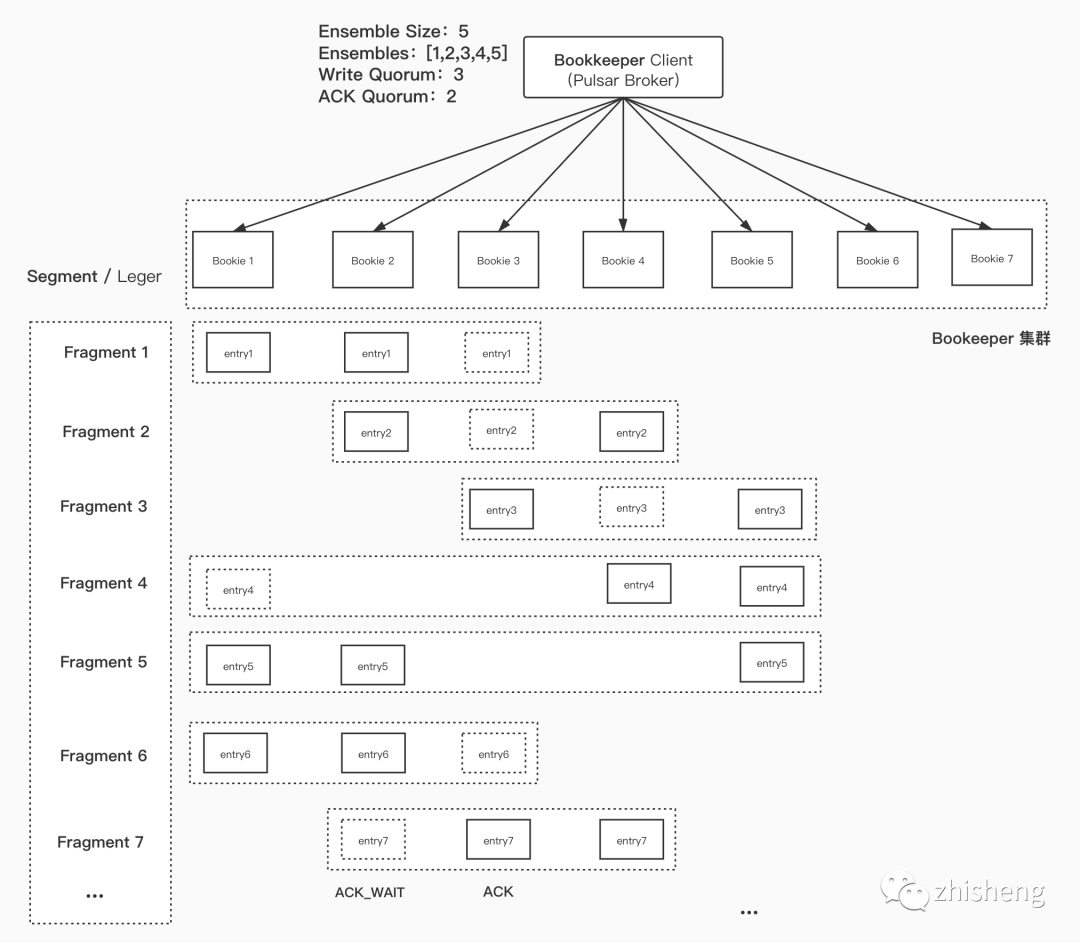
3.1.3 结论
-
Client 会以 Round Robin 的策略挑选出 bookie,依次顺延写 entry
-
Client 只等待 ACK Quorum 个 broker 返回 Append ACK 就认为写成功。
-
一个 Segment / Ledger 包含多个 Fragment
-
Fragment 内的 entry 呈
带状连续
分布在 Ensembles Bookies 上。 -
一个周期内,一台 Bookie 会存储
不连续
的
(EnsembleSize - WriteQuorum)
条 Entry
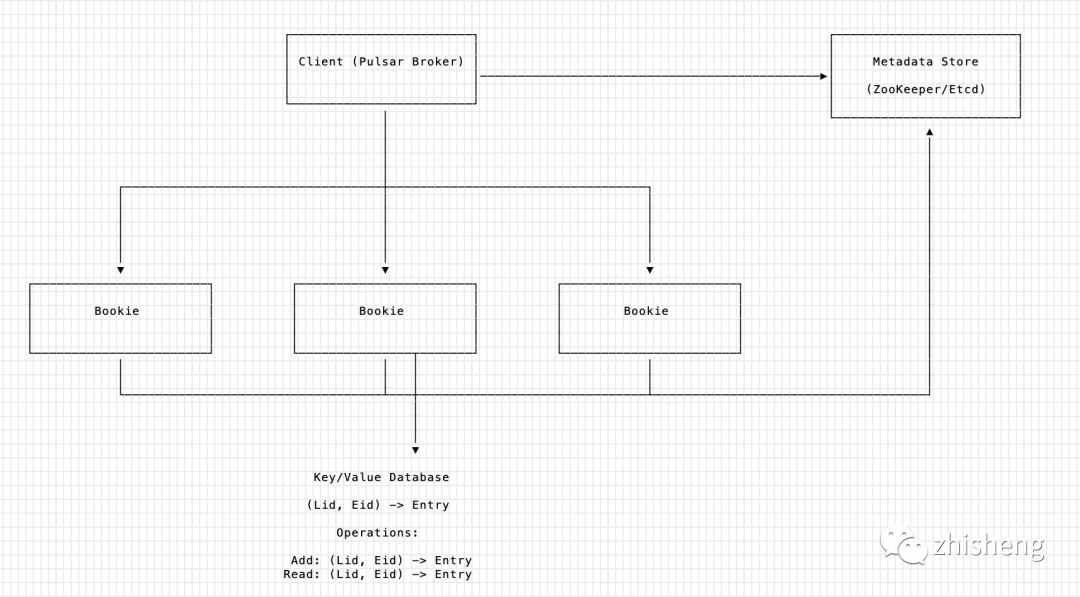
3.2 架构
三个组件
-
zk / etcd:强一致性元数据存储
-
元数据存储:ledger 元数据。
-
服务发现:bookie 的注册中心,bookie 互相发现,client 读取集群全部 bookie 地址。
-
-
Bookie:存储节点,只允许
ADD
/
READ
两个操作,
不保证一致性,不保证可用性
,功能简单。 -
Client:实现冗余复制的逻辑,保证数据的一致性,实现复杂且最重要。
3.3 写流程
3.3.1 三种文件
-
Journal WAL
-
概念:用于持久化存储 bookie 操作 ledger 的事务日志,接收来自多个 Ledger Client 写入的不同 ledger entries,直接 高效地 append 到内存,随后 fsync 顺序写磁盘,延迟低。
-
清理:当 Write Cache 完成 Flush 落盘后自动删除。
-
-
Entry Logs
-
概念:真正落盘的日志文件,有序保存不同 ledger 的 entries,并维护 Write Cache 加速热日志的查找。
-
清理:bookie 后台 GC 线程定期检查其关联的 ledgers 是否在 zk 上已删除,若已删除则自动清理。
-
-
Index Files
-
概念:高效顺序写的副作用是,必须在外围维护
(ledger_id, entry_id)
到
Entry_Log
的映射索引,才能实现高效读,故 Flush Cache 时会分离出索引文件。 -
实现:可选 RocksDB 和文件存储索引。
-
3.3.2 ADD 操作
-
Clients 混乱地给 Bookie 发来不同 ledger 的日志。
-
Bookie 往追加写 Journal,同时向 Write Cache 有序写(Write Cache 内部使用 SkipList 实现动态有序,同时保证读写都高效)
-
WriteCache 写满后 Flush 分离出 index 文件和落盘的日志文件。
-
删除旧 Journal,创建新 Journal 继续追加写,如此循环。
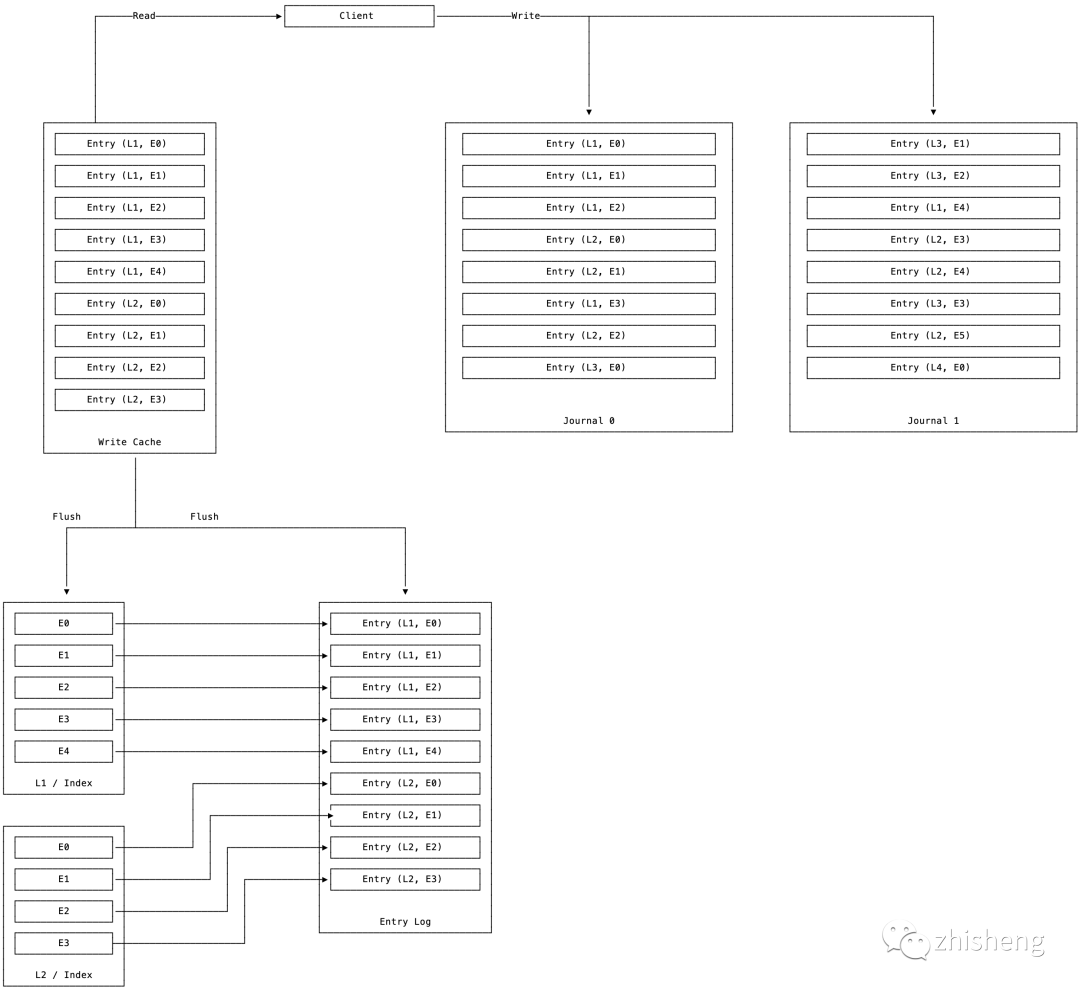
3.3.3 结论
broker 内部为每个 ledger 持久化了其存储的 entry logs,并建立索引提高读效率。
3.4 读流程
Client 发来
(ledger_id, entry_id)
的 KEY
-
热 KEY:在 Write Cache 中则直接返回。
-
冷 KEY:读取 ledger_id 对应的 index 文件,根据 index 找出 entry_id 对应的 entry log 再返回。
3.4.1 读被均摊
如同轮询写,Cleint 也会轮询 Ensembles 均摊读取,同样不存在 leader 读瓶颈。
3.4.2 读有预期
若某个 Bookie 读响应确实很慢,Client 会向其他副本 Bookie 发起读请求,同时等待,从而保证读延时低。
3.4.3 读结果无序
Client 往 bookie 写是轮询无序地写,故从 Ensembles 中读到是消息是无序的,需在 Client 端自行按 entry_id 重新排序,以保证有序响应。
4. 水平扩容
4.1 水平扩展 Broker
新 Broker 加入集群后,Broker Leader 会将高负载 Broker 的部分 topic ownership 转移给新 Broker,从而分摊读写压力。
4.2 水平扩展 Bookie
新 Bookie 加入集群后,Broker 通过 ZK 感知到,并将 ledger 的新 entry log 写到新 Bookie,提高存储层的读写吞吐、存储容量。
5. Pulsar Consistency
5.1 一致性机制
日志的冗余复制、一致性保证均由 Bookkeeper Client 实现。
5.1.1 冗余副本
由如上的 Eensembles 的 QW 和 QA 的多副本写,保证每条日志确实持久化到了 bookie 中。
5.1.2 一致性机制
滑动窗口:
[0, ..., READABLE ... LAC], [LAC+1, ... WAIT_QUOROM ..., LAP]
-
LAP(Last Add Pushed):Client 发出的最后一条 entry_id(从 0 自增的正整数)
-
LAC(Last Add Confirmed):Client 收到的最后一条 ACK 的 entry_id,是一致性的边界。
实现一致性的三个前置条件:
-
写 ledger 只能以 Append-Only 方式追加写,写满后变为 Read-Only
-
一个 Ledger 同一时间只会有一个 Client 在写。
-
LAC 必须按照 LAP 的顺序,依次进行 ACK 确认:保证 LAC 作为一致性边界,前边的日志可读,后边的日志等待多副本复制。
5.2 Bookie Auto Recovery:Ensemble Change
5.2.1 场景
bookie crash 下线后,需恢复副本数量。
5.2.2 流程
-
存在 Leader Bookie 5 作为 Daemon Auditor,不断向其他 Bookies 发送心跳保活。
-
Auditor 发现 Bookie 4 超时,读取 zk 发现 ledger x 的
[0, 7)
entry_id 区间需要从 4 转移到新 Bookie -
找出负载较小的 Bookie 6,并根据 Ensembles 发现冗余数据分布在
{B1, B2, B3, B5}
-
按轮询均摊复制读压力的方式,将 entry log 逐一复制到 Bookie 6
-
复制完毕后修改 ZK 元数据,将 LAC0 的副本 4 替换为 6
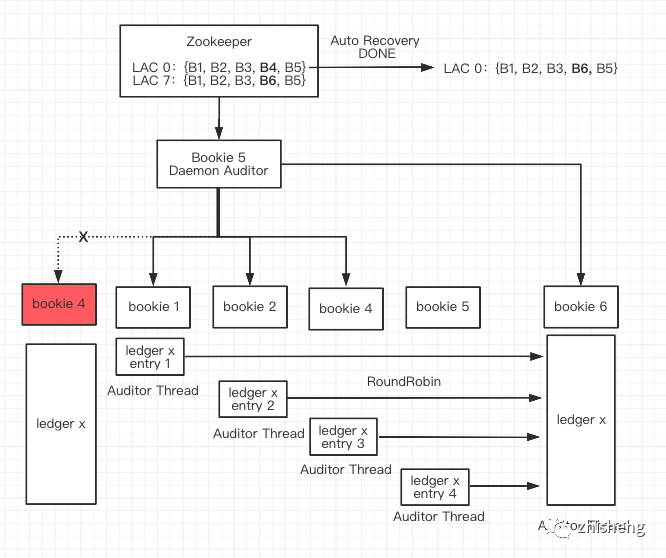
5.2.3 结论:Bookie 故障秒级恢复
-
写请求快速转移:
Bookie 6 加入 Ensembles 后,直接代替 Bookie 4 继续 Append 日志。因为副本数恢复是各个 Ensembles 内部各节点的 Auditor 线程后台异步复制,不会导致 Client 的写中断,整个 Recovery 过程对 Client 几乎透明。
-
LAC 分界线记录 Ensemble Change 历史:
在 ZK 的 ledger metadata 中,会记录每次 Recovery 导致的 ensembles 更新,即记录了 ledger 各 entry log 区间的分布情况。
如下元数据记录了 ledger16 在 LAC46 处,Bookie 3183 下线,随后 Bookie 3182 上线从 LAC47 处继续处理请求:> get /ledgers/00/0000/L0016 ensembleSize: 3 quorumSize: 2 ackQuorumSize: 2 lastEntryId: -1 state: OPEN segment { ensembleMember: "10.13.48.57:3185" ensembleMember: "10.13.48.57:3184" ensembleMember: "10.13.48.57:3183" firstEntryId: 0 } segment { ensembleMember: "10.13.48.57:3185" ensembleMember: "10.13.48.57:3184" ensembleMember: "10.13.48.57:3182" firstEntryId: 47 }
注意:右上可看出 ZK 中各 ledger 的元数据硬编码了 Bookie 的 IP,容器部署时若 Bookie 重启后 IP 变化,会导致旧 Ledger 的该副本作废,故在 k8s 上部署时应选择 DaemonSet 或 StatefulSet
5.3 Broker Recovery:Fencing
5.3.1 场景
Broker crash,或 Broker 与 ZK 出现网络分区导致脑裂,需进行 partition ownership 转移。
5.3.2 流程
-
Broker1 心跳超时后,ZK 将 topic partition 的 ownership 转移到 Broker2
-
Broker2 向 Ensemble 发起 Fencing ledger_X 请求,Bookies 纷纷将 ledger_X 置为 Fencing 不可写状态。
-
Broker1 写数据失败收到 FenceException,说明该 partition 已被 Broker 接管,主动放弃 ownership
-
Client 收到异常后与 Broker1 断开连接,进行 Topic Lookup 与 Broker2 建立长连接。
-
同时,Broker2 对 ledger_X LAC1 之后的 entry log 依次逐一进行 Forwarding Recovery(若 unknow 状态的 entry 副本数实际上已达到 WQ,则认为该 entry 写成功,LAC1 自增为 LAC2)
-
Broker2 更新 ledger_X 的 metadata,将其置为 CLOSE 状态,再创建新 ledger,继续处理 Client 的写请求。
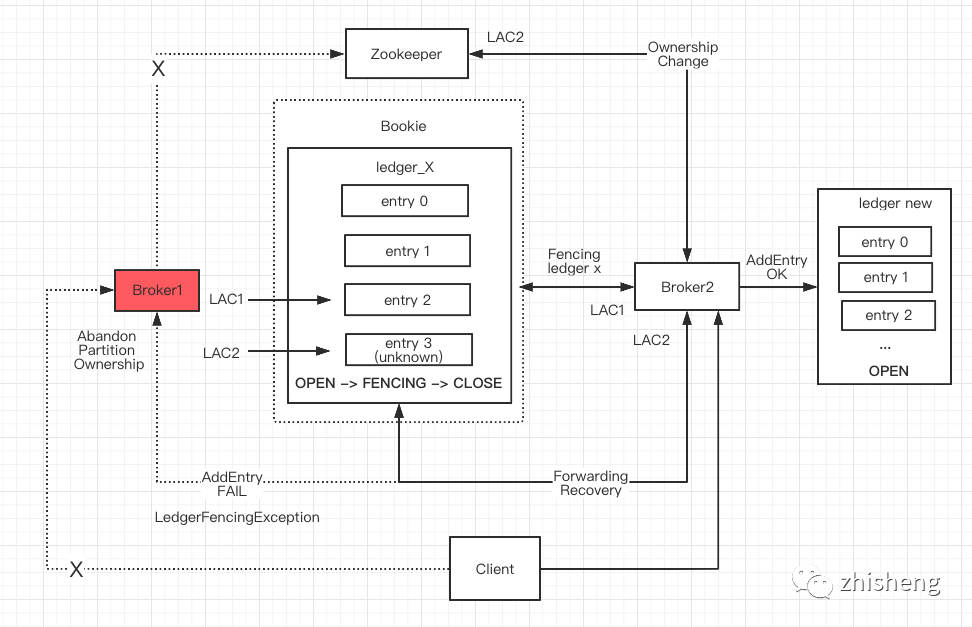
5.3.3 结论:Broker 故障秒级恢复
-
不复用旧 ledger,降低复杂度
若复用旧 ledger_X,必须保证所有 ensemble 的 LAC 一致,同时涉及尾部 entry 的强一致复制,逻辑复杂。直接 CLOSE 能保证旧 ledger 不会再被写入。 -
Recovery 逻辑简单,耗时短
在 Client 的视角,只需等待两个过程:等待结束后,直接往新 Broker 的新 ledger 上追加写数据,Broker 不参与任何数据冗余复制的流程,所以是无状态的,可以直接水平扩展提升以提升吞吐。
-
ZK 进行 partition ownership 的转移。
-
新 Broker 对 UNKNOWN 状态的尾部 entry 进行 Forwarding Recovery
-
6. Distributed Log 与 Raft
6.1 概念对比
| 概念 | Raft | DL |
|---|---|---|
| role | Leader 与 Followers | Writer (broker) 与 Bookies |
| failover | term | ledger_id |
| replication | Majority AppendEntries RPC | Quorum Write |
| consistency | Last Committed Index | Last Add Confirmed(LAC) |
| brain split | Majority Vote | Broker Fencing |
6.2 流程对比
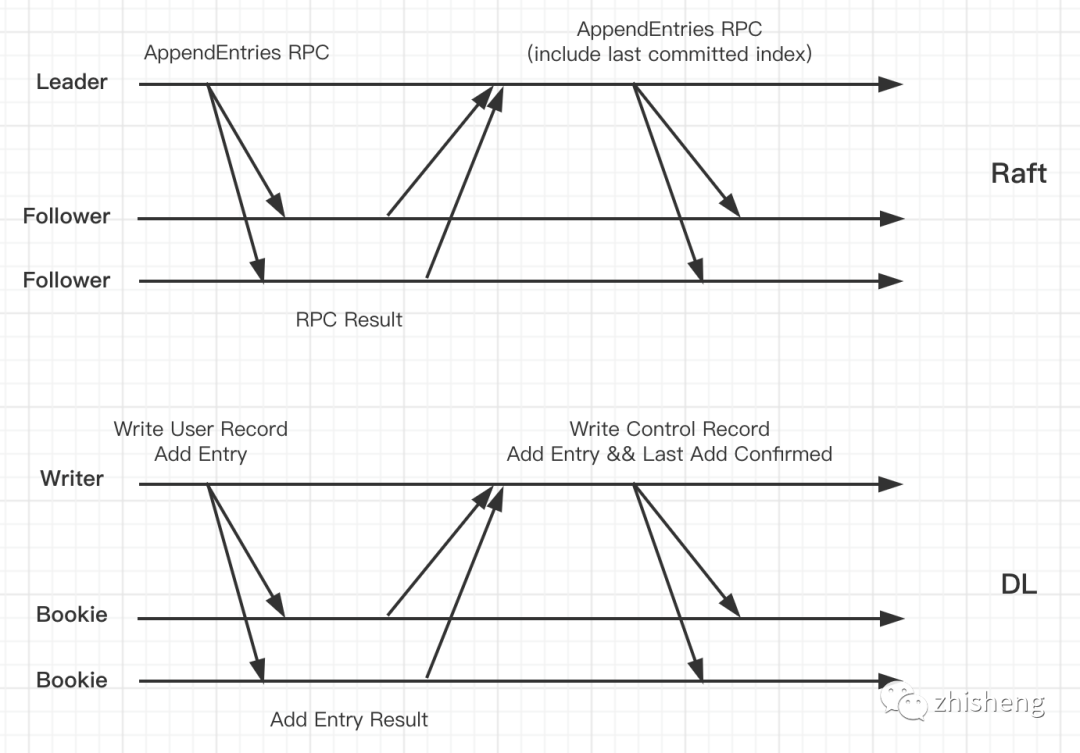
6.3 总结
-
LAC 与 LAP 的存在,使 entry 能以内嵌顺序元数据的方式,均匀分散存储到各台 bookie 中。
-
DL 与 Raft 不同之处在于:
各 bookie 节点的数据不是从单个节点异步复制而来,而是由 Client 直接轮询分发。
-
为保证 bookie 能快速 append 日志,bookkeeper 设计了 Journal Append-only 顺序写日志机制。
-
为保证 bookie 能快速根据
(lid, eid)
读取消息
(entry)
,bookkeeper 设计了 Ledger Store
-
因此,各 bookie 存储节点的身份是平等的,没有传统一致性算法的 Leader 和 Follower 的概念,完美避开了读写只能走 Leader 导致 Leader 容易成为单点瓶颈的问题。
同时,能直接添加新 Bookie 提升读写吞吐,并降低其他旧 Bookie 的负载。
7. 总结
7.1 Pulsar 的优点
直接解决 Kafka 容器平台现有的手工扩容、故障恢复慢的问题。
-
稳定性可用性高:秒级 Broker / Bookie 的快速故障恢复。
-
水平线性扩容:存储与计算分离,可对 Broker 扩容提升读写吞吐,可对 Bookie 扩容降低集群负载并提升存储容量。
-
扩容负载均衡:Bookie 扩容后新的 ledger 会在新 Bookie 上创建,自动均摊负载。
7.2 Pulsar 的缺点
-
概念多,系统复杂,隐藏 bug 修复门槛高。
-
背书少,国内仅腾讯金融和智联招聘在使用。
本文地址:
https://yinzige.com/2020/04/24/pulsar-survey/
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug ?