1. 常见的机器学习模型融合方式
-
Voting
假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。 -
Averaging
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6 -
Bagging
Bagging主要分为两步:
a.重复K次有放回抽样,训练抽样的子模型
b.模型融合:voting or Avreraging
经典算法:随机森林 -
Boosting
关于Boosting,加州大学欧文分校Alex Ihler教授的两页PPT十分经典。核心思想是:每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
经典算法:AdaBoost、GBDT
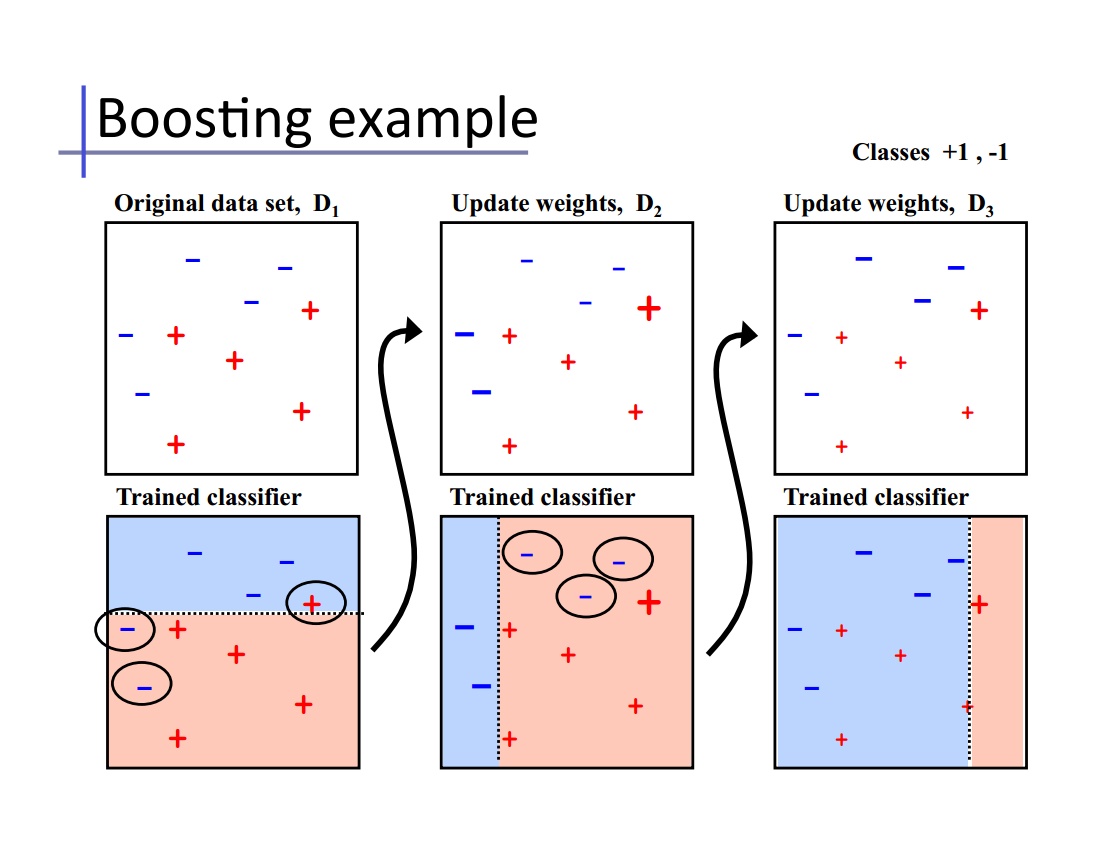
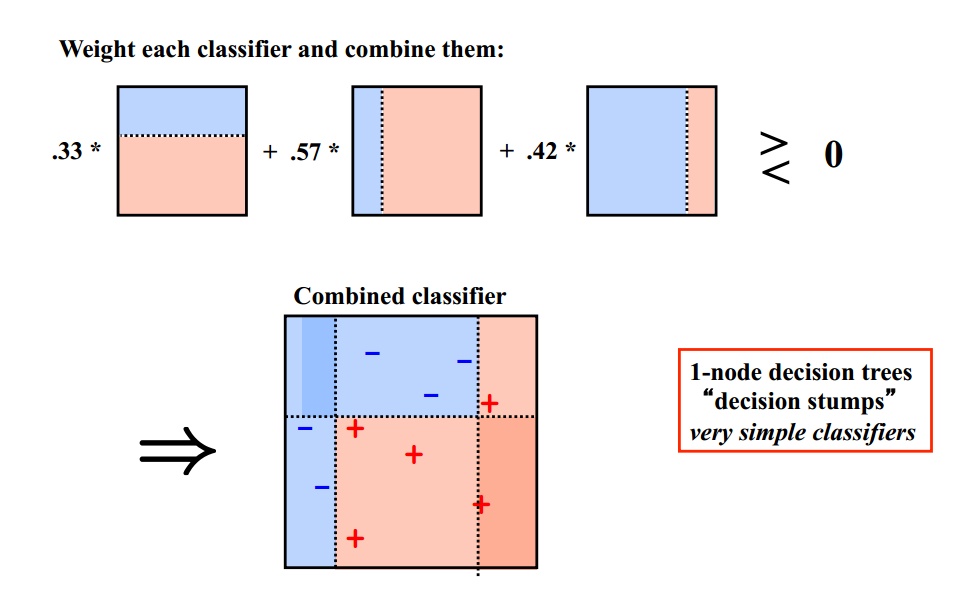
-
Stacking
Stacking基本思想是使用大量基分类器,然后使用另一种分类器来融合它们的预测结果,旨在降低泛化误差。
Stacking算法分为2层,第一层是用不同的算法形成T个基础分类器,同时产生一个与原数据集大小相同的新数据集,利用这个新数据集和一个新算法构成第二层的分类器。在训练第二层分类器时采用各基础分类器的输出作为输入,第二层分类器的作用就是对基础分类器的输出进行集成
对于5-fold交叉验证的Stacking,可以参考这张图:

一定要注意,
对于每一轮的 5-fold,Model 1都要做满5次的训练和预测。
(这里有个坑,原图中最上面是Model1-Mode5,具有误导性)
参考资料:
【机器学习】模型融合方法概述
Kaggle机器学习之模型融合(stacking)心得
天池大赛:街景字符编码识别——Part5:模型集成
2.深度学习中的集成方法
常用的本地验证集划分方法如下:
留出法(Hold-Out):
直接将训练集划分成两部分,新的训练集和验证集。这种划分方式的优点是最为直接简单;缺点是只得到了一份验证集,有可能导致模型在验证集上过拟合。留出法应用场景是数据量比较大的情况。
交叉验证法(Cross Validation,CV)
将训练集划分成K份,将其中的K-1份作为训练集,剩余的1份作为验证集,循环K训练。这种划分方式是所有的训练集都是验证集,最终模型验证精度是K份平均得到。这种方式的优点是验证集精度比较可靠,训练K次可以得到K个有多样性差异的模型;CV验证的缺点是需要训练K次,不适合数据量很大的情况。
自助采样法(BootStrap)
通过有放回的采样方式得到新的训练集和验证集,每次的训练集和验证集都是有区别的。这种划分方式一般适用于数据量较小的情况。
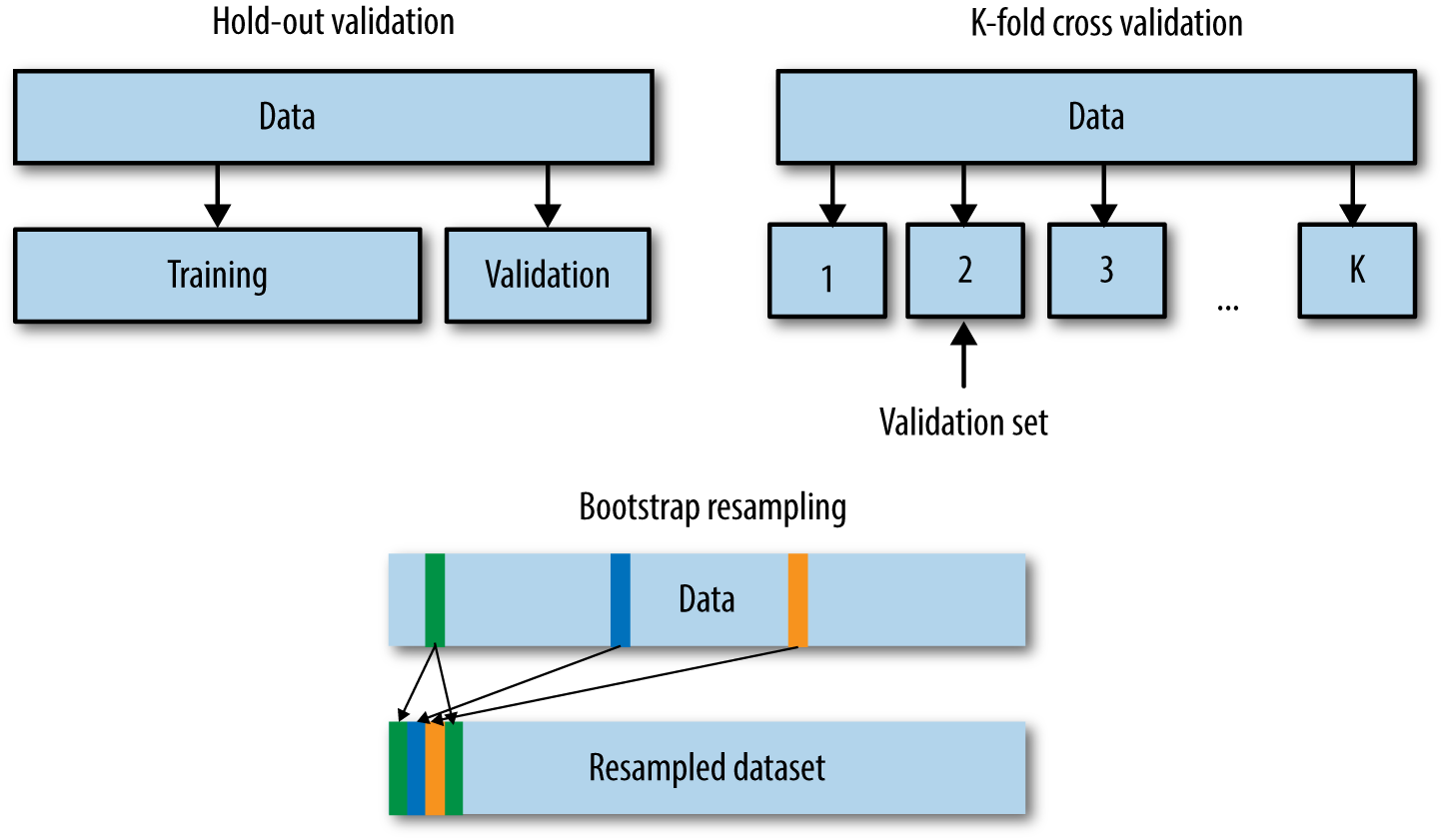
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交叉验证的方法。
下面假设构建了10折交叉验证,训练得到10个CNN模型。
在深度学习中本身还有一些集成学习思路的做法,值得借鉴学习:
2.1 Dropout
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。
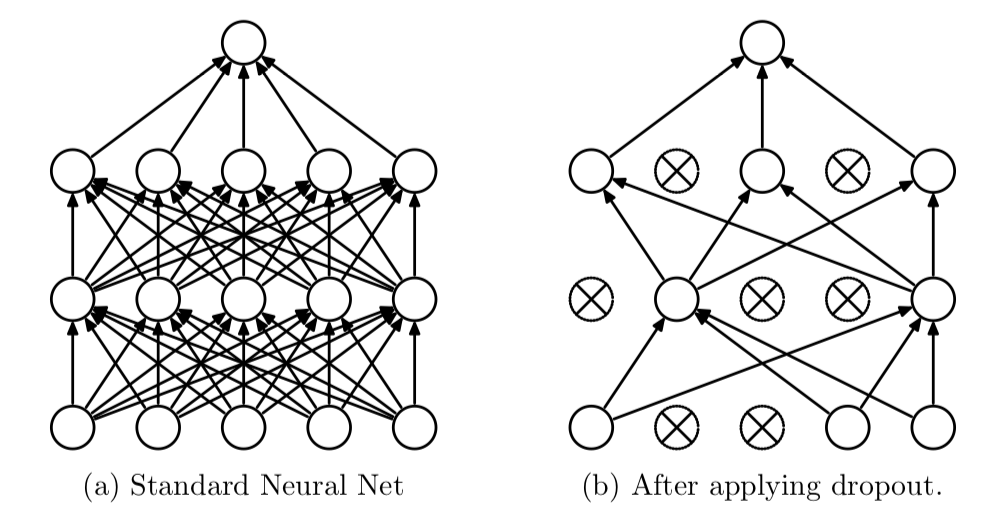
Dropout经常出现在在先有的CNN网络中,可以有效的缓解模型过拟合的情况,也可以在预测时增加模型的精度。
2.2 TTA
测试集数据扩增(Test Time Augmentation,简称TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。
2.3 Snapshot
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。
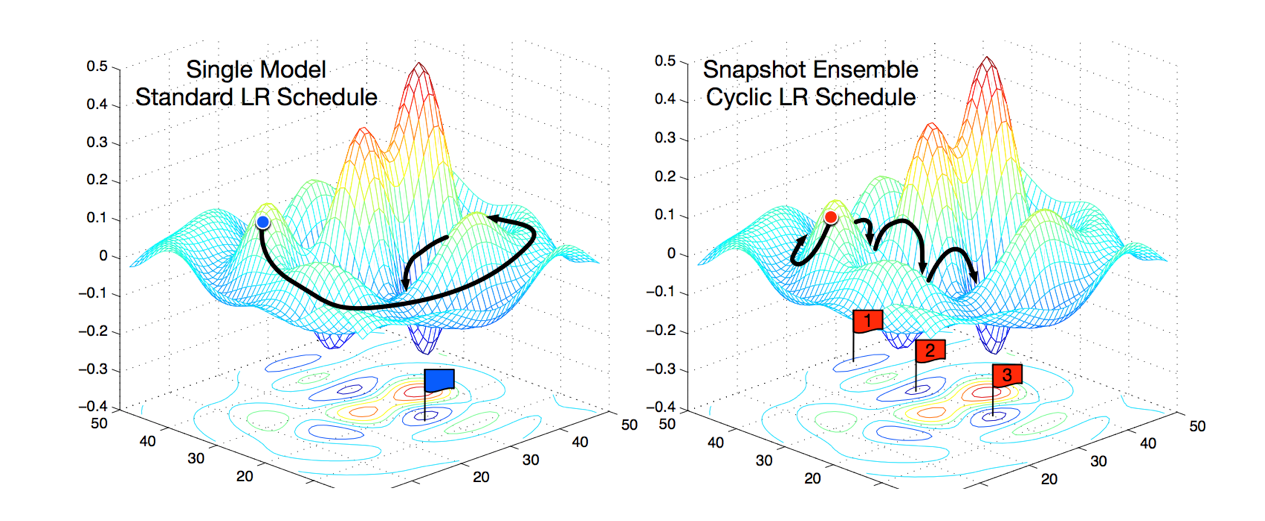
由于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。