前段时间做过语音识别相关的内容,先把小组整理的文档发布出来,供大家参考。
一、语音预处理
在对语音信号进行分析和处理之前,必须对其进行预加重、分帧、加窗等预处理操作。这些操作的目的是尽可能减小因为人类发声器官本身和由于采集语音信号的设备所带来的混叠、高次谐波失真、高频等等因素对语音信号质量的影响。保证后续语音处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高语音处理质量。
1.1预加重 (Pre-emphasis)
定义:
预加重是一种在发送端对输入信号高频分量进行补偿的信号处理方式。随着信号速率的增加,信号在传输过程中受损很大,为了在接收终端能得到比较好的信号波形,就需要对受损的信号进行补偿,预加重技术的思想就是在传输线的始端增强信号的高频成分,以补偿高频分量在传输过程中的过大衰减。而预加重对噪声并没有影响,因此有效地提高了输出信噪比。
对语音进行预加重处理的原因:
(1) 平衡频谱,因为高频相较于低频通常具有较小的幅度。声道的终端为口和唇。从声道输出的是速度波,而语音信号是声压波,二者之比的倒数称为辐射阻抗。它表征口和唇和辐射效应,也包括圆形头部的绕射效应等。语音信号s(n)的平均功率谱受声门激励和口鼻辐射的影响,高频端大约在800Hz以上按6dB/oct (倍频程)衰减,频率越高相应的成分越小,为此要在对语音信号s(n)进行分析之前对其高频部分加以提升。
(2) 避免在傅里叶变换操作期间的数值问题;
(3) 改善信噪比
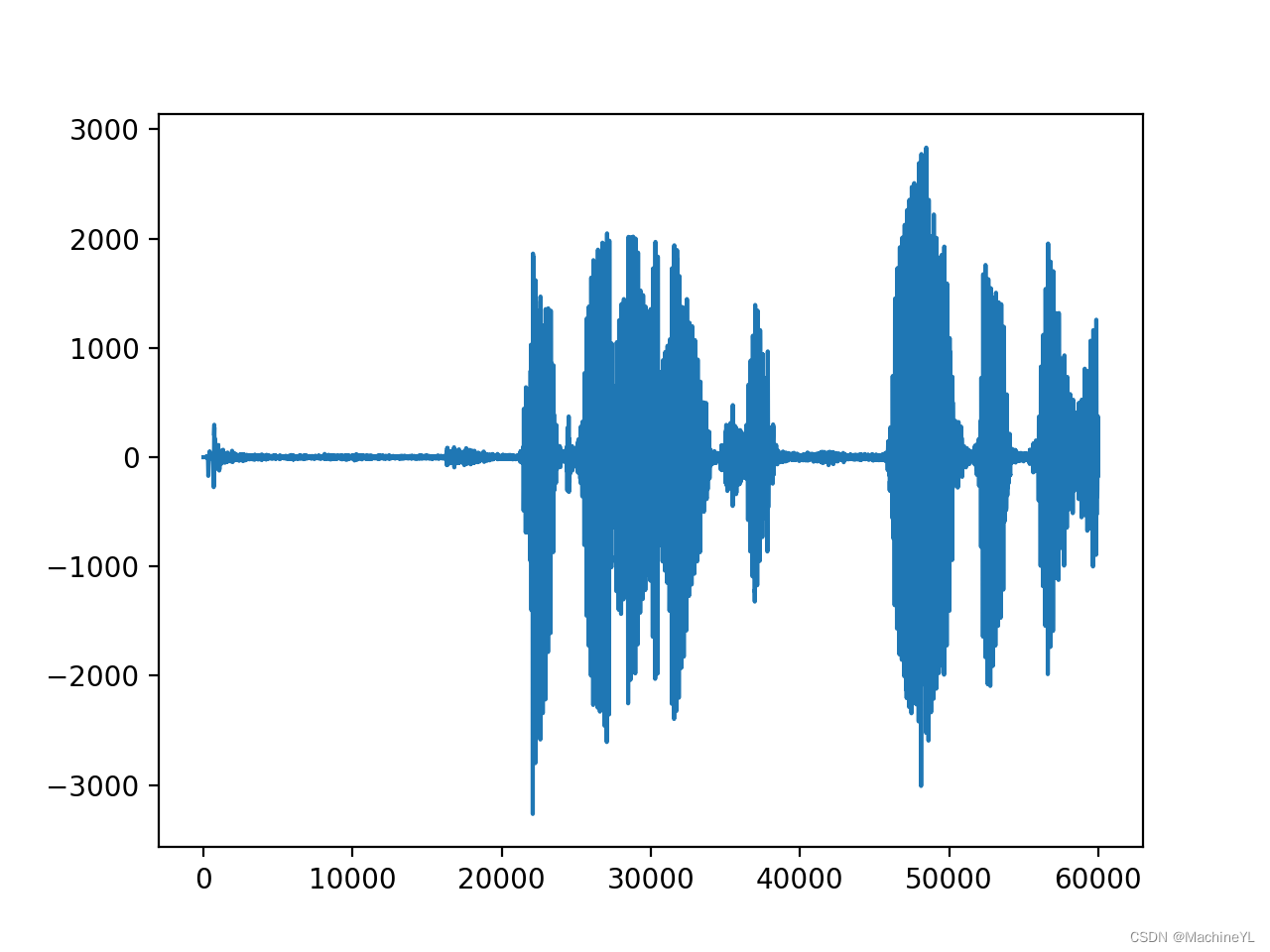
预加重前
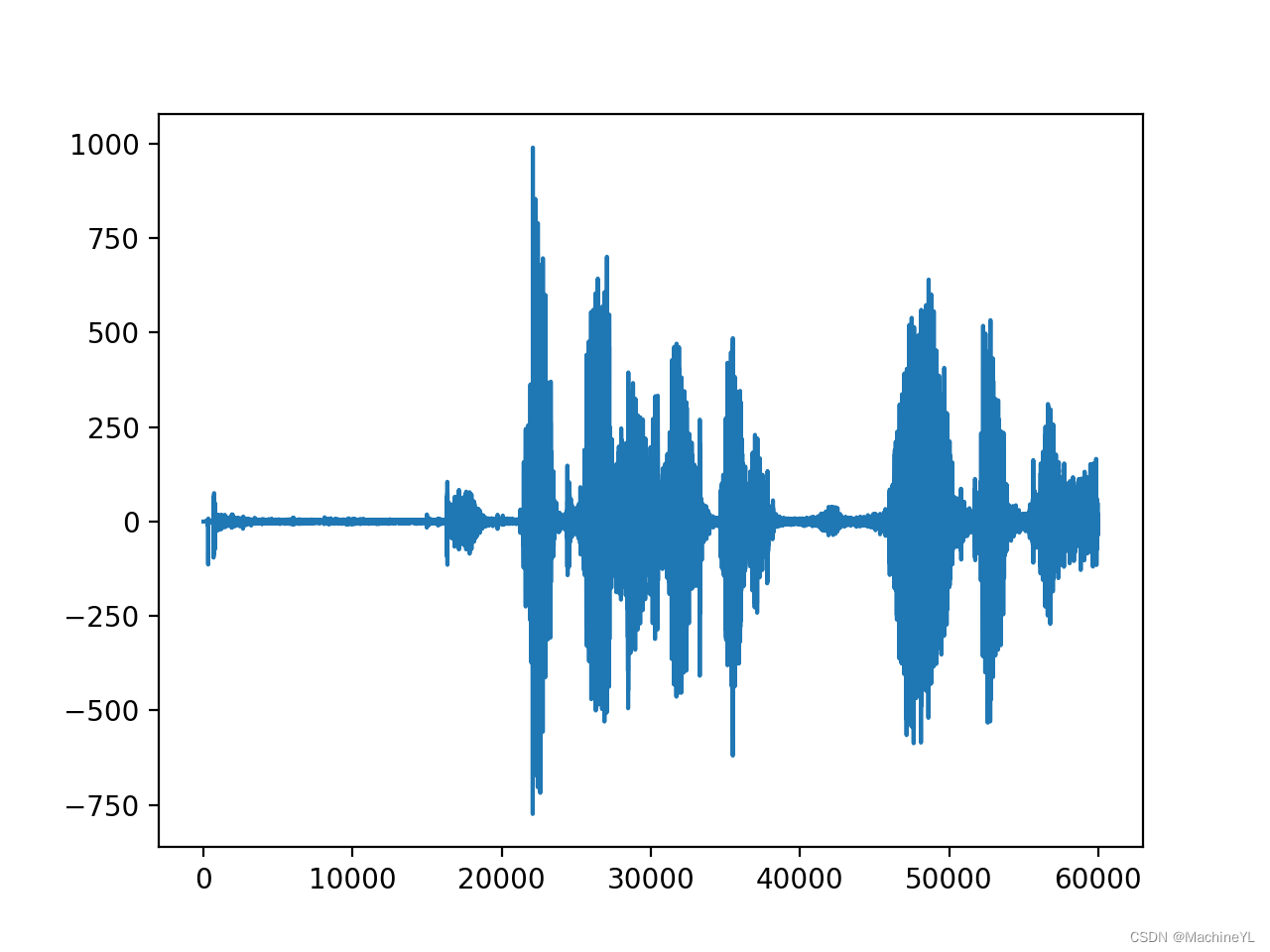
预加重后
1.2分帧 (Framing)
分帧的原因
算法在处理语音信号时,一般首先采用的是傅里叶变化,将语音信号由时域转换到频域空间。傅里叶变化是针对周期函数的,这是它的限制所在。语音信号,其频率是不断变化的,也就是“非周期性”的。如果直接将这样长的语音信号进行傅里叶变换,是很难获得其信号频率的良好近似的。那么如何采用傅里叶变化对语音信号进行处理呢?
这就需要考虑到语音的特性了。语音在较短的时间内变化是平稳的,即具有”短时平稳性“(10-30ms内可以认为语音信号近似不变),因此可以将长语音截断为短的片段,进行“短时分析”。我们可以认为这段短时语音是具有周期性的,可以对其进行周期延拓。这样就得到了一个周期函数,可以进行傅里叶变换了。 上面中”短的片段“,每一个短的片段称为”一帧“。将不定长的音频切分成固定长度的小段,这一步称为分帧。
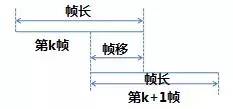
帧长和帧移
帧长就是每一帧的时间长度,一般取20mx-40ms.
帧移就是每次处理完一帧后向后移动的步长,一般设置与帧长有 50%(+/-10%)的重叠。
设置帧移的目的
(1)考虑不设置帧移的情况。对于一个100ms长的音频,取frame size =25ms,那么可以得到4帧,[0,25), [25,50), [50,75),[75,100),每一帧经过处理后得到一个值,这个值可以看做对应帧的特征表征,那么最终也就得到4个值。
(2)考虑设置帧移的情况。同样取frame size = 25ms, frame stride = 10ms, 那么可以得到9帧,[0, 25), [9, 34), [19, 44)…[89, 100),每一帧经过处理后得到一个值,那么最终可以得到9个值。相比较,2中可以提取到更为细致而丰富的语音信息,因为显然其处理的粒度比1小很多,也可以更好地捕获到1中相邻两帧的边缘信息。(举个例子,对于1中25ms附近的语音信号特征,只在第二帧[25,50)中进行了提取;在2中,[0,25),[9,34),[19,44)这三帧都对其进行了特征提取,所以更为平滑准确。)
1.3加窗
在上面进行分帧后,需要对帧加窗函数。
为什么需要加窗函数
(1) 截取一小段音频以便进行周期性延拓与傅里叶变换
(2) 不同的窗函数的频谱泄漏不同,可以根据数据与任务要求进行选择
仍然承接以上分帧的思路,运用计算机实现工程测试信号处理时,不可能对无限长的信号进行测量和运算,而是取其有限的时间片段进行分析。做法是从信号中截取一个时间片段,然后用截取的信号时间片段进行周期延拓处理,得到虚拟的无限长的信号,然后就可以对信号进行傅里叶变换、相关分析等数学处理。那么窗函数就需要是在某一区间内有非零值,而在其余区间值几乎为0,那么用该函数f, 乘以任何一个其他函数g, f * g只有一部分有非零值。这里的f即为窗函数,g即为我们的音频,这样就可以截取出一小段音频了。
无限长的信号被截断以后,其频谱发生了畸变,原来集中在f(0)处的能量被分散到两个较宽的频带中去了(这种现象称之为频谱能量泄漏)。
也可以想象成,如果将原波形在窗口两端直接截断,使其取值为0,这就为在进行傅里叶变换,也就是进行时域到频域的变换时,为了要拟合这个突然降为0的波形,需要引入高频成分,那么这样进行傅里叶变换的结果并不能很好的反应原音频的真实情况了。
为了减少频谱能量泄漏,所以需要用这种在两端平滑变为0的窗函数,以避免谱泄露。
窗函数的选择
不同的窗函数对信号频谱的影响是不一样的,这主要是因为不同的窗函数,产生泄漏的大小不一样,频率分辨能力也不一样。信号的截断产生了能量泄漏,而用FFT算法计算频谱又产生了栅栏效应,从原理上讲这两种误差都是不能消除的,但是我们可以通过选择不同的窗函数对它们的影响进行抑制。(矩形窗主瓣窄,旁瓣大,频率识别精度最高,幅值识别精度最低;布莱克曼窗主瓣宽,旁瓣小,频率识别精度最低,但幅值识别精度最高)。
窗函数_百度百科
中对矩形窗、三角窗、汉宁窗(Hanning)、海明窗(Hamming)、高斯窗进行了比较。
几种常见窗函数的特性_greedyhao的博客-CSDN博客_布莱克曼窗函数
中则显示了窗函数及其主旁瓣衰减的图示。
(1) 矩形窗
这种窗的优点是主瓣比较集中,缺点是旁瓣较高,并有负旁瓣,导致变换中带进了高频干扰和泄漏,甚至出现负谱现象。
(2) 汉宁窗 (Hanning)
汉宁窗主瓣加宽并降低,旁瓣则显著减小,从减小泄漏观点出发,汉宁窗优于矩形窗.但汉宁窗主瓣加宽,相当于分析带宽加宽,频率分辨力下降。
(3) 海明窗 (Hamming)
海明窗与汉宁窗都是余弦窗,只是加权系数不同。海明窗加权的系数能使旁瓣达到更小。分析表明,海明窗的第一旁瓣衰减为一42dB.海明窗旁瓣衰减速度为20dB/(10oct),这比汉宁窗衰减速度慢。海明窗与汉宁窗都是很有用的窗函数。
二、端点检测
(Voice Activity Detection,VAD)
2.1理论基础:
STE:
短时能量
,即一帧语音信号的能量
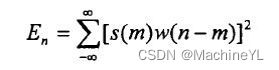
(语音和噪声的区别可以体现在它们的能量上,语音段的能量比噪声段能量大,语音段的能量是噪声段叠加语音波能量的和。)
ZCC:
过零率
,即一帧语音时域信号穿过0(时间轴)的次数
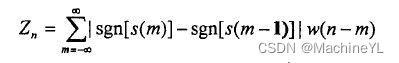
(过零率有两类重要的应用。第一,用于粗略的描述信号的频谱特性;第二,用于判别清音和浊音、有话和无话。)
在信噪比(SNR)不是很低的情况下,语音片段的STE相对较大,而ZCC相对较小;而非语音片段的STE相对较小,但是ZCC相对较大。因为语音信号能量绝大部分包含在低频带内,而噪音信号通常能量较小且含有较高频段的信息。
故而可以通过测量语音信号的这两个特征并且与两个门限(阈值)进行对比,从而判断语音信号与非语音信号
可以将一段语音片段分为 静音段、过渡段、语音段、结束。
2.2检测方法:
首先为短时能量和过零率分别设置两个门限,一个较低的门限对信号变化比较敏感,很容易超过;和一个比较高的门限。低门限被超过未必是语音的开始,有可能是很短的噪声引起的,高门限被超过,并且接下来自定义的时间内语音超过低门限,则意味着语音开始。
设开始为静音段,若能量或过零率超过低门限,标记起始点,进入过渡段。过渡段若两个参数值都落到低门限以下,则当前状态重新进入静音段。若其中有一个参数超过高门限,则认为进入语音段,在语音段期间,两个参数降到门限以下,且持续时间大于预先设置的最短时间门限,则标记结束。持续时间小于预先设置的最短时间门限则视该段为噪音。
三、噪声抑制
(Noise Reduction)
3.1理论基础
前面提到,实际采集到的音频通常会有一定强度的背景音,这些背景音一般是背景噪音,当背景噪音强度较大时,会对语音应用的效果产生明显的影响,比如语音识别率降低,端点检测灵敏度下降等,因此,在语音的前端处理中,进行噪声抑制也是是很有必要的。
噪声有很多种,既有频谱稳定的白噪声,又有不稳定的脉冲噪声和起伏噪声,在语音应用中,稳定的背景噪音最为常见,技术也最成熟,效果也最好。这里仅讨论稳定的白噪声,即总是假设背景噪声的频谱是稳定或者是准稳定的。前面的语音端点检测是在时域上进行的,降噪的过程则是在频域上进行的。
噪音抑制的关键是提取出噪声的频谱,然后将含噪语音根据噪声的频谱做一个反向的补偿运算,从而得到降噪后的语音
假设音频起始处的一小段语音是背景音,这一假设非常重要,因为这一小段背景音也是背景噪声,是提取噪声频谱的基础。
3.2降噪过程:
首先将这一小段背景音进行分帧,并按照帧的先后顺序进行分组,每组的帧数可以为10或其他值,组的数量一般不少于5,随后对每组背景噪声数据帧使用傅里叶变换得到其频谱,再将各频谱求平均后得到背景噪声的频谱。

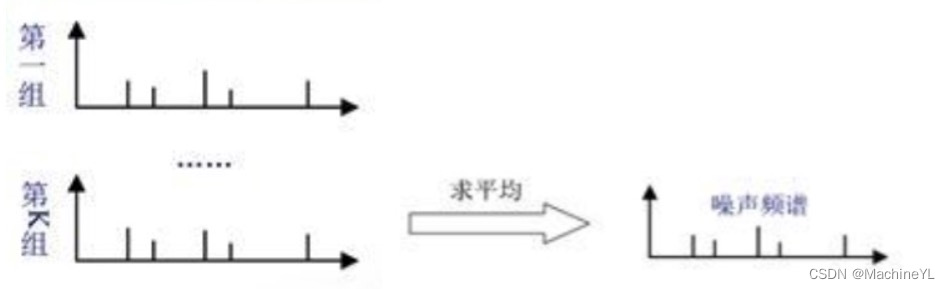
得到噪声的频谱后,降噪的过程就非常简单了,下图左侧的图中红色部分即为噪声的频谱,黑色的线为有效语音信号的频谱,两者共同构成含噪语音的频谱,用含噪语音的频谱减去噪音频谱后得到降噪后语音的频谱,再使用傅里叶逆变换转回到时域中,从而得到降噪后的语音
