基于CNN卷积神经网络的KNN算法实现
前言
暑假自学深度学习的时候曾经写过的几个卷积神经网络的基础算法,因为自己也是新手,所以自认为注释写的相当友好hhh。
一、KNN是什么?
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
二、原理介绍
1.对数据预处理
1. 计算测试样本点
-
(也就是待分类点)到其他每个样本点的距离,一般我们选择的距离计算方法位欧式距离计算。
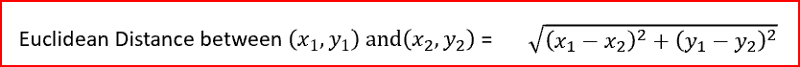
-
对每个距离进行排序,然后选择出距离最小的K个点 。
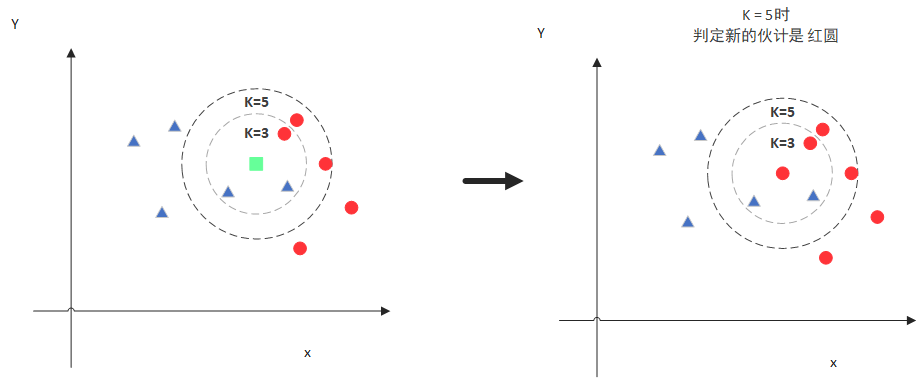
-
对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。
2. 读入数据
代码如下(示例):
import numpy as np
.npy文件是numpy专用的二进制文件
arr = np.array([[1, 2], [3, 4]])
# 保存.npy文件
np.save("../data/arr.npy", arr)
print("save .npy done")
#读取.npy文件
np.load("../data/arr.npy")
print(arr)
print("load .npy done")
三、完整代码实现
1. KNN方法优缺点
- 优点:思路简单,不需要估计参数和训练
- 缺点:计算量较大,每一个待分类的样本都要计算它到全体已知样本的距离,来求得最近距离及其分类。
2. 代码实现
'''
算法原理:
根据测试样本的特征,去训练集中,找距离最近的K个训练样本,取类别数最多的这类,作为测试样本的标签。
函数参数:
trainData - 训练集
testData - 测试集
labels - 分类
'''
#引入numpy库
import operator
import numpy as np
def knn(trainData, testData, labels, k):
# 计算训练样本的行数
rowSize = trainData.shape[0]
# 计算训练样本和测试样本的差值
diff = np.tile(testData, (rowSize, 1)) - trainData
# 计算欧氏距离
sqrDiff = diff ** 2
distances = sqrDiff.sum(axis=1)
# 对所得的距离从低到高进行排序
sortDistance = distances.argsort()
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
count[vote] = count.get(vote, 0) + 1
# 对类别出现的频数从高到低进行排序
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
# 返回出现频数最高的类别
return sortCount[0][0]
#加载转换好的.npy文件
train_feat = np.load("train_feat.npy")
train_label = np.load("train_label.npy")
test_feat = np.load("test_feat.npy")
test_label = np.load("test_label.npy")
#print(train_feat.shape)
#print(test_feat.shape)
#print(train_label)
#输出KNN算法的模型计算准确率
for i in range(len(test_feat)):
pred = knn(train_feat, test_feat[i][:], train_label, 10)
print(i, " - pred:", pred, " gd:", test_label[i])
总结
以上就是关于python实现KNN算法的内容,感觉有帮助可以为博主点赞。
版权声明:本文为weixin_45750855原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。