在开发环境中经常需要将处理好的数组进行保存与加载
一、数组保存为二进制文件
1、单个数组的保存与加载
np.save(r’路径\文件名’,数组名)
np.load(r’路径\文件名’)
- 将数组ndarray保存为文件,一般需要指定文件的路径,否则保存到默认路径
- 文件默认为.npy格式
- 加载文件,即可直接加载文件中的数组
实例:数组保存
import datetime as dt
import numpy as np
print('start:',dt.datetime.now())
a=np.array([2,3,6,8])
b=np.array([4,7,5,6])
c=np.array([5,2,2,4])
res=np.array([a,b,c]).reshape(2,3,2)
np.save(r'C:\Users\xyy\Desktop\res',res)
print('文件res.npy已保存:',dt.datetime.now())
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
start: 2021-06-25 11:16:38.015372
文件res.npy已保存: 2021-06-25 11:16:38.016613
实例:数组加载
import numpy as np
res=np.load(r'C:\Users\xyy\Desktop\res.npy')
print('res:\n',res)
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
res:
[[[2 3]
[6 8]
[4 7]]
[[5 6]
[5 2]
[2 4]]]
2、多个数组的保存与加载
np.savez(r’路径\文件名’,参数1=数组1,参数2=数组2,…)
加载打包文件:对象=np.load(r’路径\文件名’)
提取各数组:数组名=对象[‘参数’]
- 其实就是将几个数组对应的.npy文件打包保存到同一个文件中
- 打包文件默认为.npz格式
-
加载打包文件赋给新对象(加载时要加文件后缀.npz),然后用
对象[‘参数’]
即可加载对应数组 - 保存时,若每个数组未给定参数,则默认为arr_0,arr_1依此类推
- np.savez()代表不压缩每个.npy数组文件,直接打包到一起
- np.savez_compressed()代表压缩每个.npy数组文件然后再打包,这样可以减少.npz文件的大小
实例:多数组保存
import datetime as dt
import numpy as np
print('start:',dt.datetime.now())
a=np.array([2,3,6,8])
b=np.array([4,7,5,6])
np.savez(r'C:\Users\xyy\Desktop\a_b',a=a,b=b)
print('文件a_b.npz已保存:',dt.datetime.now())
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
start: 2021-06-25 11:25:04.138222
文件a_b.npz已保存: 2021-06-25 11:25:04.140234
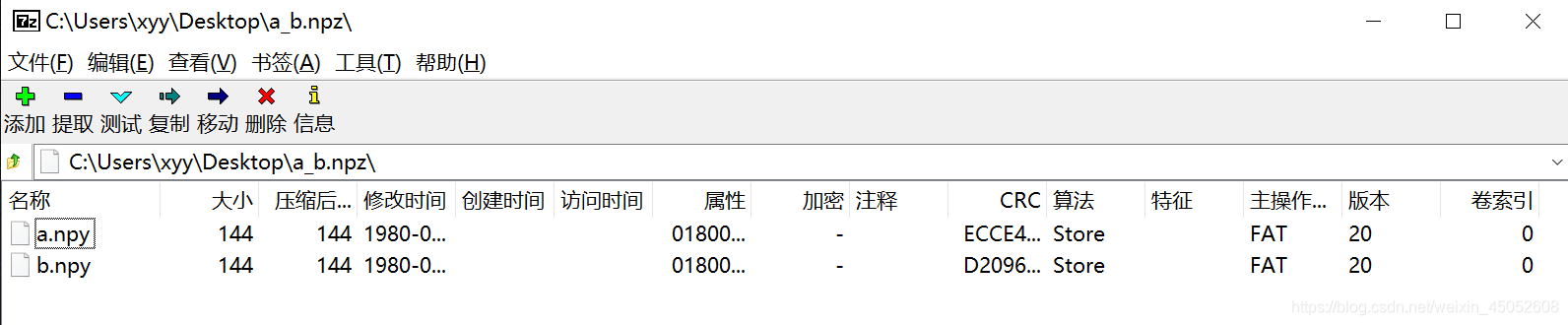
实例:多数组加载
import numpy as np
a_b=np.load(r'C:\Users\xyy\Desktop\a_b.npz')
a=a_b['a']
b=a_b['b']
print('a:\n',a)
print('b:\n',b)
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
a:
[2 3 6 8]
b:
[4 7 5 6]
二、数组保存为文本文件
1、保存
np.savetxt(r’路径\文件名’,数组名,fmt=‘数据格式’,delimiter=’’,newline=’\n’,header=’’,footer=’’,
comments=’#’,encoding=None)
-
只适用于一维、二维数组
- 文件名默认为.txt格式。若后缀为.gz,则保存为.gzip格式;若后缀为.csv,则保存为.csv格式
-
fmt:单个数据格式用于指定所有数据的格式;数据格式列表用于指定每列数据的格式
(eg:’%f’所有数据格式为浮点型;[’%.2f’,’%.4f’]第一列保留两位小数,第二列保留4位小数)
- delimiter:指定列分隔符,默认为空格
- newline:指定行分隔符,默认为回车
- header:文件头部写入内容
- footer:文件尾部写入内容
- comments:文件头部或尾部内容的开头字符串,默认为#
- encoding:使用默认就行
2、加载
np.loadtxt(r’路径\文件名’,dtype=float,
delimiter=None,converters=None,comments=’#’,skiprows=0,usecols=None,unpack=False,encoding=‘bytes’)
- dtype:读取文件后,指定整个文件内容的数据类型,默认为float
- delimiter:读取文件后,对每个数据按照参数进行分隔,默认不分隔
- converters:对列数据进行函数处理再读取,{列号:函数},列号从0开始
- comments:不读取以参数开头的字符串
- skiprows:不读取参数指定的行,行号从1开始
- usecols:只读取参数指定的列,列号从0开始
- unpack:默认为False即将数据按行输出;True指将数据按列输出
- encoding:读取文件时的编码,默认即可
实例:.txt文件的保存与加载
保存
import datetime as dt
import numpy as np
print('start:',dt.datetime.now())
a=np.array([2,3,6,8])
b=np.array([4,7,5,6])
c=np.array([a,b])
np.savetxt(r'C:\Users\xyy\Desktop\c',c,fmt=['%.2f','%.2f','%.1f','%.1f'],delimiter=',',header='(2,4)型数组')
print('文件c.txt已保存:',dt.datetime.now())
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
start: 2021-06-25 12:39:51.345848
文件c.txt已保存: 2021-06-25 12:39:51.349730
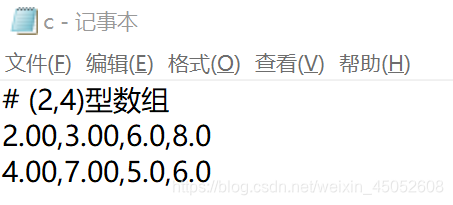
加载
import numpy as np
c=np.loadtxt(r'C:\Users\xyy\Desktop\c',dtype=list)
print('列表c:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c',dtype=list,delimiter=',')
print('列表c,用,分割数据:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c',dtype=list,delimiter=',',converters={2:lambda x:len(x),3:lambda x:x*2})
print('列表c,用,分割数据,第3列数据返回数据长度,第4列数据*2:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c',dtype=list,delimiter=',',converters={2:lambda x:len(x),3:lambda x:x*2},usecols=[0,2,3])
print('列表c,用,分割数据,第3列数据返回数据长度,第4列数据*2,只读取第1、3、4列:\n',c)
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
列表c:
['2.00,3.00,6.0,8.0' '4.00,7.00,5.0,6.0']
列表c,用,分割数据:
[['2.00' '3.00' '6.0' '8.0']
['4.00' '7.00' '5.0' '6.0']]
列表c,用,分割数据,第3列数据返回数据长度,第4列数据*2:
[['2.00' '3.00' 3 b'8.08.0']
['4.00' '7.00' 3 b'6.06.0']]
列表c,用,分割数据,第3列数据返回数据长度,第4列数据*2,只读取第1、3、4列:
[['2.00' 3 b'8.08.0']
['4.00' 3 b'6.06.0']]
实例:.csv文件的保存与加载
保存
import datetime as dt
import numpy as np
print('start:',dt.datetime.now())
dtype=[('name','S10'),('age',int),('grade',float)]
values=[('cindy',18,95.255),('alice',20,86.512)]
c=np.array(values,dtype=dtype)
np.savetxt(r'C:\Users\xyy\Desktop\c.csv',c.T,delimiter=',',fmt=['%s','%f','%.2f'],header='(2,3)型数组')
print('文件c.csv已保存:',dt.datetime.now())
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
start: 2021-06-25 13:55:34.020964
文件c.csv已保存: 2021-06-25 13:55:34.022043
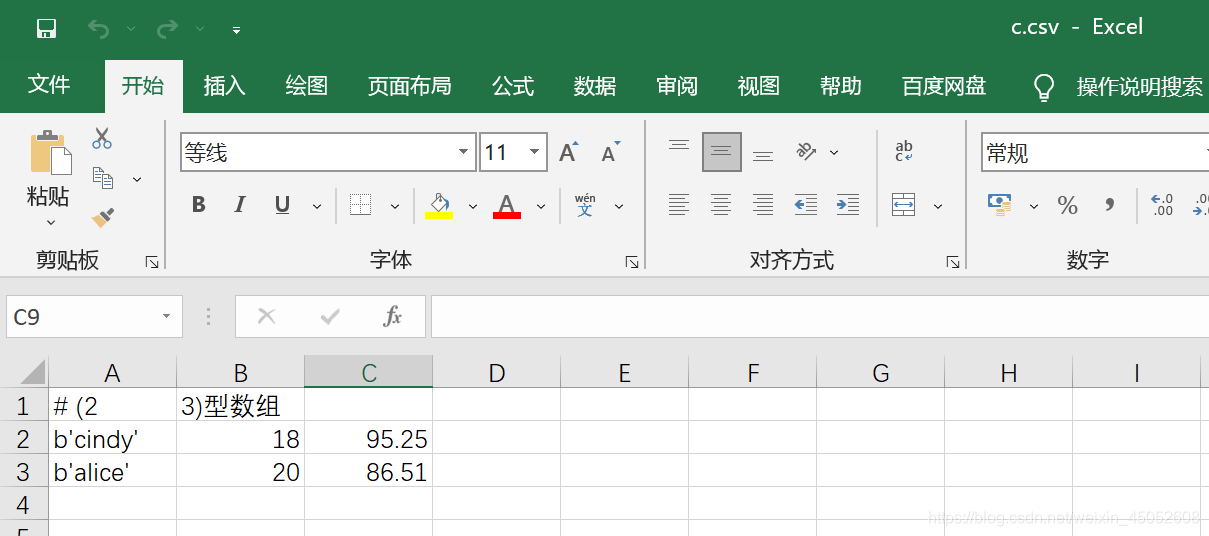
加载
import numpy as np
c=np.loadtxt(r'C:\Users\xyy\Desktop\c.csv',dtype=list)
print('列表c:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c.csv',dtype=list,delimiter=',')
print('列表c,用,分割数据:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c.csv',dtype=list,delimiter=',',converters={0:lambda x:len(x),2:lambda x:x*2})
print('列表c,用,分割数据,第1列数据返回数据长度,第3列数据*2:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c.csv',dtype=list,delimiter=',',converters={0:lambda x:len(x)},usecols=[0,1])
print('列表c,用,分割数据,第1列数据返回数据长度,只读取第1、2列:\n',c)
c=np.loadtxt(r'C:\Users\xyy\Desktop\c.csv',dtype=list,delimiter=',',unpack=True)
print('列表c按,分割数据,按列返回:\n',c)
runfile('C:/Users/xyy/.spyder-py3/temp.py', wdir='C:/Users/xyy/.spyder-py3')
列表c:
["b'cindy',18.000000,95.25" "b'alice',20.000000,86.51"]
列表c,用,分割数据:
[["b'cindy'" '18.000000' '95.25']
["b'alice'" '20.000000' '86.51']]
列表c,用,分割数据,第1列数据返回数据长度,第3列数据*2:
[[8 '18.000000' b'95.2595.25']
[8 '20.000000' b'86.5186.51']]
列表c,用,分割数据,第1列数据返回数据长度,只读取第1、2列:
[[8 '18.000000']
[8 '20.000000']]
列表c按,分割数据,按列返回:
[["b'cindy'" "b'alice'"]
['18.000000' '20.000000']
['95.25' '86.51']]
版权声明:本文为weixin_45052608原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。