利用对称性进行高效的6D姿态检测
本文参考自CVPR2022的这篇文章:ES6D: A Computation Efficient and Symmetry-Aware 6D Pose Regression Framework
Github链接为:https://github.com/GANWANSHUI/ES6D
介绍
在6D姿态检测中,一些具备对称性的物体,比如球、圆盘等,有着多个等价的姿态
那么能否利用这种对称性,对计算精度进行提升呢?
该文章提出了一个全卷积的特征提取网络
XYZNet
,比 PVN3D
[1]
以及 DenseFusion
[2]
要更加高效
[1] Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation.
[2] Densefusion: 6d object pose estimation by iterative dense fusion.
这个工作主要是两个特点:
(1)使用了2D卷积来统一处理深度和RGB信息
(2)考虑了物体的对称性,引入新的误差
技术细节
首先,来看一看整体的计算流程

如上图所示,可以将整个计算流程分成三个部分:
- 局部特征提取
- 空域信息编码
- 特征聚合
局部特征提取 Local Feature Extraction
文章的图示中,RGB图像和XYZ映射是一起送到CNN中得到特征,并没给出十分具体的张量形状,通过分析代码,我们找到以下的相关代码:
class XYZNet(nn.Module):
def __init__(self,
in_channel=3,
strides=[2, 2, 1],
pn_conv_channels=[128, 128, 256, 512]):
super(XYZNet, self).__init__()
self.ft_1 = resnet_extractor(in_channel, strides)
self.ft_2 = spatial_encoder(1024, pn_conv_channels)
def forward(self, xyzrgb):
ft_1 = self.ft_1(xyzrgb)
b, c, h, w = ft_1.size()
rs_xyz = F.interpolate(xyzrgb[:, :3], (h, w), mode='nearest')
ft_2 = self.ft_2(ft_1, rs_xyz)
ft_3 = torch.cat([ft_1, ft_2], dim=1)
return ft_3, rs_xyz
class ES6D(nn.Module):
def __init__(self, num_class=21):
super(ES6D, self).__init__()
self.num_class = num_class
self.xyznet = XYZNet(6)
self.trans = get_header(1024 + 512 + 512, 3 * num_class)
self.prim_x = get_header(1024 + 512 + 512, 4 * num_class)
self.score = get_header(1024 + 512 + 512, num_class)
def forward(self, rgb, xyz, cls_ids):
xyzrgb = torch.cat([xyz, rgb], dim=1)
ft, rs_xyz = self.xyznet(xyzrgb)
b, c, h, w = ft.size()
# ...
可以看到,其中的XYZNet有两个主要部分,一个是
resnet_extractor
, 一个是
spatial_encode
而且在初始化的时候,in_channel被设置成6,很明显,就是将rgb彩色图像和xyz深度图像的通道进行连接
在xyz里面,每一个像素的三个通道内容,便是x和y的像素坐标,以及z的深度
根据代码,这里应该使用的是resnet18作为特征提取器,最红输出一个1024通道的向量
我们不妨记,输入的大小为
[
B
,
6
,
H
,
W
]
[B, 6, H, W]
[
B
,
6
,
H
,
W
]
, 特征提取的输出则为
[
B
,
1024
,
H
1
,
W
1
]
[B, 1024, H_1, W_1]
[
B
,
1024
,
H
1
,
W
1
]
空域信息编码
在得到
[
B
,
1024
,
H
1
,
W
1
]
[B, 1024, H_1, W_1]
[
B
,
1024
,
H
1
,
W
1
]
的输出
f
t
1
ft_1
f
t
1
之后,首先对原来的xyz深度图像进行降采样,变成
[
B
,
3
,
H
1
,
W
1
]
[B, 3, H_1, W_1]
[
B
,
3
,
H
1
,
W
1
]
使用PointNet,以上面两个不同大小的张量作为输入,最终得到
[
B
,
1024
,
H
1
,
W
1
]
[B, 1024, H_1, W_1]
[
B
,
1024
,
H
1
,
W
1
]
形状的张量
f
t
2
ft_2
f
t
2
这边的结果是笔者测试了其部分代码得到的,具体的计算流程请查看
https://github.com/GANWANSHUI/ES6D/blob/master/models/pointnet.py
随后,将
f
t
1
ft_1
f
t
1
和
f
t
2
ft_2
f
t
2
连接起来,得到
[
B
,
2048
,
H
1
,
W
1
]
[B, 2048, H_1, W_1]
[
B
,
2048
,
H
1
,
W
1
]
的张量
特征聚合
继续看ES6D的代码,主要看他的forward函数,如下所示
¥def forward(self, rgb, xyz, cls_ids):
# 连接RGB图像和深度图像的通道
xyzrgb = torch.cat([xyz, rgb], dim=1)
ft, rs_xyz = self.xyznet(xyzrgb)
b, c, h, w = ft.size() # 得到特征提取后的张量形状
# 使用多个1x1的卷积+ReLU+BN的序列,不改变张量宽高,只改变通道数
px = self.prim_x(ft)
tx = self.trans(ft)
sc = F.sigmoid(self.score(ft))
cls_ids = cls_ids.view(b).long()
obj_ids = torch.tensor([i for i in range(b)]).long().cuda()
px = px.view(b, -1, 4, h, w)[obj_ids, cls_ids]
tx = tx.view(b, -1, 3, h, w)[obj_ids, cls_ids]
sc = sc.view(b, -1, h, w)[obj_ids, cls_ids]
# pr[bs, 4, h, w], tx[bs, 3, h, w], xyz[bs, 3, h, w]
tx = tx + rs_xyz
# res is the final result
return {'pred_r': px.contiguous(),
'pred_t': tx.contiguous(),
'pred_s': sc.contiguous(),
'cls_id': cls_ids.contiguous()}
可以看到,在使用
XYZNet
之后,得到了两个返回,一个是降采样后的深度图,一个是拼接后的特征
经过三个分支,分别预测物体的旋转,平移,以及类别分数
这里使用四元数对旋转进行建模,所以输出是4个通道的
对称性关联的误差
经过上述的技术细节分析之后,我们其实已经能够对旋转、平移等信息去做回归的训练,
这里文章引入一种新的对称性关联的误差。首先,由于物体的对称特征,我们可以构建出多个群
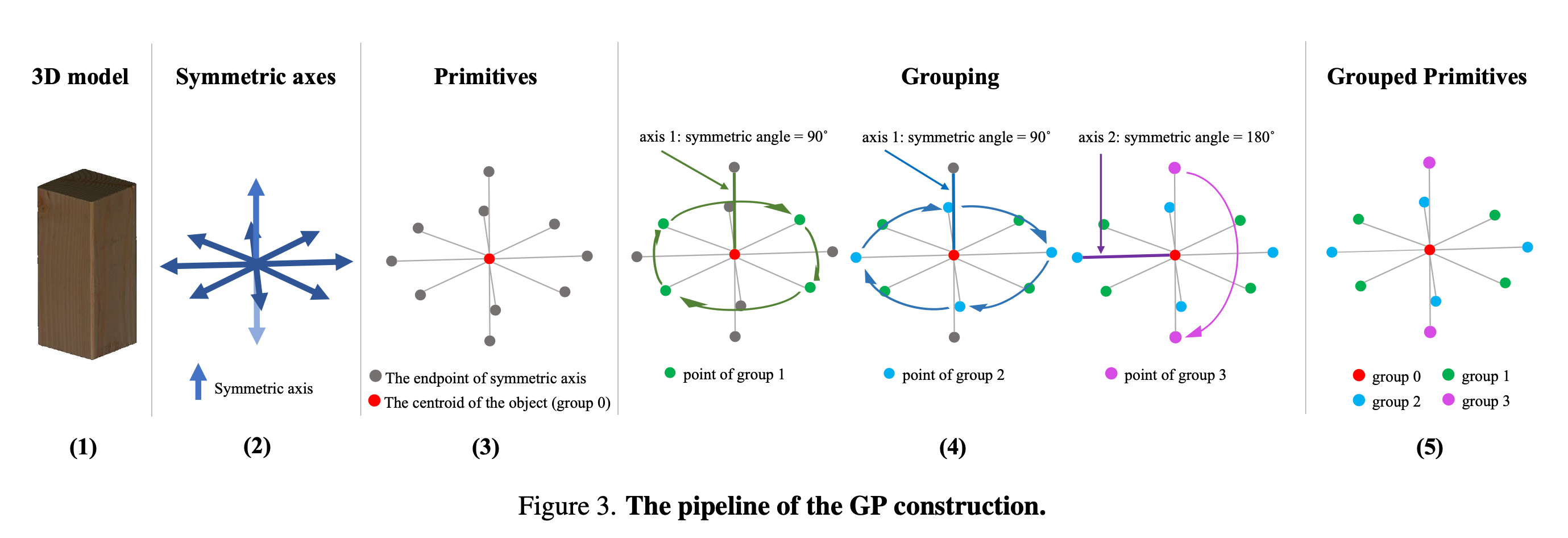
首先找到对称轴,然后构建出一些原语(primitives),代表一些基础的姿态,然后利用旋转90度、180度去构造群
那么这些个群有什么用呢?我们在计算姿态估计误差的时候,有时候真实的姿态标记忽略了对称性,这样我们的误差就可能过度估计了
因此,只需要在计算姿态误差的时候,查找每一个群,并且只算误差最小的那个姿态即可
也就是文章给出的
Maximum Grouped Primitives Distance
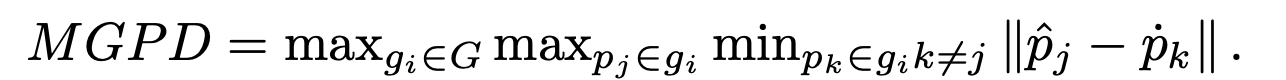
实验分析
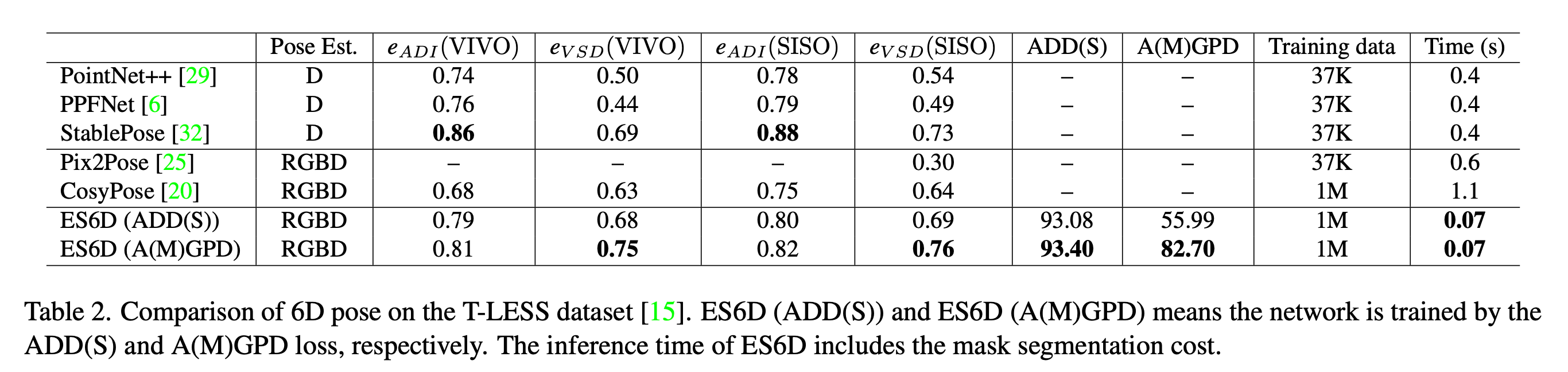
首先在YCB-Video数据集上进行测试,可以看到,相比较PVN3D以及DenseFusion其精度具备优势,
但是这里比较的都是一些有对称性的物体
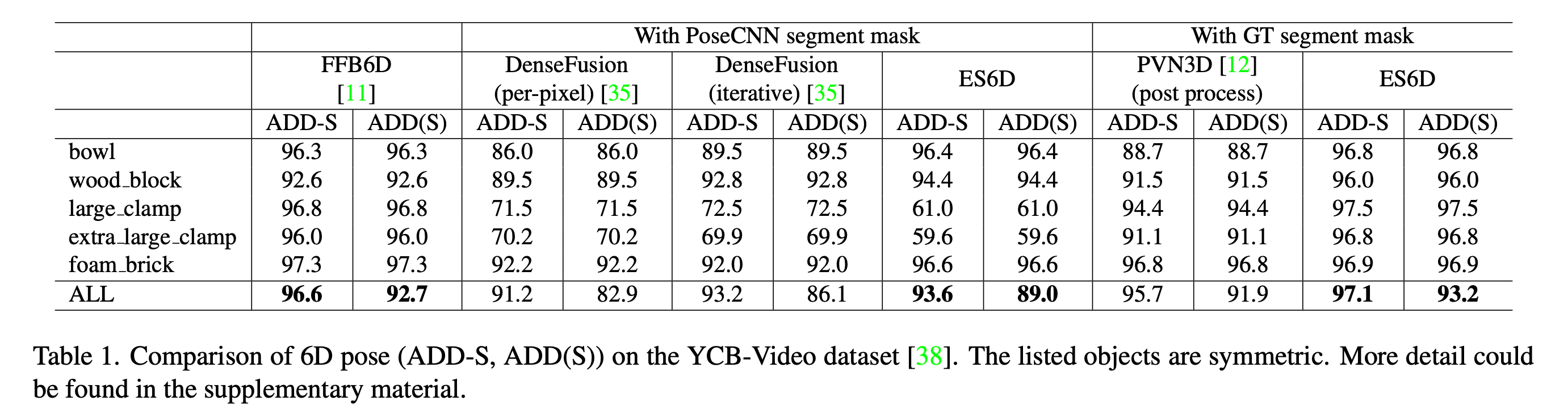
在T-Less数据集上,和StablePose互有胜负(但是StablePose是只有深度信息),速度也很快,70ms就可以实现推断