多行输入,一个结果
实现 UDAF 需要实现两个类
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver2
UDAF入口类
负责参数校验,决定UDAF核心逻辑实现类
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
UDAF核心逻辑实现类
负责数据聚合
案例
为了更加直观,本篇文章将以实现
计算平均数
的案例来讲解
功能:计算平均数
参数类型:num int
返回值类型:avg double
GenericUDAFResolver2
GenericUDAFResolver2 是 UDAF 的入口类,负责参数检验
实现 GenericUDAFResolver2 接口,并实现其方法即可
public class Avg implements GenericUDAFResolver2 {
/**
* UDAF入口函数
* 负责:
* 1. 参数校验
* 2. 返回UDAF核心逻辑实现类
*/
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
ObjectInspector[] parameters = info.getParameterObjectInspectors();
// 1. 参数个数校验
if (parameters.length != 1)
throw new UDFArgumentException("只接受一个参数");
// 2. 参数类型校验
else if (parameters[0].getCategory() != ObjectInspector.Category.PRIMITIVE ||
((PrimitiveObjectInspector)parameters[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.INT)
throw new UDFArgumentException("第一个参数是int");
// 3. 可以获取参数的其他信息
if (info.isAllColumns()) // 函数参数是否为 *
System.out.println("FUNCTION(*)");
if (info.isDistinct()) // 函数参数是否被 DISTINCT 修饰
System.out.println("FUNCTION(DISTINCT xxx)");
if (info.isWindowing()) // 是否是窗口函数
System.out.println("FUNCTION() OVER(xxx)");
// 3. UDAF核心逻辑实现类
return new AvgEvaluator();
}
/**
* 该方法是用于兼容老的UDAF接口,不用实现
* 如果通过 AbstractGenericUDAFResolver 实现 Resolver,则该方法作为 UDAF 的入口
*/
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException {
throw new UDFArgumentException("方法未实现");
}
}
GenericUDAFEvaluator
GenericUDAFEvaluator 是 UDAF 的核心逻辑实现,需要实现的方法较多,而且不同的
模式
下会调用不同的方法
在实现 GenericUDAFEvaluator 之前,首先需要理解它的
四个模式
Mode
GenericUDAFEvaluator 内部有一个 Mode 枚举类,并且有一个对应的成员变量
Mode 对应了 MapReduce 中的一些阶段,其详细信息请见下方代码
/**
* UDAF入口函数类
*/
public abstract class GenericUDAFEvaluator implements Closeable {
/**
* Mode.
*
*/
public static enum Mode {
/**
* 读取原始数据,聚合部分数据,获得部分聚合结果
* 调用:iterate()、terminatePartial()
* 对应 Map 阶段(不包括Combiner)
*/
PARTIAL1,
/**
* 读取部分聚合结果,再做部分聚合,获得新的部分聚合结果
* 调用:merge()、terminatePartial()
* 对应 Map 的 Combiner 阶段
*/
PARTIAL2,
/**
* 读取部分聚合结果,进行全局聚合,获得全局聚合结果
* 调用:merge()、terminate()
* 对应 Reduce 阶段
*/
FINAL,
/**
* 读取原始数据,直接进行全局聚合,获得全局聚合结果 and
* 调用:iterate()、terminate()
* 对应 Map Only 任务,只有 Map 阶段
*/
COMPLETE
};
Mode mode;
}
各个Mode调用的方法如下
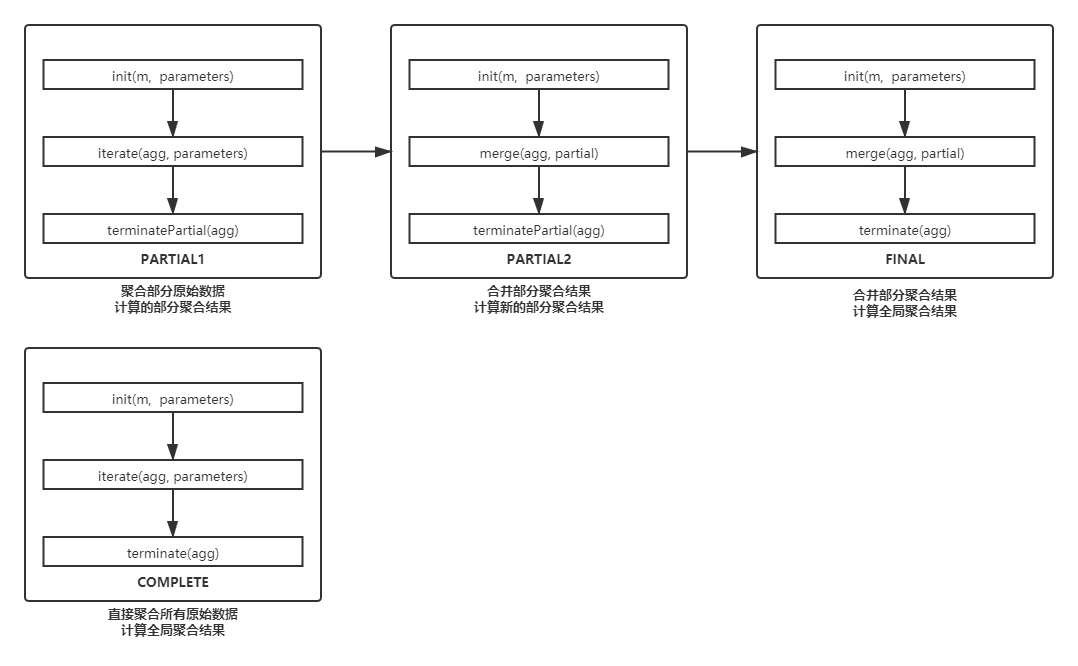
AggregationBuffer
聚合过程中,用于保存中间结果的 Buffer
核心函数
| 函数 | 描述 |
|---|---|
| getNewAggregationBuffer() | 获取一个新的 Buffer,用于保存中间计算结果 |
| reset(agg) | 重置 Buffer,在 Hive 程序执行时,可能会复用 Buffer 实例 |
|
init (m,parameters) |
各个模式下,都会调用该方法进行初始化。校验上一阶段的参数,并且决定该阶段的输出 |
|
iterate (agg, parameters) |
读取原始数据,计算部分聚合结果 |
|
terminatePartial (agg) |
输出部分聚合结果 |
|
merge (agg, partial) |
合并部分聚合结果 |
|
terminate (agg) |
输出全局聚合结果 |
核心函数的调用过程如下:

实现代码
/**
* UDAF核心逻辑类
*/
public class AvgEvaluator extends GenericUDAFEvaluator {
/**
* 聚合过程中,用于保存中间结果的 Buffer
* 继承 AbstractAggregationBuffer
* <p>
* 对于计算平均数,我们首先要计算总和(sum)和总数(count)
* 最后用 总和 / 总数 就可以得到平均数
*/
private static class AvgBuffer extends AbstractAggregationBuffer {
// 总和
private Integer sum = 0;
// 总数
private Integer count = 0;
}
/**
* 初始化
*
* @param m 聚合模式
* @param parameters 上一个阶段传过来的参数,可以在这里校验参数:
* 在 PARTIAL1 和 COMPLETE 模式,代表原始数据
* 在 PARTIAL2 和 FINAL 模式,代表部分聚合结果
* @return 该阶段最终的返回值类型
* 在 PARTIAL1 和 PARTIAL2 模式,代表 terminatePartial() 的返回值类型
* 在 FINAL 和 COMPLETE 模式,代表 terminate() 的返回值类型
*/
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
if (m == Mode.PARTIAL1 || m == Mode.PARTIAL2) {
// 在 PARTIAL1 和 PARTIAL2 模式,代表 terminatePartial() 的返回值类型
// terminatePartial() 返回的是部分聚合结果,这时候需要传递 sum 和 count,所以返回类型是结构体
List<ObjectInspector> structFieldObjectInspectors = new LinkedList<ObjectInspector>();
structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.writableIntObjectInspector);
structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.writableIntObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(
Arrays.asList("sum", "count"),
structFieldObjectInspectors
);
} else {
// 在 FINAL 和 COMPLETE 模式,代表 terminate() 的返回值类型
// 该函数最终返回一个 double 类型的数据,所以这里的返回类型是 double
return PrimitiveObjectInspectorFactory.writableDoubleObjectInspector;
}
}
/**
* 获取一个新的 Buffer,用于保存中间计算结果
*/
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
// 直接实例化一个 AvgBuffer
return new AvgBuffer();
}
/**
* 重置 Buffer,在 Hive 程序执行时,可能会复用 Buffer 实例
*
* @param agg 被重置的 Buffer
*/
public void reset(AggregationBuffer agg) throws HiveException {
// 重置 AvgBuffer 实例的状态
((AvgBuffer) agg).sum = 0;
((AvgBuffer) agg).count = 0;
}
/**
* 读取原始数据,计算部分聚合结果
*
* @param agg 用于保存中间结果
* @param parameters 原始数据
*/
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
if (parameters == null || parameters[0] == null)
return;
if (parameters[0] instanceof IntWritable) {
// 计算总和
((AvgBuffer) agg).sum += ((IntWritable) parameters[0]).get();
// 计算总数
((AvgBuffer) agg).count += 1;
}
}
/**
* 输出部分聚合结果
*
* @param agg 保存的中间结果
* @return 部分聚合结果,不一定是一个简单的值,可能是一个复杂的结构体
*/
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
// 传递中间结果时,必须传递 总和、总数
// 这里需要返回一个数组,表示结构体
return new Object[]{
new IntWritable(((AvgBuffer) agg).sum),
new IntWritable(((AvgBuffer) agg).count)
};
}
/**
* 合并部分聚合结果
* 输入:部分聚合结果
* 输出:部分聚合结果
*
* @param agg 当前聚合中间结果类
* @param partial 其他部分聚合结果值
*/
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
if (partial != null) {
((AvgBuffer) agg).sum += ((IntWritable) ((LazyBinaryStruct) partial).getField(0)).get();
((AvgBuffer) agg).count += ((IntWritable) ((LazyBinaryStruct) partial).getField(1)).get();
}
}
/**
* 输出全局聚合结果
*
* @param agg 保存的中间结果
*/
public Object terminate(AggregationBuffer agg) throws HiveException {
// 总和 / 总数
return new DoubleWritable(1.0 * ((AvgBuffer) agg).sum / ((AvgBuffer) agg).count);
}
}
版权声明:本文为qq_38783098原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。